






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ClickHouse Deep Dive
ClickHouse Deep Dive
展开查看详情
1 .ClickHouse Deep Dive Alexey Zatelepin
2 .ClickHouse use cases A stream of events › Actions of website visitors › Ad impressions › DNS queries › E-commerce transactions › … We want to save info about these events and then glean some insights from it 2
3 .ClickHouse philosophy › Interactive queries on data updated in real time › Cleaned structured data is needed › Try hard not to pre-aggregate anything › Query language: a dialect of SQL + extensions 3
4 .Sample query in a web analytics system Top-10 referers for a website for the last week. SELECT Referer, count(*) AS count FROM hits WHERE CounterID = 111 AND Date BETWEEN ‘2018-04-18’ AND ‘2018-04-24’ GROUP BY Referer ORDER BY count DESC LIMIT 10 4
5 .How to execute a query fast? Read data fast › Only needed columns: CounterID, Date, Referer › Locality of reads (an index is needed!) › Data compression 5
6 .How to execute a query fast? Read data fast › Only needed columns: CounterID, Date, Referer › Locality of reads (an index is needed!) › Data compression Process data fast › Vectorized execution (block-based processing) › Parallelize to all available cores and machines › Specialization and low-level optimizations 6
7 .Index needed! The principle is the same as with classic DBMSes A majority of queries will contain conditions on CounterID and (possibly) Date (CounterID, Date) fits the bill Check this by mentally sorting the table by primary key Differences › The table will be physically sorted on disk › Is not a unique constraint 7
8 .Index internals (CounterID, Date) CounterID Date Referer primary.idx .mrk .bin .mrk .bin .mrk .bin … … 111 2017-07-22 N 111 2017-10-04 N+8192 111 2018-04-20 N+16384 222 2013-02-16 222 2013-03-12 … … (One entry each 8192 rows) 8
9 .Things to remember about indexes Index is sparse › Must fit into memory › Default value of granularity (8192) is good enough › Does not create a unique constraint › Performance of point queries is not stellar Table is sorted according to the index › There can be only one › Using the index is always beneficial 9
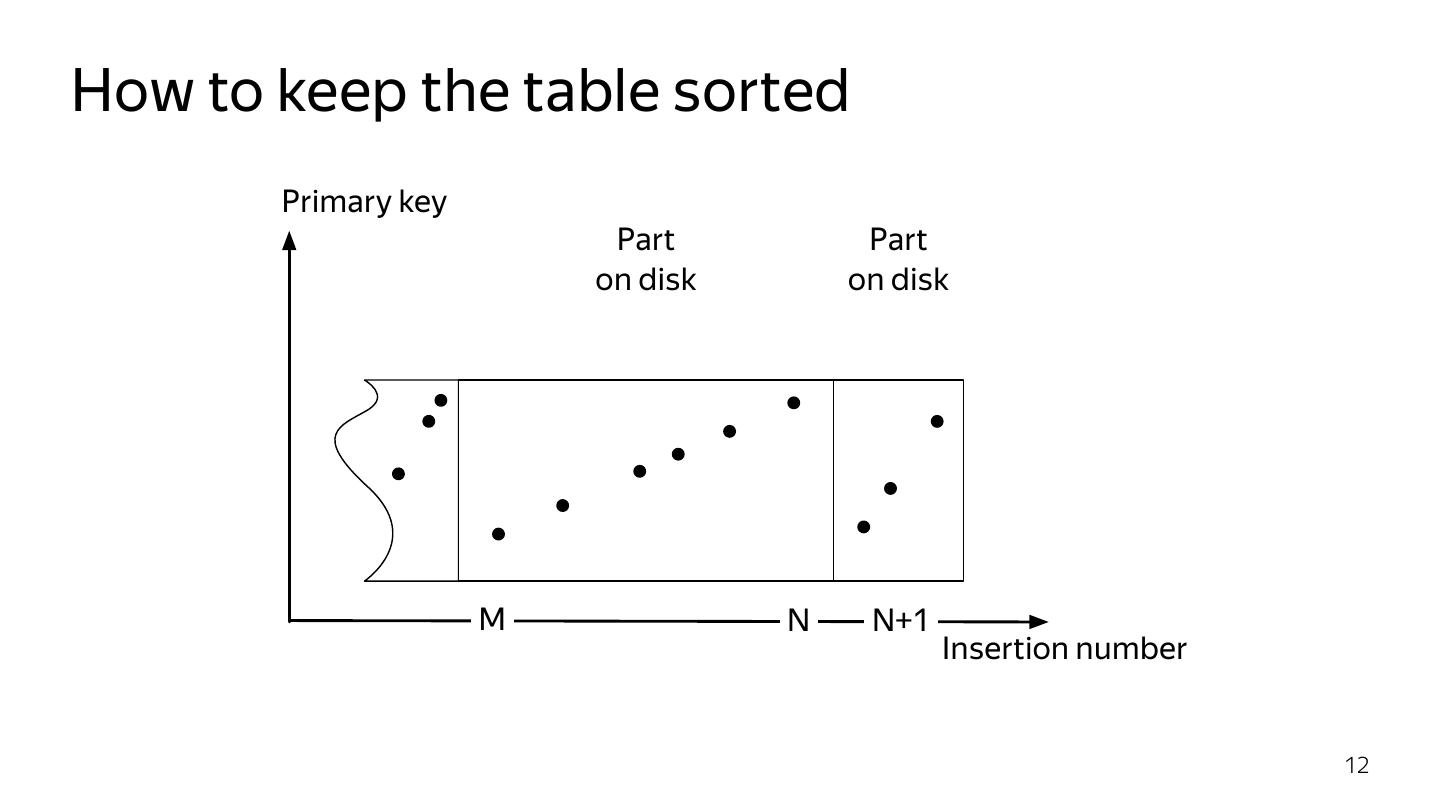
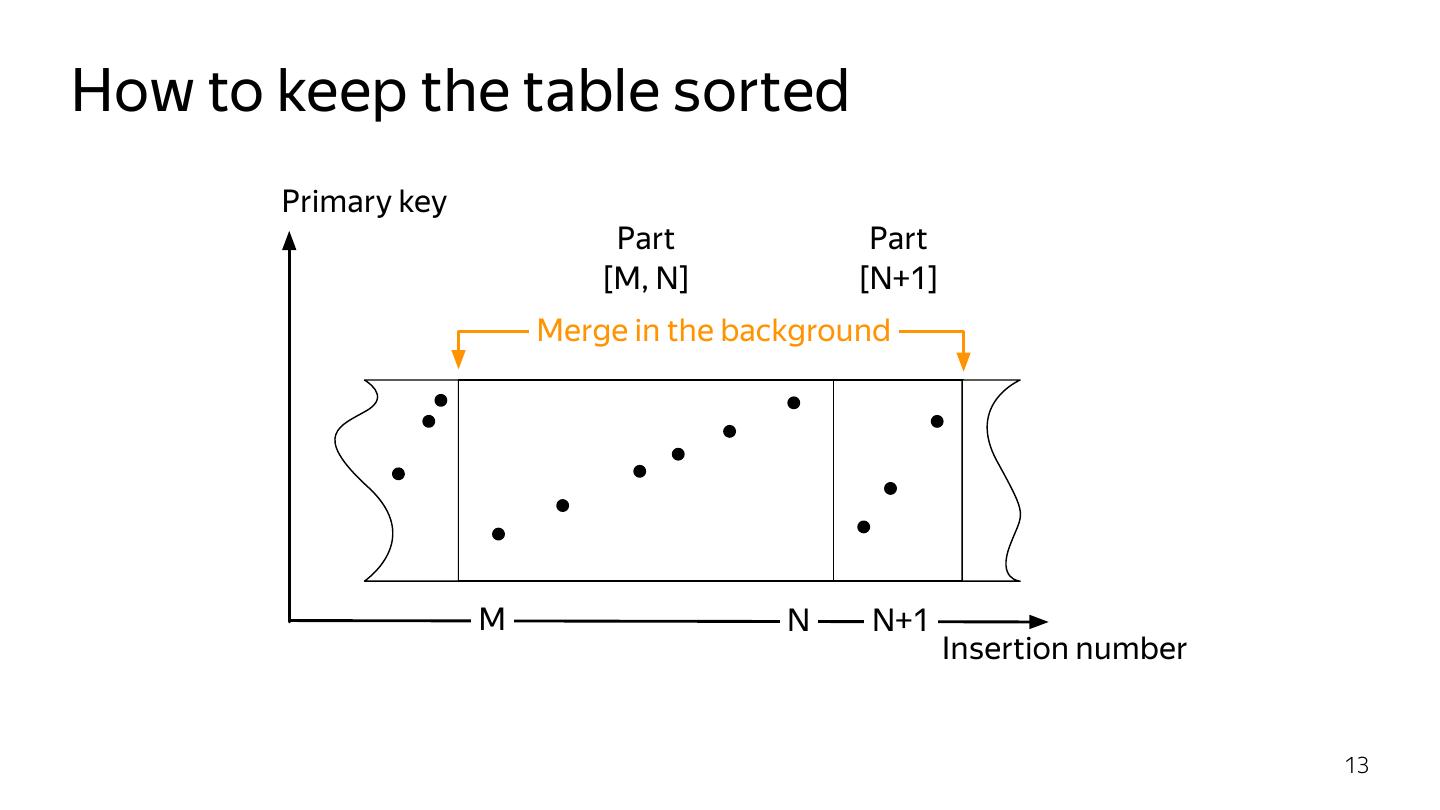
10 .How to keep the table sorted Inserted events are (almost) sorted by time But we need to sort by primary key! MergeTree: maintain a small set of sorted parts Similar idea to an LSM tree 10
11 .How to keep the table sorted Primary key Part To on disk insert M N N+1 Insertion number 11
12 .How to keep the table sorted Primary key Part Part on disk on disk M N N+1 Insertion number 12
13 .How to keep the table sorted Primary key Part Part [M, N] [N+1] Merge in the background M N N+1 Insertion number 13
14 .How to keep the table sorted Primary key Part [M, N+1] M N+1 Insertion number 14
15 .Things to do while merging Replace/update records › ReplacingMergeTree › CollapsingMergeTree Pre-aggregate data › AggregatingMergeTree Metrics rollup › GraphiteMergeTree 15
16 .MergeTree partitioning ENGINE = MergeTree … PARTITION BY toYYYYMM(Date) › Table can be partitioned by any expression (default: by month) › Parts from different partitions are not merged › Easy manipulation of partitions ALTER TABLE DROP PARTITION ALTER TABLE DETACH/ATTACH PARTITION › MinMax index by partition columns 16
17 .Things to remember about MergeTree Merging runs in the background › Even when there are no queries! Control total number of parts › Rate of INSERTs › MaxPartsCountForPartition and DelayedInserts metrics are your friends 17
18 .When one server is not enough › The data won’t fit on a single server… › You want to increase performance by adding more servers… › Multiple simultaneous queries are competing for resources… 18
19 .When one server is not enough › The data won’t fit on a single server… › You want to increase performance by adding more servers… › Multiple simultaneous queries are competing for resources… ClickHouse: Sharding + Distributed tables! 19
20 .Reading from a Distributed table SELECT FROM distributed_table GROUP BY column SELECT FROM local_table GROUP BY column Shard 1 Shard 2 Shard 3 20
21 .Reading from a Distributed table Full result Partially aggregated result Shard 1 Shard 2 Shard 3 21
22 .NYC taxi benchmark CSV 227 Gb, ~1.3 bln rows SELECT passenger_count, avg(total_amount) FROM trips GROUP BY passenger_count Shards 1 3 140 Time, s. 1,224 0,438 0,043 Speedup x2.8 x28.5 22
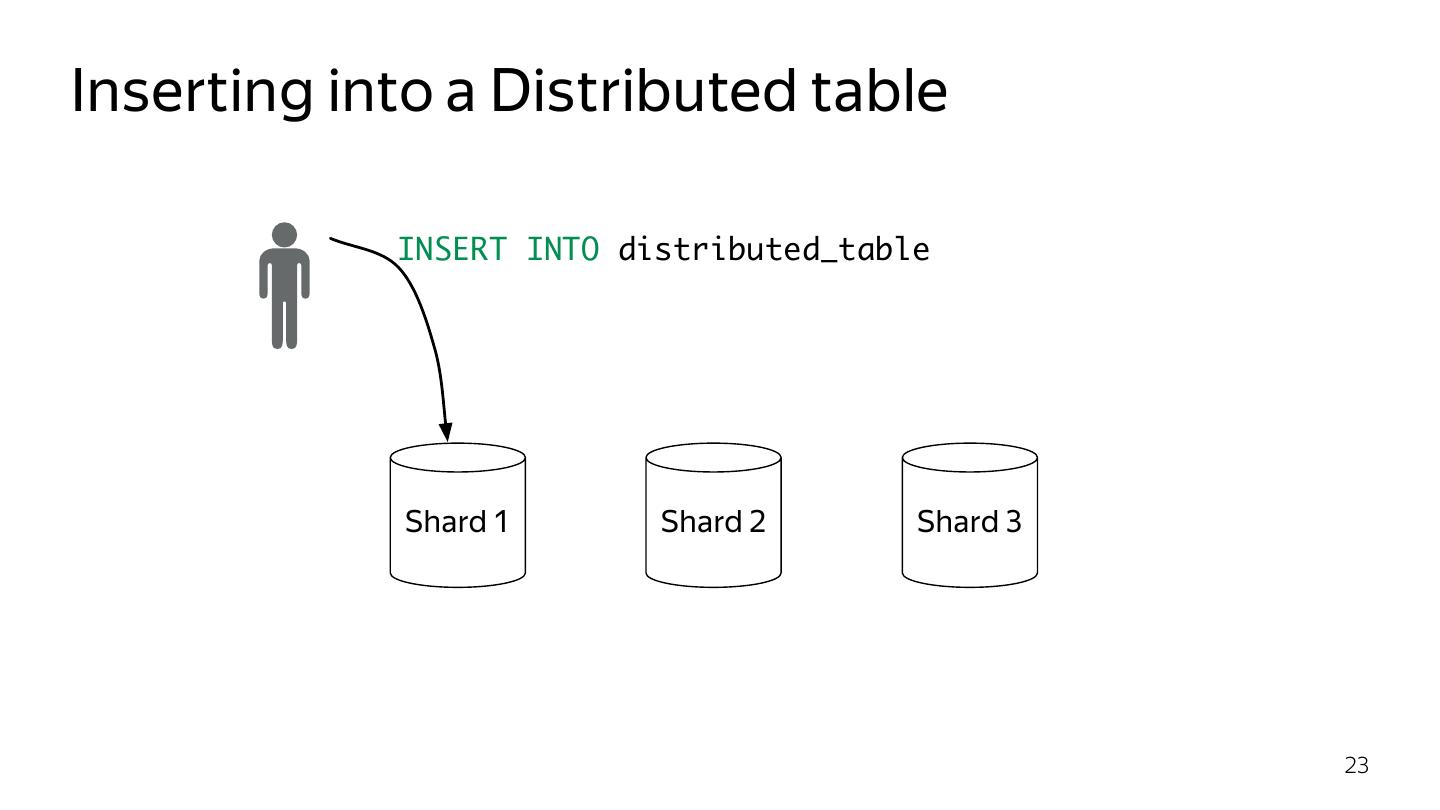
23 .Inserting into a Distributed table INSERT INTO distributed_table Shard 1 Shard 2 Shard 3 23
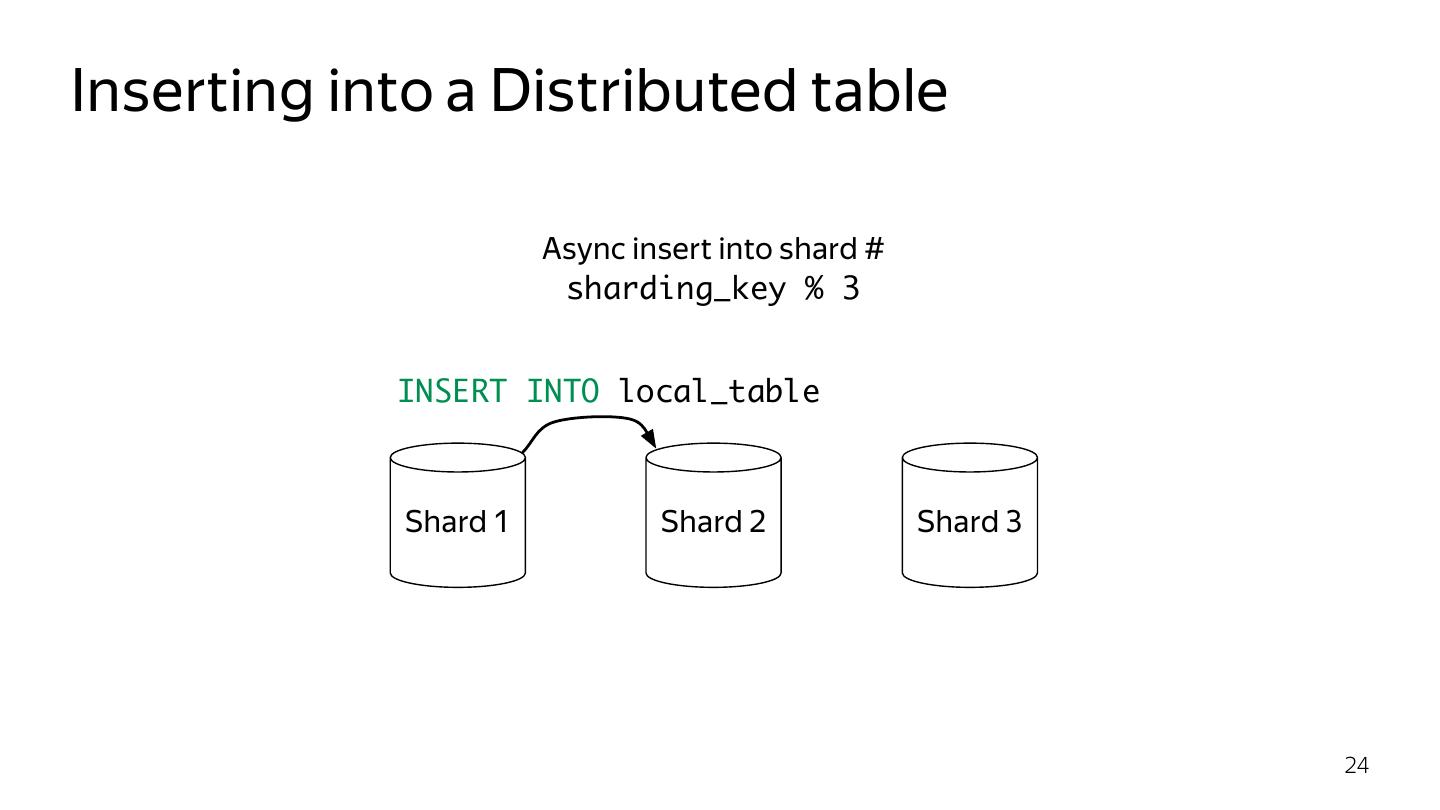
24 .Inserting into a Distributed table Async insert into shard # sharding_key % 3 INSERT INTO local_table Shard 1 Shard 2 Shard 3 24
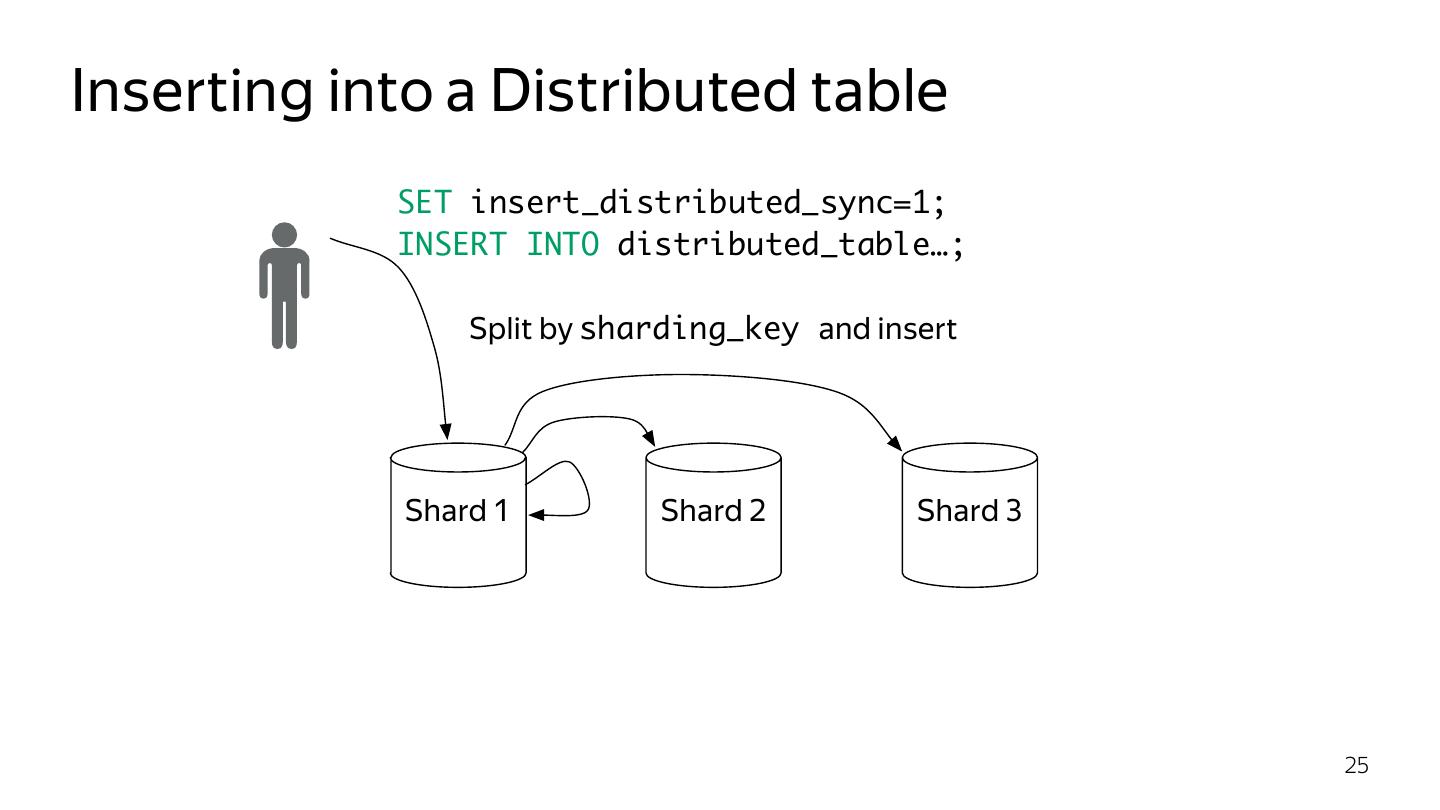
25 .Inserting into a Distributed table SET insert_distributed_sync=1; INSERT INTO distributed_table…; Split by sharding_key and insert Shard 1 Shard 2 Shard 3 25
26 .Things to remember about Distributed tables It is just a view › Doesn’t store any data by itself Will always query all shards Ensure that the data is divided into shards uniformly › either by inserting directly into local tables › or let the Distributed table do it (but beware of async inserts by default) 26
27 .When failure is not an option › Protection against hardware failure › Data must be always available for reading and writing 27
28 .When failure is not an option › Protection against hardware failure › Data must be always available for reading and writing ClickHouse: ReplicatedMergeTree engine! › Async master-master replication › Works on per-table basis 28
29 .Replication internals Inserted block number INSERT Replica 1 fetch fetch Replication Replica 2 queue merge (ZooKeeper) Replica 3 merge 29
3秒后跳转登录页面
去登陆

