





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- <iframe src="https://www.slidestalk.com/DBAPlus/Amazon_Aurora?embed" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
韩思捷 - 云原生数据库Amazon Aurora技术架构详解与迁移实战
分享
点赞
0
收藏
1
下载 3
AWS资深架构师韩思捷分享《云原生数据库Amazon Aurora技术架构详解与迁移实战》
展开查看详情
1 . Amazon Aurora 为云计算而生的关系型数据库 演讲人:韩思捷 AWS解决方案架构师 2019 中国数据智能管理峰会
2 .议程 ➢ Aurora特性 ➢ Aurora技术架构 ➢ 迁移至Aurora ➢ Aurora客户案例 2019 中国数据智能管理峰会
3 .议程 ➢ Aurora特性 ➢ Aurora技术架构 ➢ 迁移至Aurora ➢ Aurora客户案例 2019 中国数据智能管理峰会
4 .Amazon Aurora 的与众不同 兼容 MySQL 和 PostgreSQL 的关系数据库,为云打造。 性能和可用性与商用数据库相当,成本只有 1/10。 高性能和高可扩展性 高可用性和高耐用性 高度安全 完全托管 5 倍于标准 MySQL 的吞吐量 可用性高于 99.99% 通过VPC 进行网络级 无需担心硬件、软件补丁、 3 倍于PostgreSQL 的吞吐量 具有容错及自我修复能力 隔离,支持静态存储 设置、配置或备份等数据 性能相当而成本仅为商用DB的1/10 跨3个AZ复制6个数据副本 及传输时加密,集群 库管理任务。会自动持续 可以跨3个AZ,最多 15 个可读副本 数据持续备份到 S3 中的备份、快照和副 监控并将其备份到 S3,可 存储自增长,单实例可达 64TB 实例故障转移小于3 秒 本自动加密 以实现精细的时间点恢复。 2019 中国数据智能管理峰会
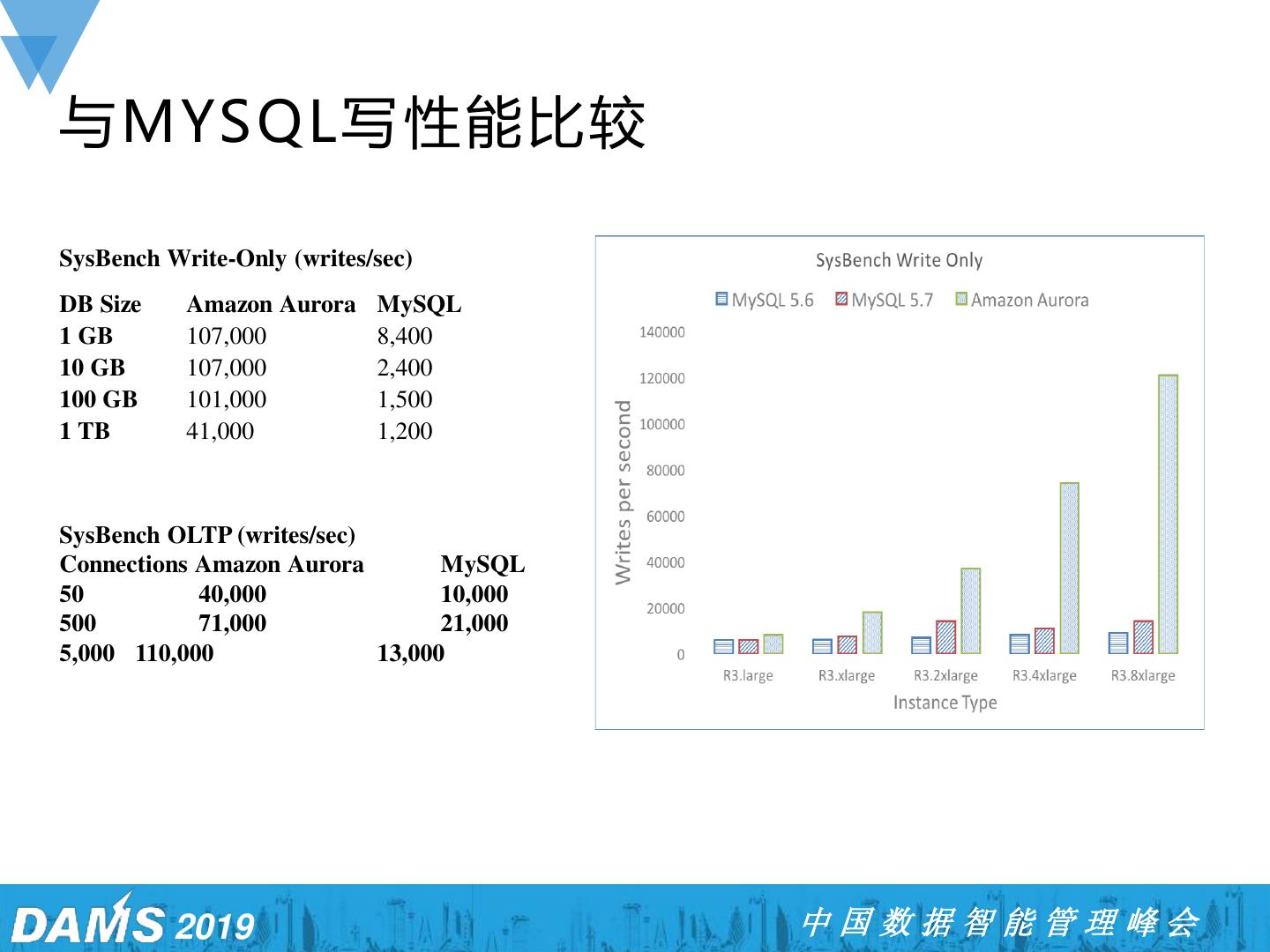
5 .与MYSQL写性能比较 SysBench Write-Only (writes/sec) DB Size Amazon Aurora MySQL 1 GB 107,000 8,400 10 GB 107,000 2,400 100 GB 101,000 1,500 1 TB 41,000 1,200 SysBench OLTP (writes/sec) Connections Amazon Aurora MySQL 50 40,000 10,000 500 71,000 21,000 5,000 110,000 13,000 2019 中国数据智能管理峰会
6 .与MYSQL读性能比较 2019 中国数据智能管理峰会
7 . 性能测试 • MySQL SysBench • R3.8XL with 32 cores and 244 GB RAM WRITE PERFORMANCE READ PERFORMANCE • Four client machines with 1,000 threads each • Single client with 1,600 threads 更多的测试可以看:https://amazonaws-china.com/cn/blogs/china/aurora-test/?nc1=b_rp 2019 中国数据智能管理峰会
8 .如何实现高性能? 减少不必要工作 提高效率 更少IO 异步处理 减少网络传输 减少延迟 缓存 优化锁机制 计算和存储分离 批量处理 数据库取决于IO 网络存储依赖流量 2019 中国数据智能管理峰会
9 .AWS全球区域 https://www.infrastructure.aws/ 2019 中国数据智能管理峰会
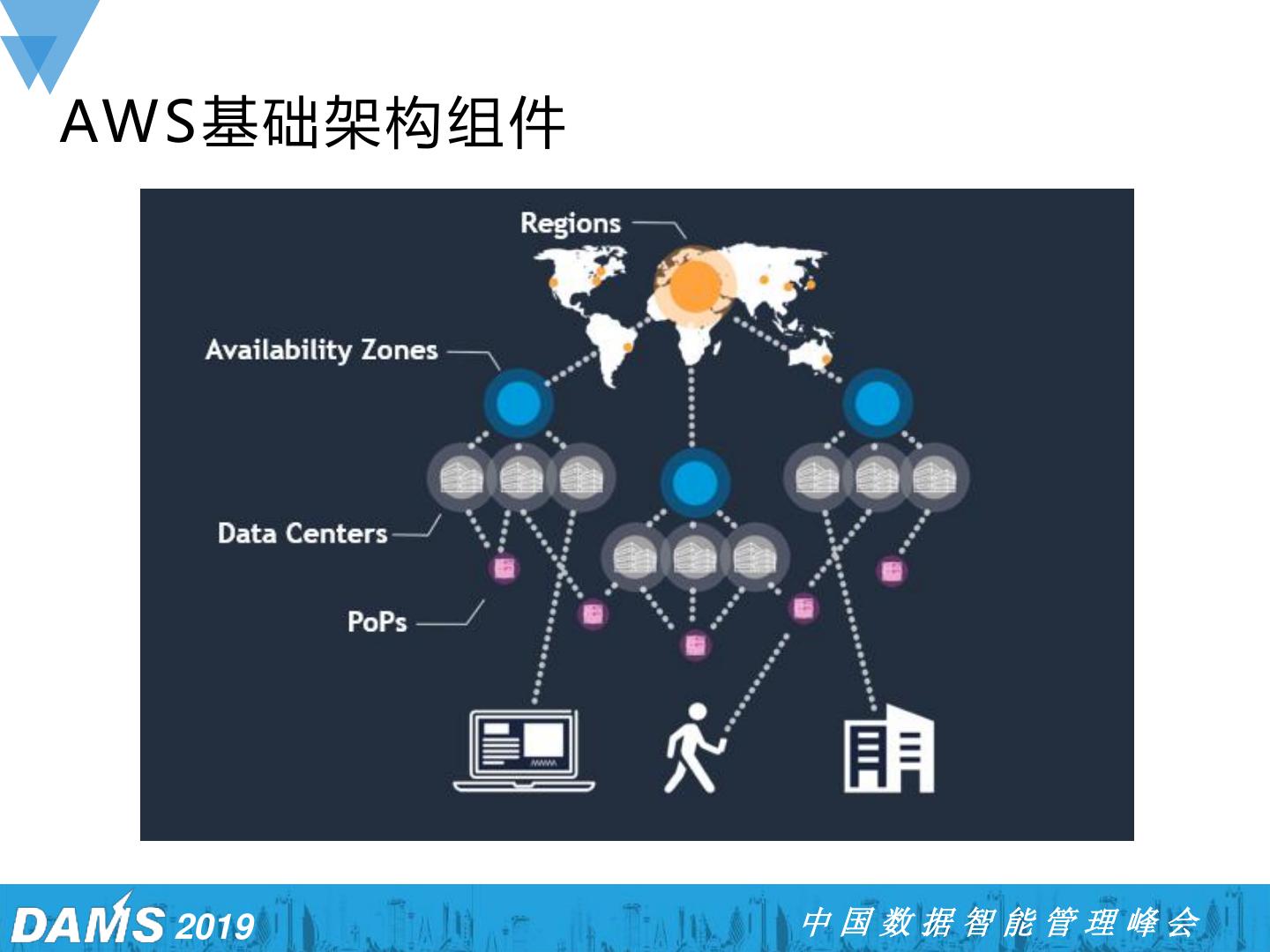
10 .AWS基础架构组件 2019 中国数据智能管理峰会
11 . AWS可用区(A Z)设计 • 通过一个或多个数据中心,在基础架构层面 进行完全隔离 • 两个AZ之间相隔几十公里 • 每个数据中心具有各自独立的电源系统 • 高达10万台服务器的规模 • 不同的数据中心之间通过高速网络进行连接 通过访问infrastructure.aws 了解更多的AWS 全球基础架构设施 2019 中国数据智能管理峰会
12 .Availability Zone 可用区 Beijing Region 北京区域 Ningxia Region 宁夏区域 • 每个region区域至少有两个可用区 Availability • 每个可用区都由多个数据中心组成 Availability Zone B Availability Availability • 可用区之间地理与网络都是独立设计与运营 Zone A Zone A Zone B • 可用区间网络延时保持在3ms以下 Availability • 可用区内延时保持在0.3ms以下 Zone A • 跨可用区的高可用部署 • 极低成本的城市圈级别的实时异地容灾方案 2019 中国数据智能管理峰会
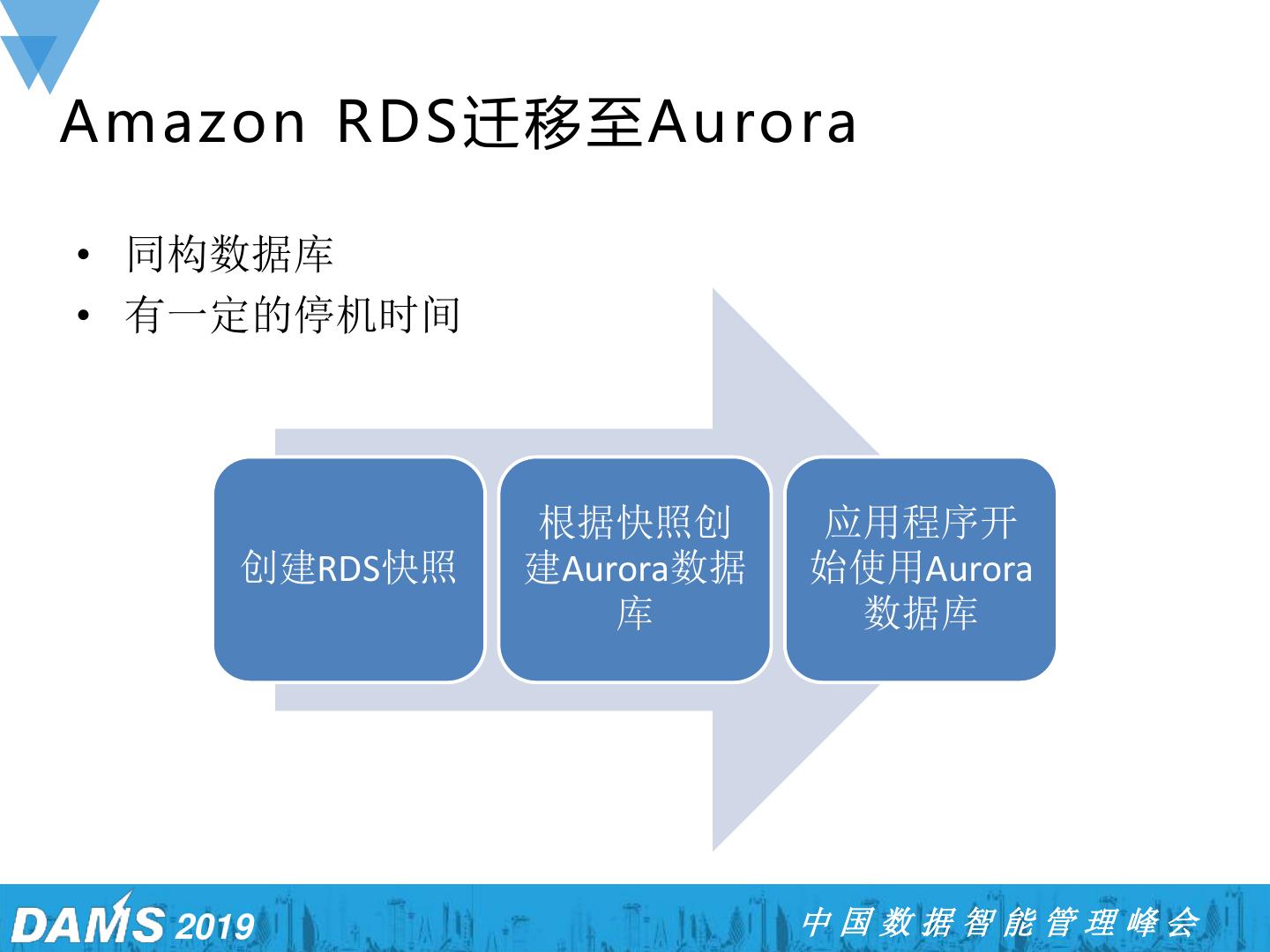
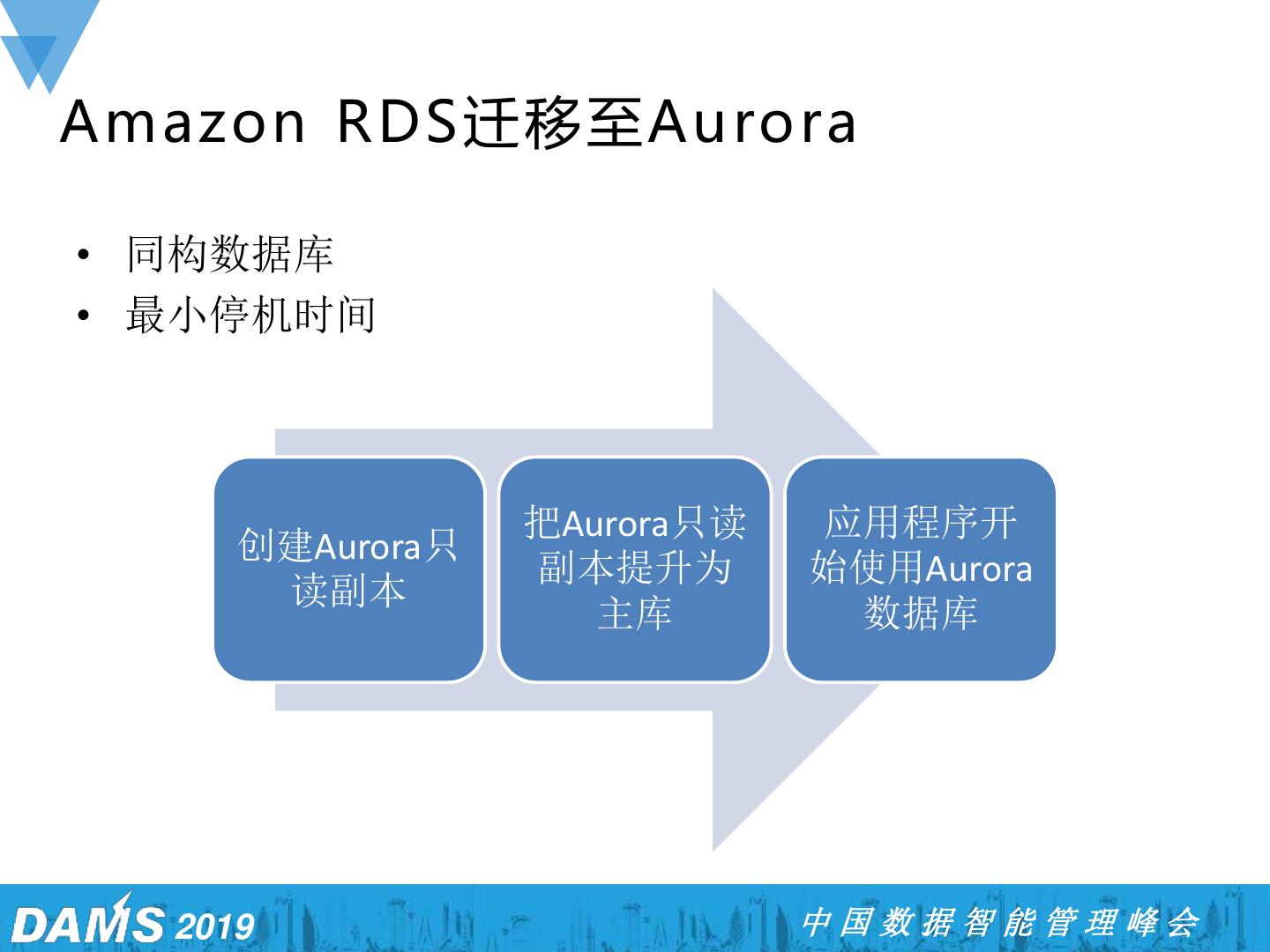
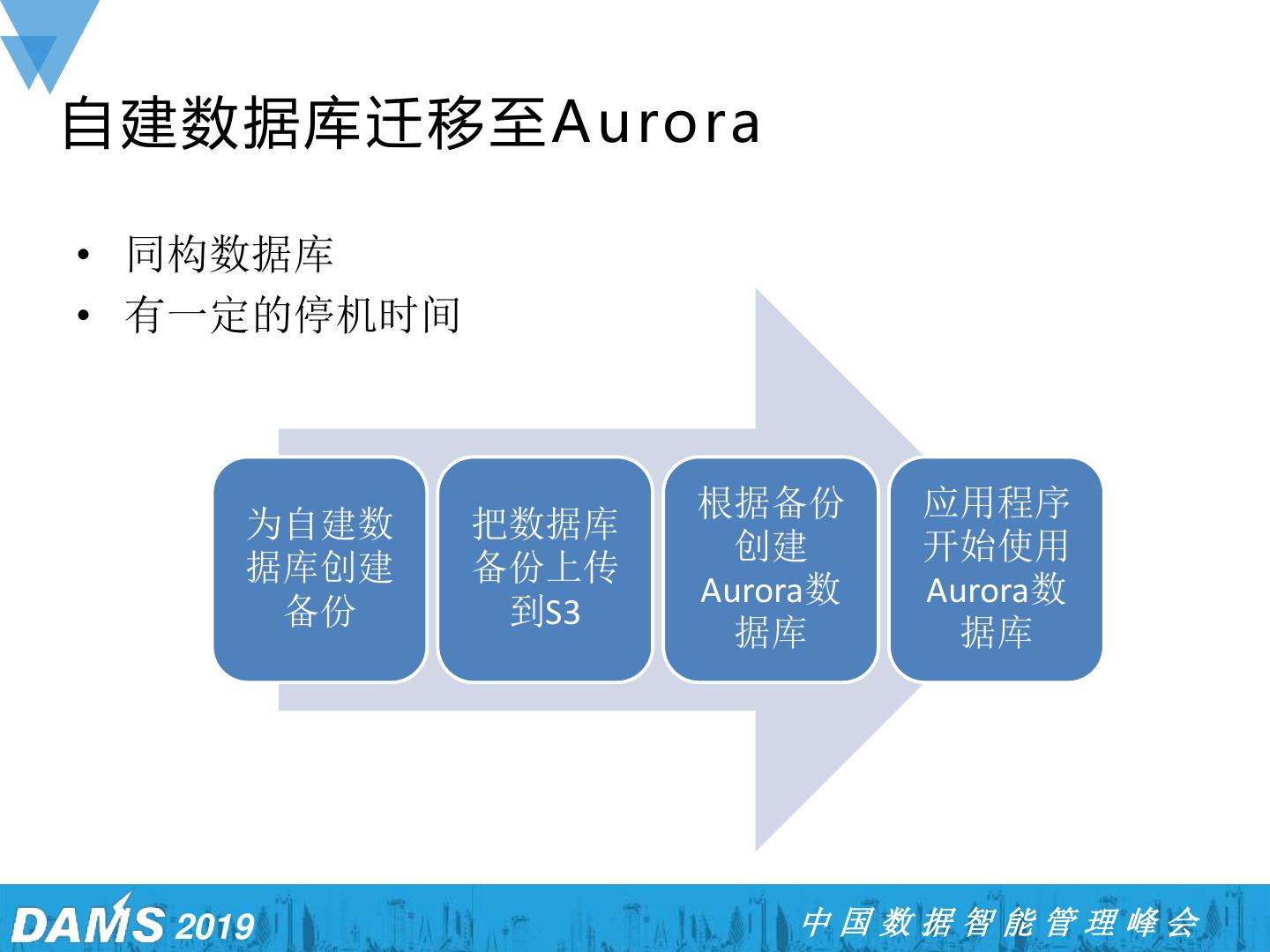
13 .议程 ➢ Aurora特性 ➢ Aurora技术架构 ➢ 迁移至Aurora ➢ Aurora客户案例 2019 中国数据智能管理峰会
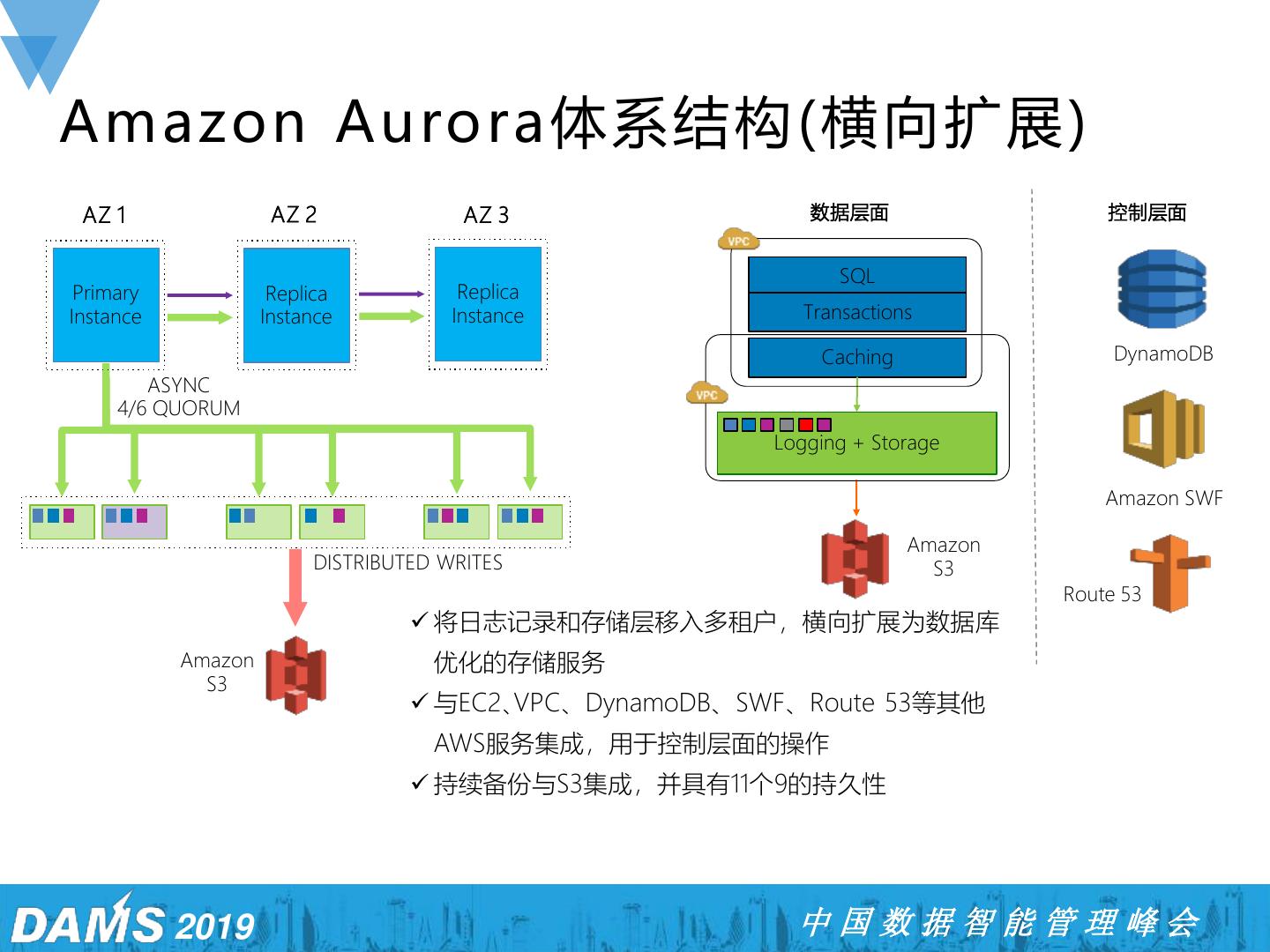
14 .Amazon Aurora 体系结构 (横向扩展) AZ 1 AZ 2 AZ 3 数据层面 控制层面 SQL Primary Replica Replica Instance Instance Instance Transactions Caching DynamoDB ASYNC 4/6 QUORUM Logging + Storage Amazon SWF Amazon DISTRIBUTED WRITES S3 Route 53 ✓ 将日志记录和存储层移入多租户,横向扩展为数据库 Amazon 优化的存储服务 S3 ✓ 与EC2、VPC、DynamoDB、SWF、Route 53等其他 AWS服务集成,用于控制层面的操作 ✓ 持续备份与S3集成,并具有11个9的持久性 2019 中国数据智能管理峰会
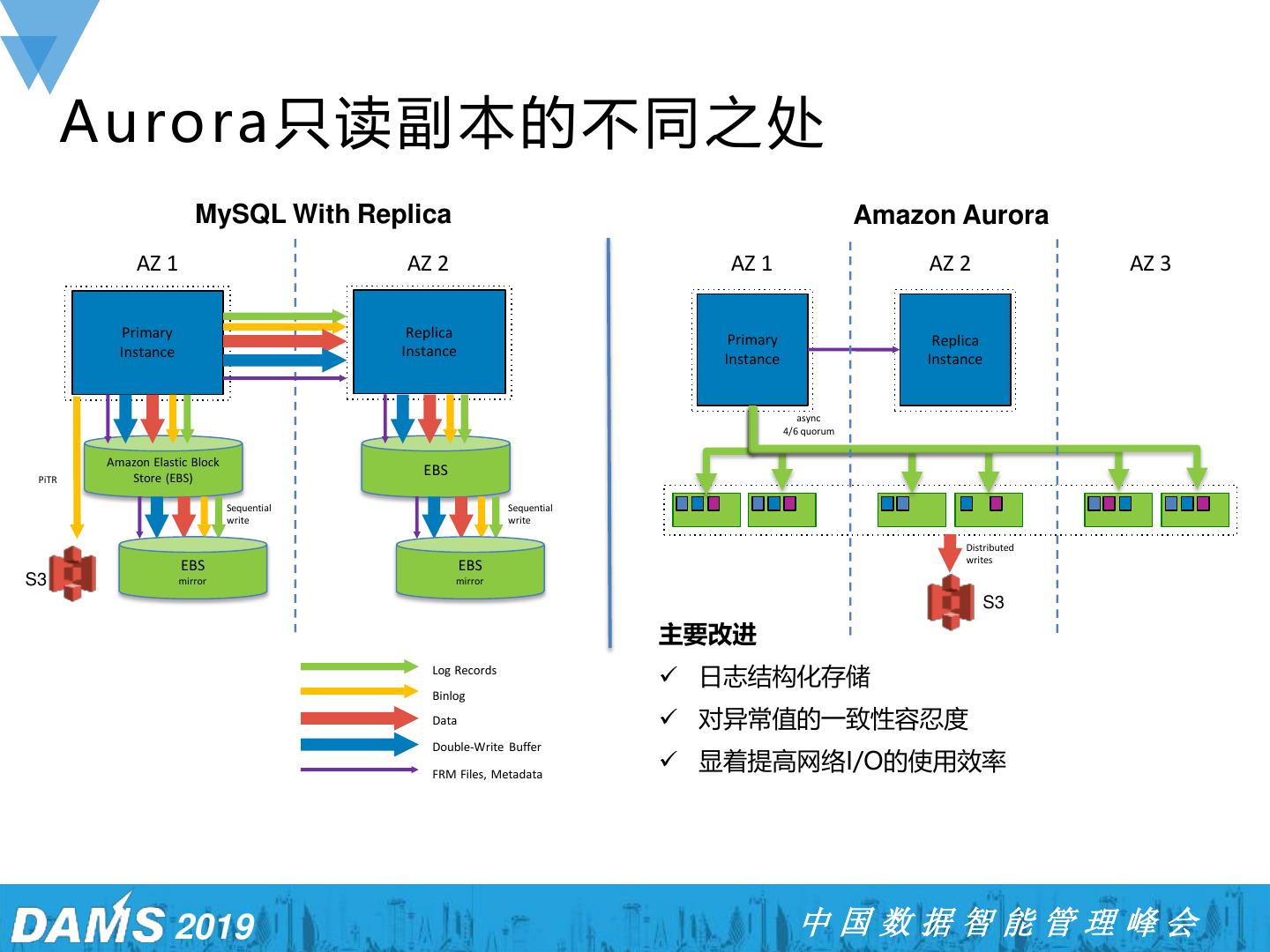
15 . Aurora只读副本的不同之处 MySQL With Replica Amazon Aurora AZ 1 AZ 2 AZ 1 AZ 2 AZ 3 Primary Replica Primary Replica Instance Instance Instance Instance async 4/6 quorum Amazon Elastic Block PiTR Store (EBS) EBS Sequential Sequential write write Distributed writes EBS EBS S3 mirror mirror S3 主要改进 Log Records ✓ 日志结构化存储 Binlog Data ✓ 对异常值的一致性容忍度 Double-Write Buffer FRM Files, Metadata ✓ 显着提高网络I/O的使用效率 2019 中国数据智能管理峰会
16 . Aurora存储节点的 I/O处理 STORAGE NODE I/O 控制流 ① 接收记录并添加到内存队列中 LOG RECORDS INCOMING QUEUE 1 7 ② 持久化日志记录并确认 Primary ACK GC ③ 组织日志记录并鉴别日志中的缝隙 Instance 2 UPDATE ④ 通过Gossip协议填补对等节点中缝隙 QUEUE COALESCE DATA ⑤ 将日志记录合并到新版本的数据块中 BLOCKS SCRUB 8 ⑥ 定期将日志和新块中转到S3 5 SORT GROUP 3 ⑦ 定期垃圾回收旧块 ⑧ 定期对块进行CRC校验 Peer PEER TO PEER GOSSIP HOT Storage LOG Nodes 4 实际运行效果 POINT IN TIME SNAPSHOT ① 所有步骤都是异步的 6 ② 仅有步骤1与2处于前台延时过程中 ③ 输入队列比MySQL少46倍 S3 BACKUP ④ 有利于延时敏感型操作 ⑤ 使用磁盘空间缓冲活动中的峰值 2019 中国数据智能管理峰会
17 . Amazon Aurora 存储引擎概述 • 数据在3 Availability Zones中复制6 份 • 持续备份到Amazon S3 (11个9的持 久性) AZ 1 AZ 2 AZ 3 Database • 持续监视节点和磁盘并自动修复 Node • 10GB 的区段作为修复和存储根据用 Storage 量自动增长的基础,存储最大扩展 Storage Storage Storage Storage Storage Storage Monitoring Node Node Node Node Node Node 到64 TB • Quorum system 读写; • Quorum membership 变更不会阻塞 Amazon S3 写 2019 中国数据智能管理峰会
18 .Amazon 存储引擎容错 • 可能问题? • 优化 Segment 损坏 (磁盘) • 4 out of 6 write quorum 节点损坏(主机) • 3 out of 6 read quorum AZ 损坏 (网络或数据中心) • Peer-to-peer replication for repairs AZ 1 AZ 2 AZ 3 AZ 1 AZ 2 AZ 3 SQL SQL Transaction Transaction Caching Caching 2019 中国数据智能管理峰会
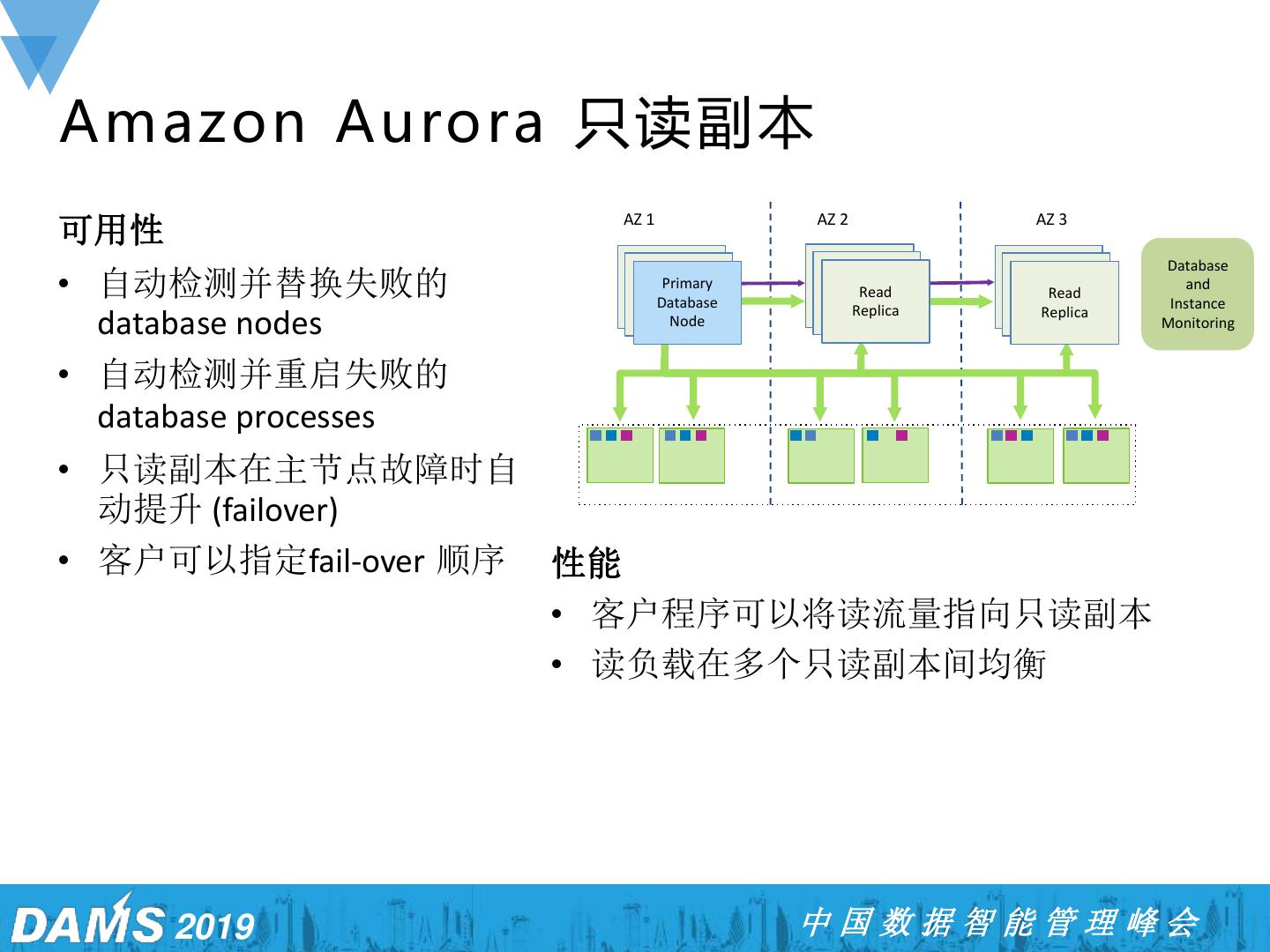
19 .Amazon Aurora 只读副本 AZ 2 可用性 AZ 1 AZ 3 Database • 自动检测并替换失败的 Primary Primary Primary Node Database Node Primary Primary Read Node Node Primary Primary Read Node Node and Instance Replica Replica database nodes Node Monitoring • 自动检测并重启失败的 database processes • 只读副本在主节点故障时自 动提升 (failover) • 客户可以指定fail-over 顺序 性能 • 客户程序可以将读流量指向只读副本 • 读负载在多个只读副本间均衡 2019 中国数据智能管理峰会
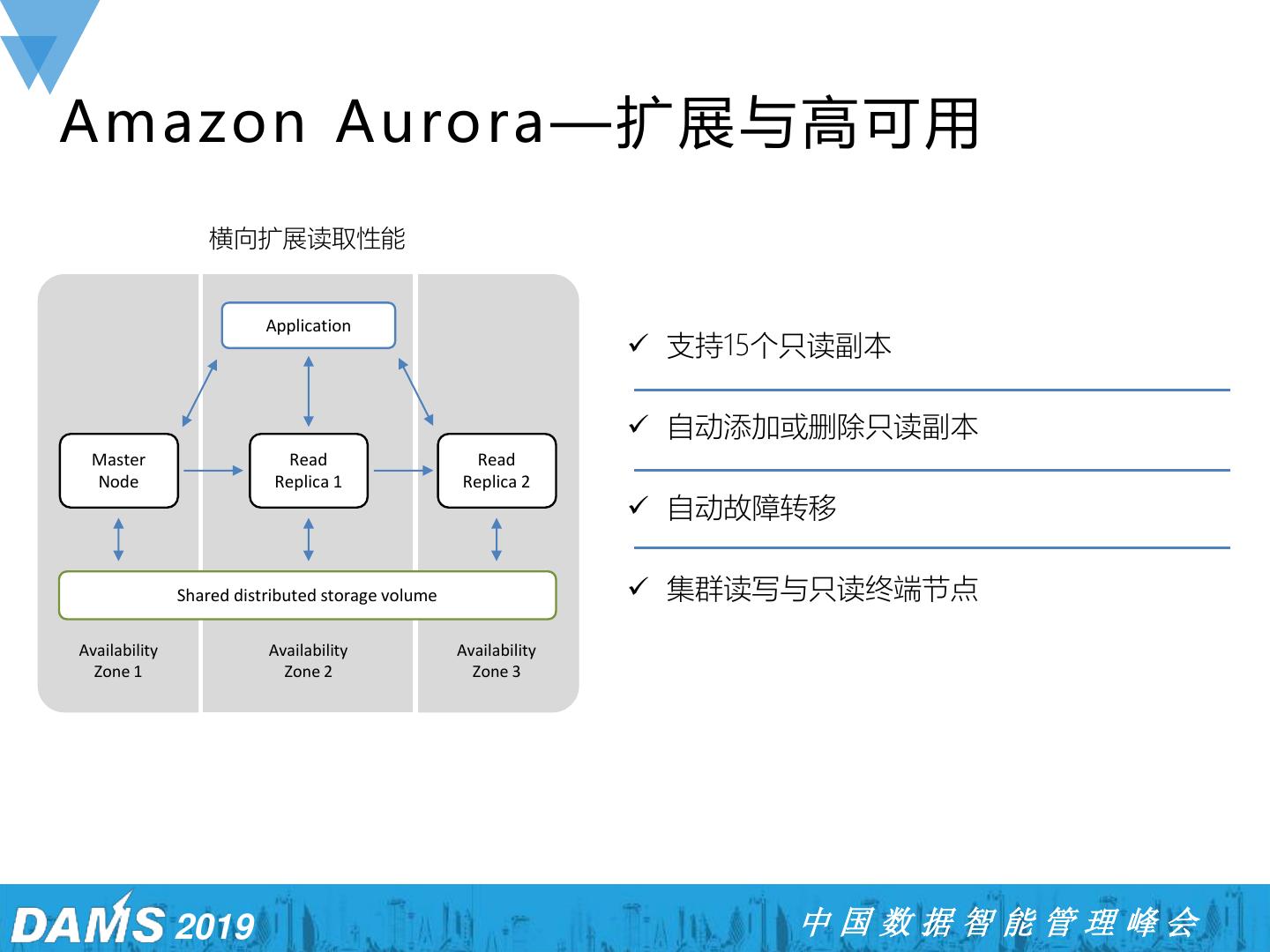
20 .Amazon Aurora —扩展与高可用 横向扩展读取性能 Application ✓ 支持15个只读副本 ✓ 自动添加或删除只读副本 Master Read Read Node Replica 1 Replica 2 ✓ 自动故障转移 Shared distributed storage volume ✓ 集群读写与只读终端节点 Availability Availability Availability Zone 1 Zone 2 Zone 3 2019 中国数据智能管理峰会
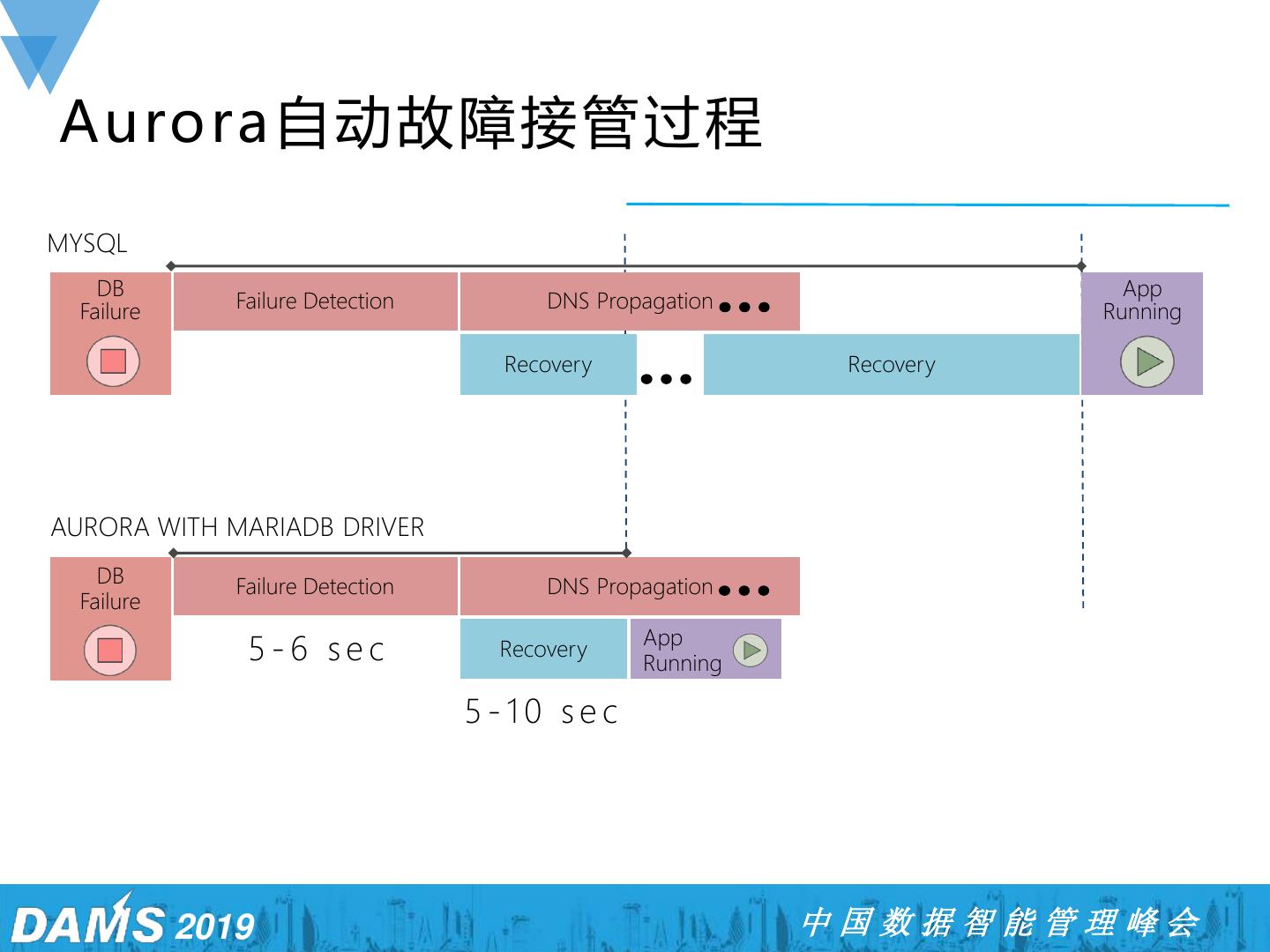
21 .Aurora自动故障接管过程 MYSQL DB App Failure Failure Detection DNS Propagation Running Recovery Recovery AURORA WITH MARIADB DRIVER DB Failure Detection DNS Propagation Failure App 5-6 sec Recovery Running 5-10 sec 2019 中国数据智能管理峰会
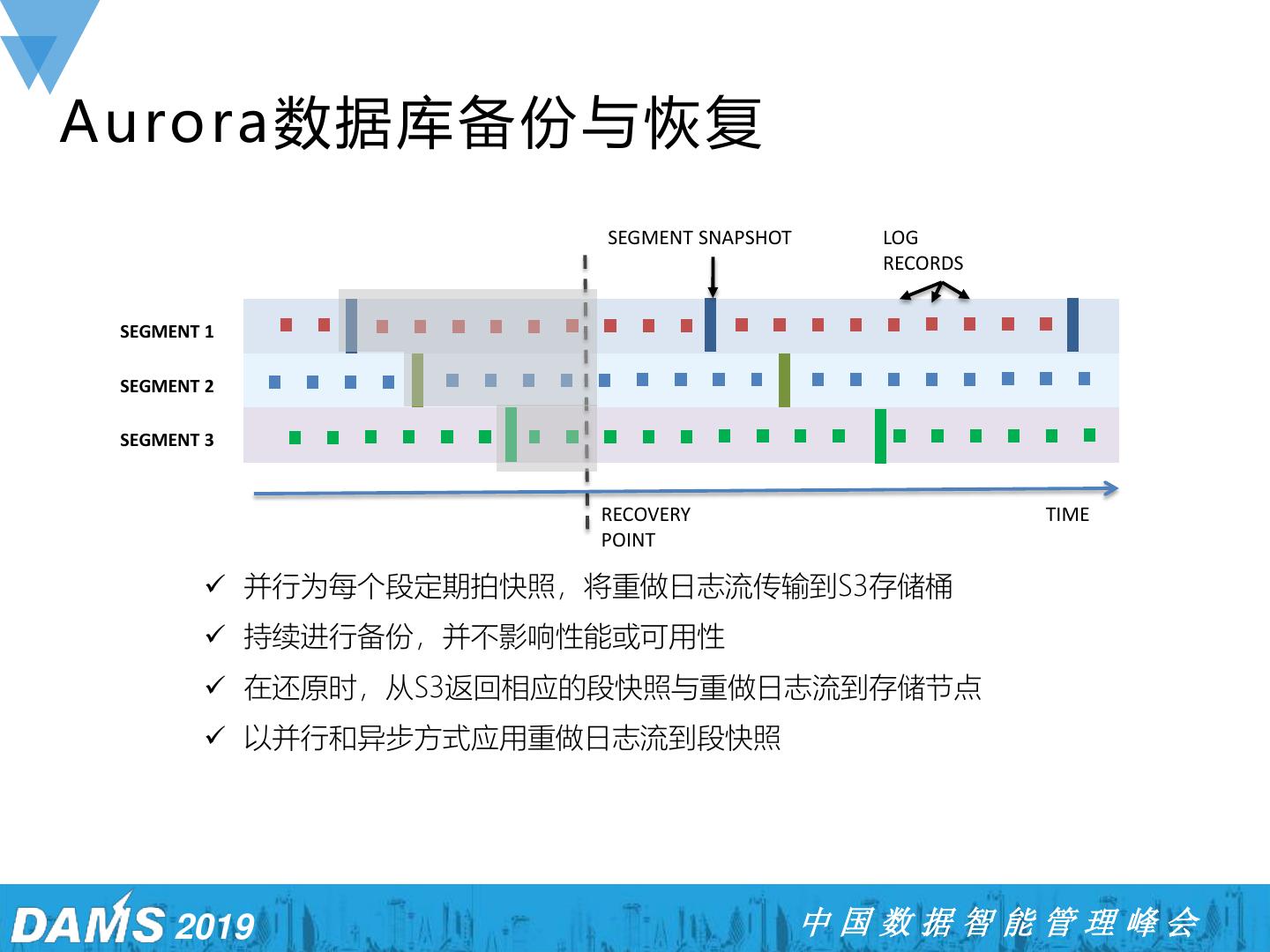
22 .Aurora数据库备份与恢复 SEGMENT SNAPSHOT LOG RECORDS SEGMENT 1 SEGMENT 2 SEGMENT 3 RECOVERY TIME POINT ✓ 并行为每个段定期拍快照,将重做日志流传输到S3存储桶 ✓ 持续进行备份,并不影响性能或可用性 ✓ 在还原时,从S3返回相应的段快照与重做日志流到存储节点 ✓ 以并行和异步方式应用重做日志流到段快照 2019 中国数据智能管理峰会
23 .Amazon Aurora 紧急崩溃恢复 传统数据库 Amazon Aurora • 需要从last checkpoint重放所有日志 • 启动时无需重放,存储系统 事务感知 • 一般来说从checkpoints开始5分钟内 • 底层存储由多个segment组成,不同 • 在MySQL 和 PostgreSQL上是Single- segment有自己的重做日志 threaded需要大量的disk accesses • 应用日志操作是并行,分布和异步的 Crash at T0 requires Crash at T0 will result in logs being applied to a re-application of the each segment on demand, in parallel, SQL in the log since asynchronously last checkpoint Checkpointed Data Log T0 T0 2019 中国数据智能管理峰会
24 .Aurora只读副本自动伸缩技术 READER END-POINT READ READ READ MASTER REPLICA REPLICA REPLICA SHARED DISTRIBUTED STORAGE VOLUME Availability Availability Availability Zone 1 Zone 2 Zone 3 ✓ 跨多个可用区最多可提升15个只读副本 ✓ 基于重做日志复制的副本低延时 - 通常<10毫秒 ✓ 读取器端点具有负载平衡和自动缩放(CPU及连接数) 2019 中国数据智能管理峰会
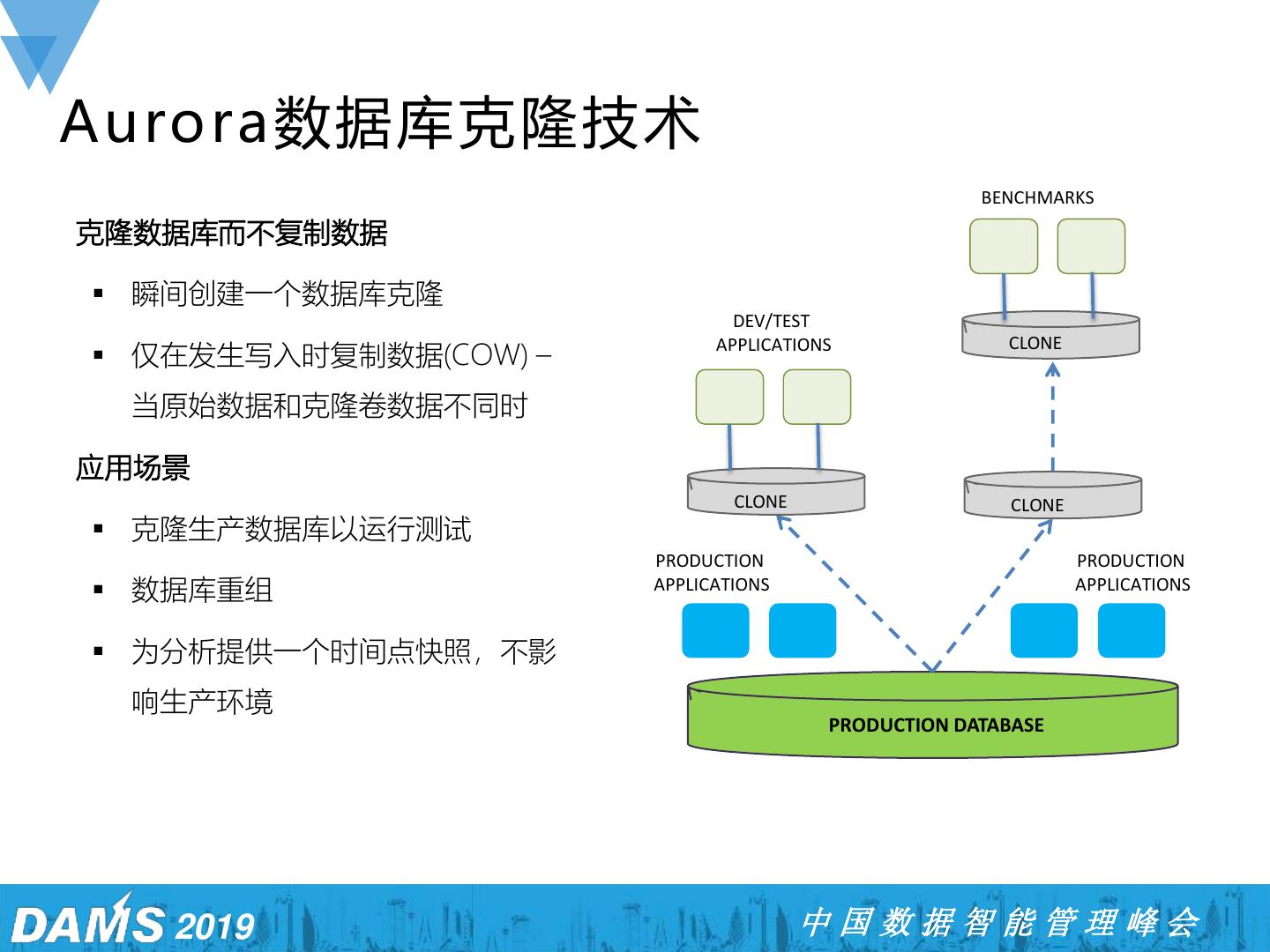
25 .Aurora数据库克隆技术 BENCHMARKS 克隆数据库而不复制数据 ▪ 瞬间创建一个数据库克隆 DEV/TEST ▪ 仅在发生写入时复制数据(COW) – APPLICATIONS CLONE 当原始数据和克隆卷数据不同时 应用场景 CLONE CLONE ▪ 克隆生产数据库以运行测试 PRODUCTION PRODUCTION ▪ 数据库重组 APPLICATIONS APPLICATIONS ▪ 为分析提供一个时间点快照,不影 响生产环境 PRODUCTION DATABASE 2019 中国数据智能管理峰会
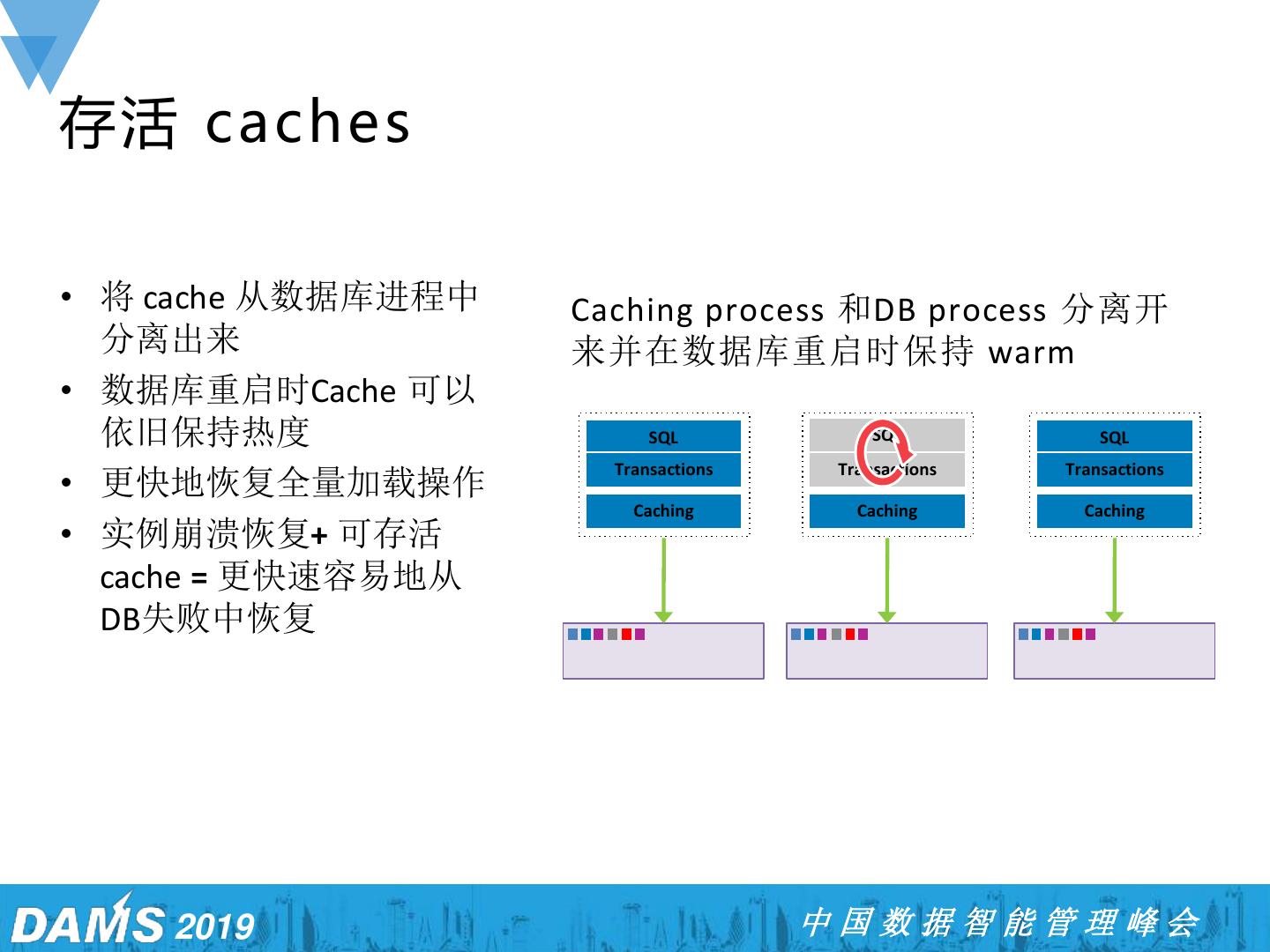
26 .存活 caches • 将 cache 从数据库进程中 Caching process 和DB process 分离开 分离出来 来并在数据库重启时保持 warm • 数据库重启时Cache 可以 依旧保持热度 SQL SQL SQL Transactions Transactions Transactions • 更快地恢复全量加载操作 Caching Caching Caching • 实例崩溃恢复+ 可存活 cache = 更快速容易地从 DB失败中恢复 2019 中国数据智能管理峰会
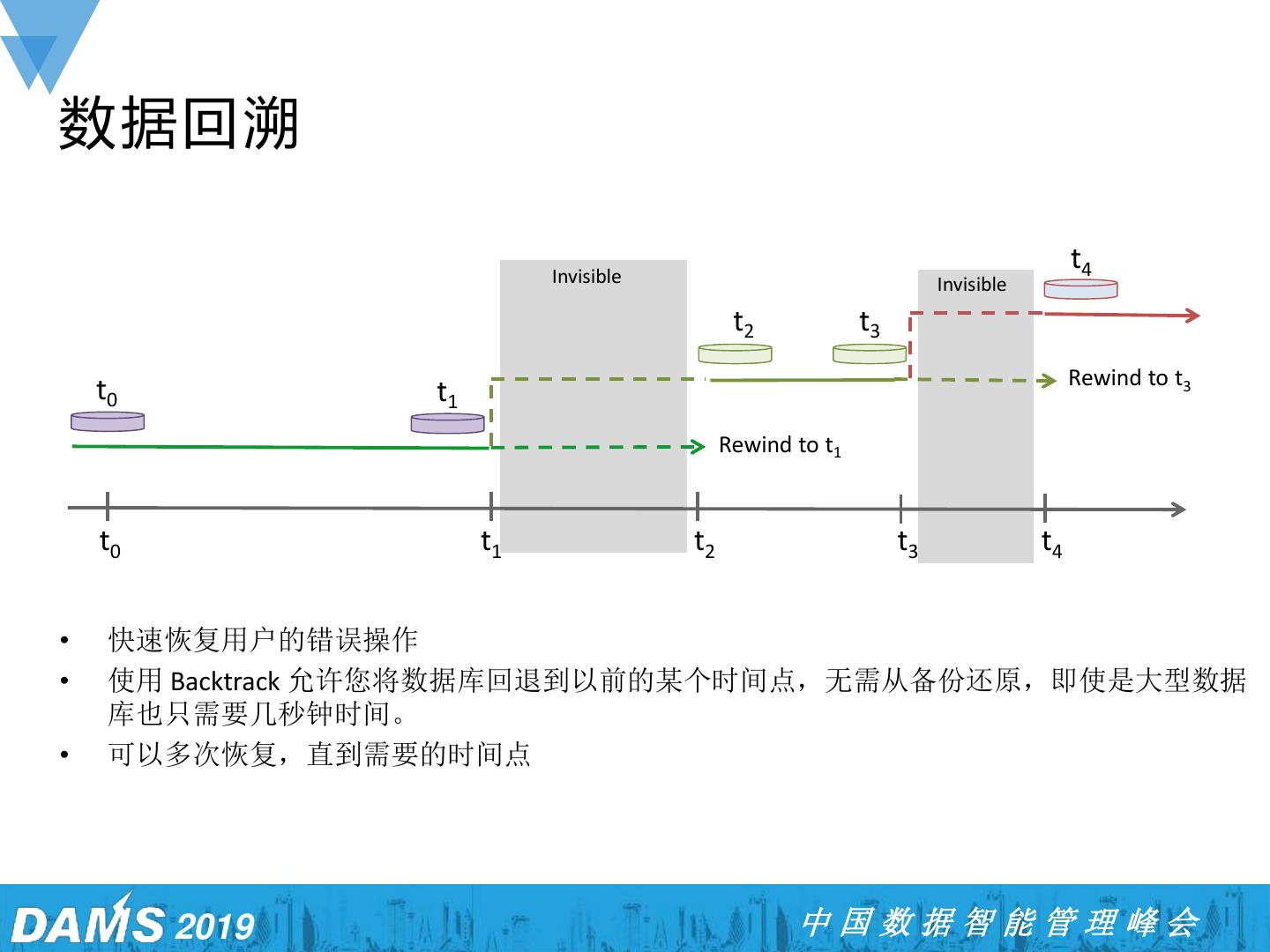
27 .数据回溯 Invisible t4 Invisible t2 t3 Rewind to t3 t0 t1 Rewind to t1 t0 t1 t2 t3 t4 • 快速恢复用户的错误操作 • 使用 Backtrack 允许您将数据库回退到以前的某个时间点,无需从备份还原,即使是大型数据 库也只需要几秒钟时间。 • 可以多次恢复,直到需要的时间点 2019 中国数据智能管理峰会
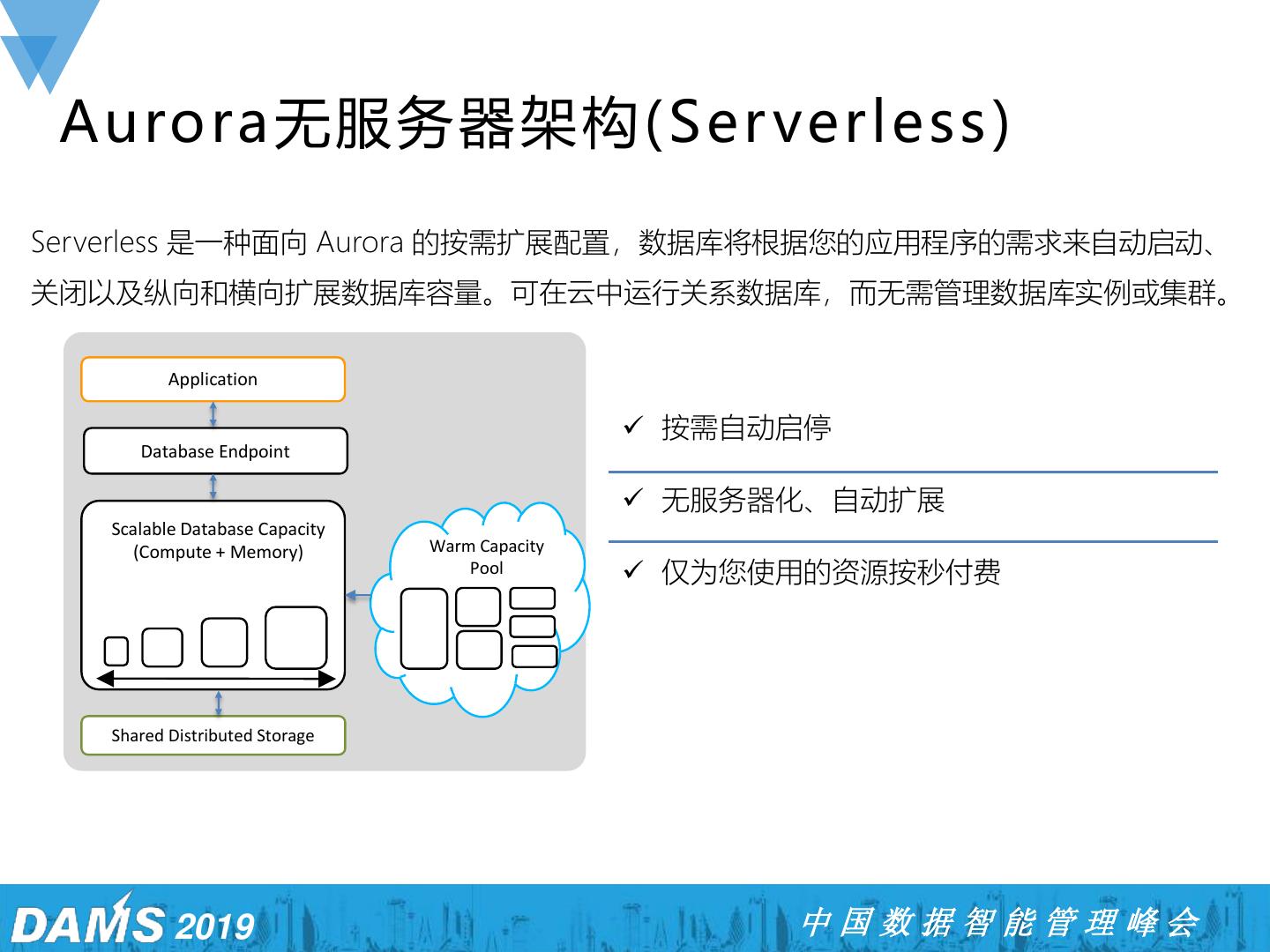
28 . Aurora无服务器架构 (Ser verless ) Serverless 是一种面向 Aurora 的按需扩展配置,数据库将根据您的应用程序的需求来自动启动、 关闭以及纵向和横向扩展数据库容量。可在云中运行关系数据库,而无需管理数据库实例或集群。 Application ✓ 按需自动启停 Database Endpoint ✓ 无服务器化、自动扩展 Scalable Database Capacity (Compute + Memory) Warm Capacity Pool ✓ 仅为您使用的资源按秒付费 Shared Distributed Storage 2019 中国数据智能管理峰会
29 .议程 ➢ Aurora特性 ➢ Aurora技术架构 ➢ 迁移至Aurora ➢ Aurora客户案例 2019 中国数据智能管理峰会
3秒后跳转登录页面
去登陆

