展开查看详情
1 .运维场景下的数据运营化与智能化
演讲人:王超
全球敏捷运维峰会 北京站
�
2 .关于我
14年~今 京东数科 应用架构部负责人
11年~14年 人人网 运维主管
08年~11年 传统大型企业 开发&运维
传统运维 自动化运维 智能运维
全球敏捷运维峰会 北京站
�
3 . 目录
1 运维演进历程
2 智能运维技术实践
3 典型案例-质量提高
4 典型案例-成本优化
5 典型案例-效率提升
全球敏捷运维峰会 北京站
�
4 .让我们先看看工业的演进历程
全球敏捷运维峰会 北京站
�
5 . 手工作坊
简单纯粹
锻炼身体
效率低下
全球敏捷运维峰会 北京站
�
6 .蒸汽机的出现
18世纪中期
机器替代人力
生产力提高
工作细分
资源消耗严重
全球敏捷运维峰会 北京站
�
7 .车间流水线的出现
19世纪20年代
标准化零件
流水线操作
生产力大幅提高
简单重复劳动
工人成为工具
全球敏捷运维峰会 北京站
�
8 .工业3.0
全面信息化
自动化控制
供应链管理
全球敏捷运维峰会 北京站
�
9 . 工业4.0
物联网
数据流动自动化
人工智能
全球敏捷运维峰会 北京站
�
10 .让我们再看看运维的演进历程
全球敏捷运维峰会 北京站
�
11 . 手工操作时代
• 手工登录机器操作
• 优点
• 灵活
• 酷炫
• 缺点
• 依赖专家经验
• 容易出错
• 操作时间久
全球敏捷运维峰会 北京站
�
12 .自动化时代
• 开发自动化脚本
• 优点
• 效率提高
• 缺点
• 依赖开发能力
• 脚本和配置可能不一致
全球敏捷运维峰会 北京站
�
13 . 平台化时代
• 大量使用开源工具
• 系统间集成
• 参考DevOps/SRE等理论基础
• 优点:
• 可靠,高效,信息集中管理
• 缺点
• 依然依赖人的经验
全球敏捷运维峰会 北京站
�
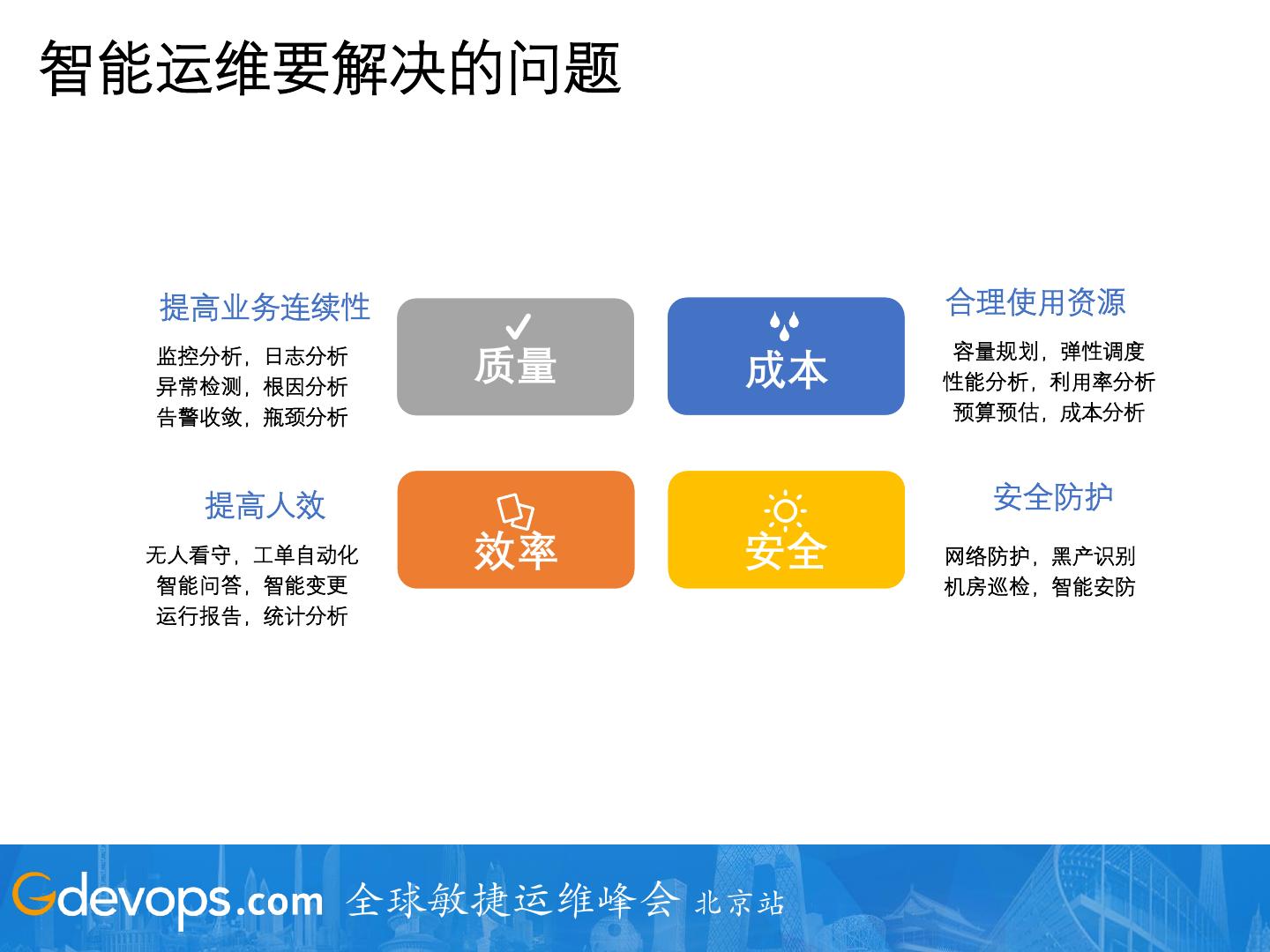
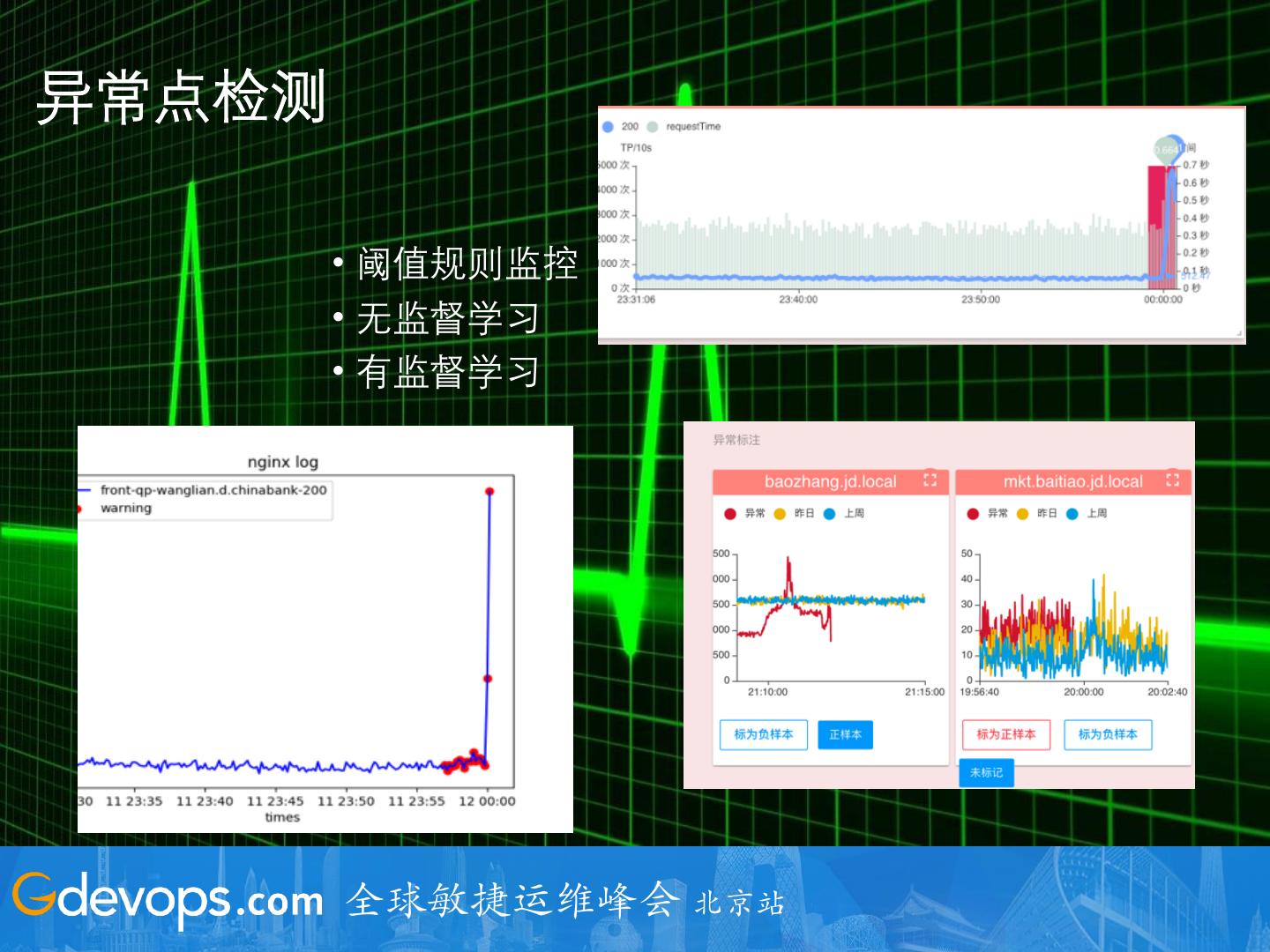
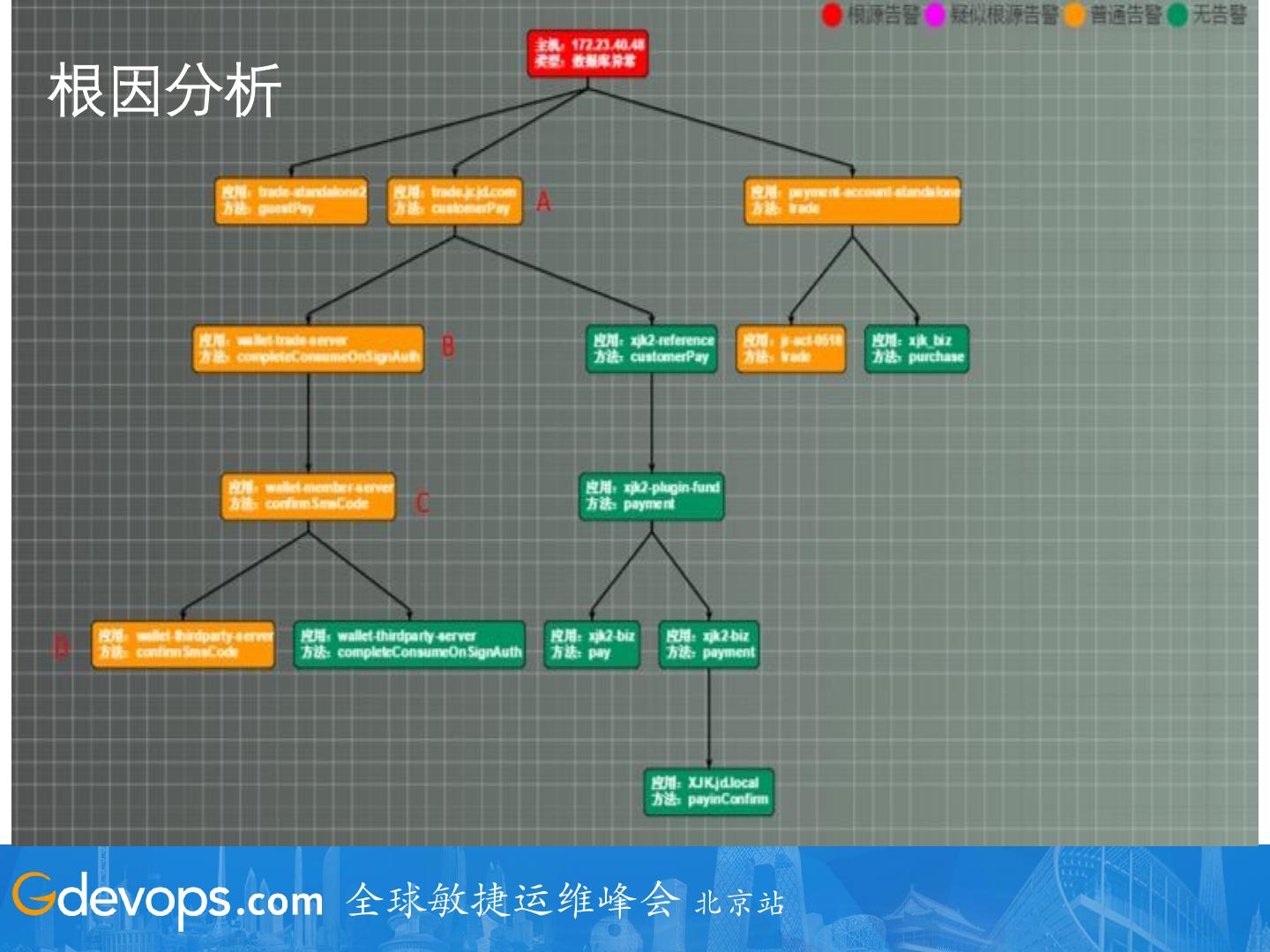
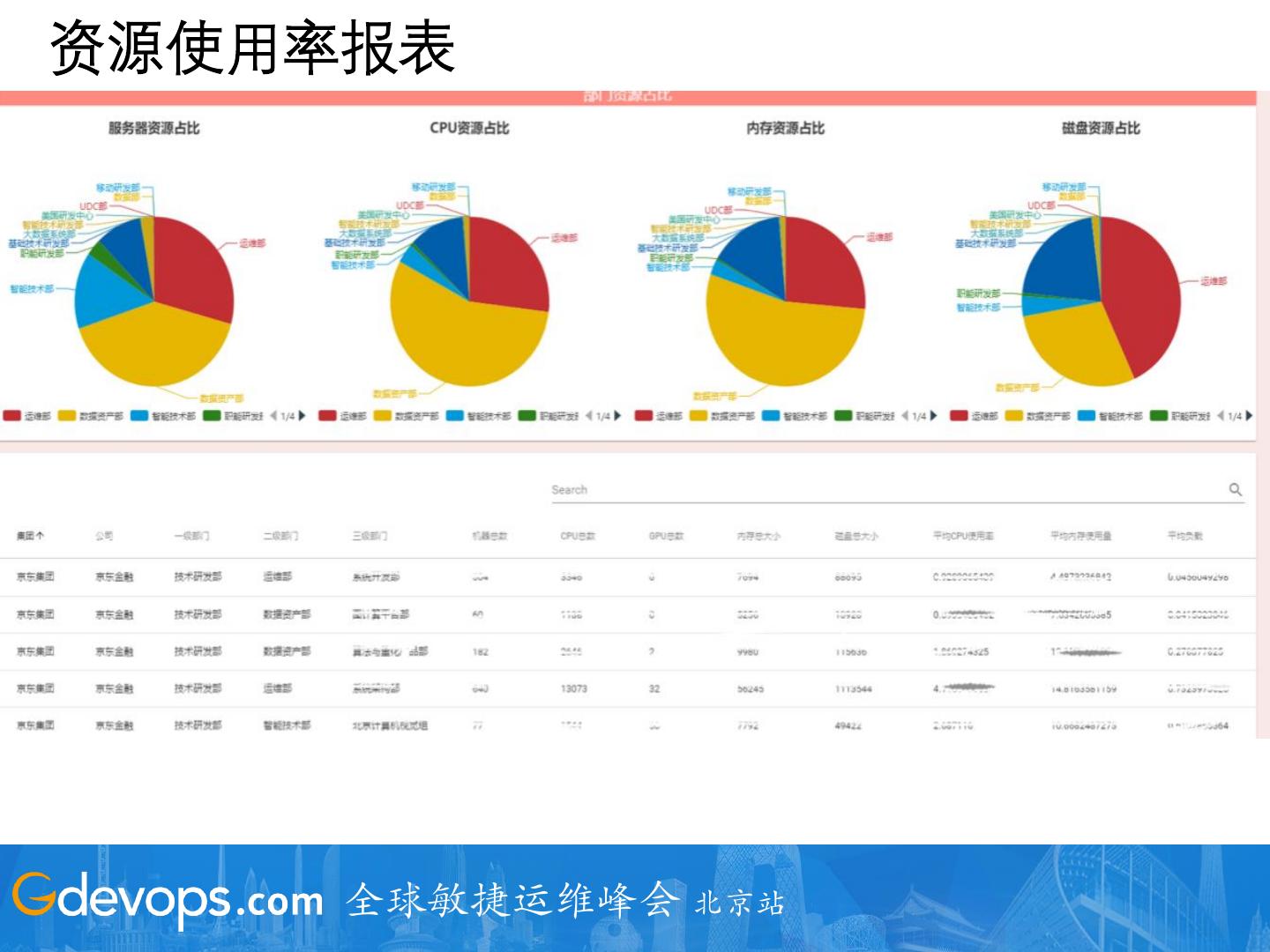
15 .智能运维要解决的问题
提高业务连续性 合理使用资源
容量规划,弹性调度
监控分析,日志分析
异常检测,根因分析
质量 成本 性能分析,利用率分析
告警收敛,瓶颈分析 预算预估,成本分析
提高人效 安全防护
无人看守,工单自动化 效率 安全 网络防护,黑产识别
智能问答,智能变更 机房巡检,智能安防
运行报告,统计分析
全球敏捷运维峰会 北京站
�
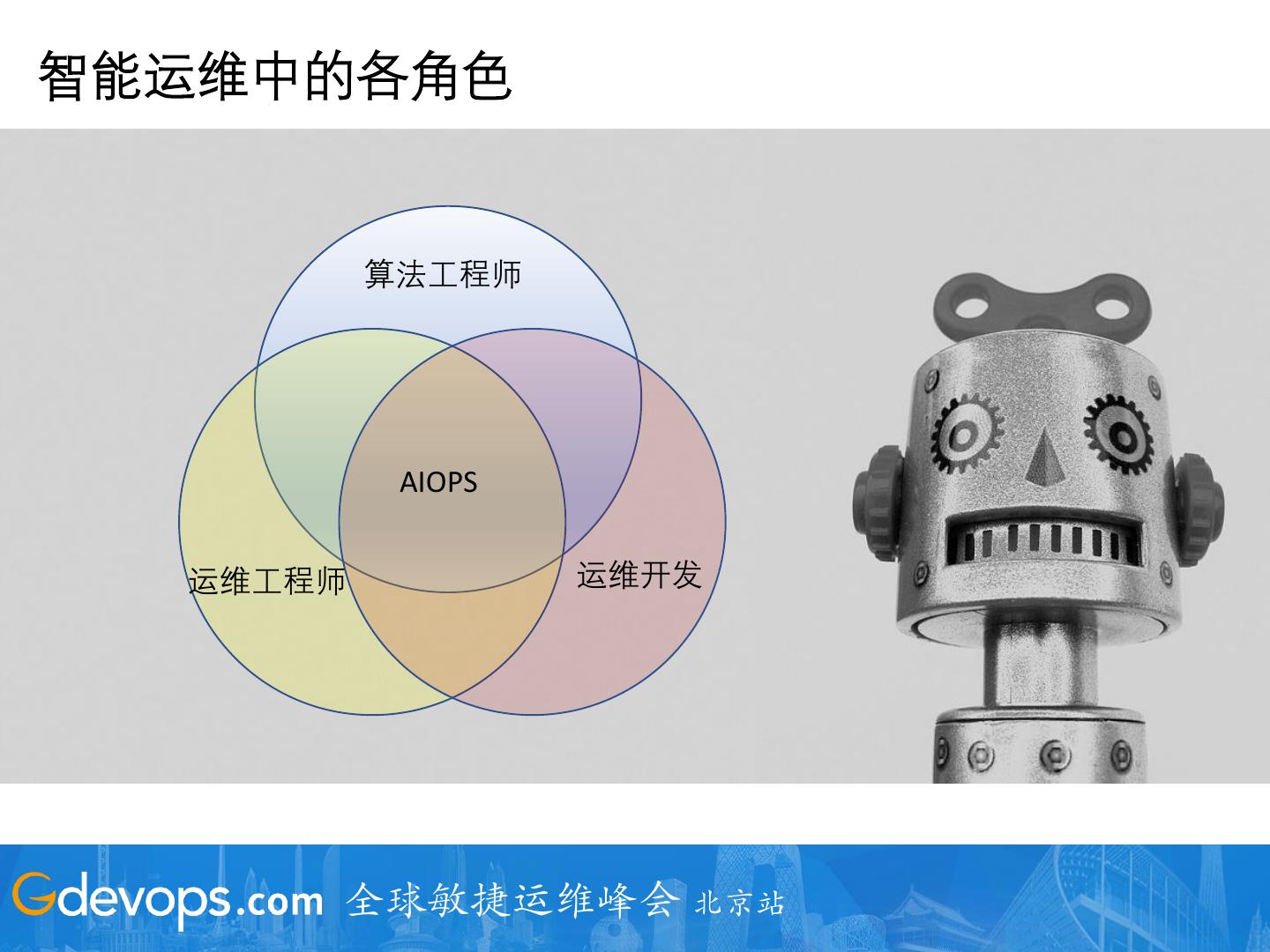
16 .智能运维中的各角色
算法工程师
AIOPS
运维工程师 运维开发
全球敏捷运维峰会 北京站
�
17 .运维开发工程师做什么?
前端
平台开发
后端
运维开发
数据采集
大数据开发 数据处理
数据存储
全球敏捷运维峰会 北京站
�
18 .大数据技术-数据流动
实时监控
流式计算 实时仪表盘
监控大屏
业务系统 数据采集 数据加工 数据存储
报表推送
跑批计算
让数据流动起来 健康分析
全球敏捷运维峰会 北京站
�
19 .大数据技术-技术栈
-以开源技术举例
让数据流动起来
数据采集加工 数据存储 数据分析 数据应用
源系统
Hive 实时监控
Spark HDFS
API
Kafka 实时仪表盘
Hbase Phoenix
页面 Flume
监控大屏
Azkaban ES Impala
MQ
Sqoop 报表推送
TSDB
日志
健康分析
数据库
全球敏捷运维峰会 北京站
�
21 . 运维算法工程师做什么?
全球敏捷运维峰会 北京站
�
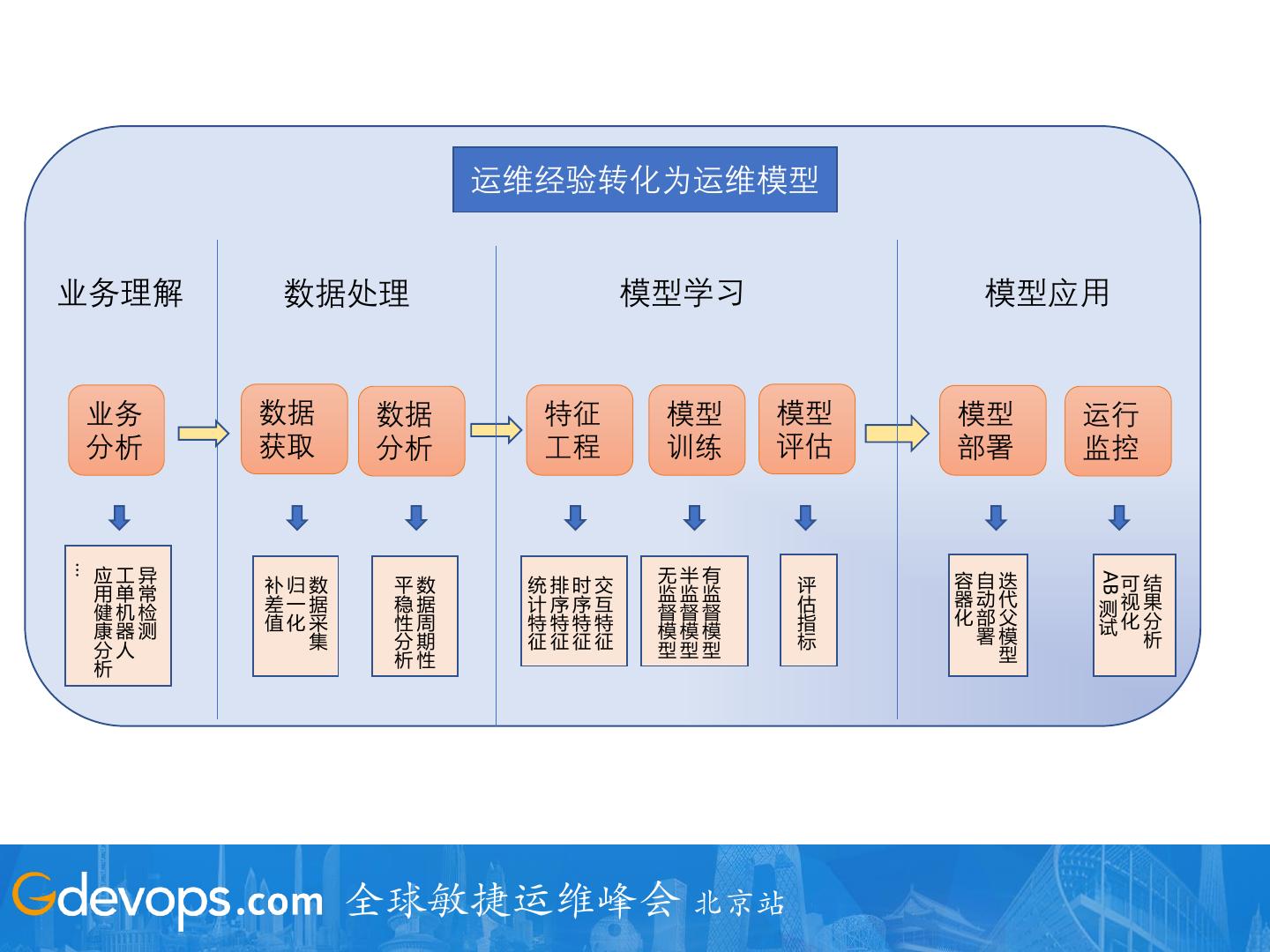
22 . 运维经验转化为运维模型
业务理解 数据处理 模型学习 模型应用
业务 数据 数据 特征 模型 模型 模型 运行
分析 获取 分析 工程 训练 评估 部署 监控
…
应工异 无半有 容自迭
AB
补归数 平数 统排时交 评 可结
用单常 监监监 器动代
健机检 差一据 稳据 计序序互 督督督 估
化部父 测视果
康器测 值化采 性周 特特特特 模模模 指
署模 试化分
集 分期 征征征征 标 析
分人 型型型 型
析 析性
全球敏捷运维峰会 北京站
�
23 .基于规则的模型
如:异常告警中,将告警原因与告警类型关联建立告警关联规则,进行异常检测。
基于统计方法的模型以及基于机器学习方法的模型都是建立规则库的过程。
基于规则的模型 基于规则的模型更加倾向于一种表达方式。
基于规则的模型很大一部分都是基于历史数据标记的情况下进行建立关联规
则,对数据未标记的情况会缺乏讨论。
全球敏捷运维峰会 北京站
�
24 .基于统计方法的模型
(1)基于参数检验的方式:假设采样数据中大部分为正常点,以数据点的均值、众数、中位数
等作为正常点统计模型,当参数在正常点附近波动时,认为KPI正常,反之异常。
(2)基于非参数检验方式:采用历史数据的分布函数和经验分布函数等作为正常模型,
将新数据的分布与原始分布进行对比,分布一致则认为正常,否则异常。
(3)将参数描述成时间序列: 对序列的相似性、周期性、线性/非线性相关、趋势、时频特征等
进行建模,形成时序特征模型,当新数据不满足建立的特性模型时,KPI数据被判别成异常。
基于统计方法的
模型 不足之处
统计检验对分布、回归拟合 基于统计方法的模型利用正常点数据占
等存在假设,此方法针对多 主导的特点来建立正常模型,忽略历史
变量分析时扩展性较低; 数据中异常点对于模型的影响,使得正
常模型存在偏差,模型鲁棒性较差。
全球敏捷运维峰会 北京站
�
25 . 基于机器学习方法的模型
机器学习最大的优点
与基于统计方法的模型相同点
不需要假定参数的分布或者参数之间的关系,
都是通过历史数据建立KPI正常状态模型, 直接通过学习的方法得到模型,对海量数据、
与正常模型匹配判定KPI异常状态。 高维数据、复杂场景等具有较强的适应性与扩
展性。
基于机器学习方法的模型主要分为三类:
(1)基于已经标记异常的历史数据,采用监督学习的方法学习异常和正常群体的历史表现,进
基于机器学习方法的 行新数据监测时,可以通过模型输出异常情况。
模型
(2)基于无标记的历史数据分析,采用无监督的方法进行异常识别。比如,在进行高维度连
续数据的异常检测时,可选用孤立森林算法,通过多棵iTree树形成森林来判断是否异常。
(3)基于半监督的方法扩充标签样本库,尽快满足有监督学习方法的数据量级要求
全球敏捷运维峰会 北京站
�
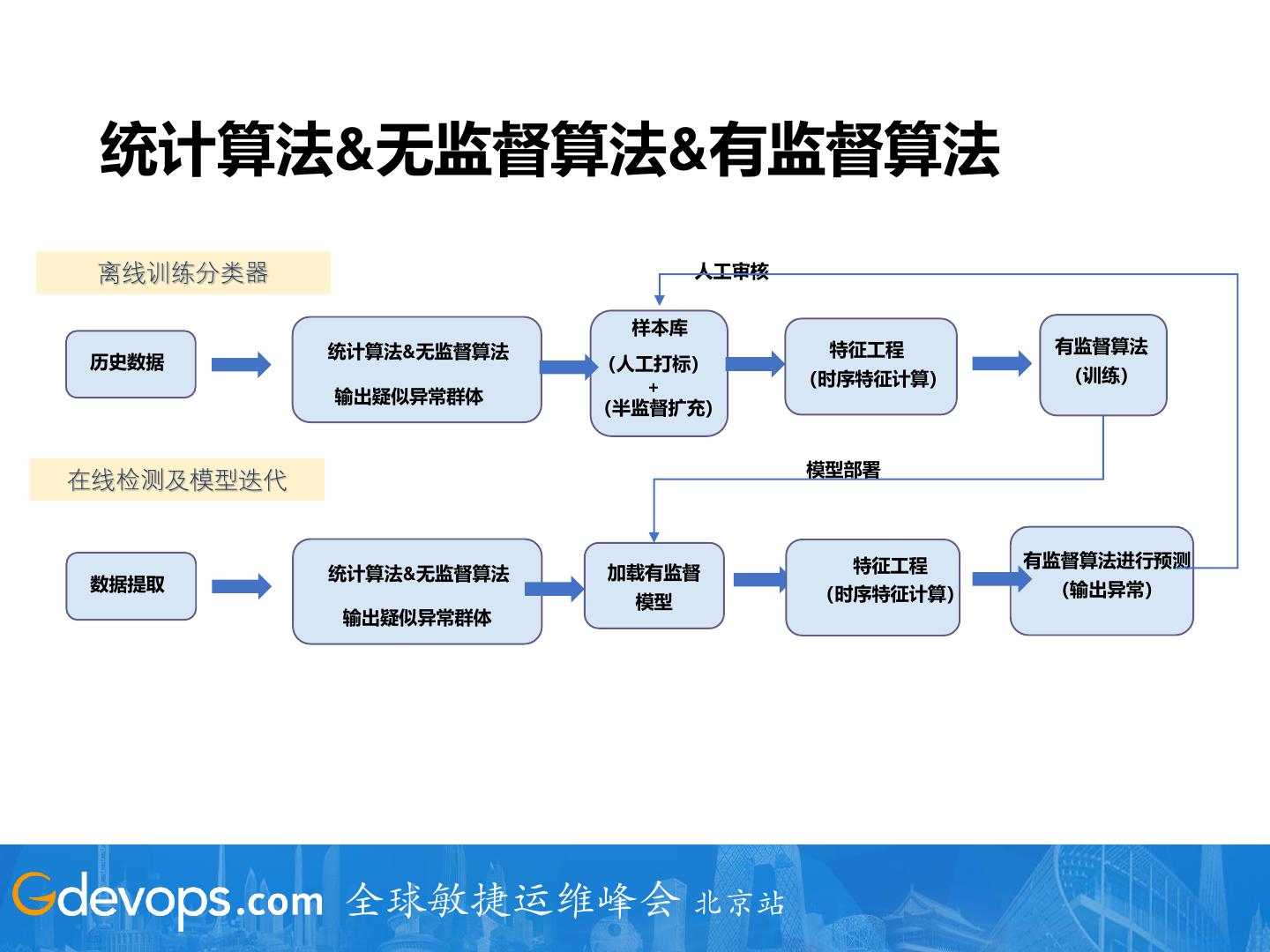
26 . 统计算法&无监督算法&有监督算法
离线训练分类器 人工审核
样本库
统计算法&无监督算法 特征工程 有监督算法
历史数据 (人工打标)
(时序特征计算) (训练)
+
输出疑似异常群体
(半监督扩充)
模型部署
在线检测及模型迭代
特征工程 有监督算法进行预测
统计算法&无监督算法 加载有监督
数据提取 (输出异常)
模型 (时序特征计算)
输出疑似异常群体
全球敏捷运维峰会 北京站
�
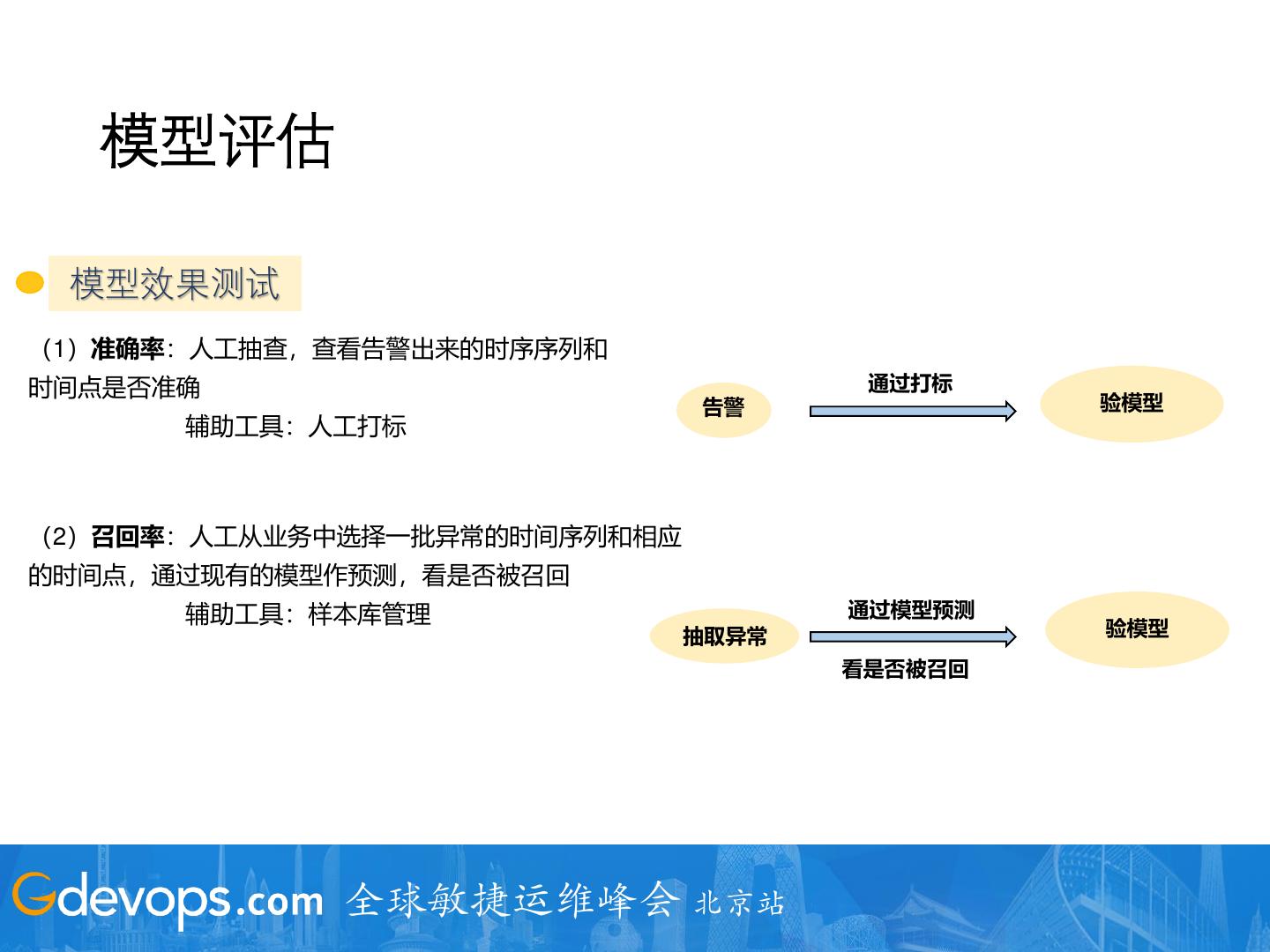
27 . 模型评估
模型效果测试
(1)准确率:人工抽查,查看告警出来的时序序列和
时间点是否准确 通过打标
告警 验模型
辅助工具:人工打标
(2)召回率:人工从业务中选择一批异常的时间序列和相应
的时间点,通过现有的模型作预测,看是否被召回
辅助工具:样本库管理 通过模型预测
抽取异常 验模型
看是否被召回
全球敏捷运维峰会 北京站
�
29 . 目录
1 运维演进历程
2 智能运维技术实践
3 典型案例-质量提高
4 典型案例-成本优化
5 典型案例-效率提升
全球敏捷运维峰会 北京站
�