















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
黄立-DolphinScheduler在长安车联网数据平台的实践
展开查看详情
1 . 2023 DolphinScheduler 在长安汽车车联网数 据平台的实践 黄立 长安软件高可用技术主管 Apache DolphinScheduler Committer
2 .目录 CONTENTS 01 车云业务概览 02 车云数据处理架构 03 DS运维&血缘 04 车联网数据架构展望
3 .01 车云业务概览
4 . 数字化对汽车进行深度重构 智能网联云成为设备控制中心、算法训练中心、生态运营中心,需具备高并发、高可用、大算力等特点 • 海量数据:伴随智能网联汽车的逐步普及,车上的电子设备逐渐增多,数据量也随之增长,云端需具备低成本的海量存储能力 • 并发交互:伴随智舱、智驾等一系列新兴场景的不断涌现,并发交互需求愈发旺盛,云端需具备高并发的实时处理能力 • 融合计算:伴随数据量和数据交互的增加,对数据的处理效率要求越来越高,云端需具备可伸缩的大算力 • 生态服务:需要开放、安全的合作伙伴连接能力; 具备多功能空间的轮式智能机器人 Intelligent Autobot with Multifunctional Space 配备电子功能 配备机械功能 金 机械产品 智能电子产品 融 娱 大型智能移动终端 乐 数据采集载体 云、数据、AI 能源储能单元 交 通 移动多功能空间 消 费 融合 Fusion
5 .消费者需要能持续进化的汽车 智能空间:也就是智能座舱,目前是新势力、主机厂用户体验最直接的争夺点,是用户的直接触点,主打场景体验 自动驾驶:量产场景下,目前行业聚焦L2+自动驾驶系统研发量产。高阶自动驾驶系统技术路线(国内主推C-V2X)、 商业闭环仍需时间检验。 适应复杂的人机交互 适应复杂的路况交通 Complex Human-Computer Interaction Adaption Complex Road Conditions Adaption 语音 手势 表情 强行加塞 近距跟车 非标车位
6 .分阶段实施数字化改造 启智 治数 上云 数字汽车4.0+ 智慧交通融合 数字汽车3.0 全场景数据+先进AI闭环进化 车辆数据赋能研发与经营 数字汽车2.0 数据+AI功能闭环进化 数字汽车1.0 车辆数据上云 生态应用上车 车辆功能上云 腾讯云 长安云
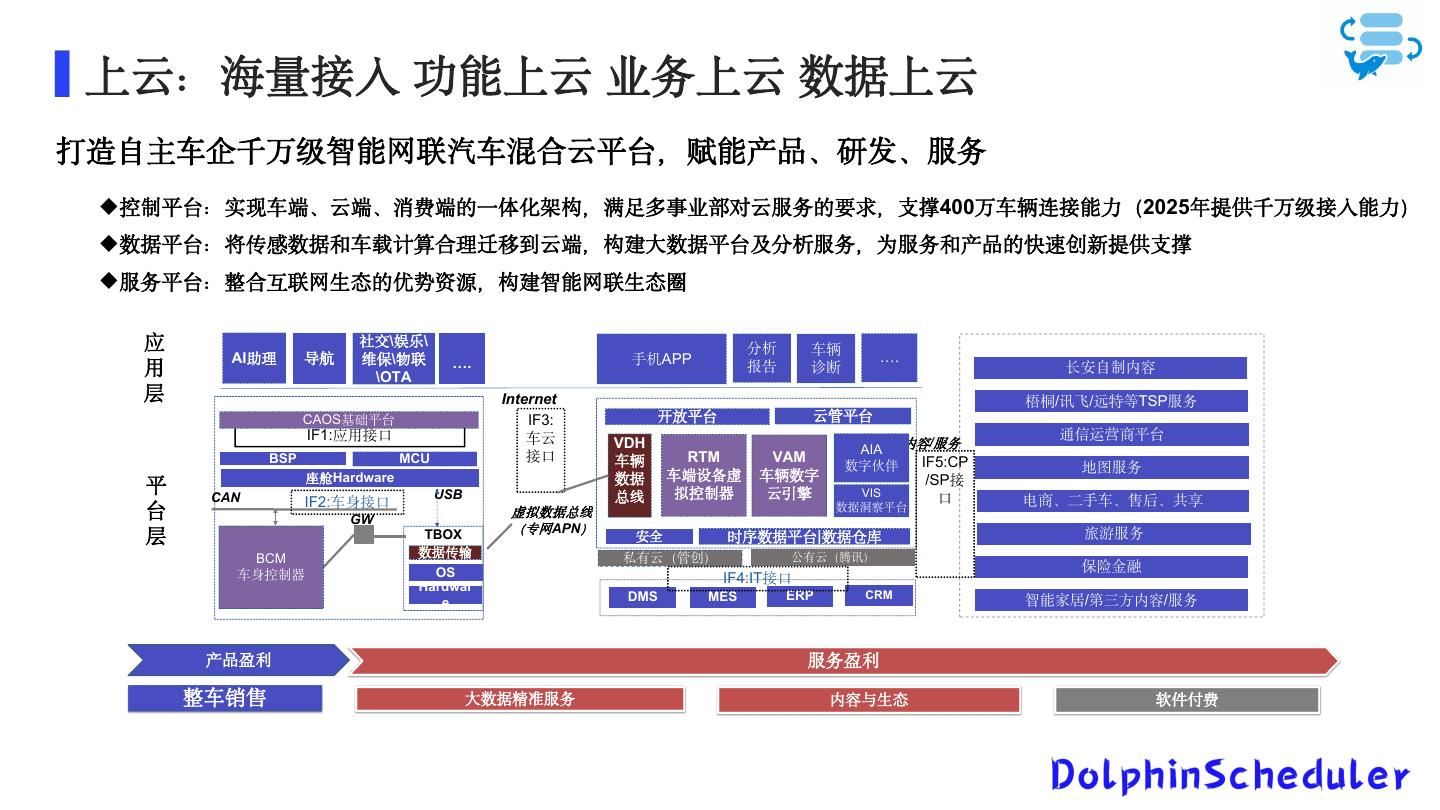
7 .上云:海量接入 功能上云 业务上云 数据上云 打造自主车企千万级智能网联汽车混合云平台,赋能产品、研发、服务 控制平台:实现车端、云端、消费端的一体化架构,满足多事业部对云服务的要求,支撑400万车辆连接能力(2025年提供千万级接入能力) 数据平台:将传感数据和车载计算合理迁移到云端,构建大数据平台及分析服务,为服务和产品的快速创新提供支撑 端 云 服务平台:整合互联网生态的优势资源,构建智能网联生态圈 应 社交\娱乐\ 分析 车辆 AI助理 导航 维保\物联 …. 手机APP …. 用 \OTA 报告 诊断 长安自制内容 层 Internet 梧桐/讯飞/远特等TSP服务 CAOS基础平台 IF3: 开放平台 云管平台 IF1:应用接口 车云 通信运营商平台 VDH AIA 内容/服务 BSP MCU 接口 车辆 RTM VAM IF5:CP 数字伙伴 地图服务 座舱Hardware 数据 车端设备虚 车辆数字 /SP接 平 CAN USB 总线 拟控制器 云引擎 VIS IF2:车身接口 口 电商、二手车、售后、共享 台 GW 虚拟数据总线 数据洞察平台 (专网APN) 层 TBOX 安全 时序数据平台|数据仓库 旅游服务 数据传输 BCM 私有云(管创) 公有云(腾讯) OS 内部IT系统 保险金融 车身控制器 IF4:IT接口 数据同步 Hardwar DMS MES ERP CRM 智能家居/第三方内容/服务 e 产品盈利 服务盈利 整车销售 大数据精准服务 内容与生态 软件付费
8 . 治数:车辆控制器数据上云改造及标准化 统一车载控制器超500项信号采集标准,构建云上海量数据存储与处理能力,确保高质量数据 统一车辆数据资产管理,从“采、治、管、用”进行全生命周期跟踪管理,确保数据隐私安全 数据标准化与质量管理 数据处理与监控 车况大数据 多 车 型 交互大数据 数 据 驾驶大数据 源 环境大数据 智能汽车云上数据资产管理
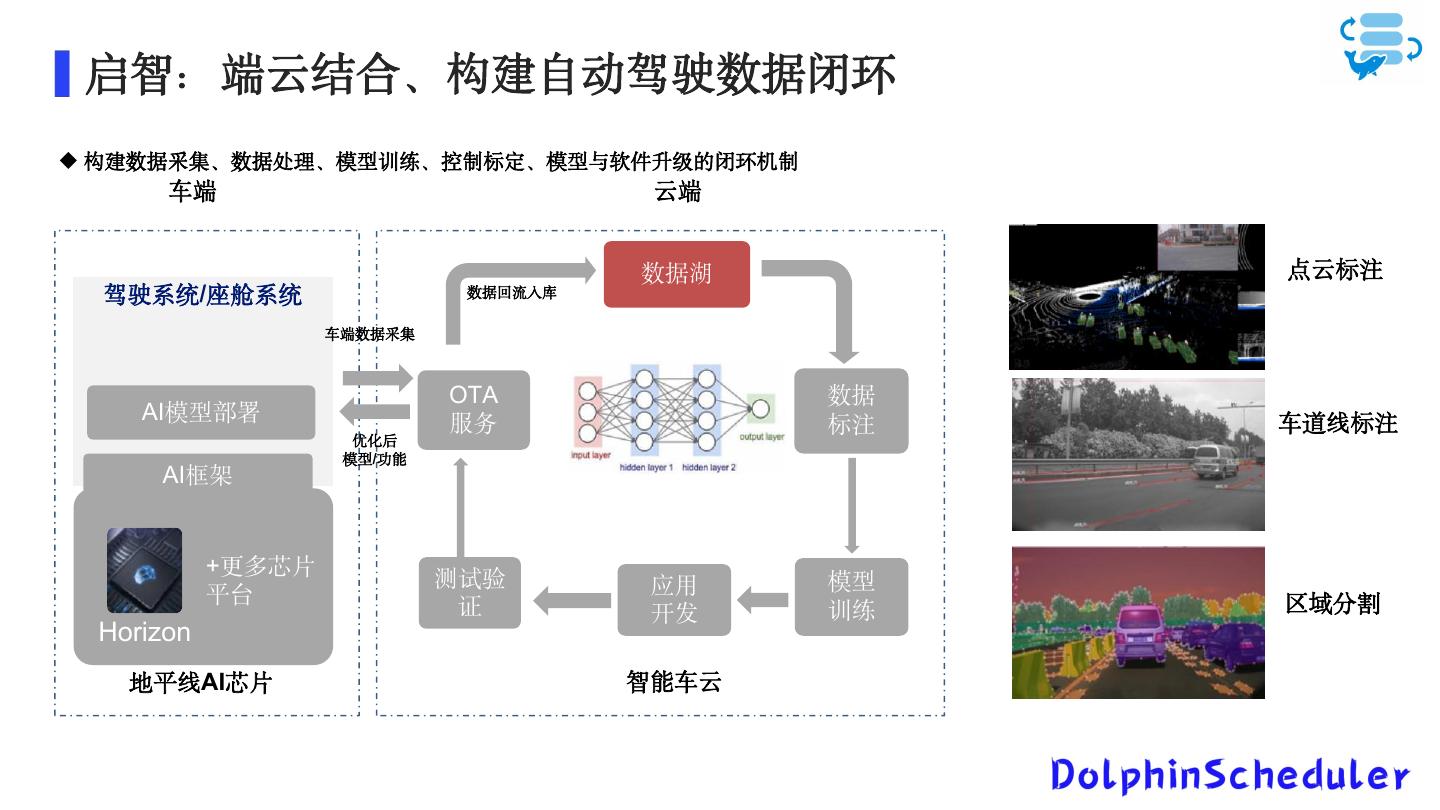
9 . 启智:端云结合、构建自动驾驶数据闭环 构建数据采集、数据处理、模型训练、控制标定、模型与软件升级的闭环机制 车端 云端 数据湖 点云标注 驾驶系统/座舱系统 数据回流入库 车端数据采集 OTA 数据 AI模型部署 服务 标注 车道线标注 优化后 模型/功能 AI框架 +更多芯片 测试验 应用 模型 平台 证 区域分割 开发 训练 Horizon 地平线AI芯片 智能车云
10 .02 车联网数据处理架构
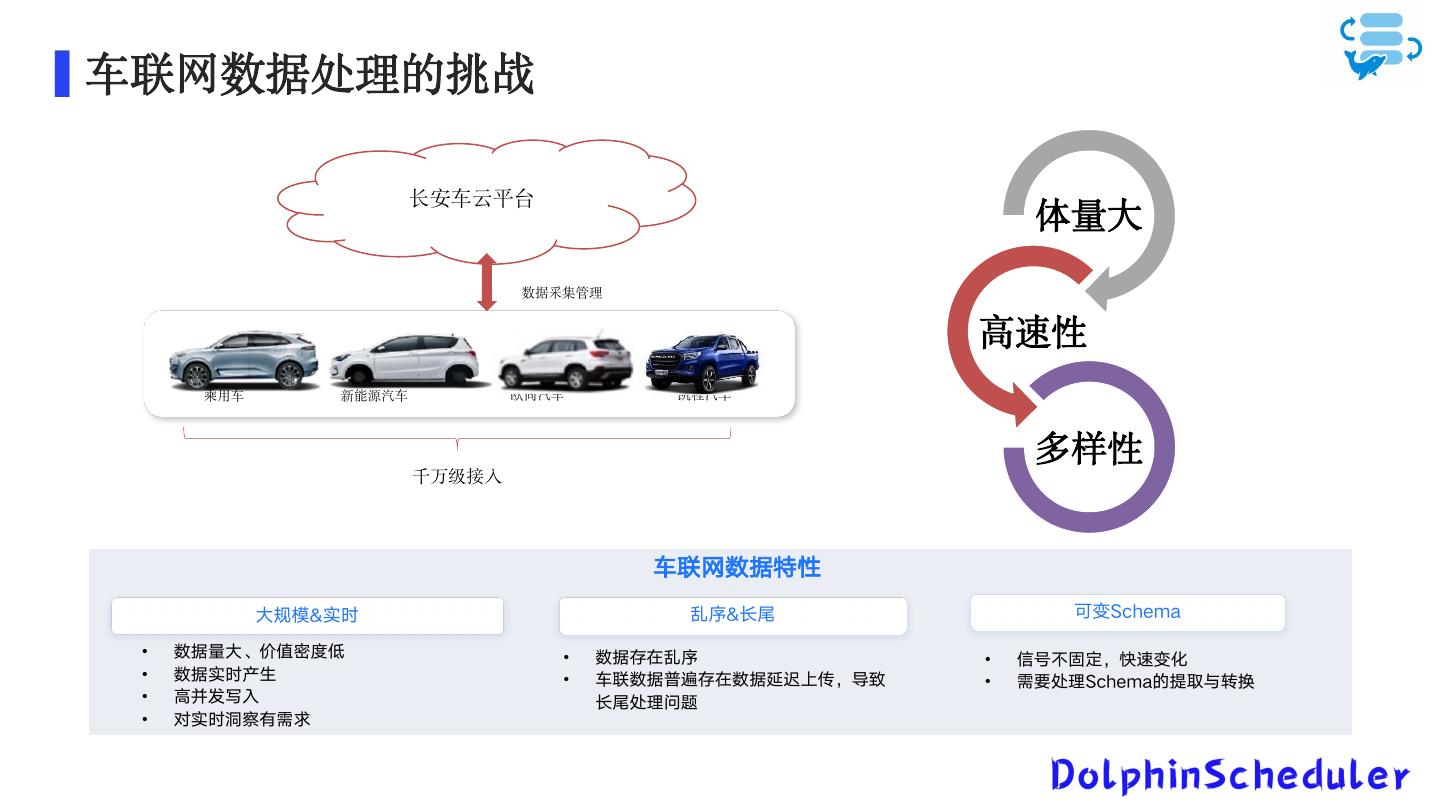
11 .车联网数据处理的挑战 长安车云平台 体量大 数据采集管理 高速性 乘用车 新能源汽车 欧尚汽车 凯程汽车 多样性 千万级接入 车联网数据特性 大规模&实时 乱序&长尾 可变Schema • 数据量大、价值密度低 • 数据存在乱序 • 信号不固定,快速变化 • 数据实时产生 • 车联数据普遍存在数据延迟上传,导致 • 需要处理Schema的提取与转换 • 高并发写入 长尾处理问题 • 对实时洞察有需求
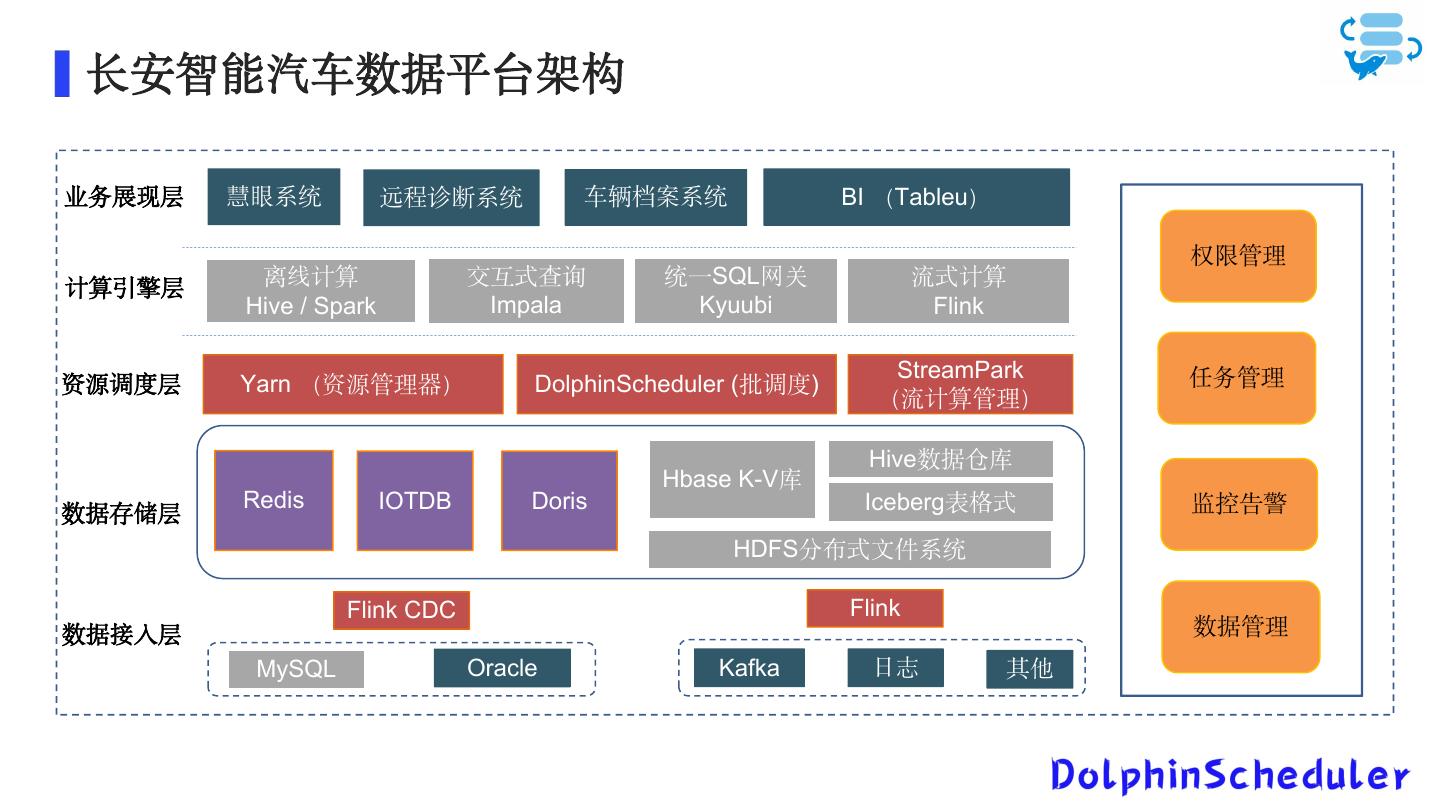
12 .长安智能汽车数据平台架构 业务展现层 慧眼系统 远程诊断系统 车辆档案系统 BI (Tableu) 权限管理 计算引擎层 离线计算 交互式查询 统一SQL网关 流式计算 Hive / Spark Impala Kyuubi Flink StreamPark 任务管理 资源调度层 Yarn (资源管理器) DolphinScheduler (批调度) (流计算管理) Hive数据仓库 Hbase K-V库 Redis IOTDB Doris Iceberg表格式 监控告警 数据存储层 HDFS分布式文件系统 Flink CDC Flink 数据接入层 数据管理 MySQL Oracle Kafka 日志 其他
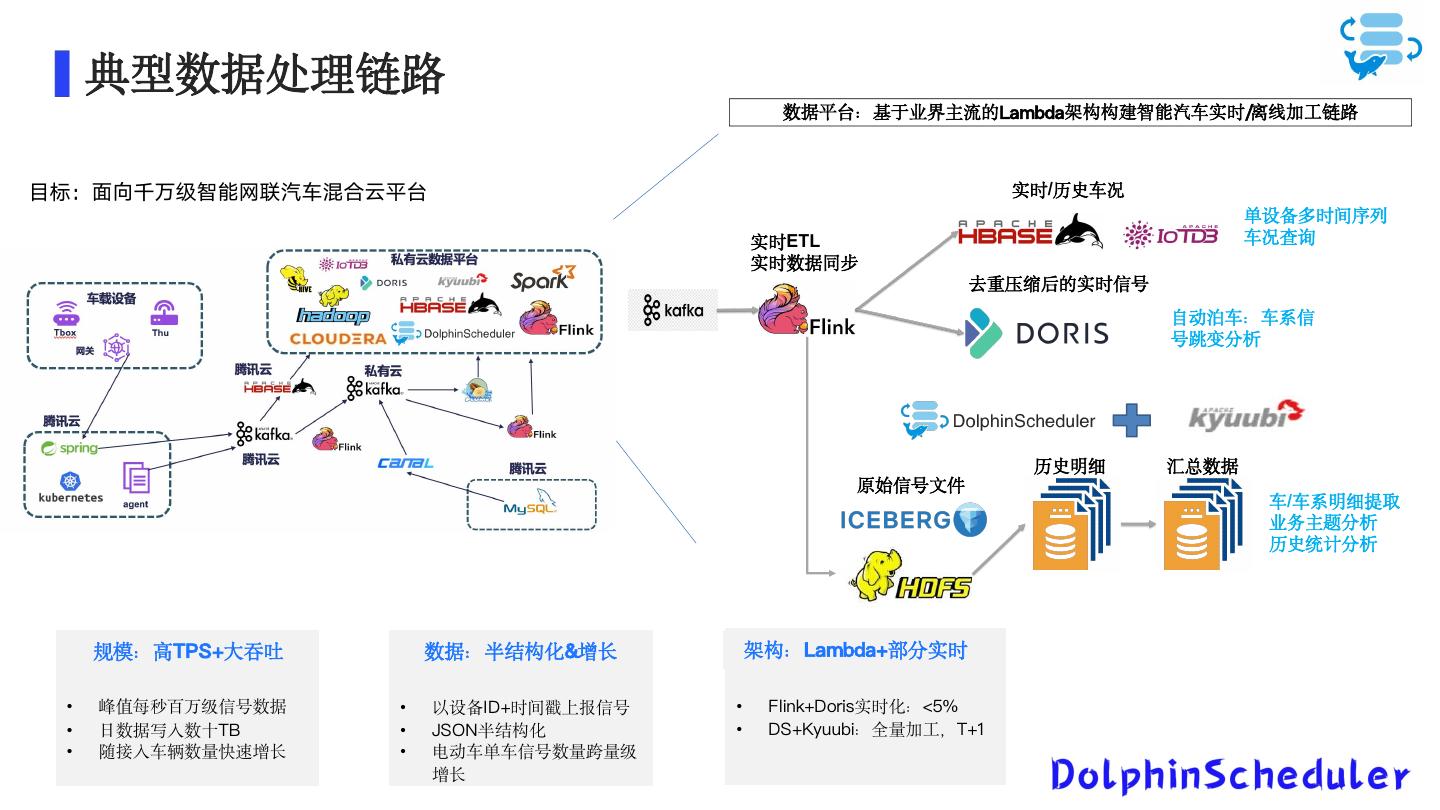
13 . 典型数据处理链路 数据平台:基于业界主流的Lambda架构构建智能汽车实时/离线加工链路 目标:面向千万级智能网联汽车混合云平台 实时/历史车况 单设备多时间序列 实时ETL 车况查询 实时数据同步 去重压缩后的实时信号 自动泊车:车系信 号跳变分析 历史明细 汇总数据 原始信号文件 车/车系明细提取 业务主题分析 历史统计分析 规模:高TPS+大吞吐 数据:半结构化&增长 架构:Lambda+部分实时 • 峰值每秒百万级信号数据 • 以设备ID+时间戳上报信号 • Flink+Doris实时化:<5% • 日数据写入数十TB • JSON半结构化 • DS+Kyuubi:全量加工,T+1 • 随接入车辆数量快速增长 • 电动车单车信号数量跨量级 增长
14 .03 DS运维&血缘
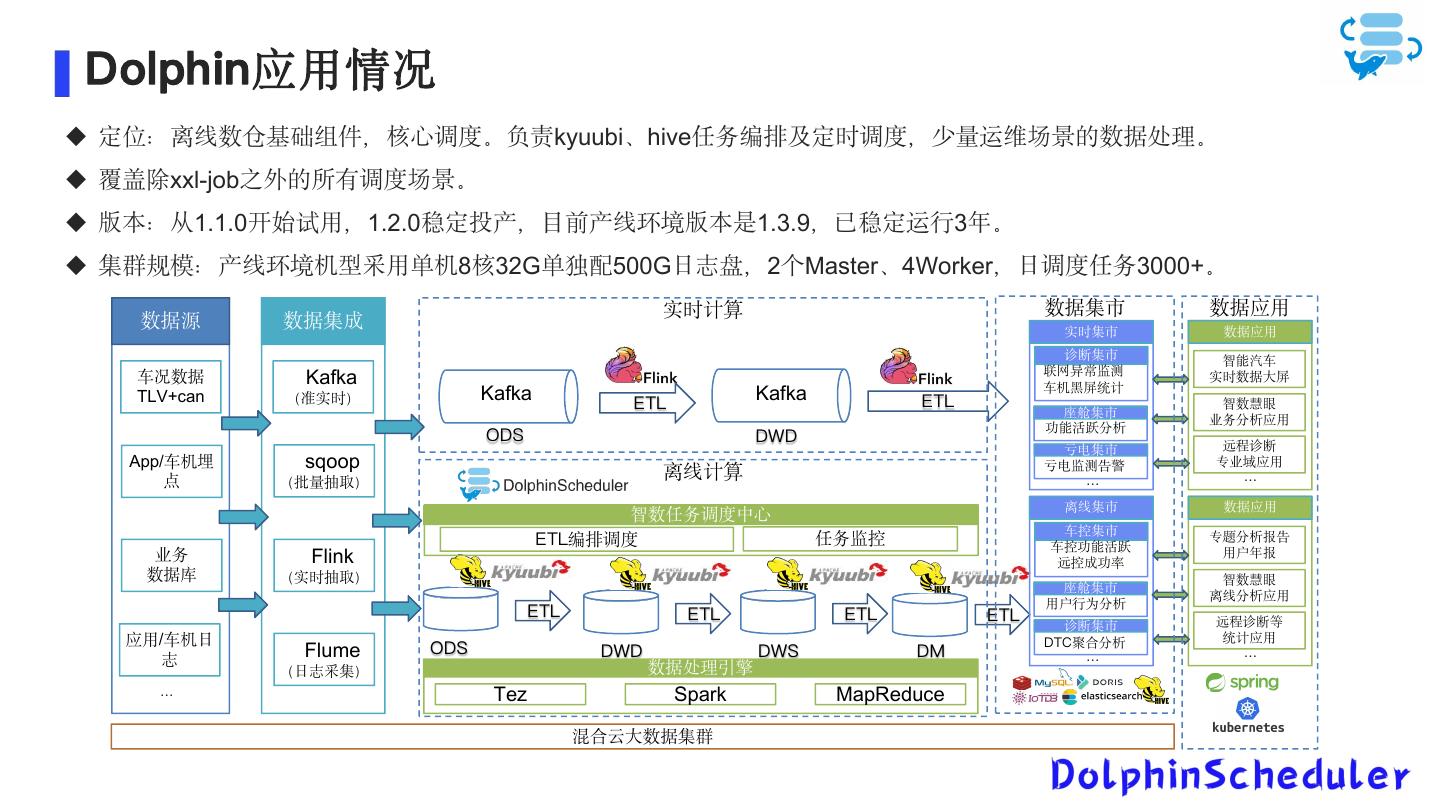
15 . Dolphin应用情况 定位:离线数仓基础组件,核心调度。负责kyuubi、hive任务编排及定时调度,少量运维场景的数据处理。 覆盖除xxl-job之外的所有调度场景。 版本:从1.1.0开始试用,1.2.0稳定投产,目前产线环境版本是1.3.9,已稳定运行3年。 集群规模:产线环境机型采用单机8核32G单独配500G日志盘,2个Master、4Worker,日调度任务3000+。 实时计算 数据集市 数据应用 数据源 数据集成 实时集市 数据应用 诊断集市 智能汽车 车况数据 Kafka 联网异常监测 实时数据大屏 TLV+can (准实时) Kafka ETL Kafka ETL 车机黑屏统计 智数慧眼 座舱集市 业务分析应用 功能活跃分析 ODS DWD 远程诊断 亏电集市 App/车机埋 sqoop 离线计算 亏电监测告警 专业域应用 点 (批量抽取) … … 离线集市 数据应用 智数任务调度中心 车控集市 ETL编排调度 任务监控 车控功能活跃 专题分析报告 业务 Flink 远控成功率 用户年报 数据库 (实时抽取) 智数慧眼 座舱集市 离线分析应用 用户行为分析 ETL ETL ETL ETL 诊断集市 远程诊断等 应用/车机日 DTC聚合分析 统计应用 志 Flume 新的分析重点 ODS DWD DWS DM … … (日志采集) 数据处理引擎 … Tez Spark MapReduce 混合云大数据集群
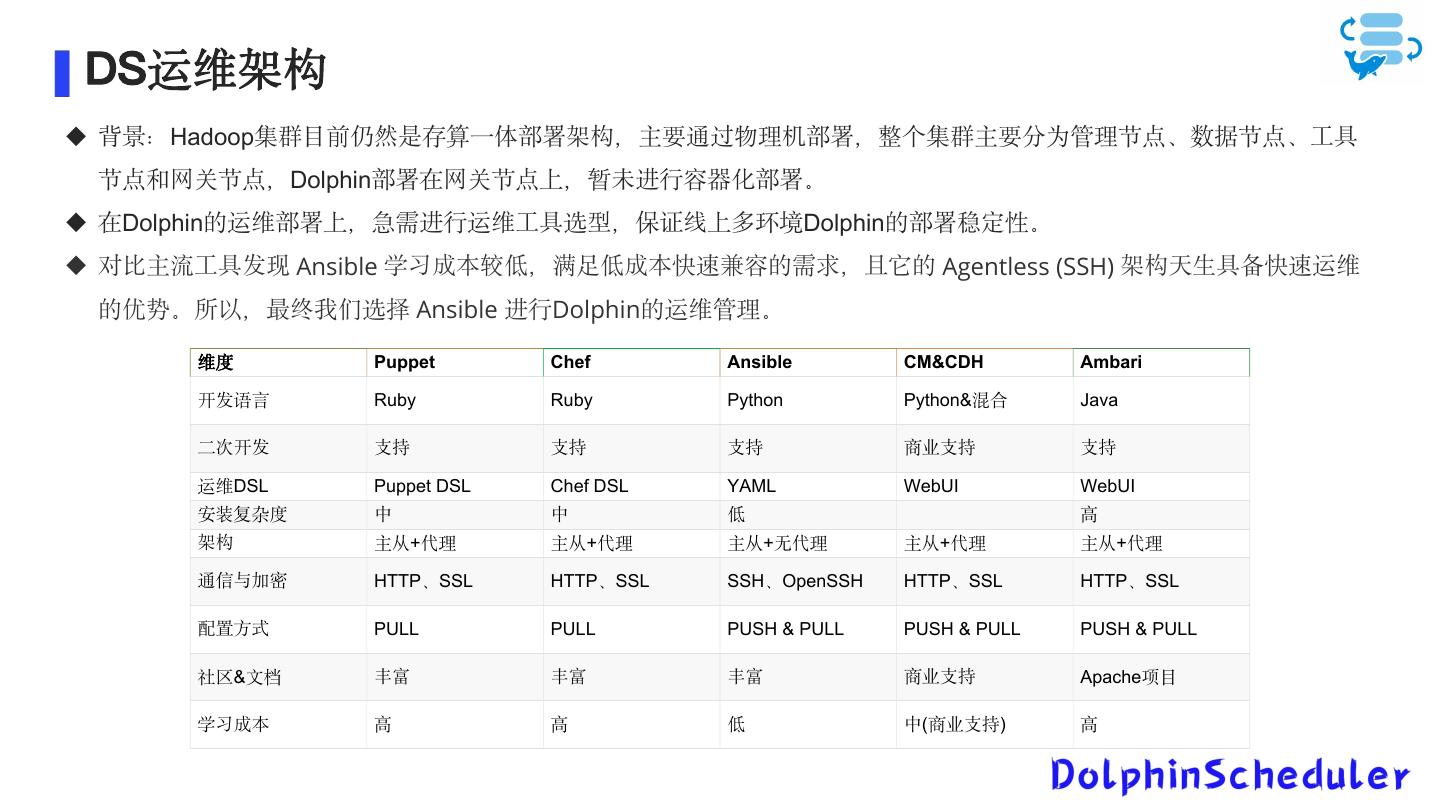
16 . DS运维架构 背景:Hadoop集群目前仍然是存算一体部署架构,主要通过物理机部署,整个集群主要分为管理节点、数据节点、工具 节点和网关节点,Dolphin部署在网关节点上,暂未进行容器化部署。 在Dolphin的运维部署上,急需进行运维工具选型,保证线上多环境Dolphin的部署稳定性。 对比主流工具发现 Ansible 学习成本较低,满足低成本快速兼容的需求,且它的 Agentless (SSH) 架构天生具备快速运维 的优势。所以,最终我们选择 Ansible 进行Dolphin的运维管理。 维度 Puppet Chef Ansible CM&CDH Ambari 开发语言 Ruby Ruby Python Python&混合 Java 二次开发 支持 支持 支持 商业支持 支持 运维DSL Puppet DSL Chef DSL YAML WebUI WebUI 安装复杂度 中 中 低 高 架构 主从+代理 主从+代理 主从+无代理 主从+代理 主从+代理 通信与加密 HTTP、SSL HTTP、SSL SSH、OpenSSH HTTP、SSL HTTP、SSL 配置方式 PULL PULL PUSH & PULL PUSH & PULL PUSH & PULL 社区&文档 丰富 丰富 丰富 商业支持 Apache项目 学习成本 高 高 低 中(商业支持) 高
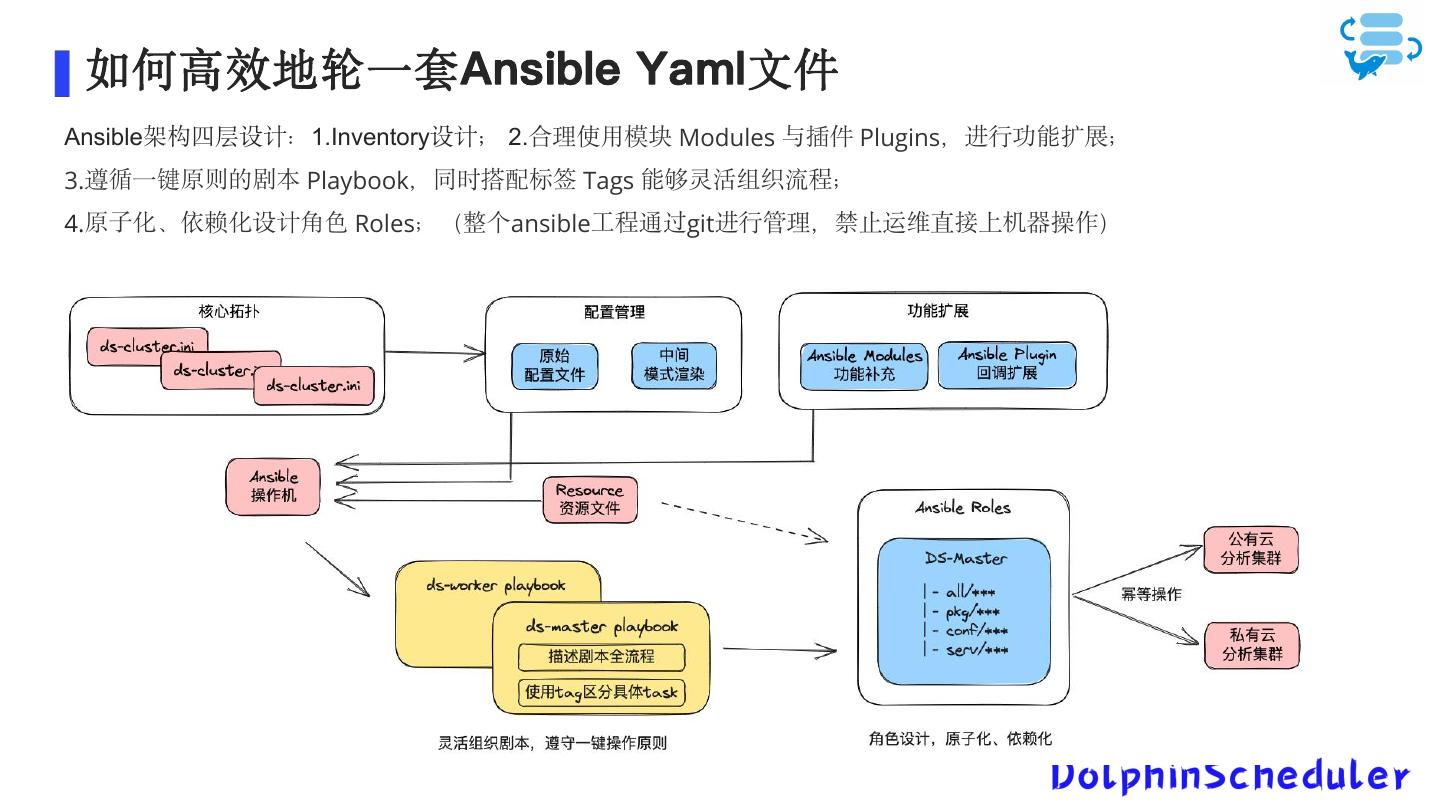
17 . 如何高效地轮一套Ansible Yaml文件 Ansible架构四层设计:1.Inventory设计; 2.合理使用模块 Modules 与插件 Plugins,进行功能扩展; 3.遵循一键原则的剧本 Playbook,同时搭配标签 Tags 能够灵活组织流程; 4.原子化、依赖化设计角色 Roles;(整个ansible工程通过git进行管理,禁止运维直接上机器操作)
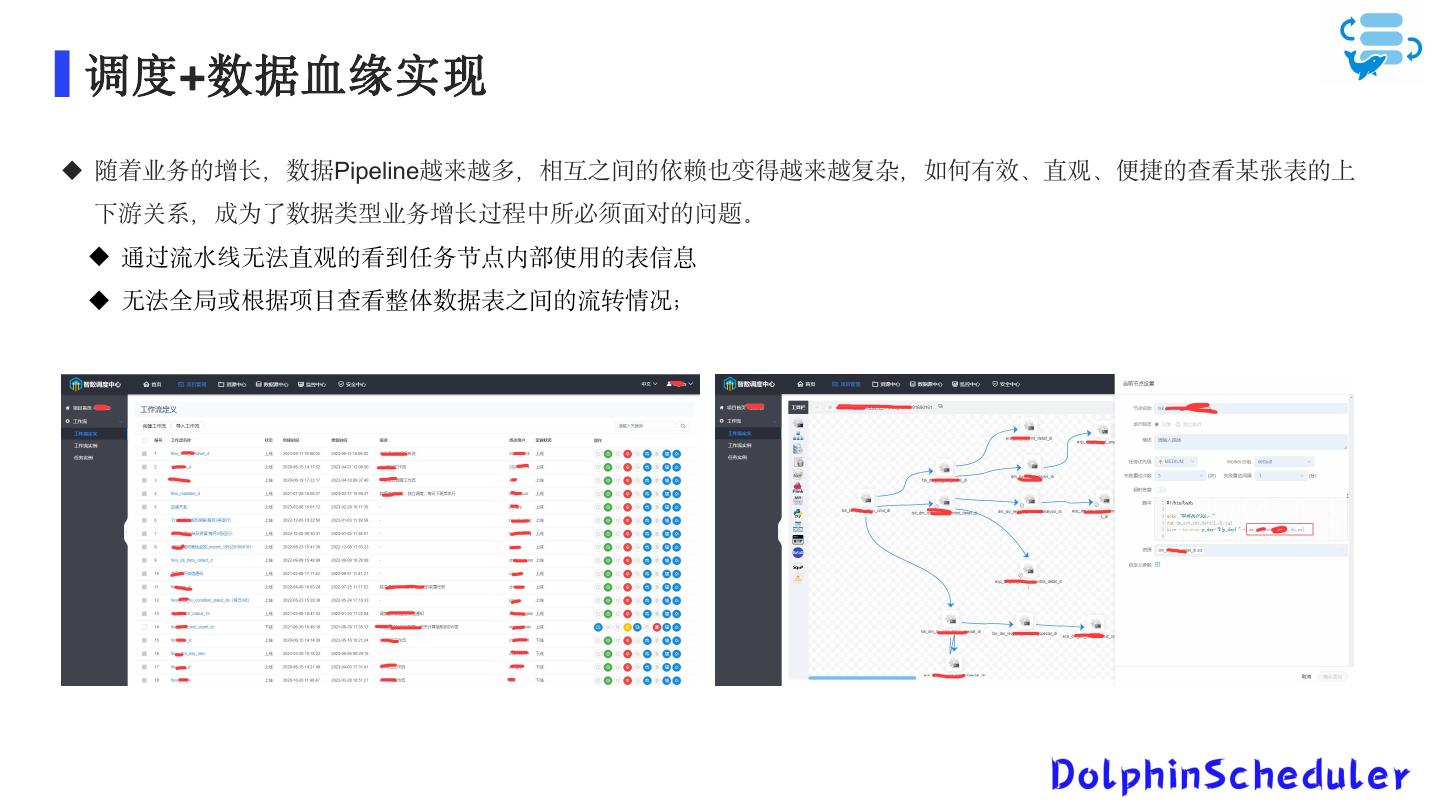
18 . 调度+数据血缘实现 随着业务的增长,数据Pipeline越来越多,相互之间的依赖也变得越来越复杂,如何有效、直观、便捷的查看某张表的上 下游关系,成为了数据类型业务增长过程中所必须面对的问题。 通过流水线无法直观的看到任务节点内部使用的表信息 无法全局或根据项目查看整体数据表之间的流转情况;
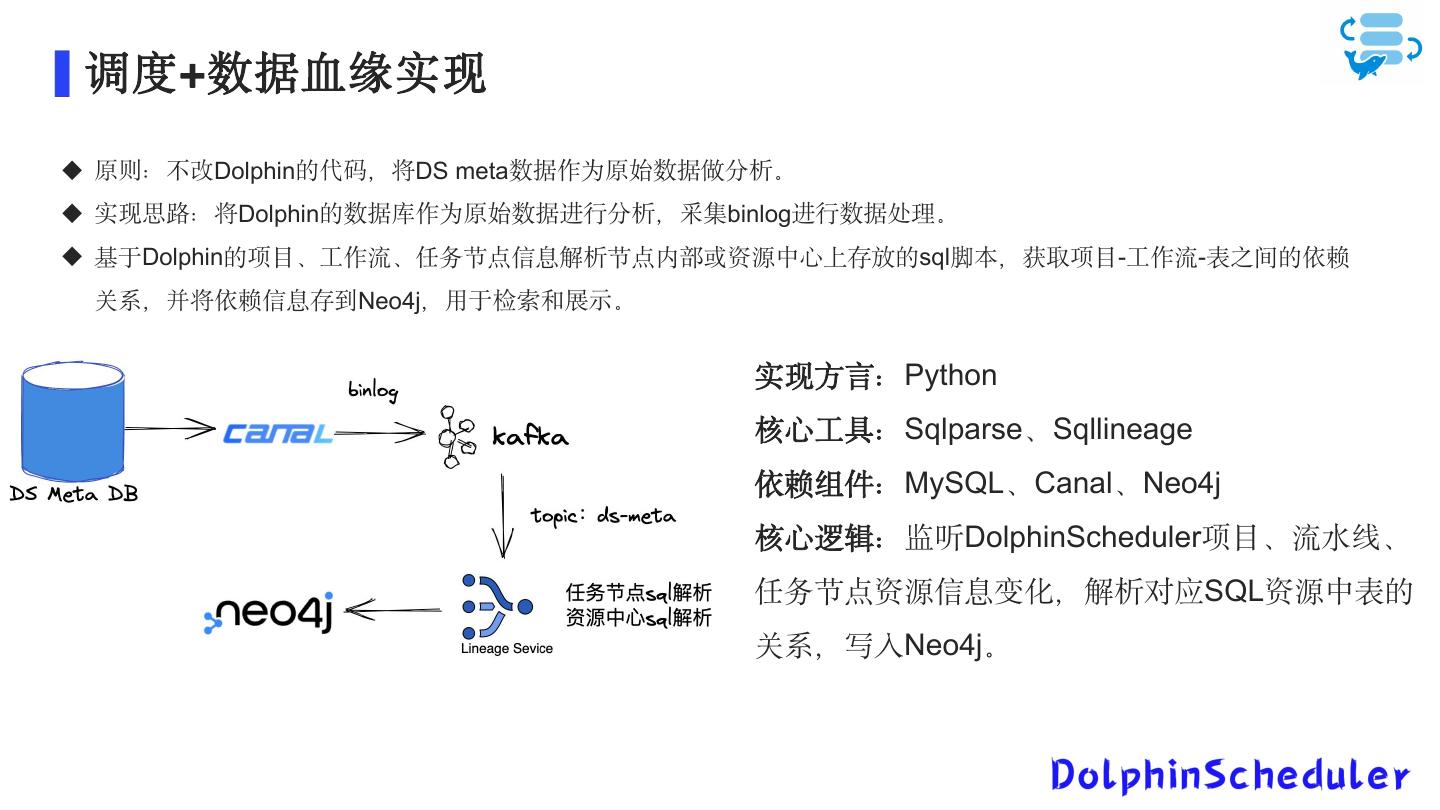
19 . 调度+数据血缘实现 原则:不改Dolphin的代码,将DS meta数据作为原始数据做分析。 实现思路:将Dolphin的数据库作为原始数据进行分析,采集binlog进行数据处理。 基于Dolphin的项目、工作流、任务节点信息解析节点内部或资源中心上存放的sql脚本,获取项目-工作流-表之间的依赖 关系,并将依赖信息存到Neo4j,用于检索和展示。 实现方言:Python 核心工具:Sqlparse、Sqllineage 依赖组件:MySQL、Canal、Neo4j 核心逻辑:监听DolphinScheduler项目、流水线、 任务节点资源信息变化,解析对应SQL资源中表的 关系,写入Neo4j。
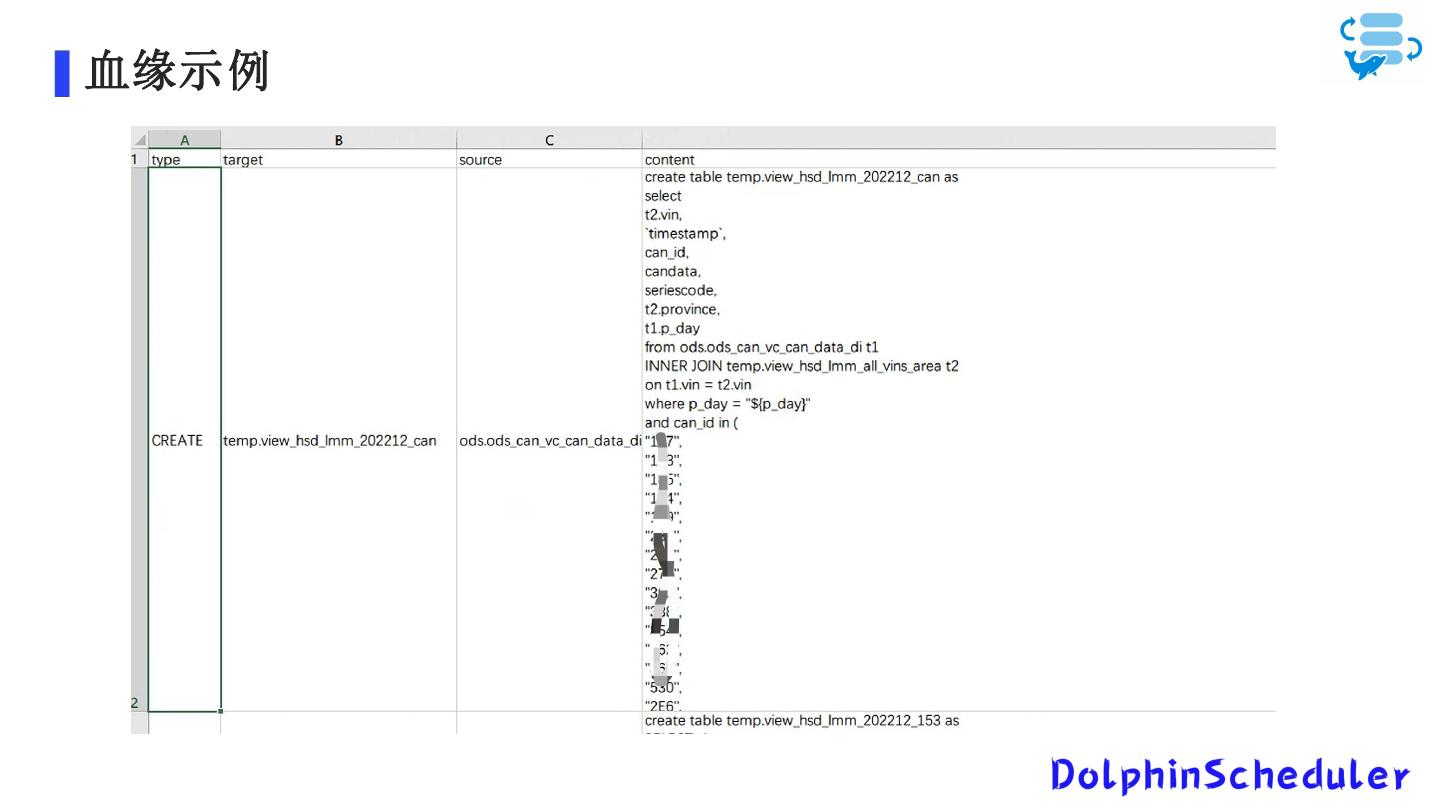
20 .血缘示例
21 .04 车联网数据架构展望
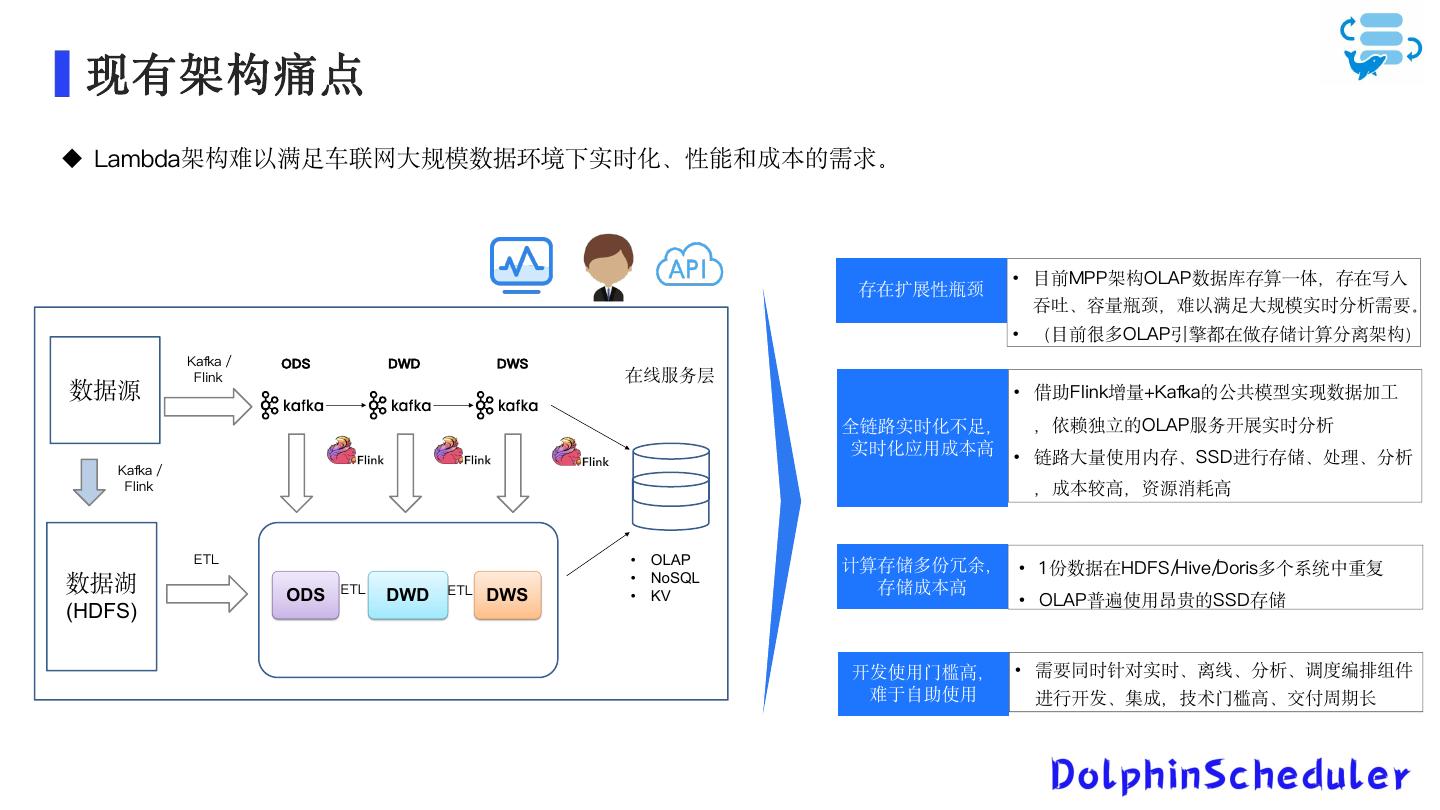
22 . 现有架构痛点 Lambda架构难以满足车联网大规模数据环境下实时化、性能和成本的需求。 • 目前MPP架构OLAP数据库存算一体,存在写入 存在扩展性瓶颈 吞吐、容量瓶颈,难以满足大规模实时分析需要。 • (目前很多OLAP引擎都在做存储计算分离架构) Kafka / ODS DWD DWS Flink 在线服务层 数据源 • 借助Flink增量+Kafka的公共模型实现数据加工 全链路实时化不足, ,依赖独立的OLAP服务开展实时分析 实时化应用成本高 • 链路大量使用内存、SSD进行存储、处理、分析 Kafka / Flink ,成本较高,资源消耗高 ETL • OLAP 计算存储多份冗余, • 1 份数据在HDFS/Hive/Doris多个系统中重复 • NoSQL 数据湖 ODS ETL DWD ETL DWS • KV 存储成本高 • OLAP普遍使用昂贵的SSD存储 (HDFS) 开发使用门槛高, • 需要同时针对实时、离线、分析、调度编排组件 难于自助使用 进行开发、集成,技术门槛高、交付周期长
23 .对下一代平台的要求 两个统一的Lakehouse 关键的技术能力 统一计算:统一批计算/流计算/交互计算 • 一套元数据/存储引擎/SQL引擎实现基于增量的统一存储和计算 Data Freshness 数据写入:任何表支持实时/离线插入、改写,数据实时可见 数据处理:基于增量化模式统一流式处理和批处理,支持增量数 - 根据交互性的要求和可用的资 源量 据的自动识别、增量计算,极大提升实时数据处理吞吐、降低计 决定什么时候算,怎么 算成本;不再区分离线、流式计算、交互计算系统,一套SQL满 算 统一的系统支持 足需求; 优化执行计划、资源调 度 数据分析:仓内直接进行高性能查询分析,无需数据移动到加速引擎,减 少不必要的数据冗余存储和计算; Resource costs Query performance • 统一的增量化形态(计算/存储) 统一存储:使用廉价的数据湖上建仓 增量识别:基于元数据+文件版本的增量识别机制 湖上建仓:使用大规模低成本的数据湖上构建数仓,支持存算分离架构 增量计算:自动化,用户只需写全量逻辑,增量逻辑自动化生成,无需用户管理 非结构数据管理与分析:统一Meta安全管理湖上的结构化、非结构化、 半结构化数据,支持AI负载,支持非结构化数据的处理与分析 任意复杂的全量SQL查询自动增量化:破除对SQL算子限制,更满足生产使用需要
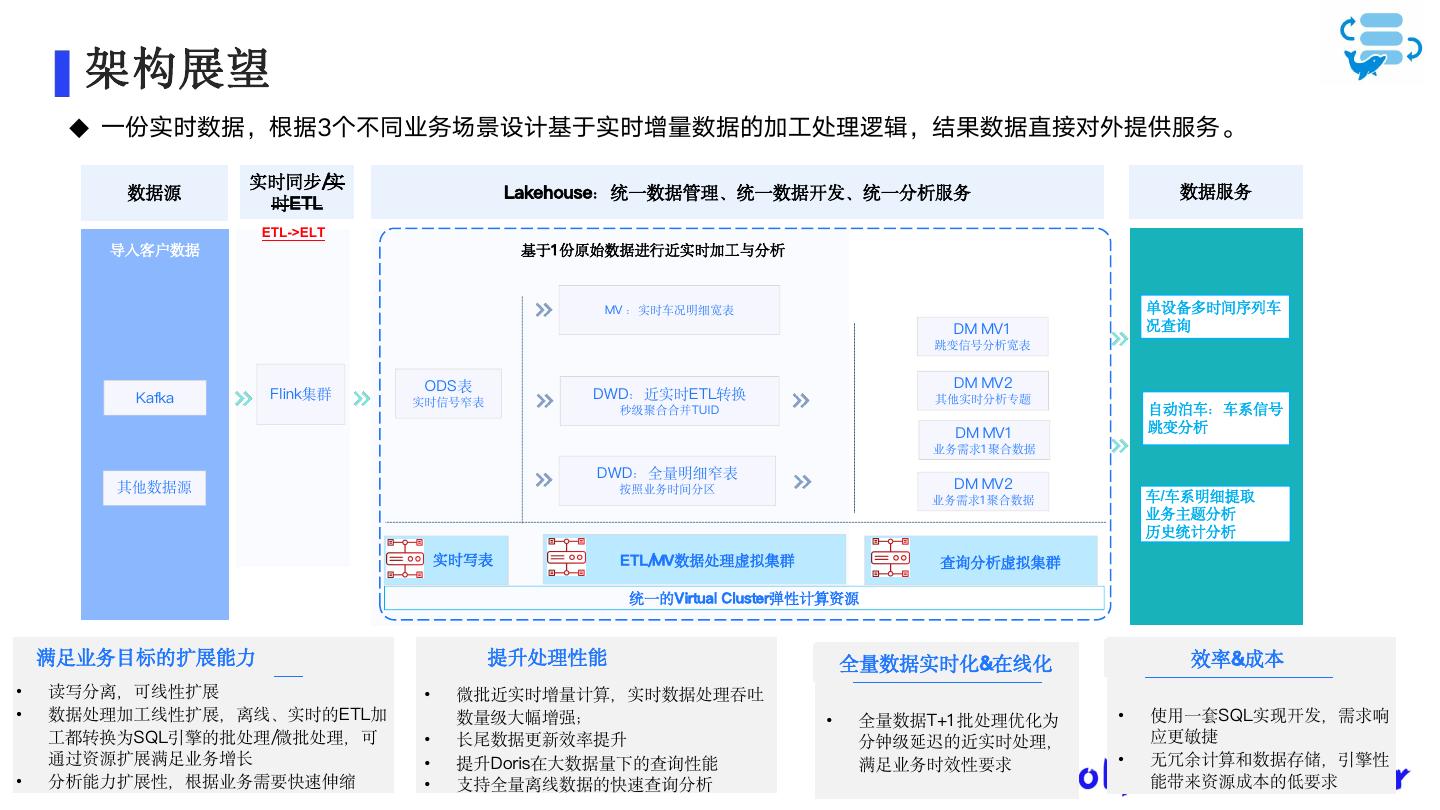
24 . 架构展望 一份实时数据,根据3个不同业务场景设计基于实时增量数据的加工处理逻辑,结果数据直接对外提供服务。 实时同步/实 数据源 Lakehouse:统一数据管理、统一数据开发、统一分析服务 数据服务 时ETL ETL->ELT 导入客户数据 基于1 份原始数据进行近实时加工与分析 MV :实时车况明细宽表 单设备多时间序列车 DM MV1 况查询 跳变信号分析宽表 ODS表 DM MV2 Kafka Flink集群 实时信号窄表 DWD:近实时ETL转换 其他实时分析专题 秒级聚合合并TUID 自动泊车:车系信号 DM MV1 跳变分析 业务需求1 聚合数据 DWD:全量明细窄表 其他数据源 按照业务时间分区 DM MV2 业务需求1 聚合数据 车/车系明细提取 业务主题分析 历史统计分析 实时写表 ETL/MV数据处理虚拟集群 查询分析虚拟集群 统一的Virtual Cluster弹性计算资源 满足业务目标的扩展能力 提升处理性能 全量数据实时化&在线化 效率&成本 • 读写分离,可线性扩展 • 微批近实时增量计算,实时数据处理吞吐 • 数据处理加工线性扩展,离线、实时的ETL加 数量级大幅增强; • 全量数据T+1 批处理优化为 • 使用一套SQL实现开发,需求响 工都转换为SQL引擎的批处理/微批处理,可 • 长尾数据更新效率提升 分钟级延迟的近实时处理, 应更敏捷 通过资源扩展满足业务增长 • 提升Doris在大数据量下的查询性能 满足业务时效性要求 • 无冗余计算和数据存储,引擎性 • 分析能力扩展性,根据业务需要快速伸缩 • 支持全量离线数据的快速查询分析 能带来资源成本的低要求
25 .Website: https://dolphinscheduler.apache.org GitHub:https://github.com/apache/dolphinscheduler Wehchat:海豚调度 Slack: https://s.apache.org/dolphinscheduler-slack Twitter : @dolphinschedule Video:https://space.bilibili.com/515596012
26 . THANKS! Ending
3秒后跳转登录页面
去登陆

