1 . 2022 T3出行基于DolphinScheduler和Kylin 自动构建指标模型的实践 郑平贺 2022.8.13
2 . 01 为什么要实现模型管理自动化 02 湖仓一体架构下的自动化模型管理设计 目录 CONTENTS 03 自动化模型管理的实现 04 未来展望
3 .PART 01为什么要实现模型管理自动化 第一部分
4 .湖仓一体架构 Kylin
5 .统一指标平台 为了统一各部门间指标名称、定义、统计口径、 计算方法,减少沟通成本,提高沟通效率。
6 .统一指标平台-看板
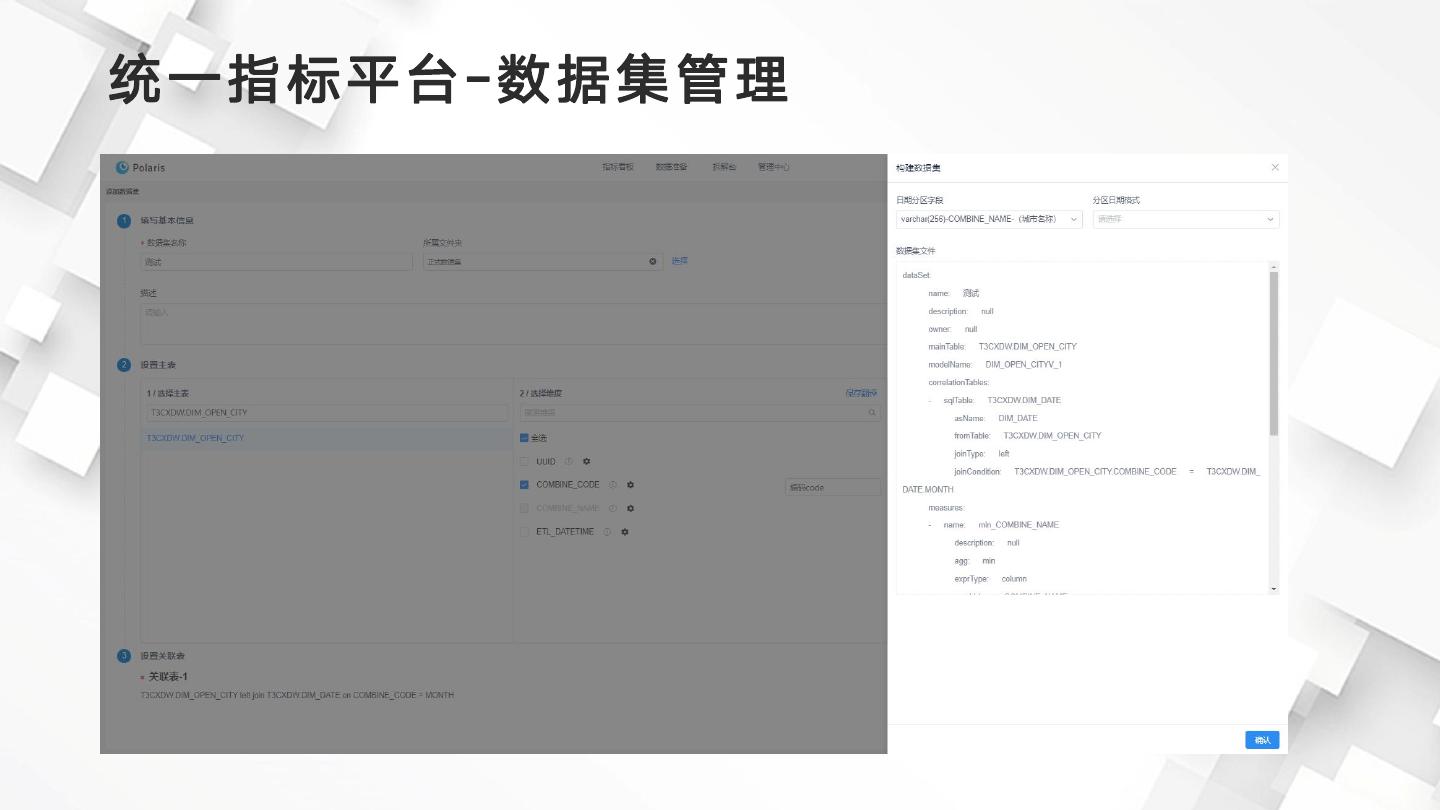
7 .统一指标平台-数据集管理
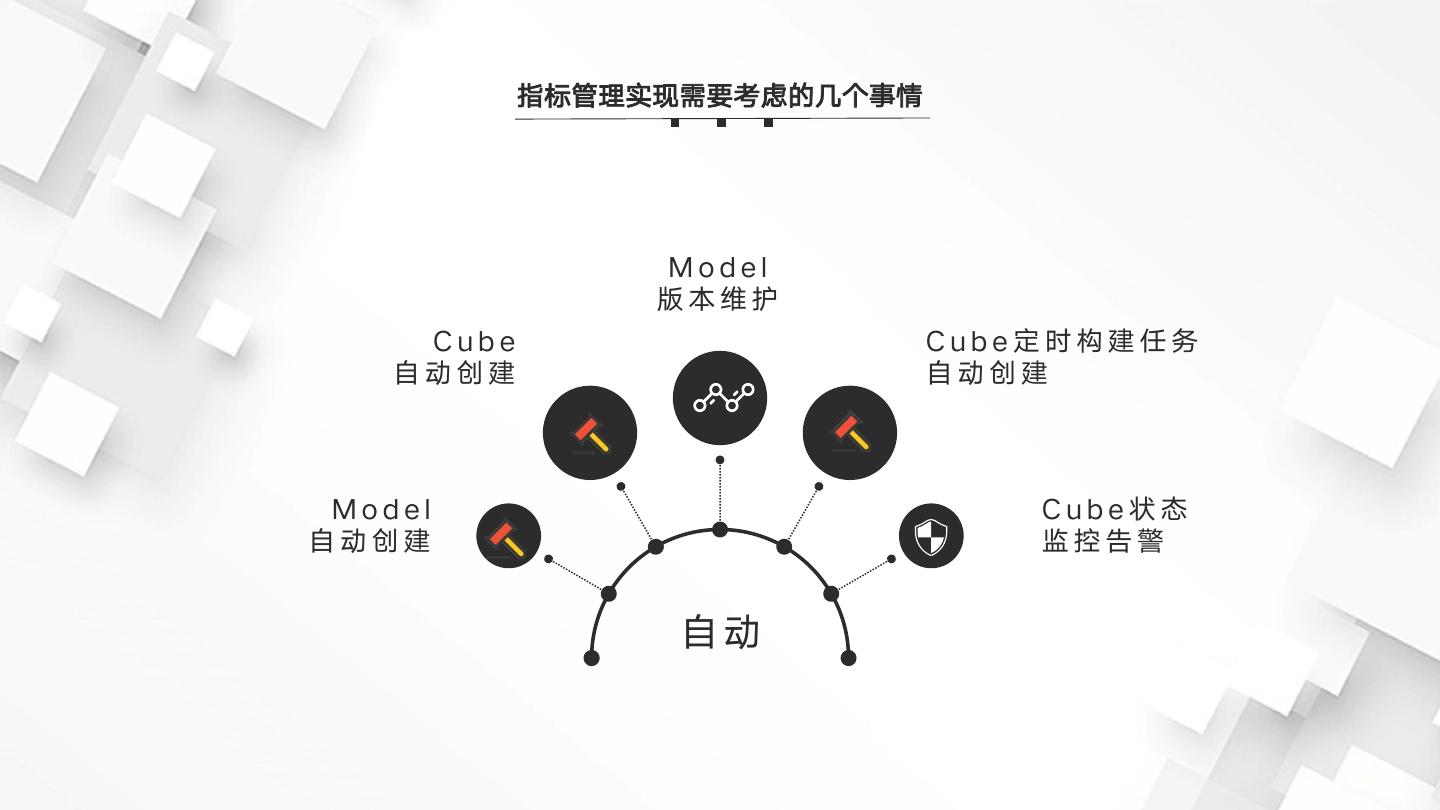
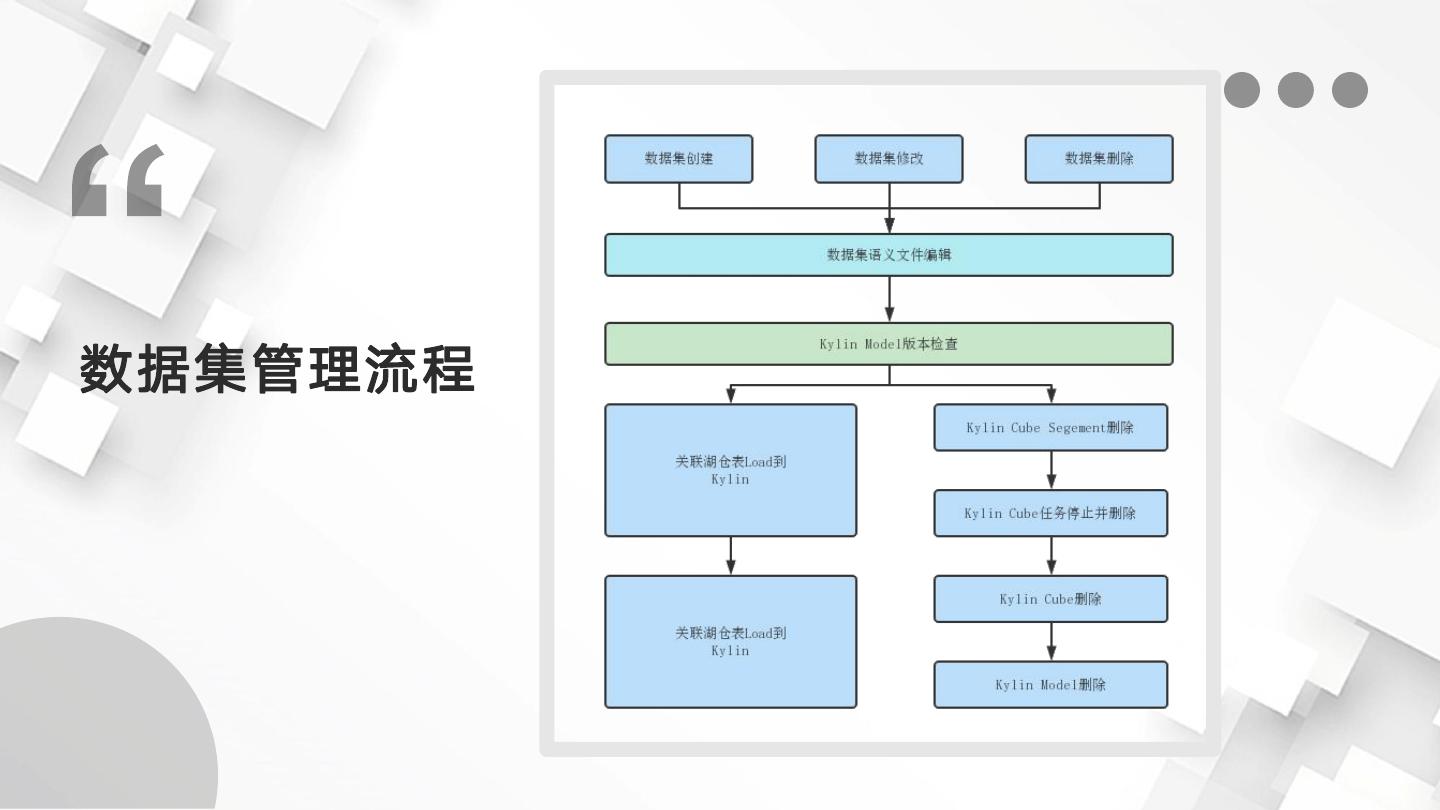
8 . 为什么要实现指标模型管理自动化 统一指标平台主要包括了数据集管理,指标管理,公式拆解,指标看板,驾驶舱以 及监控任务监控等,在自动化管理上主要涉及到对数据集和引擎模型的自动打通管理。 指标模型主要指指标所依赖的数据集,在配置指标之前,需要提前构建好数据集,包 括:模型所依赖事实表、维表、维度字段、度量字段配置 使用Kylin作为引擎底座,涉及到Cube的构建,Cube所关联的维度字段和度量字段 以及度量的聚合方式的配置,Fact表构建以及Cube构建调度策略配置 使用DolphinScheduler作为Fact表加工以及Cube构建
9 . 湖仓一体架构下的自动化模型 PART 02 管理设计 第二部分
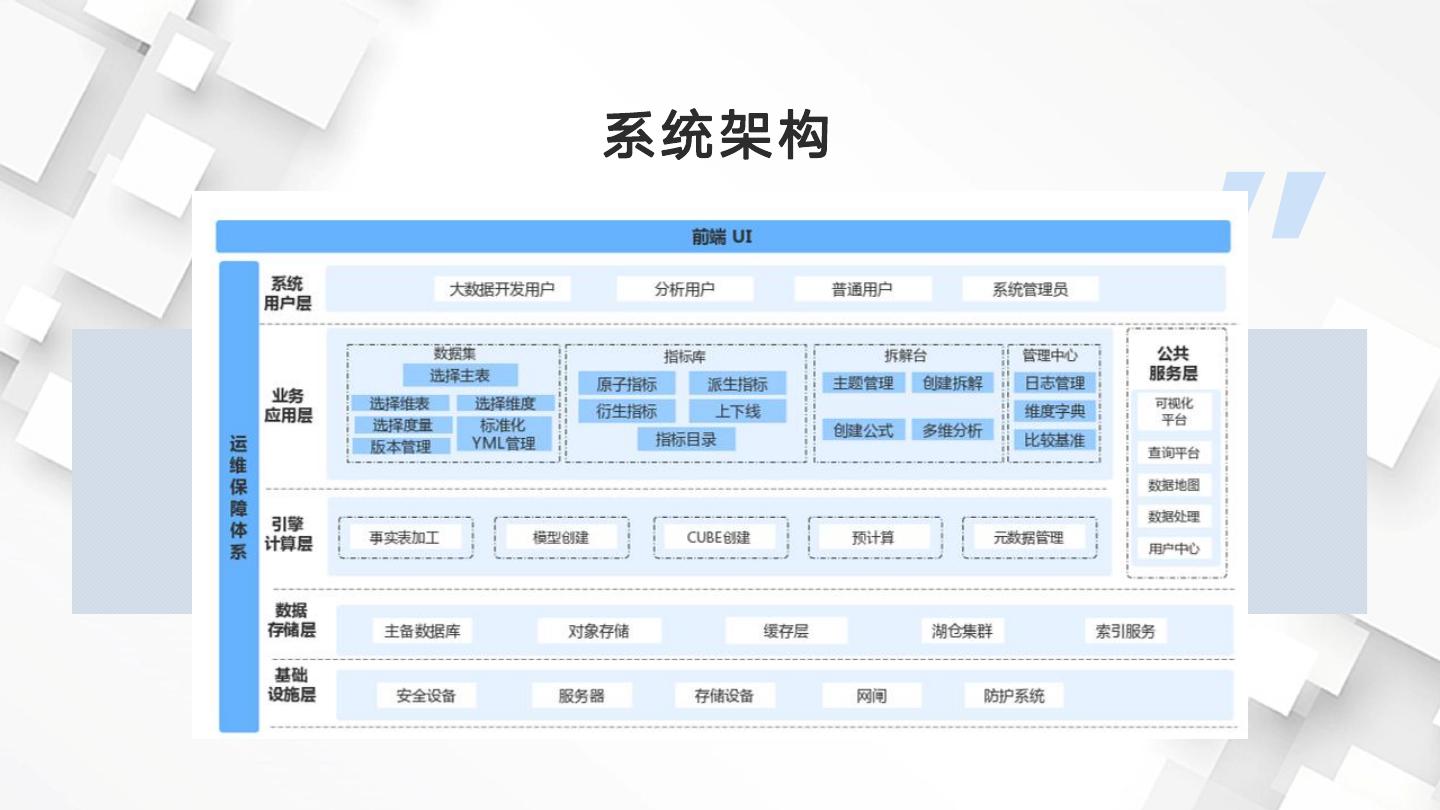
10 .系统架构
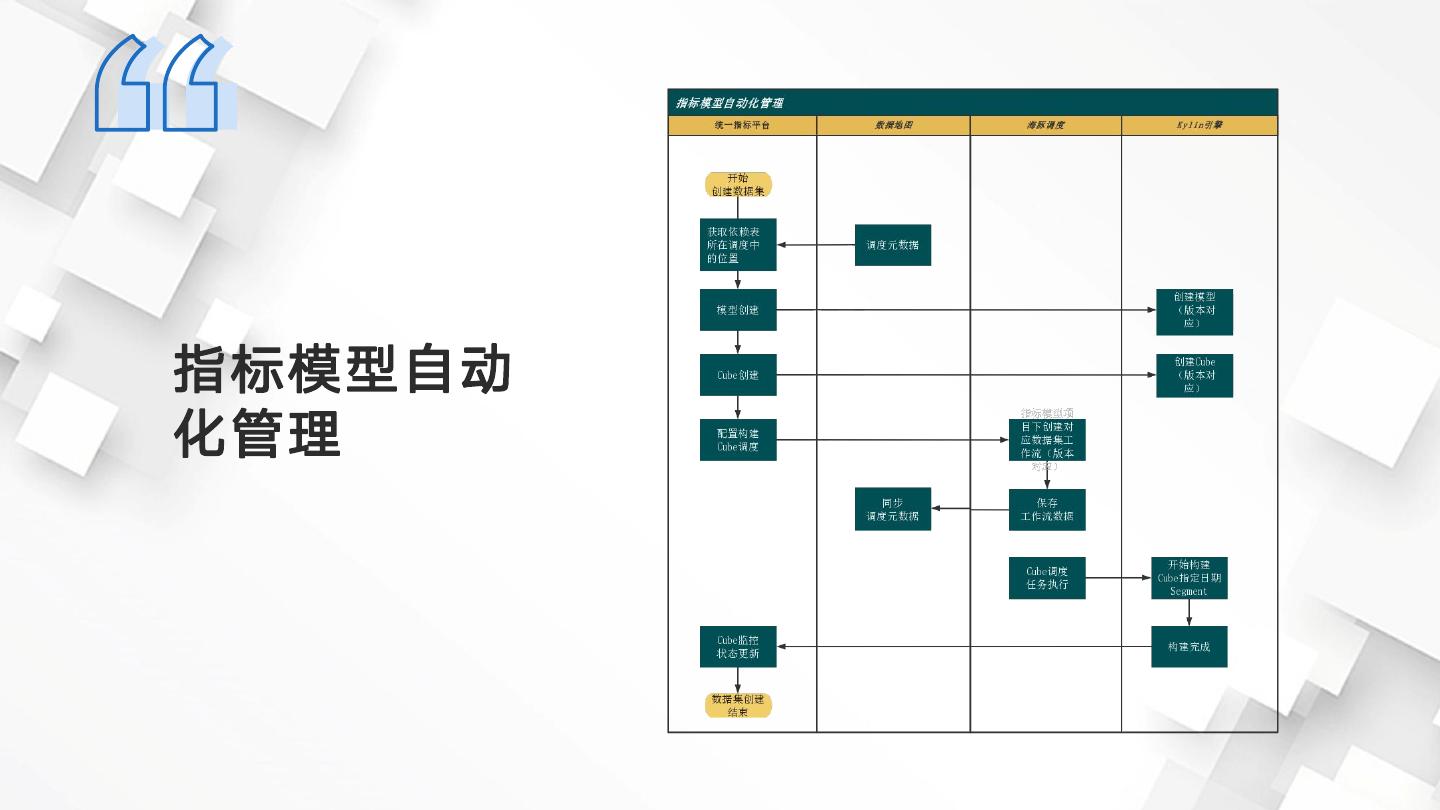
11 .指标模型自动 化管理
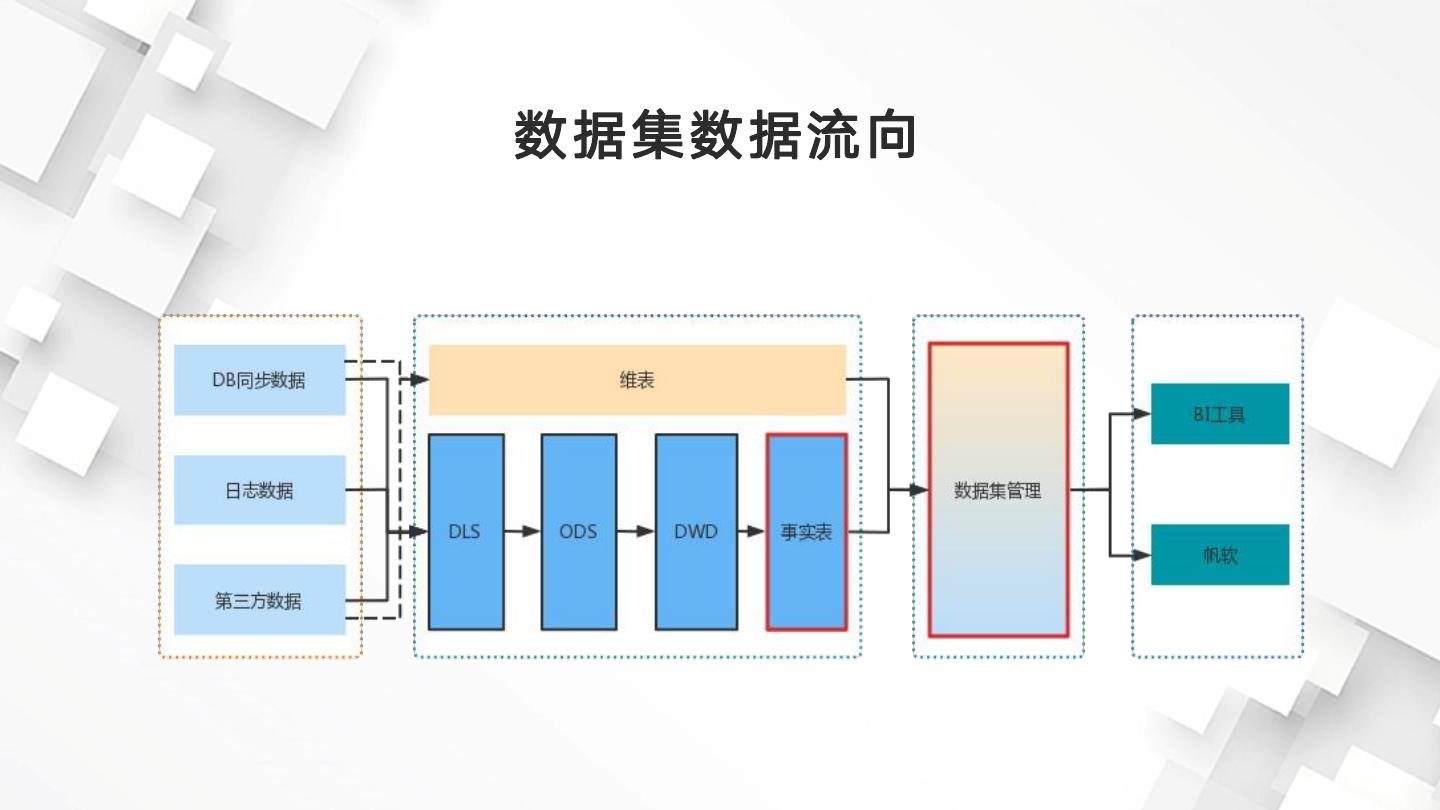
12 .数据集数据流向
13 .PART 03 自动化模型管理的实现 第三部分
14 . 指标管理实现需要考虑的几个事情 Model 版本维护 Cube Cube定时构建任务 自动创建 自动创建 Model Cube状态 自动创建 监控告警 自动
15 .数据集管理流程
16 .Kylin模型管理实现
17 .Kylin Cube管理实现
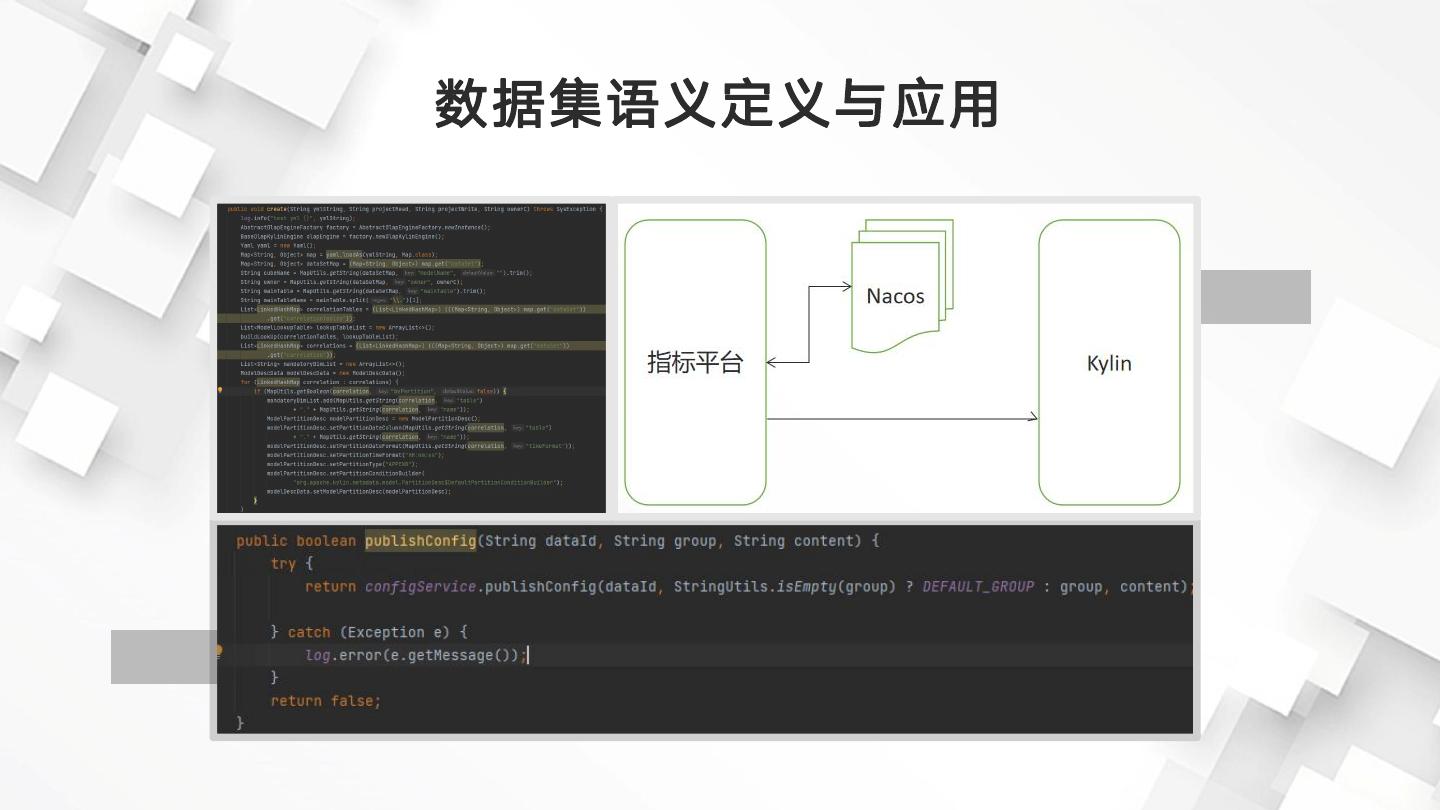
18 .数据集语义定义与应用
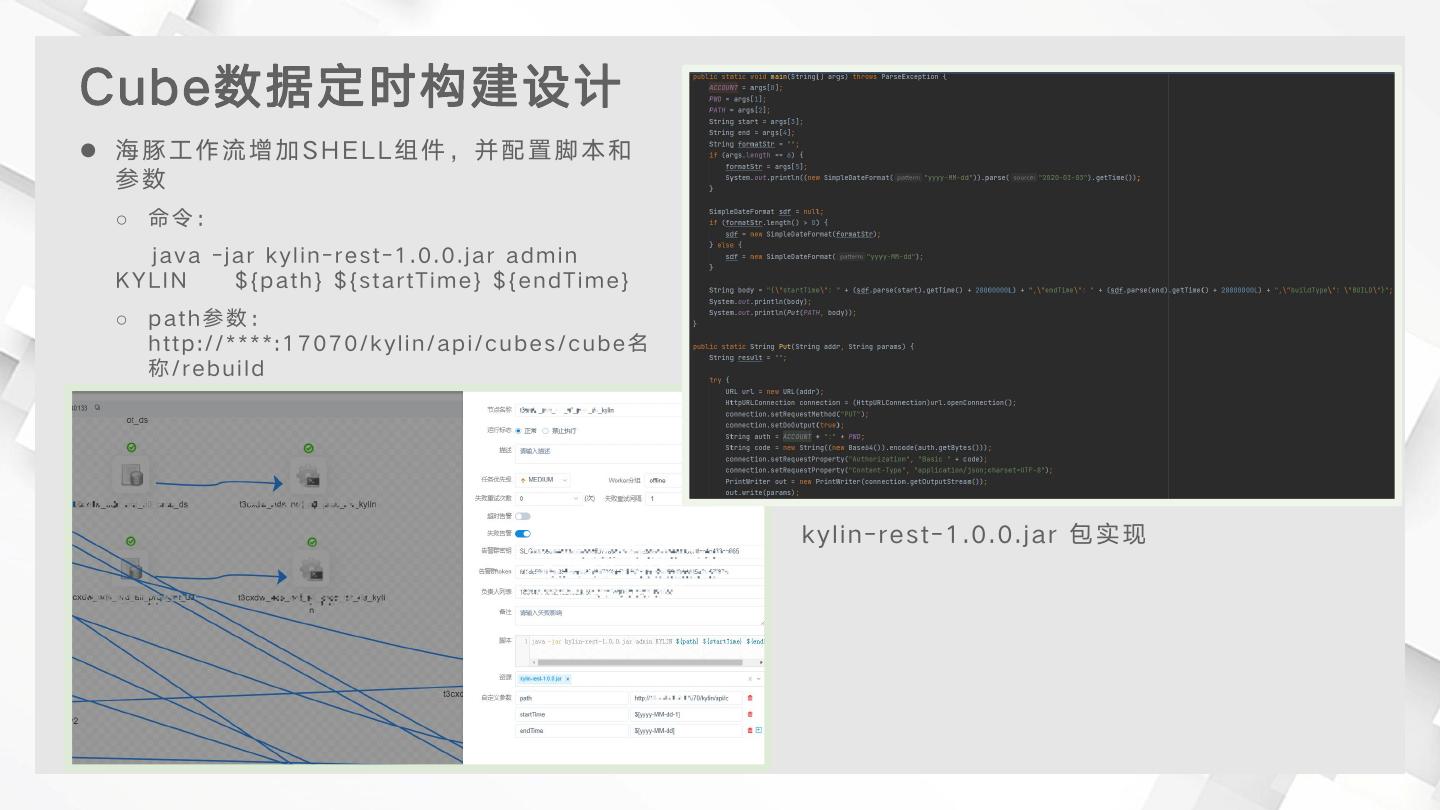
19 .Cube数据定时构建设计
20 .Cube数据定时构建设计 海豚工作流增加SHELL组件,并配置脚本和 参数 ○ 命令: java -jar kylin-rest-1.0.0.jar admin KYLIN ${path} ${startTime} ${endTime} ○ path参数: http://****:17070/kylin/api/cubes/cube名 称/rebuild kylin-rest-1.0.0.jar 包实现
21 .PART 04未来展望 第四部分
22 . 未来展望 包括湖仓加工表所属项目, 使用在数据地图上的海豚信息, 所属工作流,工作流定时信 可自动实现Cube任务在海豚 Kylin跨项目cube名称不可 息,实例负责人,跨项目实 上构建依赖,确保构建cube 重复构建问题和实时指标兼 例血缘,告警信息,任务执 数据时候,上游依赖表已成功 容性。 行状态等 执行。 数据地图采集海豚元信息 Cube构建任务与数据地图打通 结合Kylin版本问修复迭代
23 .感谢收看
确定删除吗?