展开查看详情
1 .Apache HBase at DiDi
Kang Yuan
�
2 .Agenda
1. About Us
2. DiDi HBase Platform
3. Application and Solution
4. Challenges and future
�
3 . About Us
• DiDi
• In <Silicon valley>
�
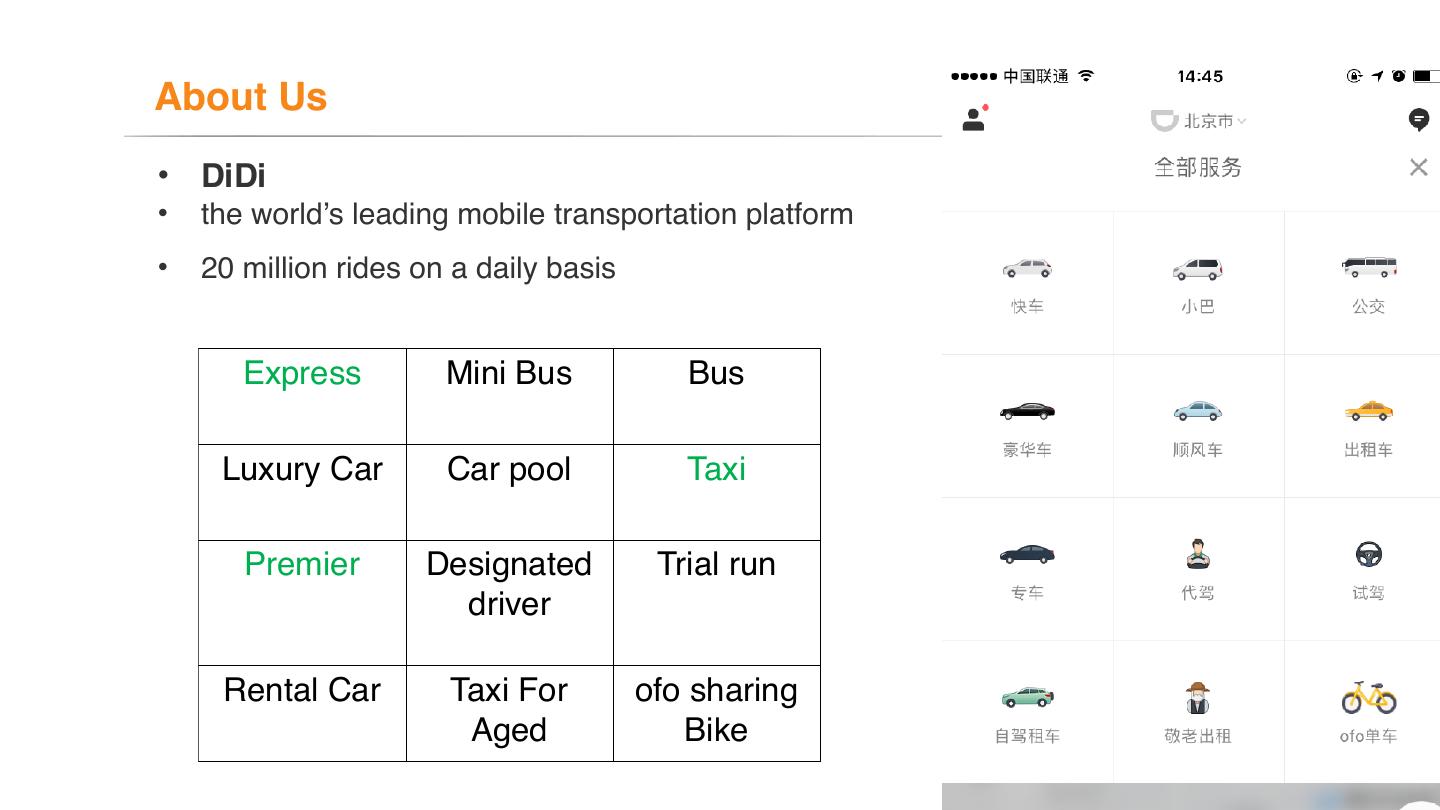
4 .About Us
• DiDi
• the world’s leading mobile transportation platform
• 20 million rides on a daily basis
Express Mini Bus Bus
Luxury Car Car pool Taxi
Premier Designated Trial run
driver
Rental Car Taxi For ofo sharing
Aged Bike
�
5 .About Us
• Mission
To Redefine the Future of Mobility
• Vision
To become a global leader in smart transportation and automotive
technology, the world’s largest operator of vehicle networks and a global
leader in smart transportation systems
�
6 .About Us
• HBase Team:4 Developers
• Kang Yuan
• Yang Li
• Hanzhi Zhang
• Jingyi Yao
• Attached to BigData Architecture Department
• Cooperate with Hadoop/Hive/Spark/Flink/Druid Team closely
�
7 . DiDi HBase Platform
• Cluster(3)
• Storage Cluster – location A
• Compute Cluster – location B
• Storage Cluster – location B
• Location A: the same place with the hadoop Cluster
• Location B: for online business or streaming
• Application(50+ business and 160+ tables)
• Batching Job result storage
• Online writing/reading
• Persistence for Streaming Jobs
• 99.95% available
�
8 .DiDi HBase Platform
• HBase Version
• Based on 0.98.21
• Region Group patch HBASE-6721
• Thrift2 patch
• Multi-tenant Problem
• A bad table can put down a cluster
• We don’t know who the tables belong to
�
9 .DiDi HBase Platform
• Region Group
�
10 .DiDi HBase Platform
• Region Group
• Isolate important use cases from others
• Easy to manage(web ui, user group, operation tools)
• Elastic to assign resources
• Different Configuration in one Cluster(for different machine types,
business, testing etc)
• Easy to compute the cost of the business
• Easy to upgrade the regionserver in one Group before do it in the whole
cluster
• Cost(share pool) = TableSize*x x = cost/GB
• Cost(specific group ) = Rscount*y y = cost/RS
�
11 .DiDi HBase Platform
• Improvement
• Web UI to show group
• MoveTables bug fix
• CreateTableHandler fix
�
13 .DiDi HBase Platform
• DiDi HBase Service
�
14 .DiDi HBase Platform
Create Project and Tables
�
15 .DiDi HBase Platform
workflow
�
16 .DiDi HBase Platform
Monitor your tables
Get your bill, user must care for their cost
�
17 .DiDi HBase Platform
• Phoenix
• Advantage
• Easy to use for RDBMS User(jdbc、sql)
• Auto salting table for performance and hot spot avoiding
• Like a Big Mysql(One sentence to explain to our users)
• Disadvantage
• Some bug like ordering vector item
• Unstable statistic info caching
• No good in Join case
• So many other hotter system :Presto/Impala/Spark SQL/Kylin
• Successful Use
• Row Timestamp
• Multidimensional Table Schema
�
18 .DiDi HBase Platform
• Phoenix(more customers recently)
• Row Timestamp for metrics
• Monitoring table write/read/storage
• Easy to compute avg, max, min for metrics
• Quick to query recently data
• Multi-dimension Table Schema
• MR/Spark Job to compute BI reporting data
• Many demission combination result like city, gender, age, business type
• Primary Key: JobID, date, dimission1, dimission2, dimission3…
• Value: dimNameArray, valueArray
• This can fit nearly all the Multi-dimension reporting business
�
19 .DiDi HBase Platform
• Client Access
• Multiple Languages Clients
• C++, Go, Python, PHP
• Thritf2, QueryServer
• Security(ACL)
�
20 .Application and Solution(Hadoop Monitor)
• Hadoop Monitor
• Help hadoop to query their fsimage and jobhistory
• BI for Hadoop manager
• Store data in phoenix
�
21 .Application and Solution
�
22 .Application and Solution(Gis Query)
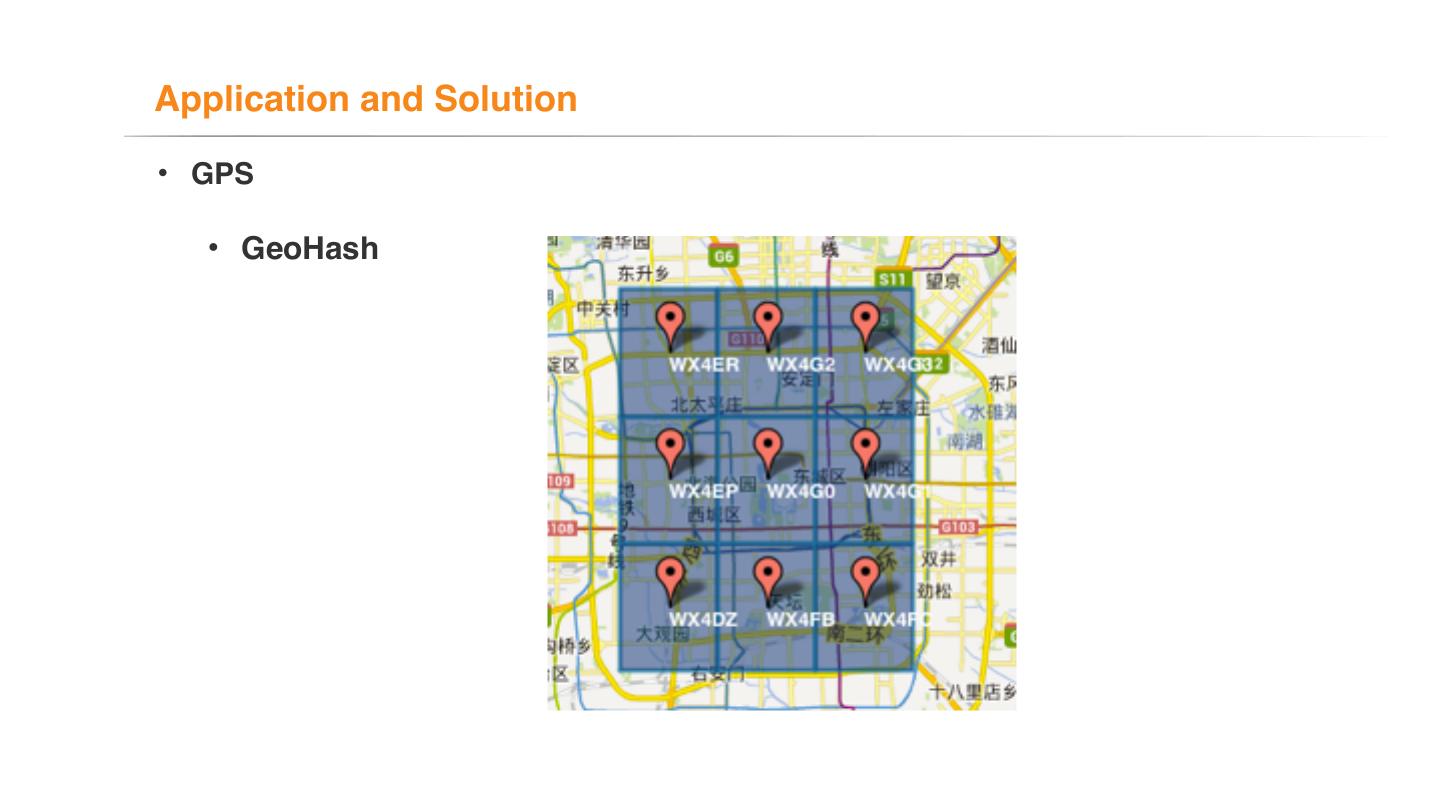
• GPS
�
23 .Application and Solution
• GPS
• Query Model
• Rowkey:ID+Timestamp
• Rowkey:Reversed GeoHash+timestamp+ID
• GeoHash
• A index in two dimensions
• Fit HBase rowkey prefect
• Point 1: same prefix code result in a nearby place
• Point 2: query rowkey prefix can location a region whose area decided by
prefix length
�
24 .Application and Solution
• GPS
• GeoHash
�
25 .Application and Solution(Online Machine Learning)
• ETA(Estimated Time of Arrival)
• Origin data collection
• ETL
• Feature extraction
• Storage
• Model Training
�
26 .Application and Solution
• ETA(Estimated Time of Arrival)
• Training data by spark, every 30 minutes
• Pick up data by city from HBase in 5 minutes
• Compute ETA in 25 minutes
• Rowkey: Salting+CityId+Type0+Type1+Type2+Timestamp
• Columns: Order,Feature
• Every day HBase data will be dumped into HDFS for offline training
�
27 .Application and Solution(Image)
• Traffic in Cloud
• High Volume Throughput, Little Read
• Read via 8 Thrift nodes
• Road traffic info
• POI data
• Heat-map
• Write with Spark Job
�
28 .Application and Solution
• Architecture
�
29 .Challenges and future
• More connect with other bigdata framework
• Hive Phoenix/HBase Handler
• Integration with hive
• Use Hive sql to query phoenix
• Easy to load data from hadoop cluster
• Join with Hive table
• Spark Phoenix/HBase Handler
�