如何架构海量存储系统
分享
点赞
0
收藏
1
下载 2
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 云+社区
云+社区
/
发布于
/
8066
人观看
海量存储是云计算中最底层和核心的基础设施,也是后台众多技术面临的技术挑战最大的。本期议题将带您深度剖析海量存储系统,怎样从零开始构建出一个海量存储系统,以及结合多年的运营经验,介绍下在架构设计上曾经踩过的坑。
展开查看详情
2 .如何架构海量存储系统
朱建平
腾讯存储研发中心副总监
�
3 .SPEAKER
朱建平
腾讯云资深技术专家 存储研发中心副总监
硕士毕业于武汉大学数学系,2018年加入腾讯,致力于分布式存
储平台研发工作10年,参与设计与研发分布式Key-Value存储平台
TDB、TSSD以及EB级文件存储平台TFS。同时,近年来也带领团队
从事网络传输加速,基于FPGA的异构计算,视频编解码器,医疗
AI的相关技术研发和探索。
�
4 .CONTENTS
1 2 3 4
认识存储 从零构建海量存储系统 关键技术 经验分享
�
5 .认识存储——面粉
• 内存
• 非易失性内存(NVM)
• 固态硬盘
性能,成本,IO约束
• 机械硬盘
• 磁带
• 蓝光盘
�
6 .认识存储——面包
AWS S3接口
• 对象存储 Block Device接口
Posix-Compliant FileSystem接口
SQL接口
• 数据库 Redis/Memcached接口
MogoDB接口
图存储,时序数据库, ElasticSearch,HBase/Cassandra列存储,…
�
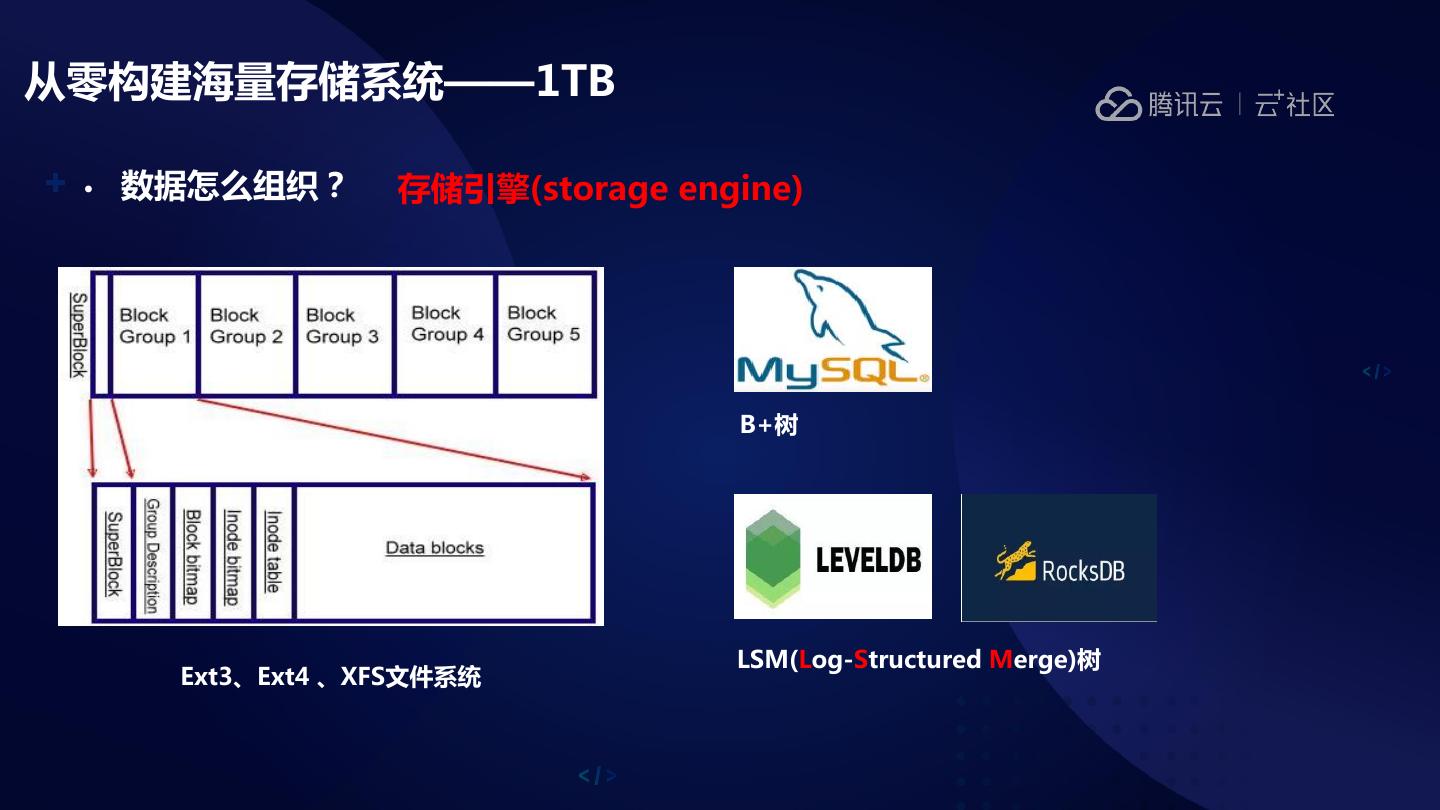
7 .从零构建海量存储系统——1TB
• 数据怎么组织? 存储引擎(storage engine)
B+树
LSM(Log-Structured Merge)树
Ext3、Ext4 、XFS文件系统
�
8 .从零构建海量存储系统——10TB
• 读写访问1万次/秒, 10毫秒的响应延时? 存储介质 + 存储服务器
�
9 .从零构建海量存储系统——100TB
• 1台服务器存不下了? 数据分布 + 数据多副本
• DHT(Distributed Hash Table)
• CRUSH(Controlled Replication Under Scalable Hashing)
Hierarchical Cluster Map
• 数据分布表
(range_begin,range_end) → Shard
shard → (replica#1,replica#2,…,replica#3)
�
10 .从零构建海量存储系统——1PB(1024TB)
• 设备多了,管理很费劲? 存储运维系统(OSS)
• 业务接入&部署结构
• 容量管理:容量统计,容量预测,设备上架/下架,自动扩容
• 磁盘/设备管理:坏盘/宕机探测,剔除/置换,磁盘更换/重建,状态恢复
• 数据备份:数据备份,定点回档
• 数据搬迁(Migration)
�
11 .从零构建海量存储系统——10PB
• 数据热度变化:当初合理的存储方案 不再合理? 数据分层(Data Tiering)
纠删存储(冷数据1.x份) 自动数据分层调度
�
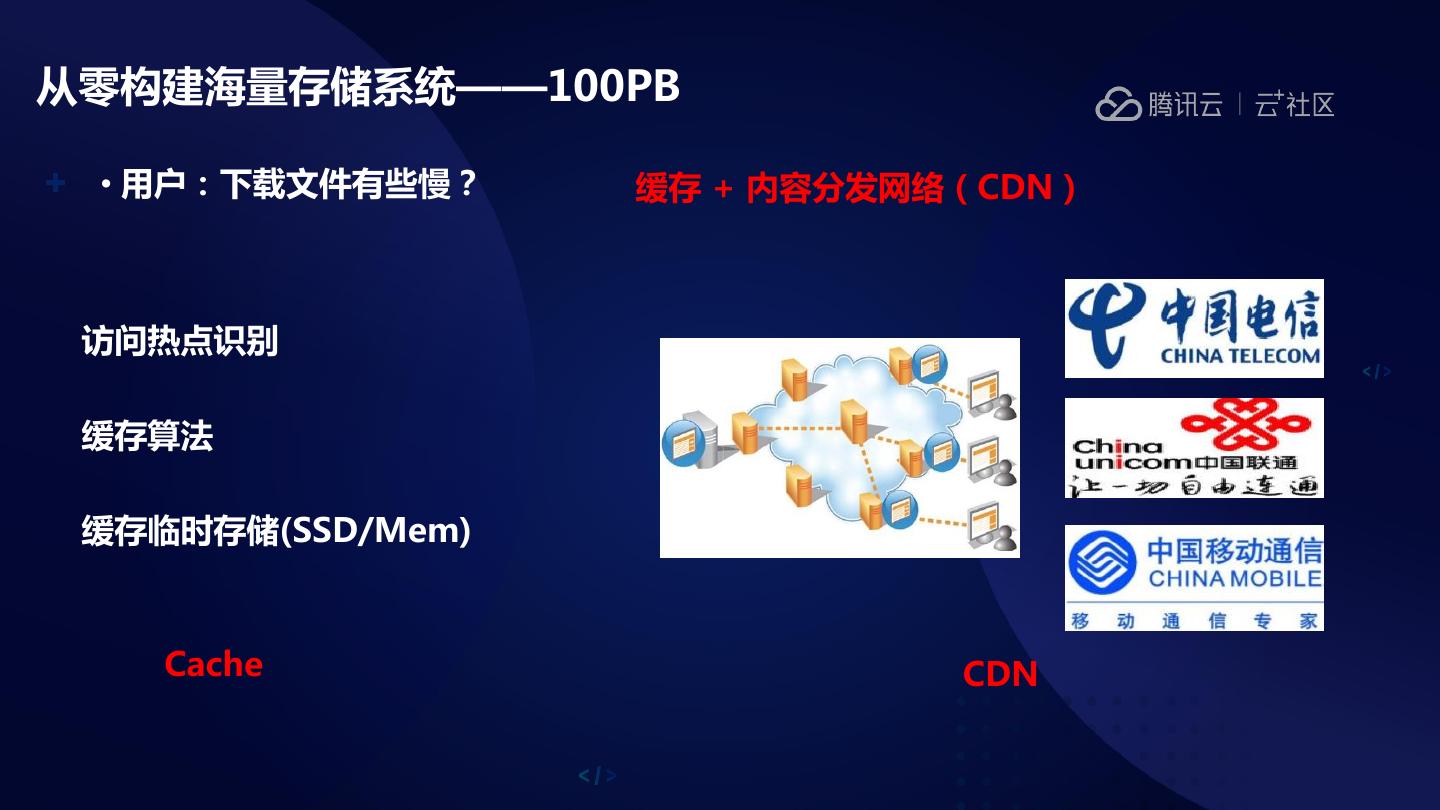
12 .从零构建海量存储系统——100PB
• 用户:下载文件有些慢? 缓存 + 内容分发网络(CDN)
访问热点识别
缓存算法
缓存临时存储(SSD/Mem)
Cache CDN
�
13 .从零构建海量存储系统——1EB
• 资源管理:存储设备晚上CPU都很闲? 虚拟化&容器
�
14 .海量存储系统的关键技术
• 数据分布算法(Sharding):将多个记录分散存储到多个存储节点
• 存储引擎(Storage Engine):索引数据,实现空间利用率+IO性能与索引空间的平衡
• 数据一致性协议( Raft & Paxos):并发访问和故障时,实现多数据副本的一致性
• 数据迁移(Migration Service):数据分层调度&安全搬迁数据
• 磁盘管理(Disk Service):坏盘探测,更换与数据修复
• 数据容灾&恢复(Data Backup & Recovering):备份&定点回档,多AZ与异地容灾
�
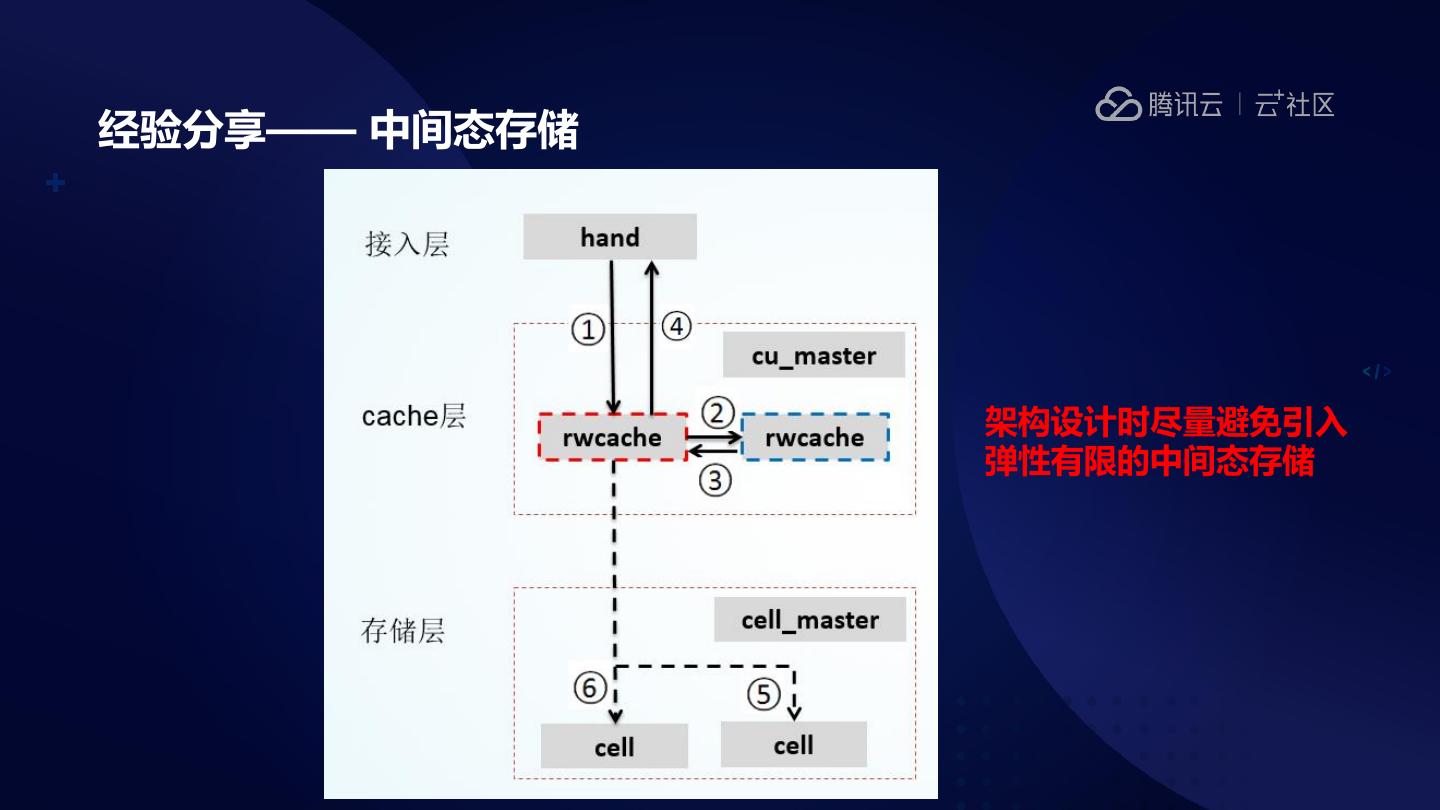
15 .经验分享—— 中间态存储
架构设计时尽量避免引入
弹性有限的中间态存储
�
16 .经验分享—— 运营可控
• TSSD 1.0版本,基于SSD的键值对存储(uin->value)
• 数据分布表:
grid = (uin/10000) % 10万
grid => (node1,node2)
海量存储运营中,运
营可控性非常关键
• 数据搬迁一个grid:
数据大小: 0 ~5G
SSD盘IO : 0 ~1万次
迁移耗时: 1s~30min
�