1 . 2023 DolphinScheduler 在蔚来汽车一站式数据治 理开发平台的应用改造 张金明 是 蔚来汽车 大数据平台研发工程师
2 .目录 CONTENTS 01 背景 02 应用现状 03 技术改造 xx
3 .01 背景
4 .业务痛点 数据缺乏治理,数仓不规范、不完整 • 没有统一的数据仓库,无全域的数据资产视图 • 存在数据孤岛; 工具散乱,用户权限不统一、学习成本高 • 用户需要在多个工具之间切换,导致开发效率降低 • 底层运维成本高; 数据需求响应周期长,找数难、取数难 • 无沉淀的数据资产与中台能力,重复处理原始数据; • 业务数据需求从提出到获取结果的周期长
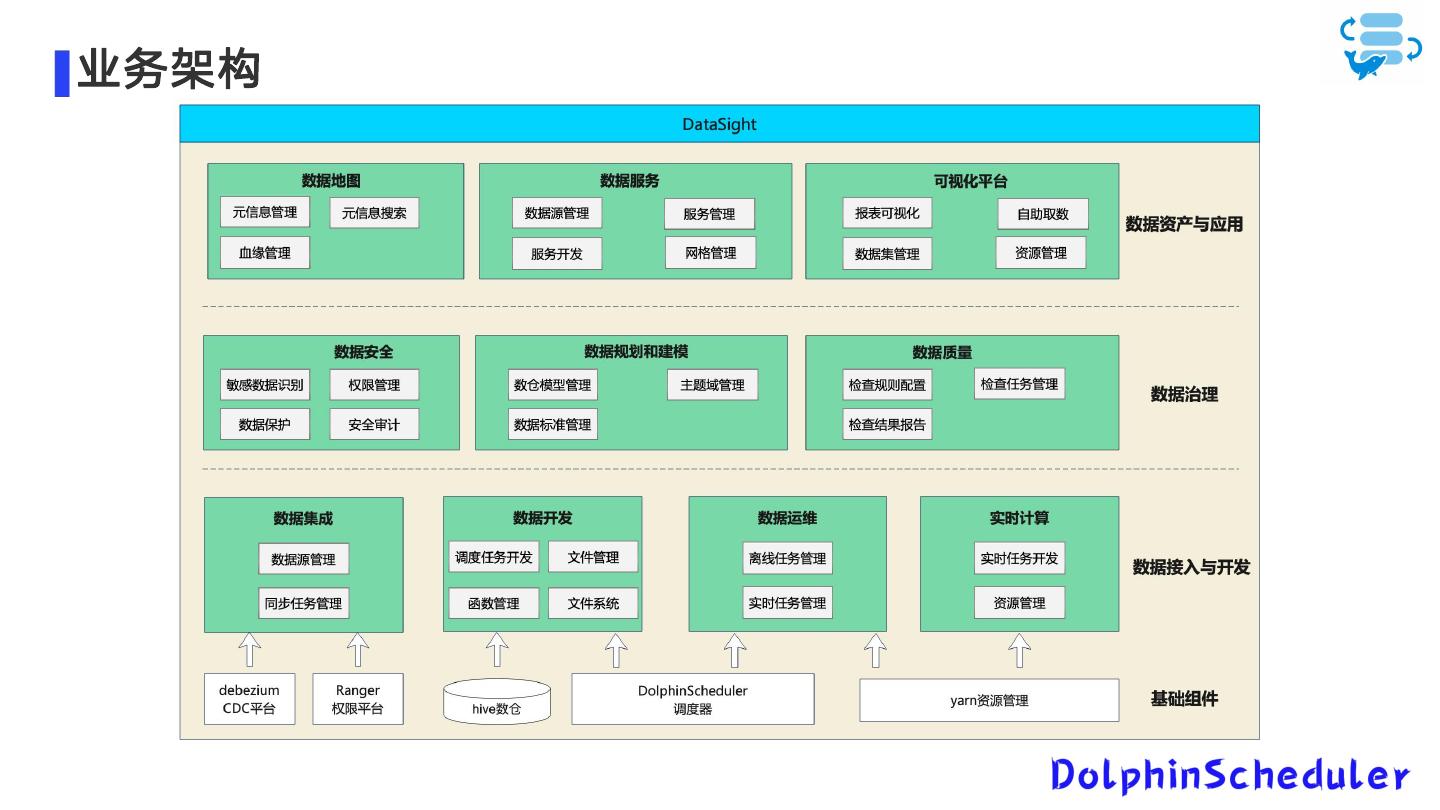
5 .业务架构
6 .02 应用现状
7 .作业现状 机器 • 2台master:8c 32g • 6台worker:16c 64g • 1台alert:8c 32g 版本 • 2.0.7
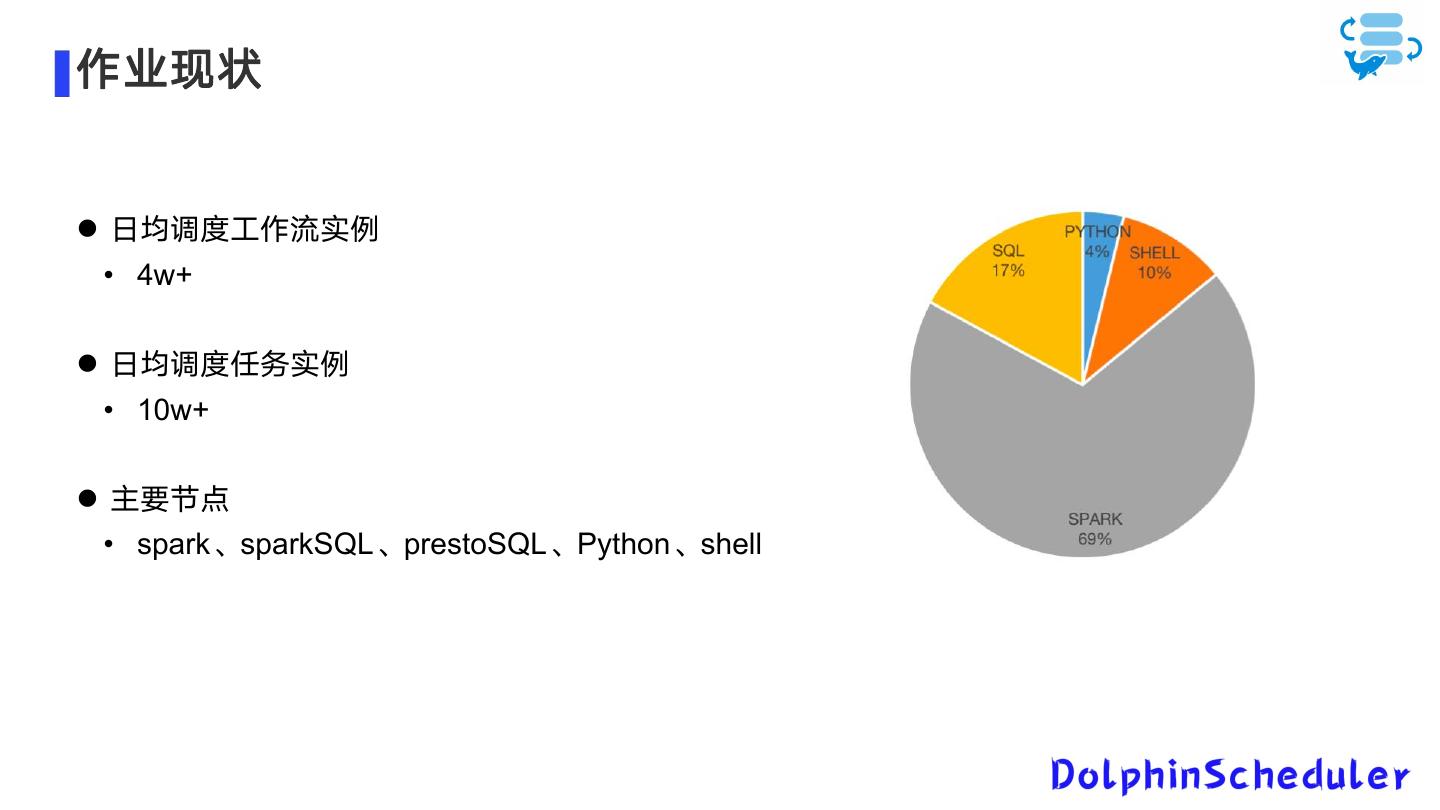
8 .作业现状 日均调度工作流实例 • 4w+ 日均调度任务实例 • 10w+ 主要节点 • spark、sparkSQL、prestoSQL、Python、shell
9 .03 技术改造
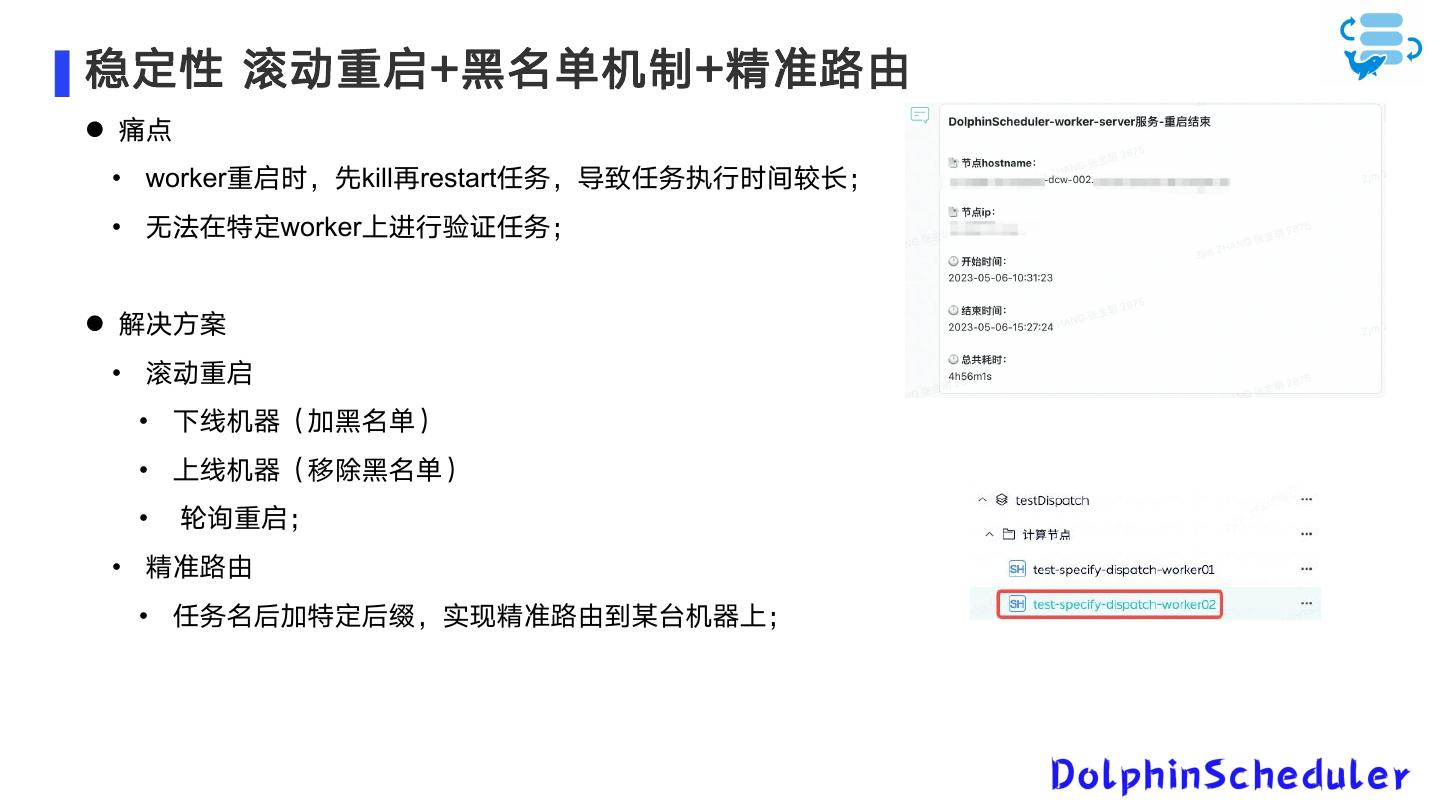
10 .稳定性 滚动重启+黑名单机制+精准路由 痛点 • worker重启时,先kill再restart任务,导致任务执行时间较长; • 无法在特定worker上进行验证任务; 解决方案 • 滚动重启 • 下线机器(加黑名单) • 上线机器(移除黑名单) • 轮询重启; • 精准路由 • 任务名后加特定后缀,实现精准路由到某台机器上;
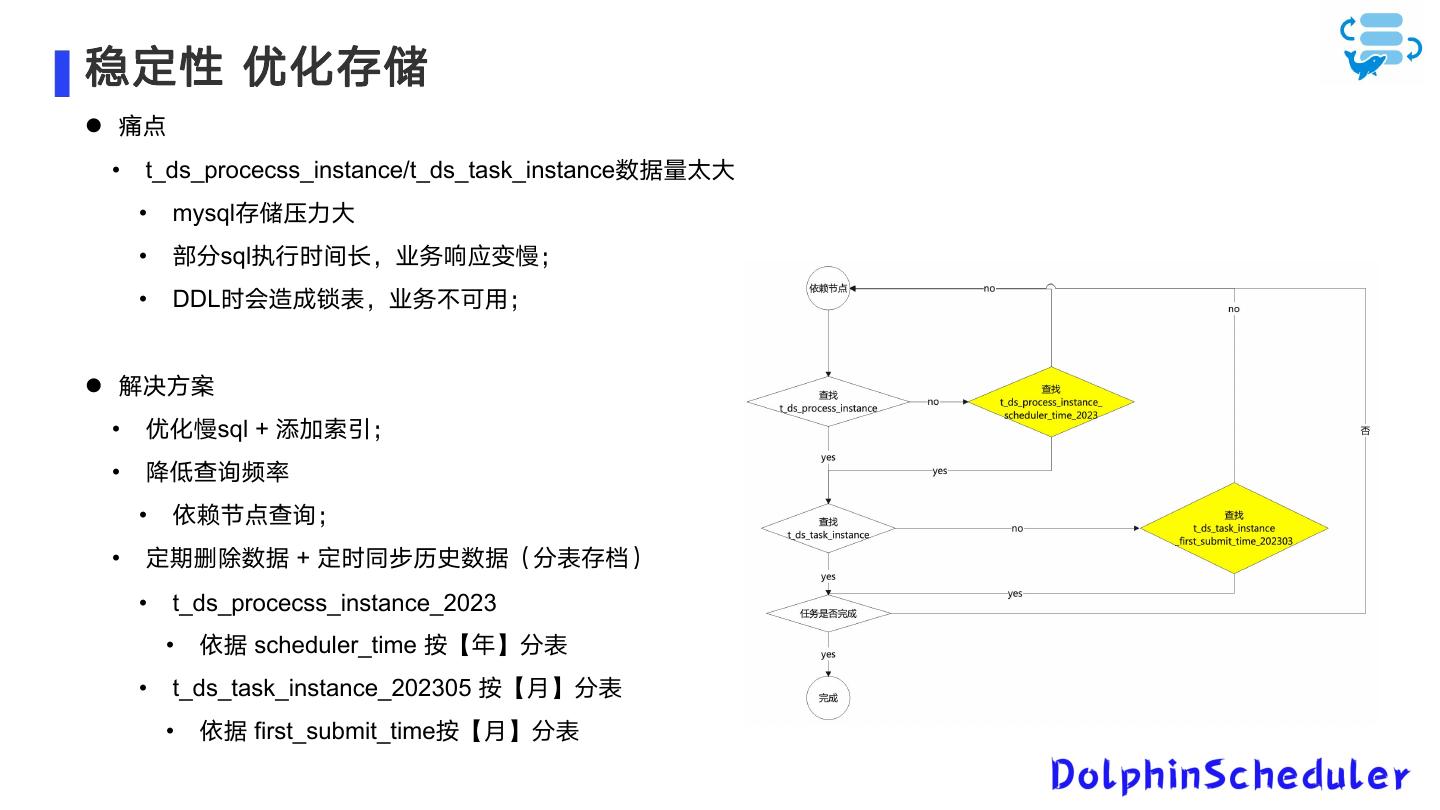
11 .稳定性 优化存储 痛点 • t_ds_procecss_instance/t_ds_task_instance数据量太大 • mysql存储压力大 • 部分sql执行时间长,业务响应变慢; • DDL时会造成锁表,业务不可用; 解决方案 • 优化慢sql + 添加索引; • 降低查询频率 • 依赖节点查询; • 定期删除数据 + 定时同步历史数据(分表存档) • t_ds_procecss_instance_2023 • 依据 scheduler_time 按【年】分表 • t_ds_task_instance_202305 按【月】分表 • 依据 first_submit_time按【月】分表
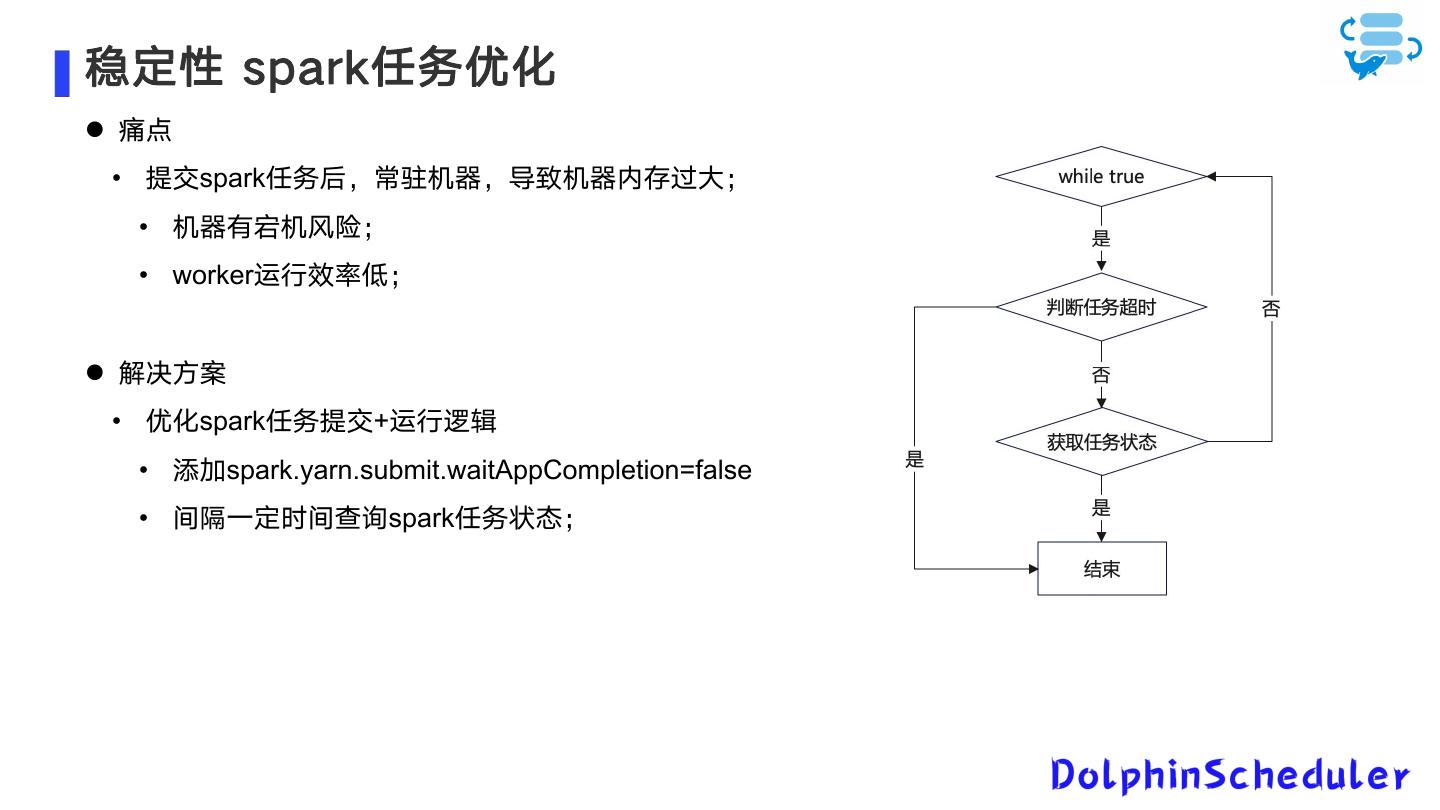
12 .稳定性 spark任务优化 痛点 • 提交spark任务后,常驻机器,导致机器内存过大; • 机器有宕机风险; • worker运行效率低; 解决方案 • 优化spark任务提交+运行逻辑 • 添加spark.yarn.submit.waitAppCompletion=false • 间隔一定时间查询spark任务状态;
13 .易用性 依赖节点优化 痛点 • 使用规则不符合用户需求; • 单次查询不到上游即失败; • 日志内容显示信息不全,不友好; • 无法自定义依赖范围; 解决方案 • 修改查询逻辑为继续等待 • 超过24小时自动失败 • 支持强制成功; • 支持用户自定义依赖范围; • 优化日志输出;
14 .易用性 补数任务优化 痛点 • 补数任务没有进度提示; • 并行补数流程实例不严格按照时间顺序; • 停止并行补数任务逻辑比较麻烦; 解决方案 • 并行任务引入线程池; • 并行任务停止逻辑优化 • shutdown这个线程池
15 .易用性 多SQL执行 痛点 • 多SQL需要多节点执行浪费集群资源; • 自定义环境变量无法实现; • 无法跟踪sparkSQL的运行日志; 解决方案 • 拆分sql • 支持多条SQL同时执行; • 在sparkSQL执行前拦截执行 • (select engine_id() as engine_id)
16 .Website: https://dolphinscheduler.apache.org GitHub:https://github.com/apache/dolphinscheduler Wehchat:海豚调度 Slack: https://s.apache.org/dolphinscheduler-slack Twitter : @dolphinschedule Video:https://space.bilibili.com/515596012
17 . THANKS! Ending
确定删除吗?