展开查看详情
1 .HBase i n Youzan HBase 在有赞的平台实践和应用
2 .目录 / Contents 01 关于我们 02 管控平台 03 改造与业务实践 04 未来展望
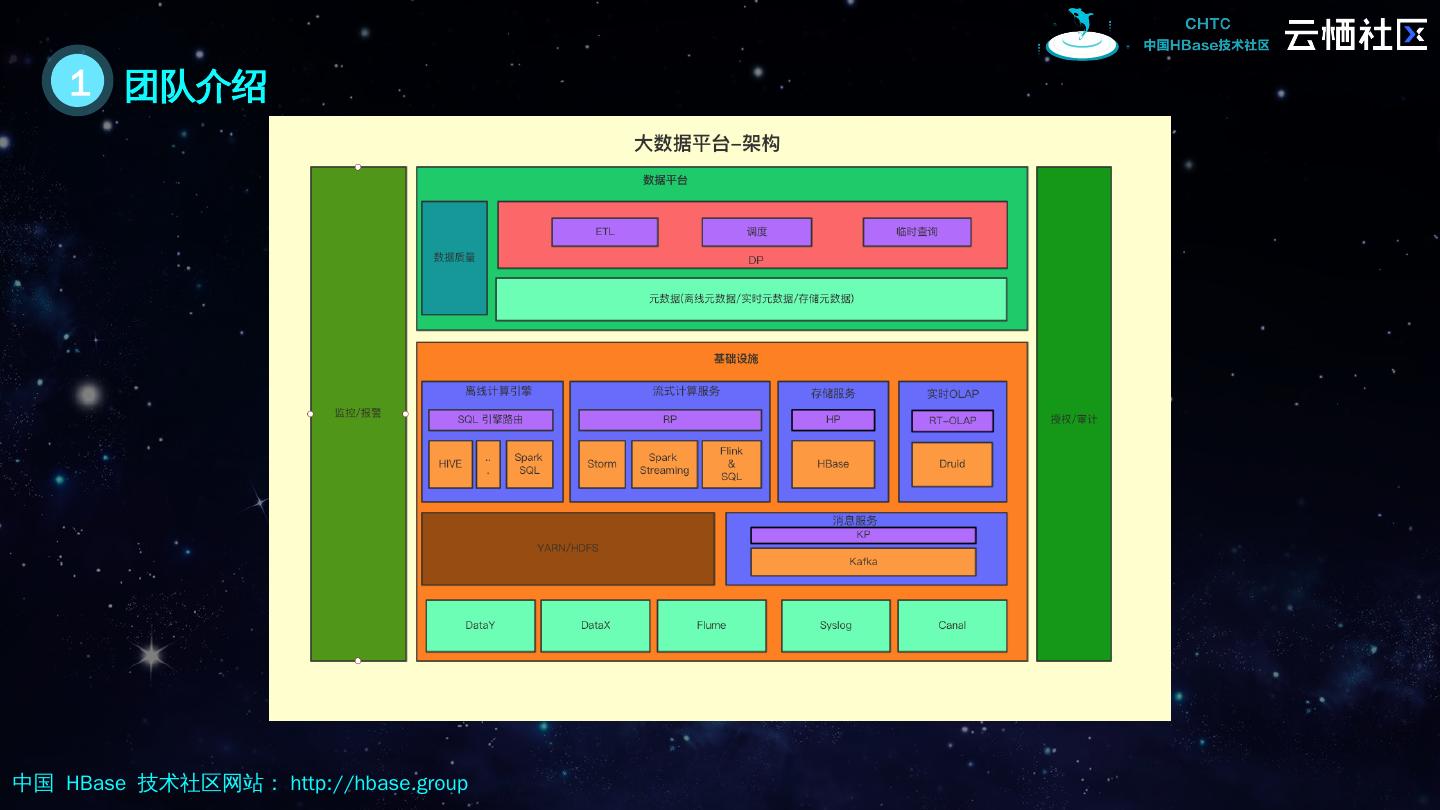
5 .1 HBase 产品定位 多集群容灾存储,在线实时访问 在线存储 离线批量导入导出,非敏感实时读取, 数据冷备 离线存储 OpenTSDB 组件后端存储 监控数据存储 K ylin 的后端存储 Kylin 服务
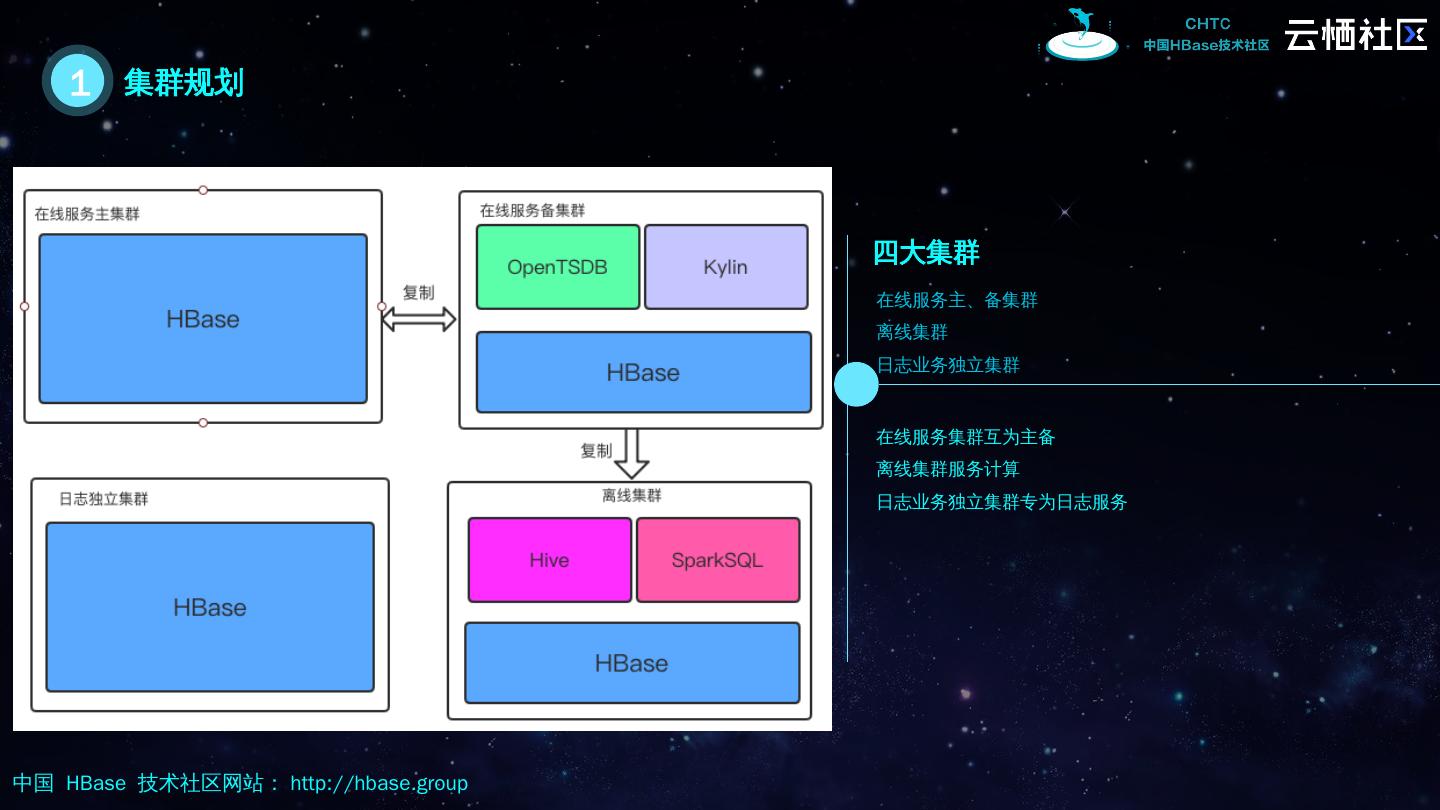
6 .1 集群规划 四大集群 在线服务集群互为主备 离线集群服务计算 日志业务独立集群专为日志服务 在线服务主、备集群 离线集群 日志业务独立集群
8 .2 管控平台 只有一个离线大集群,部署了很多组件 混布问题 不知道接入了多少业务,不知道哪些业务需要什么样的 SLA ,出了问题找不到对接人 业务管控问题 痛点 …… 原有的监控不够灵活,告警配置单一,难扩展 监控系统问题 人肉运维问题 没有成熟好用的迁移工具等运维工具,全靠人肉运维
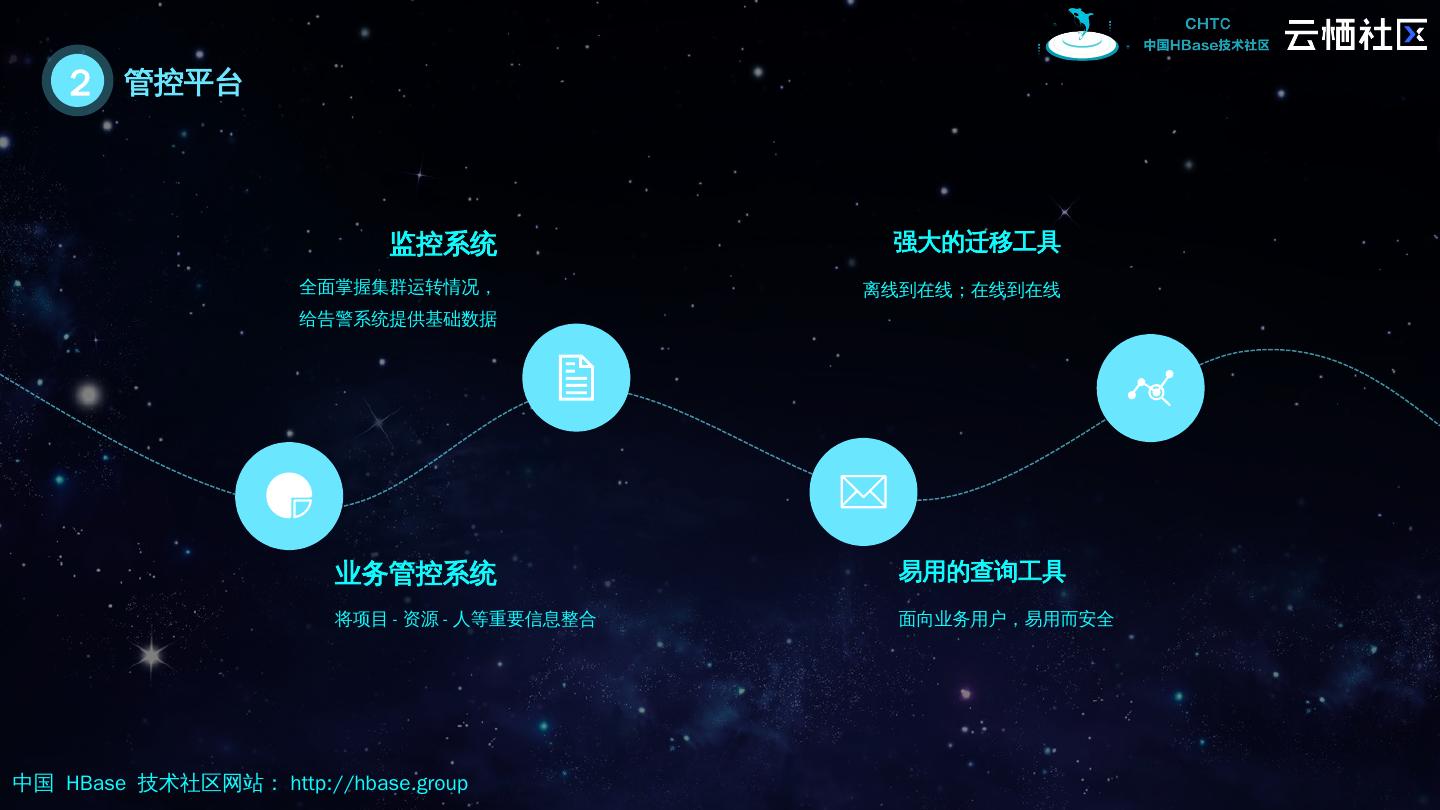
9 .2 管控平台 将 项目 - 资源 - 人等重要信息整合 业务 管控系统 全面掌握集群运转情况 , 给 告警系统提供基础数据 监控系统 面向业务用户,易用而安全 易用的查询工具 离线到在线;在线到在线 强大的迁移工具
10 .2 管控平台 / 业务管控 工单 权限 大盘 用户申请建表统一需要走工单流程审批,所有操作有迹可循 业务用户可以根据需求申请项目级别的权限,查看其它表的元信息与监控数据 核心指标监控有数据大盘,哪些表占用了最多的资源一目了然 面向用户
11 .2 管控 平台 / 监控系统 系统级别监控 相比原有监控系统的 优势 支持 RegionServer 逻辑 分组 指标逻辑 分组 关键指标监控 系统级别, RS 级别
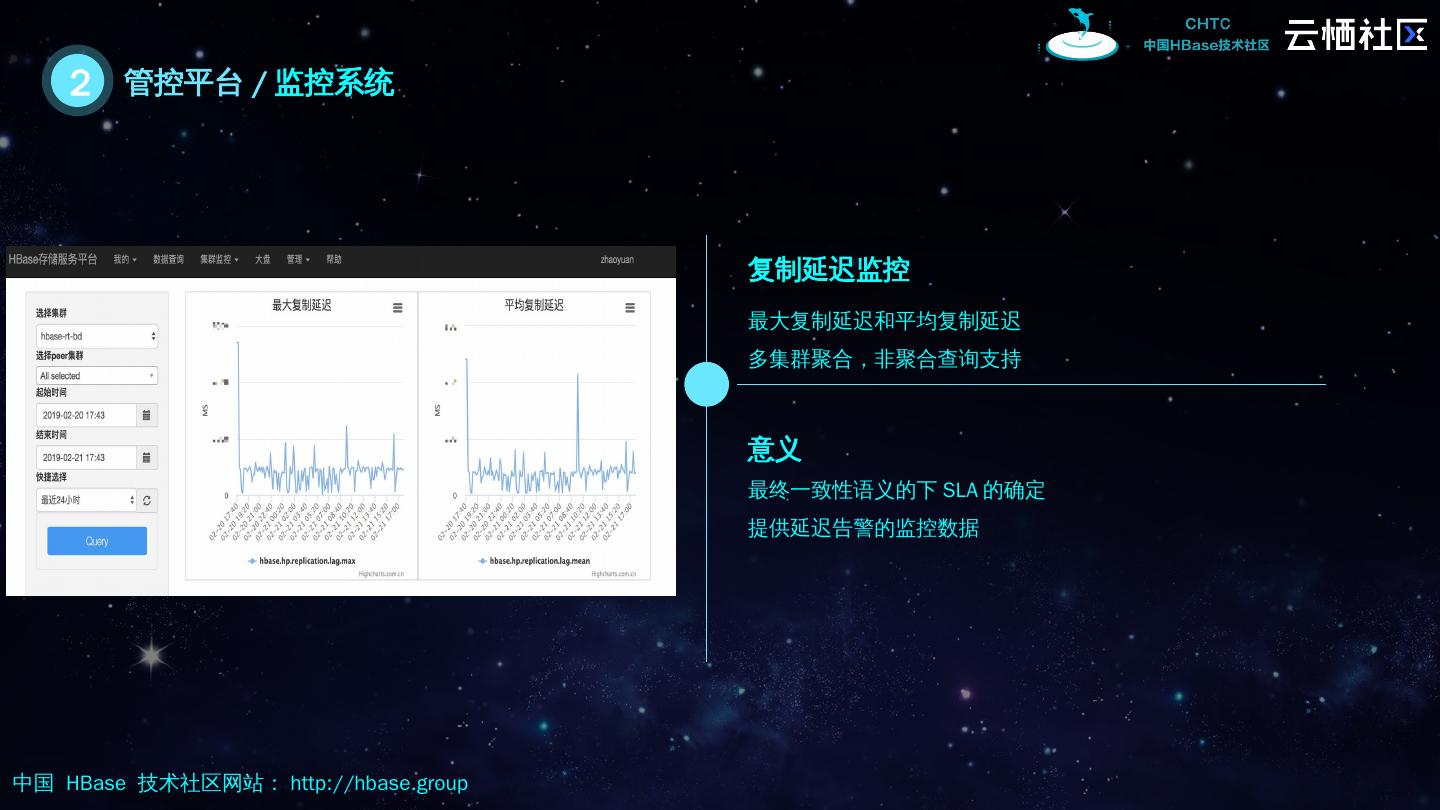
12 .2 管控 平台 / 监控系统 复制延迟监控 意义 最终一致性语义的下 SLA 的确定 提供延迟告警的监控数据 最大复制延迟和平均复制延迟 多集群聚合,非聚合查询支持
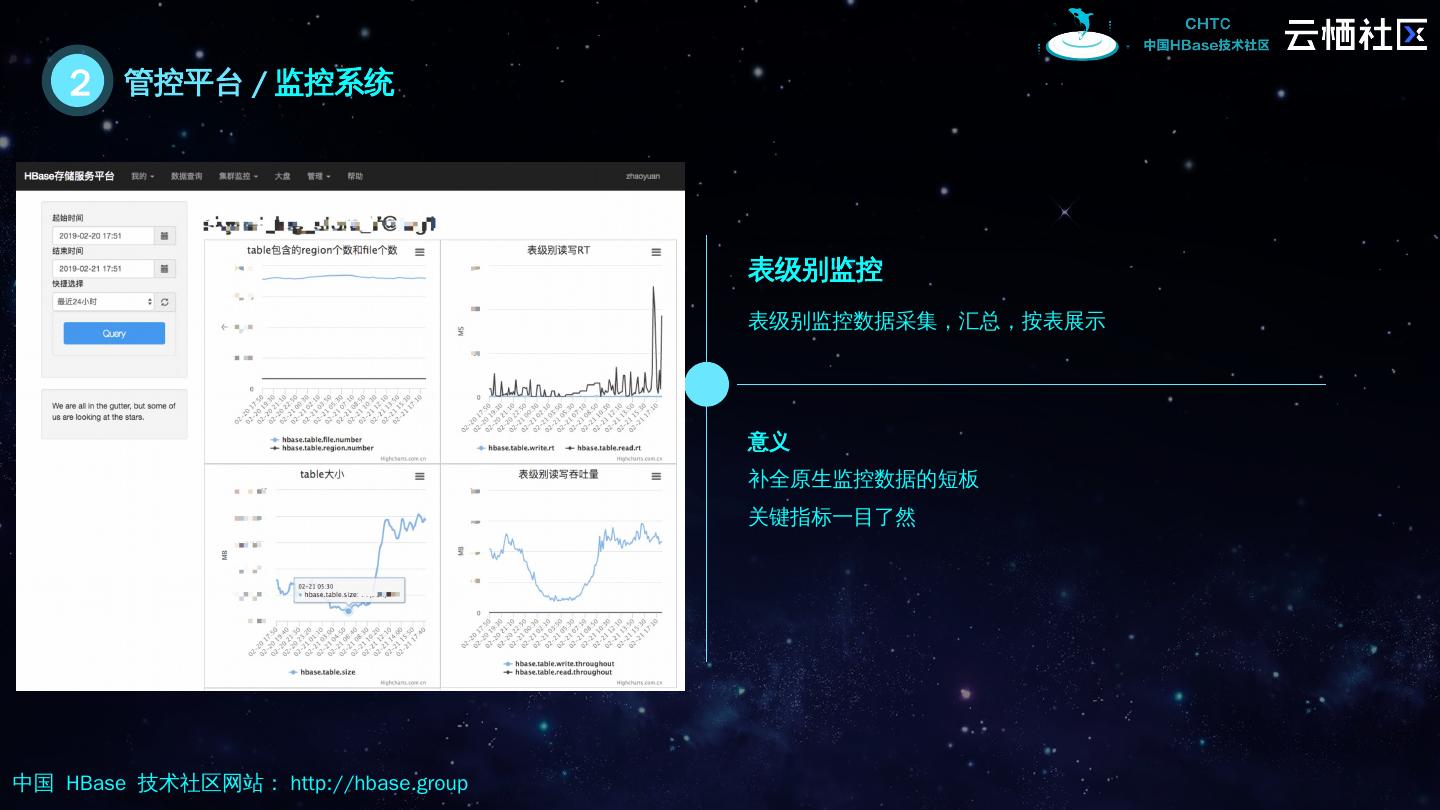
13 .2 管控平台 / 监控系统 表级别监控 意义 补全原生监控数据的短板 关键指标一目了然 表级别监控数据采集,汇总,按表展示
14 .2 管控 平台 / 告警 RIT , RS dead count , Replication lag …… Phone , sms , wechat … . Group , Person 定制化告警
15 .2 管控平台 / 效率工具 Hive-> HBase bulkoad 方式导入 工具 HBase 集群间数据 同步 MySql -> HBase Hive-> HBase , ; DataX 在线查询工具,方便用户 ad hoc query
17 .03 改造与业务实践 我们在 1.2.6 版本之上做了哪些改造,我们为何要做这些改造,这些改造给业务带来了哪些价值?
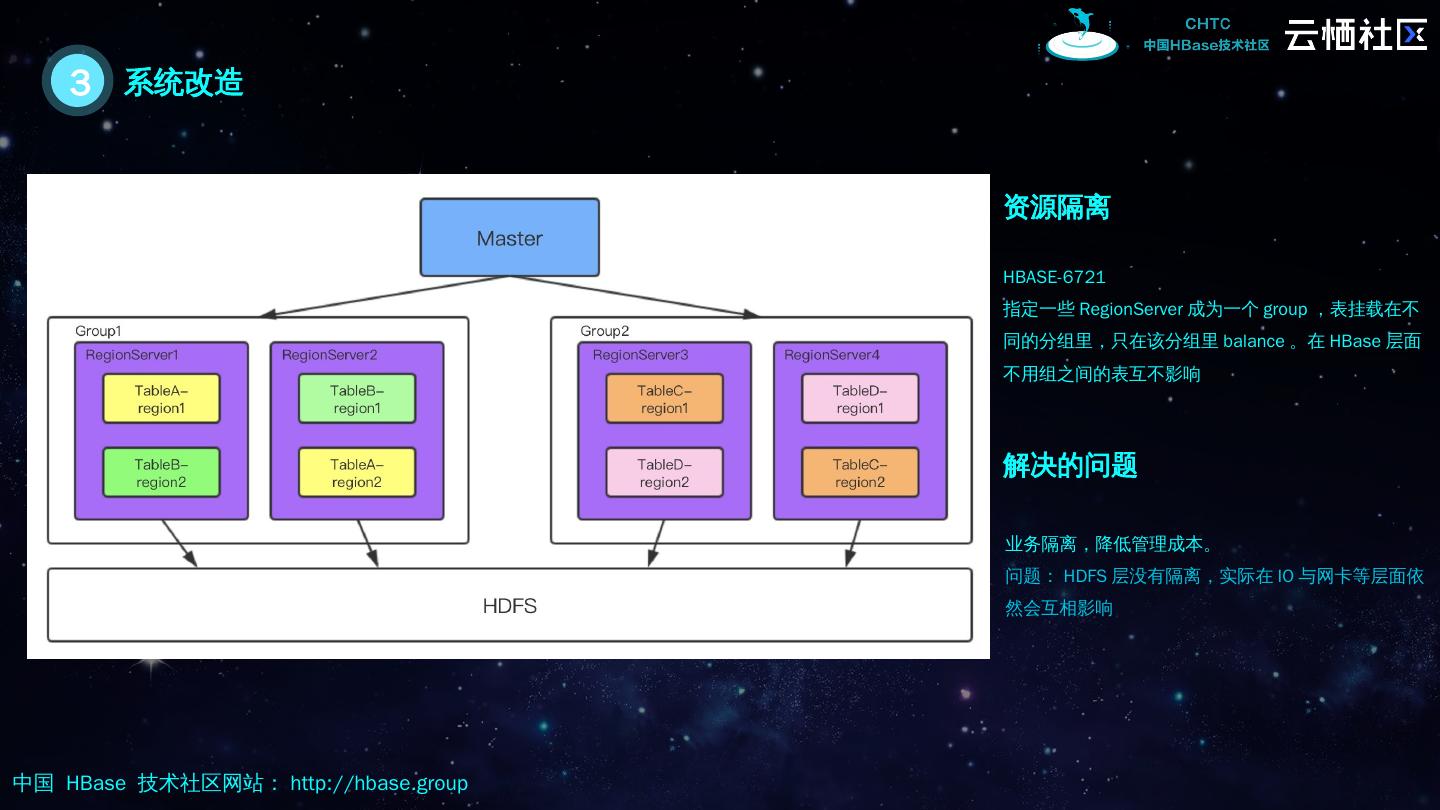
18 .3 系统改造 资源隔离 HBASE-6721 指定一些 RegionServer 成为一个 group ,表挂载在不同的分组里,只在该分组里 balance 。在 HBase 层面 不用组之间的表互不影响 解决的问题 业务隔离,降低管理成本。 问题: HDFS 层没有隔离,实际在 IO 与网卡等层面依然会互相影响
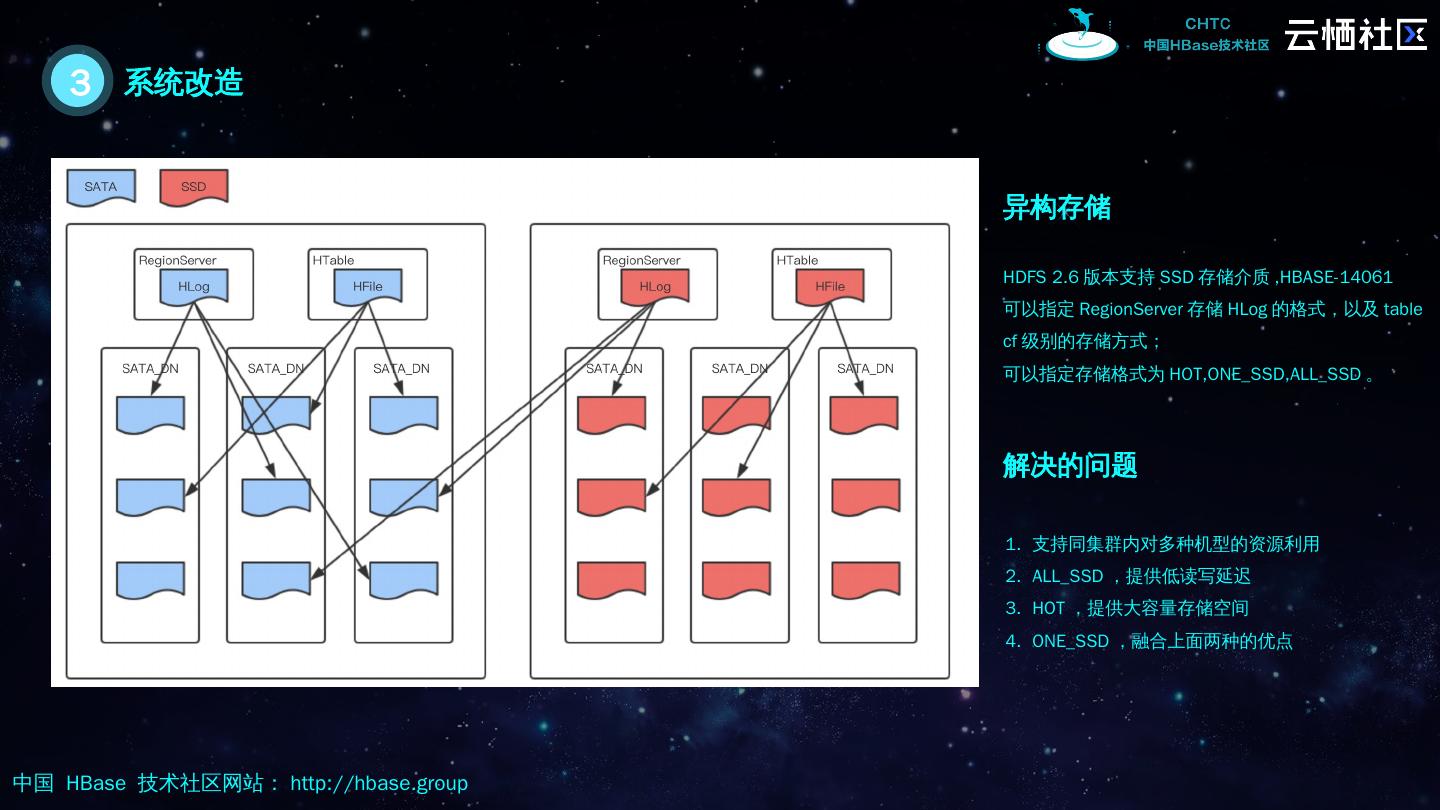
19 .3 系统改造 异构存储 HDFS 2.6 版本支持 SSD 存储介质 , HBASE-14061 可以指定 RegionServer 存储 HLog 的格式,以及 table cf 级别的存储方式; 可以指定存储格式为 HOT,ONE_SSD,ALL_SSD 。 解决的问题 支持同集群内对多种机型的资源利用 ALL_SSD ,提供低读写延迟 HOT ,提供大容量存储空间 ONE_SSD ,融合上面两种的优点
20 .3 系统改造 优化资源隔离 利用 RSGroup 结合异构存储,完成 HBase 层面与 HDFS 层面的双重隔离。 利用廉价的 SATA 存储较多的副本, SSD 存储本地副本,或者所有的副本都存储在 SSD DN 上,达到最好的效果。 解决的问题 1.HDFS 层面的隔离 2. 提供满足不同 SLA 的分组
21 .3 Bug Fixed 监控数据 漏失 Split_policy 无法设置 HBASE-19340 缓存不生效问题 HBASE-20697
22 .3 业务实践 低延迟,高可用 粉丝详情 重写低读,高吞吐 调用链 已接入的业务 天网日志 订单详情 商品详情 消息 风控数据 其他 ……
23 .3 业务实践 / 粉丝详情 ShortCircuit Read Hedged Read ALL_SSD HA READ
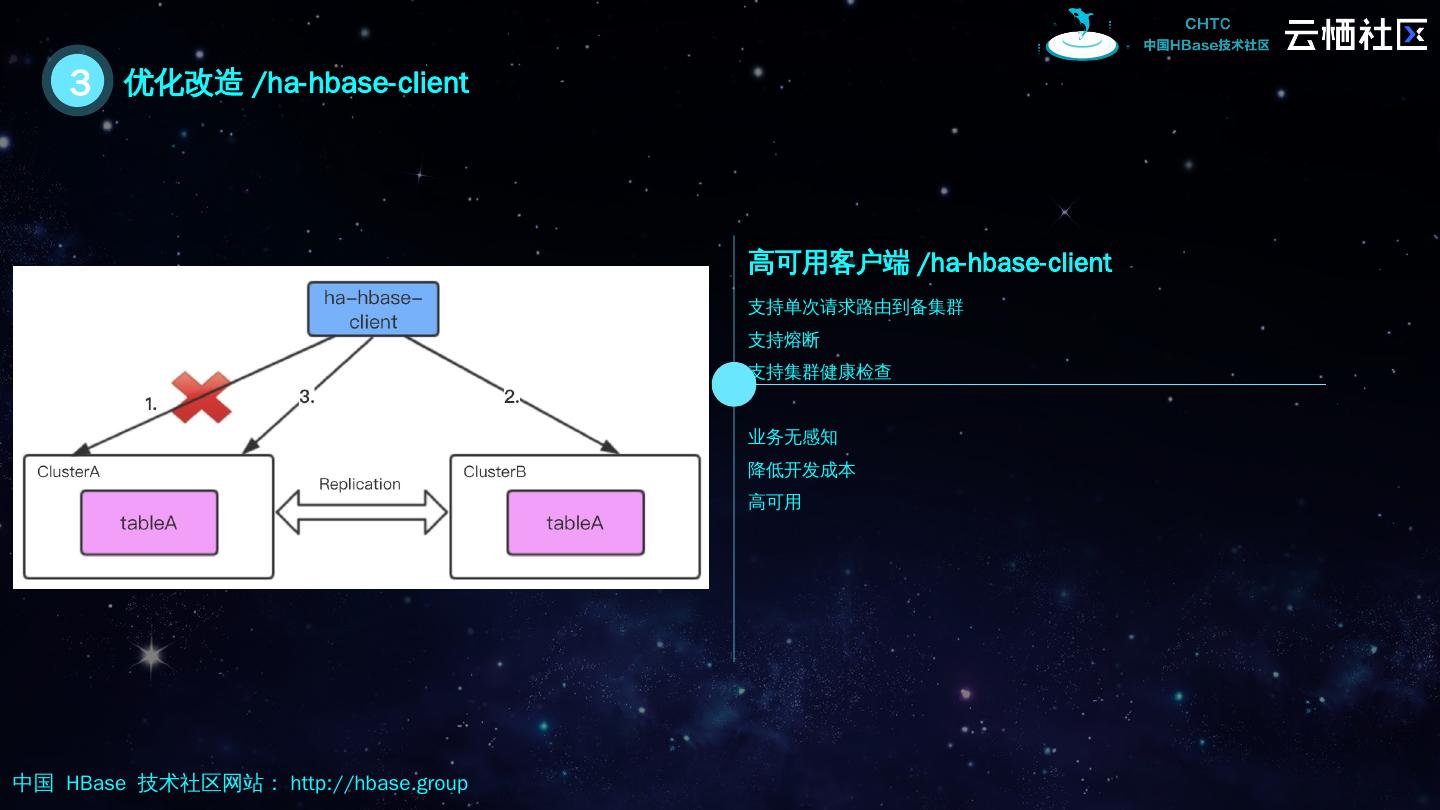
24 .3 优化改造 /ha- hbase -client 高可用客户端 /ha- hbase -client 业务无感知 降低开发成本 高可用 支持单次请求路由到备集群 支持熔断 支持集群健康检查
25 .3 业务实践 / 调用链 在写不发生阻塞的情况,对读写 rt 要求不高 读写延迟不敏感 单条数据平均下来比较大 写 TPS 很高,读 TPS 较少 高吞吐 运维成本偏高 集群负载高,服务不稳定 Cassandra 优化做的不够,掌控能力差 痛点 多台 cassandra ssd 机型 负载高 运维成本高 改造前情况
26 .3 业务实践 / 调用链 预分区 HDFS 副本数 避免 MC
27 .3 业务实践 / 调用链 更少的机器 更稳定的服务 更好的扩展性 我们用更少的机器,更低的负载完成了对调用链的支持,即使调用链流量翻倍,我们可以较快的横向扩展,且不会影响 SLA HBASE !
29 .4 未来规划 获取社区红利,将发现的问题解决的 bug ,产出 patch 回馈社区 跟进社区,反馈社区 完善存储平台,开发更多更有用的工具,接入更多的业务 服务更多的业务 与其他组件有机结合,而不单纯只做一个存储的组件,它将会是实时数仓的重要组成部分 实时数仓的 重要组成部分