展开查看详情
1 .DolphinScheduler在
数据管道平台中的应用
讲师 长城汽车-IDC-数据中台部-刘永飞
�
2 .目录
CONTENTS
01 数据管道
02 DolphinScheduler在数据
管道平台中的应用
03 在使用DolphinScheduler时
遇到的问题 04 总结
�
3 . 平台简介
技术架构
01
支持多种数据源
支持多种管道
数据管道
主要界面
引擎设置
数据类型映射
任务告警
推广
�
4 .平台简介
数据管道是一个基于分布式技术构建的数据传输平台,支持多种数据源海量数据的实时、离线的方式传输。
数据管道可通过简单的页面配置即可完成数据传输,操作过程简单且高效,降低用户使用门槛;内设告警机制,传输任务出现异常可第一时间通过钉钉将
信息发送具体责任人。
�
5 .技术架构
整个架构在形式上就是左中右的架构,最左边是一个数据的源端,也是整个数据的起点,最右边数据数据的目标端,是数据的目的地。
通过中间的数据管道可以实现数据的传输。
数据源 目标数据源
DataTube数据管道
MySQL MySQL
数据管道WEB
SQLServer SQLServer
Project Task Scheduler Alert
Oracle 项目管理 任务管理 调度 监控告警 Oracle
PgSQL Resource Log日志 PgSQL
资源管理
Hdfs Hdfs
Hive Hive
DolphinScheduler
Kafka Kafka
Spark Flink
Clickhouse Clickhouse
……… 数据管道资源池 ………
�
6 .支持多种数据源
MySQL Oracle MS SQLSever Postgre Hdfs
Kafka MongoDB TiDB API Hive
Maxcompute OSS Hologres Kudu ElasticSearch
(共23种)
Hudi Clickhouse Doris HANA
�
7 . 支持多种管道
在现有支持的 23 种数据源基础上,细分到离线任务、实时任务的全量同步、增量同步维度后,数据管道平台可支持将近 900 种管道。
以常见的关系型数据库 MySQL 做为数据源为例,一共可以支持 38 个管道。
�
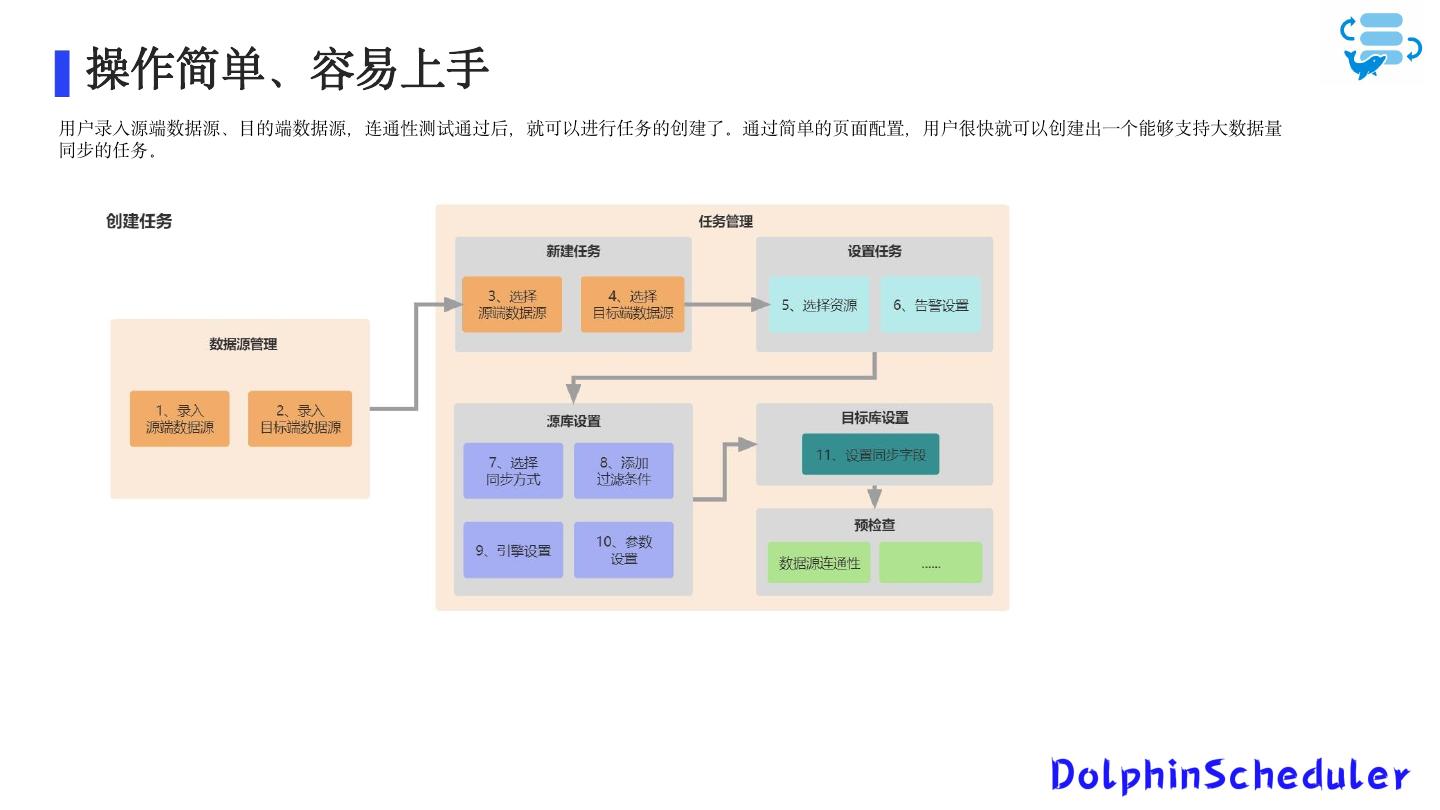
8 . 操作简单、容易上手
用户录入源端数据源、目的端数据源,连通性测试通过后,就可以进行任务的创建了。通过简单的页面配置,用户很快就可以创建出一个能够支持大数据量
同步的任务。
�
10 .引擎设置
数据管道平台可以根据任务使用的计算引擎(Spark/Flink)来设置任务运行过程中所需的资源参数。
�
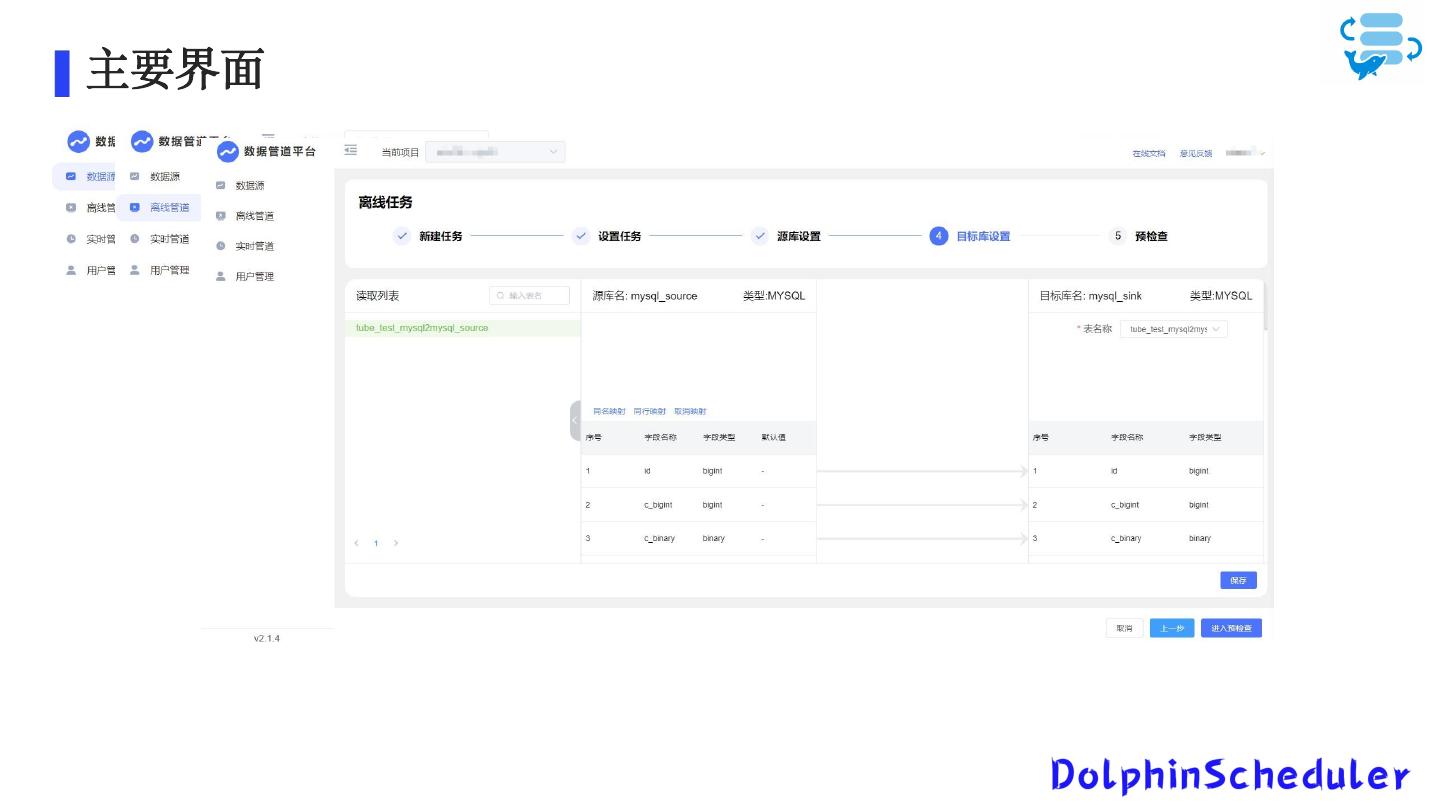
11 .数据类型映射
目标库设置时可以方便的进行源端字段和目标端字段的映射。我们收集了Spark/Flink的数据类型映射字典,用于进行源端数据类型到目标数据类型的转换。
�
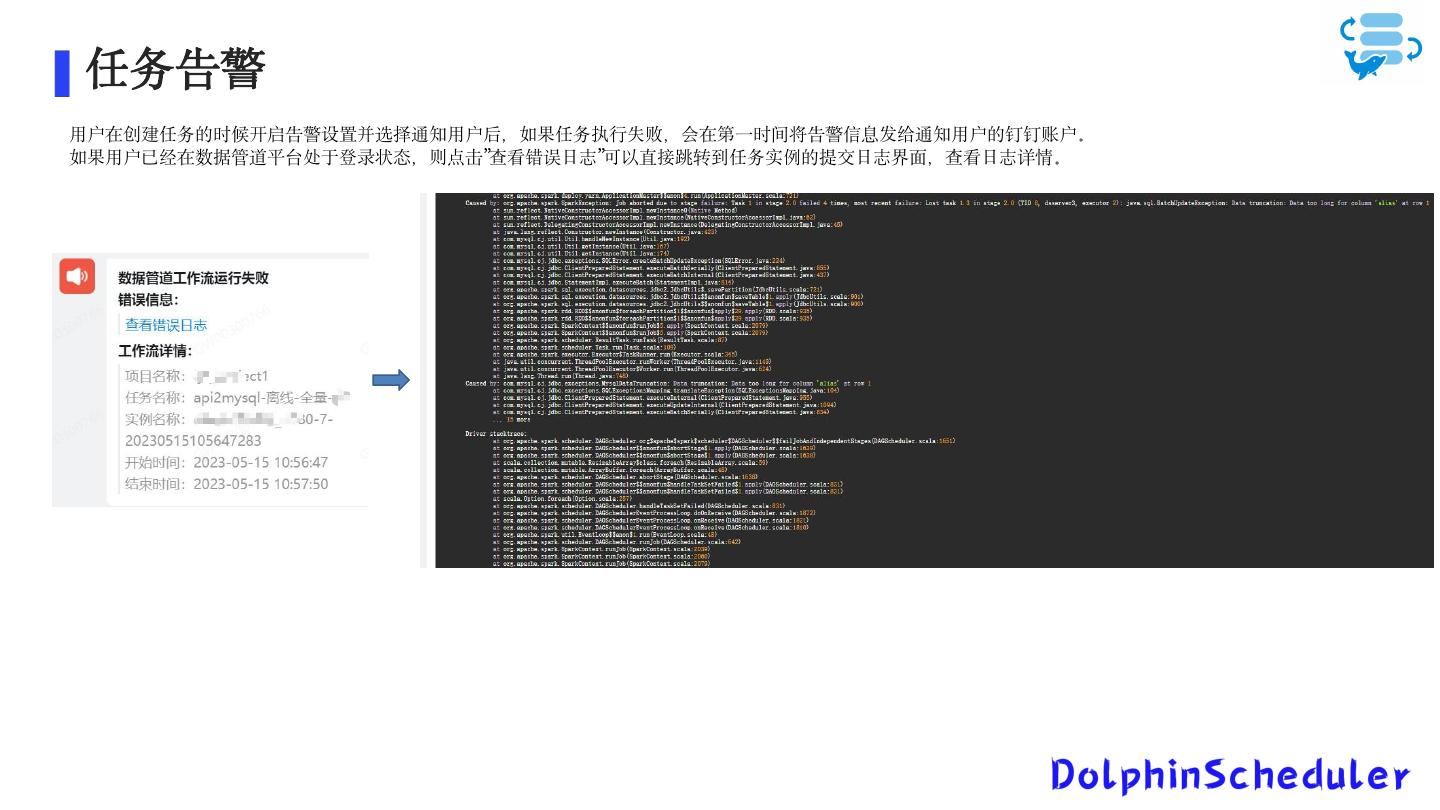
12 .任务告警
用户在创建任务的时候开启告警设置并选择通知用户后,如果任务执行失败,会在第一时间将告警信息发给通知用户的钉钉账户。
如果用户已经在数据管道平台处于登录状态,则点击”查看错误日志”可以直接跳转到任务实例的提交日志界面,查看日志详情。
�
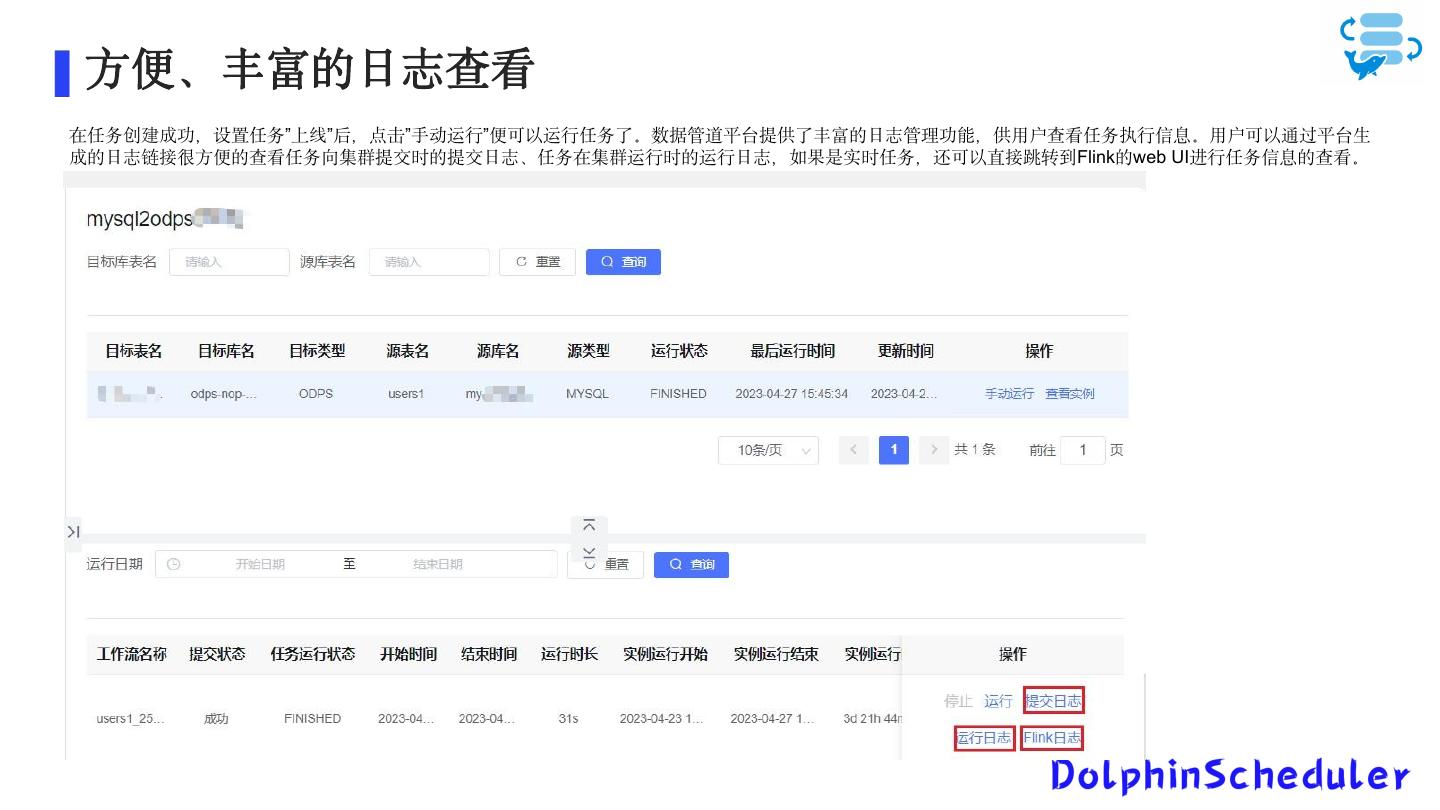
13 .方便、丰富的日志查看
在任务创建成功,设置任务”上线”后,点击”手动运行”便可以运行任务了。数据管道平台提供了丰富的日志管理功能,供用户查看任务执行信息。用户可以通过平台生
成的日志链接很方便的查看任务向集群提交时的提交日志、任务在集群运行时的运行日志,如果是实时任务,还可以直接跳转到Flink的web UI进行任务信息的查看。
�
14 .方便、丰富的日志查看
在任务创建成功,设置任务”上线”后,点击”手动运行”便可以运行任务了。数据管道平台提供了丰富的日志管理功能,供用户查看任务执行信息。用户可以通过平台生
成的日志链接很方便的查看任务向集群提交时的提交日志、任务在集群运行时的运行日志,如果是实时任务,还可以直接跳转到Flink的web UI进行任务信息的查看。
�
15 .推广成果
推广成果
目前该产品已经在我们内部的一
些部门及子公司进行了使用。
截止到目前的一个使用情况如下:
创建任务300+个,每日近2000个
任务实例运行 。
�
16 . 主要流程
数据管道使用了哪些DolphinScheduler的api服务
02 数据管道创建任务会生成工作流定义数据
DolphinScheduler
参数设置
在数据管道平台中的应用
提交日志
扩充实例列表支持实时任务断点续传
�
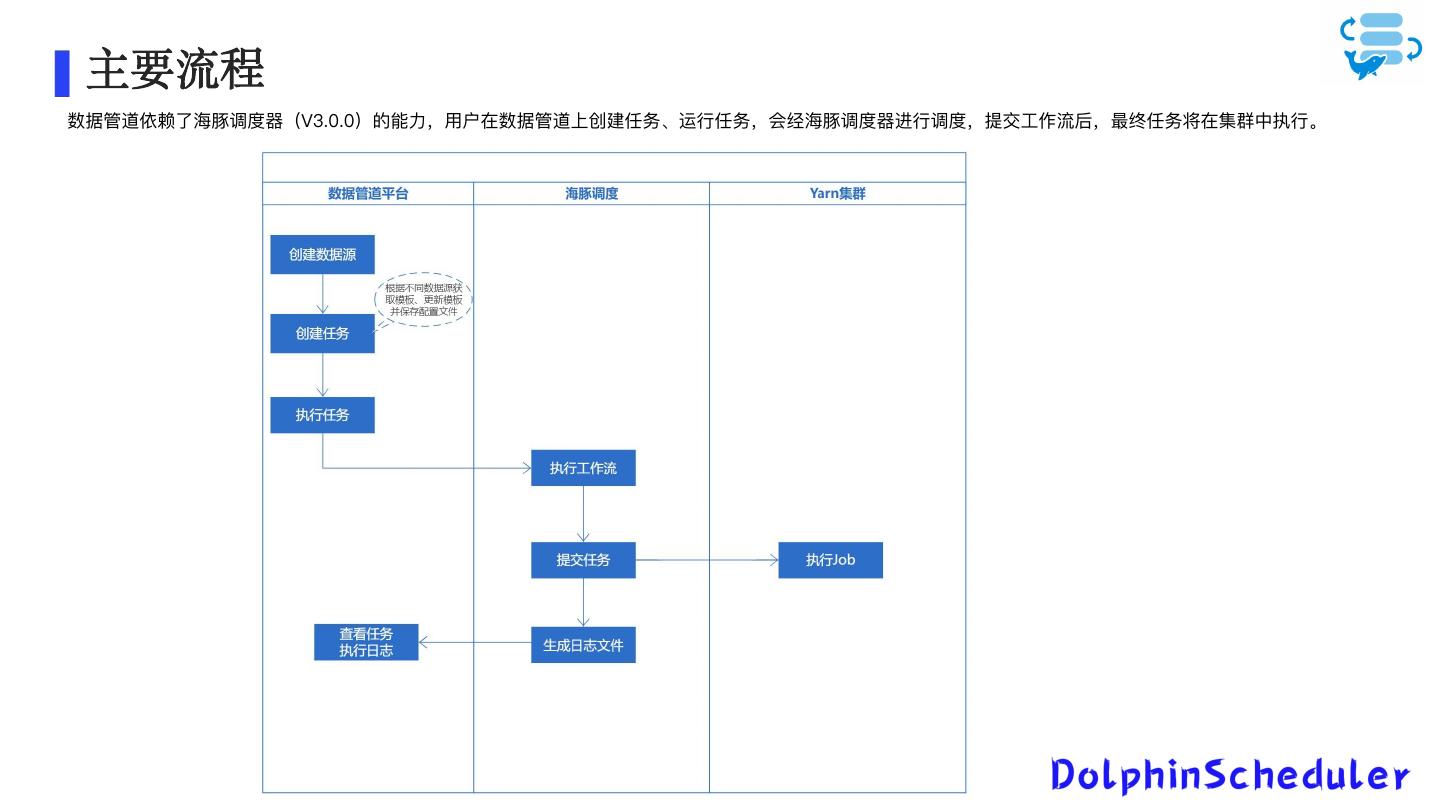
17 . 主要流程
数据管道依赖了海豚调度器(V3.0.0)的能力,用户在数据管道上创建任务、运行任务,会经海豚调度器进行调度,提交工作流后,最终任务将在集群中执行。
�
18 . 数据管道使用了哪些DolphinScheduler的api服务
数据管道前台使用了我们自定义的UI界面,后台的许多功能
使用了DolphinScheduler的api服务。
�
19 . 数据管道数据管道创建任务会生成工作流定义数据
用户在数据管道创建任务时,后台会将用户的配置解析为提交任务所需的配置文件,并组装好数据格式后,会请求DolphinScheduler的创建工作流定义接口。
�
20 .参数设置
用户在数据管道创建任务时,可以进行参数设置,这里我们使用了海豚调度器的内置时间参数进行参数赋值,然后在过滤条件里使用定义好的参数进行数据的过滤。
�
21 . 提交日志
从数据管道平台运行任务后,会调用DolphinScheduler的运行工作流接口,我们通过DolphinScheduler的提交任务日志详情接口拿到提交任务日志数据,用户可以
刷新、下载日志。
�
22 . 扩充实例列表支持实时任务断点续传
数据管道平台在创建任务时支持创建多个子任务。每个子任务均可查看实例列表。这里我们调用了DolphinScheduler的实例列表接口来展示运行信息。并在该接口的基
础上,添加了实例的运行状态、运行开始时间、运行结束时间、实例运行时长等。同时,我们提供了实时任务的停止、运行按钮,可支持实时任务的断点续传功能。
�
23 . 在使用DolphinScheduler时遇到的问题
问题1:获取到的任务状态不对
最初,我们在数据管道平台调用工作流实例列表接口获取实例的信息时,发现接口返回的state字段值是SUCCESS,但其实任务是执行失败的。于是就去仔细研究了一
下这个state字段其实只是海豚调度器提交任务时获取到的一个状态,并不能真实反映任务的运行状态,于是我们在改接口的基础上又添加了实例的运行状态的逻辑封
装。
问题2:DolphinScheduler集群扩容,workgroup分组遇到的问题
这个问题是这样,我们在扩容时新增的节点的也加入到了默认的default组,由于新扩容的节点和现在的work节点属于不同的hadoop集群,这样的话,提交任务到
default组,会存在这个组的节点不是属于同一个集群而报错。所以需要把这些新增的节点根据hadoop集群而进行分组。
最初修改了install_env.sh配置文件里面的works设置,分发文件,重启集群,但是通过海豚web界面发现work分组设置没有生效,新节点还是属于default组。为什么
没生效呢?找了好长的时间,最后发现新节点的worker-server的application.yaml配置里面看到groups是default,于是修改default为新的workgroup名称,再次重启
DolphinScheduler集群,分组就显示正常了。
问题3:资源中心配置
这个说起来也是因为我们的海豚调度上面有两个hadoop集群,配置一个hdfs,提交到另一个集群的任务可能会存在找不到文件的情况。我们知道对于 standalone环境,
可以选择本地文件目录作为上传文件夹,想了两个方案一个是NFS文件共享,另一个是OSS,我们选择了后者,OSS通过服务器挂载就像普通磁盘一样使用方便,还有
就是OSS底层是多副本存储,数据存储上和NFS相比更安全。
�
25 . 总结
得益于DolphinScheduler强大的能力、丰富的文档、火热的社区等多方面综合因素,我们在技术选项的时候首选了DolphinScheduler。
截止到当前数据管道最新版为止,DolphinScheduler对数据管道平台提供了强有力的支撑,使我们的开发工作重心可全面投入到数据管道本身产品功能上去,跟工作流
调度有关的实现直接调用DolphinScheduler的API服务即可,我们会在此基础上添加了针对数据管道平台场景的逻辑补充去完善数据管道的产品功能。
在后续的数据管道版本迭代中,我们会根据功能需求,继续深入研究我们尚未体验和使用的DolphinScheduler功能,也希望DolphinScheduler社区能够一直活跃下去,
DolphinScheduler能够越来越好。
�
26 .Website: https://dolphinscheduler.apache.org
GitHub:https://github.com/apache/dolphinscheduler
Wehchat:海豚调度
Slack: https://s.apache.org/dolphinscheduler-slack
Twitter : @dolphinschedule
Video:https://space.bilibili.com/515596012
�