展开查看详情
2 . Bridging the Gap between Big Data
System Software Stack and
Applications: The Case of Distributed
Storage Service for Semiconductor
Wafer Fabrication Foundries
Huan-Ping Su (蘇桓平), Yi-Sheng Lien (連奕盛)
National Cheng Kung University
�
3 .Agenda
•Introduction
•Background
•Goal
•Design
•Performance
•Summary
�
4 .Intro
In the semiconductor manufacturing industry,
data volume increases exponentially during the
manufacturing process, which greatly helps in
monitoring and improving production quality.
�
5 .Background
•Heterogeneous storages
(such as FTP, SQL Server, HDFS, HBASE...)
•Data transfer between storages
(moving, coping, ETL...)
•Learning curve for the sophisticated storage
�
6 .Goal
•For easy administration between storages
•Compatible with underlying storages
(We can communicate with different storages in one
protocol )
•Intuitive operation
�
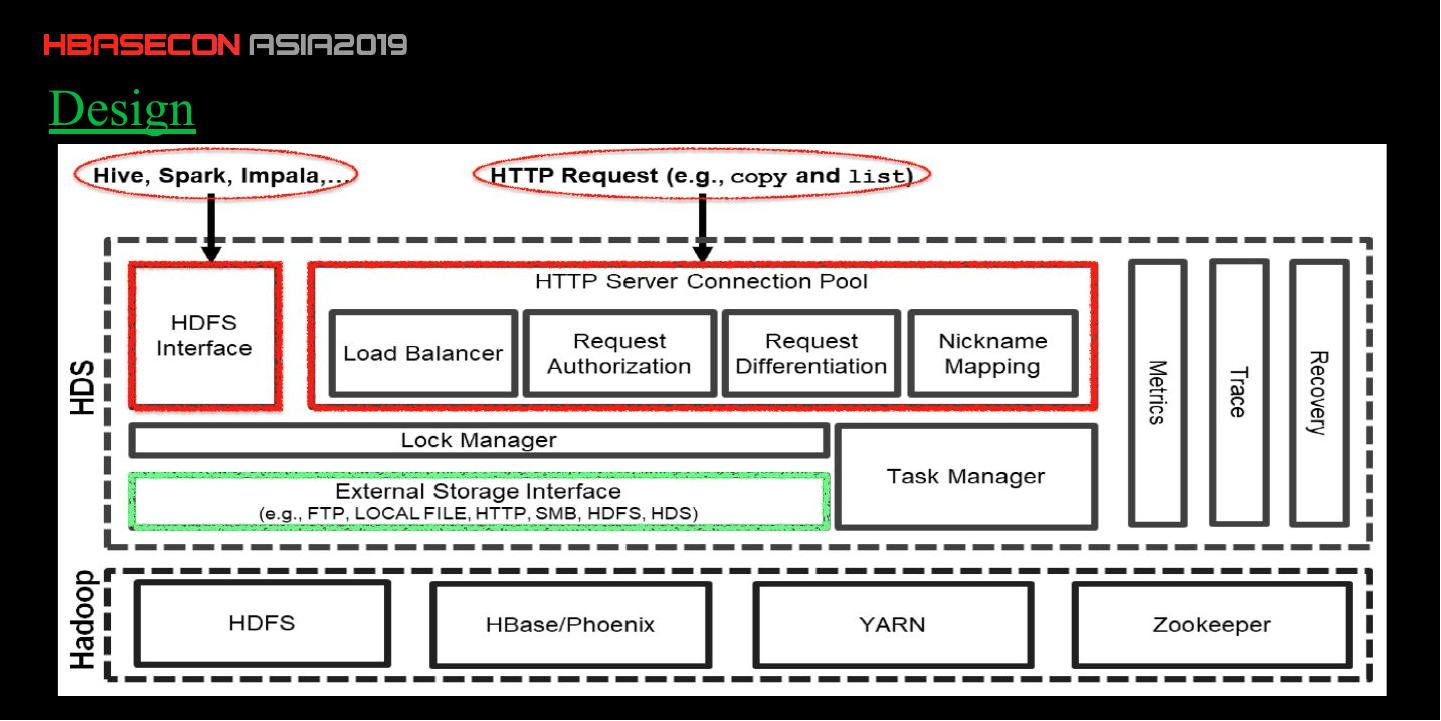
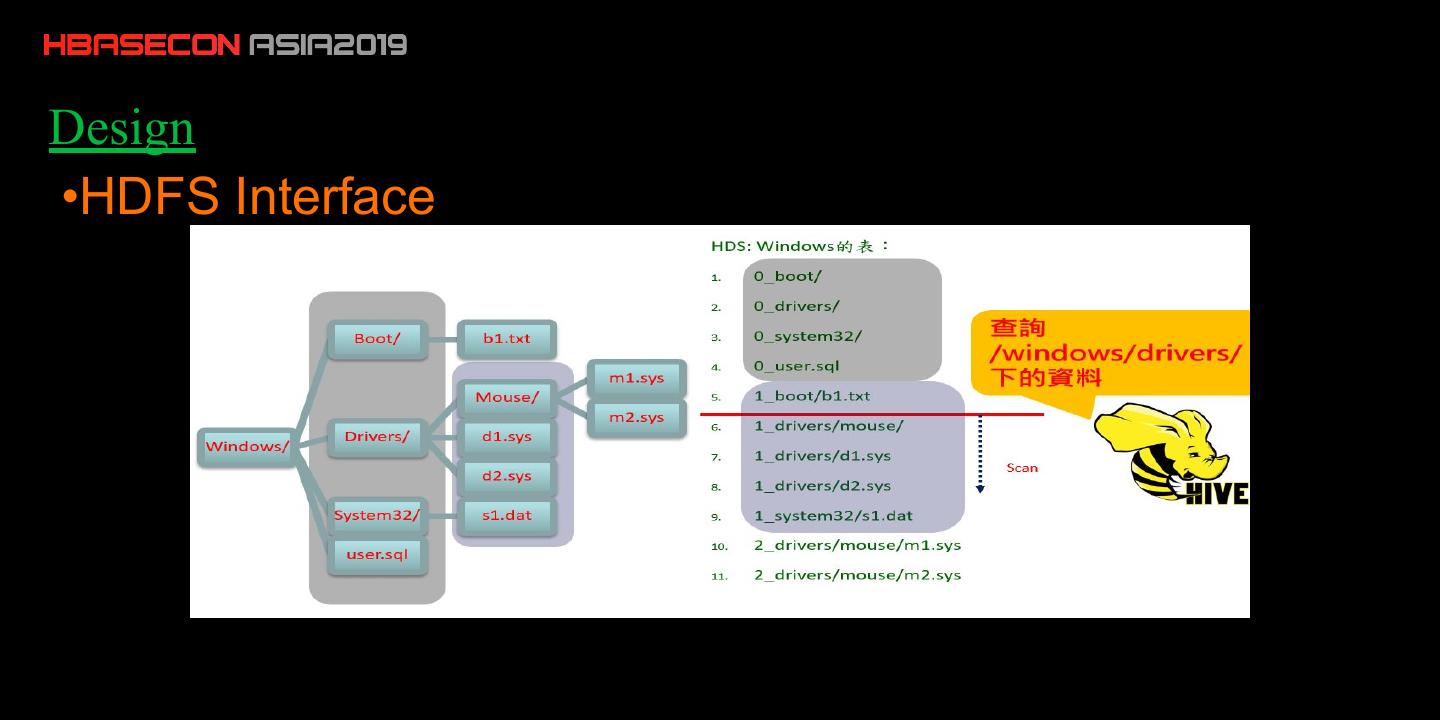
8 .Design
•HDFS Interface
�
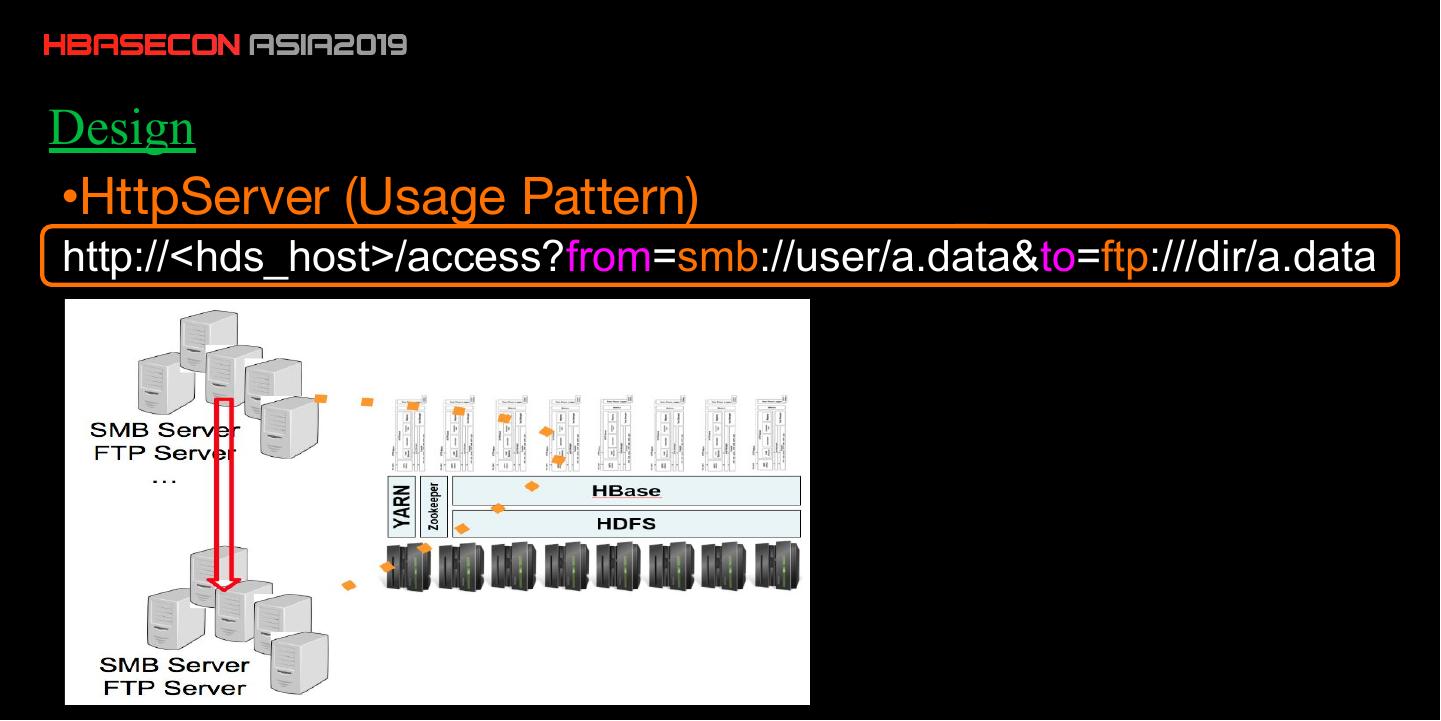
9 .Design
•HttpServer (Usage Pattern)
http://<hds_host>/access?from=smb://user/a.data&to=ftp:///dir/a.data
�
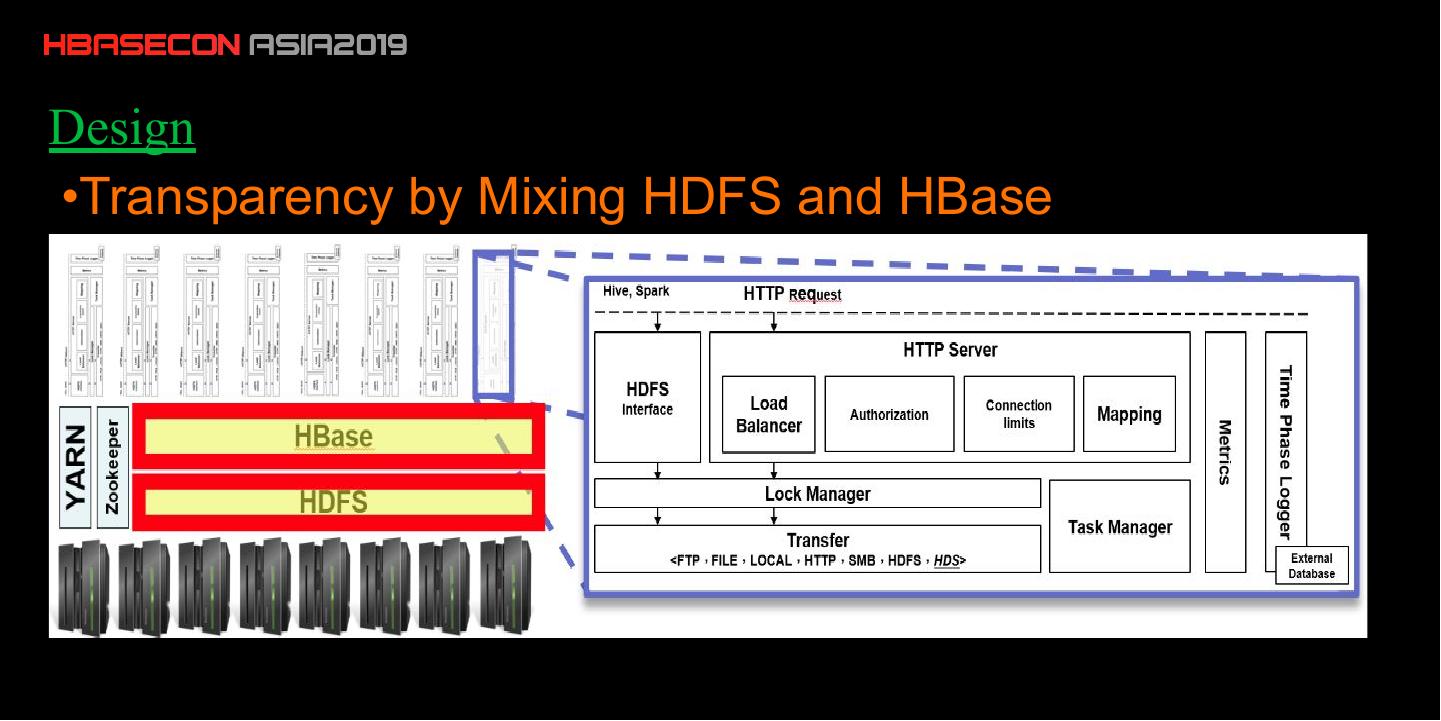
10 .Design
•Transparency by Mixing HDFS and HBase
�
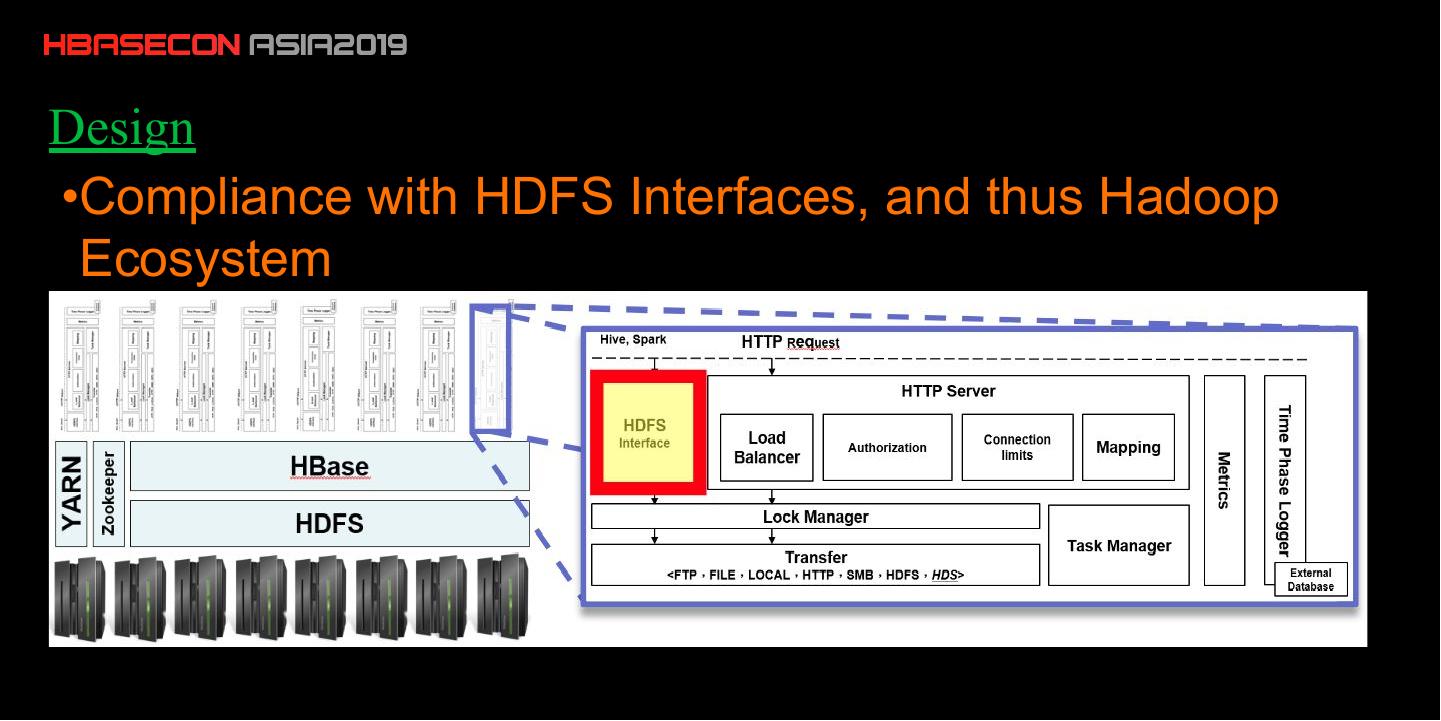
11 .Design
•Compliance with HDFS Interfaces, and thus Hadoop
Ecosystem
�
12 .Design
•Load Balancing
�
13 .Design
•Load Balancing
�
14 .Experimental Setup
•Server Spec
CPU : Intel Xeon E7-8850 @2GHz (80 cores)
Mem : 512GB
Disk : 750GB * 16
•Virtual Machine Spec (16 nodes)
CPU : 80 * 2GHz
Mem : 32GB
Disk : 750GB
�
15 .Experimental Setup
•Cluster Settings
Hadoop 2.6.0-cdh5.10.0
HBase 1.2.0-cdh5.10.0
ZooKeeper 3.4.5-cdh5.10.0
Yarn 2.6.0-cdh5.10.0
Hive 1.1.0-cdh5.10.0
�
16 .Performance Results (Transparency)
Hive and Spark are studied over our HDS
•Hive (r,s) : read small files with hive
(SELECT queries over 30000 files, each with 0.001 MBytes)
•Hive (r,l) : read large files with hive
(SELECT queries over 12 files, each with 16000 MBytes)
•Hive (w) : write with hive
(Hive consequently generates one 32 GBytes file)
�
17 .Performance Results (Transparency)
�
18 .Performance Results (Load balancing)
�
19 .Performance Results (Overheads)
Overhead by HDS, compared with the native HDFS.
The workloads are represented by (1,10000), (100,100),
(1000,10), and (10000,1), where (x,y) denotes the
replication of y files of each in x MBytes from an FTP
server to the HDS cluster.
�
20 .Performance Results (Overheads)
�
21 .Summary
•Solve small file problem in HDFS
•Transparency to different storages
•Compatible with hadoop-eco project
•Improve 1% yield rate of semiconductor manufacturing
�