






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
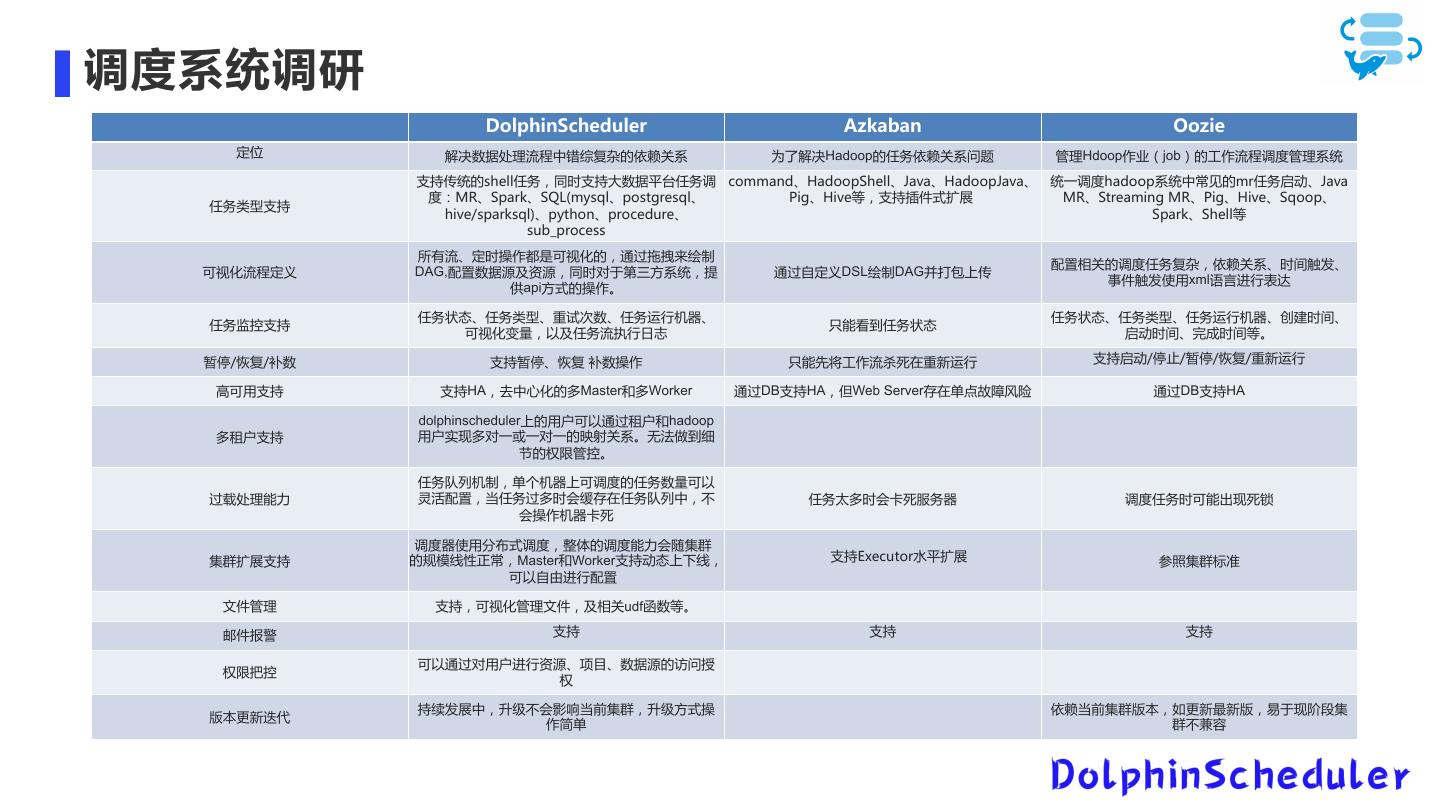
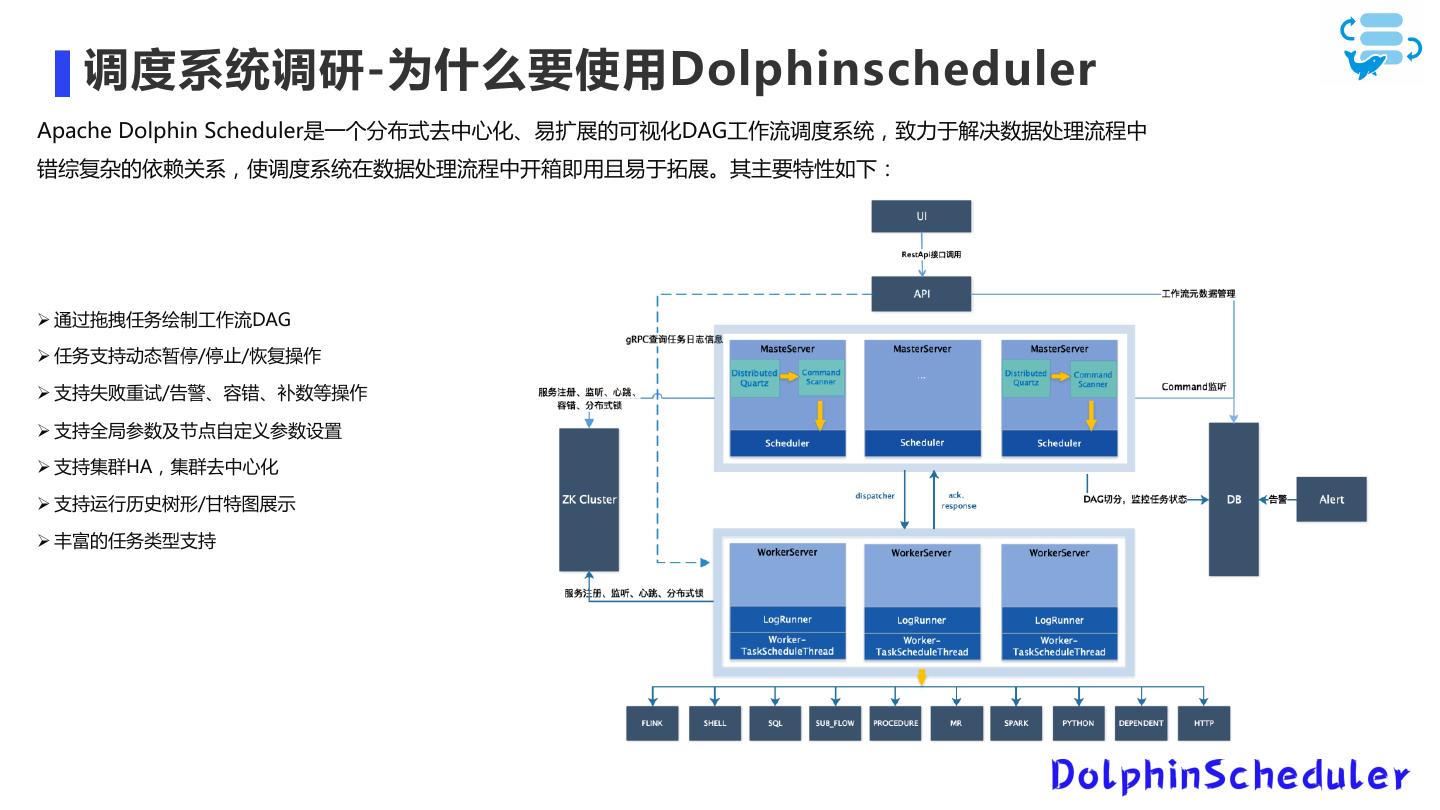
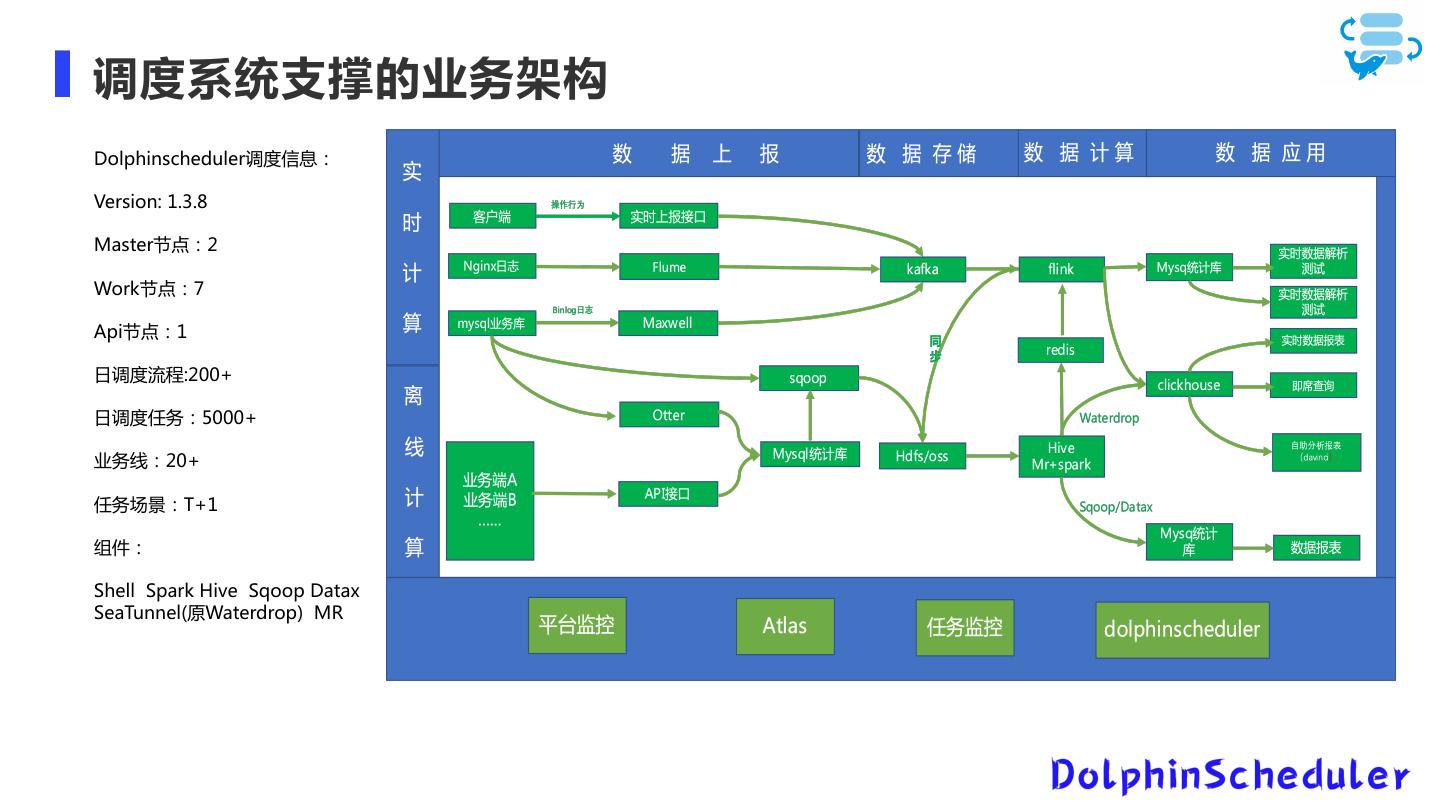
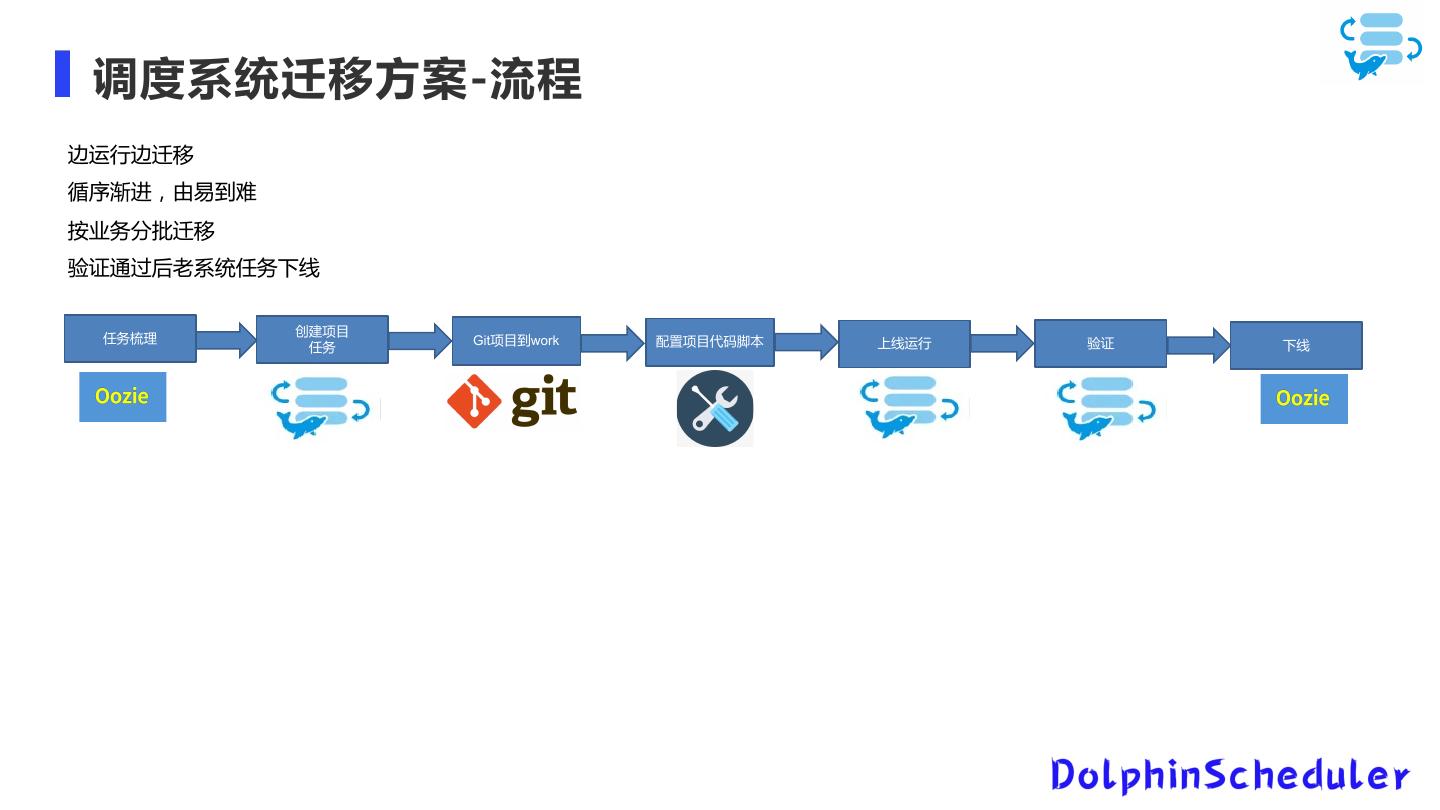
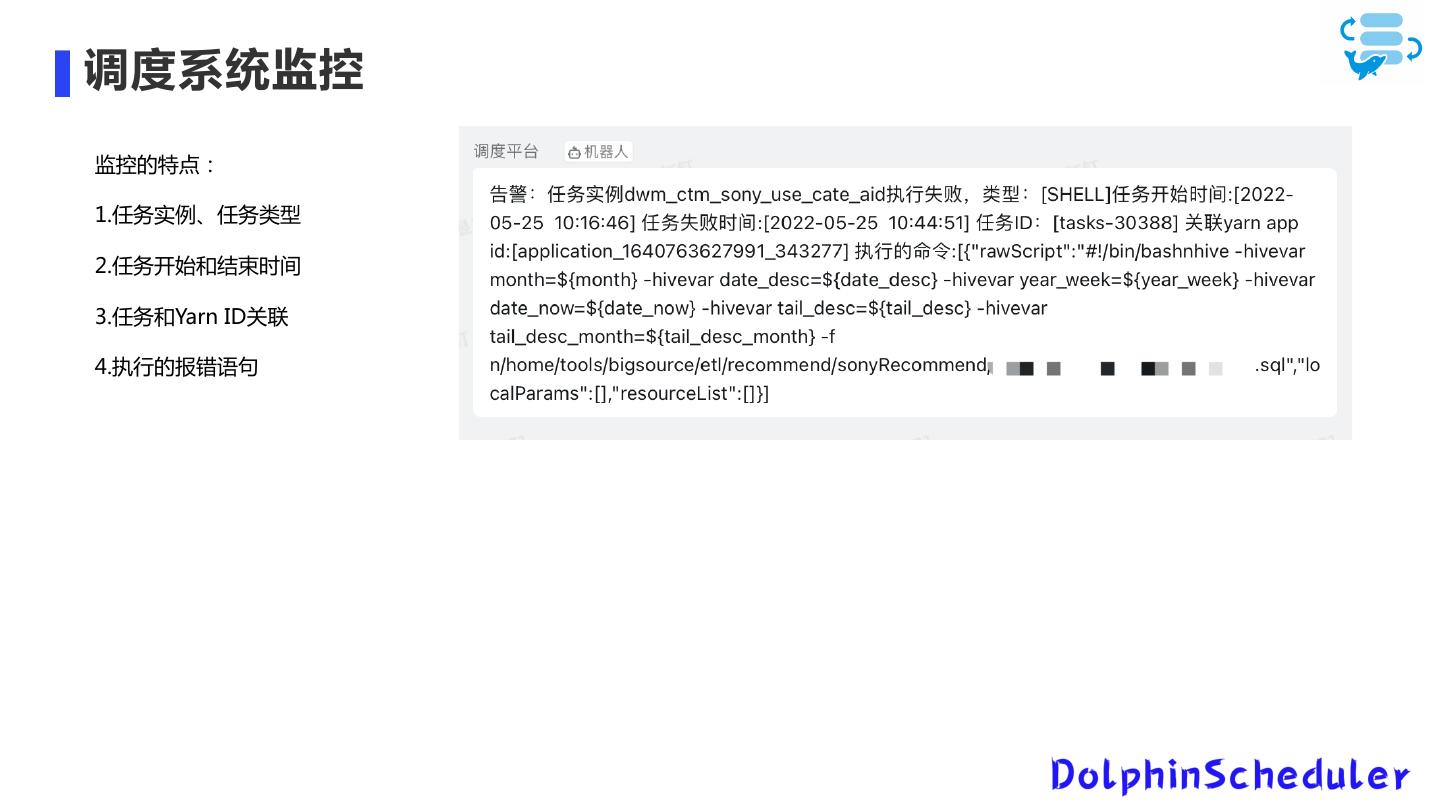
Dolphinscheduler在当贝中的应用
展开查看详情
1 . !"!! Apache Dolphinscheduler在当贝大数据环境中 的应用 讲师 :王昱翔
2 .目录 CONTENTS "# 背景 "! 大数据平台架构 "$ 调度平台 "% 下一步计划 "5 拥抱开源
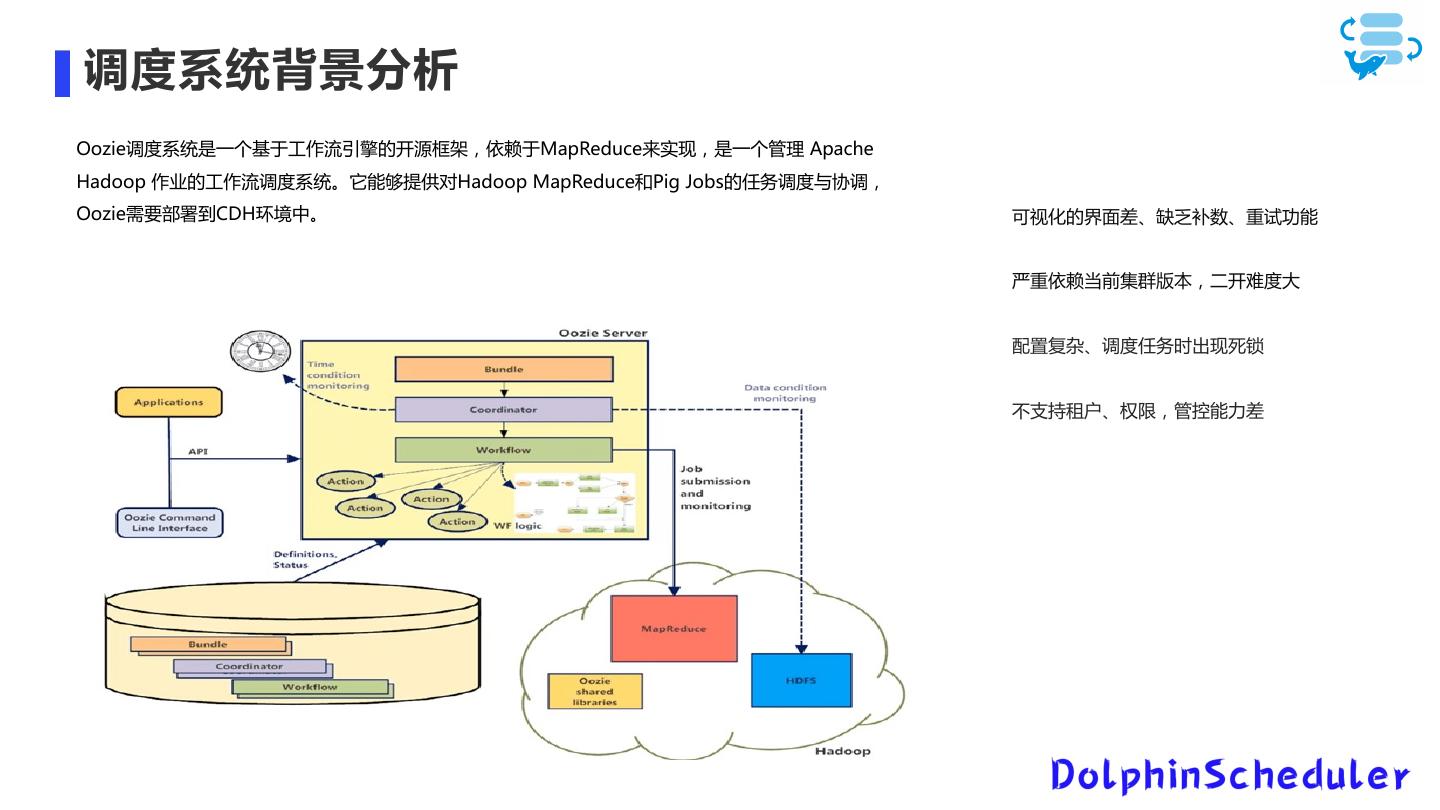
3 ."# 1.平台环境问题 背景 2.测试环境问题 3.调度环境问题
4 . 平台重构目标 "! 大数据平台架构设计 需求分析 大数据平台问题及解决方案 大数据平台架构 Clickhouse迁移 大数据平台重构、迁移 计存分离架构 大数据平台监控架构设计
5 .平台重构目标 1.打造一个高效稳定的大数据平台 2.实现数据的海量存储 3.实现平台的安全高可用架构。 4.实现计存分离 5.可视化操作 6.监控即时告警
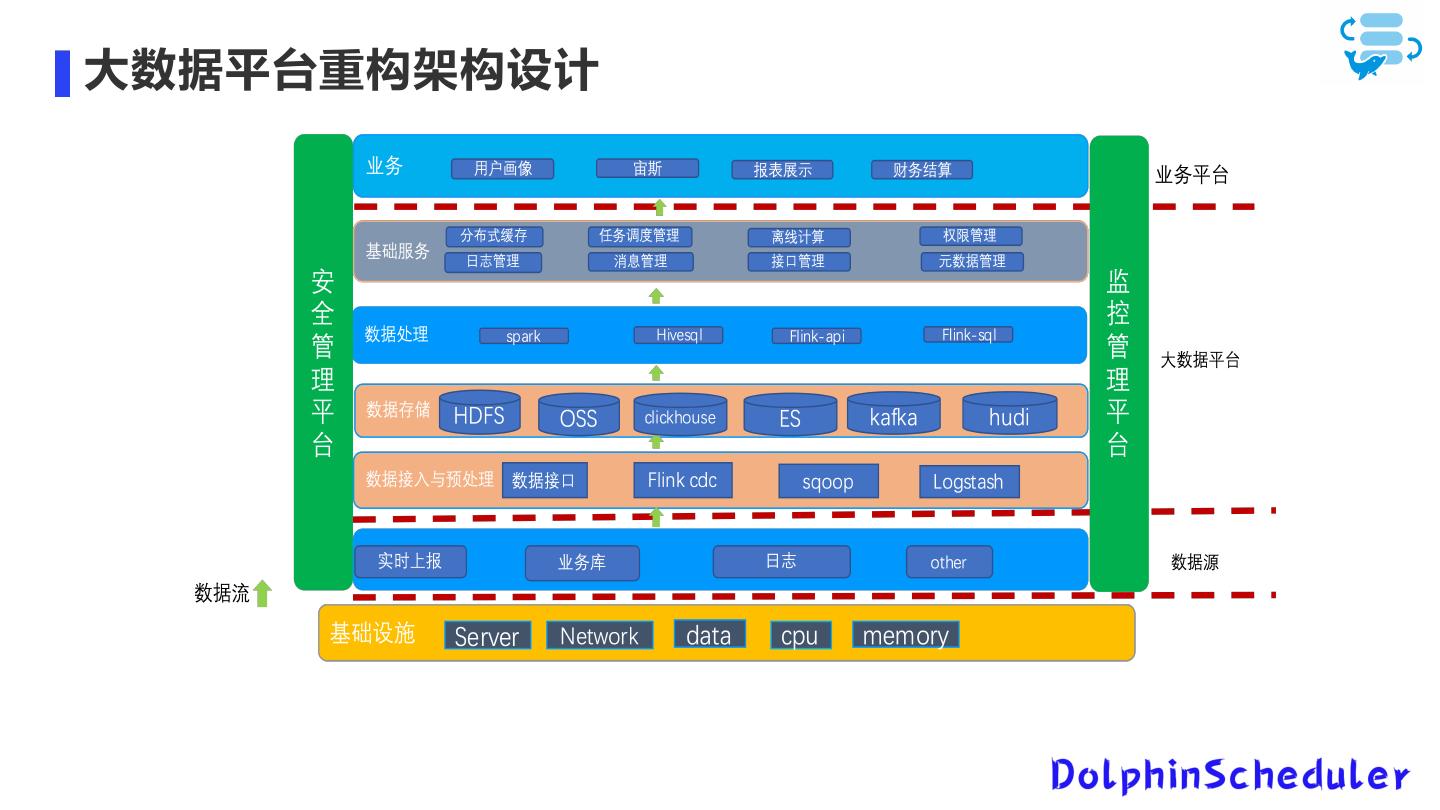
6 .大数据平台重构架构设计
7 .大数据平台问题需求分析 平台 测试 调度 环境 环境 环境 版本较低 缺少测试环境,本地开发完 调度系统配置复杂,可视化 服务部署混乱 后直接提交代码上生产,没 效果差、无法补数、不支持 计算引擎MR较慢 有经过测验证导致晚上任务 权限管理、不支持多租户、 存储不足、扩容难 异常报错 容易出现死锁 服务无高可用 运维监控能力不足,可视化 缺少可视化操作 效果差,无法在线查看日 缺少告警机制 志,故障排除进入后台排 需要人肉运维 错,流程复杂
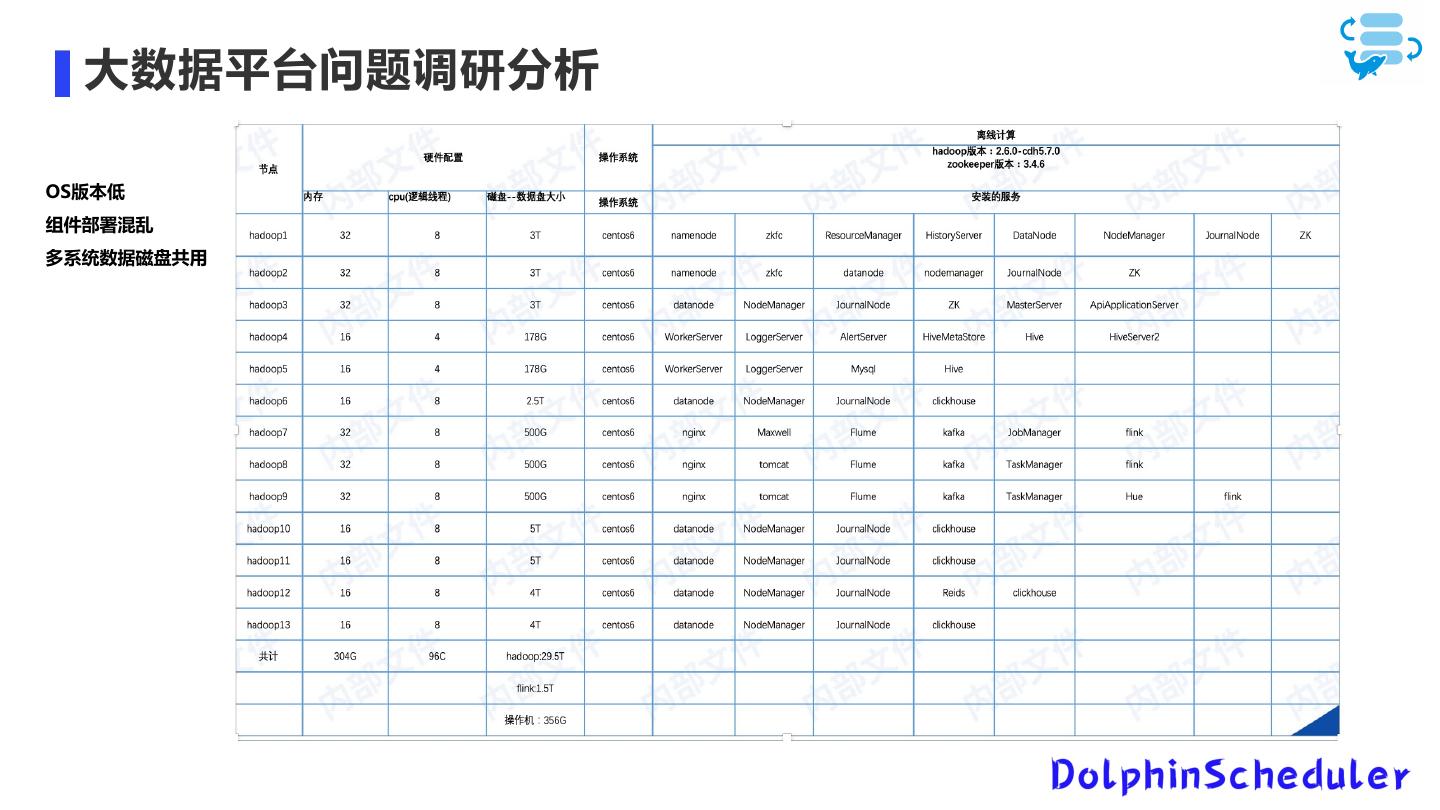
8 . 大数据平台问题调研分析 OS版本低 组件部署混乱 多系统数据磁盘共用
9 . 大数据平台问题调研分析 磁盘空间不足 痛点:天天晚上00:00之前 要把昨天的数据删掉保证任 T+1数据的存储空间
10 .大数据平台问题及解决方案 问题 解决方案 备注 迁移clickhouse 大数据混合部署 Hadoop版本较低 CDH从5.7升级到6.3.0(Hadoop3.0) 重构一套集群 MR计算时间较长 计算引擎有原来的MR切换到Spark 主要是跑hive-sql,代码改造较小 存储不够用 改用计存分离的方案(yarn + oss) 使用jindoFS为中间加速层 Ooize调度无法满足业务调度需求 改成dosphinscheudler调度系统 支持多数据源、支持重试、容错、告警等 1.组件级别 2.任务级别 3.服务器状态级别 无监控告警 Prometheus+Grafana+脚本 4.调度报错 管理节点单节点 使用HA(Namenode、ResourceManager) 可以进行故障转移
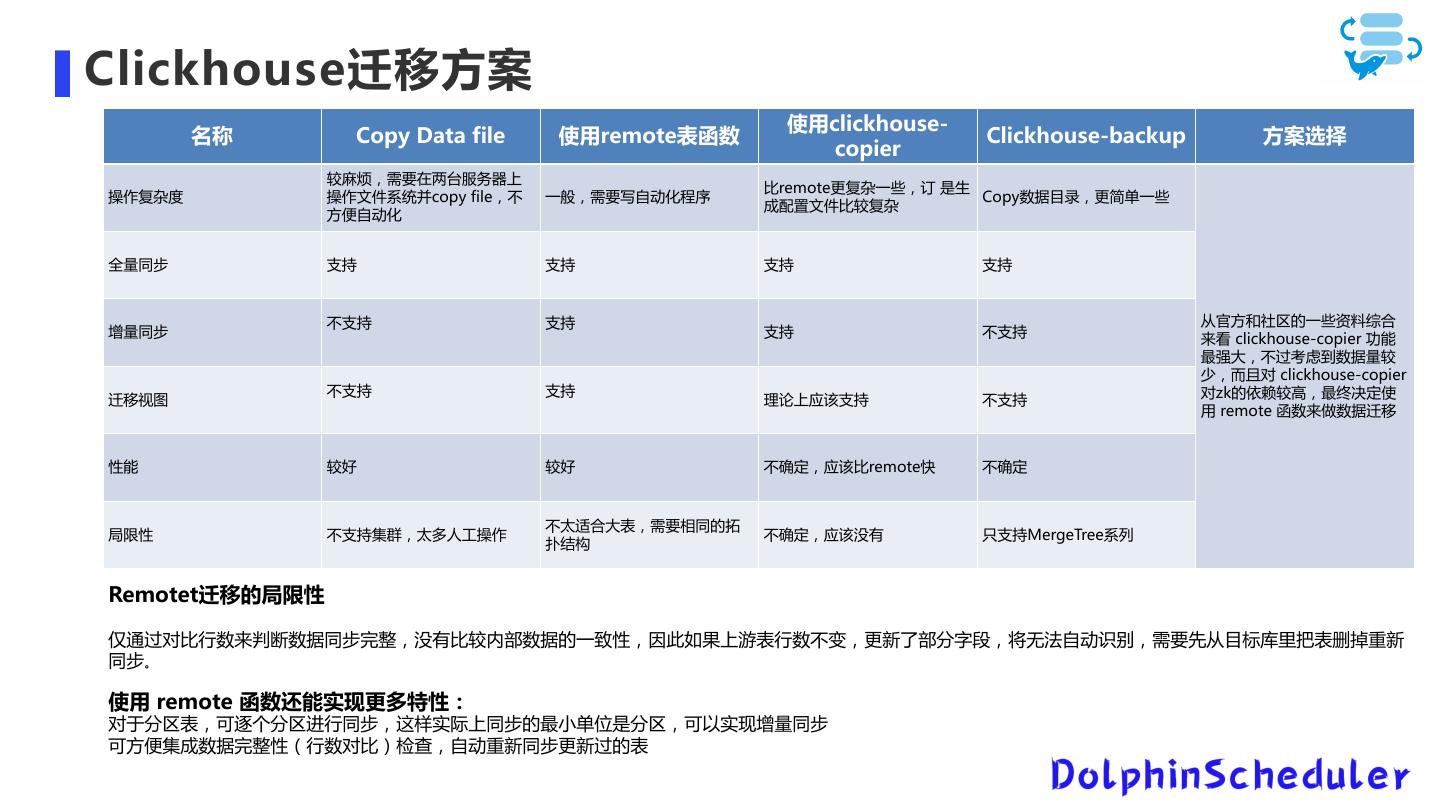
11 .Clickhouse迁移方案 使用clickhouse- 名称 Copy Data file 使用remote表函数 Clickhouse-backup 方案选择 copier 较麻烦,需要在两台服务器上 比remote更复杂一些,订 是生 操作复杂度 操作文件系统并copy file,不 一般,需要写自动化程序 Copy数据目录,更简单一些 成配置文件比较复杂 方便自动化 全量同步 支持 支持 支持 支持 不支持 支持 从官方和社区的一些资料综合 增量同步 支持 不支持 来看 clickhouse-copier 功能 最强大,不过考虑到数据量较 少,而且对 clickhouse-copier 不支持 支持 对zk的依赖较高,最终决定使 迁移视图 理论上应该支持 不支持 用 remote 函数来做数据迁移 性能 较好 较好 不确定,应该比remote快 不确定 不太适合大表,需要相同的拓 局限性 不支持集群,太多人工操作 不确定,应该没有 只支持MergeTree系列 扑结构 Remotet迁移的局限性 仅通过对比行数来判断数据同步完整,没有比较内部数据的一致性,因此如果上游表行数不变,更新了部分字段,将无法自动识别,需要先从目标库里把表删掉重新 同步。 使用 remote 函数还能实现更多特性: 对于分区表,可逐个分区进行同步,这样实际上同步的最小单位是分区,可以实现增量同步 可方便集成数据完整性(行数对比)检查,自动重新同步更新过的表
12 .Clickhouse迁移方案-迁移过程 迁移执行过程 一、找出原来建表语句 select database,create_table_query from system.tables where database in('athena','dmp','sony'); 二、在新的clickhouse创建databases和table 创建数据库 create database dmp ON CLUSTER cluster_clickhouse; 创建表:导出后搞成自动化脚本去执行 三、数据迁移语句(可以用python写成脚本的方式去执行,可以线下交流) insert into dmp.dws_dmp_user_local ON CLUSTER cluster_clickhouse SELECT * FROM remote('192.168.1.1:9000', dmp, dws_dmp_user, 'default', ''); 四、数据迁移前的注意事项 1.cluster_5shards_1replicas-->cluster_clickhouse 2.表名后面添加 ON CLUSTER cluster_clickhouse
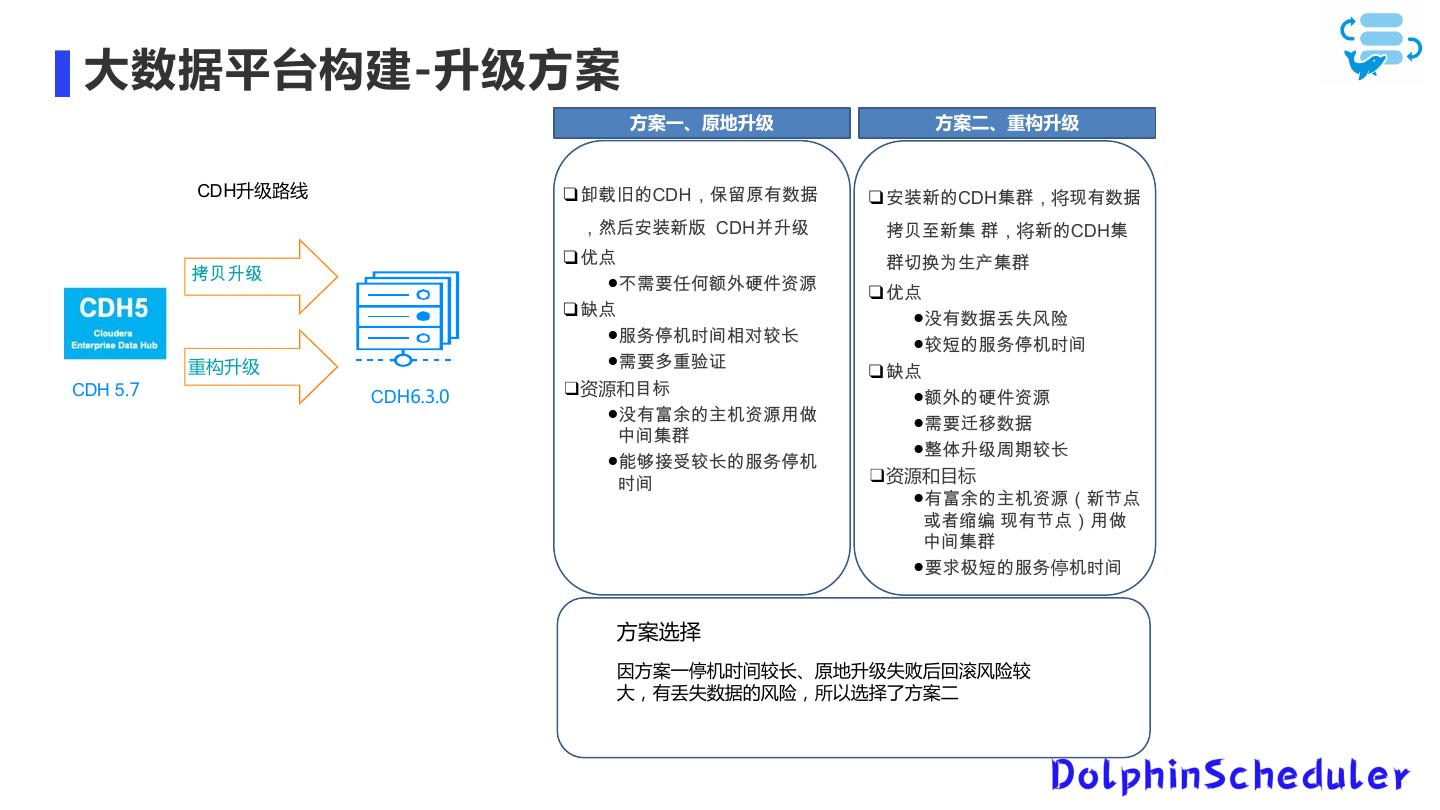
13 . 大数据平台构建-升级方案 方案一、原地升级 方案二、重构升级 原地升级 CDH升级路线 ! !"#$CDH%&'()*+ ! ./0$CDHZ[%将`)*+ %,-./01 CDH234 abc0Z [%将0$CDHZ ! 56 [defghZ[ ab34 "789:;<=>?@A ! 56 ! B6 "S)*+ijkl "CDEFGHIJKL "Km$CDEFGH 重构升级 "89MNOP ! B6 CDH 5.7 CDH6.3.0 ❑资源和QR "<=$>?@A "S)TU$VF@AWX "89no*+ YHZ[ "pq34rsKL "\]^_KL$CDEF GH ❑资源和目标 ")TU$VF@At0u6 vwxy `)u6zWX YHZ[ "9{|m$CD停FGH 方案选择 因方案一停机时间较长、原地升级失败后回滚风险较 大,有丢失数据的风险,所以选择了方案二
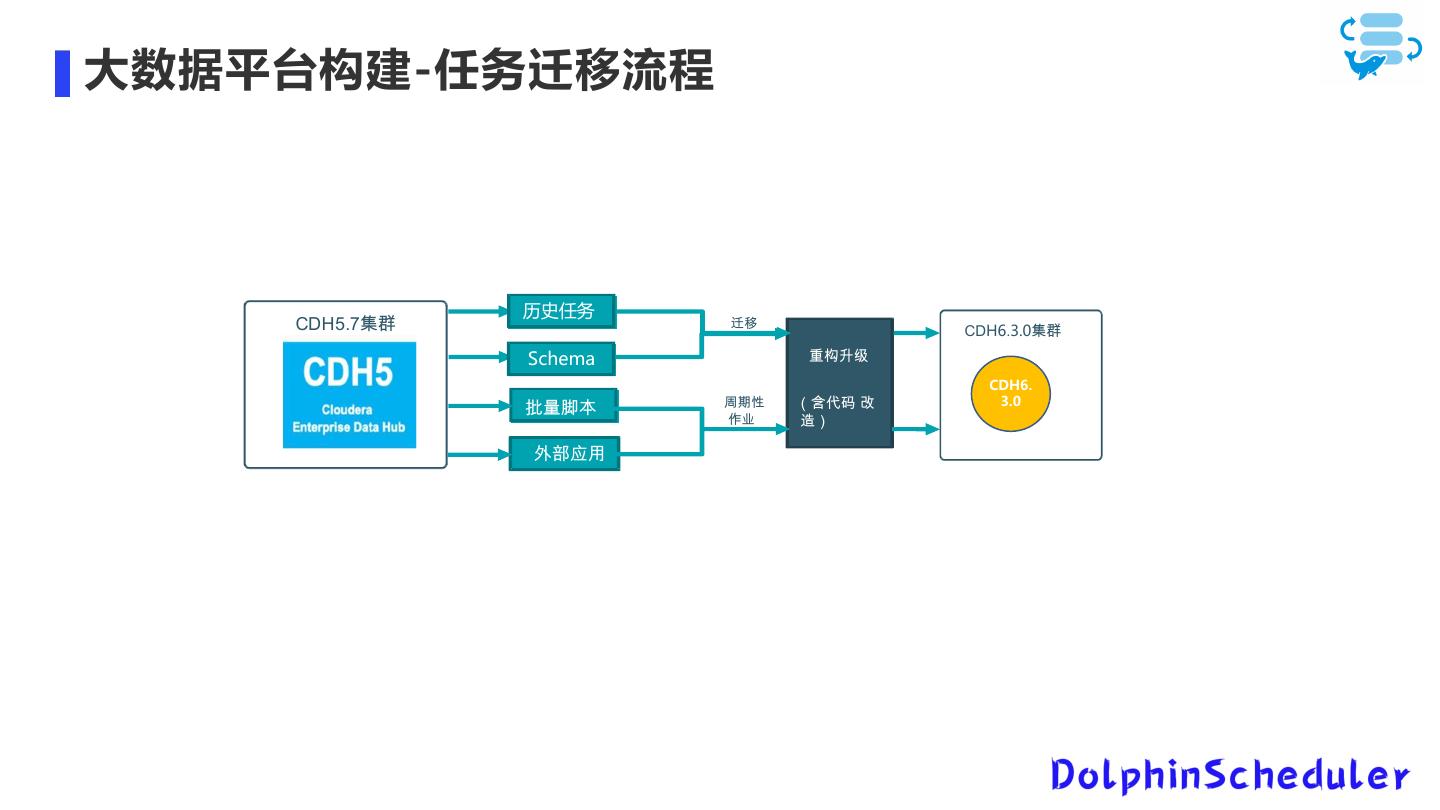
14 .大数据平台构建-任务迁移流程 历史任务 }~•€•‚Z[ !"#$ &' CDH6.3.0!" Schema #$%& CDH6. ƒ„…† !"# '()* + 3.0 $% ,- =‡ˆW
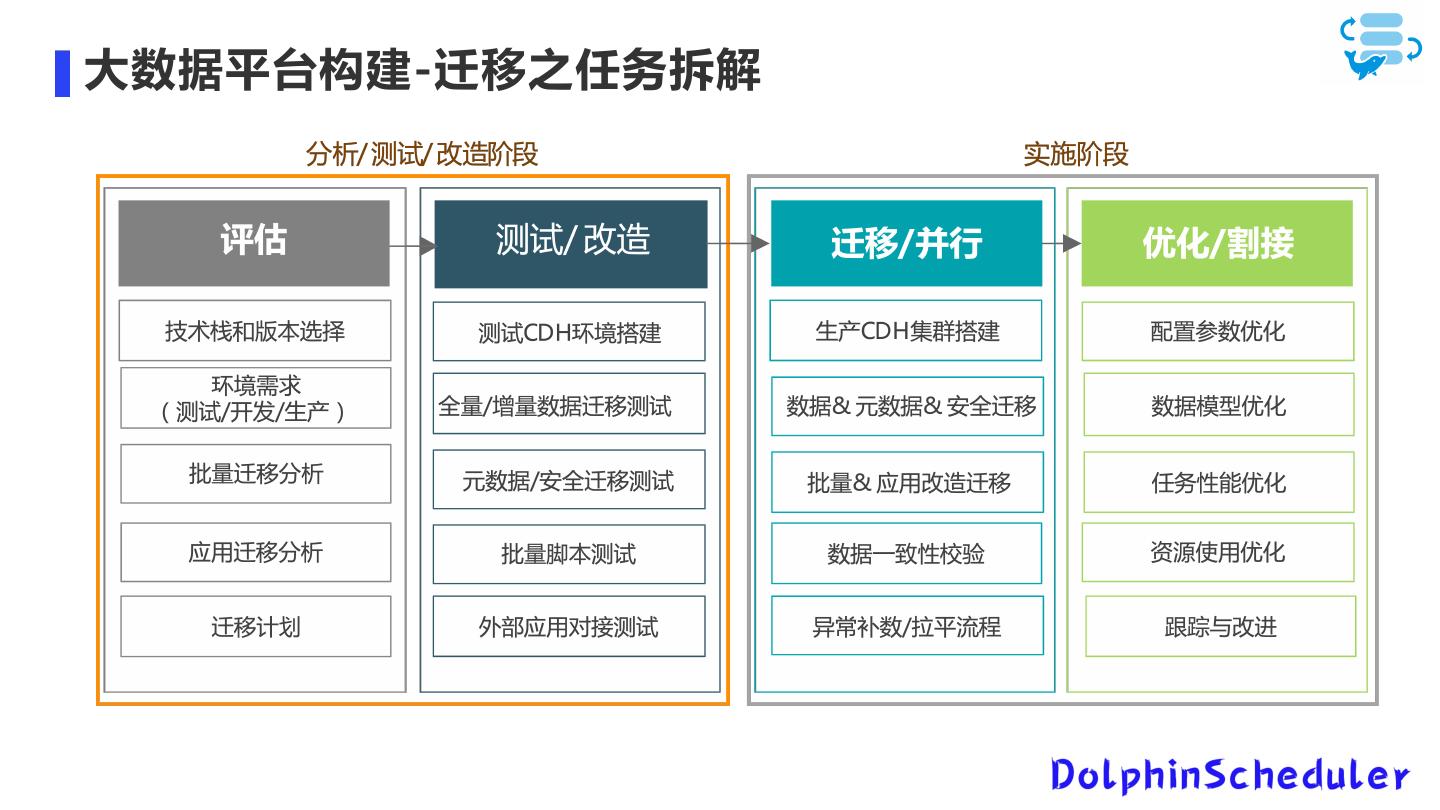
15 .大数据平台构建-迁移之任务拆解
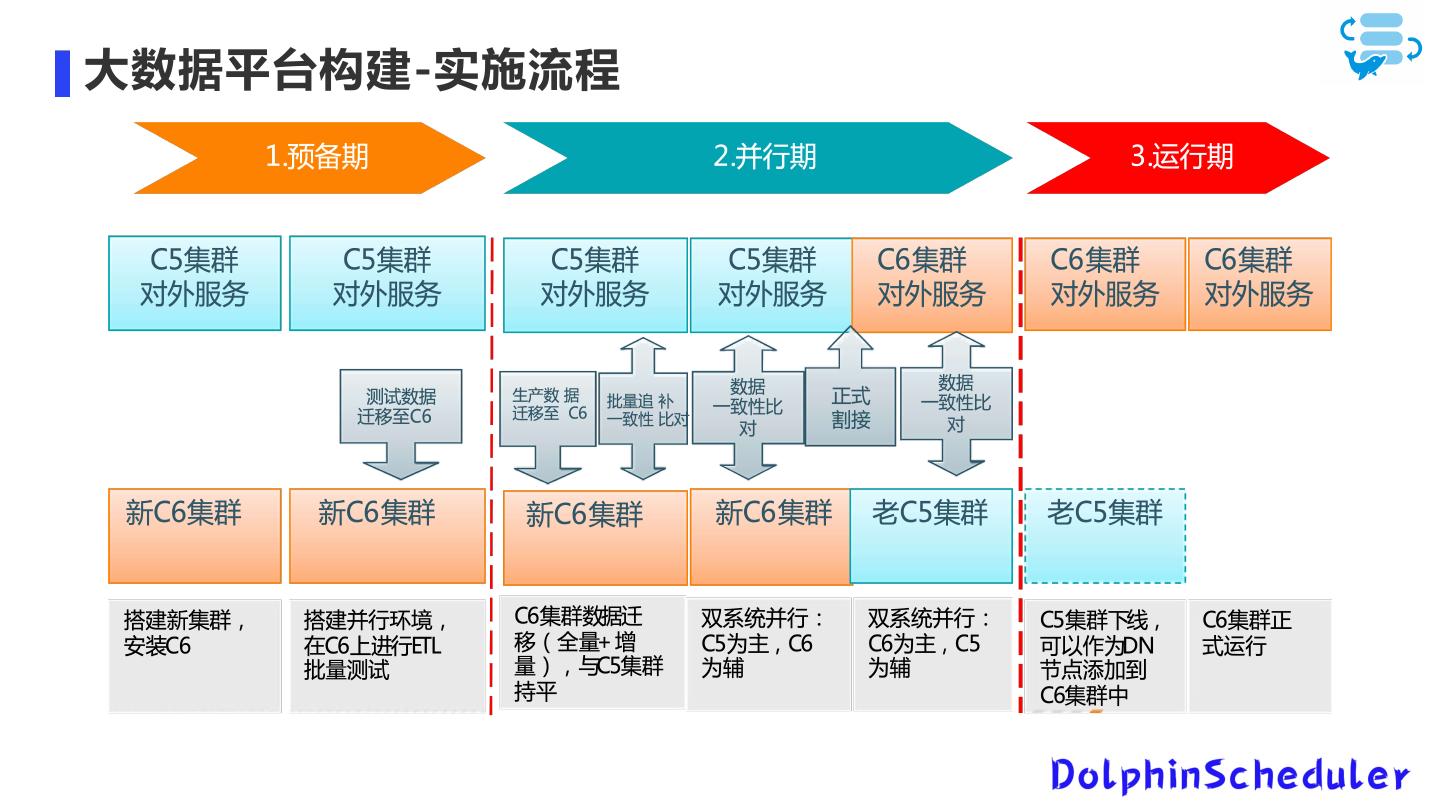
16 .大数据平台构建-实施流程
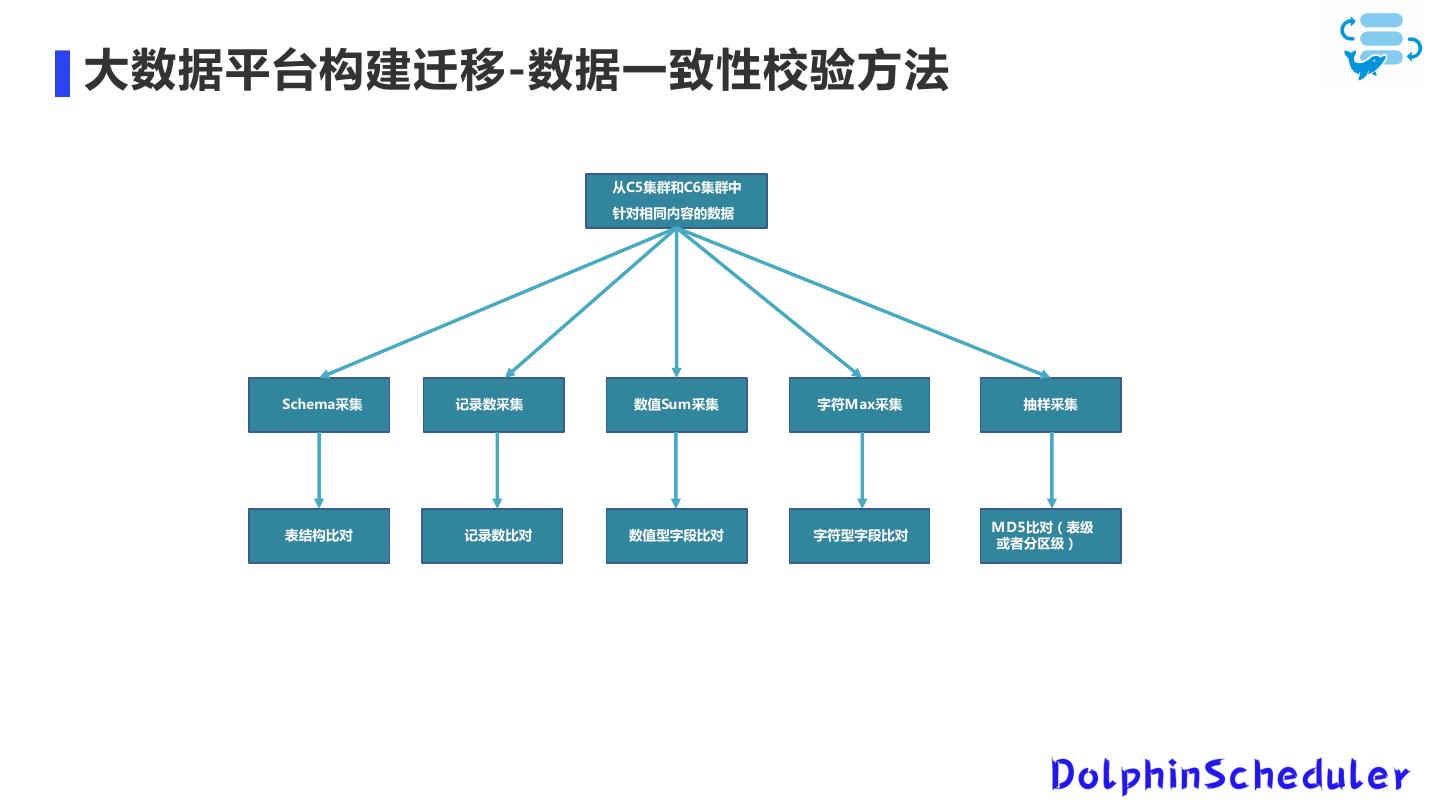
17 .大数据平台构建迁移-数据一致性校验方法 从C5集群和C6集群中 针对相同内容的数据 Schema采集 记录数采集 数值Sum采集 字符Max采集 抽样采集 MD5比对(表级 表结构比对 记录数比对 数值型字段比对 字符型字段比对 或者分区级)
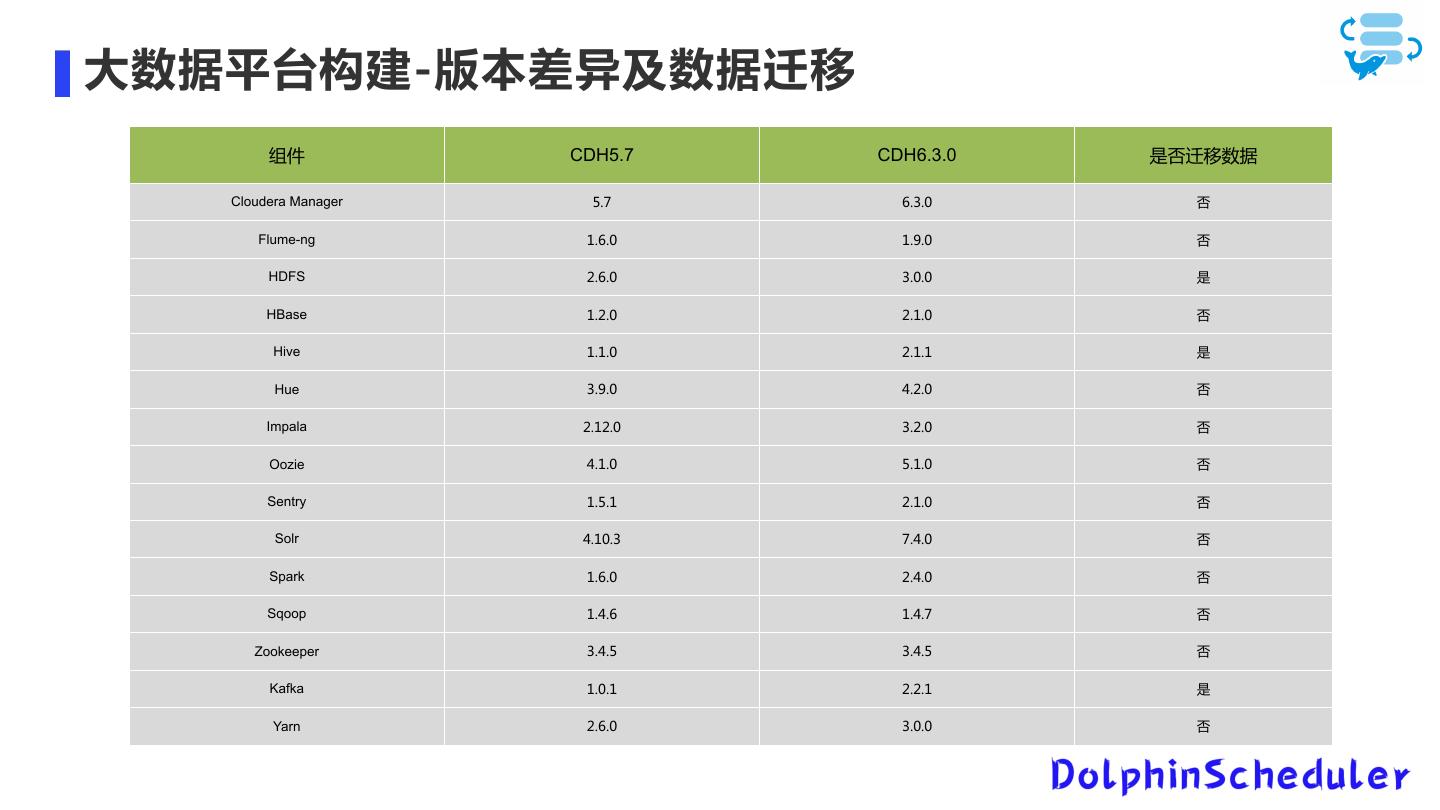
18 .大数据平台构建-版本差异及数据迁移 组件 CDH5.7 CDH6.3.0 是否迁移数据 Cloudera Manager 5.7 6.3.0 否 Flume-ng 1.6.0 1.9.0 否 HDFS 2.6.0 3.0.0 是 HBase 1.2.0 2.1.0 否 Hive 1.1.0 2.1.1 是 Hue 3.9.0 4.2.0 否 Impala 2.12.0 3.2.0 否 Oozie 4.1.0 5.1.0 否 Sentry 1.5.1 2.1.0 否 Solr 4.10.3 7.4.0 否 Spark 1.6.0 2.4.0 否 Sqoop 1.4.6 1.4.7 否 Zookeeper 3.4.5 3.4.5 否 Kafka 1.0.1 2.2.1 是 Yarn 2.6.0 3.0.0 否
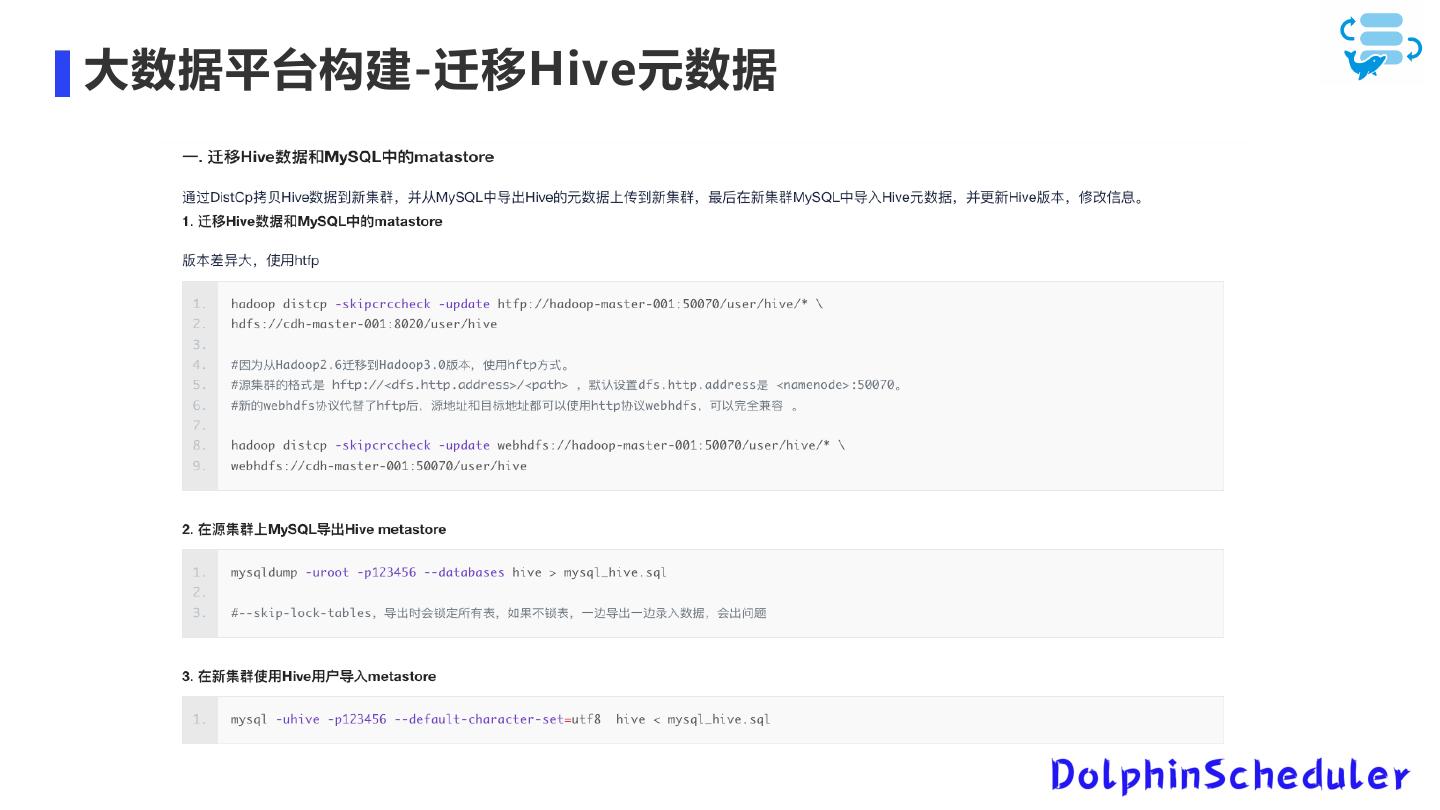
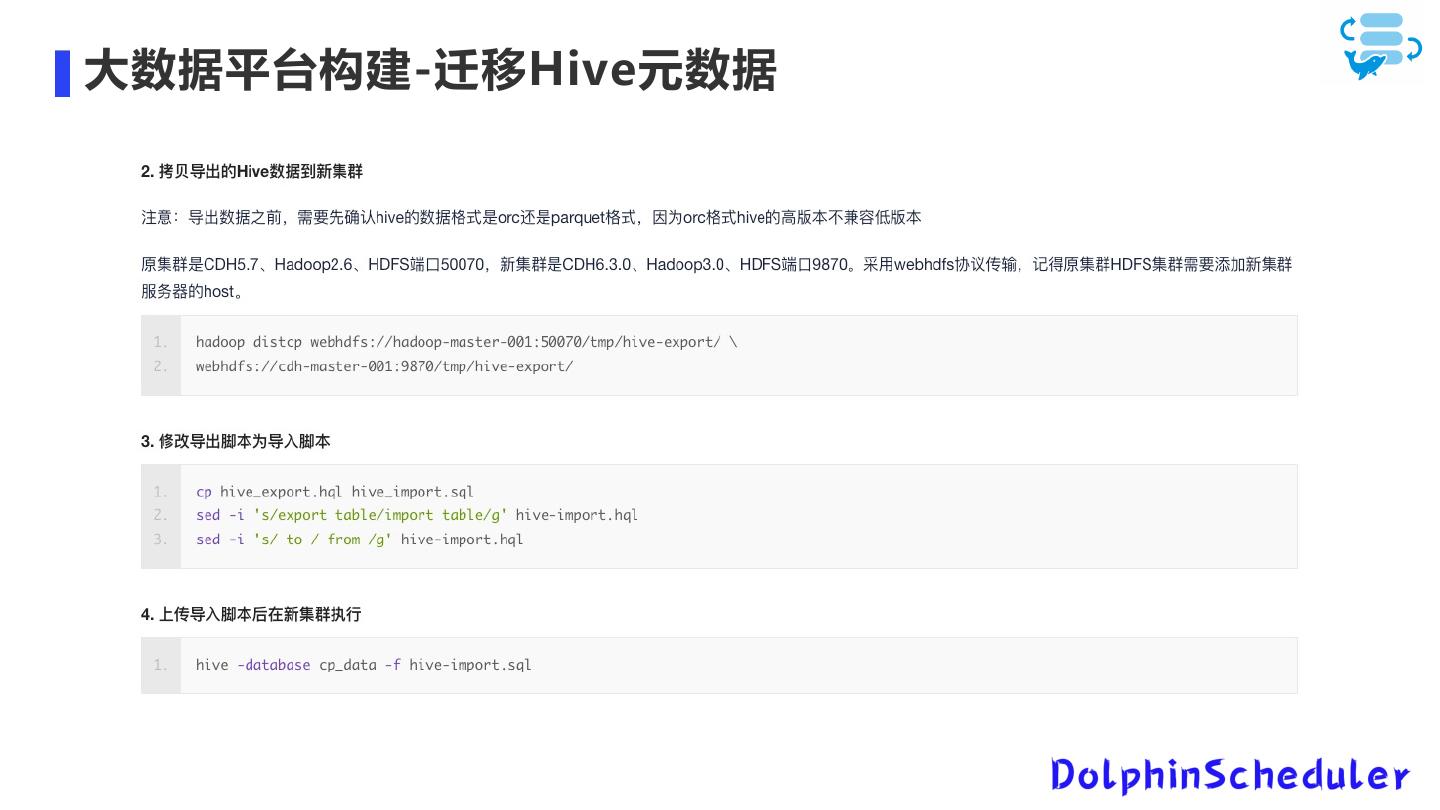
19 .大数据平台构建-迁移Hive元数据
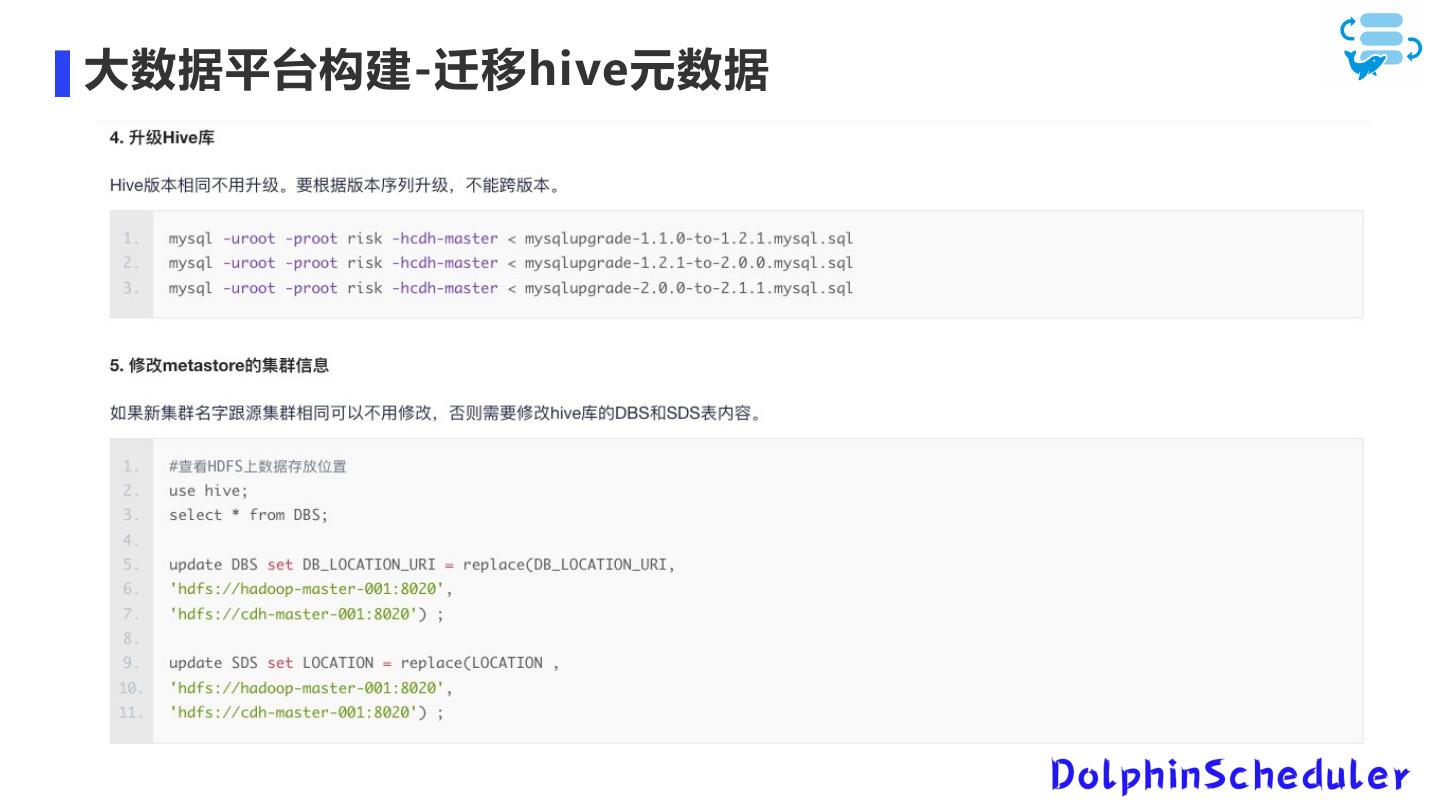
20 .大数据平台构建-迁移hive元数据
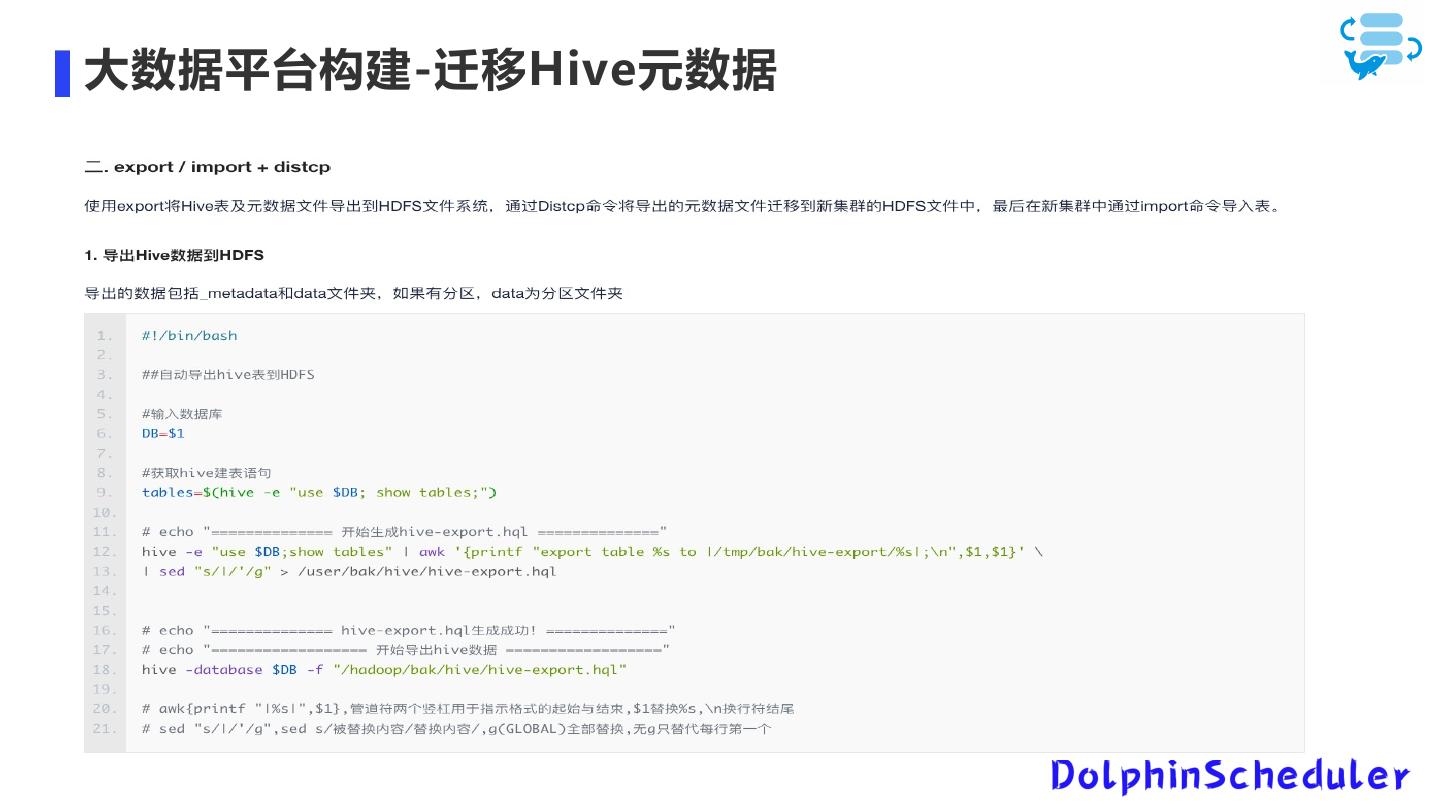
21 .大数据平台构建-迁移Hive元数据
22 .大数据平台构建-迁移Hive元数据
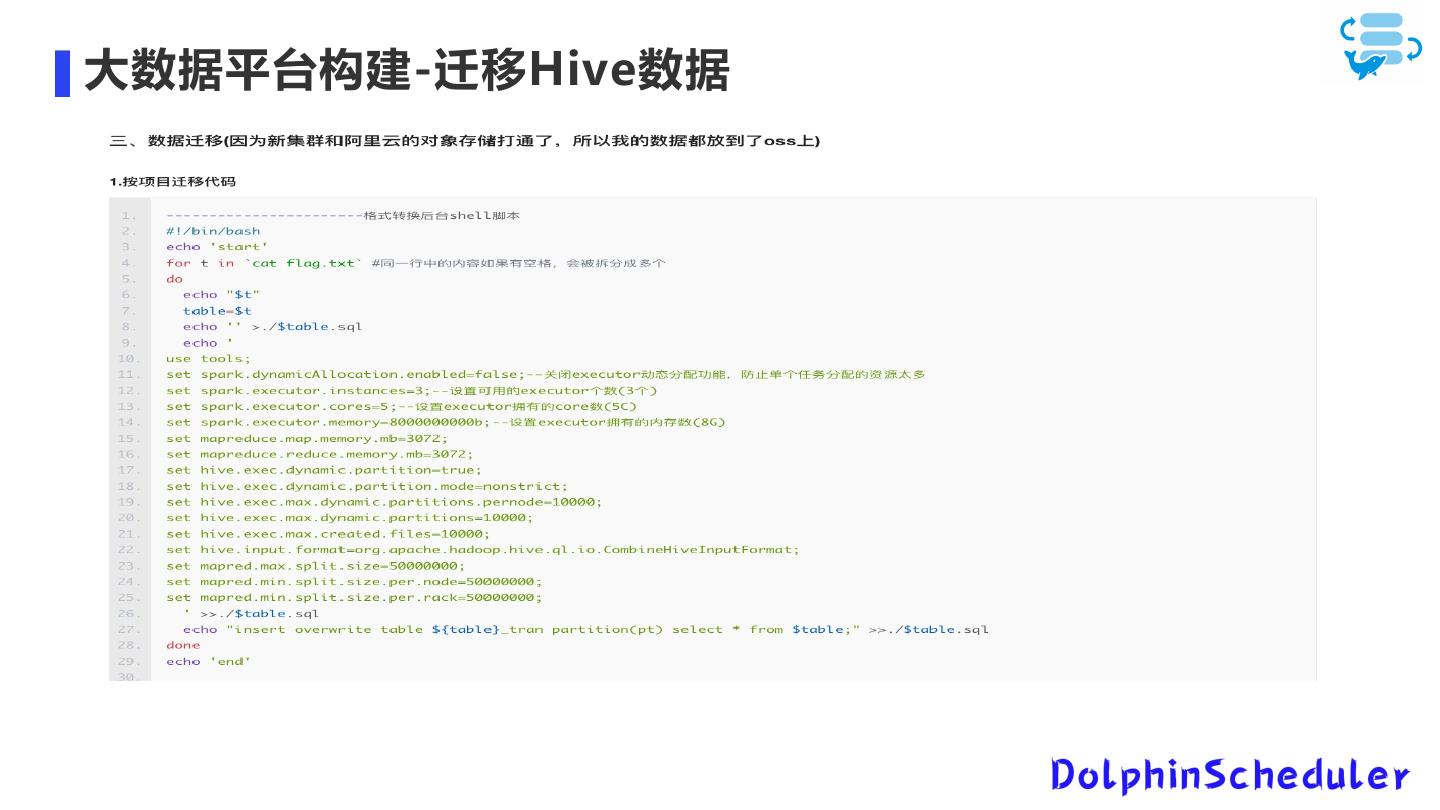
23 .大数据平台构建-迁移Hive数据
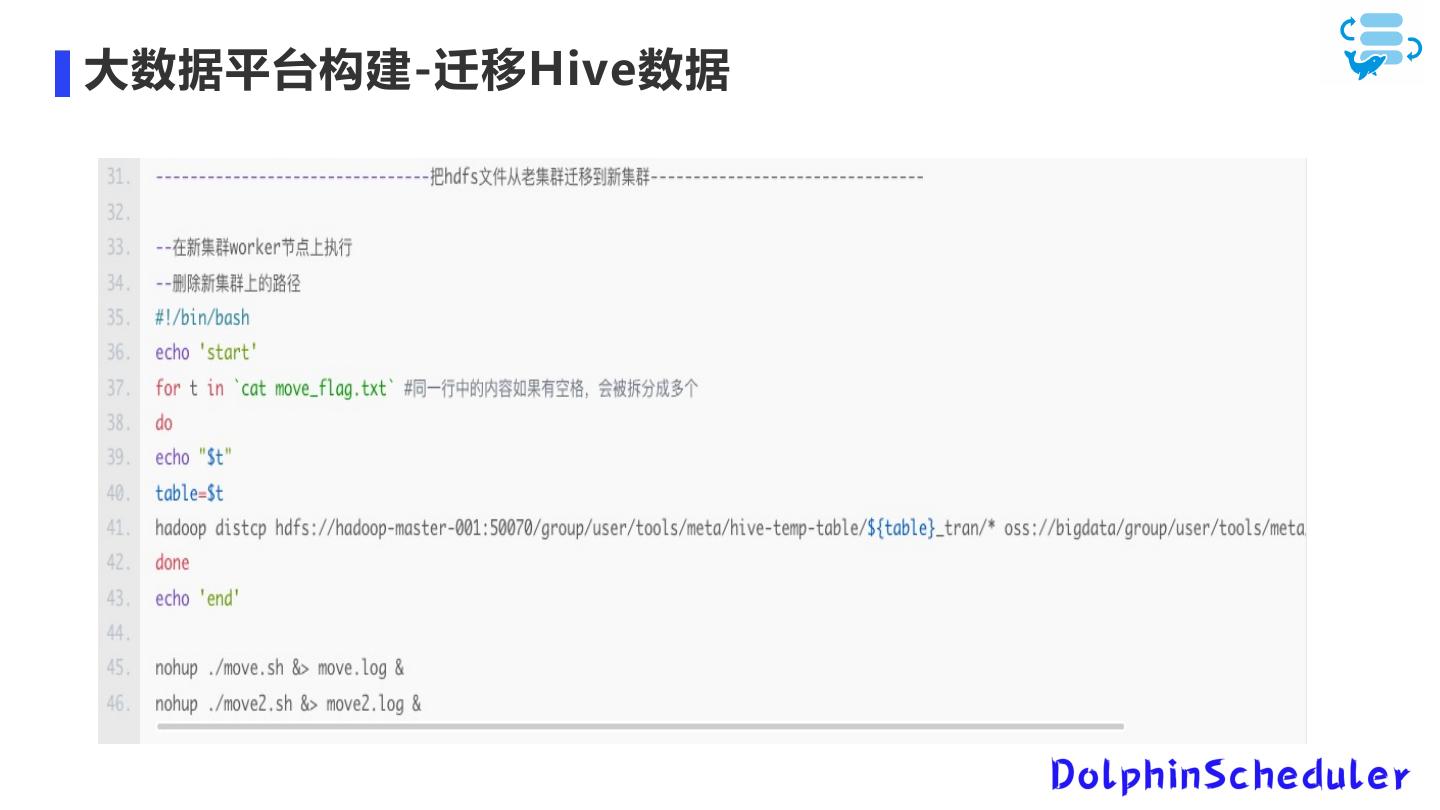
24 .大数据平台构建-迁移Hive数据
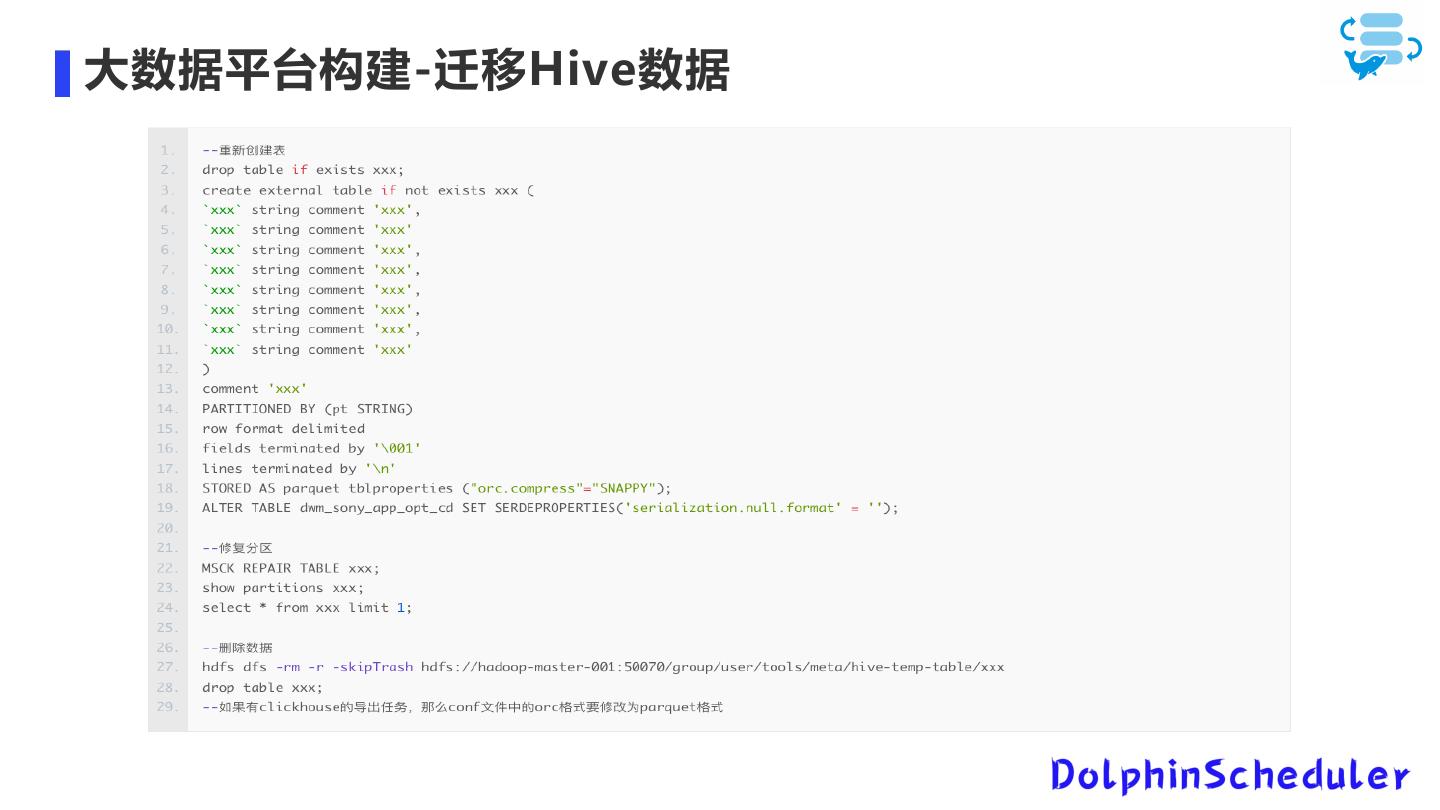
25 .大数据平台构建-迁移Hive数据
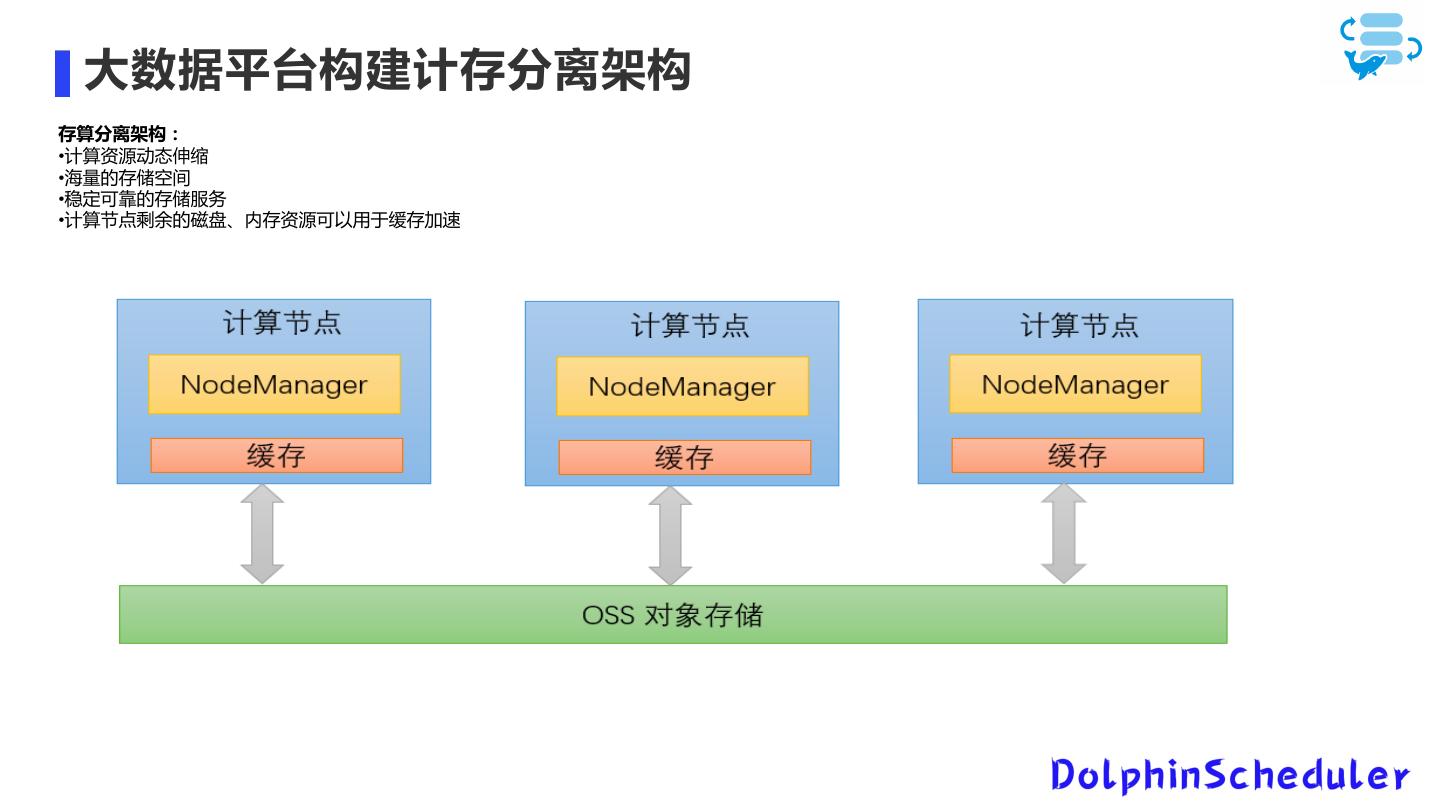
26 . 大数据平台构建计存分离架构 存算分离架构: •计算资源动态伸缩 •海量的存储空间 •稳定可靠的存储服务 •计算节点剩余的磁盘、内存资源可以用于缓存加速
27 . 大数据平台集成JindoFS JindoFS纯客户端模式为Hive和Spark等计算框架提供了访问阿里云OSS及其各种操作的优化,类似 Hadoop社区的OSS FileSystem或S3A FileSystem。此模式不改变文件或对象在OSS上的组织方式,文件 还是保存在OSS上,JindoFS只是提供面向Hadoop生态的客户端连接、扩展、适配和优化访问。可以使用 此模式,上传JindoFS SDK的JAR包至组件的classpath目录,简单易用,无需部署分布式服务 数据计算、分析 JindoFS SDK 数据加速 OSS 数据存储
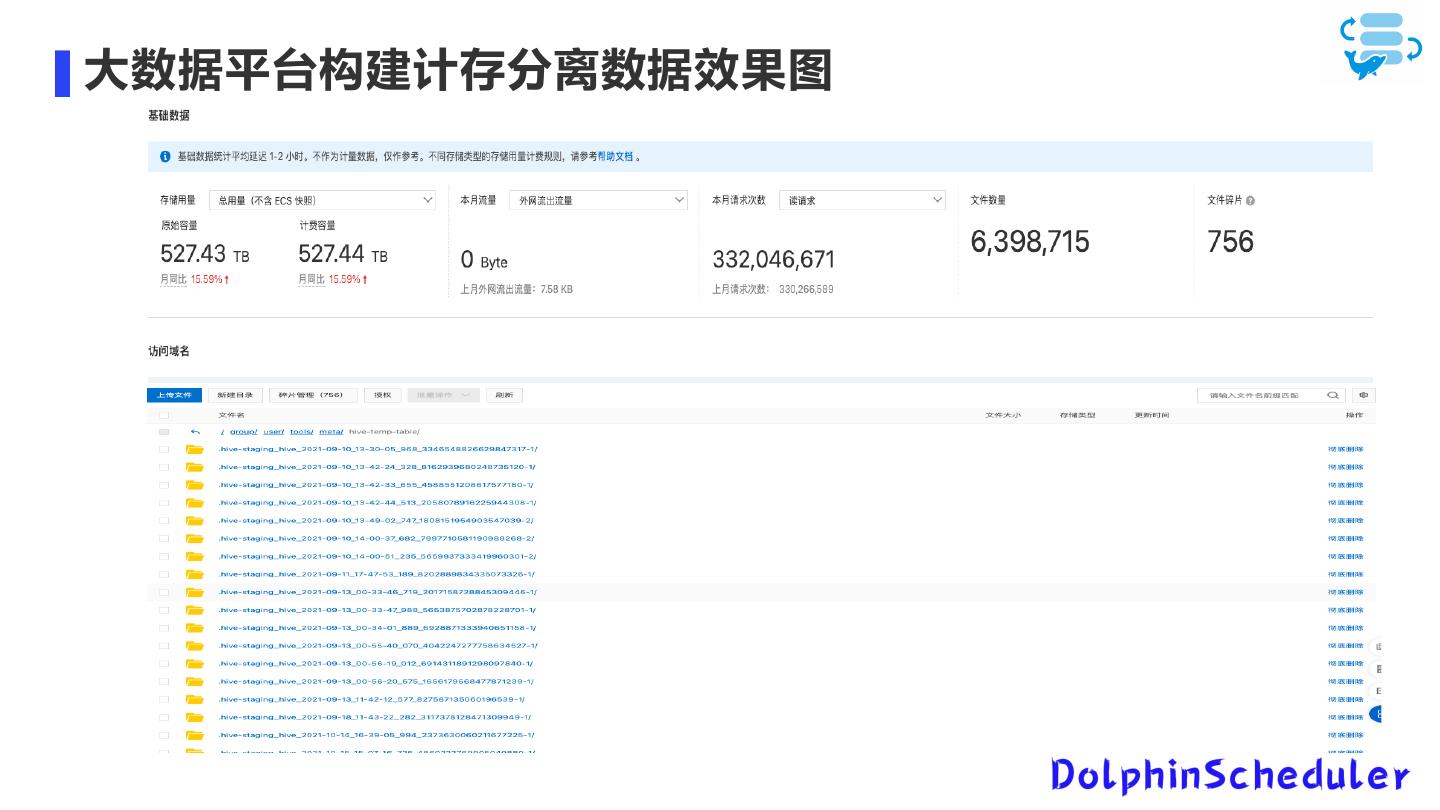
28 .大数据平台构建计存分离数据效果图
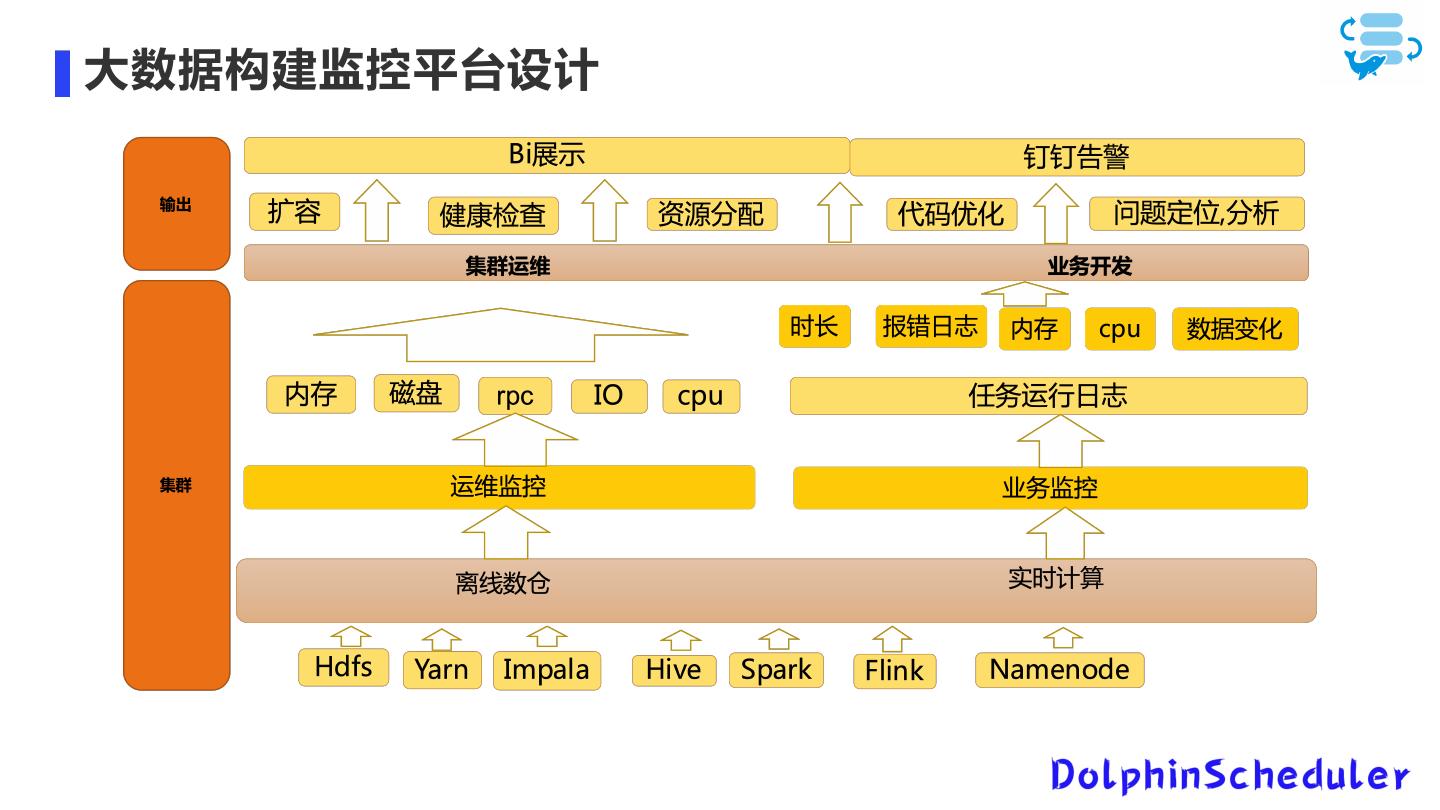
29 .大数据构建监控平台设计
3秒后跳转登录页面
去登陆

