展开查看详情
1 .基于TensorFlow Lite在移动端视频上的
应用
潘凌越
�
2 .应用场景
q 手势识别
q 二次元游戏主播
q TensorFlow Lite介绍
�
4 .流程
转化可训练格式
收集手势图片 标记手势
Google Cloud进行训练
生成模型
识别手势
�
5 .训练步骤
1. 收集训练图片,约300张针对两种不同的爱心手势,
每张图片都有相应的定界框和在图片中的位置标记
2. 将图片转换为TFRecord格式,以便训练的model可
以理解
3. 使用SSD 算法基于MobileNet网络做迁移学习的训练
(基于已经训练的模型参数,在与训练模型上做微
调)
4. 下载基于COCO数据库预训练的MobileNet网络
5. 调整超参数训练,添加训练数据基于pre-trained做
迁移学习,生成pb文件
6. 使用TensorBoard查看模型的准确率及IOU
�
6 .推断步骤
1. 采用Tensorflow lite获取更小的模型,并且可以使用
ops优化加快推断速度
2. 使用TOCO(TensorFLow Lite Optiomizing Converter)优
化,将训练出来的pb文件转换为.tfile的flatbuffer格
式
3. 将.tfile拷贝到assets目录中,引入TensorFlow lite依
赖文件,配置相关超参数
4. 在直播流中获取每一帧图像,根据tensorflowLite推
断出来的边界框实时绘制特效
�
7 .原理
Single Shot MultiBox Detector(SSD)
o SSD使用VGG-16-Atrous作为基础网络,其中黄色部分为在VGG-16基础网络上填加的特征提取
层。SSD与yolo不同之处是除了在最终特征图上做目标检测之外,还在之前选取的5个特特征
图上进行预测。此外SSD还去掉了两个fc来达到加速detector的目的
o 由于YOLO对小目标检测效果不好,所以SSD在不同的feature map上分割成grid然后采用类似
RPN的方式做回归。SSD图1为SSD网络进行一次预测的示意图,可以看出,检测过程不仅在
填加特征图(conv8_2, conv9_2, conv_10_2, pool_11)上进行,为了保证网络对小目标有很好检
测效果,检测过程也在基础网络特征图(conv4_3, conv_7)上进行
�
8 .优化
§ 训练加速:Google Cloud TPU, Batch Size,基于RetinaNet model
§ 推断阶段:模型文件大小优化,tensorflow lite应用,
§ GPU Delegate, Android NNAI,量化
�
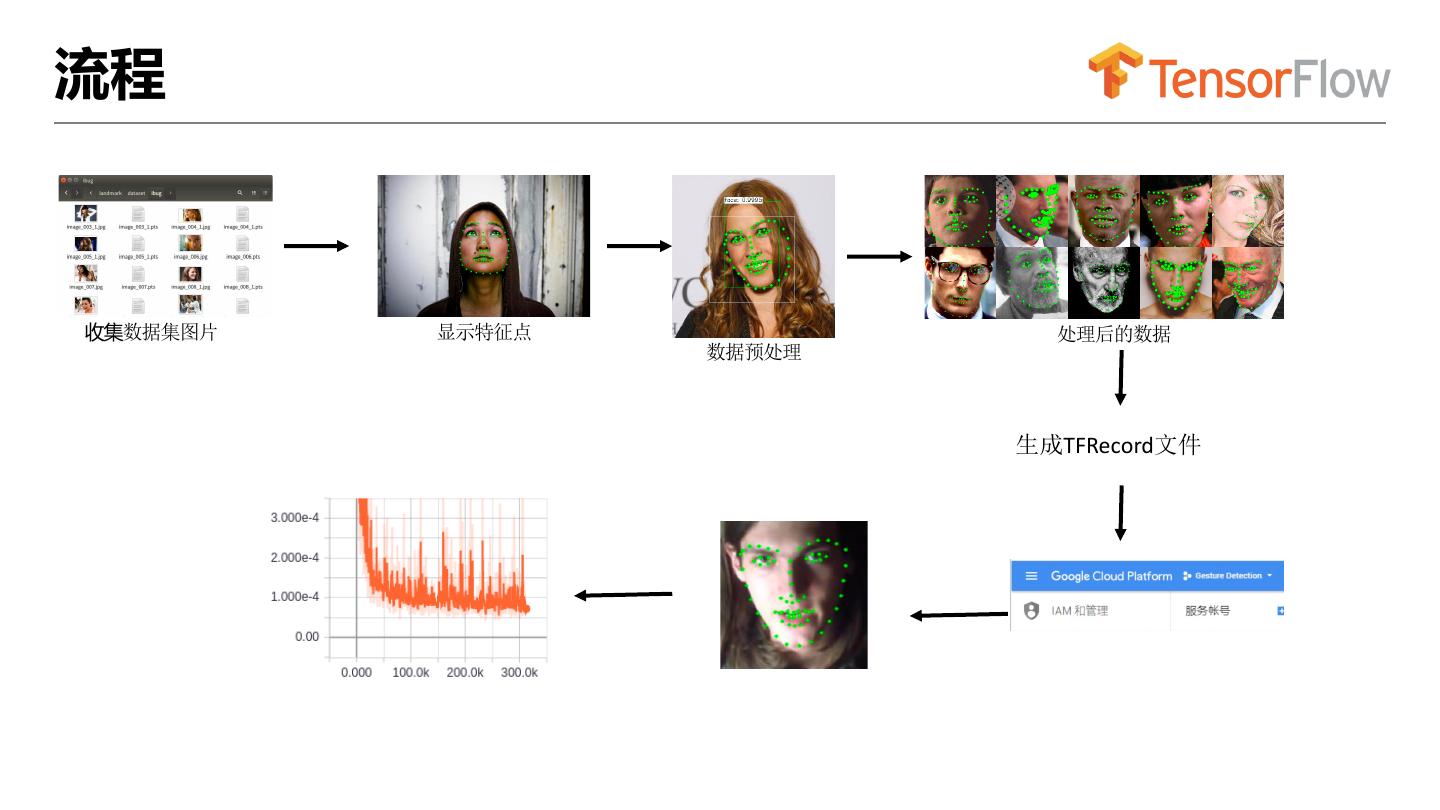
10 .流程
收集数据集图片 显示特征点 处理后的数据
数据预处理
生成TFRecord文件
�
11 .实现步骤
1. 采用已有的数据集300-W、AFW等20000多张,包含图片和pts文件,
其中pts文件中保存了特征数和每个特征的位置
2. 训练数据预处理,人脸检测和特征定位,两种方式检测出边界框
3. 使用Estimator定义网络模型结构和损失函数,采用自定义的CNN卷积
神经网络
4. 使用Estimator保存模型pb文件,使用TensorFLow Lite Optiomizing
Converter优化,将训练出来的pb文件转换为.tfile的flatbuffer格式
5. 将.tfile拷贝到assets目录中,引入TensorFlow lite依赖文件,配置相关
超参数
6. 在直播摄像头中获取每一帧图像,根据tensorflowLite推断出来的特征
点
7. 将特征点坐标关联到3D人物模型上,并与直播的游戏视频流合并绘制
推流
�
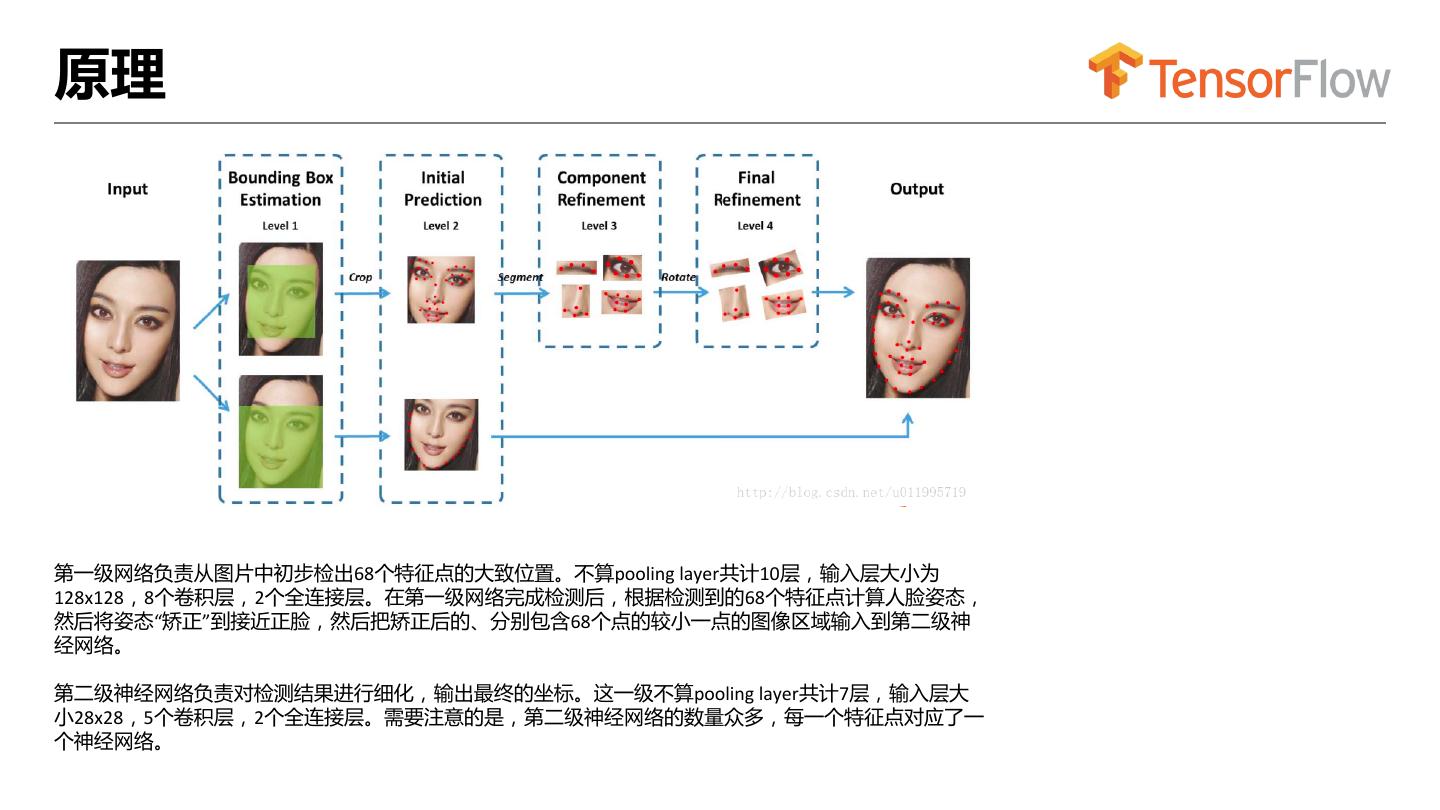
12 .原理
第一级网络负责从图片中初步检出68个特征点的大致位置。不算pooling layer共计10层,输入层大小为
128x128,8个卷积层,2个全连接层。在第一级网络完成检测后,根据检测到的68个特征点计算人脸姿态,
然后将姿态“矫正”到接近正脸,然后把矫正后的、分别包含68个点的较小一点的图像区域输入到第二级神
经网络。
第二级神经网络负责对检测结果进行细化,输出最终的坐标。这一级不算pooling layer共计7层,输入层大
小28x28,5个卷积层,2个全连接层。需要注意的是,第二级神经网络的数量众多,每一个特征点对应了一
个神经网络。
�
13 .优化
o 人脸边界框定位及预处理
o 视频推断速度及跟随
�
14 .TensorFLow Lite是什么
q TensorFLow轻量级实现,用于端侧加载机器学习模型进行
预测的推理引擎
q TensorFlow Mobile vs TensorFlow Lite
q 代码地址:
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite
q 官网地址:
https://www.tensorflow.org/lite
�
15 .选用TensorFlow Lite
q 优点:轻量级,依赖少,移动端硬件加速,跨平台性
q 缺点:ops不足(TensorFlow Select),不支持语义(控制
流,RNN),不能支持各种运算芯片
q 训练阶段 vs 推断阶段
q 精度 vs 速度
�
16 .TensorFlow Lite与Android
q 模型生成
• TenosrFlow -> Saved Model -> TF Lite Converter ->.tflite Mod
• 两种方式:tensorflow/contrib/lite/tocol 生成tfile文件
q Android配置
在app目录下的build.gradle配置文件加上以下配置信息
implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'
aaptOptions {
noCompress "tflite"
}
implementation 'org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly'
�
17 .Android中使用NNAI Delegate
q Android Neural Networks API(以下简称 NNAPI) 是 NDK 中的一套 API,
在 8.1 (API level 27)及更高版本系统上才能使用该功能。
q NNAI Delegate
Interpreter.Options tfliteOptions = new Interpreter.Options();
nnapiDelegate = new NnApiDelegate();
tfliteOptions.addDelegate(nnapiDelegate);
tflite = new Interpreter(tfliteModel, tfliteOptions);
tflite.run(imgData, labelProbArray);
�
18 .Android中使用GPU Delegate
q GPU作为加速原始浮点模型,不会增加量化的额外复杂性和潜在的精度损失。
对于不同的深度神经网络模型,使用新GPU后端,通常比浮点CPU快2-7倍。
q GPU GpuDelegate
Interpreter.Options tfliteOptions = new Interpreter.Options();
gpuDelegate = new GpuDelegate();
tfliteOptions.addDelegate(gpuDelegate);
tflite = new Interpreter(tfliteModel, tfliteOptions);
tflite.run(imgData, labelProbArray);
�
19 .TensorFlow Lite的加速
q NNAPI
o CPU vs GPU
1) 2-7倍速度
2) 增加250KB大小
�
20 .TensorFlow Lite的优化
q 定向量化(Quantization)
1) 模型大小减少4倍
2) 卷积层提供10-50%执行速度(CPU)
3) 全连接和RNN提高3倍(CPU)
o 剪枝
1) 训练过程中丢弃一些连接
2) Dense张量变稀疏
�
21 .TensorFlow Lite的源码架构
层次 功能 说明
User 调用Android API和TFLite API,最关键函数就是
实现inference runForMultipleInputsOutputs
,分类、检测等inference功能的入
口函数。
Interpreter Java API, c++函数的封装 有三个比较关键的函数:
createModel(),CreateOpResol
ver(), createInterpreter()
Modules 包括Model、SubGraph、Tensor、 主要由Model、SubGraph、Tensor
Operator等各模块 、Operator几个部分构成
Kernel 主要实现gemm,调用两个第三方库, 调用eigen和gemmlowp,主要实现
分别为gemmlowp和Eigen gemm操作,gemmlowp也是由
Context来进行计算的
�
22 .TensorFlow Lite的定点量化
量化技术计算并存储了更加紧凑的数字格式,TensorFlow Lite
增加了使用 8 位的定点量化表示。
q 浮点数模型可以直接通过官方提供的 Converter 转换得到
o 量化模型则一般需要进行伪量化 + fine-tuning 操作
o 优势:
1) 更小的文件大小
2) 更快的推断
3) 内存效率
�
23 .TensorFlow Lite的定点量化
原理:前向和后向传播中,推断只使用了前向过程。训练模型期间同时加入量化,就要确保前向过程的训练和推理
的精度相匹配。
1.训练:
tf.contrib.quantize.create_training_graph
2.将输出结果提供给 TensorFlow Lite 优化转换器(TOCO)以获得全量化的 TensorFLow Lite 模型
bazel build tensorflow/contrib/lite/toco:toco && \
./bazel-bin/third_party/tensorflow/contrib/lite/toco/toco \
--input_file=frozen_eval_graph.pb \
--output_file=tflite_model.tflite \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--inference_type=QUANTIZED_UINT8 \
--input_shape="1,224, 224,3" \
--input_array=input \
--output_array=outputs \
--std_value=127.5 --mean_value=127.5
�
24 .TensorFlow Lite的Ops自定义
q TensorFlow Lite的算子是TensorFlow子集
q 115个内置算子
q 官方根据优先级补充
q 自定义Ops
�