










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
秦江杰&孙金城_Simplify Machine Learning With Flink TableAPI
秦江杰&孙金城_Simplify Machine Learning With Flink TableAPI
展开查看详情
1 .Simplify Machine Learning With Flink TableAPI 公司:阿⾥里里巴巴 演讲者:孙⾦金金城 (⾼高级技术专家) 秦江杰 (⾼高级技术专家)
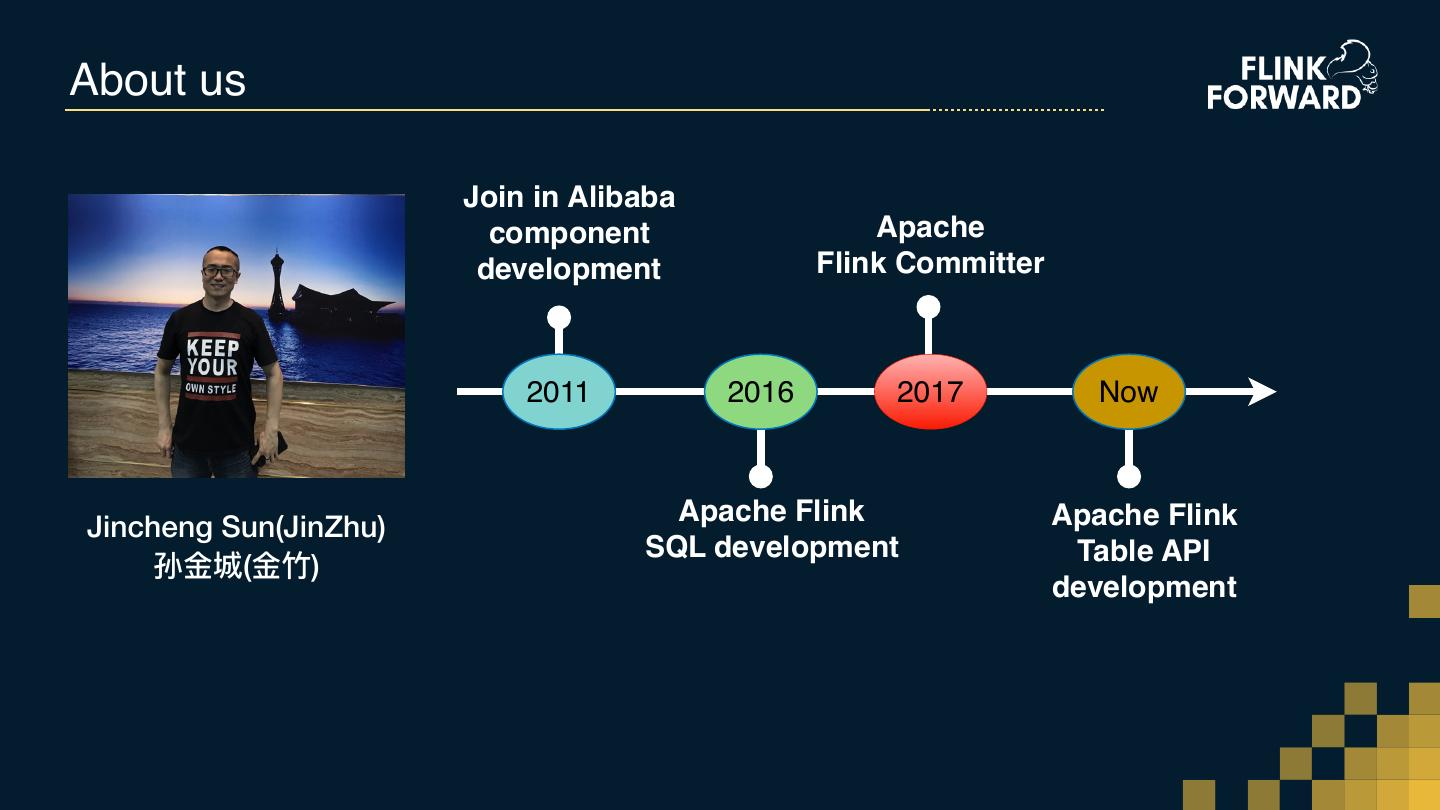
2 .About us Join in Alibaba component Apache development Flink Committer 2011 2016 2017 Now Apache Flink Apache Flink Jincheng Sun(JinZhu) SQL development Table API 孙⾦金金城(⾦金金⽵竹) development
3 .About us Alibaba Realtime Computing Platform, 2018.5 - 2018年年5⽉月加⼊入阿⾥里里巴巴实时计算平台 Worked at LinkedIn and IBM 曾就职于 LinkedIn 和 IBM M.S Information Networking, CMU, 2014 2014年年硕⼠士毕业于卡耐基梅梅陇⼤大学 Jiangjie (Becket) Qin Apache Kafka PMC Member 秦江杰 Apache Kafka 项⽬目管理理委员会成员
4 . Brief introduction to Flink Table API AGENDA Table API 简介 提要 The API requirements from Machine Learning Algorithms 机器器学习算法对 API 的核⼼心需求 The enhancement to Flink Table API Flink Table API 的扩展 Algorithm examples based on Flink Table API Apache Flink 基于 Flink Table API 的算法实现
5 . Brief introduction to Flink Table API AGENDA Table API 简介 提要 The API requirements from Machine Learning Algorithms 机器器学习算法对 API 的核⼼心需求 The enhancement to Flink Table API Flink Table API 的扩展 Algorithm examples based on Flink Table API Apache Flink 基于 Flink Table API 的算法实现
6 .Table API is high-level analytics API Apache Flink Layered APIs Descriptive API/描述性API With Optimization/基于优化 Richer Processing API/更更丰富的API Raw Processing API/底层API E.g.: Count the numbers of people by Region 示例例:按地区统计⼈人⼝口数量量 table .groupBy(‘region) .select(‘region, COUNT(1))
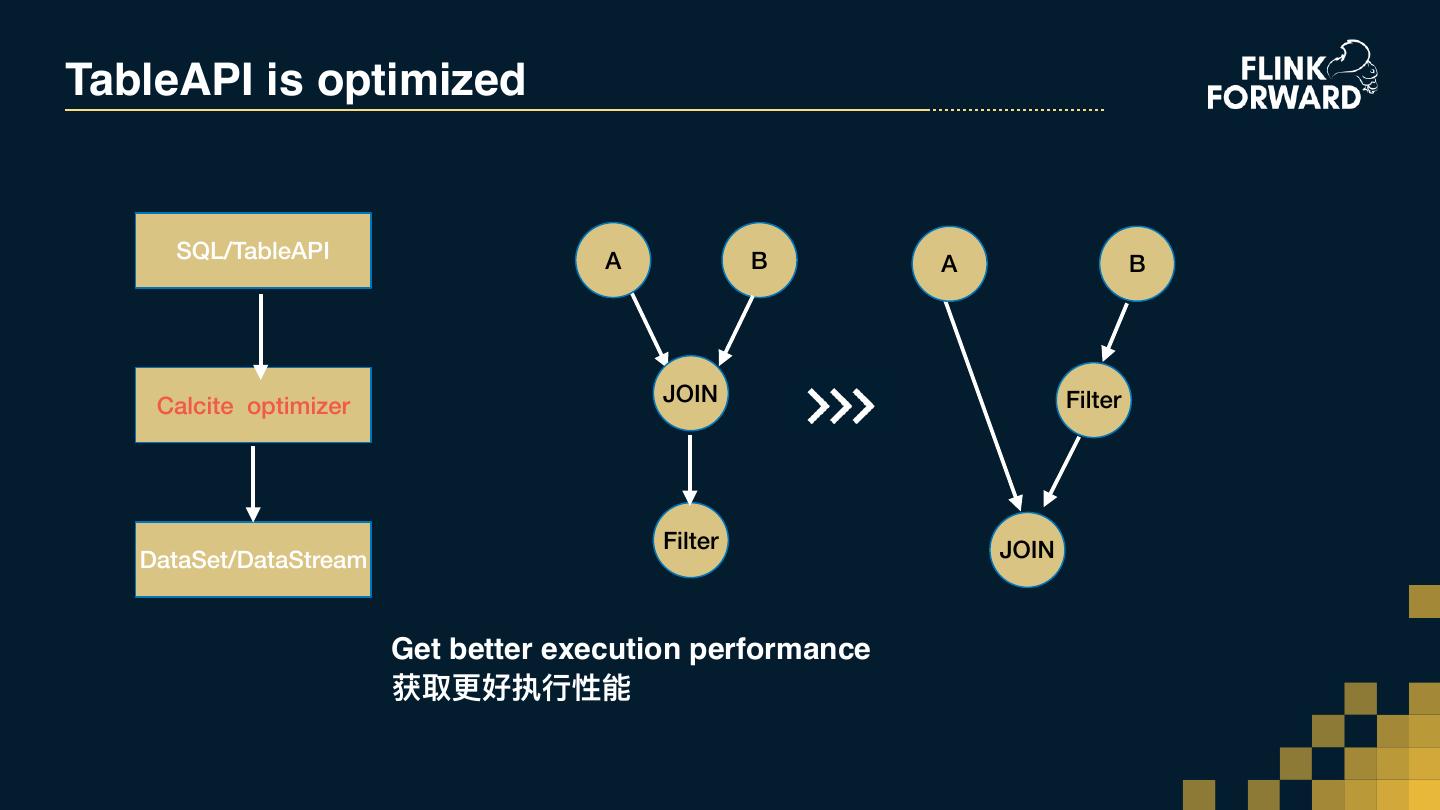
7 .TableAPI is optimized SQL/TableAPI A B A B JOIN Filter Calcite optimizer Filter JOIN DataSet/DataStream Get better execution performance 获取更更好执⾏行行性能
8 .TableAPI unifies batch and stream Component Stack 组件栈 TableAPI&SQL table .groupBy(‘region) DataSet API DataStream API .select(‘region, COUNT(1)) RunTime For Bath and Streaming ⽀支持流批两种运⾏行行模式 Local Cluster Cloud
9 .Table API is a super set of the SQL Table API = SQL + … Specially designed by Apache Flink TableAPI SQL e.g. Stream and batch SELECT/AGG/ Table API unified Y Y WINDOW etc. 流批统⼀一 map FlatAGG/Iteration/ flatMap Functional scalability Y N Column operations SQL Iteration 功能扩展性 etc. Aggregate map/flatMap/ Expressive extensibility flatAggregate Y N Row.flatten()/minus/ 表达⽅方式扩展性 … intersect etc. Compile check Y N IDE Java/Scala 编译检查
10 .Summarize what is tableAPI Stream and batch unified 流批统⼀一 With optimization So,How about Flink ML on tableAPI? 可被优化 那么可以基于TableAPI开发Flink ML吗? Concise and easy to use 简洁易易⽤用
11 .TableAPI may unify the implementation of Flink ML Flink ML Flink ML TableAPI&SQL TableAPI&SQL DataSet API DataStream API DataSet API DataStream API RunTime RunTime Local Cluster Cloud Local Cluster Cloud What are the requirements of Flink ML for the Table API? Flink 机器器学习对TableAPI有哪些需求呢?
12 . Brief introduction to Flink Table API AGENDA Table API 简介 提要 The API requirements from Machine Learning Algorithms 机器器学习算法对 API 的核⼼心需求 The enhancement to Flink Table API Flink Table API 的扩展 Apache Flink Algorithm examples based on Flink Table API 基于 Flink Table API 的算法实现
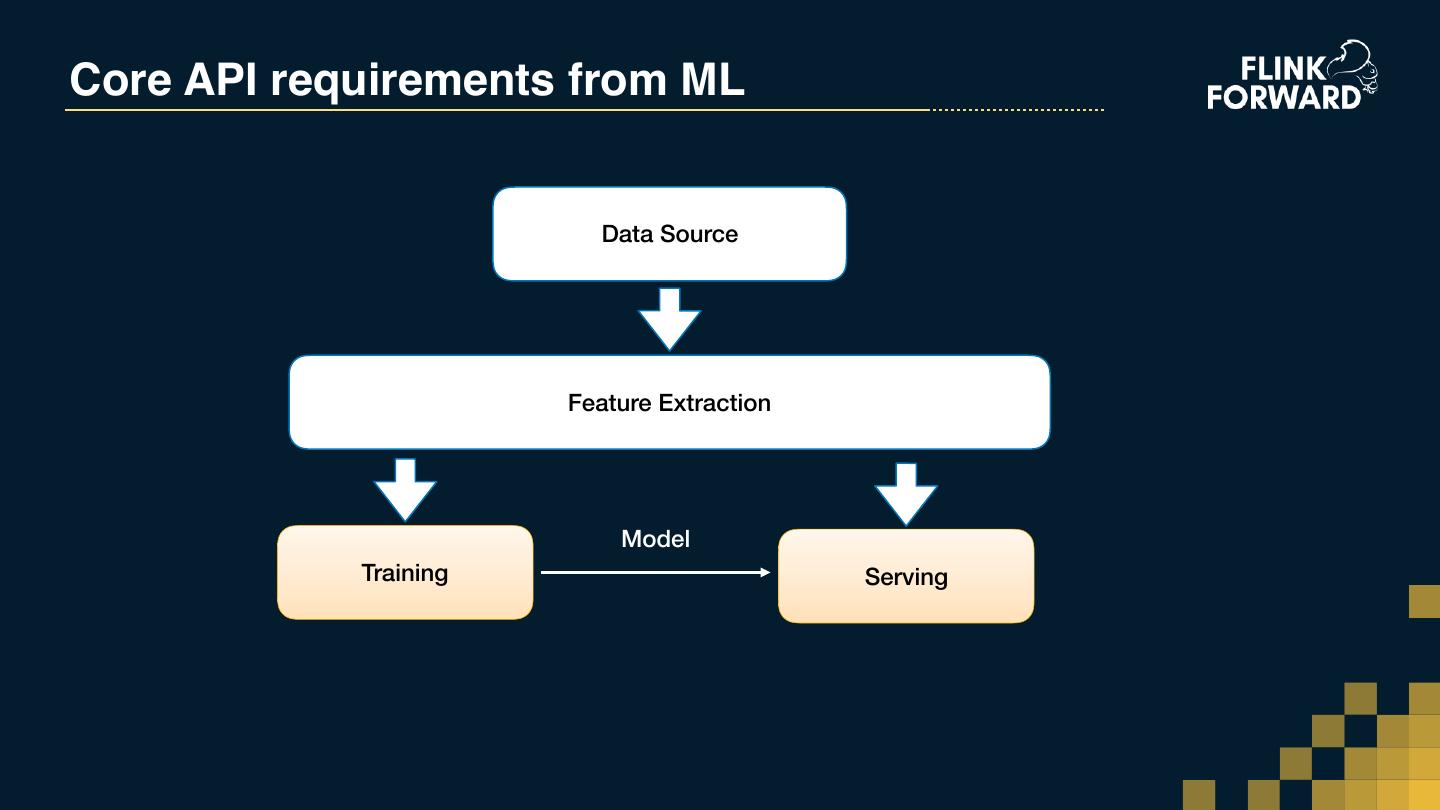
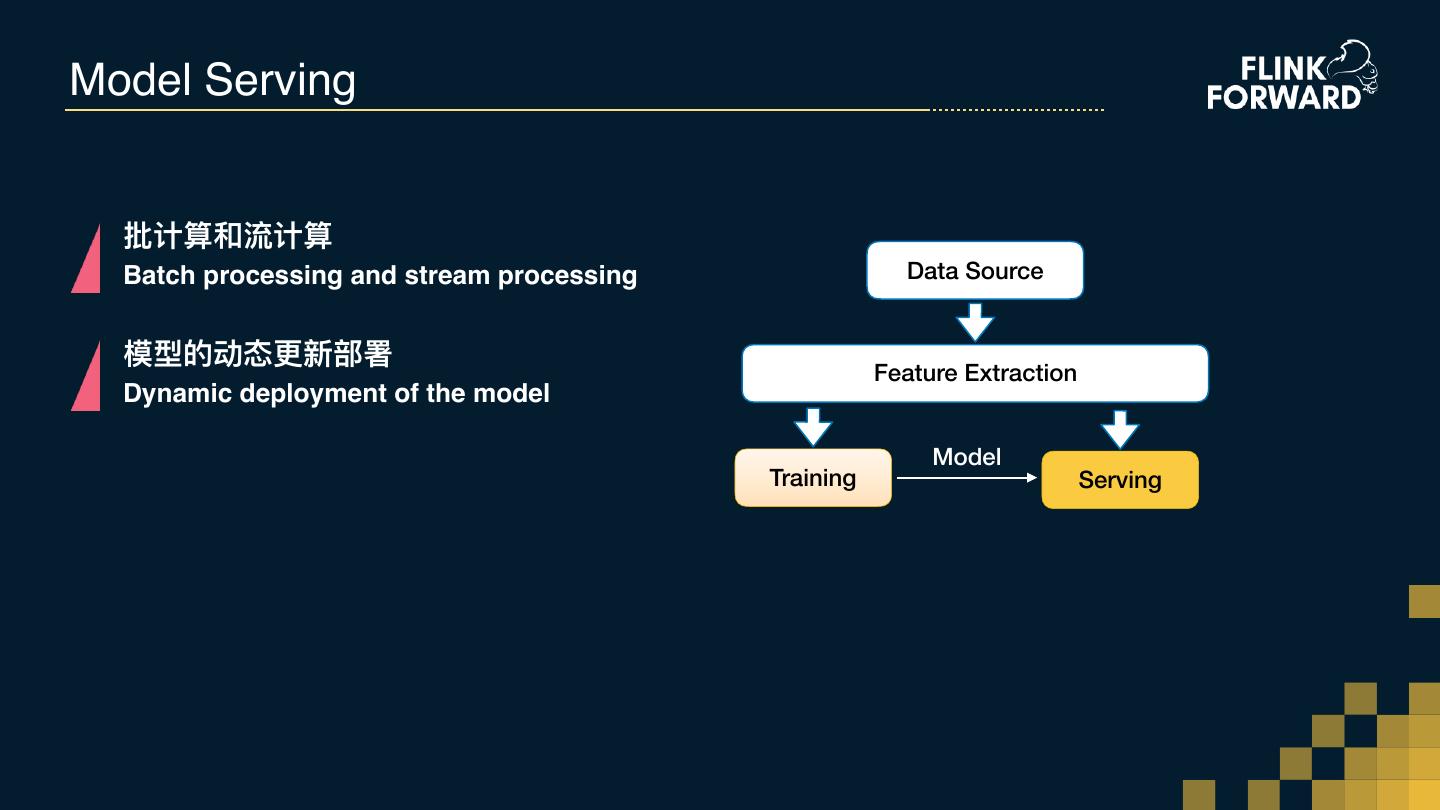
13 .Core API requirements from ML Data Source Feature Extraction Model Training Serving
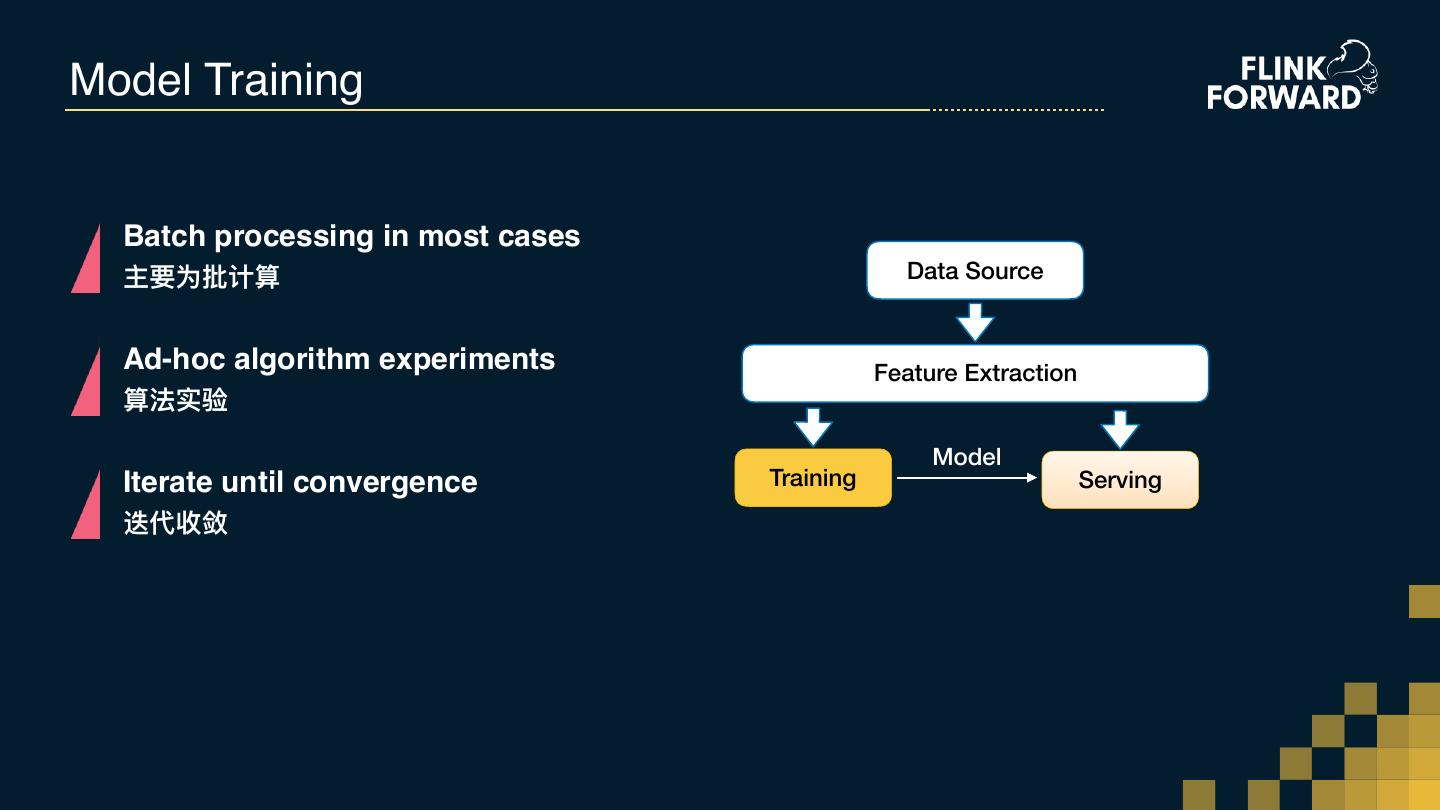
14 .Model Training Batch processing in most cases 主要为批计算 Data Source Ad-hoc algorithm experiments Feature Extraction 算法实验 Model Iterate until convergence Training Serving 迭代收敛
15 .Model Serving 批计算和流计算 Batch processing and stream processing Data Source 模型的动态更更新部署 Feature Extraction Dynamic deployment of the model Model Training Serving
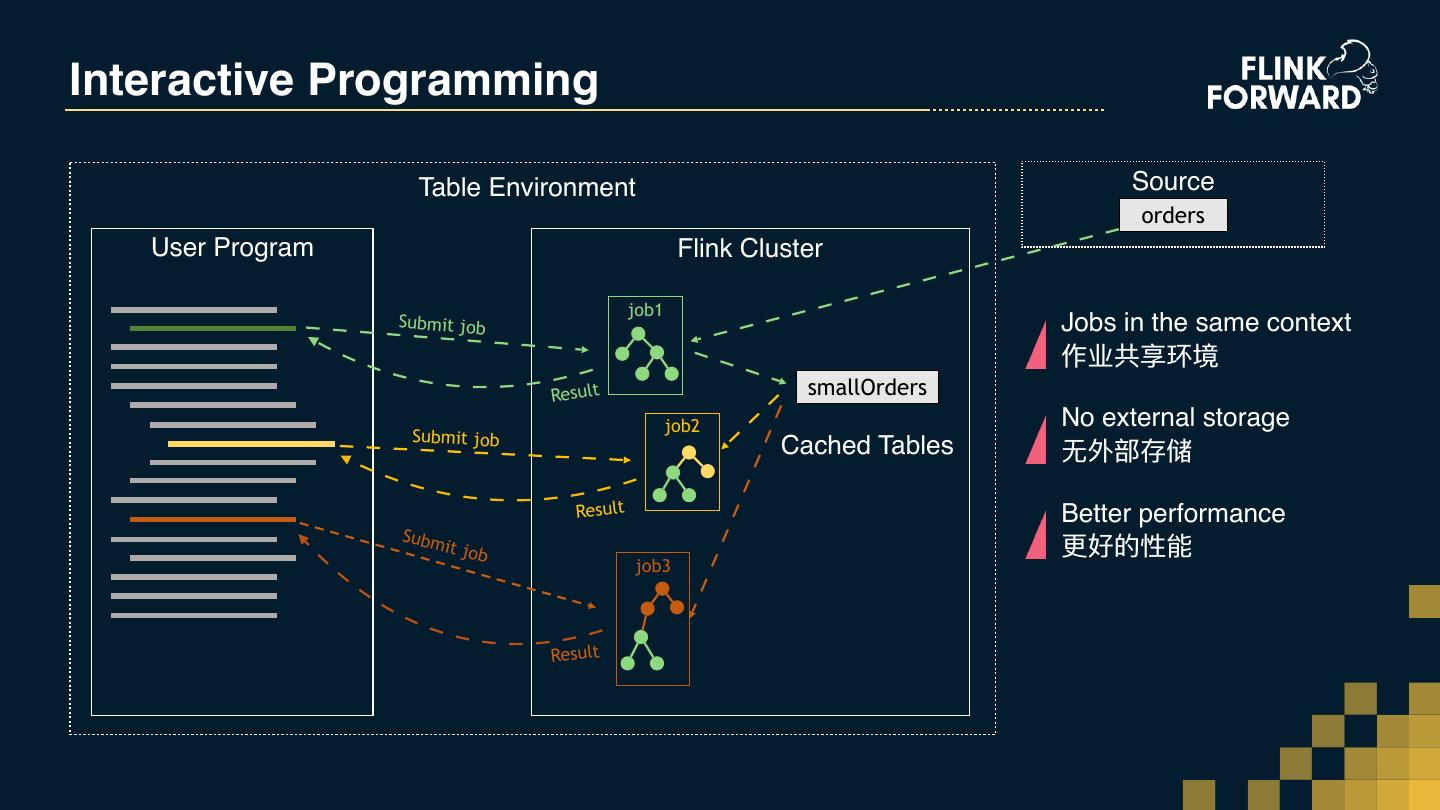
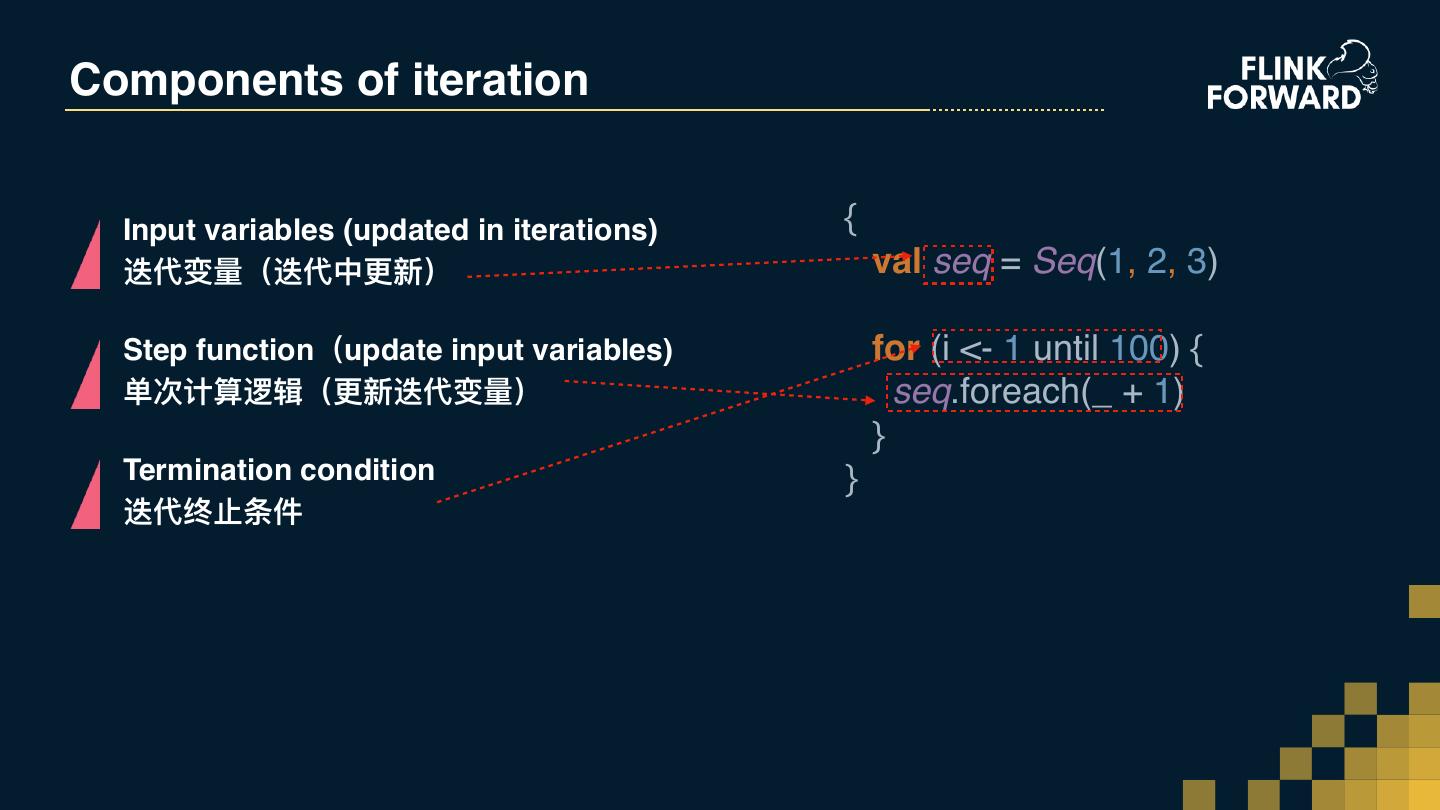
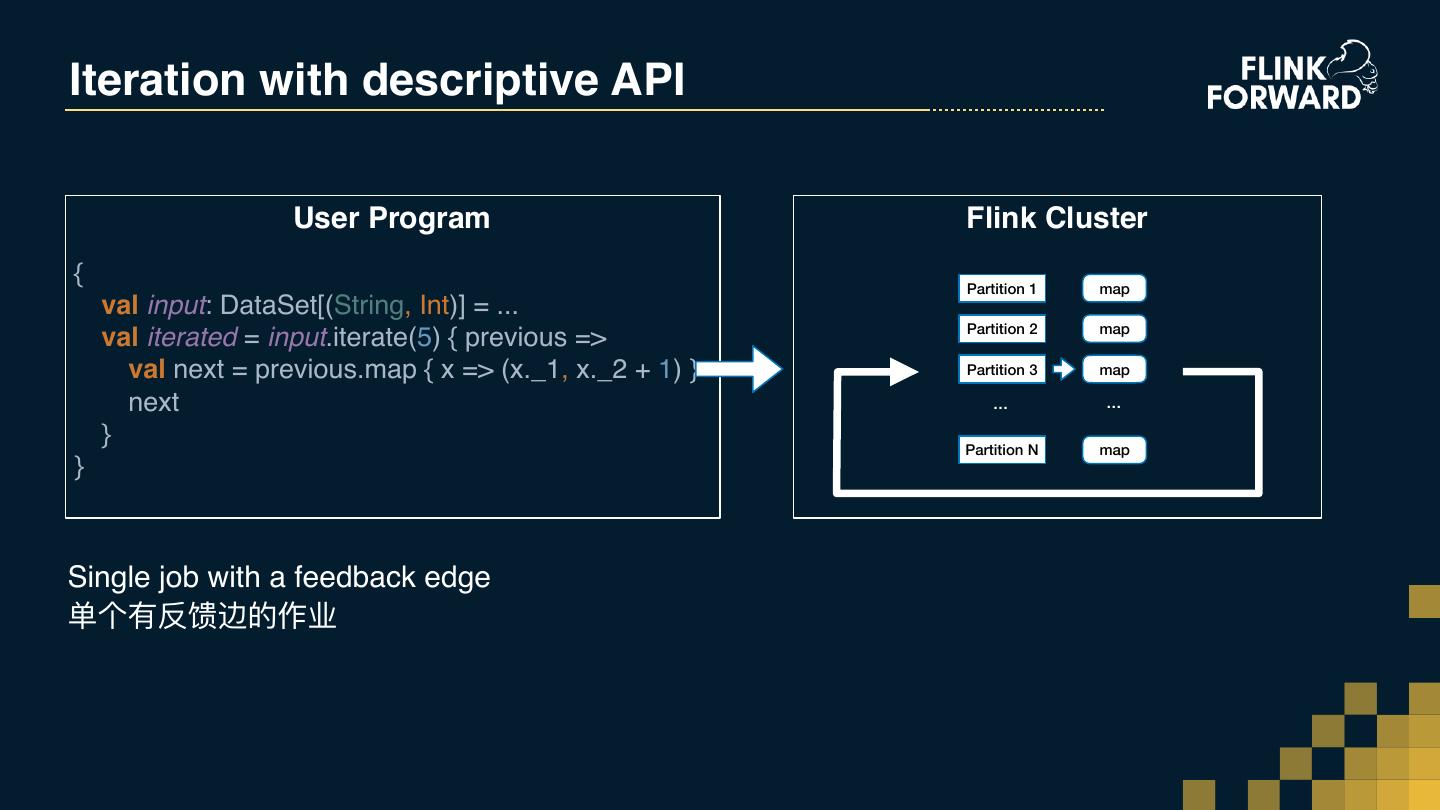
16 .From Scenarios to API Requirements 算法实验 交互式编程 Ad-hoc Algorithm Experiments Interactive programming 迭代收敛 迭代计算 Iterate until converge Iterative processing 批计算+流计算 批流统⼀一的 API Batch + Stream processing Unified API for batch and stream processing ⾏行行计算 基于整⾏行行的计算 Row-based processing Row-based API 动态模型更更新部署 Dynamic model update and deployment
17 .From Scenarios to API Requirements 算法实验 交互式编程(FLINK-11199) Ad-hoc Algorithm Experiments Interactive programming (FLINK-11199) 迭代收敛 迭代计算(coming soon) Iterate until converge Iterative processing 批计算+流计算 批流统⼀一的 API Batch + Stream processing Unified API for batch and stream processing ⾏行行计算 基于整⾏行行的计算(FLIP-29) Row-based processing Row-based API 动态模型更更新部署 Dynamic model update and deployment
18 . Brief introduction to Flink Table API AGENDA Table API 简介 提要 The API requirements from Machine Learning Algorithms 机器器学习算法对API的核⼼心需求 The enhancement to Flink Table API Flink Table API 的扩展 Apache Flink Algorithm examples based on Flink Table API 基于 Flink Table API 的算法实现
19 . The enhancement to Flink Table API AGENDA Flink Table API 的扩展 提要 基于整⾏行行的计算及聚合功能 Row-based processing and aggregation function 交互式编程 Interactive programming 迭代计算 Apache Flink Iterative processing
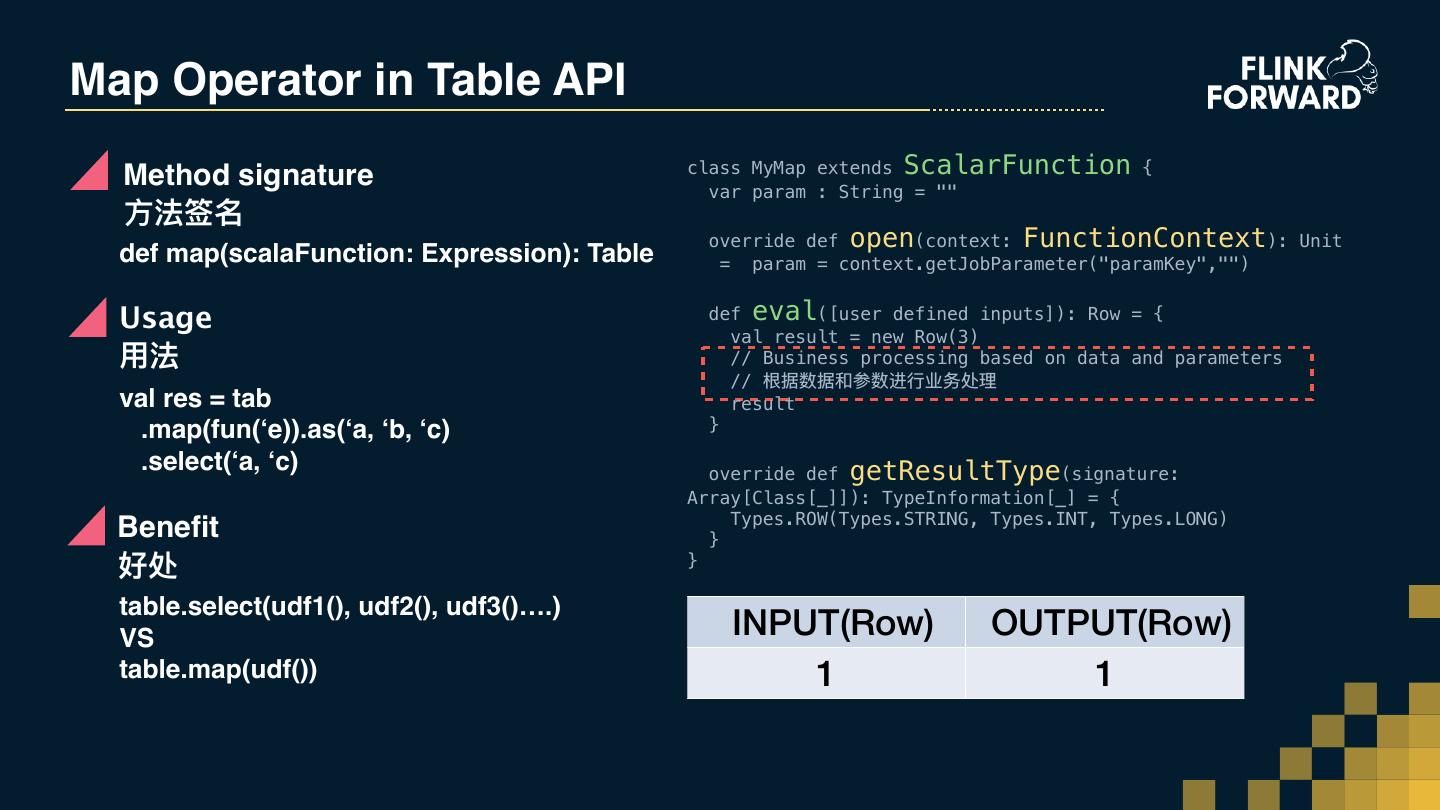
20 .Map Operator in Table API class MyMap extends ScalarFunction { Method signature var param : String = "" ⽅方法签名 override def open(context: FunctionContext): Unit def map(scalaFunction: Expression): Table = param = context.getJobParameter("paramKey","") Usage def eval([user defined inputs]): Row = { val result = new Row(3) ⽤用法 // Business processing based on data and parameters // 根据数据和参数进⾏行行业务处理理 val res = tab result .map(fun(‘e)).as(‘a, ‘b, ‘c) } .select(‘a, ‘c) override def getResultType(signature: Array[Class[_]]): TypeInformation[_] = { Types.ROW(Types.STRING, Types.INT, Types.LONG) Benefit } 好处 } table.select(udf1(), udf2(), udf3()….) VS INPUT(Row) OUTPUT(Row) table.map(udf()) 1 1
21 .FlatMap Operator in Table API Method signature ⽅方法签名 case class User(name: String, age: Int) def flatMap(tableFunction: Expression): Table class MyFlatMap extends TableFunction[User] { def eval([user defined inputs]): Unit = { for(..){ Usage collect(User(name, age)) ⽤用法 } val res = tab } } .flatMap(fun(‘e,’f)).as(‘name, ‘age) .select(‘name, ‘age) Benefit INPUT(Row) OUTPUT(Row) 好处 1 N(N>=0) table.join(udtf) VS table.flatMap(udtf())
22 .Aggregate Operator in Table API Method signature ⽅方法签名 def aggregate(aggregateFunction: Expression): AggregatedTable class AggregatedTable(table: Table, groupKeys: Seq[Expression], aggFunction: Expression) Usage class CountAccumulator extends JTuple1[Long] { f0 = 0L //count ⽤用法 } val res = groupedTab class CountAgg extends AggregateFunction[JLong, CountAccumulator] { def accumulate(acc: CountAccumulator): Unit = { .groupBy(‘a) acc.f0 += 1L .aggregate(agg(‘e,’f) as (‘a, ‘b, ‘c)) } .select(‘a, ‘c) override def getValue(acc: CountAccumulator): JLong = { acc.f0 } Benefit ... retract()/merge() 好处 } table.select(agg1(), agg2(), agg3()….) INPUT(Row) OUTPUT(Row) VS table.aggregate(agg()) N(N>=0) 1
23 .FlatAggregate Operator in Table API Method signature ⽅方法签名 def flatAggregate(tableAggregateFunction: Expression): GroupedFlatAggregateTable class GroupedFlatAggTable(table: Table, groupKey: Seq[Expression], tableAggFun: Expression) class TopNAcc { Usage var data: MapView[JInt, JLong] = _ // (rank -> value) ⽤用法 } ... val res = groupedTab class TopN(n: Int) extends TableAggregateFunction[(Int, Long), .groupBy(‘a) TopNAccum] { .faltAggregate( def accumulate(acc: TopNAcc, [user defined inputs]) { faltAgg(‘e,’f) as (‘a, ‘b, ‘c)) ... } .select(‘a, ‘c) def emitValue(acc: TopNAcc, out: Collector[(Int, Long)]): Unit = { ... Benefit } ...retract/merge 好处 } New features on the TableAPI TableAPI 上⾯面的新增功能 INPUT(Row) OUTPUT(Row) N(N>=0) M(M>=0)
24 .Aggregate VS FlatAggregate Scenes using Max and Top2 compare the difference between Aggregate and FlatAggregate 使⽤用 Max 和 TopN 的场景⽐比较 Aggregate 和 FlatAggregate 之间的差异 tab.aggregate(maxAgg(PRICE)) ID NAME PRICE tab.flatAggregate(topTableAgg(PRICE)) Both AGG and 1 Latte 6 TableAGG 2 Milk 3 represents its state 3 Breve 5 using 4 Mocha 8 accumulator 5 Tea 4 AGG 和 TableAGG 都是 利利⽤用 accumulator 来处理理 state 的 1 createAccumulator() 8866 6 8,6 8,6 6,5 6,3 6 Accumulator Accumulator (MAX-ACC) (Top2-ACC) 2 accumulate(acc, PRICE) 3 getValue(ACC acc) 3 emitValue(acc, out) ID NAME PRICE ID NAME PRICE 4 Mocha 8 4 Mocha 8 1 Latte 6
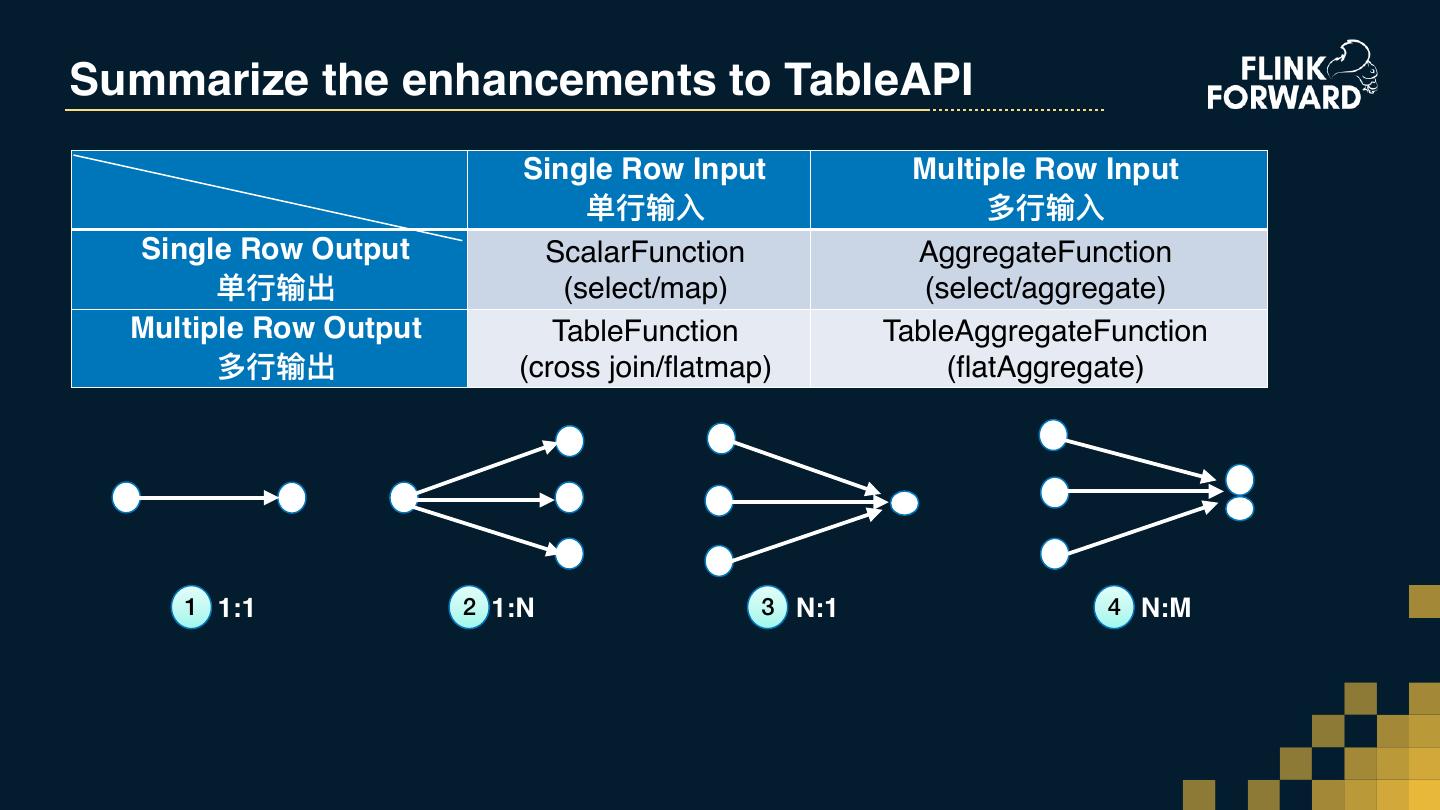
25 .Summarize the enhancements to TableAPI Single Row Input Multiple Row Input 单⾏行行输⼊入 多⾏行行输⼊入 Single Row Output ScalarFunction AggregateFunction 单⾏行行输出 (select/map) (select/aggregate) Multiple Row Output TableFunction TableAggregateFunction 多⾏行行输出 (cross join/flatmap) (flatAggregate) 1 1:1 2 1:N 3 N:1 4 N:M
26 . The enhancement to Flink Table API AGENDA Flink Table API的扩展 提要 基于整⾏行行的计算及聚合功能 Row-based processing and aggregation function Interactive programming 交互式编程 Iterative processing Apache Flink 迭代计算
27 .A example code snippet { val orders = tEnv.fromCollection(data).as ('country, 'color, 'quantity) val smallOrders = orders.filter('quantity < 100) val countriesOfSmallOrders = smallOrders.select('country).distinct() countriesOfSmallOrders.print() val smallOrdersByCountry = smallOrders.groupBy('country).select('country, 'quantity.sum as 'TotalSales) smallOrdersByCountry.print() val smallOrdersByColor = smallOrders.groupBy('color).select('color, 'quantity.avg as 'avg) smallOrdersByColor.print() }
28 .Static programming User Program Execution Environment Source job1 orders Execution Environment job2 Jobs are independent 作业间相互独 Execution Environment job3 Redundant computation 重复计算
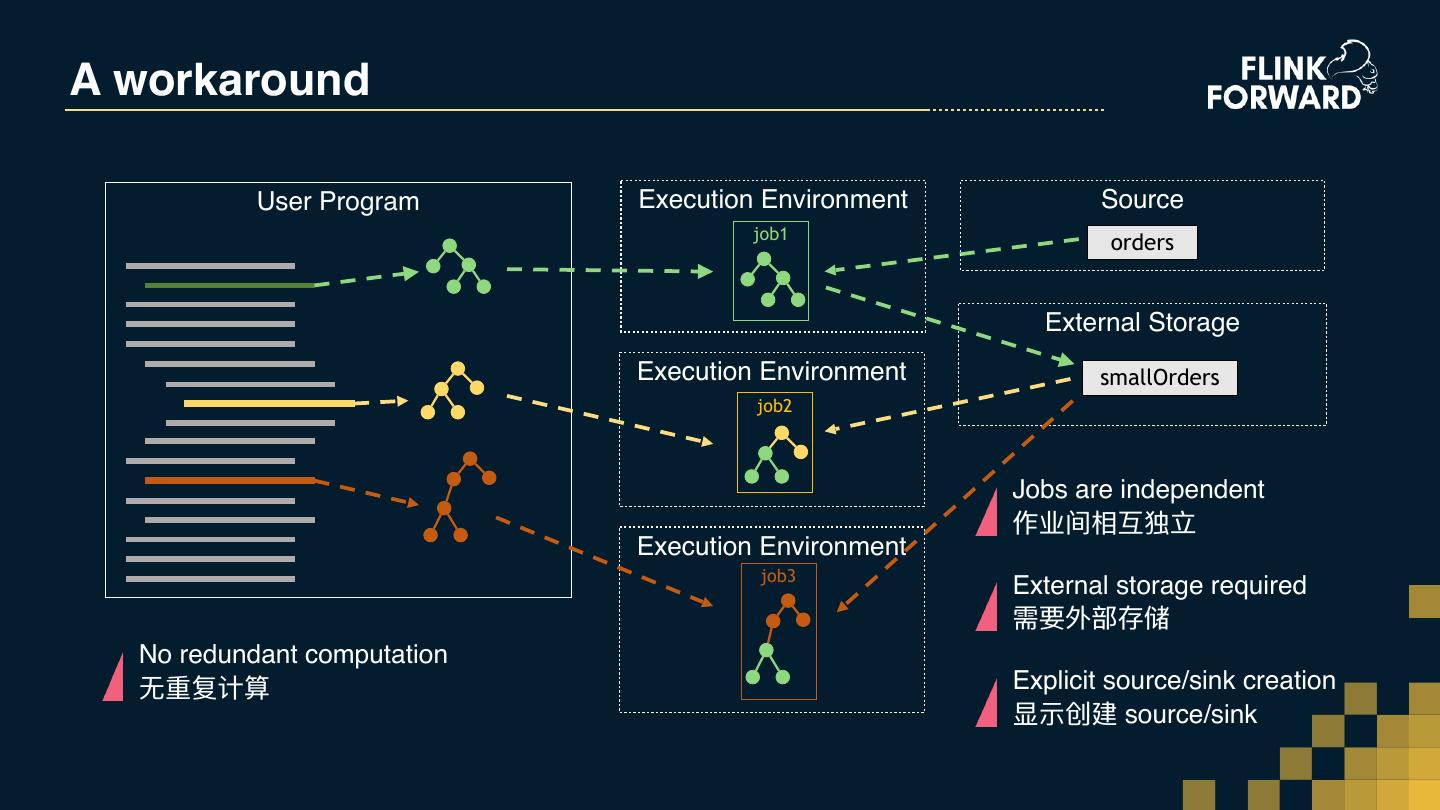
29 .A workaround User Program Execution Environment Source job1 orders External Storage Execution Environment smallOrders job2 Jobs are independent 作业间相互独⽴立 Execution Environment job3 External storage required 需要外部存储 No redundant computation ⽆无重复计算 Explicit source/sink creation 显示创建 source/sink
3秒后跳转登录页面
去登陆

