展开查看详情
1 .Columnar Execution for Apache Flink Batch
ݪلғᴨ᯾૬૬
ᘳ֖ғᦇᓒଘݣԪӱ᮱ᩒႮӫਹ
ᄍᦖᘏғᎪชพ
�
2 . About me
- Senior Staff Engineer in Alibaba MaxCompute
- Committer of Apache Drill
- Interests cover cloud infrastructure, security, big
data
- Github ID: chunhui-shi
�
3 .Content >ٖ@
- Background and Literature of vectorization >ڜୗಗᤈጱᙧว@�
- Vectorized Data Format >ڜୗහഝ໒ୗ@
- Results and Future >පຎ݊๚ᦇ@ښ
�
4 .Batch SQL in Flink >ሿࣁጱ batch SQL@
- No cost based optimizer to find physical plan
>ဌํֵአचԭcostጱս۸ᦇᓒᇔቘಗᤈᦇ@ښ
- Row based >चԭᤈጱ@
- On top of Dataset API[चԭDataset API]
�
5 . Motivations
• Two widely used techniques in SQL engines:
Code-gen & vectorization
Systems for vectorization: DB2 BLU, columnar SQL Server, VectorWise
Systems for code-gen: Spark, Peloton, Hyper
• Which is a better design choice?
The answer is obscured by implementation details: compressions,
predicate pushdown, parallelism framework, thread model, etc.
�
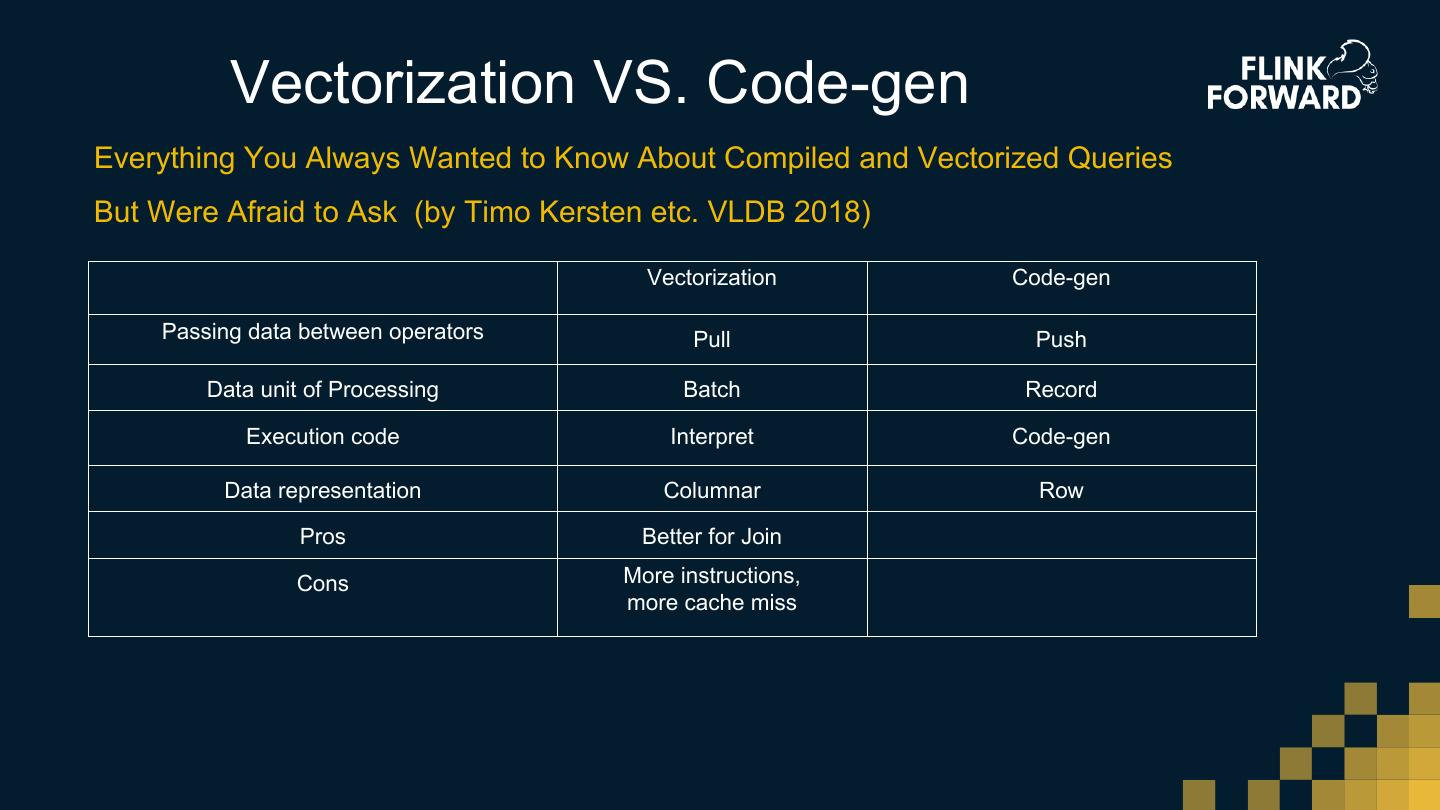
6 . Vectorization VS. Code-gen
Everything You Always Wanted to Know About Compiled and Vectorized Queries
But Were Afraid to Ask (by Timo Kersten etc. VLDB 2018)
Vectorization Code-gen
Passing data between operators Pull Push
Data unit of Processing Batch Record
Execution code Interpret Code-gen
Data representation Columnar Row
Pros Better for Join
Cons More instructions,
more cache miss
�
7 .Vectorization vs. Code-gen: What is missing
• Execution engine is in JVM
• UDF in multiple languages (Python, Java, Javascript)
• Multiple/alternative Execution Engines (GPU, FPGA, native, JVM)
• CPU cache size obeys Moore's law in last ten years (L2: 256KB –> 16MB: 1MB per core, L3:
3MB –> 24MB)
�
8 .Vectorized Execution in MaxCompute 2.0
• In big data scenarios, the most popular data formats are columnar: parquet, ORC,
Carbondata, etc.
• Alibaba develops AliORC and contributes more than 10,000 lines back to community.
• MaxCompute operates on columnar layout
since the first time data come into memory.
�
9 .Batch: Flink vs Spark
• Community version is not comparable. Fundamental refactoring is required:
• Compiler: Queries won’t be compiled to Dataset API, but will convert to StreamOperators
• Optimizer: improvement: Apply Calcite to generate physical plan
• Execution Engine improvements: Vectorized layout, batch execution
�
10 .Vectorized Execution Engine Design
• In memory layout: off-heap vs on-heap
• Extensions to StreamOperator interface
• Vectorized expression Evaluation
• Vectorization specific Improvements
�
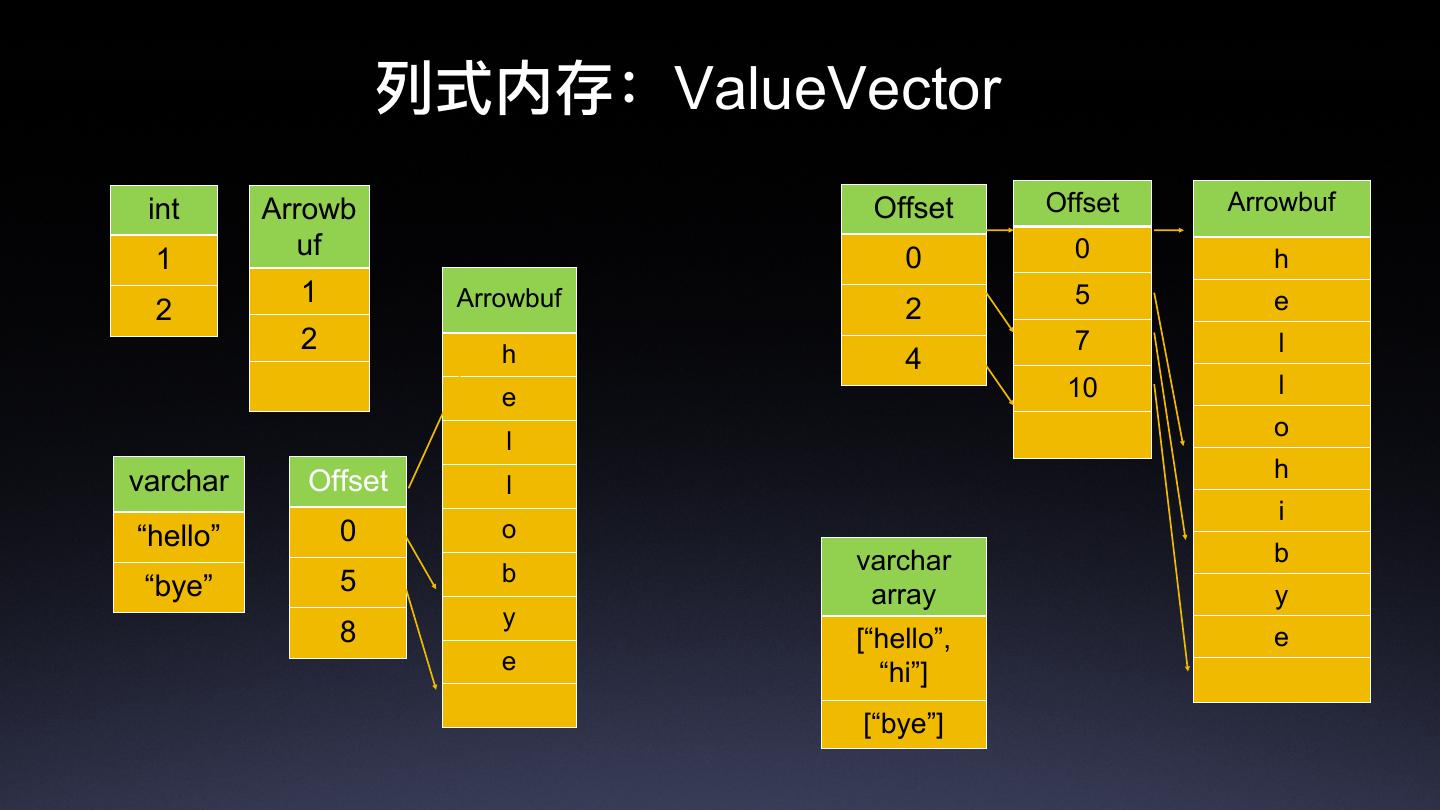
11 . ڜୗٖਂғValueVector
int Arrowb Offset Offset Arrowbuf
1 uf 0 0 h
1 Arrowbuf 5 e
2 2
2 h 7 l
4
e 10 l
o
l
varchar Offset h
l
i
“hello” 0 o
varchar b
5 b
“bye” array y
y
8 [“hello”, e
e “hi”]
[“bye”]
�
12 . Enhancements to Arrow Library
• Support both off-heap and on-heap vectors.
• Optimize buffer access to vectors: remove extra function calls and checks in Arrow library.
�
13 . Selection Vector Enhancement
• Compact and Sparse Selection Vector
{1, 7, 23, 1024}
{1,-1, -1, 4, …}
• Allow selection vector to be passed and used in next operators.
�
14 . Lazy evaluation of vectorized expression
• Introduce ‘Virtual Vector’ in batch that has not been materialized
The vector carries only the expression and required vectors.
• Materialize only when needed in serialization or evaluation.
�
15 . Interface extended to StreamOperator
• Added interfaces, abstract classes to StreamOperator
�
16 . Performance and resource gain
• TPCH benchmark improvements
Achieve significant time reduce comparing with the best number a row based
batch implementation running on the same cluster.
• Less resource consumption
Memory, network consumption are saved since the data is transferred and handled in
batch.
�
17 . Future of this vectorized execution engine
• Vectorized and Arrow based data layout makes it easy to interact with multiple languages
• Native implementation of operators and expression evaluation
- LLVM codegen for expression (Gandiva initiative from Arrow)
• Vectorized UDF framework: Python first!
�