































































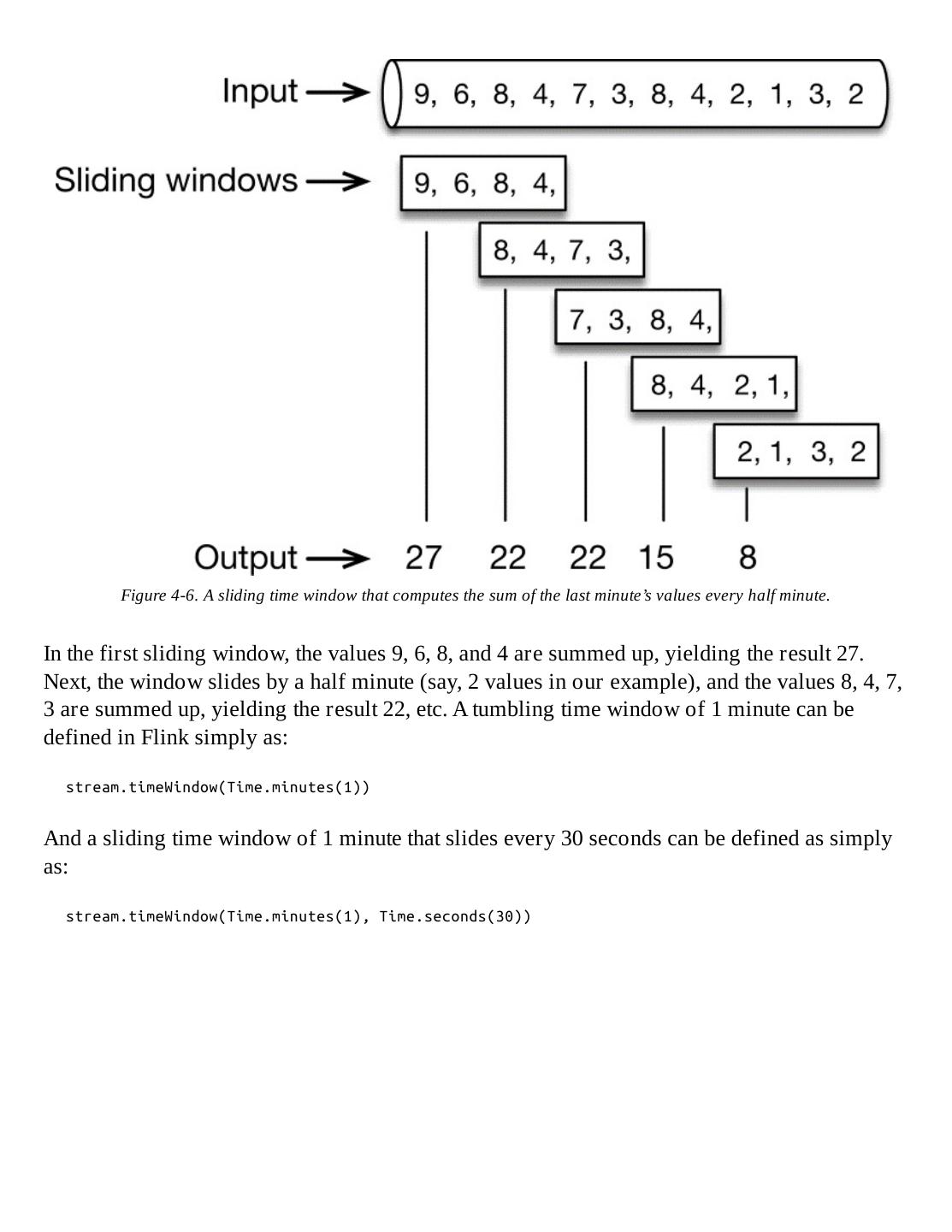







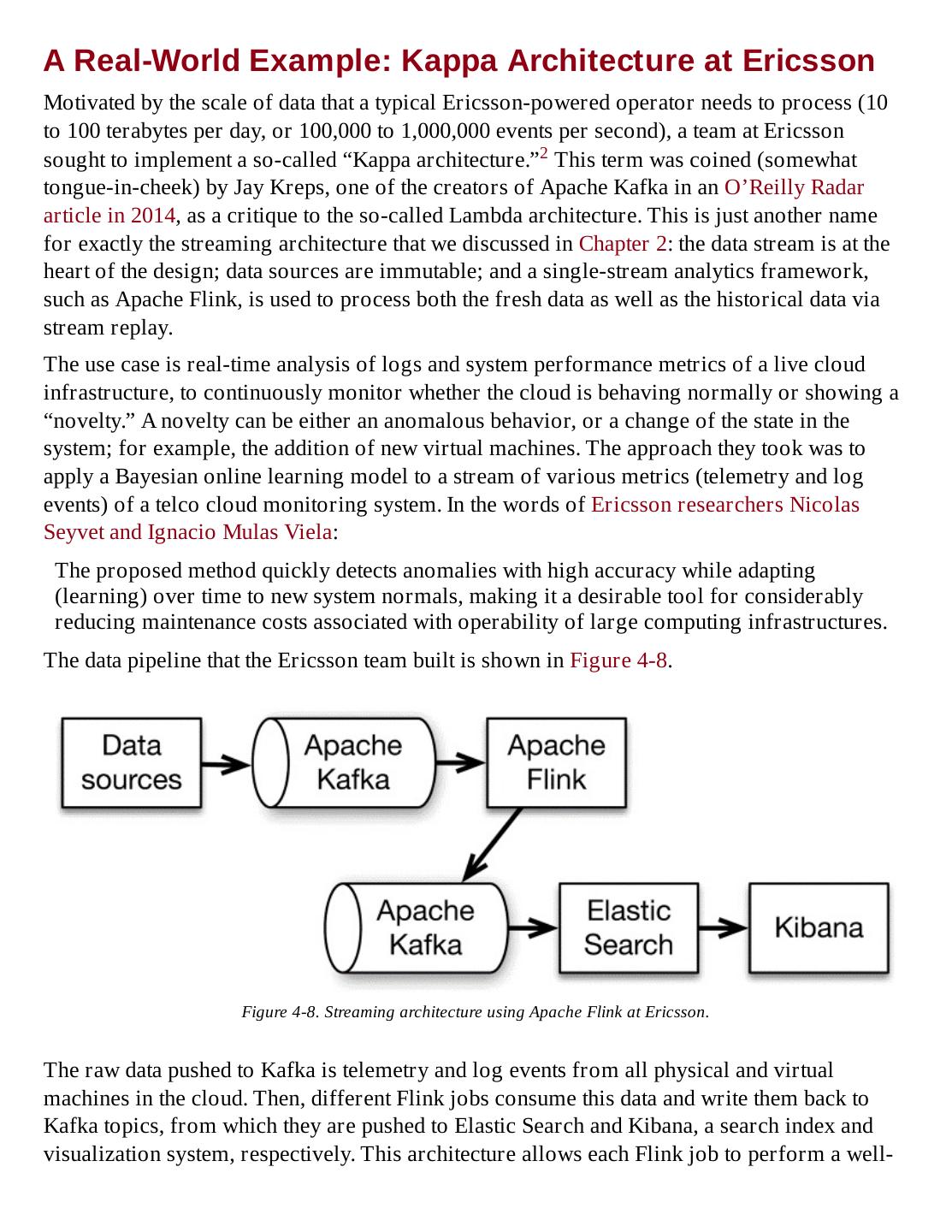
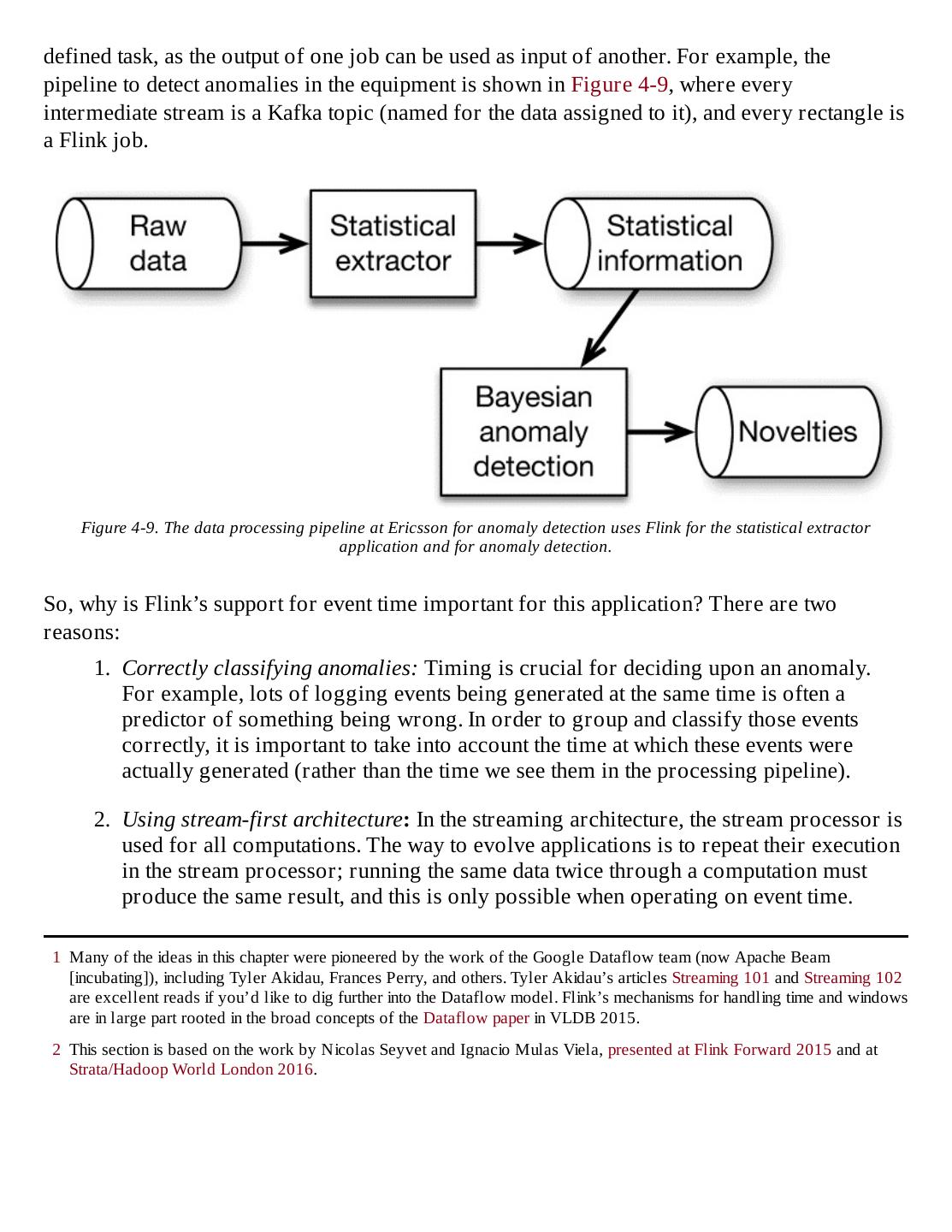

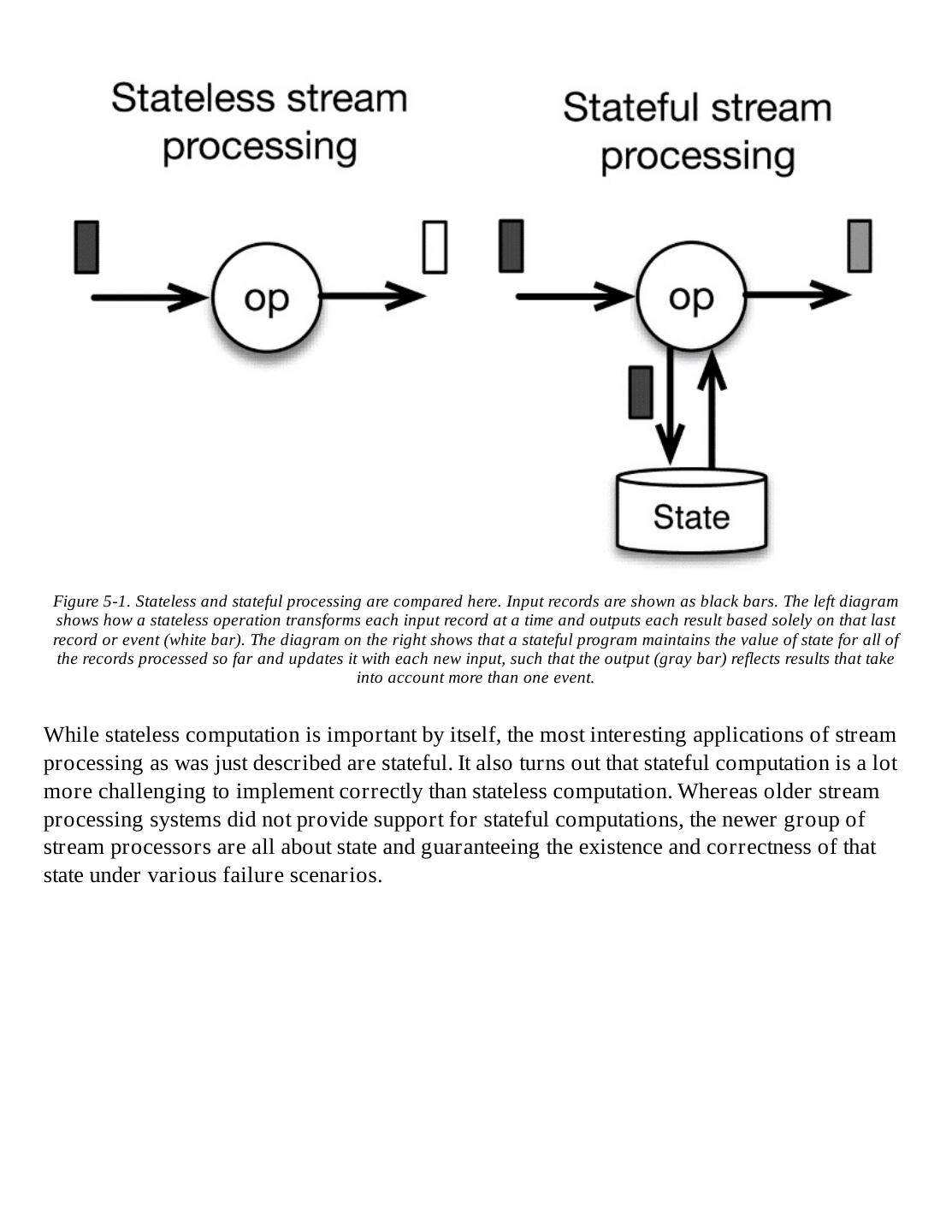




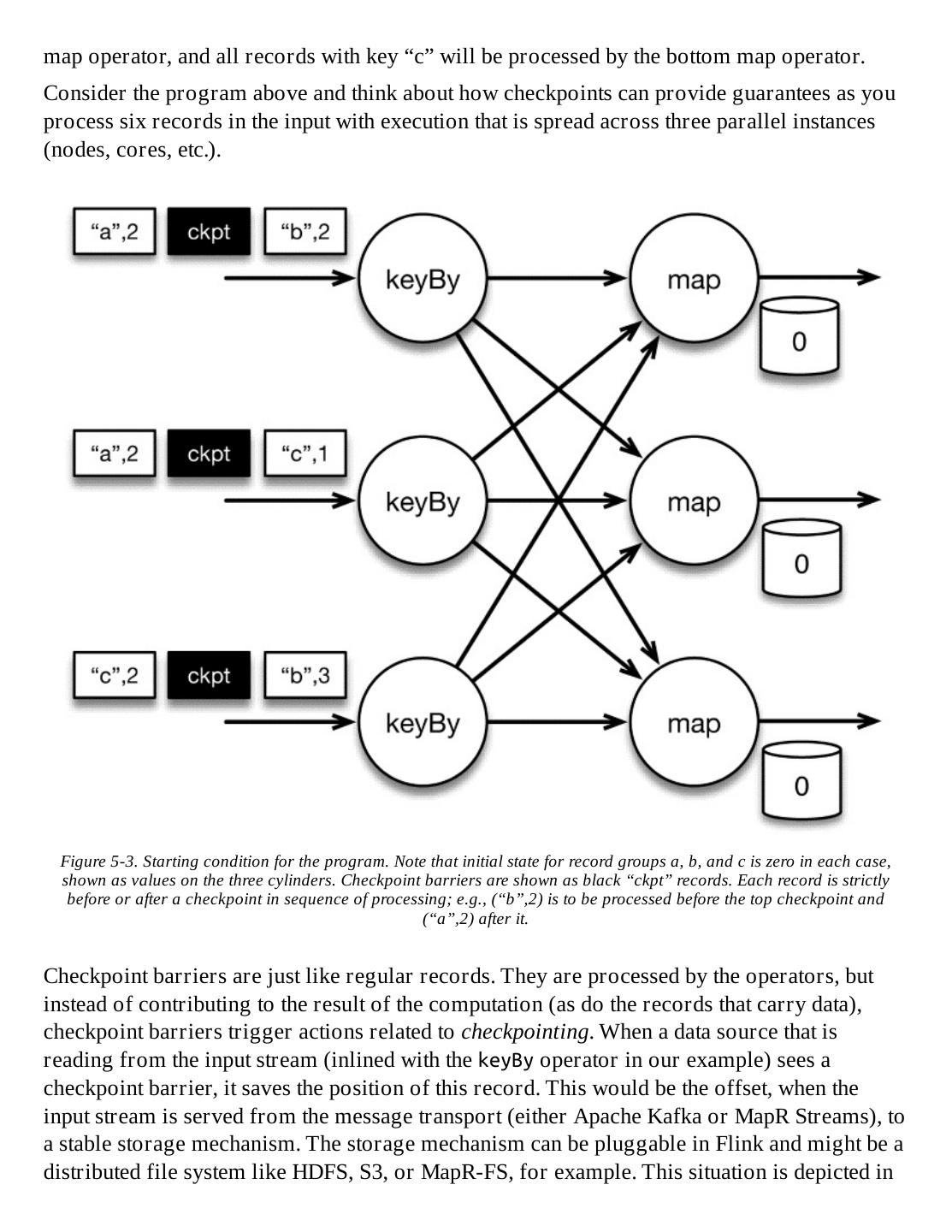
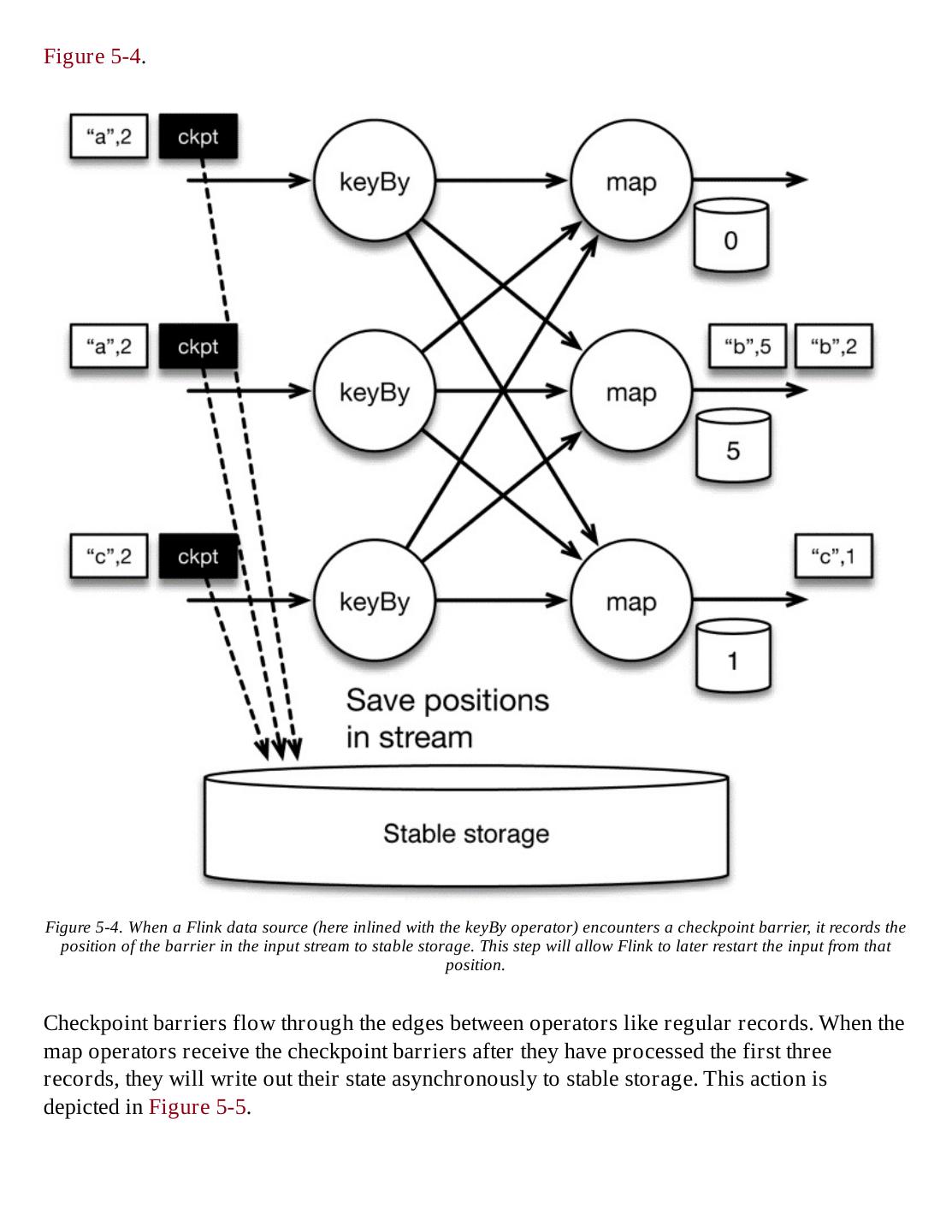
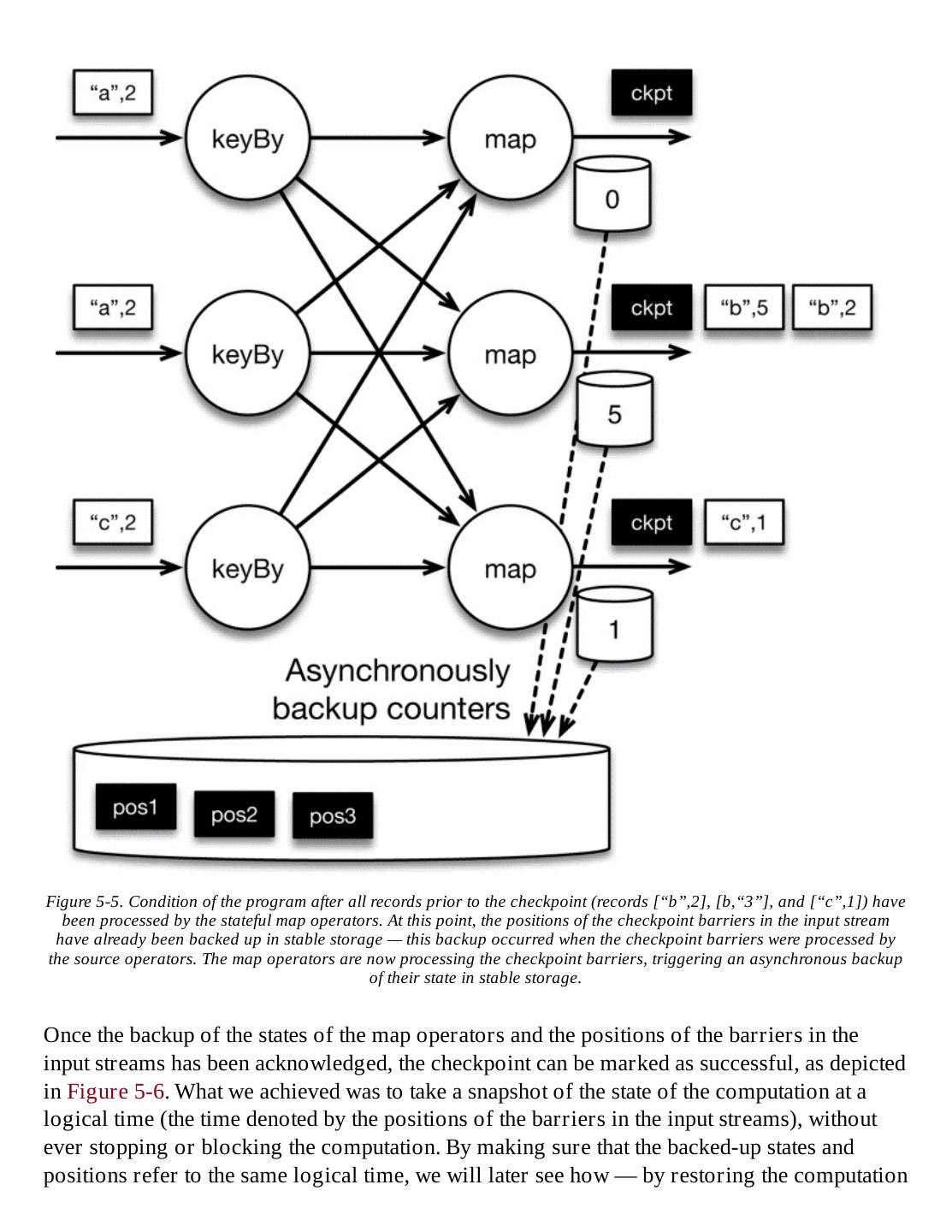
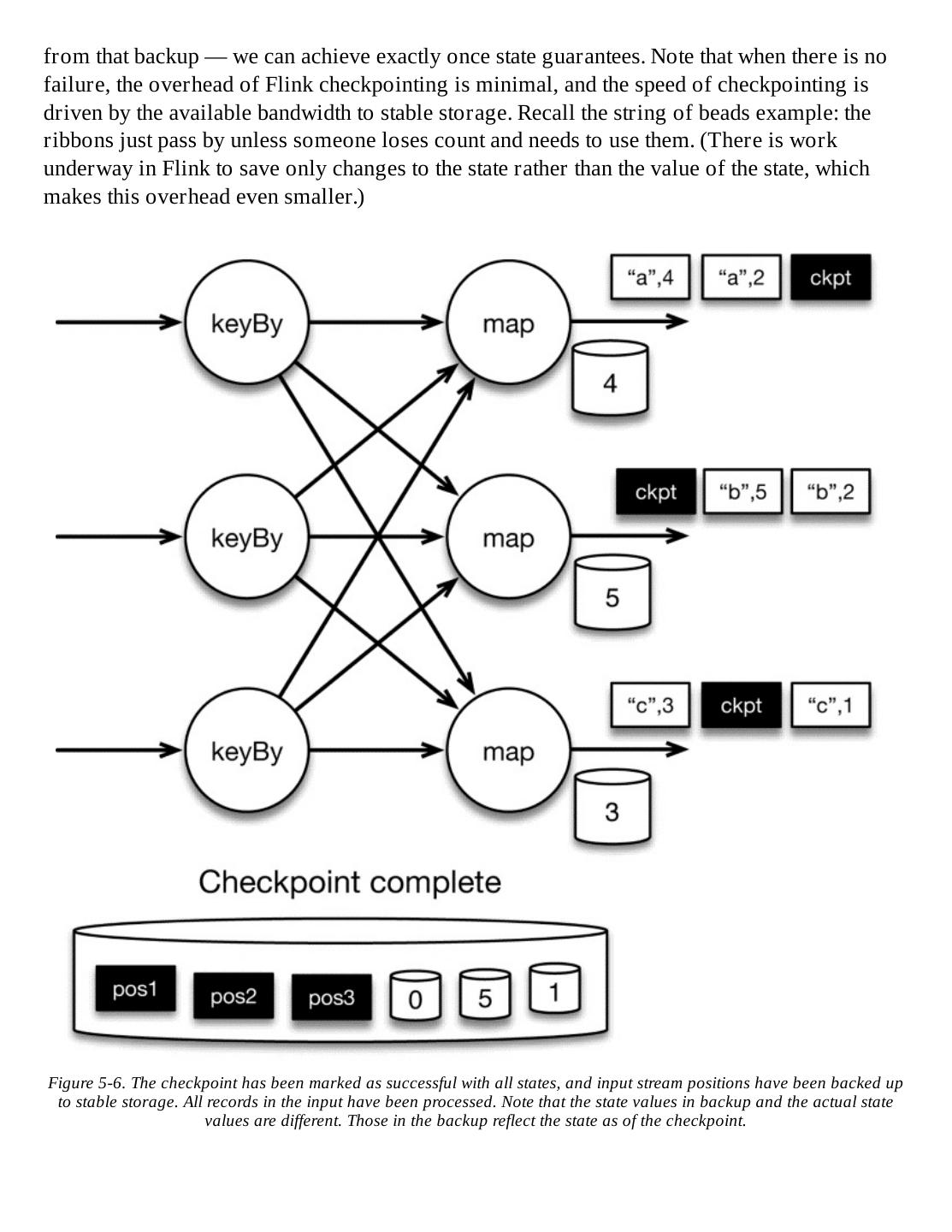





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Introduction to Apache Flink
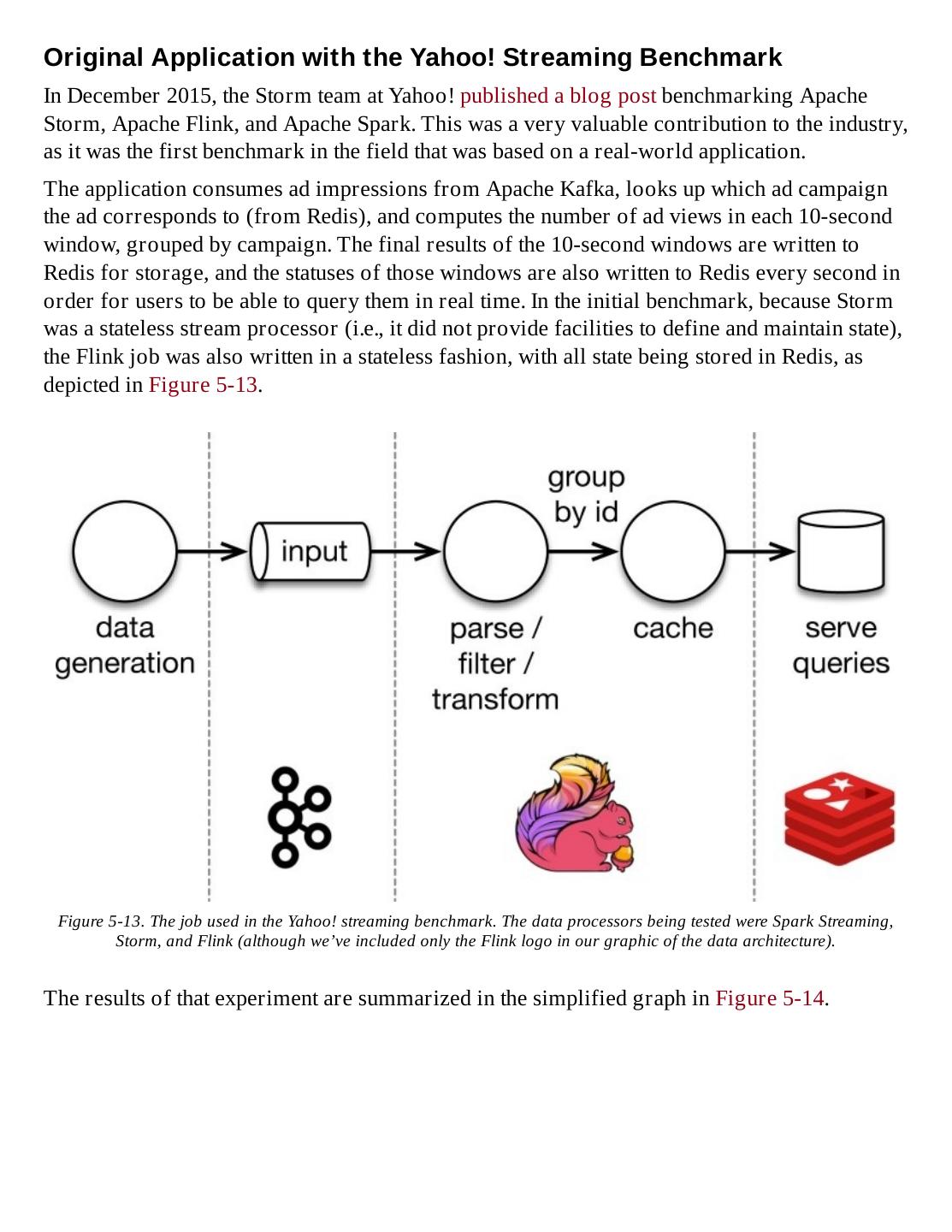
这是一本介绍Apache Flink技术的书籍,Apache Flink是一款创新的开源流式数据处理框架,利用基于流的方法,具有惊奇的数据处理能力。Flink不仅可以容错、实时分析,还可以分析历史数据,极大的减少了数据运输成本。也许最令人惊讶的是,Flink既可以让你做流式分析,也可以做批量数据处理,Flink所表现出的强大性能让开发应用程序变得更容易,而Flink本身的体系结构也同样使得这些应用程序在使用过程中变得易于维护,降低维护成本。
展开查看详情
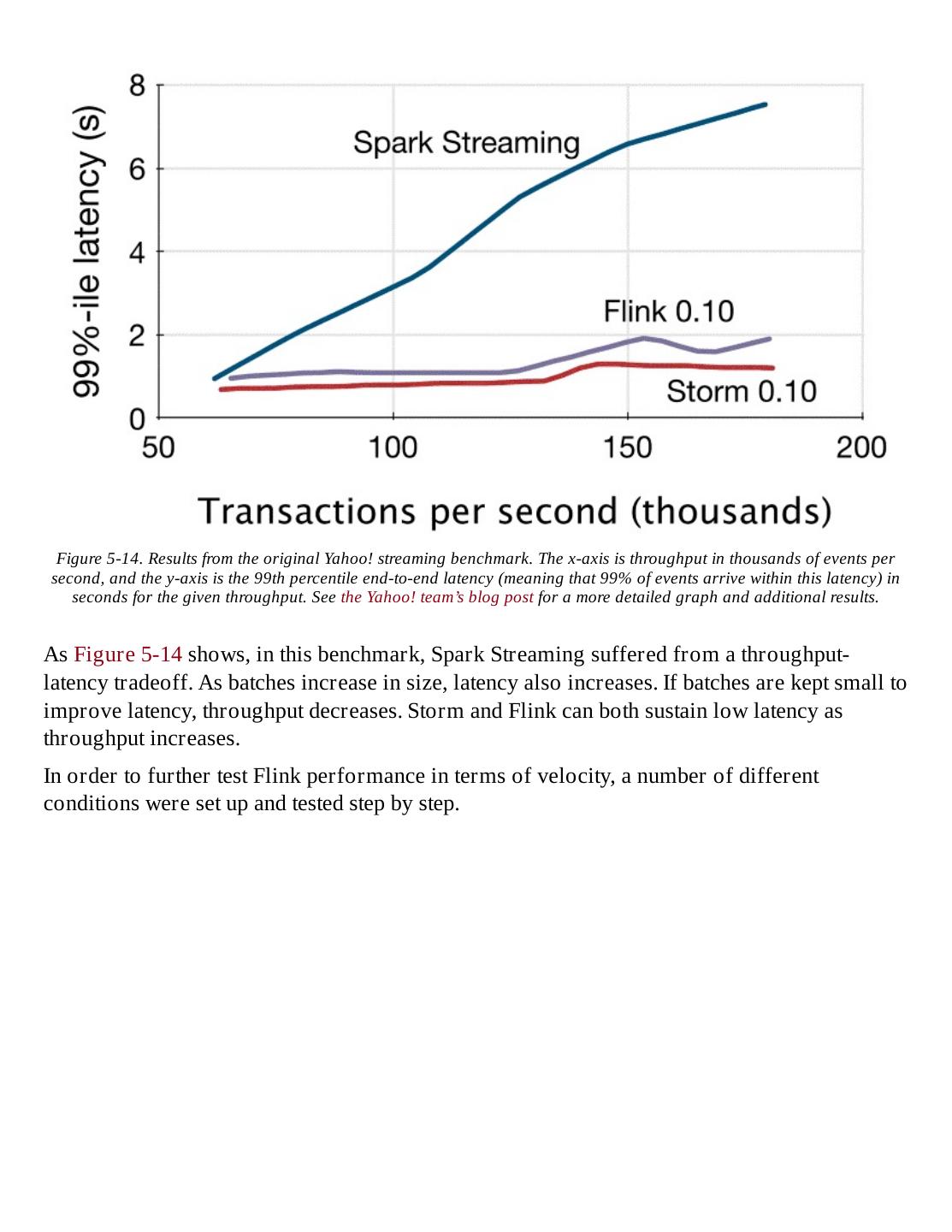
1 .
2 .
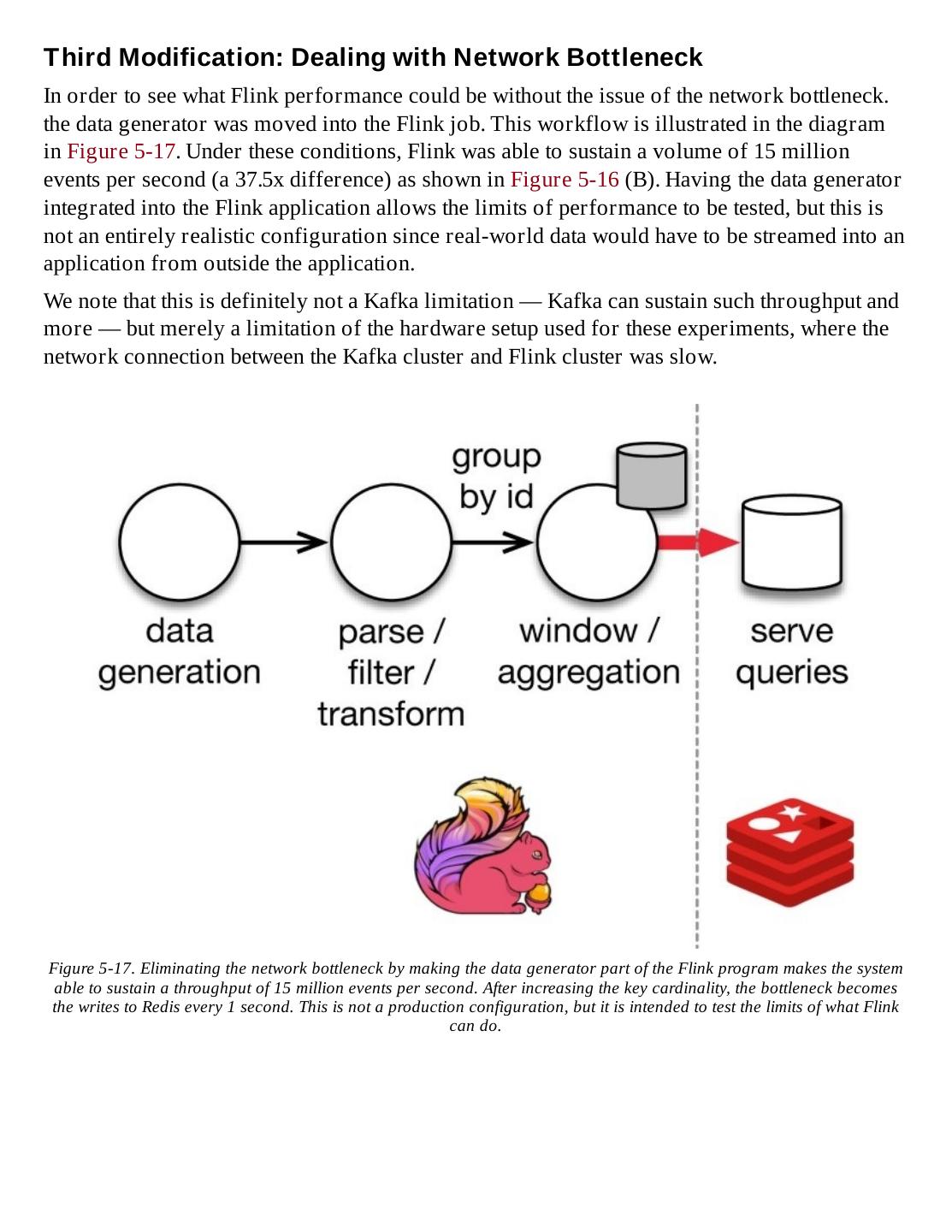
3 .Introduction to Apache Flink Stream Processing for Real Time and Beyond Ellen Friedman and Kostas Tzoumas
4 .Introduction to Apache Flink by Ellen Friedman and Kostas Tzoumas Copyright © 2016 Ellen Friedman and Kostas Tzoumas. All rights reserved. All images copyright Ellen Friedman unless otherwise noted. Figure 1-3 courtesy Michael Vasilyev / Alamy Stock Photo. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com. Editor: Shannon Cutt Production Editor: Holly Bauer Forsyth Copyeditor: Holly Bauer Forsyth Proofreader: Octal Publishing, Inc. Interior Designer: David Futato Cover Designer: Karen Montgomery Illustrator: Rebecca Panzer September 2016: First Edition
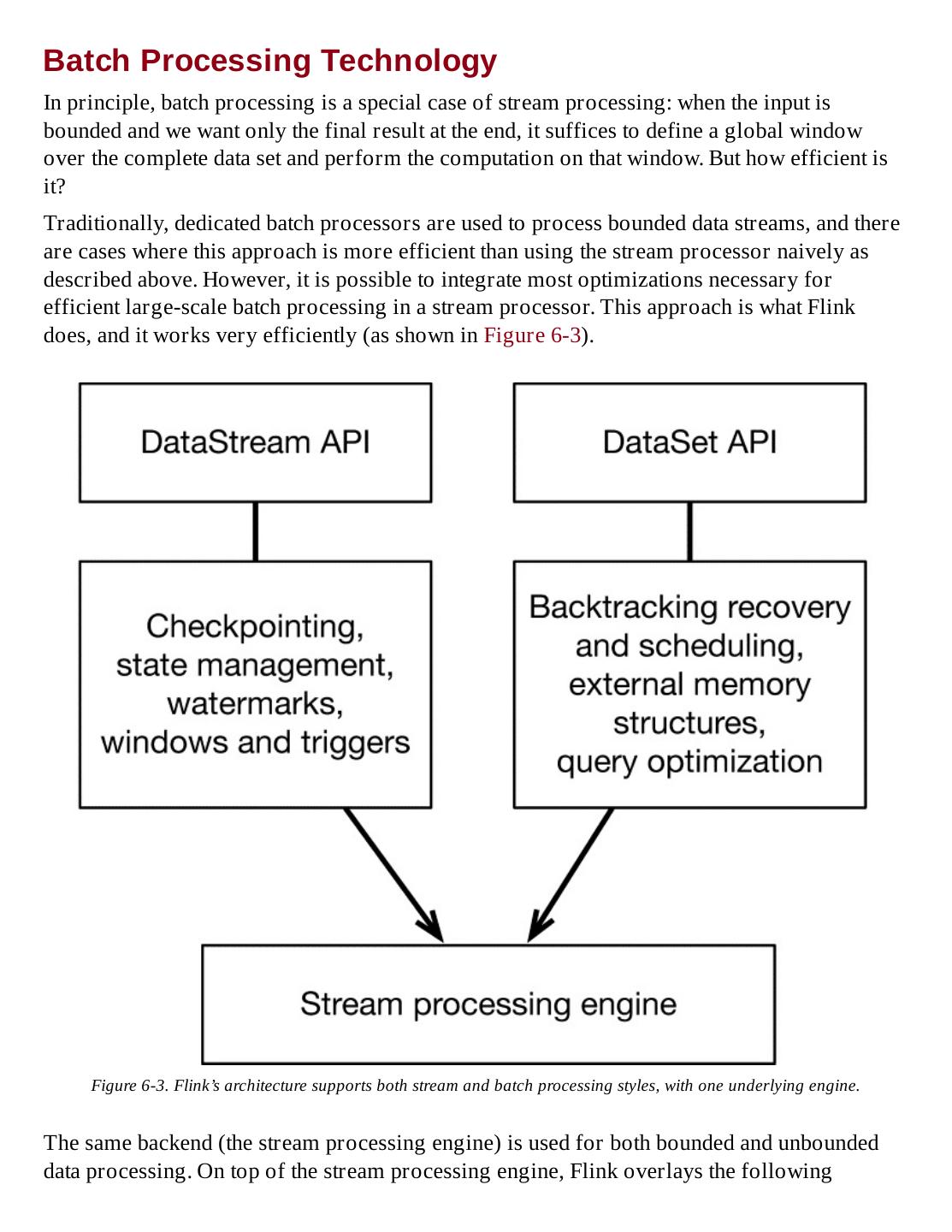
5 .Revision History for the First Edition 2016-09-01: First Release 2016-10-20: Second Release The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Introduction to Apache Flink, the cover image, and related trade dress are trademarks of O’Reilly Media, Inc. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights. 978-1-491-97658-6 [LSI]
6 .Preface There’s a flood of interest in learning how to analyze streaming data in large-scale systems, partly because there are situations in which the time-value of data makes real-time analytics so attractive. But gathering in-the-moment insights made possible by very low-latency applications is just one of the benefits of high-performance stream processing. In this book, we offer an introduction to Apache Flink, a highly innovative open source stream processor with a surprising range of capabilities that help you take advantage of stream-based approaches. Flink not only enables fault-tolerant, truly real-time analytics, it can also analyze historical data and greatly simplify your data pipeline. Perhaps most surprising is that Flink lets you do streaming analytics as well as batch jobs, both with one technology. Flink’s expressivity and robust performance make it easy to develop applications, and Flink’s architecture makes those easy to maintain in production. Not only do we explain what Flink can do, we also describe how people are using it, including in production. Flink has an active and rapidly growing open international community of developers and users. The first Flink-only conference, called Flink Forward, was held in Berlin in October 2015, the second is scheduled for September 2016, and there are Apache Flink meetups around the world, with new use cases being widely reported.
7 .How to Use This Book This book will be useful for both nontechnical and technical readers. No specialized skills or previous experience with stream processing are necessary to understand the explanations of underlying concepts of Flink’s designs and capabilities, although a general familiarity with big data systems is helpful. To be able to use sample code or the tutorials referenced in the book, experience with Java or Scala is needed, but the key concepts underlying these examples are explained clearly in this book even without needing to understand the code itself. Chapters 1–3 provide a basic explanation of the needs that motivated Flink’s development and how it meets them, the advantages of a stream-first architecture, and an overview of Flink design. Chapter 4–Appendix A provide a deeper, technical explanation of Flink’s capabilities.
8 .Conventions Used in This Book NOT E This icon indicates a general note. T IP This icon signifies a tip or suggestion. WARNING This icon indicates a warning or caution.
9 .Chapter 1. Why Apache Flink? Our best understanding comes when our conclusions fit evidence, and that is most effectively done when our analyses fit the way life happens. Many of the systems we need to understand — cars in motion emitting GPS signals, financial transactions, interchange of signals between cell phone towers and people busy with their smartphones, web traffic, machine logs, measurements from industrial sensors and wearable devices — all proceed as a continuous flow of events. If you have the ability to efficiently analyze streaming data at large scale, you’re in a much better position to understand these systems and to do so in a timely manner. In short, streaming data is a better fit for the way we live. It’s natural, therefore, to want to collect data as a stream of events and to process data as a stream, but up until now, that has not been the standard approach. Streaming isn’t entirely new, but it has been considered as a specialized and often challenging approach. Instead, enterprise data infrastructure has usually assumed that data is organized as finite sets with beginnings and ends that at some point become complete. It’s been done this way largely because this assumption makes it easier to build systems that store and process data, but it is in many ways a forced fit to the way life happens. So there is an appeal to processing data as streams, but that’s been difficult to do well, and the challenges of doing so are even greater now as people have begun to work with data at very large scale across a wide variety of sectors. It’s a matter of physics that with large-scale distributed systems, exact consistency and certain knowledge of the order of events are necessarily limited. But as our methods and technologies evolve, we can strive to make these limitations innocuous in so far as they affect our business and operational goals. That’s where Apache Flink comes in. Built as open source software by an open community, Flink provides stream processing for large-volume data, and it also lets you handle batch analytics, with one technology. It’s been engineered to overcome certain tradeoffs that have limited the effectiveness or ease- of-use of other approaches to processing streaming data. In this book, we’ll investigate potential advantages of working well with data streams so that you can see if a stream-based approach is a good fit for your particular business goals. Some of the sources of streaming data and some of the situations that make this approach useful may surprise you. In addition, the will book help you understand Flink’s technology and how it tackles the challenges of stream processing. In this chapter, we explore what people want to achieve by analyzing streaming data and some of the challenges of doing so at large scale. We also introduce you to Flink and take a first
10 .look at how people are using it, including in production.
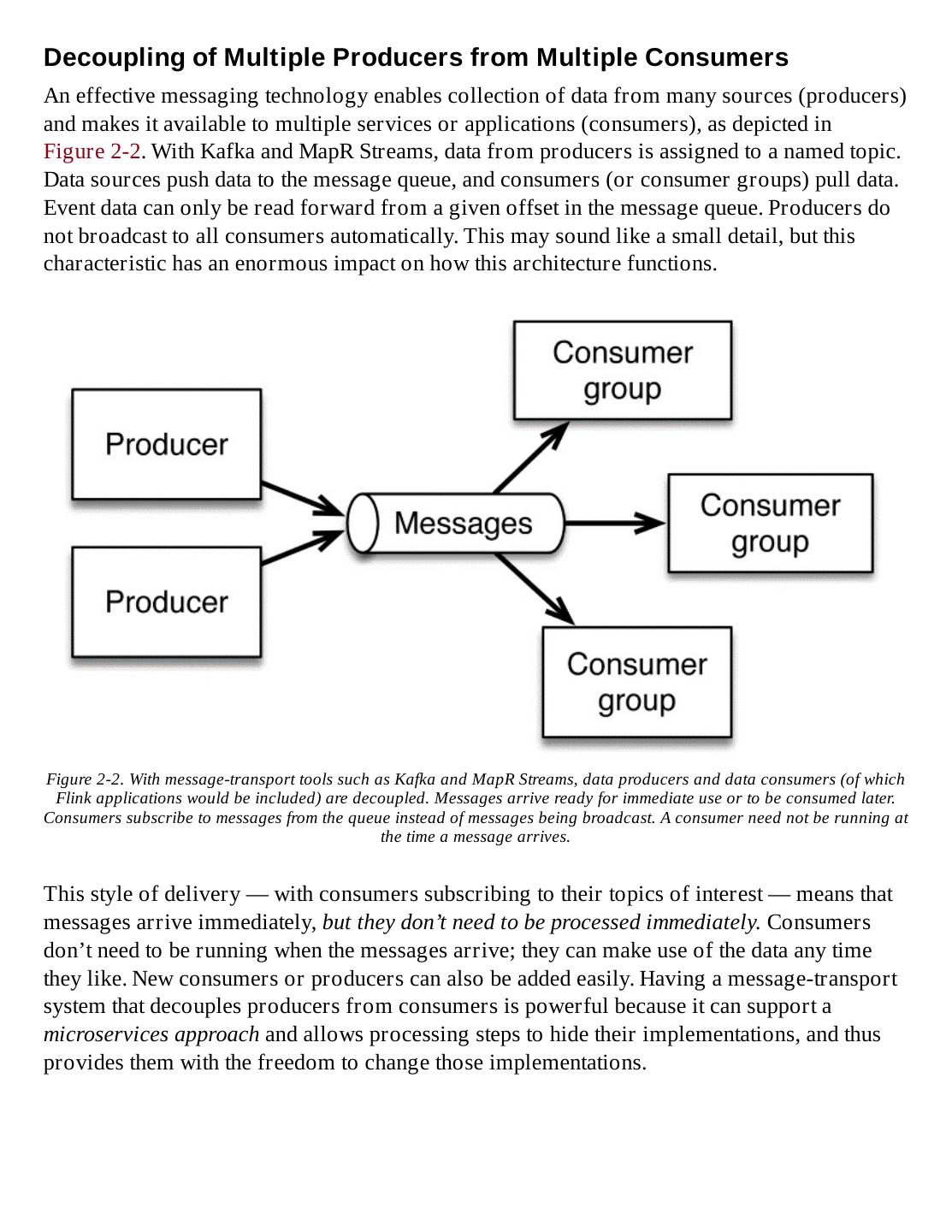
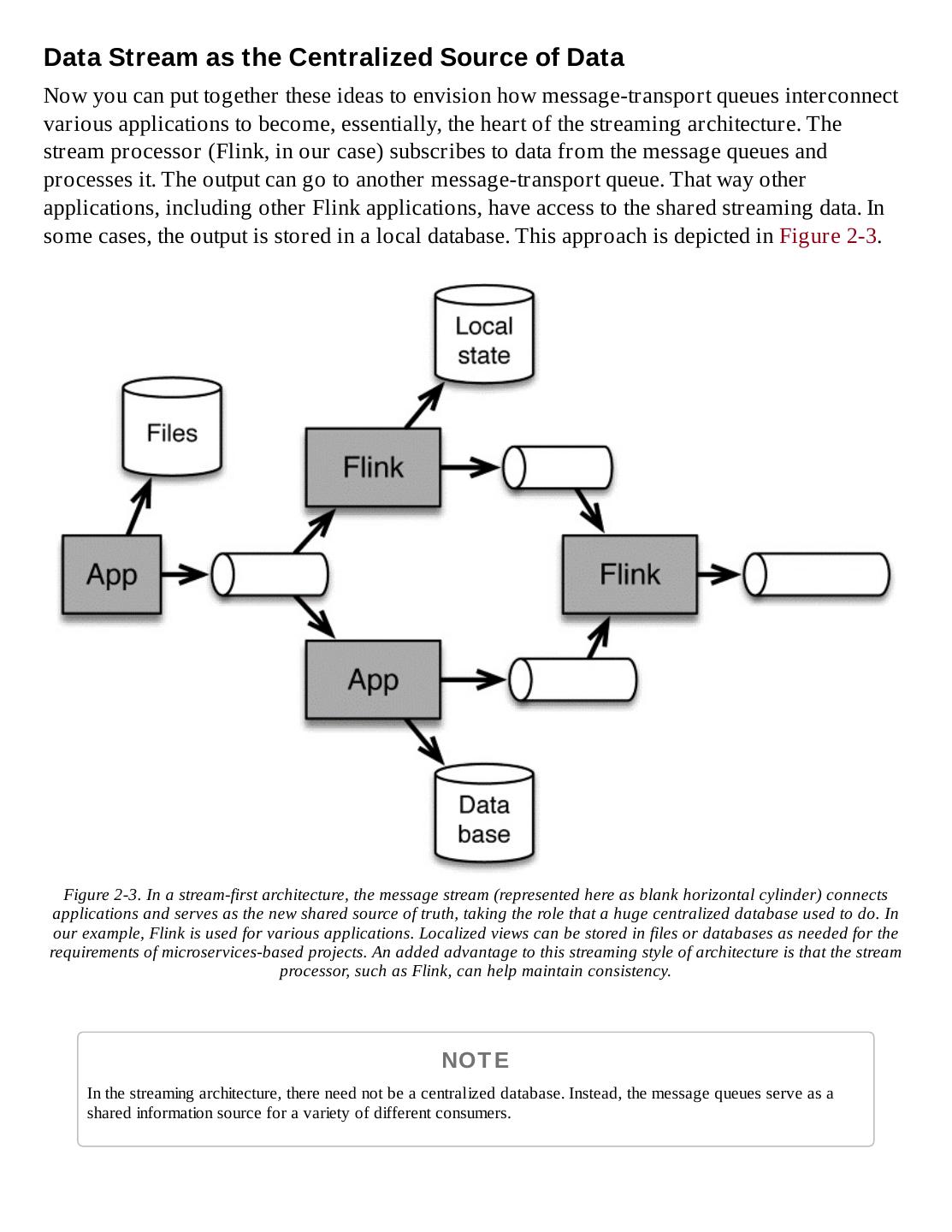
11 .Consequences of Not Doing Streaming Well Who needs to work with streaming data? Some of the first examples that come to mind are people working with sensor measurements or financial transactions, and those are certainly situations where stream processing is useful. But there are much more widespread sources of streaming data: clickstream data that reflects user behavior on websites and machine logs for your own data center are two familiar examples. In fact, streaming data sources are essentially ubiquitous — it’s just that there has generally been a disconnect between data from continuous events and the consumption of that data in batch-style computation. That’s now changing with the development of new technologies to handle large-scale streaming data. Still, if it has historically been a challenge to work with streaming data at very large scale, why now go to the trouble to do it, and to do it well? Before we look at what has changed — the new architecture and emerging technologies that support working with streaming data — let’s first look at the consequences of not doing streaming well.
12 .Retail and Marketing In the modern retail world, sales are often represented by clicks from a website, and this data may arrive at large scale, continuously but not evenly. Handling it well at scale using older techniques can be difficult. Even building batch systems to handle these dataflows is challenging — the result can be an enormous and complicated workflow. The result can be dropped data, delays, or misaggregated results. How might that play out in business terms? Imagine that you’re reporting sales figures for the past quarter to your CEO. You don’t want to have to recant later because you over-reported results based on inaccurate figures. If you don’t deal with clickstream data well, you may end up with inaccurate counts of website traffic — and that in turn means inaccurate billing for ad placement and performance figures. Airline passenger services face the similar challenge of handling huge amounts of data from many sources that must be quickly and accurately coordinated. For example, as passengers check in, data must be checked against reservation information, luggage handling and flight status, as well as billing. At this scale, it’s not easy to keep up unless you have robust technology to handle streaming data. The recent major service outages with three of the top four airlines can be directly attributed to problems handling real-time data at scale. Of course many related problems — such as the importance of not double-booking hotel rooms or concert tickets — have traditionally been handled effectively with databases, but often at considerable expense and effort. The costs can begin to skyrocket as the scale of data grows, and database response times are too slow for some situations. Development speed may suffer from lack of flexibility and come to a crawl in large and complex or evolving systems. Basically, it is difficult to react in a way that lets you keep up with life as it happens while maintaining consistency and affordability in large-scale systems. Fortunately, modern stream processors can often help address these issues in new ways, working well at scale, in a timely manner, and less expensively. Stream processing also invites exploration into doing new things, such as building real-time recommendation systems to react to what people are buying right now, as part of deciding what else they are likely to want. It’s not that stream processors replace databases — far from it; rather, they can in certain situations address roles for which databases are not a great fit. This also frees up databases to be used for locally specific views of current state of business. This shift is explained more thoroughly in our discussion of stream-first architecture in Chapter 2.
13 .The Internet of Things The Internet of Things (IoT) is an area where streaming data is common and where low- latency data delivery and processing, along with accuracy of data analysis, is often critical. Sensors in various types of equipment take frequent measurements and stream those to data centers where real-time or near real–time processing applications will update dashboards, run machine learning models, issue alerts, and provide feedback for many different services. The transportation industry is another example where it’s important to do streaming well. State-of-the-art train systems, for instance, rely on sensor data communicated from tracks to trains and from trains to sensors along the route; together, reports are also communicated back to control centers. Measurements include train speed and location, plus information from the surroundings for track conditions. If this streaming data is not processed correctly, adjustments and alerts do not happen in time to adjust to dangerous conditions and avoid accidents. Another example from the transportation industry are “smart” or connected cars, which are being designed to communicate data via cell phone networks, back to manufacturers. In some countries (i.e., Nordic countries, France, the UK, and beginning in the US), connected cars even provide information to insurance companies and, in the case of race cars, send information back to the pit via a radio frequency (RF) link for analysis. Some smartphone applications also provide real-time traffic updates shared by millions of drivers, as suggested in Figure 1-1.
14 .Figure 1-1. The time-value of data comes into consideration in many situations including IoT data used in transportation. Real-time traffic information shared by millions of drivers relies on reasonably accurate analysis of streaming data that is processed in a timely manner. (Image credit © 2016 Friedman) The IoT is also having an impact in utilities. Utility companies are beginning to implement smart meters that send updates on usage periodically (e.g., every 15 minutes), replacing the old meters that are read manually once a month. In some cases, utility companies are experimenting with making measurements every 30 seconds. This change to smart meters results in a huge amount of streaming data, and the potential benefits are large. The advantages include the ability to use machine learning models to detect usage anomalies caused by equipment problems or energy theft. Without efficient ways to deliver and accurately process streaming data at high throughput and with very low latencies, these new goals cannot be met. Other IoT projects also suffer if streaming is not done well. Large equipment such as turbines in a wind farm, manufacturing equipment, or pumps in a drilling operation — these all rely on analysis of sensor measurements to provide malfunction alerts. The consequences of not handling stream analysis well and with adequate latency in these cases can be costly or even catastrophic.
15 .Telecom The telecommunications industry is a special case of IoT data, with its widespread use of streaming event data for a variety of purposes across geo-distributed regions. If a telecommunications company cannot process streaming data well, it will fail to preemptively reroute usage surges to alternative cell towers or respond quickly to outages. Anomaly detection to processes streaming data is important to this industry — in this case, to detect dropped calls or equipment malfunctions.
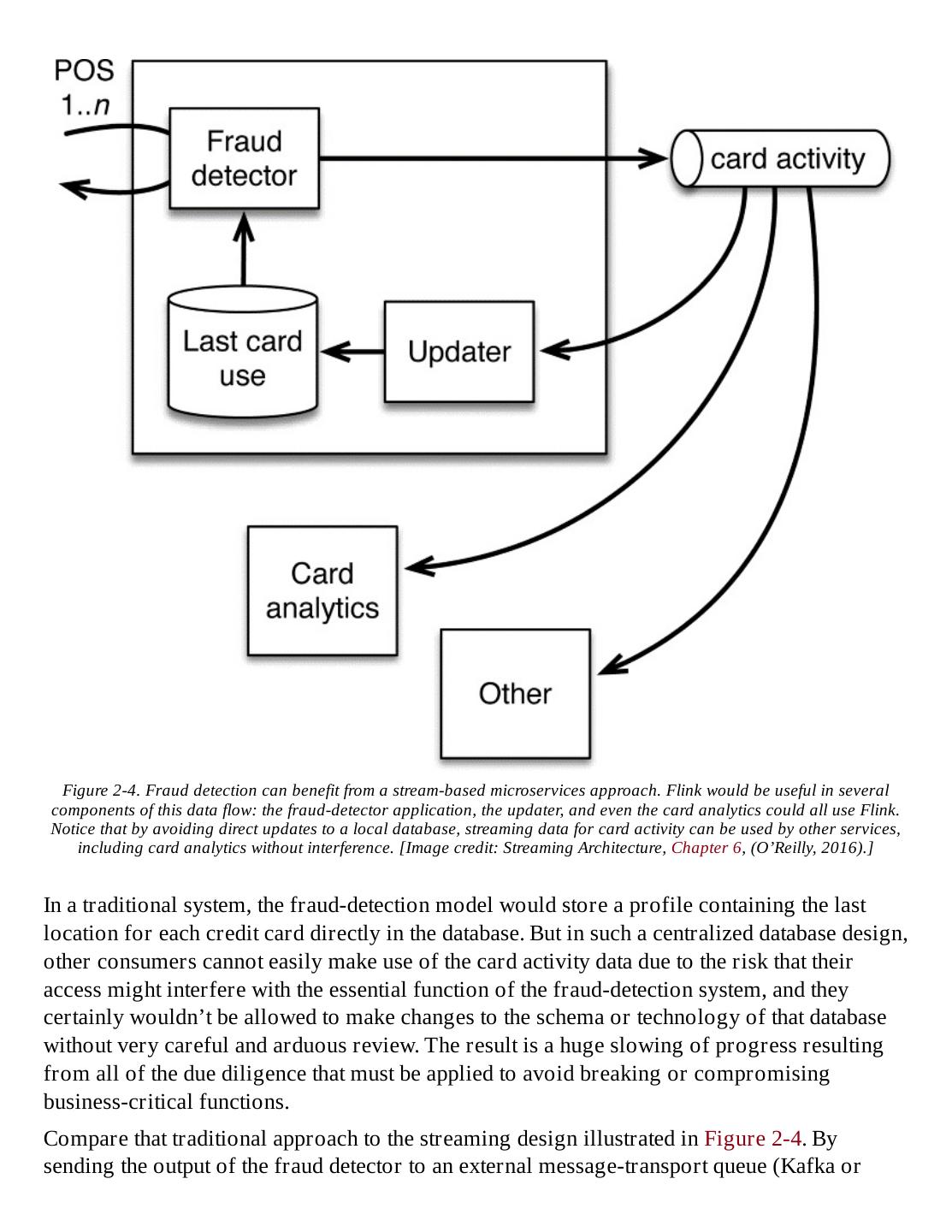
16 .Banking and Financial Sector The potential problems caused by not doing stream processing well are particularly evident in banking and financial settings. A retail bank would not want customer transactions to be delayed or to be miscounted and therefore result in erroneous account balances. The old- fashioned term “bankers’ hours” referred to the need to close up a bank early in the afternoon in order to freeze activity so that an accurate tally could be made before the next day’s business. That batch style of business is long gone. Transactions and reporting today must happen quickly and accurately; some new banks even offer immediate, real-time push notifications and mobile banking access anytime, anywhere. In a global economy, it’s increasingly important to be able to meet the needs of a 24-hour business cycle. What happens if a financial institution does not have applications that can recognize anomalous behavior in user activity data with sensitive detection in real time? Fraud detection for credit card transactions requires timely monitoring and response. Being able to detect unusual login patterns that signal an online phishing attack can translate to huge savings by detecting problems in time to mitigate loss. NOT E The time-value of data in many situations makes low-latency or real-time stream processing highly desirable, as long as it’s also accurate and efficient.
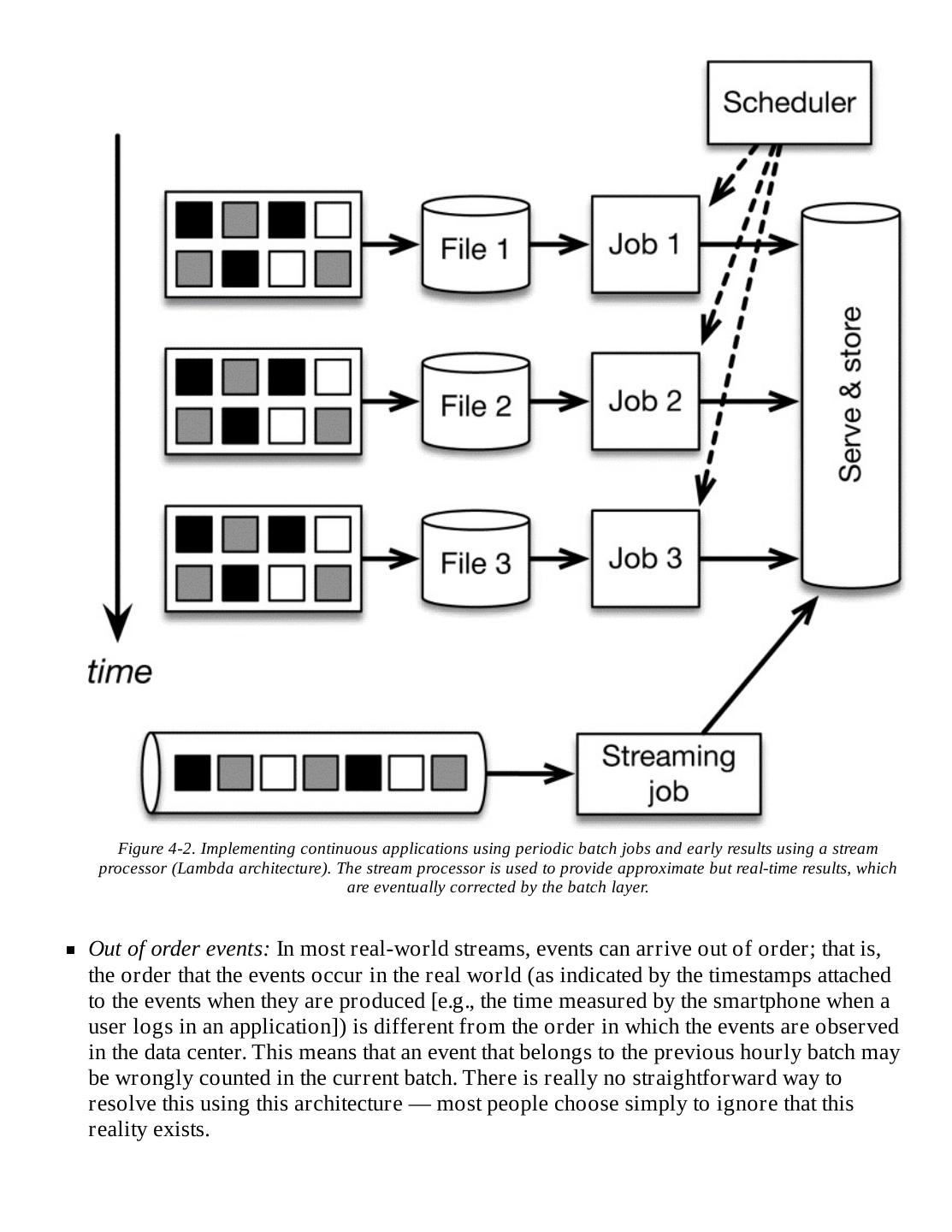
17 .Goals for Processing Continuous Event Data Being able to process data with very low latency is not the only advantage of effective stream processing. A wishlist for stream processing not only includes high throughput with low latency, but the processing system also needs to be able to deal with interruptions. A great streaming technology should be able to restart after a failure in a manner that produces accurate results; in other words, there’s an advantage to being fault-tolerant with exactly-once guarantees. Furthermore, the method used to achieve this level of fault tolerance preferably should not carry a lot of overhead cost in the absence of failures. It’s useful to be able to recognize sessions based on when the events occur rather than an arbitrary processing interval and to be able to track events in the correct order. It’s also important for such a system to be easy for developers to use, both in writing code and in fixing bugs, and it should be easily maintained. Also important is that these systems produce correct results with respect to the time that events happen in the real world — for example, being able to handle streams of events that arrive out of order (an unfortunate reality), and being able to deterministically replace streams (e.g., for auditing or debugging purposes).
18 .Evolution of Stream Processing Technologies The disconnect between continuous data production and data consumption in finite batches, while making the job of systems builders easier, has shifted the complexity of managing this disconnect to the users of the systems: the application developers and DevOps teams that need to use and manage this infrastructure. To manage this disconnect, some users have developed their own stream processing systems. In the open source space, a pioneer in stream processing is the Apache Storm project that started with Nathan Marz and a team at startup BackType (later acquired by Twitter) before being accepted into the Apache Software Foundation. Storm brought the possibility for stream processing with very low latency, but this real-time processing involved tradeoffs: high throughput was hard to achieve, and Storm did not provide the level of correctness that is often needed. In other words, it did not have exactly-once guarantees for maintaining accurate state, and even the guarantees that Storm could provide came at a high overhead. OVERVIEW OF LAM BDA ARCHIT ECT URE: ADVANT AGES AND LIM IT AT IONS The need for affordable scale drove people to distributed file systems such as HDFS and batch-based computing (MapReduce jobs). But that approach made it difficult to deal with low-latency insights. Development of real-time stream processing technology with Apache Storm helped address the latency issue, but not as a complete solution. For one thing, Storm did not guarantee state consistency with exactly-once processing and did not handle event-time processing. People who had these needs were forced to implement these features in their application code. A hybrid view of data analytics that mixed these approaches offered one way to deal with these challenges. This hybrid, called Lambda architecture, provided delayed but accurate results via batch MapReduce jobs and an in-the-moment preliminary view of new results via Storm’s processing. The Lambda architecture is a helpful framework for building big data applications, but it is not sufficient. For example, with a Lambda system based on MapReduce and HDFS, there is a time window, in hours, when inaccuracies due to failures are visible. Lambda architectures need the same business logic to be coded twice, in two different programming APIs: once for the batch system and once for the streaming system. This leads to two codebases that represent the same business problem, but have different kinds of bugs. In practice, this is very difficult to maintain. NOT E To compute values that depend on multiple streaming events, it is necessary to retain data from one event to another. This retained data is known as the state of the computation. Accurate handling of state is essential for consistency in computation. The ability to accurately update state after a failure or interruption is a key to fault tolerance. It’s hard to maintain fault-tolerant stream processing that has high throughput with very low latency, but the need for guarantees of accurate state motivated a clever compromise: what if the stream of data from continuous events were broken into a series of small, atomic batch jobs? If the batches were cut small enough — so-called “micro-batches” — your computation could approximate true streaming. The latency could not quite reach real time, but latencies of several seconds or even subseconds for very simple applications would be possible. This is
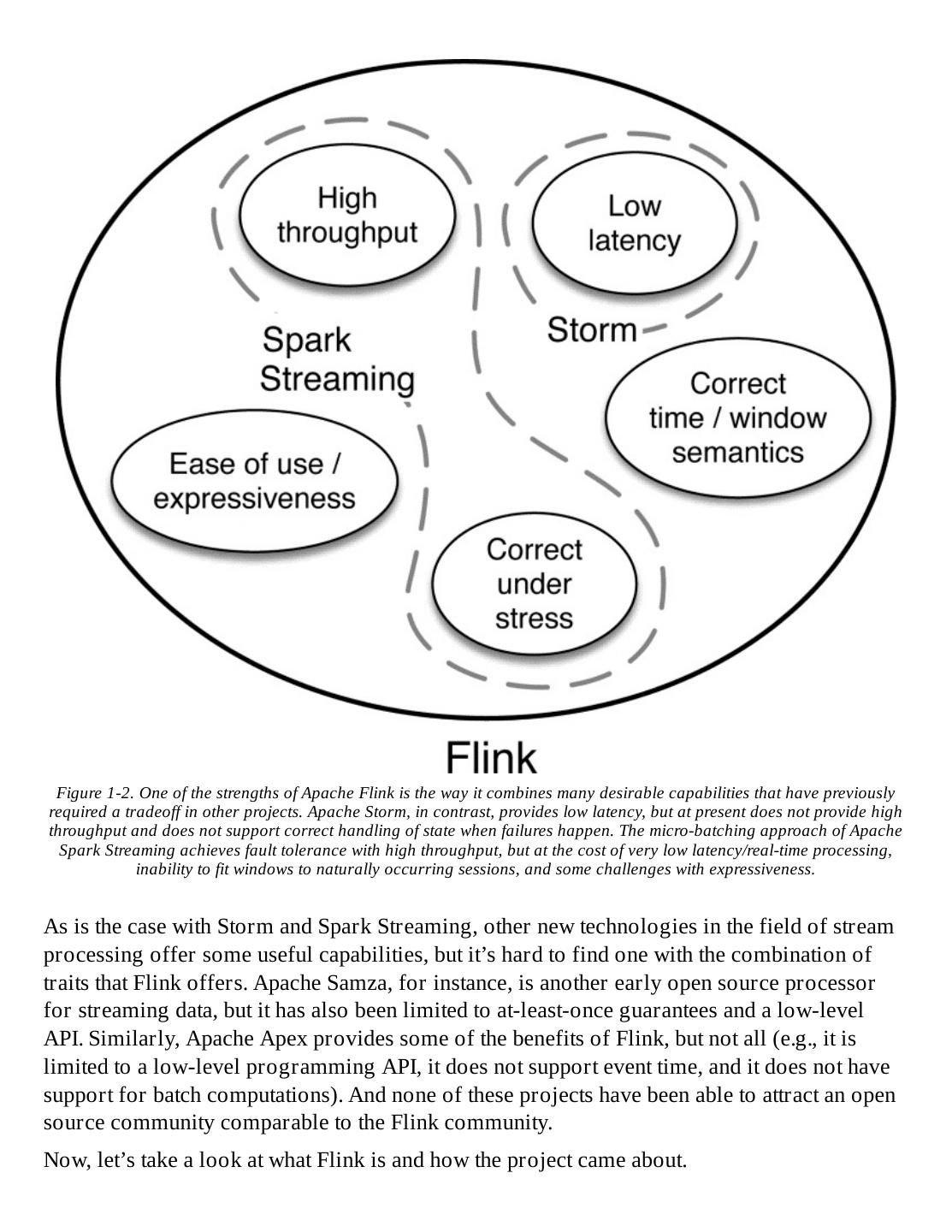
19 .the approach taken by Apache Spark Streaming, which runs on the Spark batch engine. More important, with micro-batching, you can achieve exactly-once guarantees of state consistency. If a micro-batch job fails, it can be rerun. This is much easier than would be true for a continuous stream-processing approach. An extension of Storm, called Storm Trident, applies micro-batch computation on the underlying stream processor to provide exactly-once guarantees, but at a substantial cost to latency. However, simulating streaming with periodic batch jobs leads to very fragile pipelines that mix DevOps with application development concerns. The time that a periodic batch job takes to finish is tightly coupled with the timing of data arrival, and any delays can cause inconsistent (a.k.a. wrong) results. The underlying problem with this approach is that time is only managed implicitly by the part of the system that creates the small jobs. Frameworks like Spark Streaming mitigate some of the fragility, but not entirely, and the sensitivity to timing relative to batches still leads to poor latency and a user experience where one needs to think a lot about performance in the application code. These tradeoffs between desired capabilities have motivated continued attempts to improve existing processors (for example, the development of Storm Trident to try to overcome some of the limitations of Storm). When existing processors fall short, the burden is placed on the application developer to deal with any issues that result. An example is the case of micro- batching, which does not provide an excellent fit between the natural occurrence of sessions in event data and the processor ’s need to window data only as multiples of the batch time (recovery interval). With less flexibility and expressivity, development time is slower and operations take more effort to maintain properly. This brings us to Apache Flink, a data processor that removes many of these tradeoffs and combines many of the desired traits needed to efficiently process data from continuous events. The combination of some of Flink’s capabilities is illustrated in Figure 1-2.
20 . Figure 1-2. One of the strengths of Apache Flink is the way it combines many desirable capabilities that have previously required a tradeoff in other projects. Apache Storm, in contrast, provides low latency, but at present does not provide high throughput and does not support correct handling of state when failures happen. The micro-batching approach of Apache Spark Streaming achieves fault tolerance with high throughput, but at the cost of very low latency/real-time processing, inability to fit windows to naturally occurring sessions, and some challenges with expressiveness. As is the case with Storm and Spark Streaming, other new technologies in the field of stream processing offer some useful capabilities, but it’s hard to find one with the combination of traits that Flink offers. Apache Samza, for instance, is another early open source processor for streaming data, but it has also been limited to at-least-once guarantees and a low-level API. Similarly, Apache Apex provides some of the benefits of Flink, but not all (e.g., it is limited to a low-level programming API, it does not support event time, and it does not have support for batch computations). And none of these projects have been able to attract an open source community comparable to the Flink community. Now, let’s take a look at what Flink is and how the project came about.
21 .First Look at Apache Flink The Apache Flink project home page starts with the tagline, “Apache Flink is an open source platform for distributed stream and batch data processing.” For many people, it’s a surprise to realize that Flink not only provides real-time streaming with high throughput and exactly- once guarantees, but it’s also an engine for batch data processing. You used to have to choose between these approaches, but Flink lets you do both with one technology. How did this top-level Apache project get started? Flink has its origins in the Stratosphere project, a research project conducted by three Berlin-based Universities as well as other European Universities between 2010 and 2014. The project had already attracted a broader community base, in part through presentations at several public developer conferences including Berlin Buzzwords, NoSQL Matters in Cologne, and others. This strong community base is one reason the project was appropriate for incubation under the Apache Software Foundation. A fork of the Stratosphere code was donated in April 2014 to the Apache Software Foundation as an incubating project, with an initial set of committers consisting of the core developers of the system. Shortly thereafter, many of the founding committers left university to start a company to commercialize Flink: data Artisans. During incubation, the project name had to be changed from Stratosphere because of potential confusion with an unrelated project. The name Flink was selected to honor the style of this stream and batch processor: in German, the word “flink” means fast or agile. A logo showing a colorful squirrel was chosen because squirrels are fast, agile and — in the case of squirrels in Berlin — an amazing shade of reddish-brown, as you can see in Figure 1-3.
22 . Figure 1-3. Left: Red squirrel in Berlin with spectacular ears. Right: Apache Flink logo with spectacular tail. Its colors reflect that of the Apache Software Foundation logo. It’s an Apache-style squirrel! The project completed incubation quickly, and in December 2014, Flink graduated to become a top-level project of the Apache Software Foundation. Flink is one of the 5 largest big data projects of the Apache Software Foundation, with a community of more than 200 developers across the globe and several production installations, some in Fortune Global 500 companies. At the time of this writing, 34 Apache Flink meetups take place in cities around the world, with approximately 12,000 members and Flink speakers participating at big data conferences. In October 2015, the Flink project held its first annual conference in Berlin: Flink Forward.
23 .Batch and Stream Processing How and why does Flink handle both batch and stream processing? Flink treats batch processing — that is, processing of static and finite data — as a special case of stream processing. The core computational fabric of Flink, labeled “Flink runtime” in Figure 1-4, is a distributed system that accepts streaming dataflow programs and executes them in a fault-tolerant manner in one or more machines. This runtime can run in a cluster, as an application of YARN (Yet Another Resource Negotiator) or soon in a Mesos cluster (under development), or within a single machine, which is very useful for debugging Flink applications. Figure 1-4. This diagram depicts the key components of the Flink stack. Notice that the user-facing layer includes APIs for both stream and batch processing, making Flink a single tool to work with data in either situation. Libraries include machine learning (FlinkML), complex event processing (CEP), and graph processing (Gelly), as well as Table API for stream or batch mode. Programs accepted by the runtime are very powerful, but are verbose and difficult to program directly. For that reason, Flink offers developer-friendly APIs that layer on top of the runtime and generate these streaming dataflow programs. There is the DataStream API for stream processing and a DataSet API for batch processing. It is interesting to note that,
24 .although the runtime of Flink was always based on streams, the DataSet API predates the DataStream API, as the industry need for processing infinite streams was not as widespread in the first Flink years. The DataStream API is a fluent API for defining analytics on possibly infinite data streams. The API is available in Java or Scala. Users work with a data structure called DataStream, which represents distributed, possibly infinite streams. Flink is distributed in the sense that it can run on hundreds or thousands of machines, distributing a large computation in small chunks, with each machine executing one chunk. The Flink framework automatically takes care of correctly restoring the computation in the event of machine and other failures, or intentional reprocessing, as in the case of bug fixes or version upgrades. This capability alleviates the need for the programmer to worry about failures. Flink internally uses fault-tolerant streaming data flows, allowing developers to analyze never-ending streams of data that are continuously produced (stream processing). NOT E Because Flink handles many issues of concern, such as exactly-once guarantees and data windows based in event time, developers no longer need to accommodate these in the application layer. That style leads to fewer bugs. Teams get the best out of their engineers’ time because they aren’t burdened by having to take care of problems in their application code. This benefit not only affects development time, it also improves quality through flexibility and makes operations easier to carry out efficiently. Flink provides a robust way for an application to perform well in production. This is not just theory — despite being a relatively new project, Flink software is already being used in production, as we will see in the next section.
25 .Flink in Production This chapter raises the question, “Why Apache Flink?” One good way to answer that is to hear what people using Flink in production have to say about why they chose it and what they’re using it for.
26 .Bouygues Telecom Bouygues Telecom is the third-largest mobile provider in France and is part of the Bouygues Group, which ranks in Fortune’s “Global 500.” Bouygues uses Flink for real-time event processing and analytics for billions of messages per day in a system that is running 24/7. In a June 2015 post by Mohamed Amine Abdessemed, on the data Artisans blog, a representative from Bouygues described the company’s project goals and why it chose Flink to meet them. Bouygues “...ended up with Flink because the system supports true streaming — both at the API and at the runtime level, giving us the programmability and low latency that we were looking for. In addition, we were able to get our system up and running with Flink in a fraction of the time compared to other solutions, which resulted in more available developer resources for expanding the business logic in the system.” This work was also reported at the Flink Forward conference in October 2015. Bouygues wanted to give its engineers real-time insights about customer experience, what is happening globally on the network, and what is happening in terms of network evolutions and operations. To do this, its team built a system to analyze network equipment logs to identify indicators of the quality of user experience. The system handles 2 billion events per day (500,000 events per second) with a required end-to-end latency of less than 200 milliseconds (including message publication by the transport layer and data processing in Flink). This was achieved on a small cluster reported to be only 10 nodes with 1 gigabyte of memory each. Bouygues also wanted other groups to be able to reuse partially processed data for a variety of business intelligence (BI) purposes, without interfering with one another. The company’s plan was to use Flink’s stream processing to transform and enrich data. The derived stream data would then be pushed back to the message transport system to make this data available for analytics by multiple consumers. This approach was chosen explicitly instead of other design options, such as processing the data before it enters the message queue, or delegating the processing to multiple applications that consume from the message queue. Flink’s stream processing capability allowed the Bouygues team to complete the data processing and movement pipeline while meeting the latency requirement and with high reliability, high availability, and ease of use. The Flink framework, for instance, is ideal for debugging, and it can be switched to local execution. Flink also supports program visualization to help understand how programs are running. Furthermore, the Flink APIs are attractive to both developers and data scientists. In Mohamed Amine Abdessemed’s blog post, Bouygues reported interest in Flink by other teams for different use cases.
27 .Other Examples of Apache Flink in Production King.com It’s a pretty fair assumption that right now someone, in some place in the world, is playing a King game online. This leading online entertainment company states that it has developed more than 200 games, offered in more than 200 countries and regions. As the King engineers describe: “With over 300 million monthly unique users and over 30 billion events received every day from the different games and systems, any stream analytics use case becomes a real technical challenge. It is crucial for our business to develop tools for our data analysts that can handle these massive data streams while keeping maximal flexibility for their applications.” The system that the company built using Apache Flink allows data scientists at King to get access in these massive data streams in real time. They state that they are impressed by Apache Flink’s level of maturity. Even with such a complex application as this online game case, Flink is able to address the solution almost out of the box. Zalando As a leading online fashion platform in Europe, Zalando has more than 16 million customers worldwide. On its website, it describes the company as working with “...small, agile, autonomous teams” (another way to say this is that they employ a microservices style of architecture). A stream-based architecture nicely supports a microservices approach, and Flink provides stream processing that is needed for this type of work, in particular for business process monitoring and continuous Extract, Transform and Load (ETL) in Zalando’s use case. Otto Group The Otto Group is the world’s second-largest online retailer in the end-consumer (B2C) business, and Europe’s largest online retailer in the B2C fashion and lifestyle business. The BI department of the Otto Group had resorted to developing its own streaming engine, because when it first evaluated the open source options, it could not find one that fit its requirements. After testing Flink, the department found it fit their needs for stream processing, which include crowd-sourced user-agent identification, and a search session identifier. ResearchGate ResearchGate is the largest academic social network in terms of active users. ResearchGate has adopted Flink in production since 2014, using it as one of its primary tools in the data infrastructure for both batch and stream processing.
28 .Alibaba Group This huge ecommerce group works with buyers and suppliers via its web portal. The company’s online recommendations are produced by a variation of Flink (called Blink). One of the attractions of working with a true streaming engine such as Flink is that purchases that are being made during the day can be taken into account when recommending products to users. This is particularly important on special days (holidays) when the activity is unusually high. This is an example of a use case where efficient stream processing is a big advantage over batch processing.
29 .Where Flink Fits We began this chapter with the question, “Why Flink?” A larger question, of course, is, “Why work with streaming data?” We’ve touched on the answer to that — many of the situations we want to observe and analyze involve data from continuous events. Rather than being something special, streaming data is in many situations what is natural — it’s just that in the past we’ve had to devise clever compromises to work with it in a somewhat artificial way, as batches, in order to meet the demands posed by handling data and computation at very large scale. It’s not that working with streaming data is entirely new; it’s that we have new technologies that enable us to do this at larger scale, more flexibly, and in a natural and more affordable way than before. Flink isn’t the only technology available to work with stream processing. There are a number of emerging technologies being developed and improved to address these needs. Obviously people choose to work with a particular technology for a variety of reasons, including existing expertise within their teams. But the strengths of Flink, the ease of working with it, and the wide range of ways it can be used to advantage make it an attractive option. That along with a growing and energetic community says that it is probably worth examination. You may find that the answer to “Why Flink?” turns out to be, “Why not Flink?” Before we look in more detail at how Flink works, in Chapter 2 we will explore how to design data architecture to get the best advantage from stream processing and, indeed, how a stream-first architecture provides more far-reaching benefits.
3秒后跳转登录页面
去登陆

