展开查看详情
2 .⾦金金数据
⼈人⼈人可⽤用的数据平台,助⼒力力⼯工作,成就商业。
⾦金金数据,⼈人⼈人可⽤用的数据平台,帮助个⼈人和企业客户快速设计表单,搭建
业务数据系统,如调查、预约、登记、获客、抽奖、考试、订单等等。⾦金金
数据收集和管理理⽇日常⼯工作和业务运转中的数据,助⼒力力个⼈人⼯工作效率提升,
成就企业商业价值。
⾃自2012年年上线以来,⾦金金数据已经为超过400万的个⼈人和企业客户,提供⾼高
效、安全、可靠的数据服务,赢得了了客户的认可,帮助客户获得成功。
�
3 .提纲
• ⾦金金数据的业务特性
• 数据库选型
• ⾦金金数据数据架构⽅方案
�
4 .基本概念介绍
表单
• 可以是⼀一个在线的调查问卷,或者在线投票,每个表单中包含很多题⽬目,可以是选
择题、填空题、下拉菜单题⽬目等,⽤用户可以填写并提交数据。
表单数据(表单记录)
• 代表⽤用户填写表单的记录,包括每个题⽬目⽤用户提交的内容,例例如选项值,⽂文本内容
等。
�
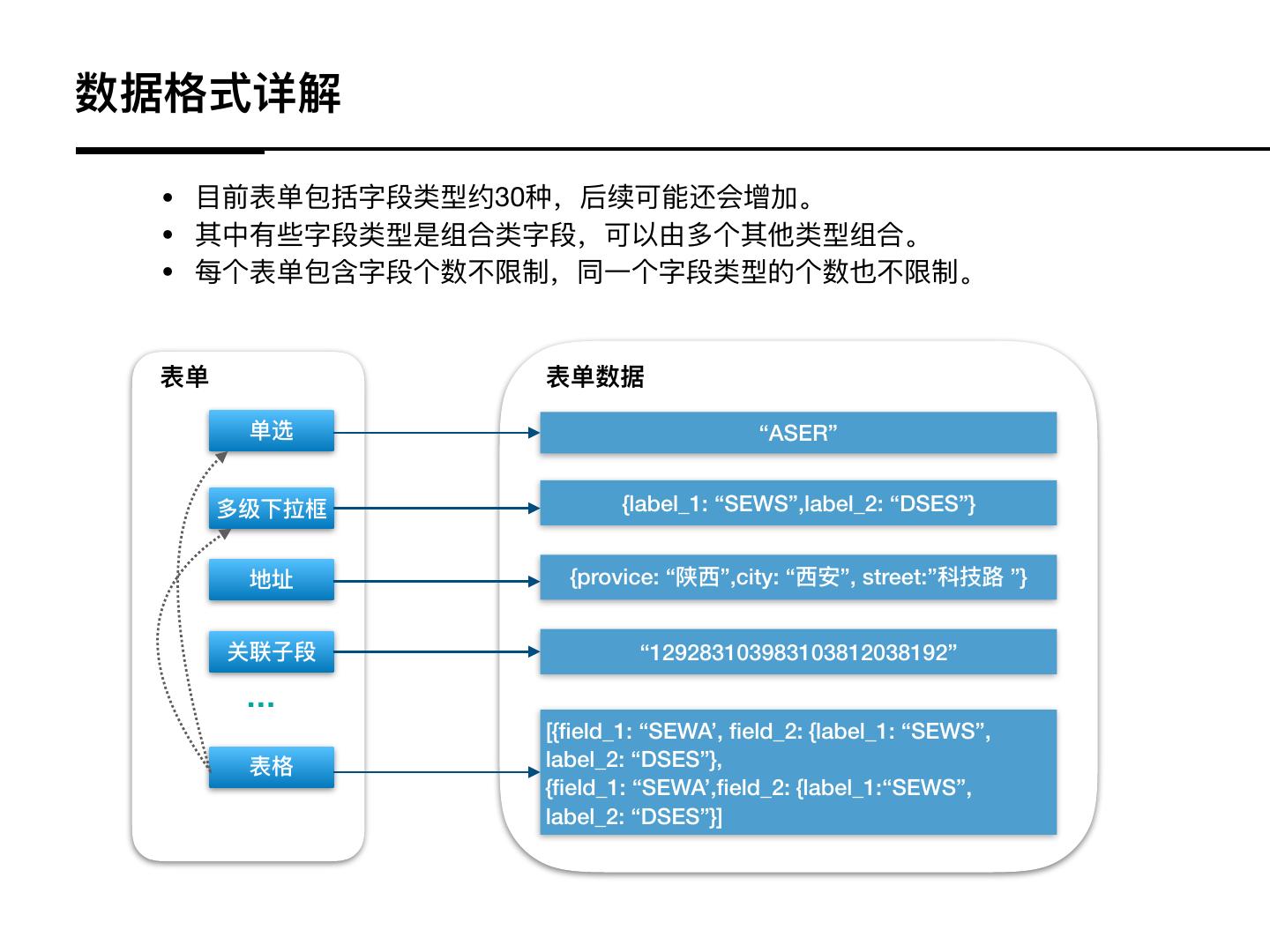
5 .数据格式详解
• ⽬目前表单包括字段类型约30种,后续可能还会增加。
• 其中有些字段类型是组合类字段,可以由多个其他类型组合。
• 每个表单包含字段个数不不限制,同⼀一个字段类型的个数也不不限制。
表单 表单数据
单选 “ASER”
多级下拉框 {label_1: “SEWS”,label_2: “DSES”}
地址 {provice: “陕⻄西”,city: “⻄西安”, street:”科技路路 ”}
关联⼦子段 “129283103983103812038192”
…
[{field_1: “SEWA’, field_2: {label_1: “SEWS”,
表格 label_2: “DSES”},
{field_1: “SEWA’,field_2: {label_1:“SEWS”,
label_2: “DSES”}]
�
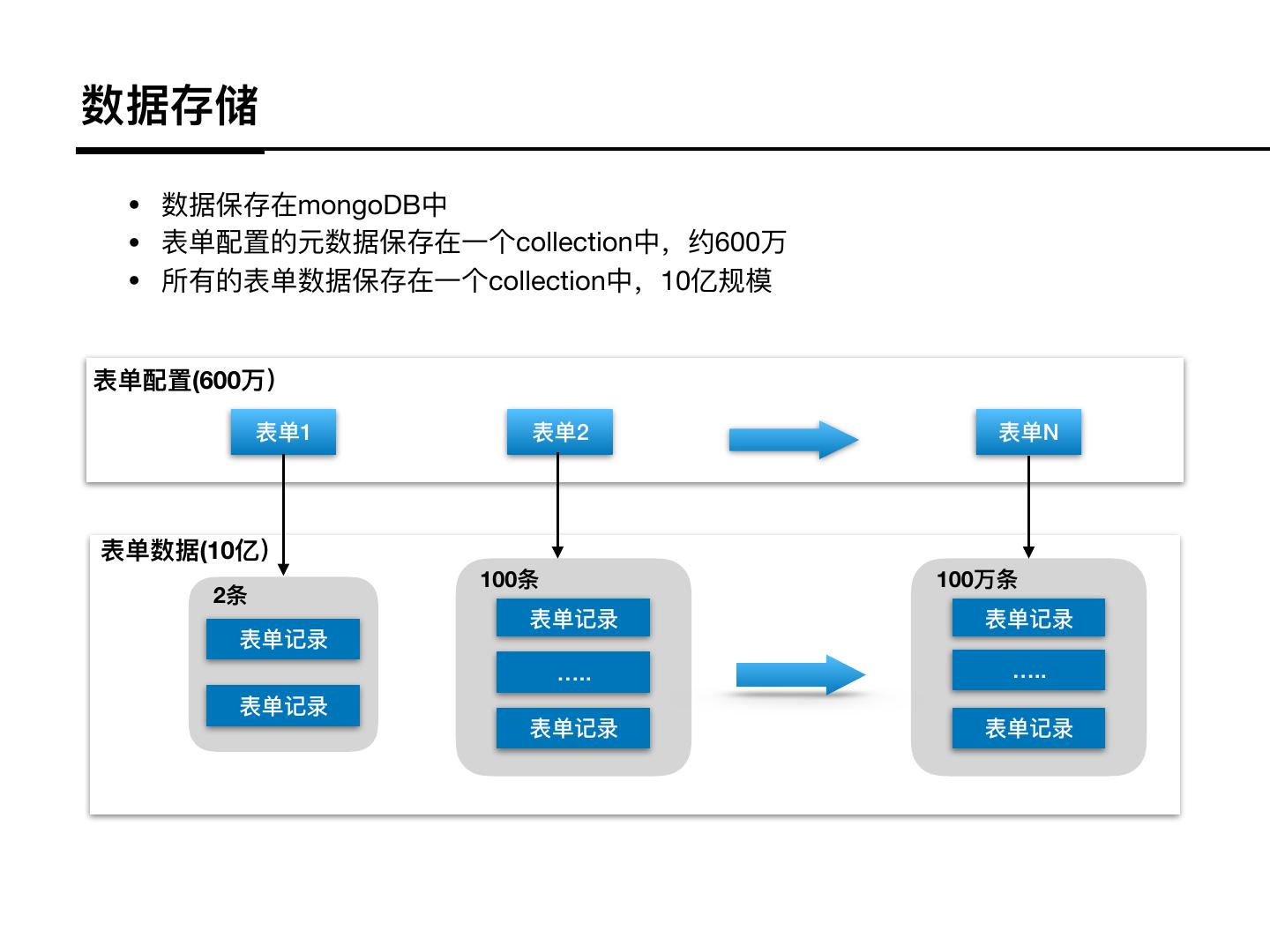
6 .数据存储
• 数据保存在mongoDB中
• 表单配置的元数据保存在⼀一个collection中,约600万
• 所有的表单数据保存在⼀一个collection中,10亿规模
表单配置(600万)
表单1 表单2 表单N
表单数据(10亿)
100条 100万条
2条
表单记录 表单记录
表单记录
….. …..
表单记录
表单记录 表单记录
�
7 .表单关联
• ⼀一个表单中的某个字段可以关联另外⼀一个表单中的⼀一个字段
• ⼀一个表单可以同时关联⼀一个表单的多个字段,或者多个表单的多个字段
• 表单关联没有⽅方向限制。
Form1 Form2
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
Field_1 Field_2 Field_N
�
8 .业务逻辑
• 100W记录以上的表单,包含多个条件和关联⼦子段组合查询在1S内完成。
• 100W记录以上的表单,包含多个条件和关联⼦子段聚合计算在1S内完成。
1.⼦子段1单选 为 A, ⼦子段5多选包含B和C,⼦子段11表
格中第⼀一列列选择F,同时⽂文本输⼊入包含“天空” 的前100
组合查询 条记录和总⾏行行数。
2. ⼦子段2单选为C, ⼦子段3关联字段的另外⼀一个表格的
字段7的选项为C的前100条记录和总⾏行行数
1. 字段1单选为C,字段7表格第⼆二列列选择为F的情况
汇聚计算 下,表格第三列列各个选项的汇总数据。
2. ⼦子端1单选为D,地段8 地址在陕⻄西⻄西安, ⼦子段10关
联的表单中第5字段数字收⼊入的最⼤大值最⼩小值,平均
值。
�
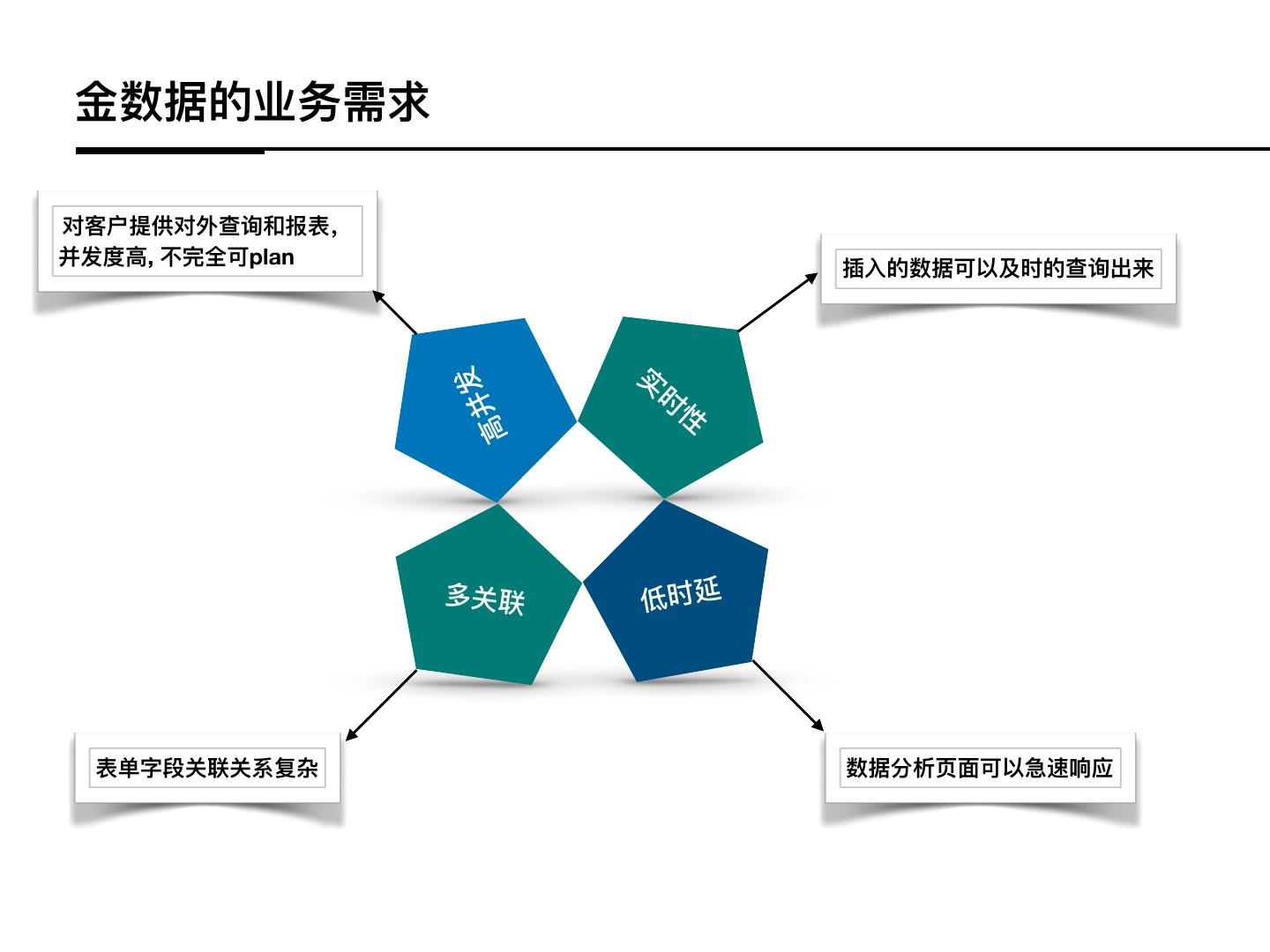
9 .⾦金金数据的业务需求
对客户提供对外查询和报表,
并发度⾼高, 不不完全可plan 插⼊入的数据可以及时的查询出来
实
发
时
性
⾼高 并
多关联 低时延
表单字段关联关系复杂 数据分析⻚页⾯面可以急速响应
�
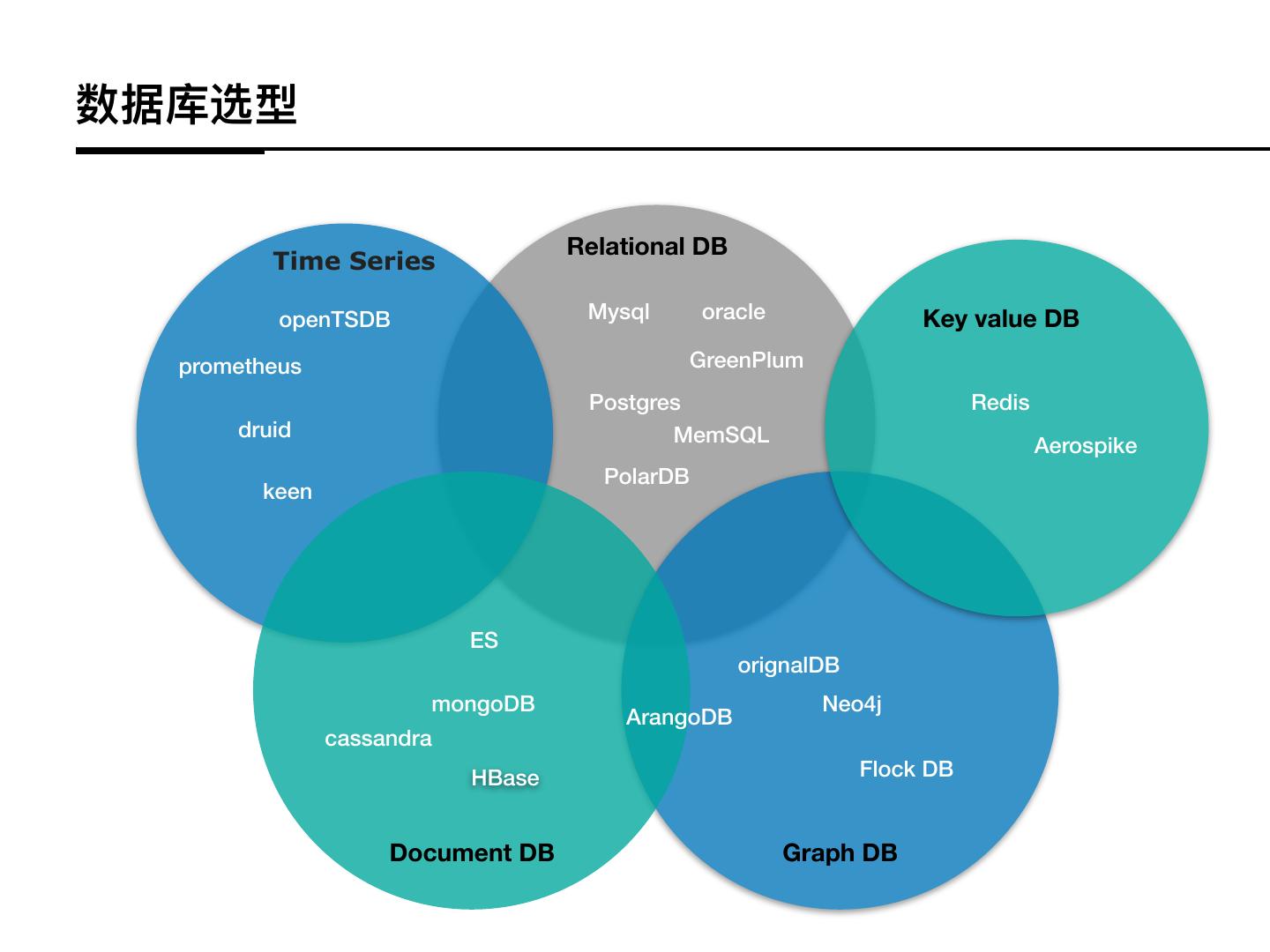
11 .数据库选型
Relational DB
Time Series
openTSDB Mysql oracle Key value DB
prometheus GreenPlum
Postgres Redis
druid MemSQL Aerospike
PolarDB
keen
ES
orignalDB
mongoDB Neo4j
ArangoDB
cassandra
HBase Flock DB
Document DB Graph DB
�
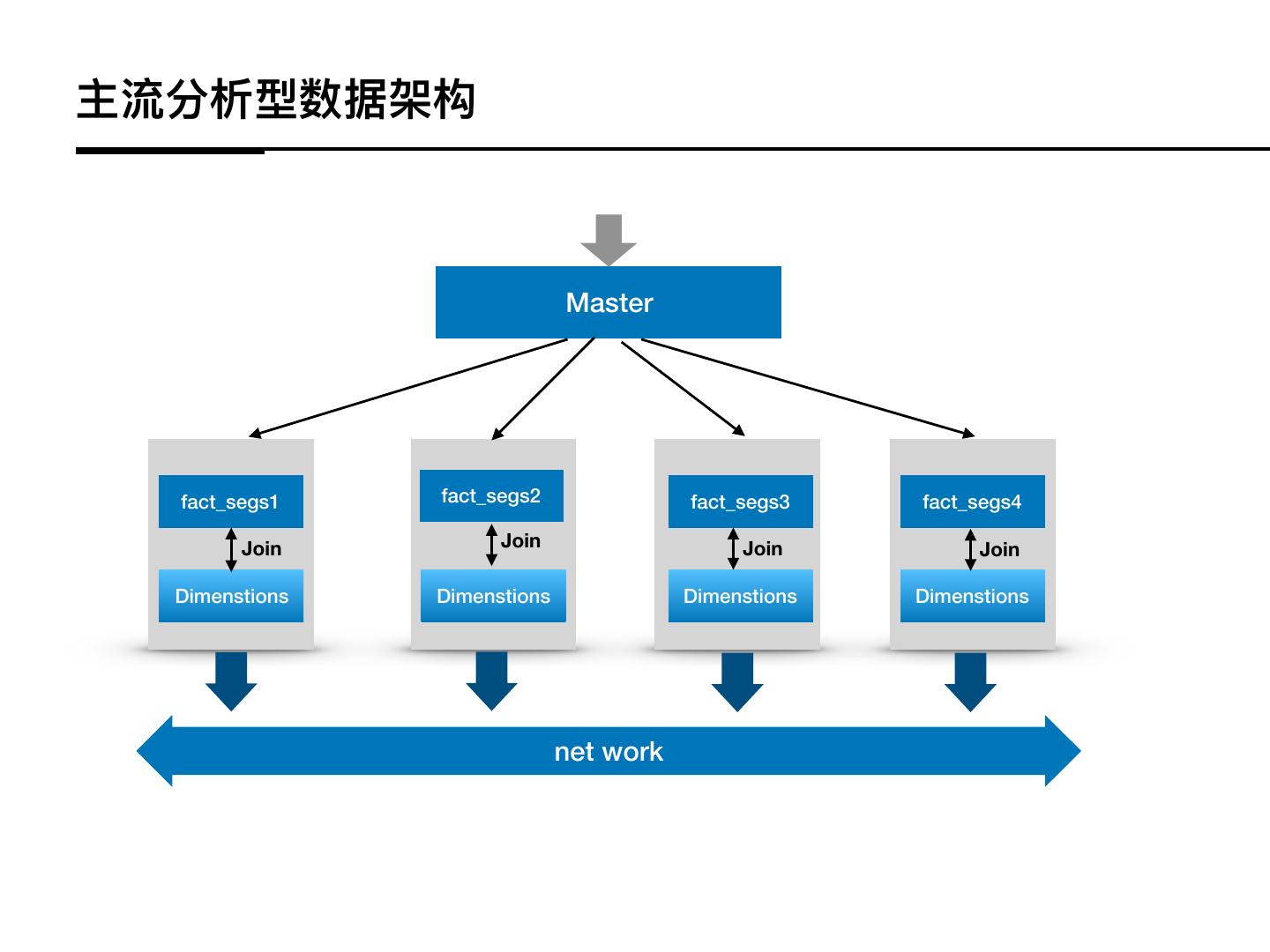
12 .主流分析型数据架构
Master
fact_segs1 fact_segs2 fact_segs3 fact_segs4
Join Join Join Join
Dimenstions Dimenstions Dimenstions Dimenstions
net work
�
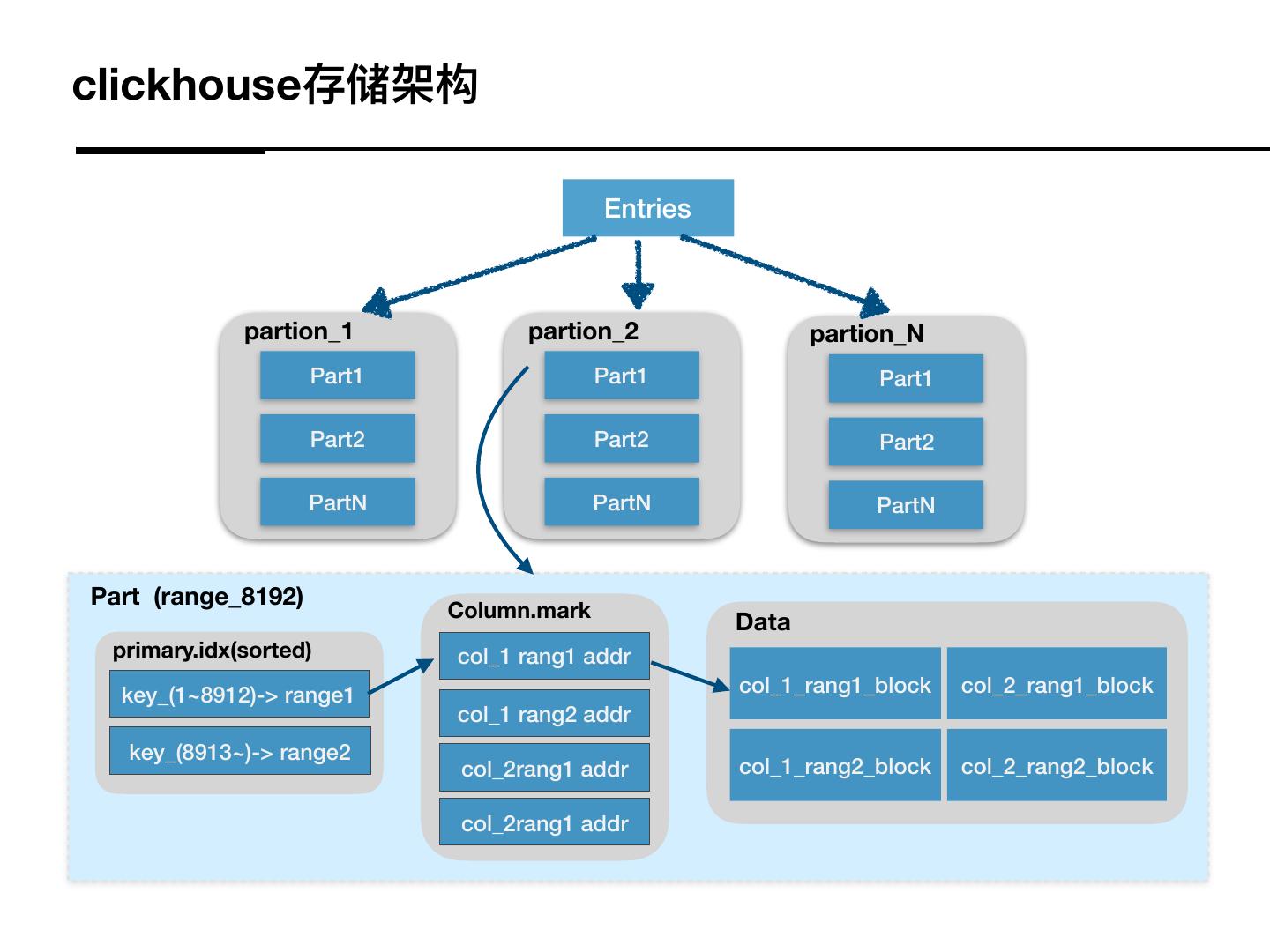
13 .clickhouse存储架构
Entries
partion_1 partion_2 partion_N
Part1 Part1 Part1
Part2 Part2 Part2
PartN PartN PartN
Part (range_8192)
Column.mark
Data
primary.idx(sorted) col_1 rang1 addr
key_(1~8912)-> range1 col_1_rang1_block col_2_rang1_block
col_1 rang2 addr
key_(8913~)-> range2
col_2rang1 addr col_1_rang2_block col_2_rang2_block
col_2rang1 addr
�
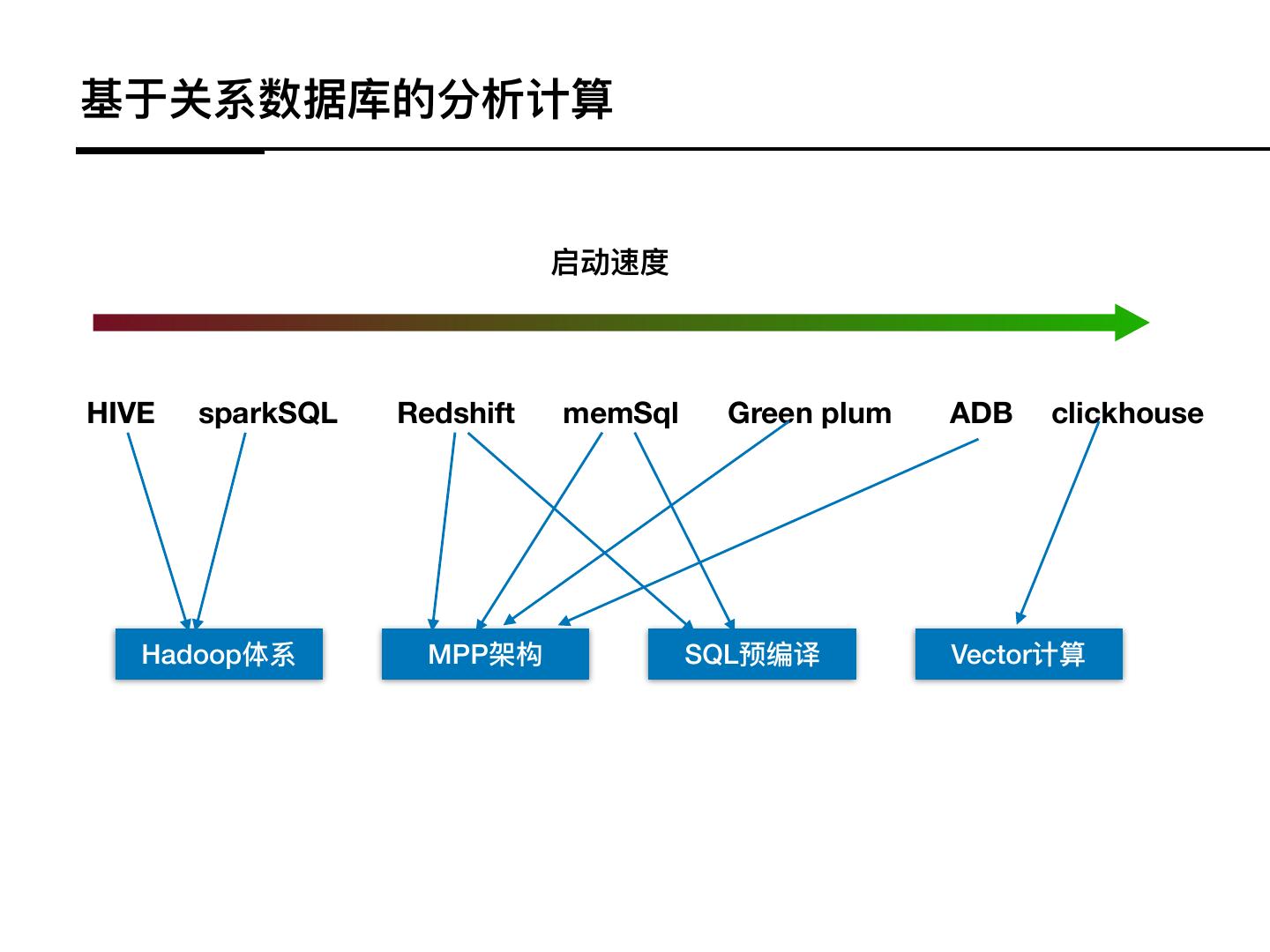
14 .基于关系数据库的分析计算
启动速度
HIVE sparkSQL Redshift memSql Green plum ADB clickhouse
Hadoop体系 MPP架构 SQL预编译 Vector计算
�
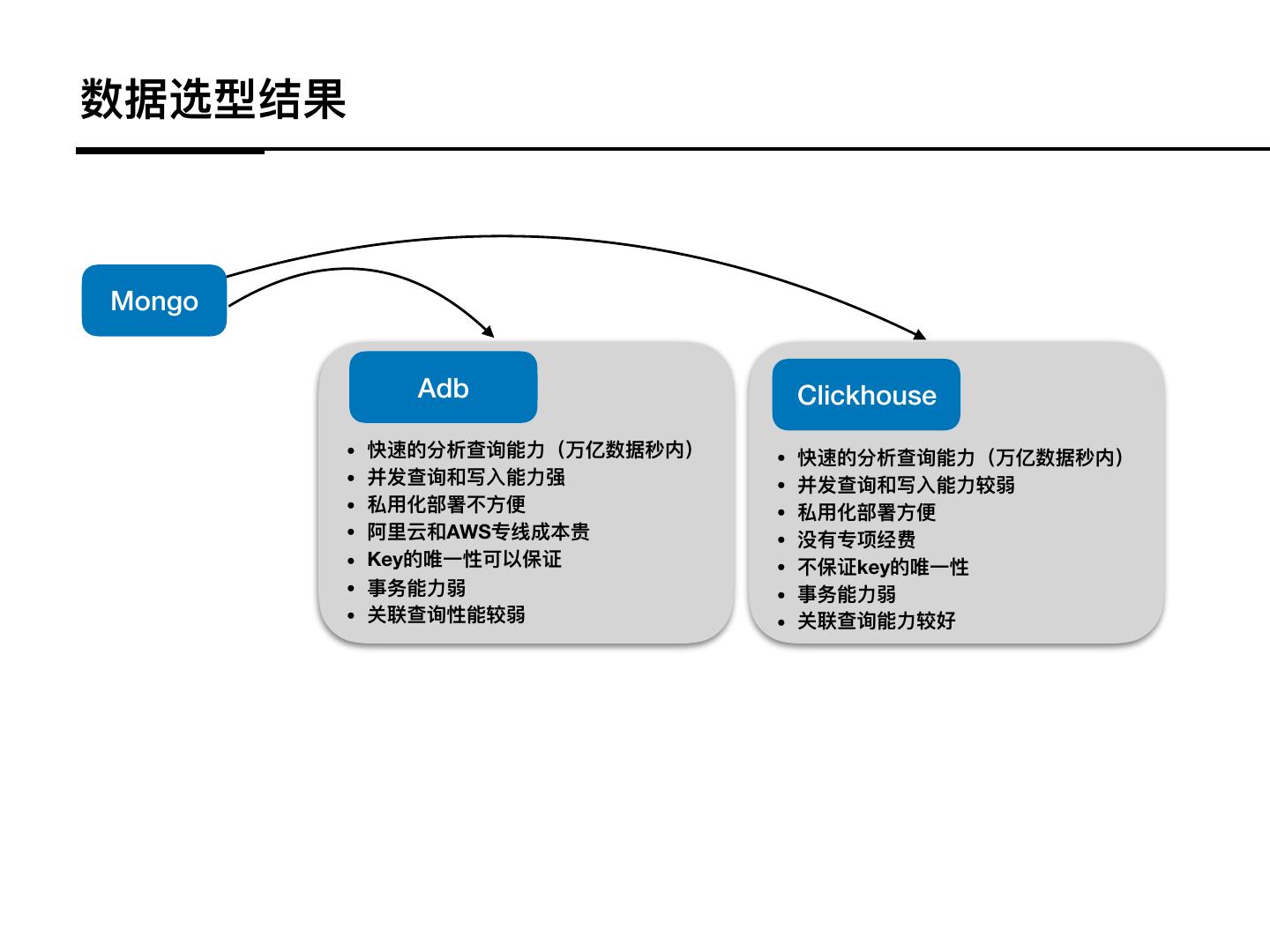
15 .数据选型结果
Mongo
Adb Clickhouse
• 快速的分析查询能⼒力力(万亿数据秒内)
• 快速的分析查询能⼒力力(万亿数据秒内)
• 并发查询和写⼊入能⼒力力强
• 并发查询和写⼊入能⼒力力较弱
• 私⽤用化部署不不⽅方便便
• 私⽤用化部署⽅方便便
• 阿⾥里里云和AWS专线成本贵
• 没有专项经费
• Key的唯⼀一性可以保证
• 不不保证key的唯⼀一性
• 事务能⼒力力弱
• 事务能⼒力力弱
• 关联查询性能较弱
• 关联查询能⼒力力较好
�
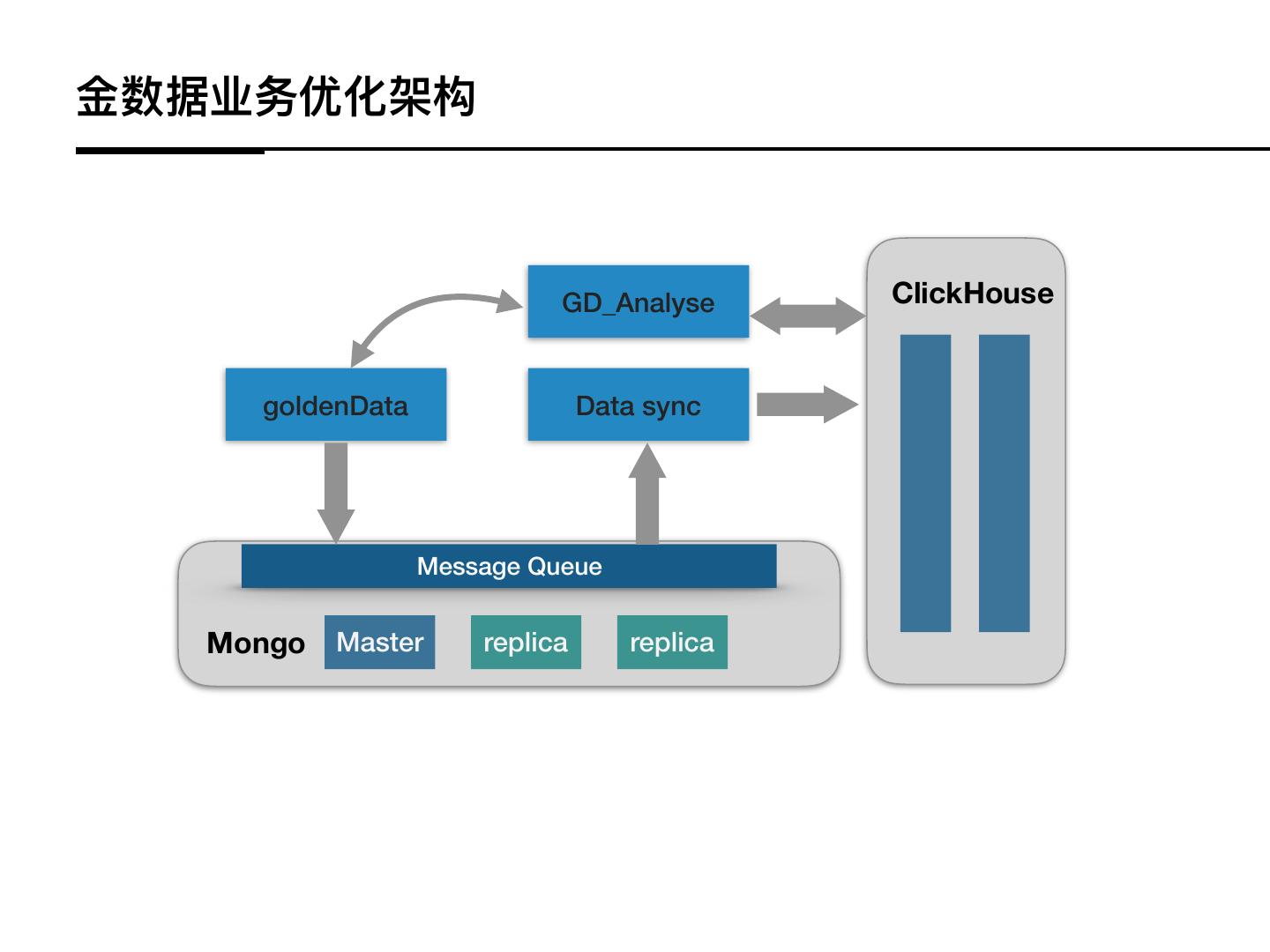
17 .⾦金金数据业务优化架构
GD_Analyse ClickHouse
goldenData Data sync
Message Queue
Mongo Master replica replica
�
18 .数据字段的映射
Document Struct
MongoDb
Clickhouse
[“SEWS”, “DSES”]
select choice, count(*) from entries_test
ARRAY JOIN splitByChar(',', field_1) as
choice group by choice
SqlDB
”SEWS,DSES” ADB
with T2 as (select split_part (a.field_1, ',', b.subindex) as
choice, 1 as count from `entry_0002` as a join incre_table
as b on b.subindex < (length(a.field_1) -
length(replace(a.field_1,','))+1)) select choice, COUNT(*)
FROM T2 GROUP BY choice
�
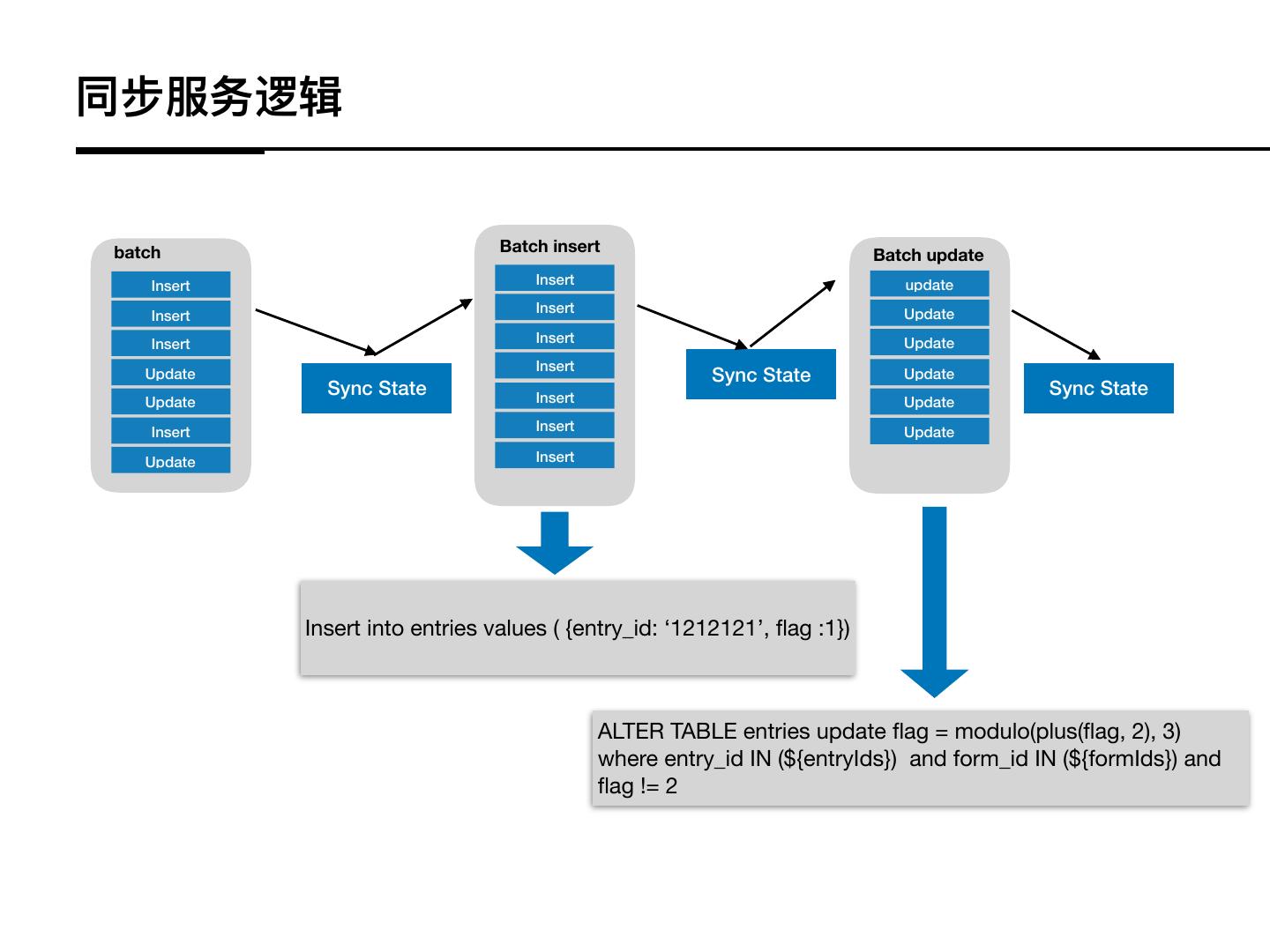
20 .同步服务逻辑
batch Batch insert Batch update
Insert Insert update
Insert Update
Insert
Insert Insert Update
Insert
Update Sync State Update
Sync State Insert Sync State
Update Update
Insert Insert Update
Update Insert
Insert into entries values ( {entry_id: ‘1212121’, flag :1})
ALTER TABLE entries update flag = modulo(plus(flag, 2), 3)
where entry_id IN (${entryIds}) and form_id IN (${formIds}) and
flag != 2
�