展开查看详情
1 . 2022
Dolphinscheduler
应用实践
讲师: 张柏强
�
2 .目录
CONTE NTS
01 基于Ds的二次改造
02 Ds的插件扩充分享
03 Ds耦合血缘系统
04 Dolphin的生产基本优化
�
3 . 01 1,元数据以及任务多环境执行改造
基于Dolphinscheduler的二
2,任务信息清单增加
次改造
3,项目文件夹功能扩充以及工作流UI改造
�
4 .1,任务多环境执行改造
前言:
说这个点之前首先说一下dolphinscheduler在这块存在的短板
1,任务上线无法编辑
2,任务无法动态切换Pro/Test环境
3,同一个ProcessWorkflow无法设置多个调度
�
5 . 1.1,元数据分离改造
针对于第一个问题:我们对dolphinscheduler进行了一个基本的改造,首先是任务上线后无法编辑,导致用
户使用不够友好,其根本也是因为如果随便更改的话可能会影响到线上的调度,所以我们对dolphinscheduler的元数
据进行了改造使用户编辑的任务和调度的任务拆分为不同的两份,当用户点击任务发布,则触发调度依赖的任务信
息表修改,而用户本地执行以及修改都不会去触发调度依赖的任务信息表。
�
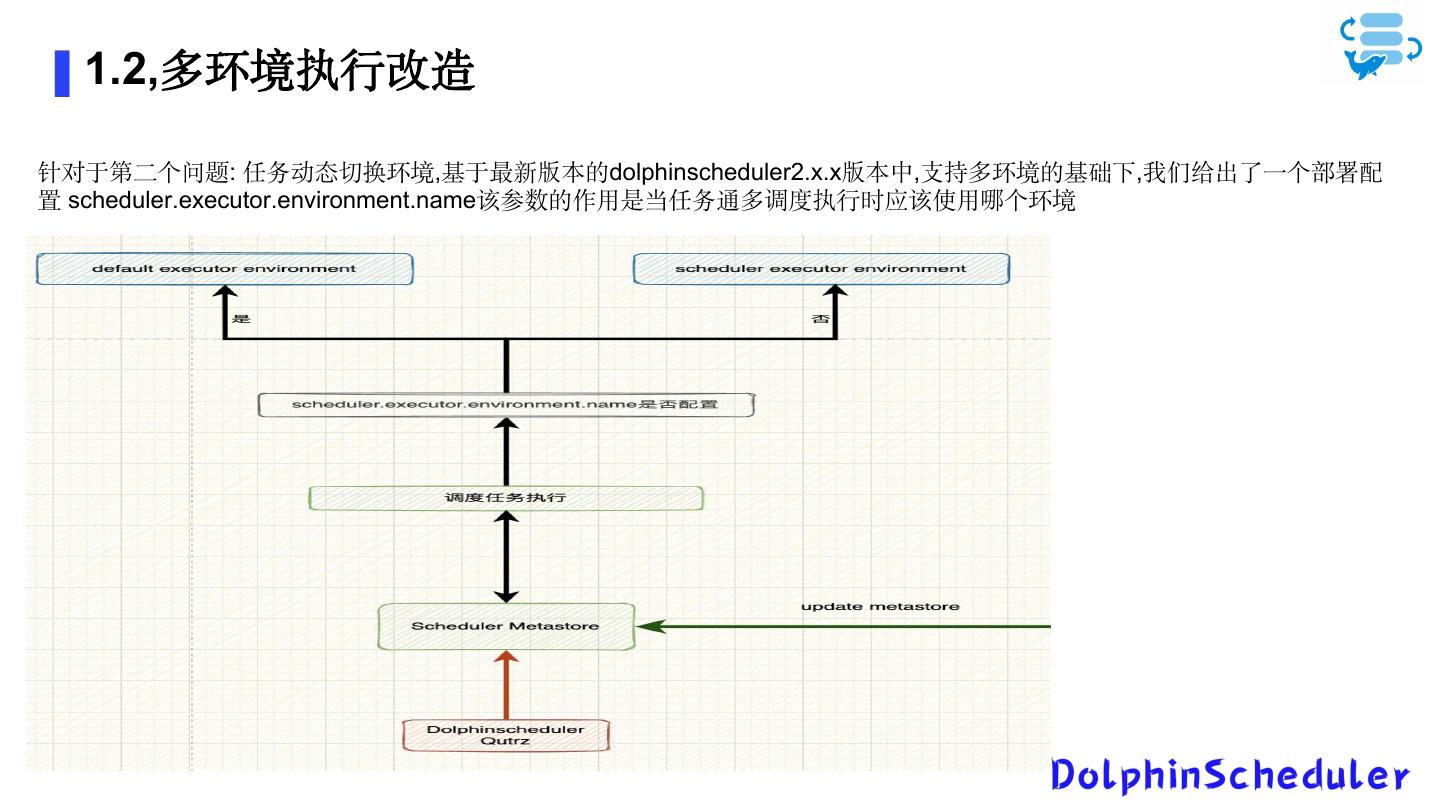
6 . 1.2,多环境执行改造
针对于第二个问题: 任务动态切换环境,基于最新版本的dolphinscheduler2.x.x版本中,支持多环境的基础下,我们给出了一个部署配
置 scheduler.executor.environment.name该参数的作用是当任务通多调度执行时应该使用哪个环境
�
7 . 2,任务信息清单增加
为了增强UI页面的可用性,特意增加了任务清单功能即减少用户的操作量,支持一页多信息,在原生dolphinscheduler
中,我们每次查找任务执行记录需要再次点击or多次点击,同时一些任务的明细信息也不是很全面,包括任务最近执行状态
等,同时我们也改造了任务上下线的模块,这里需要单独进行做一个任务展示,如下图所示:
用户通过点击任务,即可获取到任务最近10次执行信息,流程状态统计,任务历程,任务发布状态,任务描述,任务负责人等明细
�
8 . 3,项目文件夹功能扩充以及工作流UI改造
dolphinscheduler提供了以project为基础的最大单位,每个project里会包含数百上千的workflow单位,虽然其本身包含了分页的功能,
但是从使用场景来说,如果一个project中包含的workflow过多,导致用户不知道哪个任务有哪些,无法根据当前项目的业务线去划分
任务,所以需要去提供一个业务线文件夹的单位,单位划分为 project -> workflow dir -> dir,如下图所示:
也对Workflow定义UI的界面样式进行了改造
�
9 . 02 1,Spark/Hive ClientSQL Task
Dolphinscheduler的插件扩
2,DQC Task
充构建
3,SSH Task
�
10 . 1,Spark/Hive ClientSQL Task
dolphinscheduler提供的开箱即用的task中,只提供了通过jdbc的方式执行sql任务的形式,对于某些数仓场景,明
显是不满足的,于是我们提供了基于模板配置的hive/spark sql task,其最重要的作用是能够让用户快速开发离线任务,
同时将当前的task绑定血缘系统,在任务执行时能够包含完整的可追溯血缘。
�
11 . 2,DQCTask And Ssh Task
2.1 DQC Task
DQC Task在当前已经release的2.x版本中还没支持,我们基于自己的一套规则完善了一套第一版本的dqc task,目前已经
完成集成功能包括,任务检测,DQC告警以及自定义规则,但是目前这个版本的dqc还没有包含所有的大数据场景。
2.2 Ssh Task
ssh task其实就是提供了一个任务模板,在某些场景下,dolphinscheduler的worker不存在的机器上,我们需要自己去定时
执行任务,比如说每天定时清理日志,定时operator某些bash,提供了一个冗余的task,用于快速开发
�
12 . 03 1,任务表血缘绑定
Dolphinscheduler耦合血缘
2,血缘存储设计建议
系统
�
13 . 1,任务表血缘绑定
任务血缘构建的流程是这样的,当dolphinscheduler执行任务时,我们会根据type获取到如下几种类型,将这几种类型的task content,
task name,workflow name写入lineage server,然后通过lineage server构建成血缘,之后写入 graph db,最后通过api将数据查询出来。
常见SQL解析工具
1,antlr4
用户首先编写规则,编写完成规则后生成规则类等文件,之后直接
使用解析就行.
Apache Spark当前采用
2, Calcite
Apache Flink 当前采用
3,Druid
4,解析包
Hive-exec.jar
Spark-sql.jar
�
14 .2,血缘存储设计建议
Apache hbase
使用apache hbase存储血缘我觉得相比较于使用neo4j这种数据库,我们不需要再去进行额外的学习,但是复杂的
是血缘的设计,首先我们先展开血缘表结构为例,最简单的设计为
tableName lineage_table (split[])
rowkey
column family s t
之后我们每次只展开最近的血缘关系,然后根据最近的血缘关系依次展开.同时我们更新task时需要发送一个事件
来删除旧的血缘等操作
Neo4j
neo4j在会使用的情况下,存储血缘信息比hbase更简单,其天然支持血缘关系,无需我们自己去设计
…….
�
15 . 04 1,任务日志存储优化
针对于Dolphinscheduler的
2,经验分享
优化建议
�
16 . 1,任务日志存储优化
对于服务于用户以及开发者的调度系统来说,任务排错是必不可少的,一般情况下,任务排错从 demo,debug以及log入手,所以对于使用者来说针对task
执行日志进行排错是必不可少的,这也从侧面描述了log对于调度系统的重要性,但是随之任务增加以及时间递增,日志会越来越多,首先我们要知道针对于
企业中的服务器来说,存储磁盘和应用磁盘很多情况下都是分开的,所以我们需要做的第一步就是更改dolphinscheduler的execution log存储位置
�
17 .vim $DOLPHIN_HOME/conf/logback-worker.xml
<appender name="TASKLOGFILE" class="ch.qos.logback.classic.sift.SiftingAppender">
<!-- <filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter> -->
<filter class="org.apache.dolphinscheduler.server.log.TaskLogFilter"/>
<Discriminator class="org.apache.dolphinscheduler.server.log.TaskLogDiscriminator">
<key>taskAppId</key>
<logBase>/data/log/dolphin</logBase>
</Discriminator>
<sift>
<appender name="FILE-${taskAppId}" class="ch.qos.logback.core.FileAppender">
<file>/data/log/dolphin/${taskAppId}.log</file>
<encoder>
<pattern>
[%level] %date{yyyy-MM-dd HH:mm:ss.SSS} %logger{96}:[%line] - %messsage%n
</pattern>
<charset>UTF-8</charset>
</encoder>
<append>true</append>
</appender>
</sift>
</appender>
�
18 . 2,经验分享
1,实例数据如何管理?
随之系统上线的持续运行,实例的数据会随着时间逐渐递曾,针对于大量的实例数据,删除也不行,保留又会
造成读写速度过慢,常见的解决方法有分库分表,以及将数据写入HDFS,交由HIVE去管理,只将历史统计数据写
入回Mysql.
2,Shell 结果获取失败原因?
shell的执行机制是,这行代码报错后,如果下一行还有代码依然会执行,如果下一行代码执行正常则依然返
回的是0,我们可以设置 set -e
3,如何扩充新的管理员用户?
修改原生dolphinscheduler的t_ds_user表中的user_type为0
4,在原生ds中如何使用双环境执行?
为了保证ds能够两套集群运行,我们先说最简单的办法就是部署worker到测试环境中,这种情况下,我们在任务执行时可
动态选择执行的worker,其次如果不想部署这么多worker的情况下,我们可以set两套不同的execution env,之后将测试环境的
包部署到worker的某个位置,不启动服务,甚至可以将服务的jar剔除,只去依赖于client和其配置文件,同时在某些情况下需要保
证数据一致性就需要借助于一些外部工具,包括DQC工具以及自定义开发的工具
�