











































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
DH内存分析引擎
DH内存分析引擎专为高性能和大数据分析构建,比传统数据库 快 50x – 1000x。且基于工业化标准服务器,从TB 到 PB 快速扩展。
展开查看详情
1 .
2 .
3 .
4 .
5 .
6 .
7 .
8 .DH 数据分析引擎介绍 数据分析展示就用 DataHunter
9 .我们的愿景 Help people explore their data and improve business 帮助人们查看分析数据并改进业务
10 .大数据发展趋势和挑战
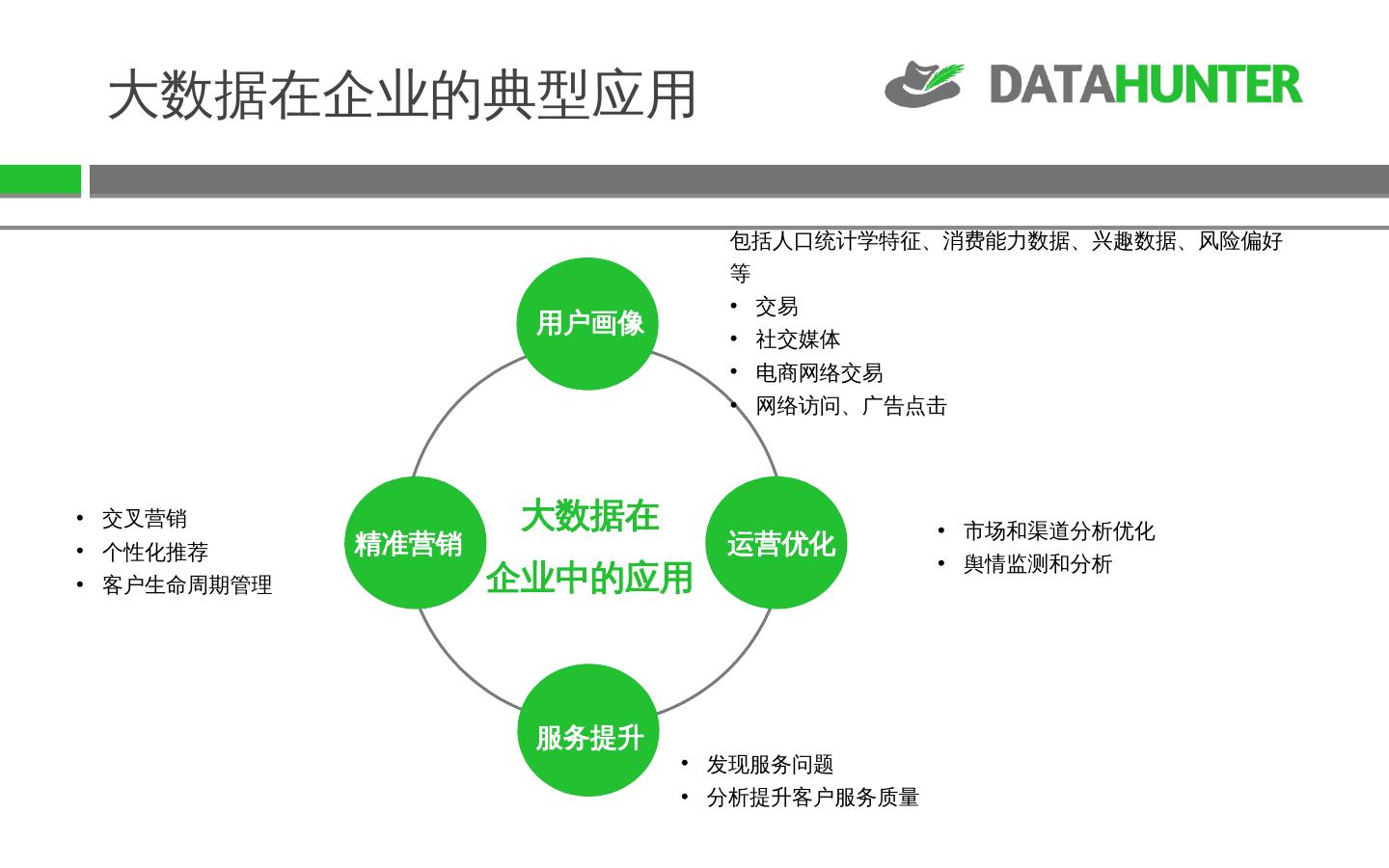
11 .精准营销 交叉营销 个性化推荐 客户生命周期管理 发现服务问题 分析提升客户服务质量 市场和渠道分析优化 舆情监测和分析 包括人口统计学特征、消费能力数据、兴趣数据、风险偏好等 交易 社交媒体 电商网络交易 网络访问、广告点击 服务提升 运营优化 用户画像 大数据在 企业中的应用 大数据在企业的典型应用
12 .大数据分析的能力需求 重要特点 : 数据量大、增长迅速、变化多样性、复杂 匹配分析 模型 Velocity Complexity 多目标 导向与互动 上下文 关系 BIG DATA 社交媒体 视频 音频 电子邮件 文本 移动电话 交易数据 设备数据 文档 收索引擎 图片 Volume Variety 快速收集 海量存储 深度挖掘 实时分析 大数据给分析平台带来巨大挑战
13 .传统 DBMS(OLTP) 的不足 主要优化措施,包括: 预计算:例如 Materialized views (物化视图) 查询加速 查询优化工具 其它一些索引技术 OLAP扩展 嵌入式分析手段 … 缺点: 1~2TB数据规模下,需要POWER780+中高端存储+大量调优工作才能勉强保证性能 2 CPU的PC服务器,License价格要30~40万 人工维护管理成本过高,需要大量的DBAs 数据库管理的复杂性:分区、表空间、索引维护、性能调优… 分析性能低下:尽管提供了一些性能优化措施,但仍无法从根本上解决分析查询性能低下的问题 OLTP DBMS 适合做: OLTP 小型企业/部门级分析应用或者很小的数据量 简单的查询分析 传统的 DBMS 并不适合做分析数据库
14 .MPP 数据引擎定义 MPP 即大规模并行处理( Massively Parallel Processor )。 在数据库非共享集群中, 每个节点都有独立的磁盘存储系统和内存系统 ,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络互相连接,彼此协同计算,作为整体提供数据 库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。 对外网络 私有网络 内部磁盘 内部磁盘 内部磁盘 Node 1 CPU RAM Node 2 CPU RAM Node 3 CPU RAM 无共享架构 (share nothing)
15 .DH 内存分析引擎的价值
16 .企业大数据平台参考架构 MPP DB 历史分析 Broker Broker … Kafka 实时 dashboard 预测分析 SQL 建模 评估 部署 流式处理 实时预测 企业模型 交互式分析 准实时预测 Hive/HBase/HDFS/... ERP CRM ... 管控 调度 批量处理 大数据存储 非结构化分析引擎 DH 数据分析引擎
17 .借助实时及批量并行装载性能,提供比传统行式数据 10X 倍的装载性能 无 I/O 瓶颈 持续的数据加载和查询 实现最佳数据分析性能 基于低成本的x86 Linux工业标准服务器,可以支持更多查询加速数个~数百个节点线性扩展 内置数据冗余,保证高可用,无单点故障,实现负载均衡 Projections和DBD自动化辅助设计优化性能,提高管理效率 10+ 编码和压缩算法,高达 90% 的空间和存储更多数据、使用更少硬件、提高吞吐量、支撑更大规模业务 比传统数据库 快 50x – 1000x 基于工业化标准服务器,从 TB 到 PB 快速 扩展 兼容 SQL-99+ ,开放架构 , 轻松与主流的 ETL 和 BI 工具、 Hadoop/Spark/Kafka 等 集成 , 无限的部署 灵活性 可扩充的 高级分析高级分析 和 机器学习 7x24 准实时持续加载和分析 精细到行、列级的 安全性 DH 数据引擎核心技术 —— 专为高性能和大数据分析构建
18 .DH 数据分析引擎 —— 专为大数据实时分析构建 高可用 高扩展 列式计算 实时聚合 高级分析 X86 大规模并行处理架构( MPP ) 自动优化 高速并行装载 实时分析查询 SQL ODBC/JDBC/ADO.NET 50x – 1000x 性能提升 TBs~10PBs 在线扩展 高级压缩,节约 90% 的存储空间 标准 sql, 多语言支持 开放、简单易用 物理机部署 云平台部署 Hadoop 上部署 海量数据 机器学习 模型快速 部署 迭代 Connectors
19 .大数据分析关键技术 Column MPP 列式存储和计算 内存计算 并行计算 核心是并行计算和降低 I/O Column Column 有效解决单机“天花板”问题 大数据分析系统主流优化技术 有效解决 I/O 瓶颈问题 计算速度快
20 .群集:大规模并行处理 (MPP) 客户端网络 专用数据网 8 TB 8 TB 8 TB 节点 1 2 个 6 至 8 核 64+GB RAM 节点 2 2 个 6 至 8 核 64+GB RAM 节点 3 2 个 6 至 8 核 64+GB RAM 节 点是同级 无专门的节点 所有节点都是同级 查询 / 加载到任何 节点 连续 / 实时加载和 查询 并行设计利用数据投影支持分布式存储和工作负载 活动冗余 自动复制、故障转移和恢复 无共享、基于网格的架构为商品服务器群集提供可扩展性 添加节点来实现最佳容量和性能
21 .DH 数据分析引擎 如何保障性能 I/O 管理 数据库 引擎 I /O 管理 数据库 引擎 I /O 管理 数据库 引擎 I/O 管理 数据库 引擎 任务调度 : SQL 解析,任务控制,结果汇总 Parse Scan Join Sum Sort Converge 20% CPU 利用率 增 加磁盘数量 / 大内存 / 列存储 / 列编码及压缩 / 延迟物化 I/O 能力不足 平衡配置的 IO ( 与 CPU 平衡 ) DH 数据仓库平台的 IO 能力 100% 80% 60% 40% 10 20 30 优点:用最廉价的硬件资源,就可以将 CPU 用满
22 .列存储 AAPL NYASE NYAASE NYSE NYASE NGGYSE NYGGGSE NYSE NYSE NYSE 143.74 NYS E NYSE NYSE 5/05/09 5/05/09 5/06/09 5/05/09 5/06/09 143.74 143.75 37.03 37.13 AAPL NYASE NYAASE NYSE NYASE NGGYSE NYGGGSE NYSE NYSE NYSE 143.74 NYSE NYSE NYSE 5/06/09 BBY NYASE NYAASE NYSE NYASE NGGYSE NYGGGSE NYSE NYSE NYSE 37.03 NYSE NYSE NYSE 5/05/09 BBY N YASE NYAASE NYSE NYASE NGGYSE NYGGGSE NYSE NYSE NYSE 37.13 NYSE NYS E NYSE 5/06/09 列存储 - 读取 3 列 行存储 - 读取所有列 NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS NYSE NYSE NYSE NQDS AAPL AAPL BBY BBY SELECT avg(price) FROM tickstore WHERE symbol = ‘ AAPL ” date = ‘ 5/06/09 ’ DH 数据分析引擎 在磁盘上针对每一列对数据进行智能化整理 只从磁盘中读取查询涉及的列,而不是所有行和列 在非常大的块大小中读取和写入 为列执行构建的查询引擎中的所有操作 由于磁盘 I/O 大幅减少,因此特别适合加载密集型 / 读取密集型工作负载
23 .高级压缩 编码机制 交易日期 客户 ID 交易 5/05/2009 5/05/2009 5/05/2009 5/05/2009 5/05/2009 5/05/2009 5/05/2009 5/05/2009 5/05/200 9 0000001 0000001 0000003 0000003 0000005 0000011 0000011 0000020 0000026 100.25 100.50 100.75 100.25 100.75 101.00 101.25 100.75 101.25 少数值 已排序 5/05/2009 , 16 RLE 0000001 0 2 2 4 10 10 19 25 DeltaVa l 100 .25 1 2 3 1 3 4 5 3 GCD 许多值整 数可能已 排序 许多值 已排序 原始数据 压缩数据 许多其他 … 通过积极压缩, DH 数据分析引擎用快速 CPU 周期代替较慢的磁盘 I/O 使用数据属性,如排序、基数和相关性 无需先解码即可运行 实施延时物化 尽可能晚地进行智能解码
24 .DH 数据分析引擎 数据 实时加载支持 异步数据移动 数据移动 磁盘式 已排序/已压缩 写优化存储 (WOS) 在内存中 已分段 低延时/少量快速插入 读优化存储 (ROS) APX 60.19 7,100 1/15/2013 MSFT 60.53 12,500 1/15/2013 NFLX 78.29 25,000 1/16/2013 APX 60.25 10,000 1/15/2013 大数据量批量加载 / 修改 APX,2 MSFT,1 NFLX,1 60.19 60.25 60.53 78.29 10,000 7,100 12,500 25,000 1/15/2013,3 1/16/2013,1 APX,1 MSFT,2 NFLX,1 60.25 60.29 60.53 78.29 10,000 11,000 13,500 25,000 1/15/2013,2 1/16/2013,2 APX,1 MSFT,2 NFLX,1 60.25 60.29 60.53 78.29 10,000 11,000 13,500 25,000 1/15/2013,2 1/16/2013,2 APX,3 MSFT,3 NFLX,2 60.19 60.25,2 60.29 60.53,2 78.29,2 7,100 10,000,211,000 12,500 13,500 25,000,2 1/15/2013,51/16/2013,3 APX,3 MSFT,3 NFLX,2 60.19 60.25,2 60.29 60.53,2 78.29,2 7,100 10,000,211,000 12,500 13,500 25,000,2 1/15/2013,51/16/2013,3 SQL 避免修改数据文件: Insert= 追加 Delete= 标记删除 Update=Delete+Insert 已分段 大量数据直接装载 小数据量频繁加载 / 修改 —— 读写分离的混合存储架构
25 .数据分析的实时性: 数据分析和数据加载的并行支持 DH 数据分析引擎不提供索引和物化视图,通过 Projection 提供高效率查询 同一张表的多个 Projection 可按不同排序方式、压缩模式以及数据分布满足查询的多样性 可通过 Pre-join Projection 提升 Join 的查询效率 排序可提升 Group by 和数据定位的效率 多个 Projection 分布在多个节点上,提升查询的并行效率 不同于传统表 + 索引的存储架构, 在数据导入时 projection 一直可用 => 数据分析一直可用 来源于独有的数据管理模式 (Projection)
26 .Tactical General Analytic User 1 并发与负载管理 无主节点瓶颈 ! 查询被自动均匀分布到每个集群节点 并发能力会随着节点数的增加而提高 配置资源管理 不同类型的查询可设定不同的资源池 限制并保证查询所需资源 可按每个资源池设置优先级别、并发数、运行时间和资源分配概要 资源限制可设置在资源池、用户或 session 级别 实时负载管理 实时调整查询的优先级 Kill 掉超时查询 tactical tactical analytic Analytic User 2
27 .本地高可用性 数据库中类似 RAID 的功能 投影有理有序,因此当某节点出现故障时,某个幸存节点上还会提供一份副本 按照不同的排序顺序自动存储冗余数据集以提高查询性能 永续在线查询和加载 无需手动进行基于日志的恢复 节点中断时,系统继续加载和查询 通过查询其他节点来恢复缺失数据 A3 B3 C3 A2 B2 C2 B1 A1 C1 B2 A2 C2 B1 A1 C1 A3 B3 C3 A1 B1 C1 B3 A3 C3
28 .故障组和大型群集 通过分发数据段承受大规模硬件故障 自动故障组 用户定义的故障组 监控故障组 机架 3 机架 2 机架 1 网络 6 5 4 9 8 7 3 2 1 故障 组 1 故障组 2 故障组 3 9 8 7 4 5 6 1 2 3
29 .灵活备份/恢复 基于文件的备份 / 恢复实用程序 完整或增量备份 仅备份自上一备份运行以来更改的文件 热备份 主动数据库操作不存在锁争用 可配置的备份选项 从 DH 数据分析引擎 节点到备份服务器的可配置映射 数据库和备份位置之间的可选加密选项 可配置的还原点数量 对象级备份 / 恢复 按照应用 / 用户 / 模式配置备份,以满足各个 SLA 要求
3秒后跳转登录页面
去登陆

