










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Flink在数据湖场景下的使用
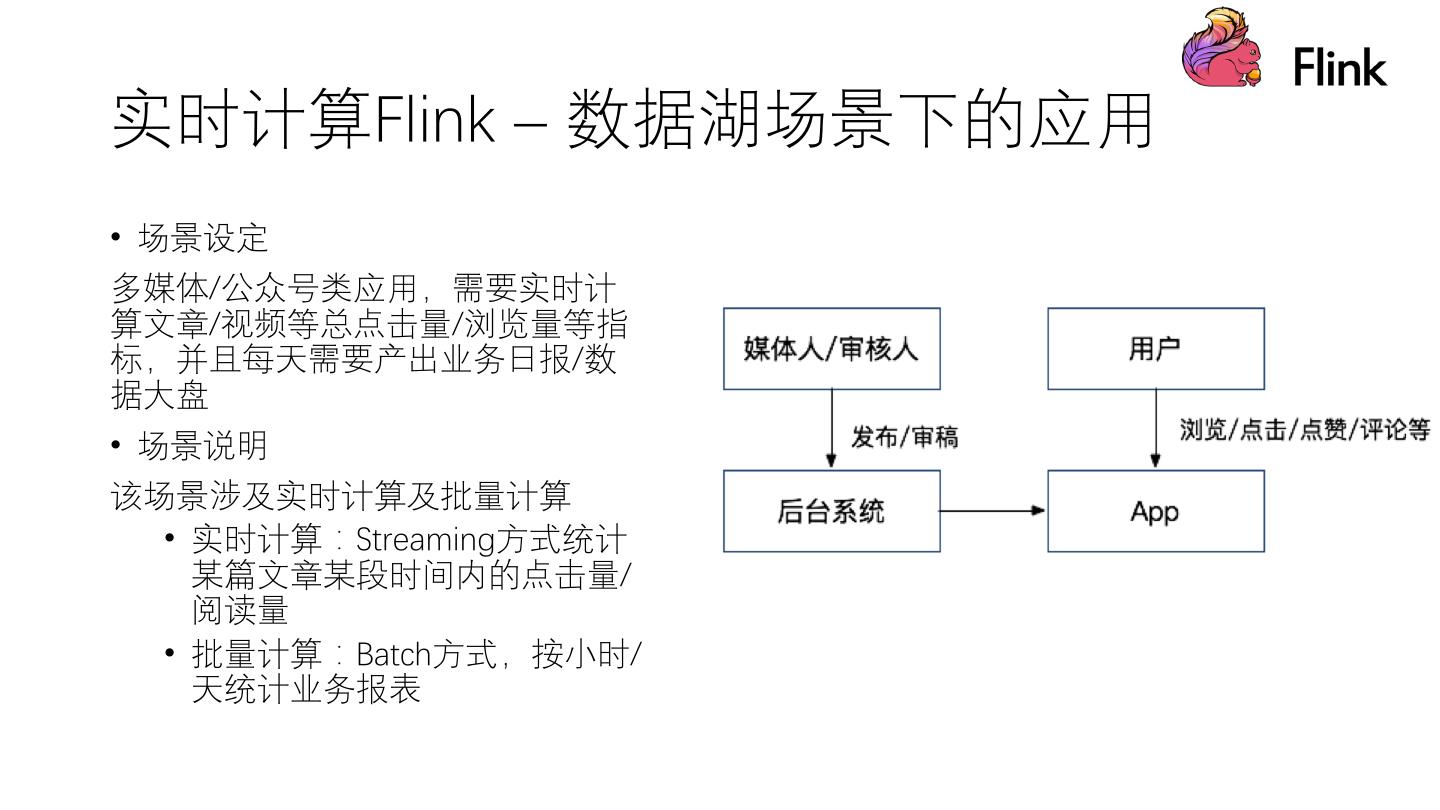
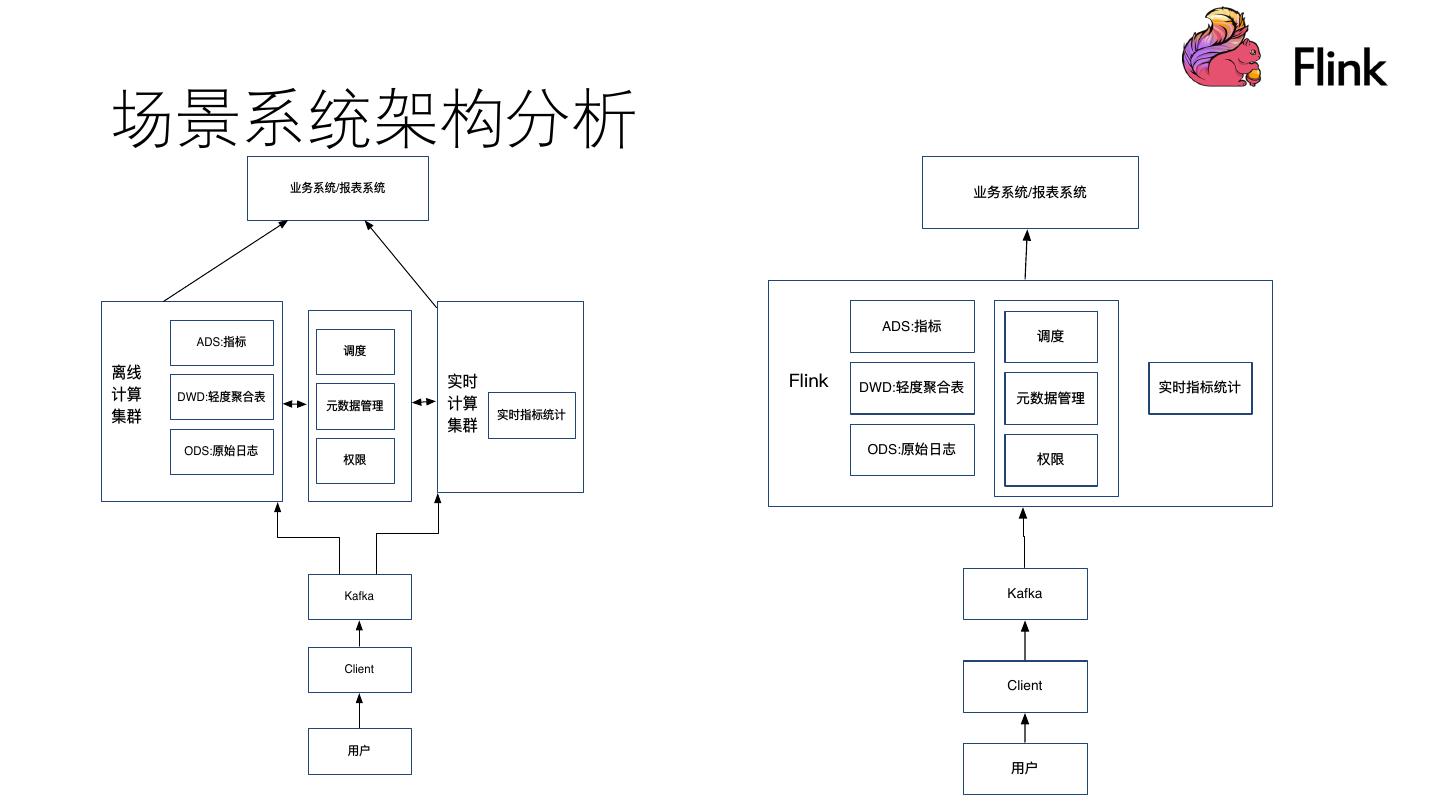
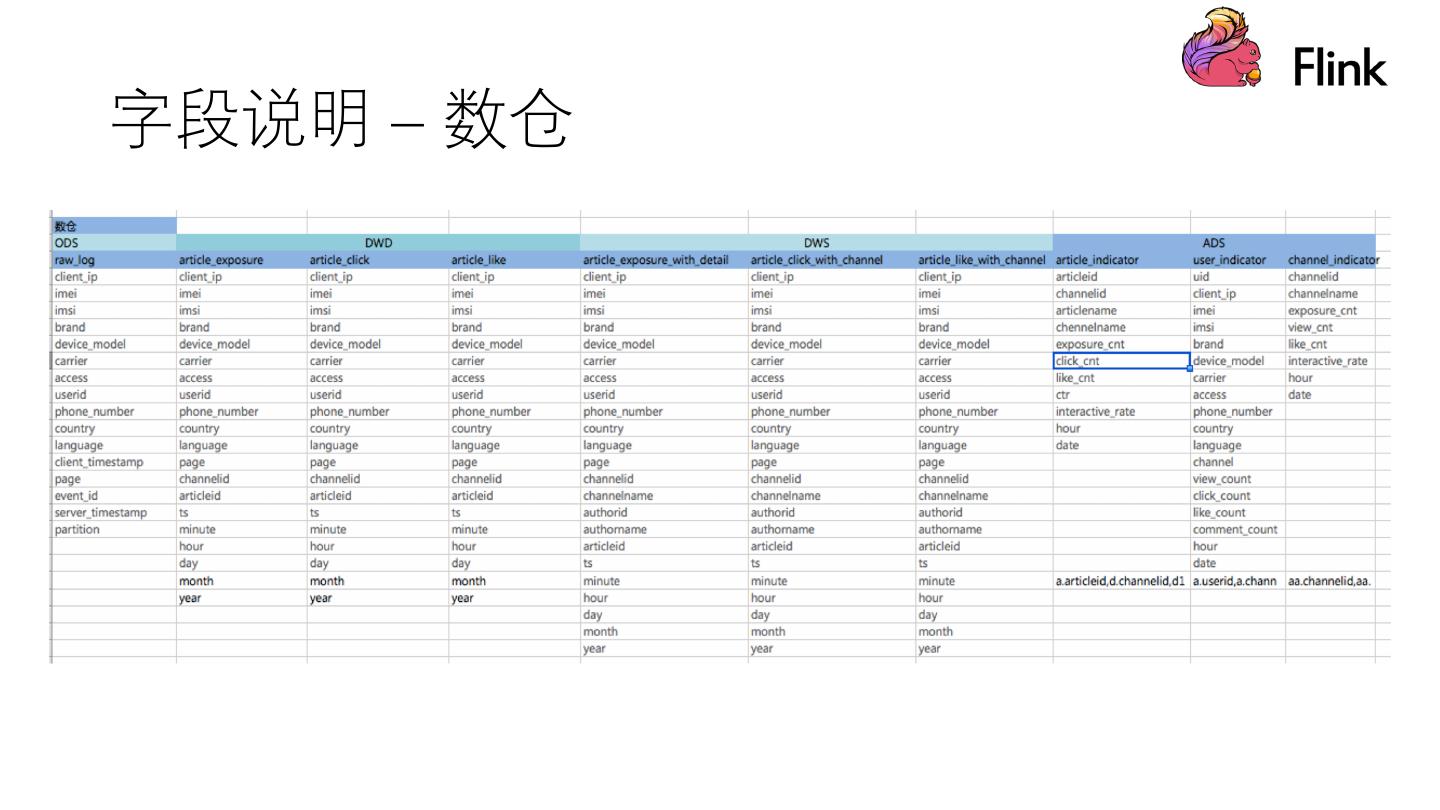
我们对比实时计算Flink批性能以及Flink在数据湖场景下的应用,并分析场景系统构架和场景业务构架,最后展示了维表、原始日志及数仓的字段说明。
3秒后跳转登录页面
去登陆

