展开查看详情
1 .How to analyze trillions data with ClickHouse
虎牙信息 HUYA
李本旺 sundy-li
Github: http://github.com/sundy-li
Mail: libenw1992@gmail.com
�
2 . APM
覆盖全公司上报数据
3000亿 + 400+
日均增量 业务指标
o 主播端 带宽,卡顿,PCU
o 客户端 卡顿,API 请求,信令通道 实时监控
o TAF 调用 秒级响应
o 基础监控 Open-Falcon
o CDN,P2P,UDB … 500w + 3个集群,近百节点部署
每秒新增 覆盖海内外服务
�
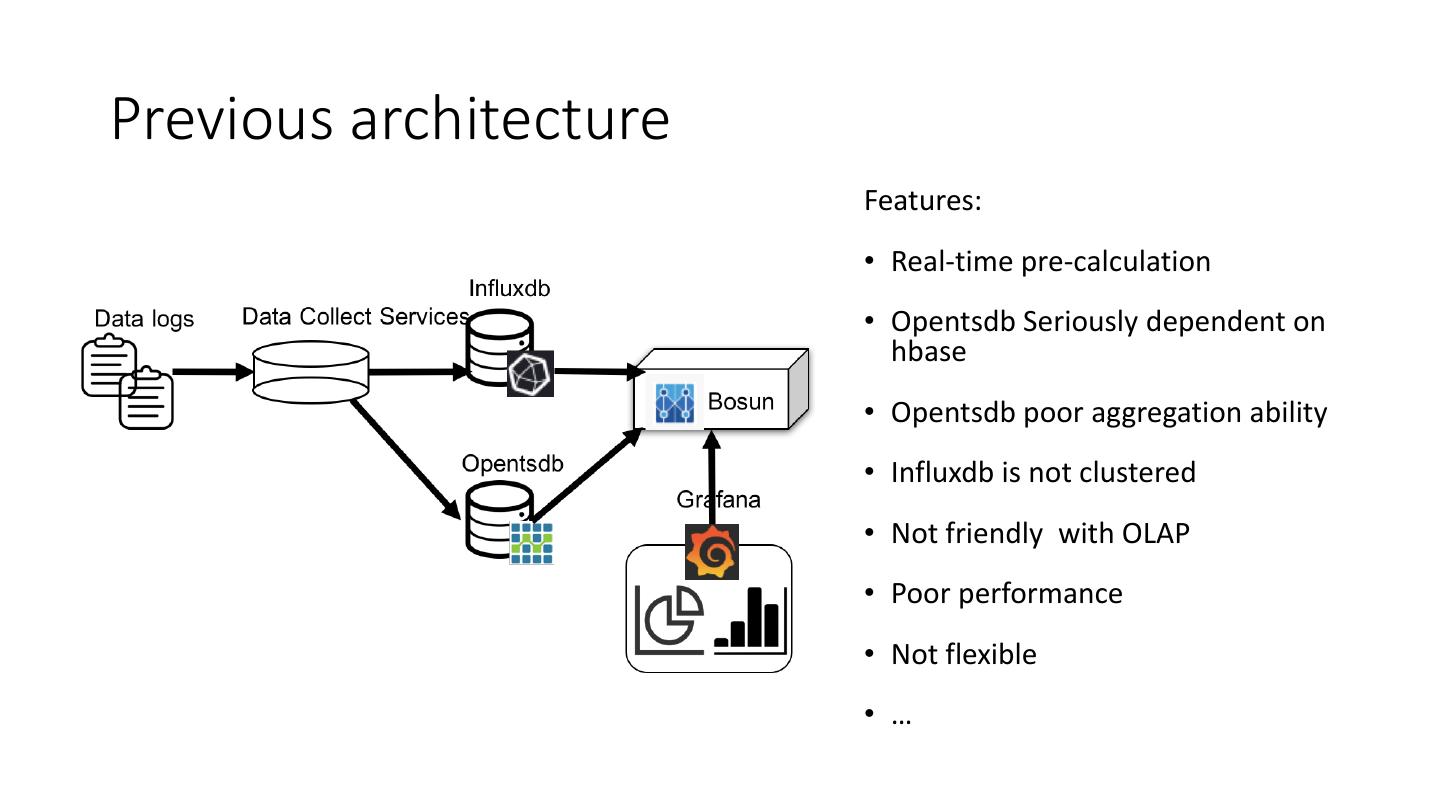
3 .Previous architecture
Features:
• Real-time pre-calculation
• Opentsdb Seriously dependent on
hbase
• Opentsdb poor aggregation ability
• Influxdb is not clustered
• Not friendly with OLAP
• Poor performance
• Not flexible
• …
�
4 .Why ClickHouse
Column Oriented
Super Fast
OLAP
SQL supported
Linearly Scalable
Simple
�
5 .ClickHouse as time-series database
Get the average value group by line, interval 20s
�
8 .Realtime ingestion
• Kafka Engine(×)
Not Recommended
Because
o Error handling
o Kafka partition && consumer auto-rebalance
o ClickHouse is shared-nothing architecture
o Bad control of data sharding
�
9 .Realtime ingestion
• How ?
huya_sinker
o Golang implemented
o Message JSON format
o Auto rebalance, easy to deploy as a
o Use Go tcp client, use gjson parser
container
o Random write Strategy
o Dynamic awareness tables and columns
o On parallel
configuration (etcd)
o High rate 10 Million rows/s
o Batch insert (interval, batch_size)
o Custom parser support
�
10 .Realtime ingestion
• How to avoid data loss
o Back pressure
o Connection auto rebuild
o Write backup data to backup kafka
o Alarm monitor
o …
�
11 .Realtime ingestion
Write to single shard table or distributed table ?
Single Shard
Consider about
I. Number of Sinker processors
I. Good control of read or write
II. Number of Connections
split
III. Number of Tables
II. Good control data transfer
IV. Number of shards
�
12 .Query
TSDB styles Grafana plugin
�
13 .Query
• Rewrite Query
o SQL Parser
o Custom function support
o Custom query statement
�
14 .Query
• Rewrite Query
�
15 .Query
• Custom query statement
�
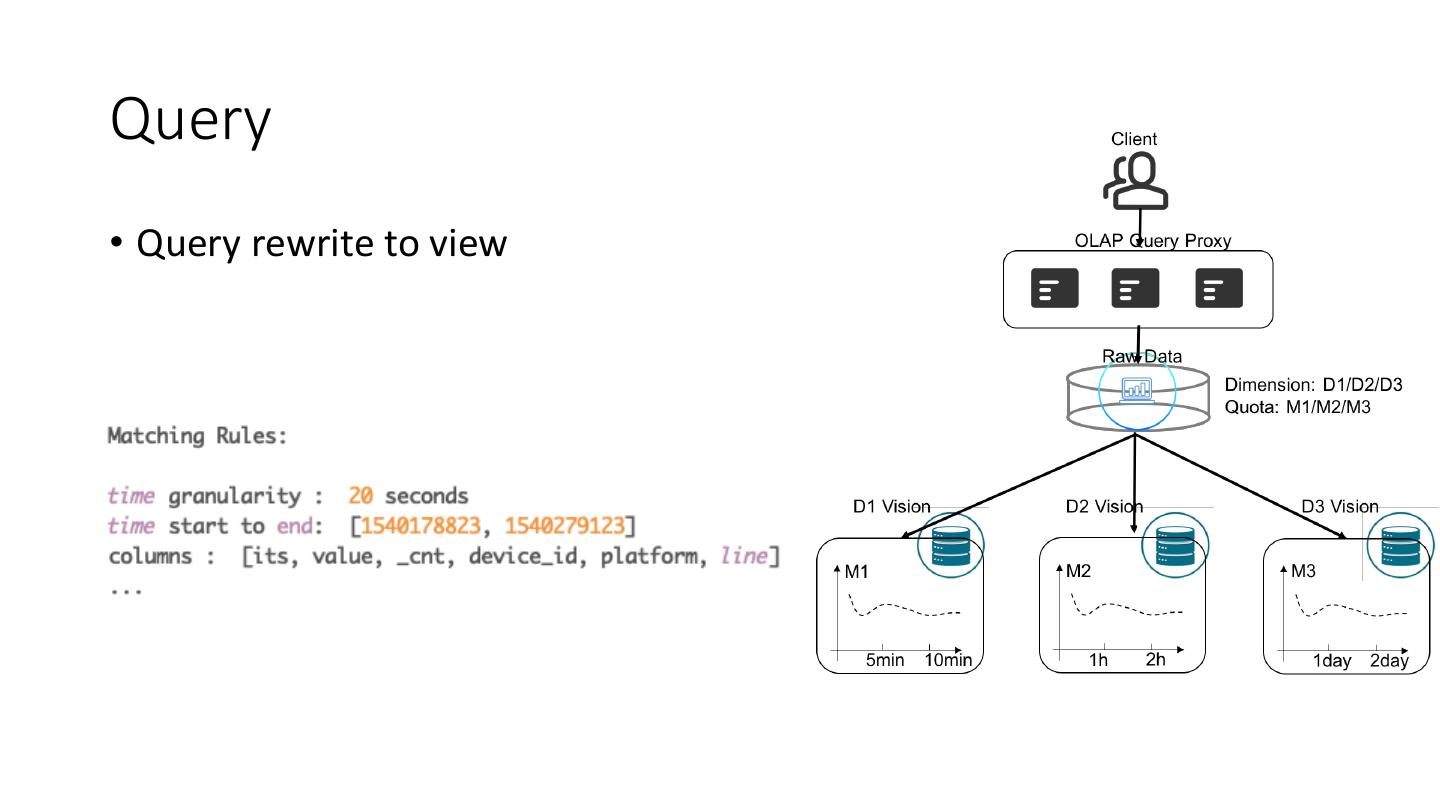
16 .Query
• Query rewrite to view
�
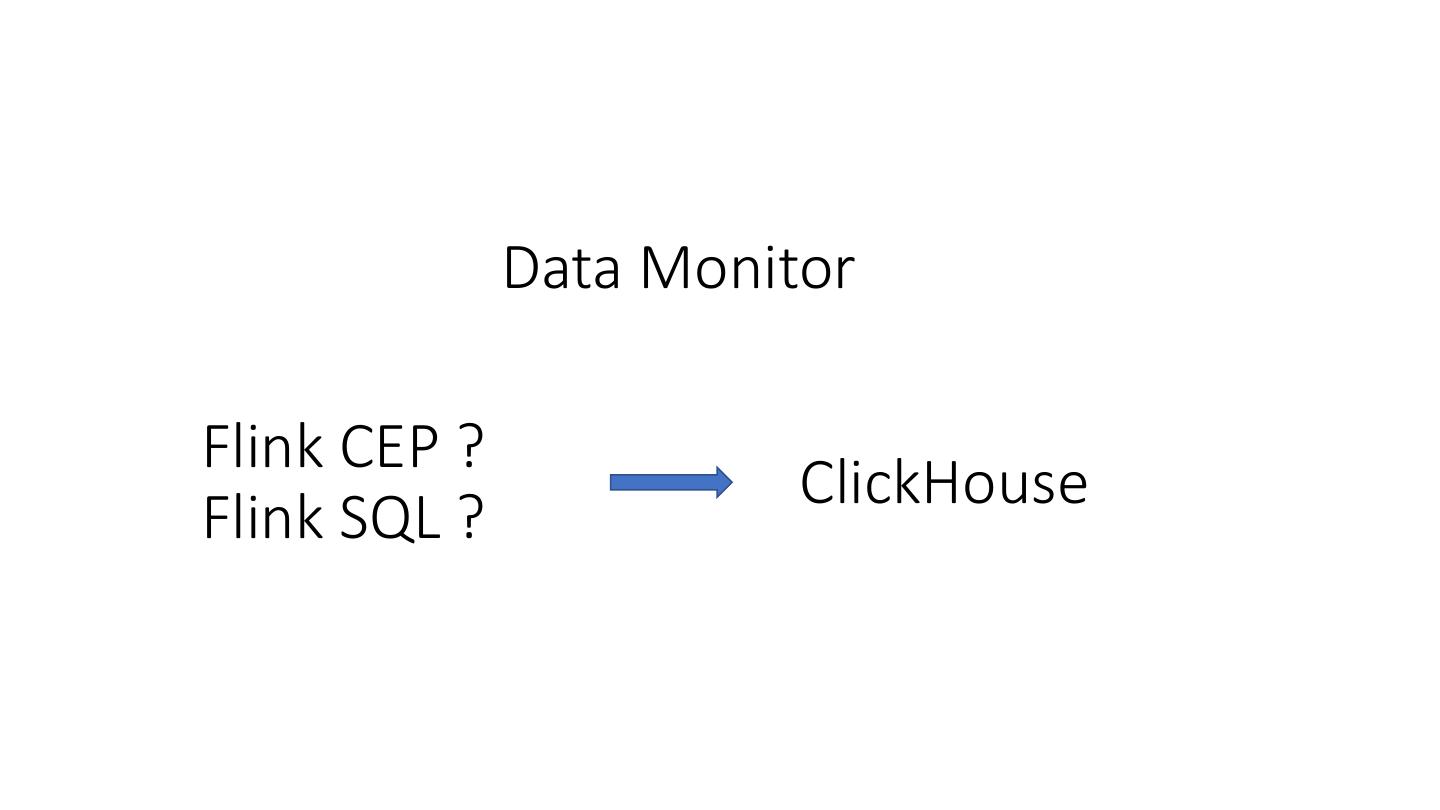
17 . Data Monitor
Flink CEP ?
ClickHouse
Flink SQL ?
�
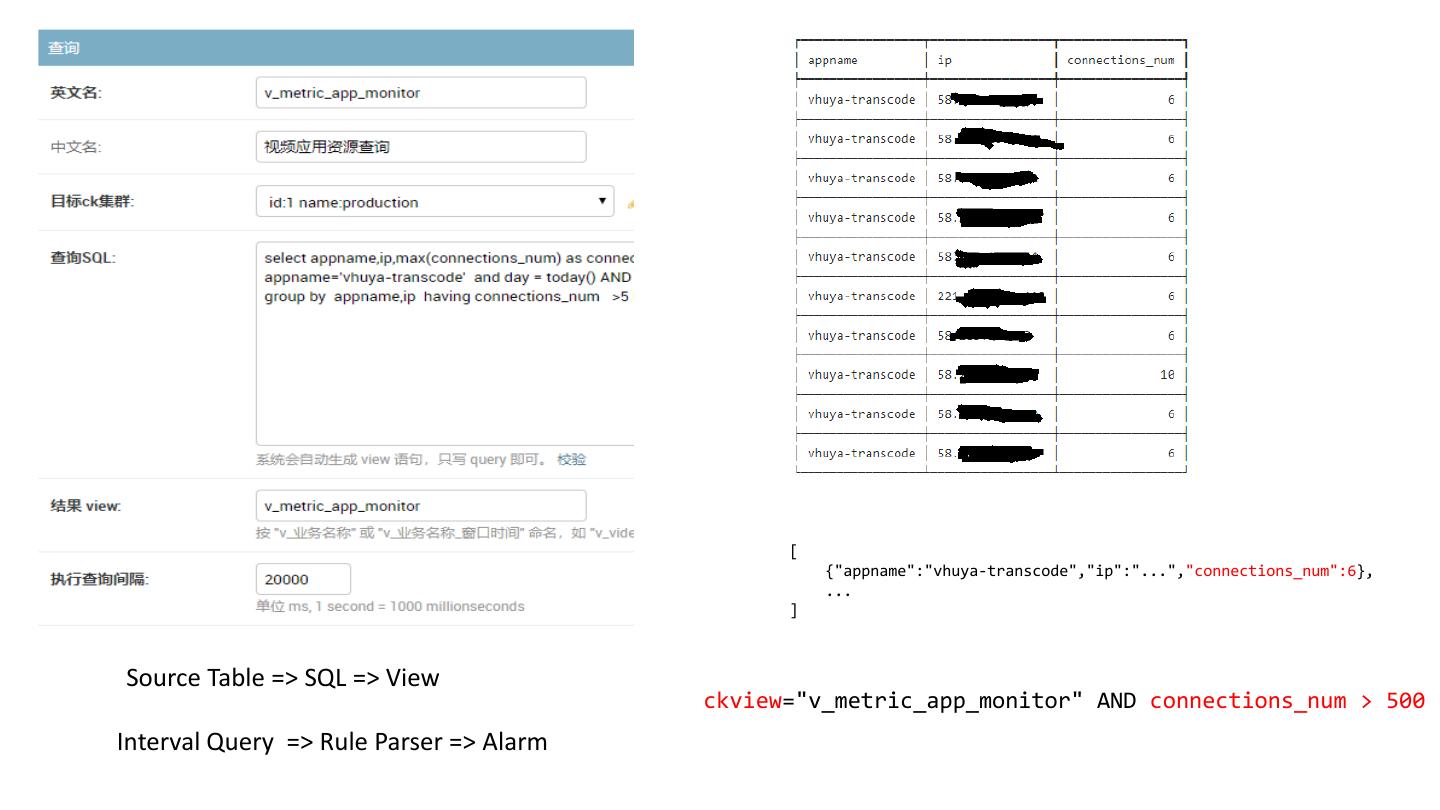
18 . [
{"appname":"vhuya-transcode","ip":"...","connections_num":6},
...
]
Source Table => SQL => View
ckview="v_metric_app_monitor" AND connections_num > 500
Interval Query => Rule Parser => Alarm
�
19 .Cloud
• IO
• Sequence Read
Sequence Write
IOPS Cloud >> local
�
20 .More about cloud
• Distributed file systems (Considering)
• Moosefs
• Aws efs(Pinterest Goku)
• Aliyun nas
• Data store separation (Working on it)
• 90% query data is about last month
• SSD for hot data, SATA for history data.
�
21 .Operations
• Deploy platform
• Ansible
• Golang Template
�
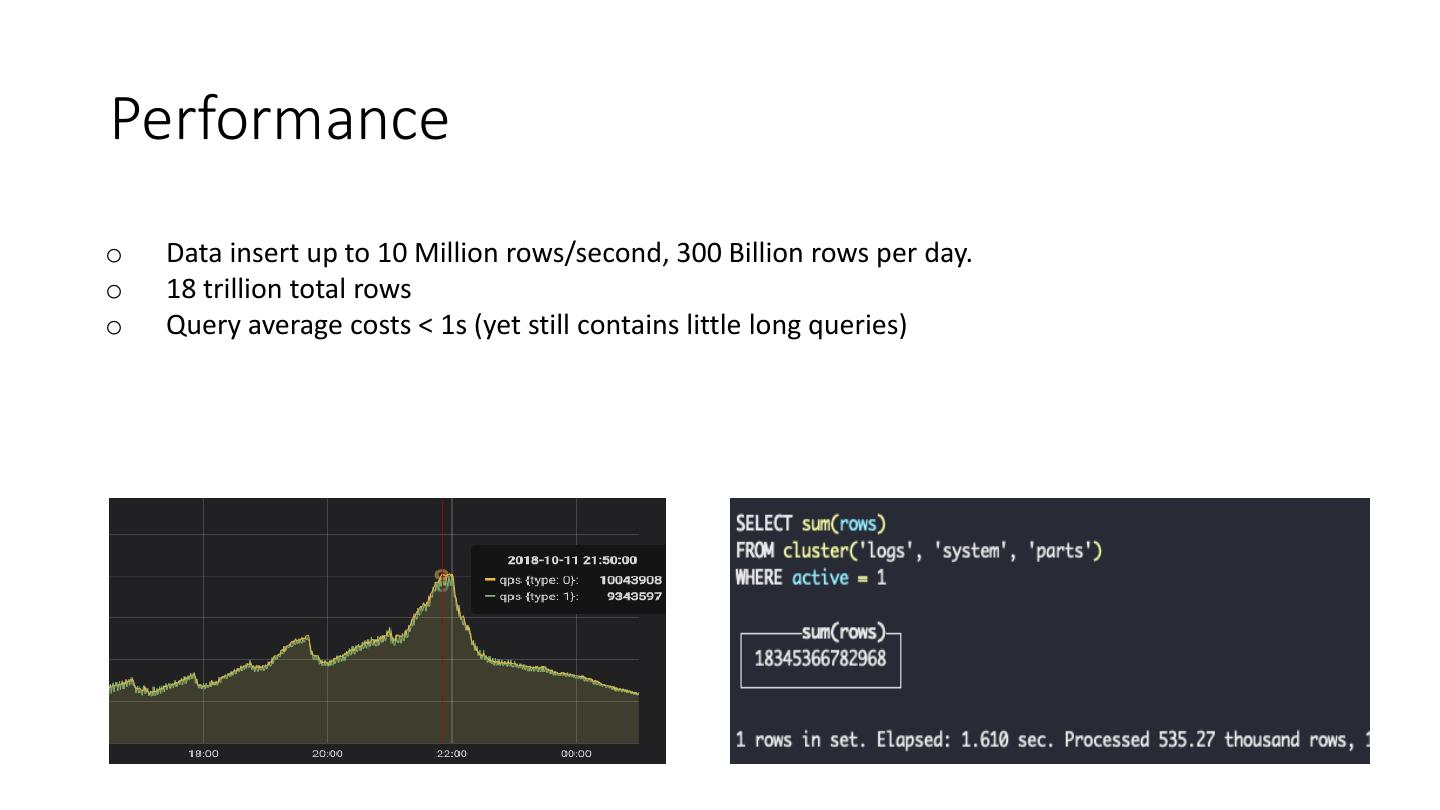
22 .Performance
o Data insert up to 10 Million rows/second, 300 Billion rows per day.
o 18 trillion total rows
o Query average costs < 1s (yet still contains little long queries)
�
23 .To community
o Tools
o JDBC https://github.com/housepower/ClickHouse-Native-JDBC
o Clickhouse_sinker https://github.com/housepower/clickhouse_sinker
o Features
o windowFunnel
o retention
�
24 . Hiring,we want you!
Thank You 大数据,算法
监控 质量分析平台开发工程师
欢迎各路人才加入
�