展开查看详情
1 . 2022
基于Apache
DolphinScheduler
对千亿级数据的应用
实践
讲师 钟霈合
�
2 .目录
CONTENTS
01 背景
02 海量数据处理
03 应用场景
04 未来规划
�
3 . 1.1 需求分析
01 1.2 任务调度对比
背景
1.3 选择DS的理由
1.4 大数据平台架构
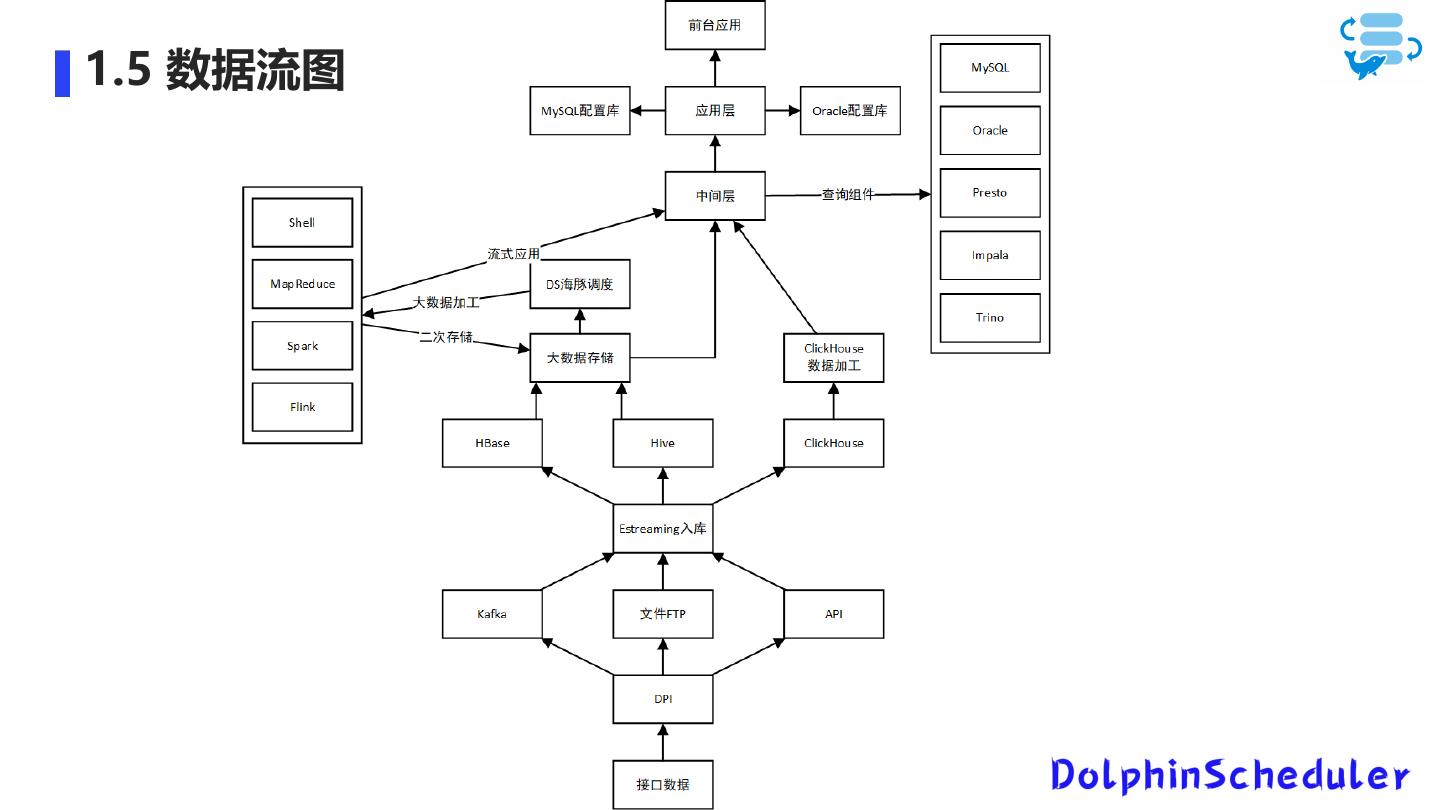
1.5 数据流图
�
4 .1.1 需求分析
1、支持多租户的权限控制
任务调度系统不仅是大数据部门在用,会提供给其余部门、其余厂商去使用。
2、上手难度简单,支持可视化任务管理
不只是研发团队会深入使用任务调度,数仓团队、数据库团队、业务团队都会基于任务调度去
跑一些任务,如果是必须要写代码才能很好使用的话,就推广起来难度很大。
3、支持对任务及节点状态进行监控
一是需要有对节点的监控,可以清晰看到节点负载情况。二是需要有对任务的监控,任务失败
与否、运行情况要一目了然。
�
5 .1.1 需求分析
4、支持较为方便的重跑、补数
数据特性分为实时、周期、离线三种,对于不同特性的数据,需要很好的支持重跑,并且在数
据出问题后,可以补前面的数据。
5、支持高可用HA、弹性扩容、故障容错
对于集群运维和集群管理,不同的项目和场景需要的方案是不一样的,并且需要支持节点、任
务的高可靠和故障容错。
6、支持时间参数
会在DS上使用ETL进行周期调度,如果任务调度系统可以支持时间参数,那在不同的组件中时
间参数可以统一管理。
�
6 .1.2 任务调度对比
Crontab:不支持多租户权限管理、平台管理、分发执行等功能,支持分钟级别的调度,不支持重跑。
Rundeck:最基本的用法就是封装shell脚本,分为企业版和付费版,付费版功能较少
xxl-job:一款国产开发的轻量级分布式调度工具,对大数据组件解耦合,功能较少
Elastic-Job:基于Quartz的无中心化弹性分布式任务调度系统,运维使用复杂
Azkaban:一个轻量级的任务调度框架,可视化支持较差,任务需要打zip包,使用不便
AirFlow:界面很高大上,需要使用Python进行DAG图的绘制,无法做到低代码任务调度
Oozie:集成在Hadoop中的大数据任务调度框架,需要使用xml进行配置,上手难度高
�
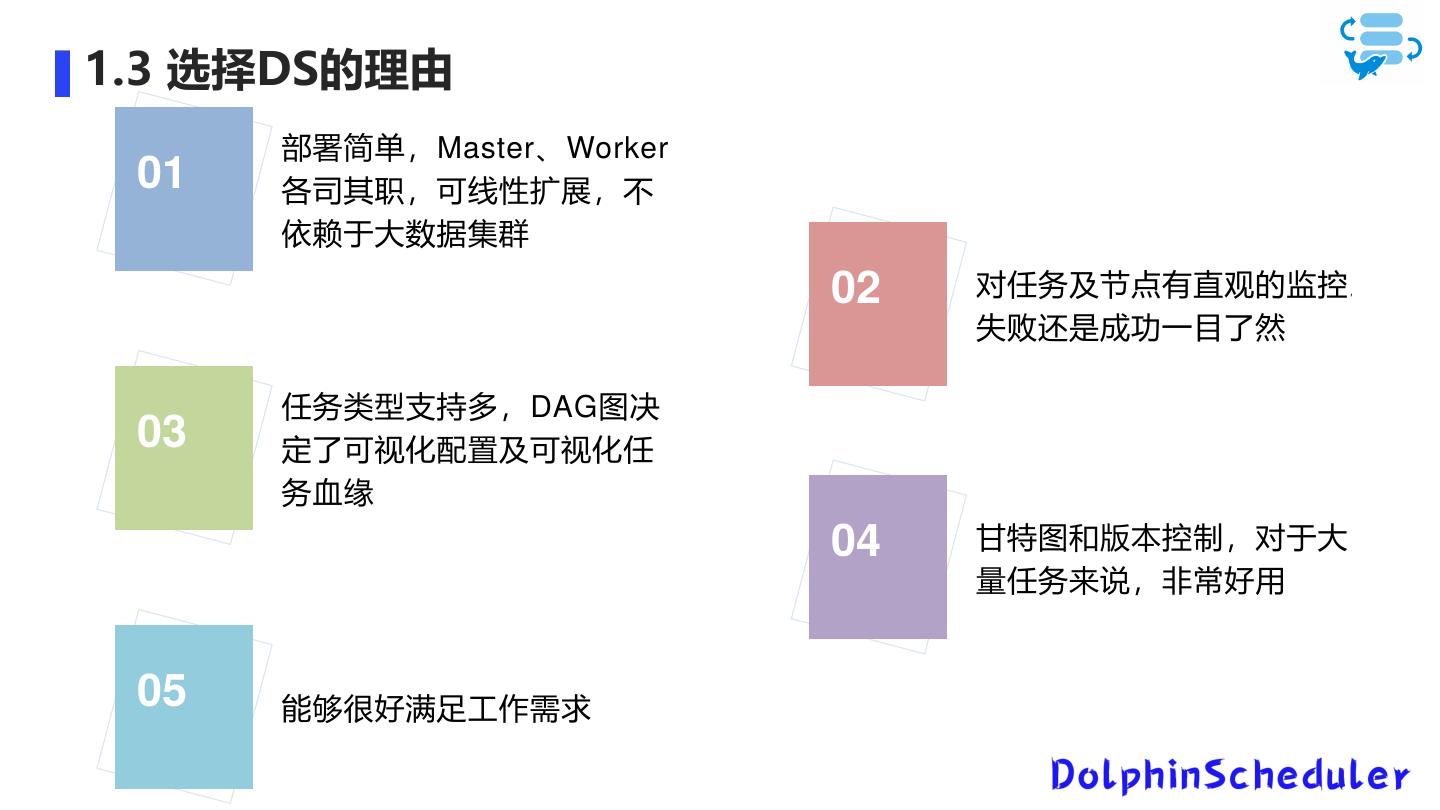
7 .1.3 选择DS的理由
部署简单,Master、Worker
01 各司其职,可线性扩展,不
依赖于大数据集群
02 对任务及节点有直观的监控 ,
失败还是成功一目了然
任务类型支持多,DAG图决
03 定了可视化配置及可视化任
务血缘
04 甘特图和版本控制,对于大
量任务来说,非常好用
05 能够很好满足工作需求
�
10 . 2.1 数据需求
02 2.2 数据同步选型
海量数据处理
2.3 ClickHouse优化
2.4 海量数据处理加工
2.5 数据同步操作
�
11 .2.1 数据需求
• 数据量:每天上千亿条
• 字段数:上百个字段,String类型居多
• 数据流程:在数据仓库中进行加工,加工完成的数据放入CK,应用直
接查询CK的数据
本章节主要讲解数据计算+数据加
• 存储周期:21天~60天
工+数据同步的一个完整技术流程,
其对于数据的需求如下所示: • 查询响应:对于部分字段需要秒级响应
�
12 .2.2 数据同步选型 Sqoop:
01 DS上集成了Sqoop任务类型,但是对于Hive到
ClickHouse的需求,Sqoop是无法支持的
Flink :
02 实时流架构,增加消息队列,额外数据开销 编写程序,
,
运维不便,高吞吐量场景不是首选
Spark&SparkSQL :
03 占用大量Yarn资源,作为二期工程在集群扩容后进行迭
代
SeaTunnel :
04 底层封装Spark、Flink,在本场景中直接选择Spark是更
优解
DataX :
05 快速迭代,资源消耗少,运维简便,吞吐量高 最终选择 ,
在一期工程中进行实现
�
13 .2.3 ClickHouse优化
1)写入本地表
数据写入流程:Niginx负载均衡——>分布式表——>本地表——>分布式本地表
2)使用MergeTree表引擎家族
使用ReplicatedMergeTree作为数据表的本地表引擎
使用ReplicatedReplacingMergeTree作为数据字典的表引擎
3)二级索引优化
二级索引从minmax替换到了bloom_filter
索引粒度更改到了32768
�
14 .2.3 ClickHouse优化
4)小文件优化
在数据计算的时候对小文件做了合并
5)参数优化
6)Zookeeper优化
1.调整MaxSessionTimeout参数,加大Zookeeper会话最大超时时间
2.在Zookeeper中将dataLogDir、dataDir目录分离
3.单独部署一套CK集群专供ClickHouse使用,磁盘选择超过1T,给的是SSD盘
�
15 .2.4 海量数据处理架构
一期技术架构:
Hive数仓架构——Hive——SparkSQL——DataX——DataX Web——DolphinScheduler—
—ClickHouse
�
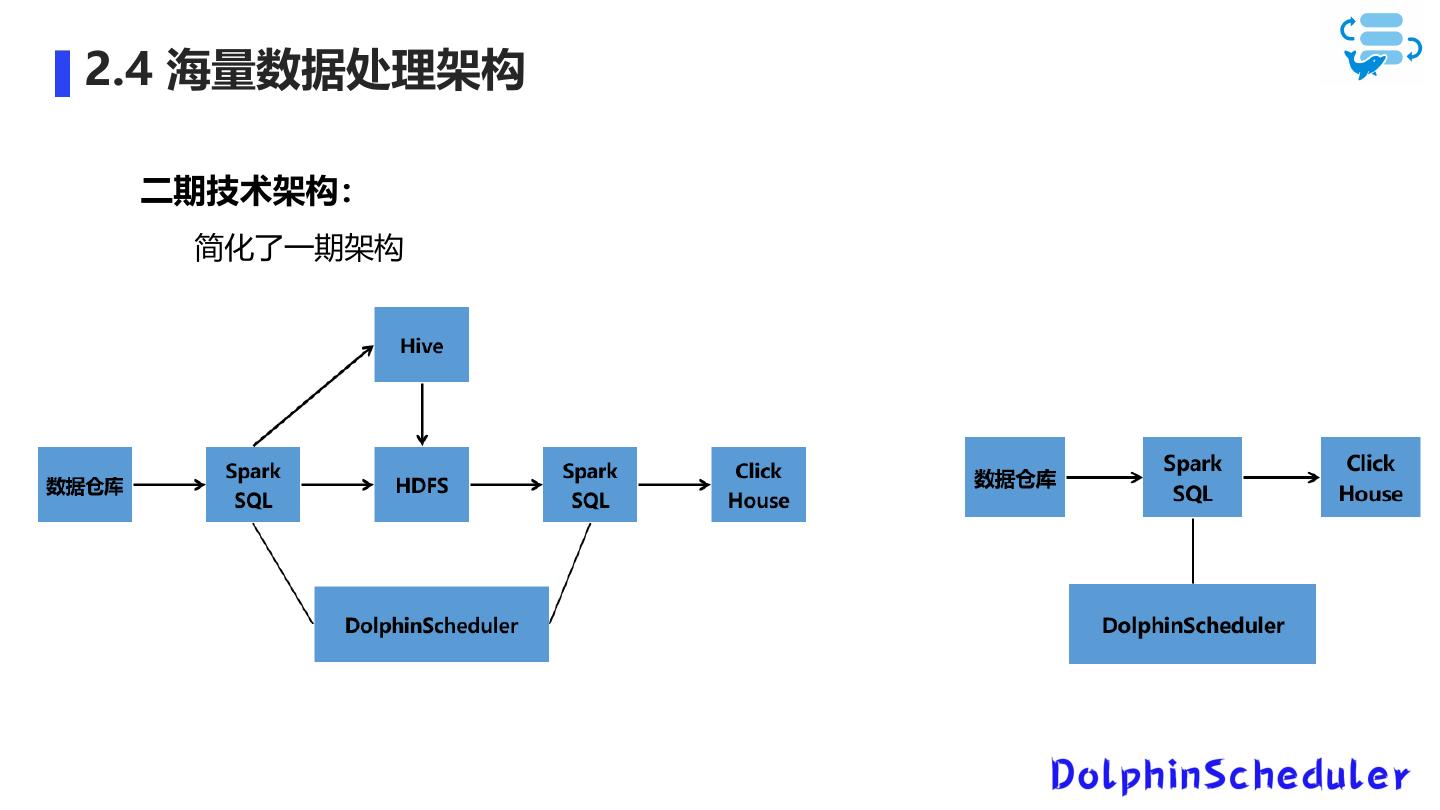
16 .2.4 海量数据处理架构
二期技术架构:
简化了一期架构
�
17 . 2.5 数据同步操作-DataX技术原理
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、
Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
�
18 . 2.5 数据同步操作-DataX在DS中的应用
DS需要集成了DataX才好去使用。
�
19 .2.5 数据同步操作-DataX在DS中的应用
DS中的DataX的不同使用方式:
�
20 . 2.5 数据同步操作-DataX在DS中的应用
DataX有多种不同的调优方式,下面所示的有channel速度调优、JVM调优、写入CK调优。
channel速度调优:
JVM调优:
写入CK调优:
�
21 . 数据&元数据备份&数据清理&日志清理:
3 应用场景
任务调度:
甘特图分析:
�
22 .4 未来规划
1 2
从某一个任务调度系统往DS DS集群部署、升级工具,减
进行任务迁移的工具,半自动 少运维工作量。
化,帮助DS推进。
3 4 5
从定制化监控转变为插件式监 二次开发,增加只读场景、回 集成API网关功能,对协议适
控,从高代码到低代码的转变, 收站功能,增多判断条件及功 配、服务管理、限流熔断、认
时监控告警更加灵活,及早发 能,资源批量上传等,助力大 证授权、接口请求等进行一站
现节点 工作流、数据库、任务
、
数据。 式操作。
等的问题。
�