























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase In-Memory Compaction
HBase In-Memory Compaction
展开查看详情
1 .Acco r d i o n : H B a s e B re at h e s w it h I n - M e m o r y C o m p act i o n Eshcar Hillel, Anastasia Braginsky, Edward Bortnikov ⎪ HBaseCon, Jun 12, 2017
2 . The Team Michael Stack Edward Bortnikov Anoop Sam John Eshcar Hillel Anastasia Braginsky Ramkrishna Vasudevan (committer) (committer) 2
3 . Quest: The User’s Holy Grail In-Memory Reliable Database Persistent Performance Storage 3
4 . What is Accordion? Novel Write-Path Algorithm Better Performance of Write-Intensive Workloads Write Throughput ì, Read Latency î Better Disk Use Write amplification î GA in HBase 2.0 (becomes default MemStore implementation) 4
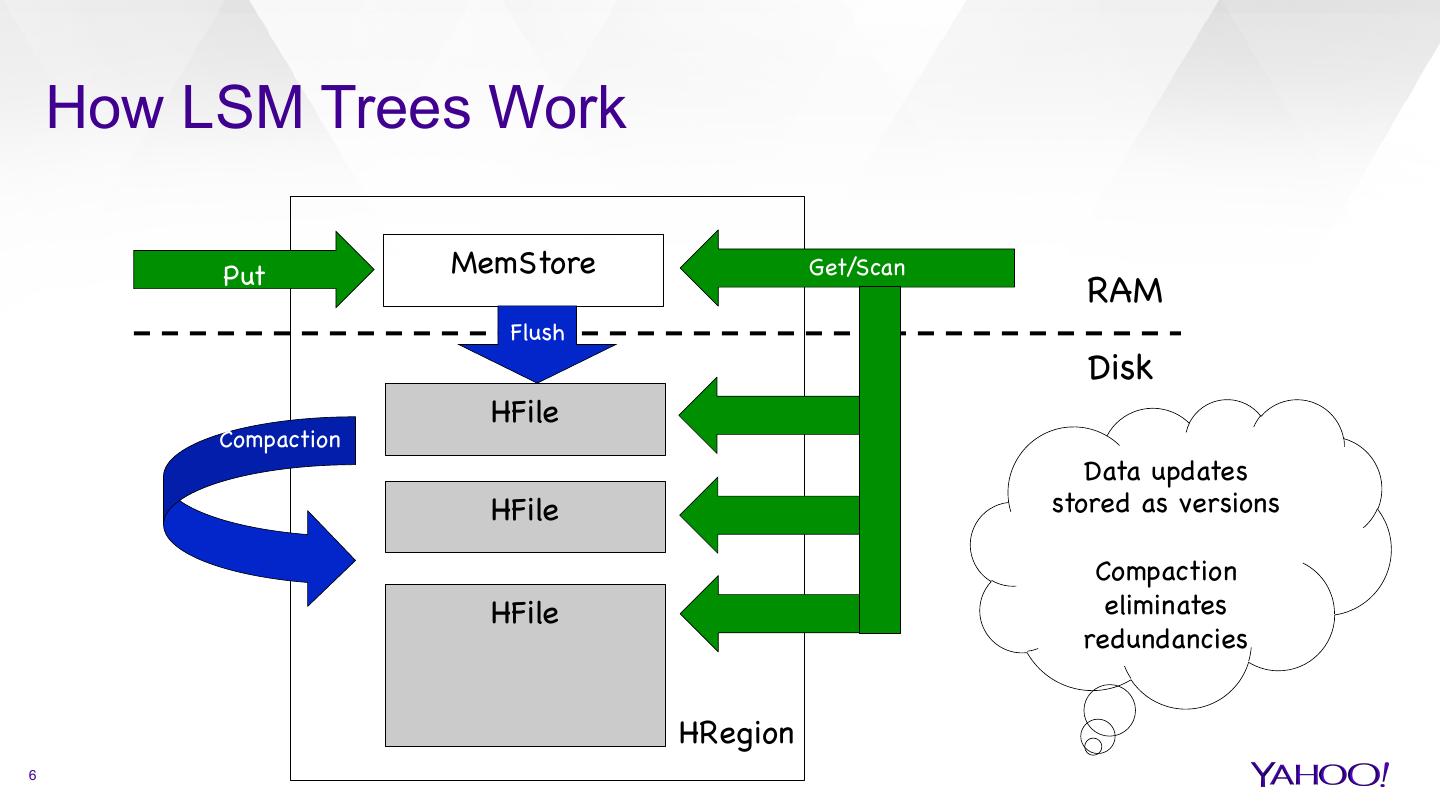
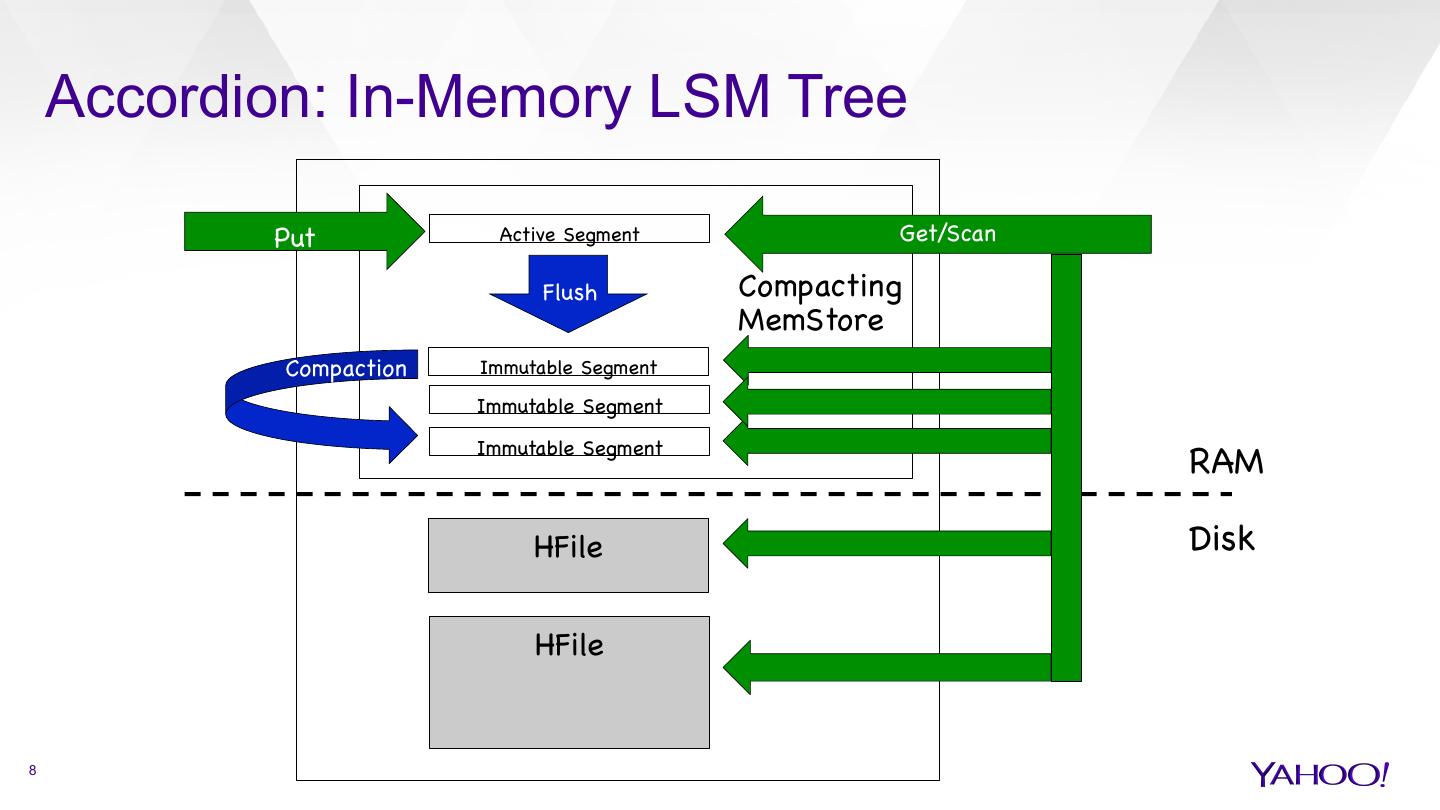
5 . In a Nutshell Inspired by Log-Structured-Merge (LSM) Tree Design Transforms random I/O to sequential I/O (efficient!) Governs the HBase storage organization Accordion reapplies the LSM Tree design to RAM data à Efficient resource use – data lives in memory longer à Less disk I/O à Ultimately, higher speed 5
6 . How LSM Trees Work Put MemStore Get/Scan RAM Flush Disk HFile Compaction Data updates HFile stored as versions Compaction HFile eliminates redundancies HRegion 6
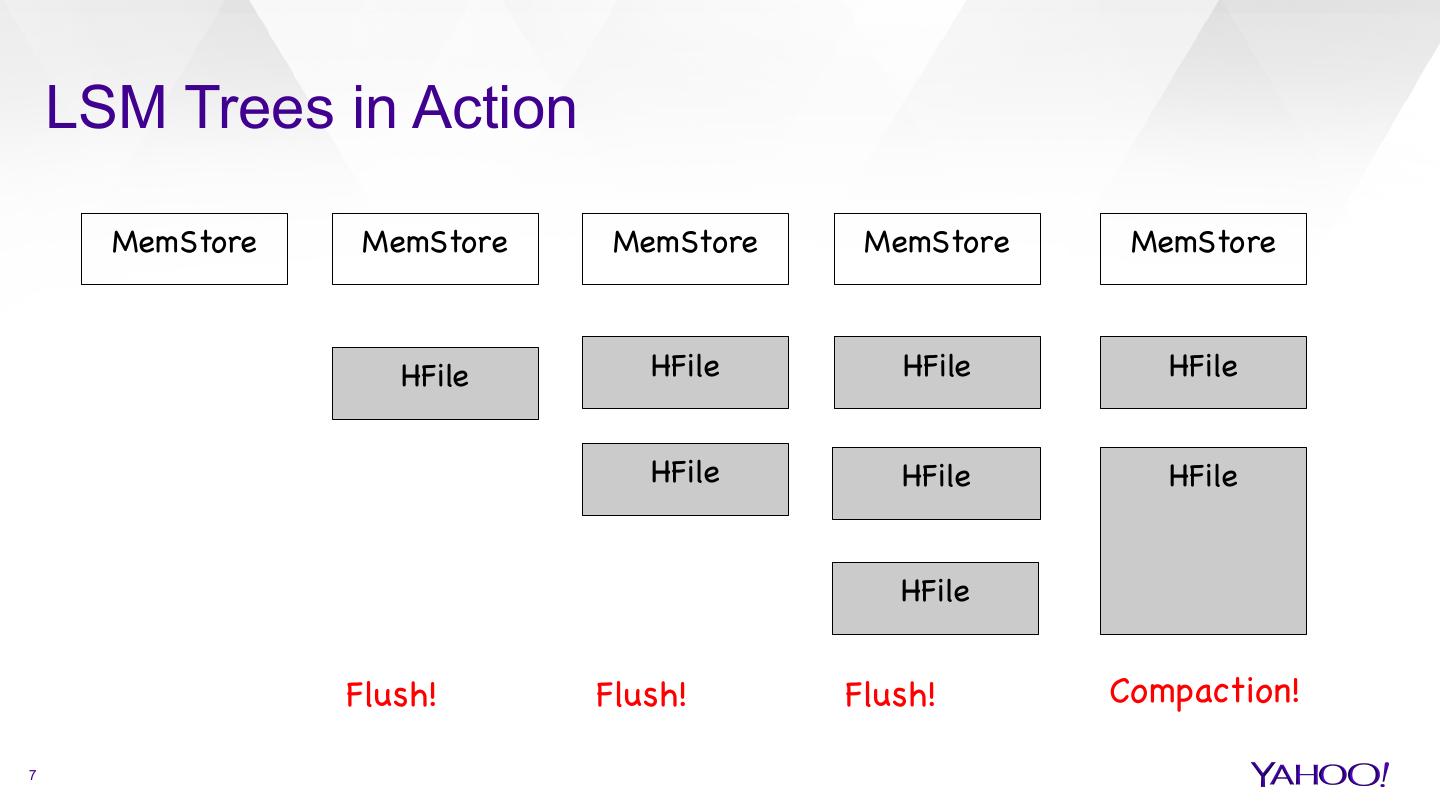
7 . LSM Trees in Action MemStore MemStore MemStore MemStore MemStore HFile HFile HFile HFile HFile HFile HFile HFile Flush! Flush! Flush! Compaction! 7
8 . Accordion: In-Memory LSM Tree Put Active Segment Get/Scan Flush Compacting MemStore Compaction Immutable Segment Immutable Segment Immutable Segment RAM HFile Disk HFile 8
9 . Accordion in Action Active Active Active Active Active Segment Segment Segment Segment Segment Compaction Immutable Immutable Immutable Segment Segment Pipeline Segment Immutable Segment Snapshot In-Memory In-Memory In-Memory Disk Flush! Flush! Flush! Compaction! 9
10 . Flat Immutable Segment Index Skiplist Index CellArrayMap Index Flatten KV- Objects Poiuytrewqa qqqwertyuioas k;wjt;wiej;iwjJkkgkykytcc Jkkgkykytktjjjjo dfghjklrtyuiopl ooooooqqbyfjt opppqqqyrtadddeiuyowehmnppppbv kjhgfpppwww dhghfhfngfhfg qqqwertyuioas Jkkgkyaaabbyf cxqqaaaxcv mnbvcmnb bcccdddeiuyo aajeutkiyt uoweiuoieu utkldfk;iopppdiwpoqqqaa hjkl;;mnppppdfghjklrtyuioplk jtdhghfhfngfhfg b weuoweiuoieu qqqyrtaaajeabbbcccddw bvcxqqaaax jhgfpppwwwm bcccdddeiuyo utkiyt euoweiuoieucvb nbvcmnb weuoweiuoieu Poiuytrewqa qqqwertyuioas Hhjs Jkkgkykytkt dfghjklrtyuiopl Jkdddfkgbbbd iutkldfk;wjt;w gcccdddeiuy sdfaaabbbm kjhgfpppwww iwpoqqqaaacc HhjjuuyrqaaJkkgkykytktg qqqwertyuioas Jkdddfkaabbb Poiuytrejkl;; dfghjklrtyuioplk nppppbvcxq mnbvcmnb cdddeiuyoweu iejerg;ioppoweuoweiuo Cell Storage ss kg;diwpoqeu mnppppbvcx jhgfpppwwwm cccdddeiuyow qqaaaxcvb nbvcmnb iuaaajeutkiytoweiuoieu euoweiuoieu Cell Storage ieu qaaaxcvb oweiuoieu Lean footprint – the smaller the cells the better! 10
11 . Redundancy Elimination In-Memory Compaction merges the pipelined segments Get access latency under control (less segments to scan) BASIC compaction Multiple indexes merged into one, cell data remains in place EAGER compaction Redundant data versions eliminated (SQM scan) 11
12 . BASIC vs EAGER BASIC: universal optimization, avoids physical data copy EAGER: high value for highly redundant workloads SQM scan is expensive Data relocation cost may be high (think MSLAB!) Configuration BASIC is default, EAGER may be configured Future implementation may figure out the right mode automatically 12
13 . Compaction Pipeline: Correctness & Performance Shared Data Structure Read access: Get, Scan, in-memory compaction Write access: in-memory flush, in-memory compaction, disk flush Design Choice: Non-Blocking Reads Read-Only pipeline clone – no synchronization upon read access Copy-on-Write upon modification Versioning prevents compaction concurrent to other updates 13
14 . More Memory Efficiency - KV Object Elimination CellArrayMap Index CellChunkMap Index Poiuytrewqa qqqwertyuioas k;wjt;wiej;iwjJkkgkykytcc Jkkgkykytktjjjjo dfghjklrtyuiopl ooooooqqbyfjt Poiuytrewqa qqqwertyuioas k;wjt;wiej;iwjJkkgkykytcc Jkkgkykytktjjjjo dfghjklrtyuiopl ooooooqqbyfjt opppqqqyrtadddeiuyowehmnppppbv kjhgfpppwww dhghfhfngfhfg opppqqqyrtadddeiuyowehmnppppbv kjhgfpppwww dhghfhfngfhfg cxqqaaaxcv mnbvcmnb bcccdddeiuyo aajeutkiyt uoweiuoieu cxqqaaaxcv mnbvcmnb bcccdddeiuyo aajeutkiyt uoweiuoieu b weuoweiuoieu b weuoweiuoieu Poiuytrewqa qqqwertyuioas Hhjs Jkkgkykytkt dfghjklrtyuiopl Jkdddfkgbbbd Poiuytrewqa qqqwertyuioas Hhjs Jkkgkykytkt dfghjklrtyuiopl Jkdddfkgbbbd Cell Storage iutkldfk;wjt;w gcccdddeiuy sdfaaabbbm kjhgfpppwww iwpoqqqaaacc iutkldfk;wjt;w gcccdddeiuy sdfaaabbbm kjhgfpppwww iwpoqqqaaacc nppppbvcxq mnbvcmnb cdddeiuyoweu iejerg;ioppoweuoweiuo ieu qaaaxcvb oweiuoieu nppppbvcxq mnbvcmnb cdddeiuyoweu iejerg;ioppoweuoweiuo ieu qaaaxcvb oweiuoieu Cell Storage Lean Footprint (no KV-Objects). Friendly to Off-Heap Implementation. 14
15 . The Software Side: What’s New? CompactingMemStore: BASIC and EAGER configurations DefaultMemStore: NONE configuration Segment Class Hierarchy: Mutable, Immutable, Composite NavigableMap Implementations: CellArrayMap, CellChunkMap MemStoreCompactor: compaction algorithms implementation 15
16 . CellChunkMap Support (Experimental) Cell objects embedded directly into CellChunkMap (CCM) New cell type - reference data by unique ChunkID ChunkCreator: Chunk allocation + ChunkID management Stores mapping of ChunkID’s to Chunk references Strong references to chunks managed by CCM’s, weak to the rest The CCM’s themselves are allocated via the same mechanism Some exotic use cases E.g., jumbo cells allocated in one-time chunks outside chunk pools 16
17 . Evaluation Setup System 2-node HBase on top of 3-node HDFS, 1Gbps interconnect Intel Xeon E5620 (12-core), 2.8TB SSD storage, 48GB RAM RS config: 16GB RAM (40% Cache/40% MemStore), on-heap, no MSLAB Data 1 table (100 regions, 50 columns), 30GB-100GB Workload Driver YCSB (1 node, 12 threads) Batched (async) writes (10KB buffer) 17
18 . Experiments Metrics Write throughput, read latency (distribution), disk footprint/amplification Workloads (varied at client side) Write-Only (100% Put) vs Mixed (50% Put/50% Get) Uniform vs Zipfian Key Distributions Small Values (100B) vs Big Values (1K) Configurations (varied at server side) Most experiments exercise Async WAL 18
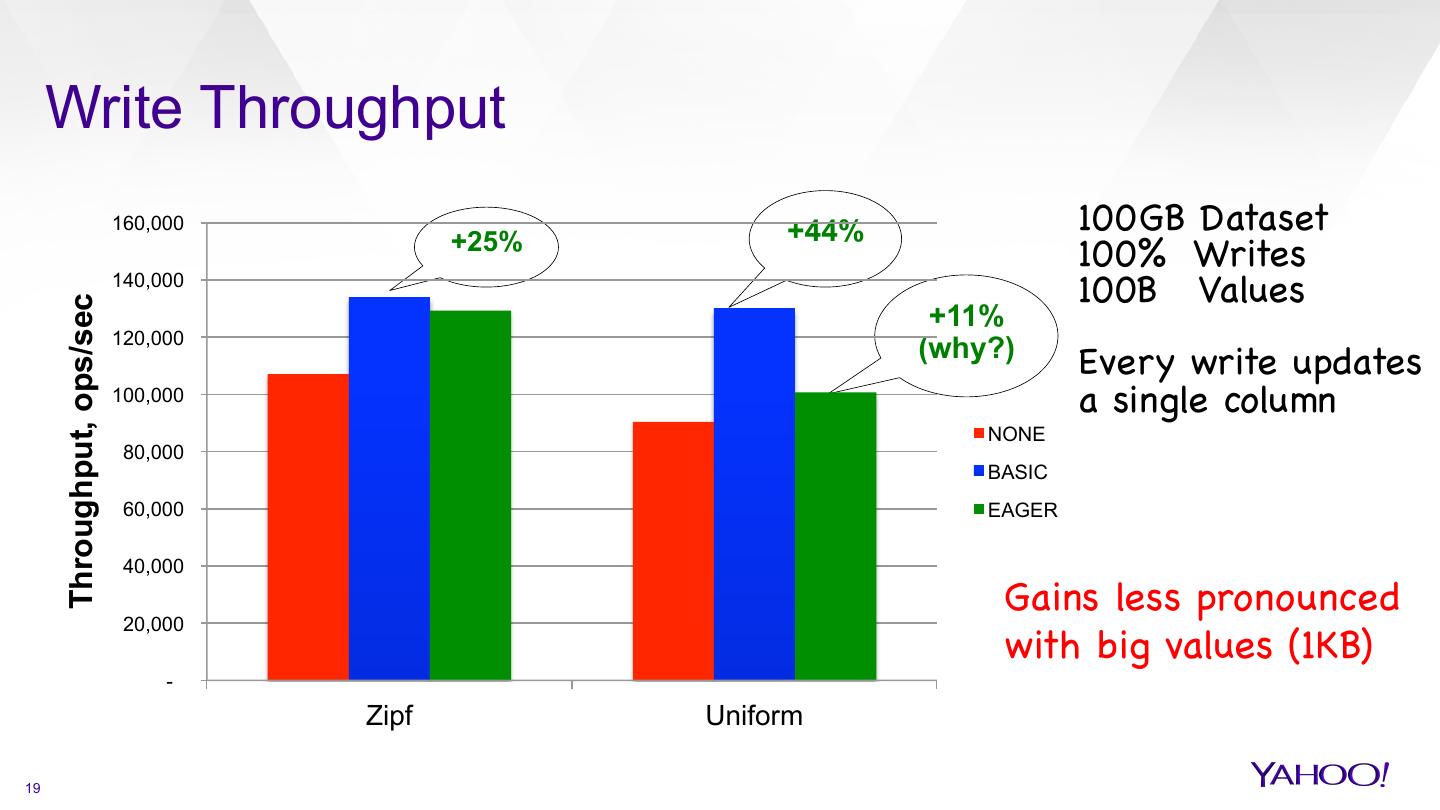
19 . Write Throughput 160,000 +44% 100GB Dataset +25% 100% Writes 140,000 100B Values Throughput, ops/sec +11% 120,000 (why?) Every write updates 100,000 a single column NONE 80,000 BASIC 60,000 EAGER 40,000 Gains less pronounced 20,000 with big values (1KB) - Zipf Uniform 19
20 . Single-Key Write Latency 7 100GB Dataset 6 Zipf distribution 100% Writes 5 100B Values Latency, ms 4 NONE BASIC 3 EAGER 2 1 0 50% (median) 75% 95% 99% (tail) 20
21 . Single-Key Read Latency +9% 6 (why?) 30GB Dataset 5 Zipf Distribution -13% 50% Writes/50% Reads 4 100B Values Latency, ms NONE 3 BASIC EAGER 2 1 0 50% (median) 75% 95% 99% (tail) 21
22 . Disk Footprint/Write Amplification 1200 100GB Dataset Zipf Distribution 1000 100% Writes 800 -29% NONE 100B Values 600 BASIC 400 EAGER 200 0 Flushes Compactions Data Written (GB) 22
23 . Status In-Memory Compaction GA in HBase 2.0 Master JIRA HBASE-14918 complete (~20 subtasks) Major refactoring/extension of the MemStore code Many details in Apache HBase blog posts CellChunkMap Index, Off-Heap support in progress Master JIRA HBASE-16421 23
24 . Summary Accordion = a leaner and faster write path Space-Efficient Index + Redundancy Elimination à less I/O Less Frequent Flushes à increased write throughput Less On-Disk Compaction à reduced write amplification Data stays longer in RAM à reduced tail read latency Edging Closer to In-Memory Database Performance 24
25 . Thanks to Our Partners for Being Awesome 25
3秒后跳转登录页面
去登陆

