






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
大数据时间简史
大数据发展的过程中出现Mapreduce、Hadoop、Flink等技术,每个技术都有它优缺点,作为最新的大数据技术框架,Apache Flink同时具备流式处理和批量数据处理的特征,本文介绍在这些年来这些大数据技术的演变和特点,特别是Flink如何解决早期框架的弊端 。
展开查看详情
1 .⼤大数据的时间简史 为什什么Flink正在成为下⼀一代⼤大数据计算引擎 巴真 @Flink China Meetup
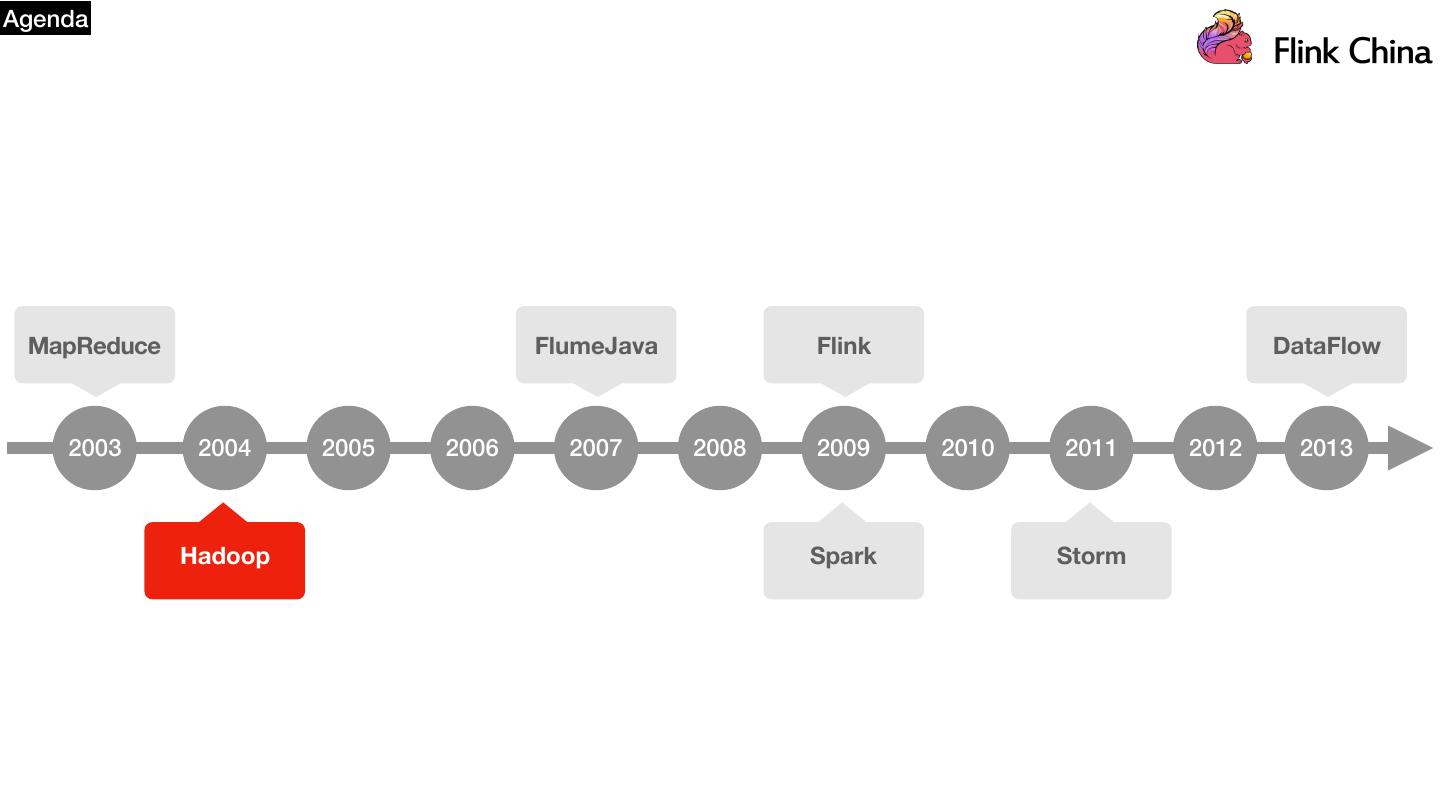
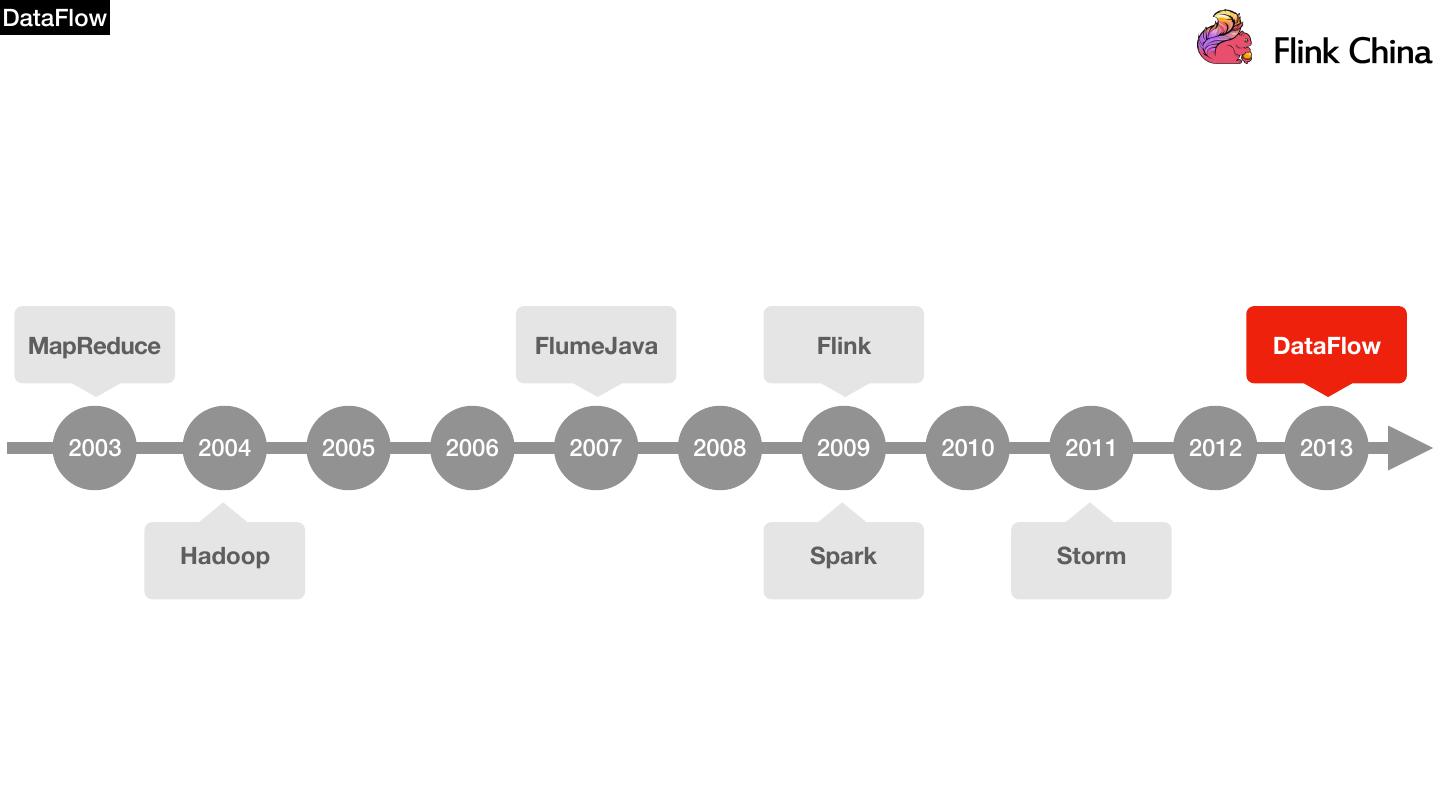
2 .Agenda MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
3 .史前时代 Database DataWarehouse
4 .⼤大数据爆发 IT化 ⽹网络化 移动化 万物互联
5 .⾯面临问题 Process Scalability Fault-Tolerance
6 .MapReduce MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
7 .MapReduce 《MapReduce: Simplied Data Processing on Large Clusters》 Google 此URL需翻墙
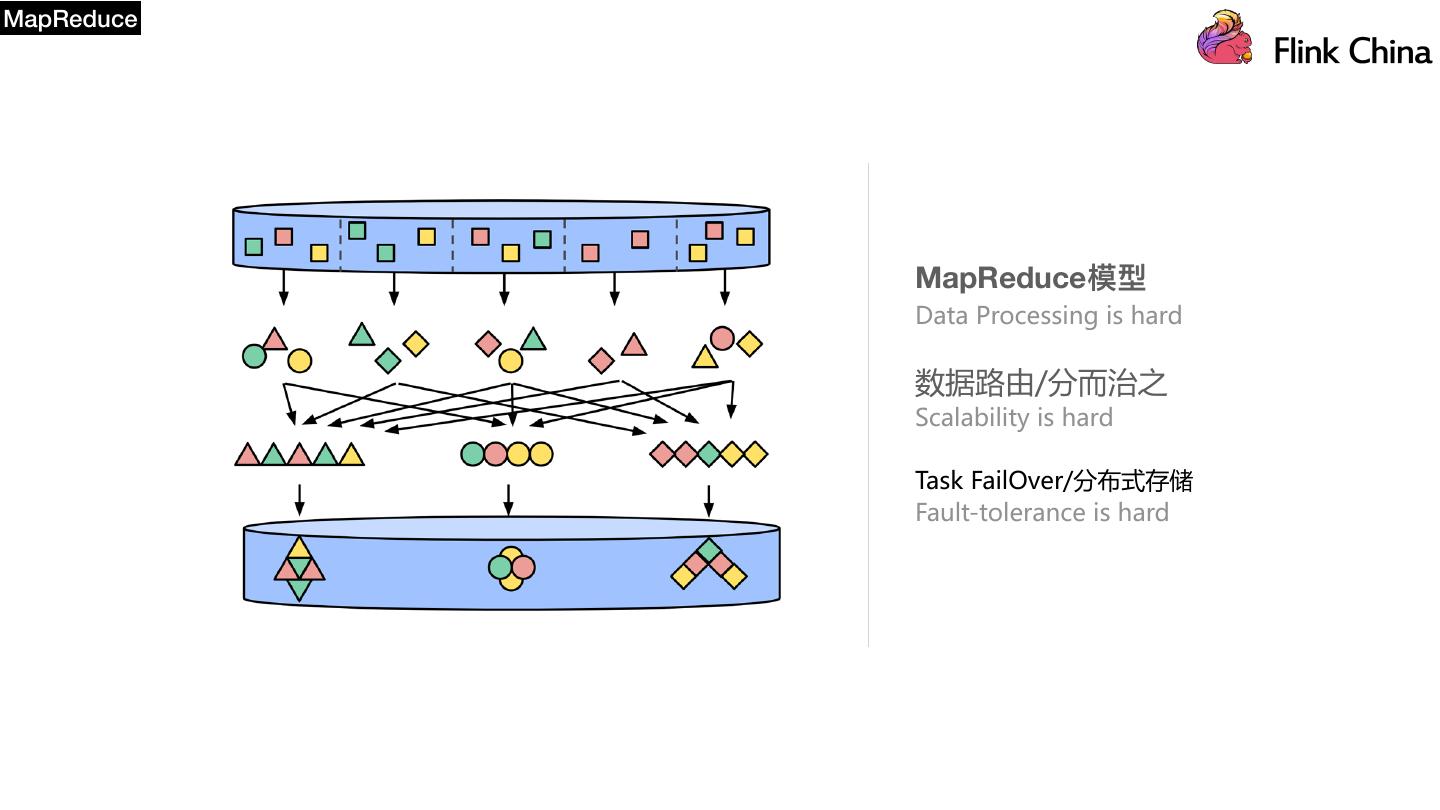
8 .MapReduce MapReduce模型 Data Processing is hard 数据路由/分而治之 Scalability is hard Task FailOver/分布式存储 Fault-tolerance is hard
9 .MapReduce 《MapReduce: A major step backwards》 David DeWitt 所谓⼤大数据: 互联⽹网⾏行行业快糙猛地解决⼤大规模数据处理理问题 为什么Google video做不过Youtube? / 如何快速拿到明星代言? 所谓退步: 是互联⽹网⼯工程的妥协/Tradeoff Database -> NoSQL/NewSQL Queue -> Kafka/Kinesis/RocketMQ
10 .Agenda MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
11 .Hadoop Hadoop Official Site http://hadoop.apache.org/ 互联⽹网再⼀一次⼭山寨了了⼭山寨品 Hadoop折扣实现了大量Google的Paper,包括调度、存储。 技术生态圈再次被开源占据,各个领域开源系统日益成为工业标准。
12 .Hadoop HasS巨大的市场机会,全球HaaS市场到2020是50B,约3300亿,中国HaaS市场到2020是578亿 开源商业化版本对于企业化客户接受度高,超过50%。 非开源不用! 企业用户采购大数据系统只认可开源大数据 50%+企业首选使用开源软件企业版本服务。
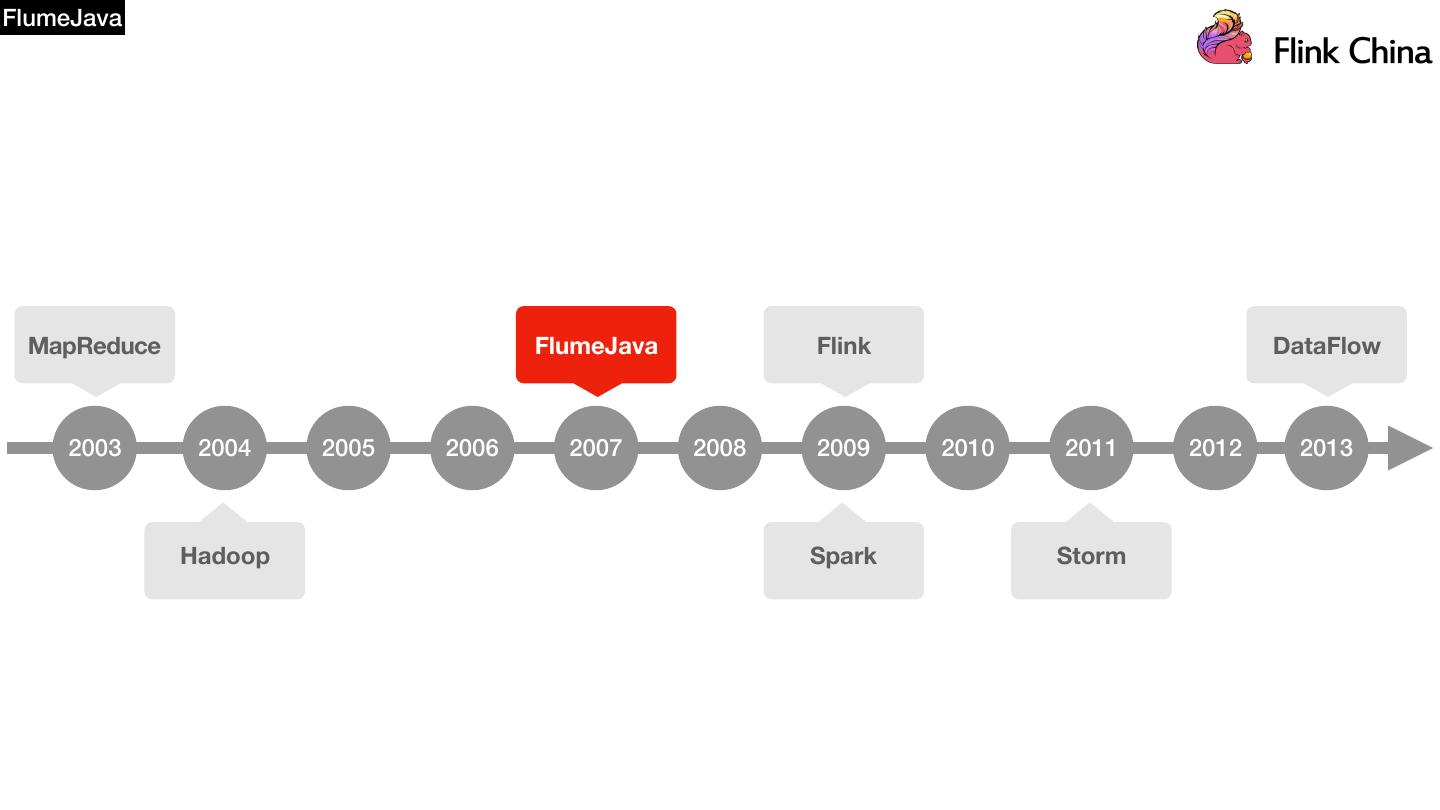
13 .FlumeJava MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
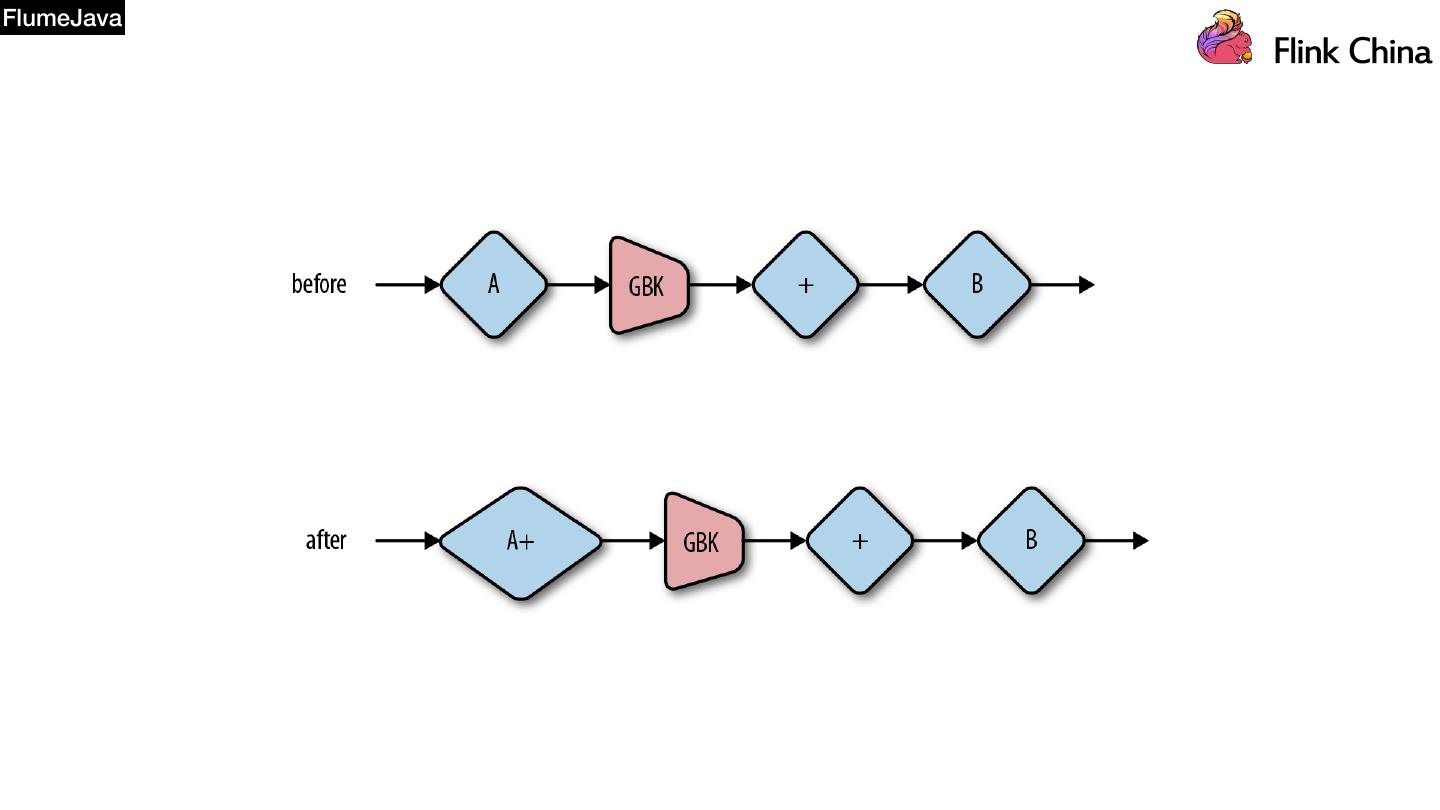
14 .FlumeJava MapReduce抽象层次太低,导致 1. 业务实现困难,复杂业务动辄上万行代码 2. 系统优化困难,黑盒导致框架无法优化
15 .FlumeJava WordCount Job count sink source split Scalability count sink source split count sink source split count sink Complexity
16 .FlumeJava
17 .FlumeJava
18 .FlumeJava
19 .FlumeJava 《Flume Java: Easy, Efficient Data-Parallel Pipelines》 FlumeJava有效解决MR抽象层次太低的问题 1. 业务可以使用较少量的代码实现曾经MR成千上万行代码 2. 系统可以根据用户的业务CODE实现优化 此URL需翻墙
20 .Storm MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
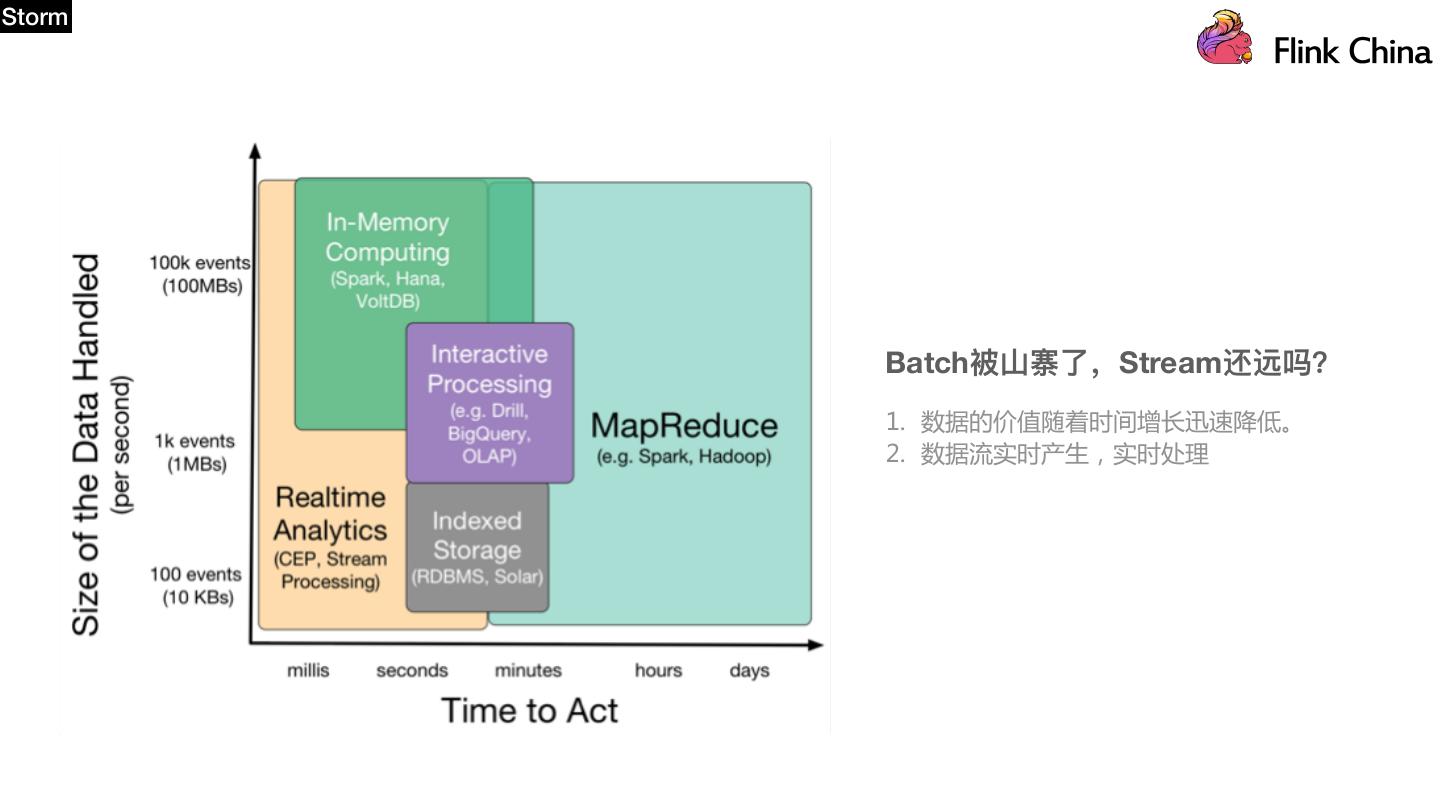
21 .Storm Batch被⼭山寨了了,Stream还远吗? 1. 数据的价值随着时间增长迅速降低。 2. 数据流实时产生,实时处理
22 .Storm Apache Hadoop Apache Storm
23 .Storm Flink: 下⼀一代流式处理理系统 ——为什什么Flink要⽐比Storm/Spark更更加优秀?
24 .Spark MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
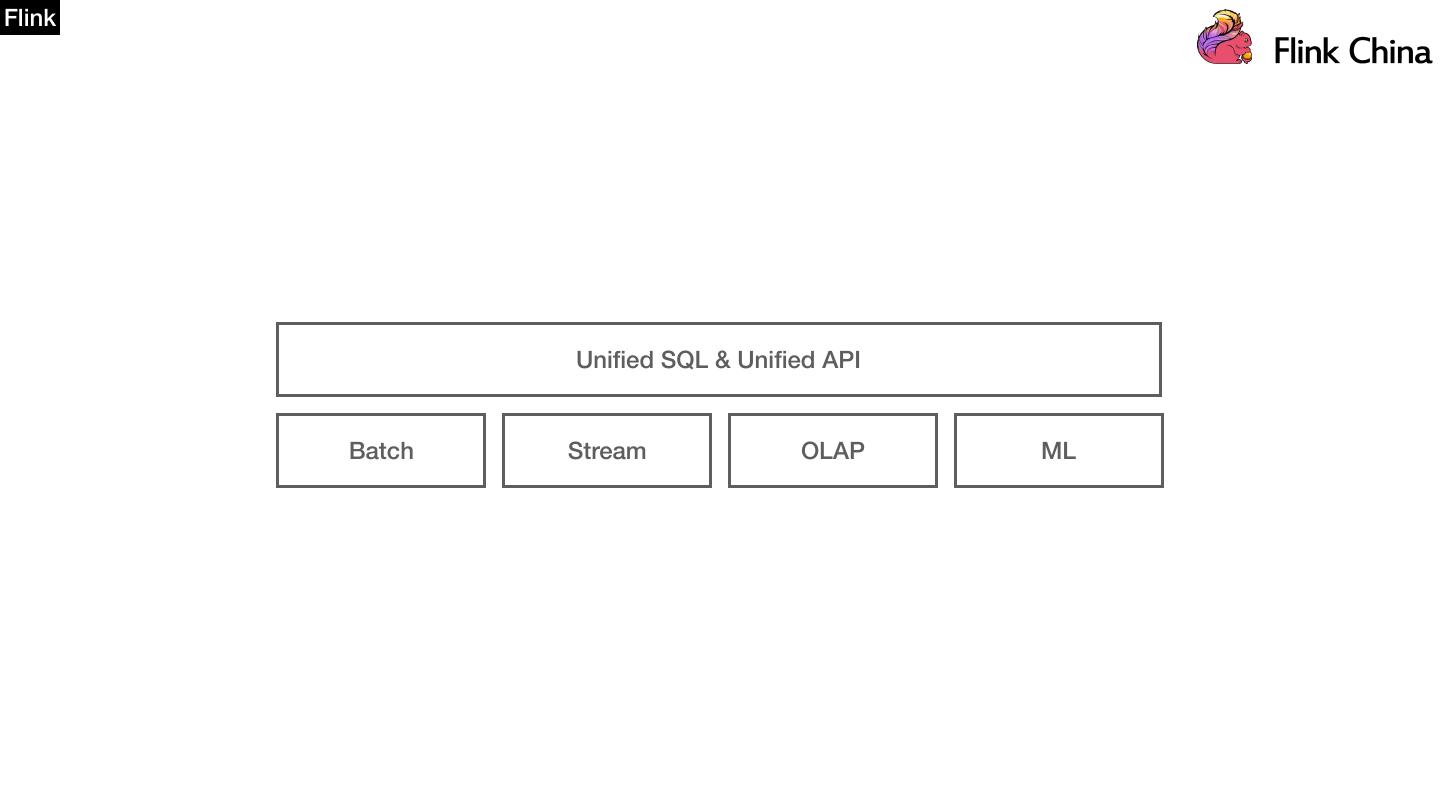
25 .Spark 《An Architecture for Fast and General Data Processing on Large Clusters》 涵盖⼤大数据⼊入⼝口处理理业务的⼀一站式⼤大数据计算引擎 1. 1/3的社区调查用户认为一套引擎解决大部分问题是Spark重要优势 2. Spark是Hadoop/Storm的下一代大数据处理引擎
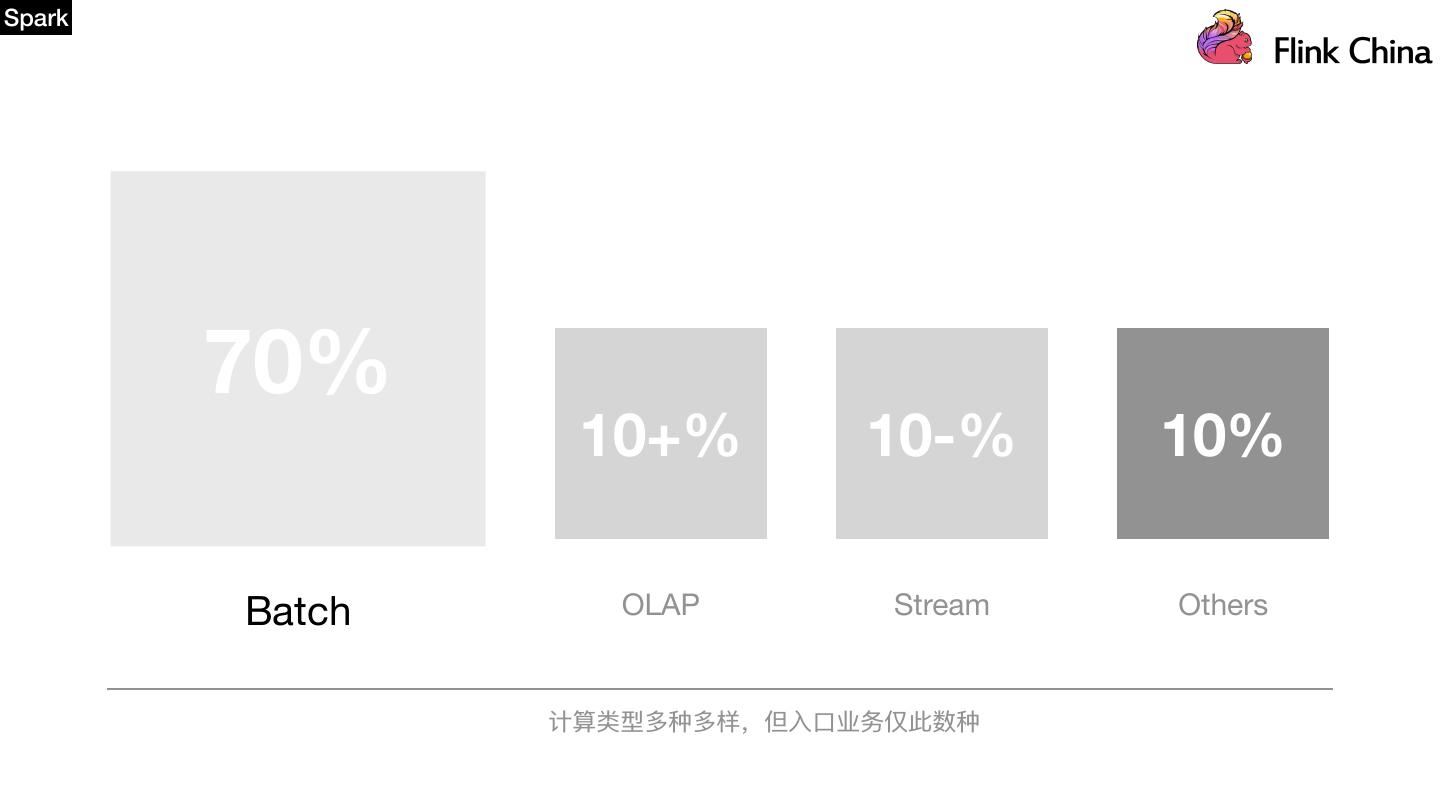
26 .Spark 70% 10+% 10-% 10% Batch OLAP Stream Others 计算类型多种多样,但⼊入⼝口业务仅此数种
27 .Spark Spark Spark优势明显 Flink 功能完备: Batch/Stream/ML 简单易用: API丰富/文档较丰富/生态对接 社区活跃: 运营出彩、大数据最活跃社区 DataFlow 云产品系列 产品化: 产品化成熟,易于上手 Kinesis Redshift Presto 稳定性: 稳定性好,商业托管 Impala 社区小: 产品封闭,不易形成社区 StreamAnalytics Storm hive 开源软件 社区活跃: 产品开放,易于形成社区 稳定性差: Bug多,不稳定 产品粗糙: 产品化初级,上手较难
28 .Spark Spark期望一套软件覆盖主要计算模型,但实际覆盖不完整 21%用户认为Spark Streaming在功能(集中在窗口)和时延(亚秒)等比不上Flink,增量流 式业务考虑使用Flink 17%用户认为Spark ML部分落后,包括提供更多算法、对接TF,部分业务迁移到TF框架 运行 25%的用户认为当前缺乏好用、内置的上层平台,包括开发界面、工作流调度,用户使 用Spark同样需要重新搭建平台系统 稳定性/调优/排错 仍未解决 31% 用户吐槽Spark集群不稳定,经常性OOM导致业务产出不稳定 另外,几乎同样客户群体(说明都是深入生产使用Spark用户)都认为Spark作业排错、调 优困难,易用性不够 中文资料/社区严重缺乏,未能形成有效组织 30%用户吐槽当前文档、案例过少,特别在调优、排错方面,用户往往不知所措 用户同时认为相关中文资料相比更少,时效性也落后英文社区太多 中美语言差异导致中国市场更加空白
29 .DataFlow MapReduce FlumeJava Flink DataFlow 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 Hadoop Spark Storm
3秒后跳转登录页面
去登陆

