












































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ClickHouse最佳实践
- 为什么ClickHouse?
- 如何工作运行
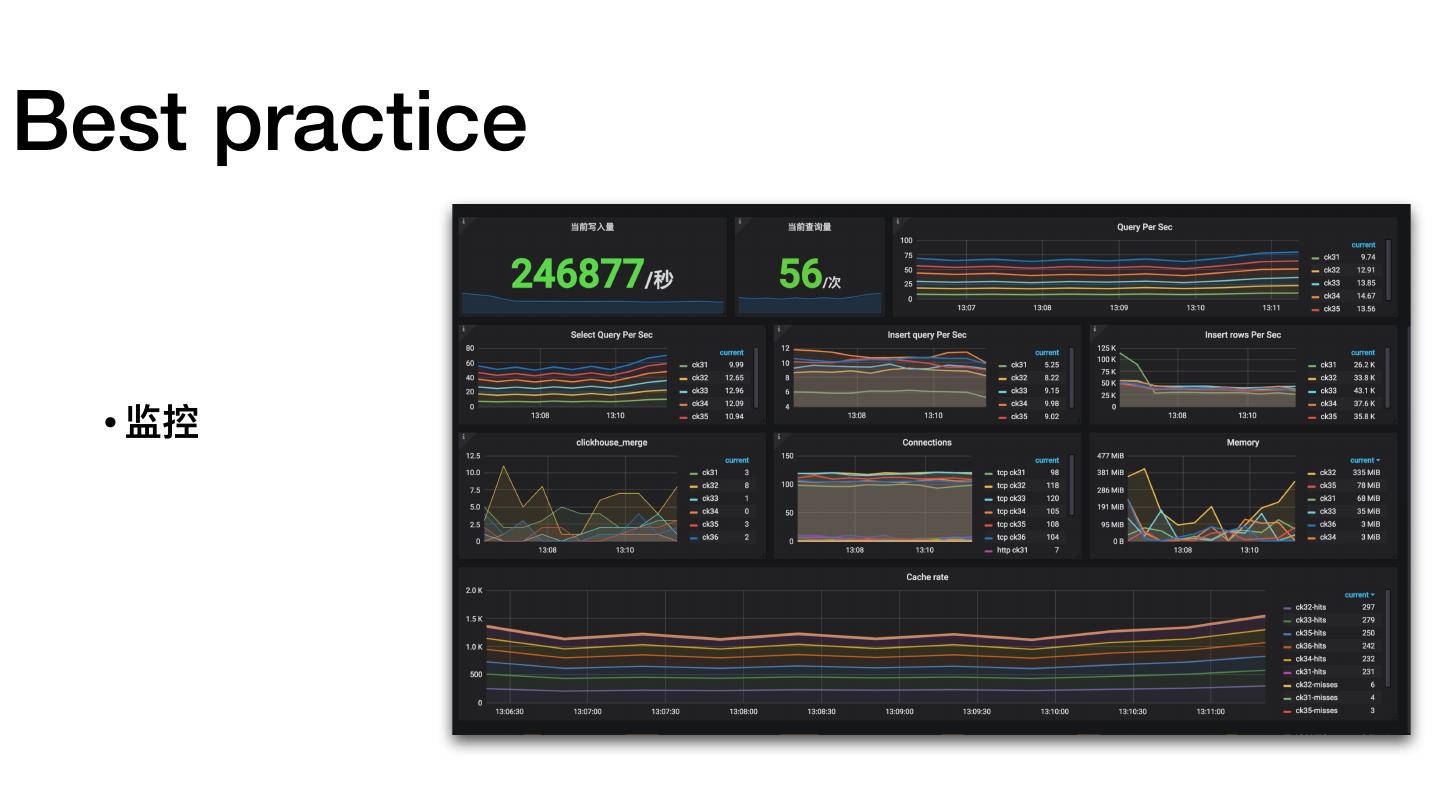
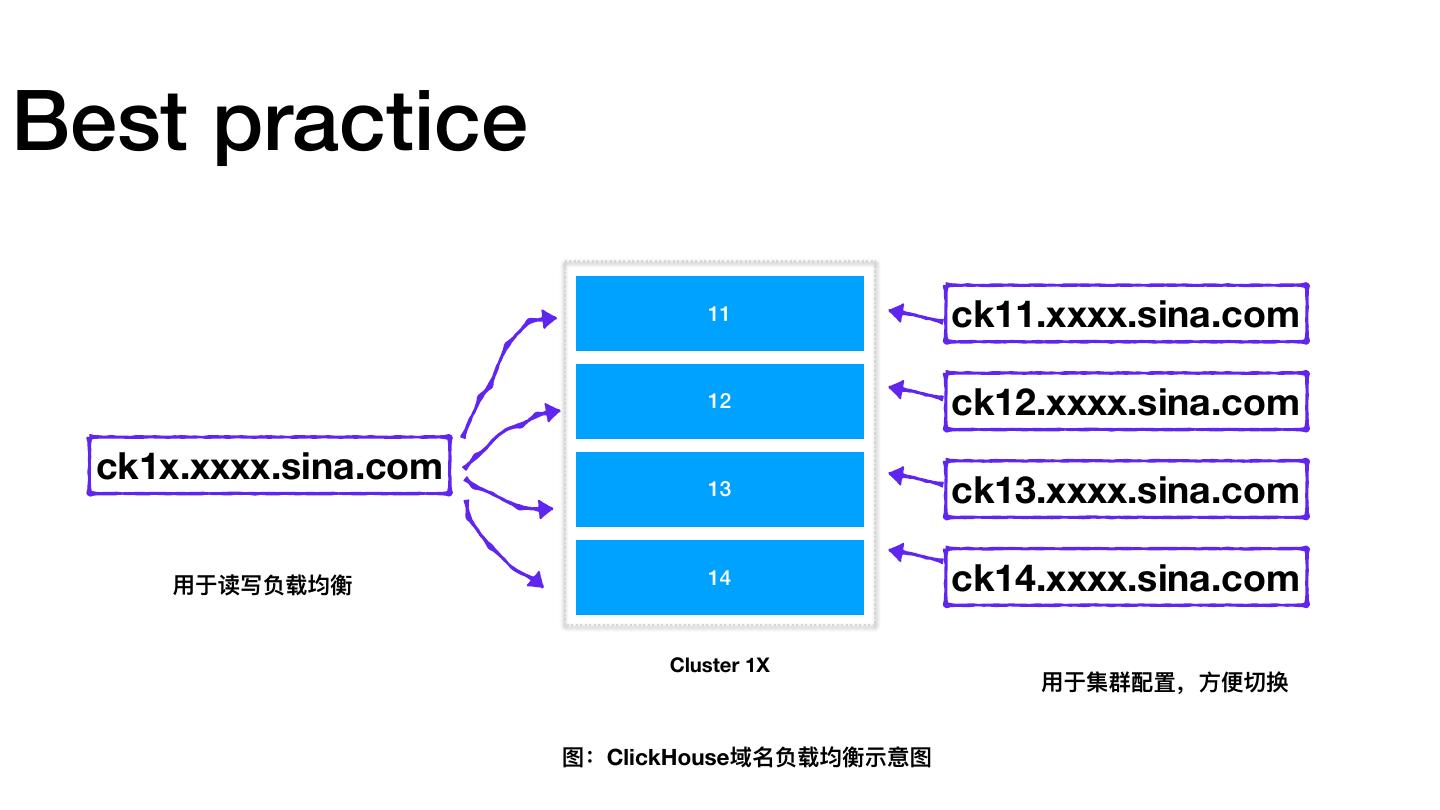
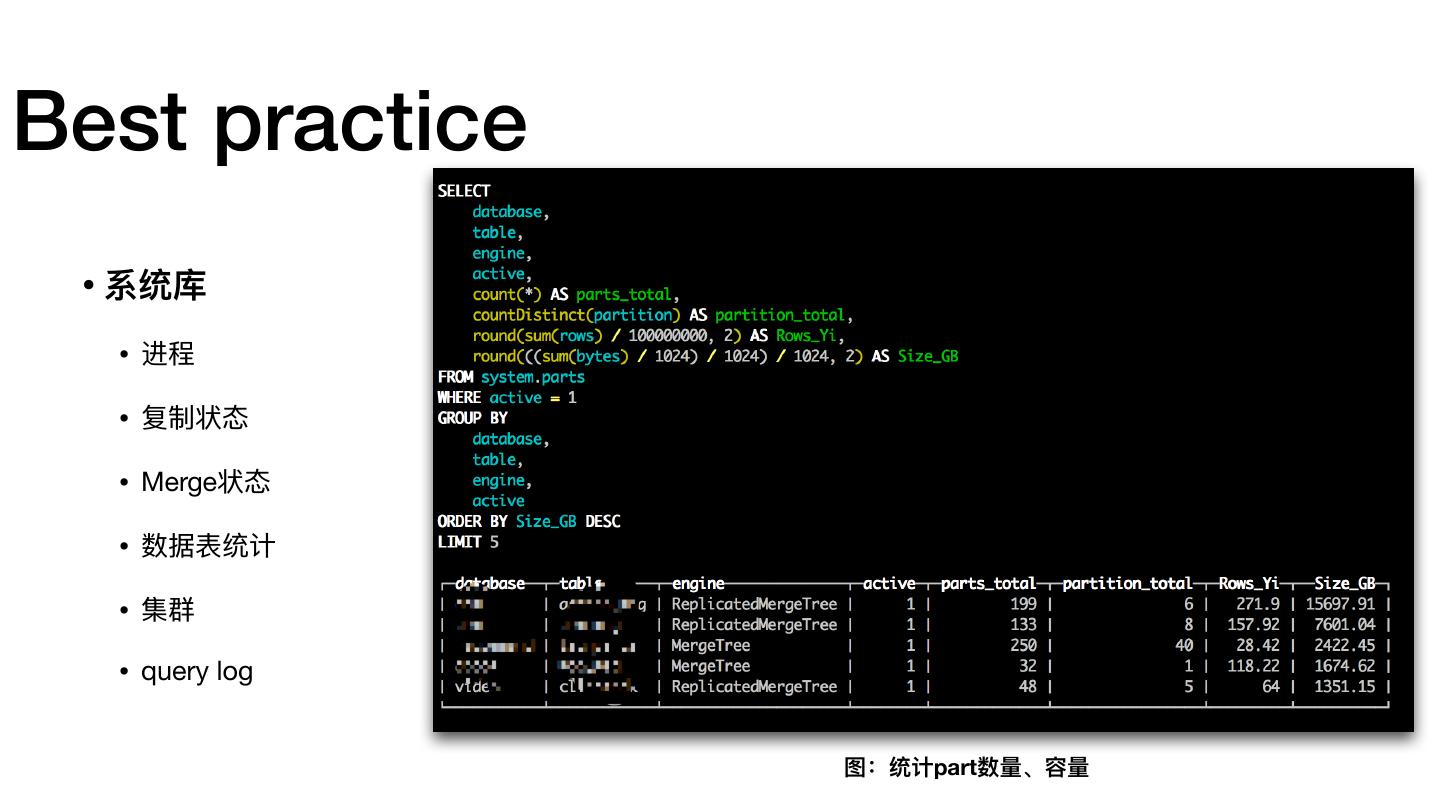
- 最佳实践
展开查看详情
1 .ClickHouse最佳实践 Power Your Data 新浪-⾼高鹏-2018年年10⽉月
2 . 19 台服务器器 300亿 /天 数据量量 存量量数据1.5万亿 800w /天 有效查询 平均查询时间 200ms 核⼼心监控查询平均 40ms 截⽌止2018年年09⽉月03⽇日
3 .Content • Why ClickHouse • How it works • Best practice
4 .About me MySQL DBA 数据分析
5 .About Me AIOps Visualization Monitoring MySQL DBA Analytics Data Science 数据分析 Big Data AIOps Back APP Net DB LB End
6 .About Data • 我们做什什么数据? Web APP • 量量级 数据库 CDN 云存储 • 实时性 • 查询需求 主机 负载均衡 DNS • 接⼊入 ⽹网络
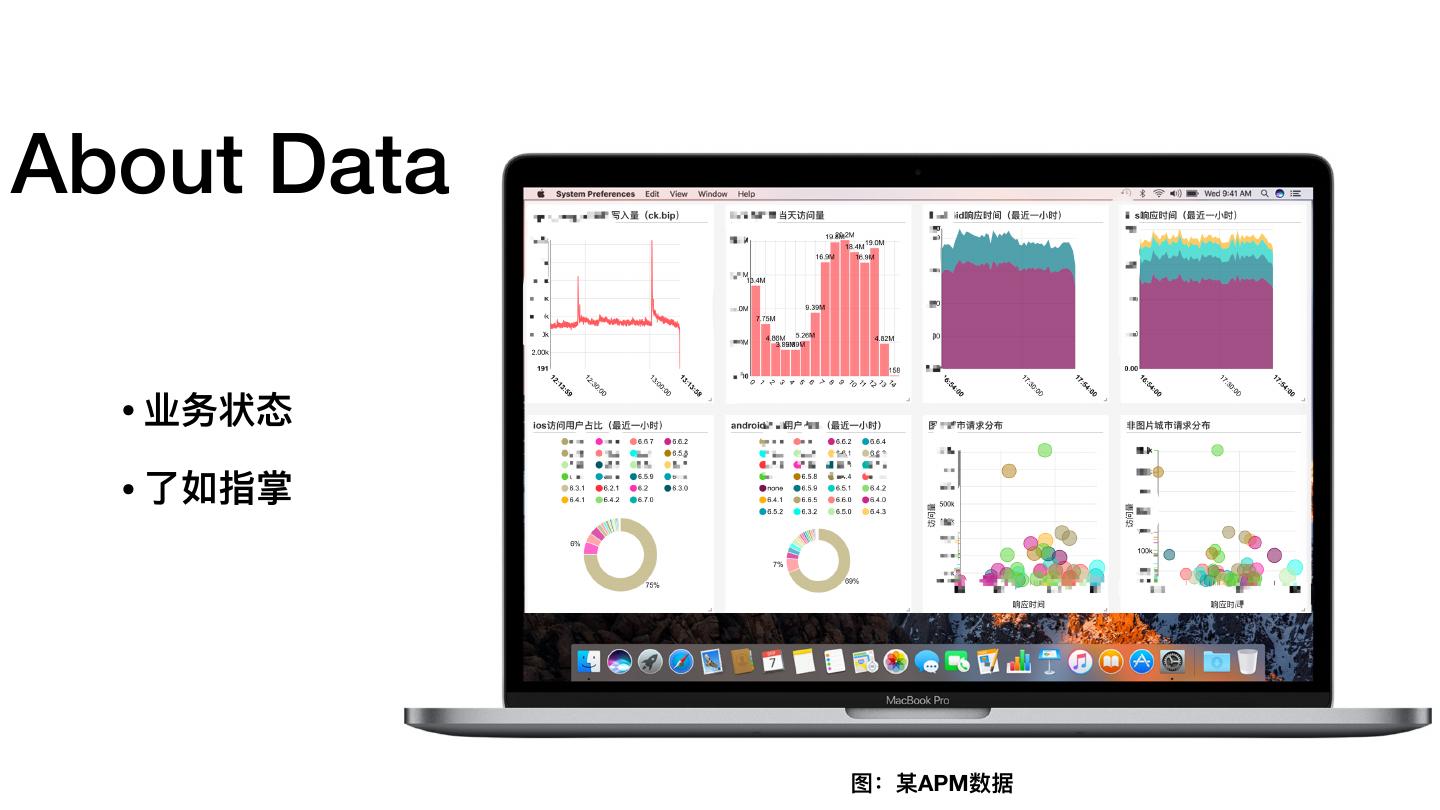
7 .About Data • 业务状态 • 了了如指掌 图:某APM数据
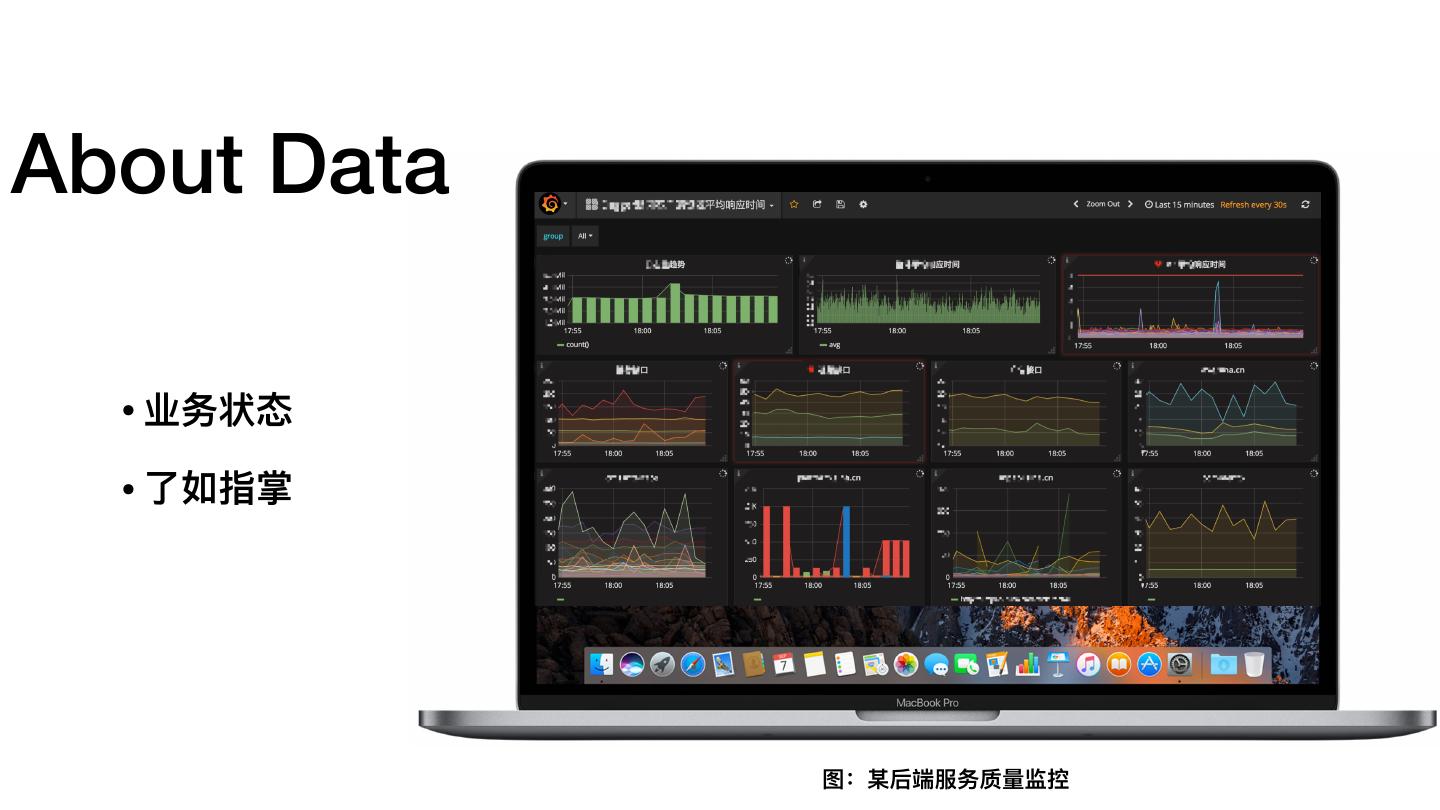
8 .About Data • 业务状态 • 了了如指掌 图:某后端服务质量量监控
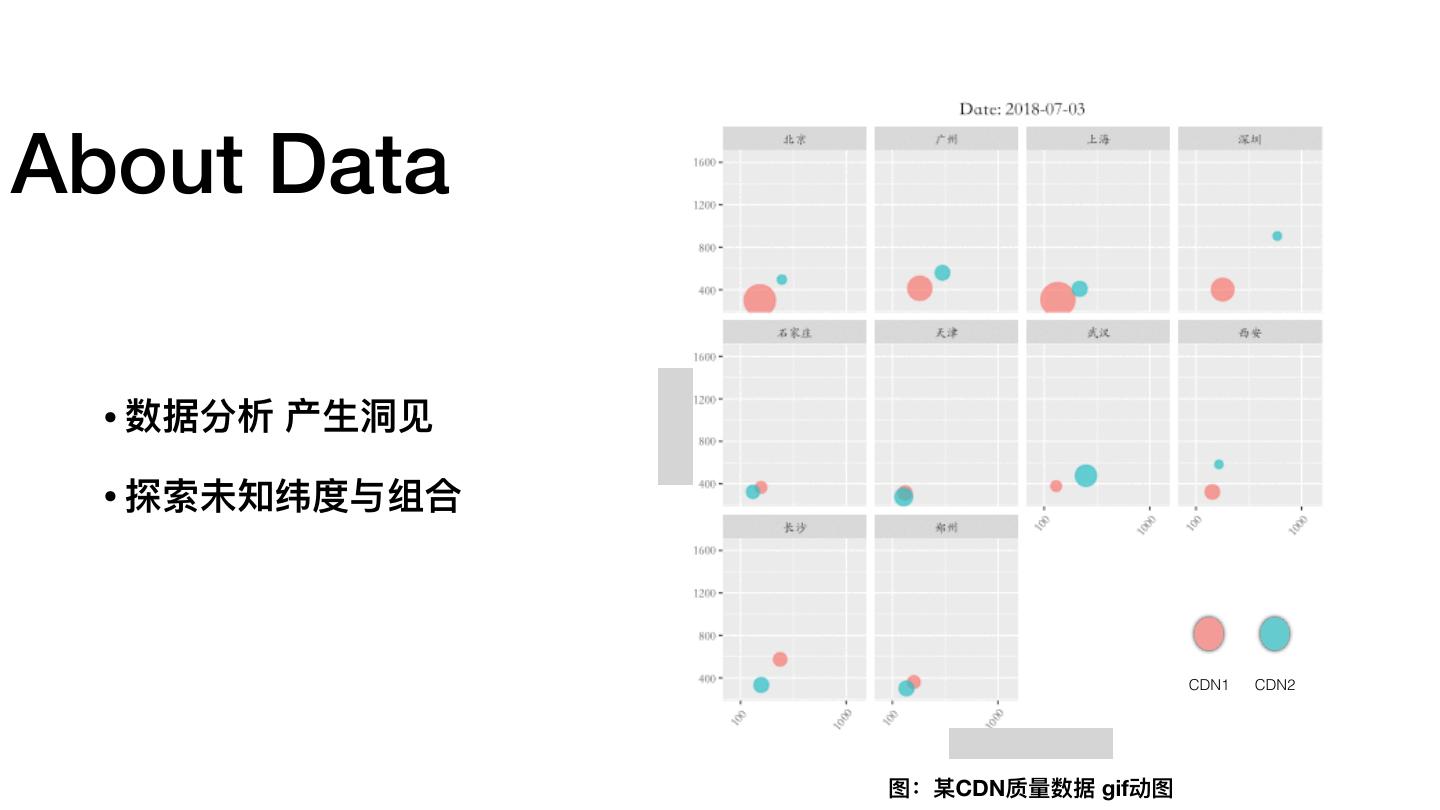
9 .About Data • 数据分析 产⽣生洞洞⻅见 • 探索未知纬度与组合 CDN1 CDN2 图:某CDN质量量数据 gif动图
10 .About Data • 数据可视化 • 直观⾼高效 图:某业务在不不同机房质量量数据分布 图:某地⽤用户CDN流量量分布
11 .About Data • 精细化运维 • 服务质量量⾃自证 图:Redis请求分析
12 .About Data • 助⼒力力AIOps 图:某域名响应时间⽆无阈值异常监控 • 异常检测 图:某域名访问量量⽆无阈值异常监控
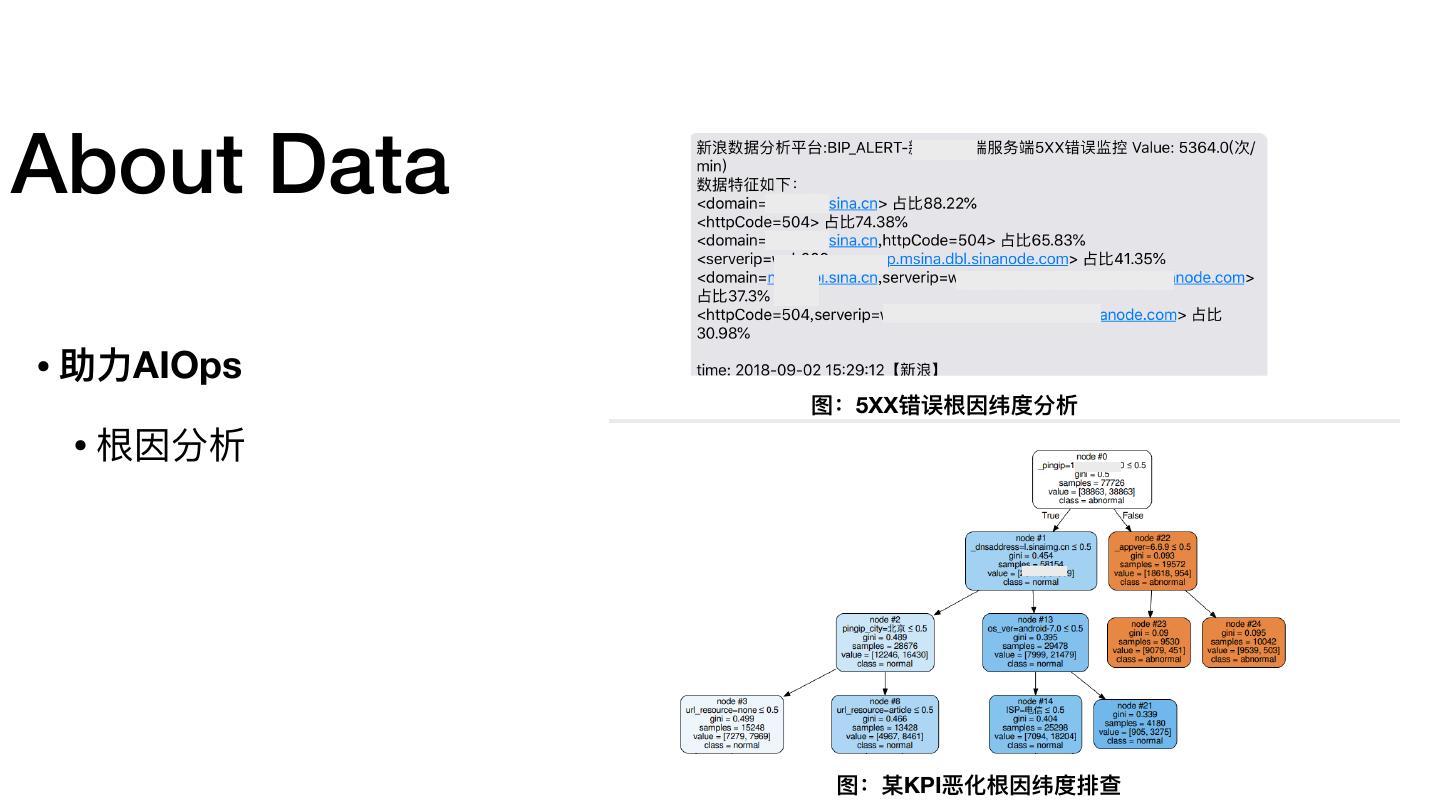
13 .About Data • 助⼒力力AIOps 图:5XX错误根因纬度分析 • 根因分析 图:某KPI恶化根因纬度排查
14 .About Data 让业务放开写⽇日志 海海量量、实时、 多维、多级 精细化运维和AIOps 数据 数据驱动业务
15 .Why ClickHouse Before ClickHouse DATA • 典型架构
16 .Why ClickHouse Before ClickHouse 1.链路路太⻓长 2.ES查询、ES存储 3.Hive太慢 4.Spark太重 5.实时⽅方式需要舍弃原始数据 6.BI⼯工具少,分析师崩溃
17 .Why ClickHouse 俄罗斯搜索巨头Yandex开源 异步复制 OLAP 最终⼀一致 SQL 统计函数 压缩 PB级别 列列式存储 集群 驱动丰富 updated in real time 超⾼高性能 线性扩展 跨数据中⼼心
18 .Why ClickHouse 图:ClickHouse线上⼀一些SQL gif动图 注:该配置为4台低配服务器器,⾮非后⽂文的机型
19 .Why ClickHouse ⼀一个体量量超级⼤大的 SQL超级快的 关系型数据仓库
20 .Why ClickHouse With ClickHouse • 准实时⼊入库 • 原始数据随⽤用随查 • 缩短数据处理理路路径 • ETL进程易易扩容、通⽤用化 • 资源使⽤用⼤大⼤大降低 图:ClickHouse架构数据流程
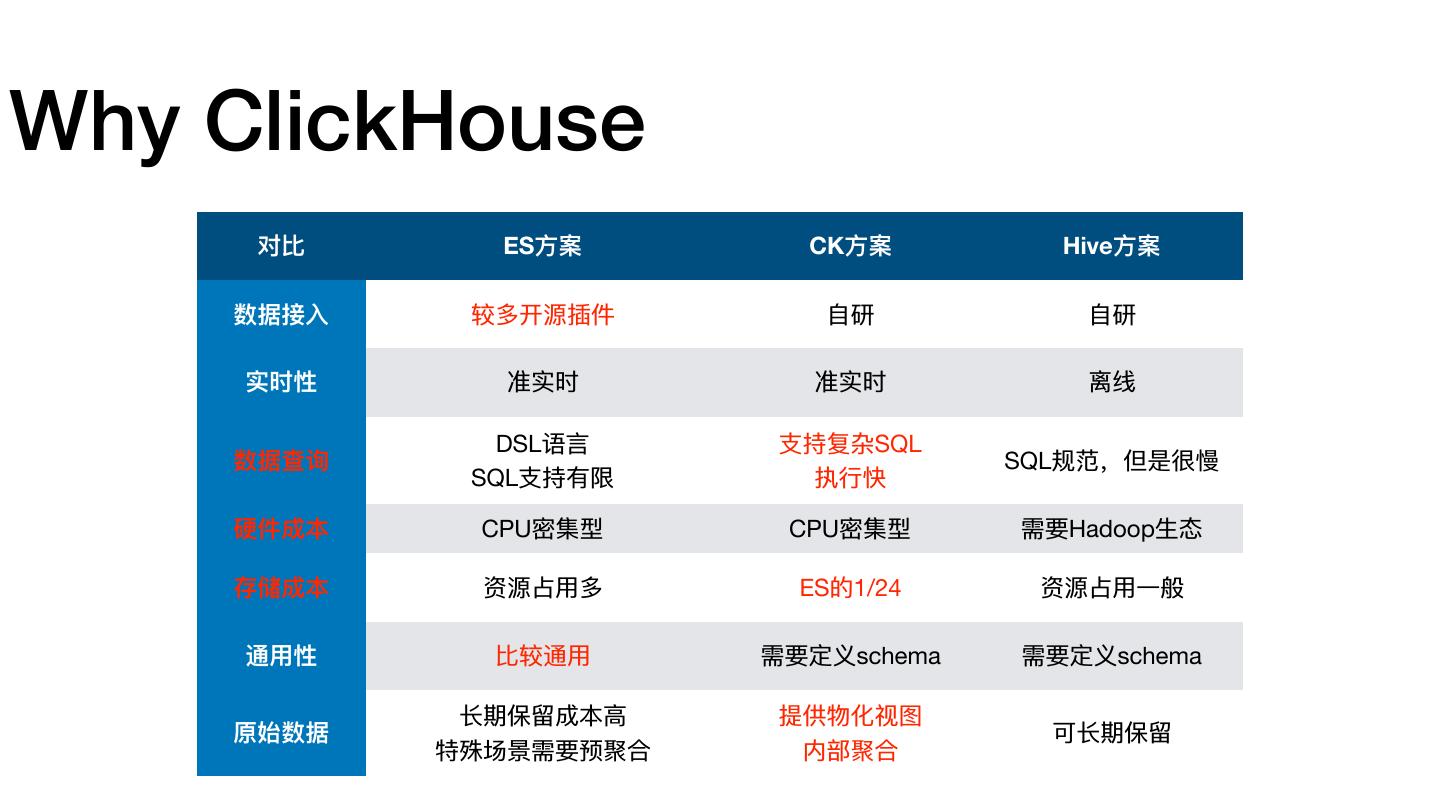
21 .Why ClickHouse 对⽐比 ES⽅方案 CK⽅方案 Hive⽅方案 数据接⼊入 较多开源插件 ⾃自研 ⾃自研 实时性 准实时 准实时 离线 DSL语⾔言 ⽀支持复杂SQL 数据查询 SQL规范,但是很慢 SQL⽀支持有限 执⾏行行快 硬件成本 CPU密集型 CPU密集型 需要Hadoop⽣生态 存储成本 资源占⽤用多 ES的1/24 资源占⽤用⼀一般 通⽤用性 ⽐比较通⽤用 需要定义schema 需要定义schema ⻓长期保留留成本⾼高 提供物化视图 原始数据 可⻓长期保留留 特殊场景需要预聚合 内部聚合
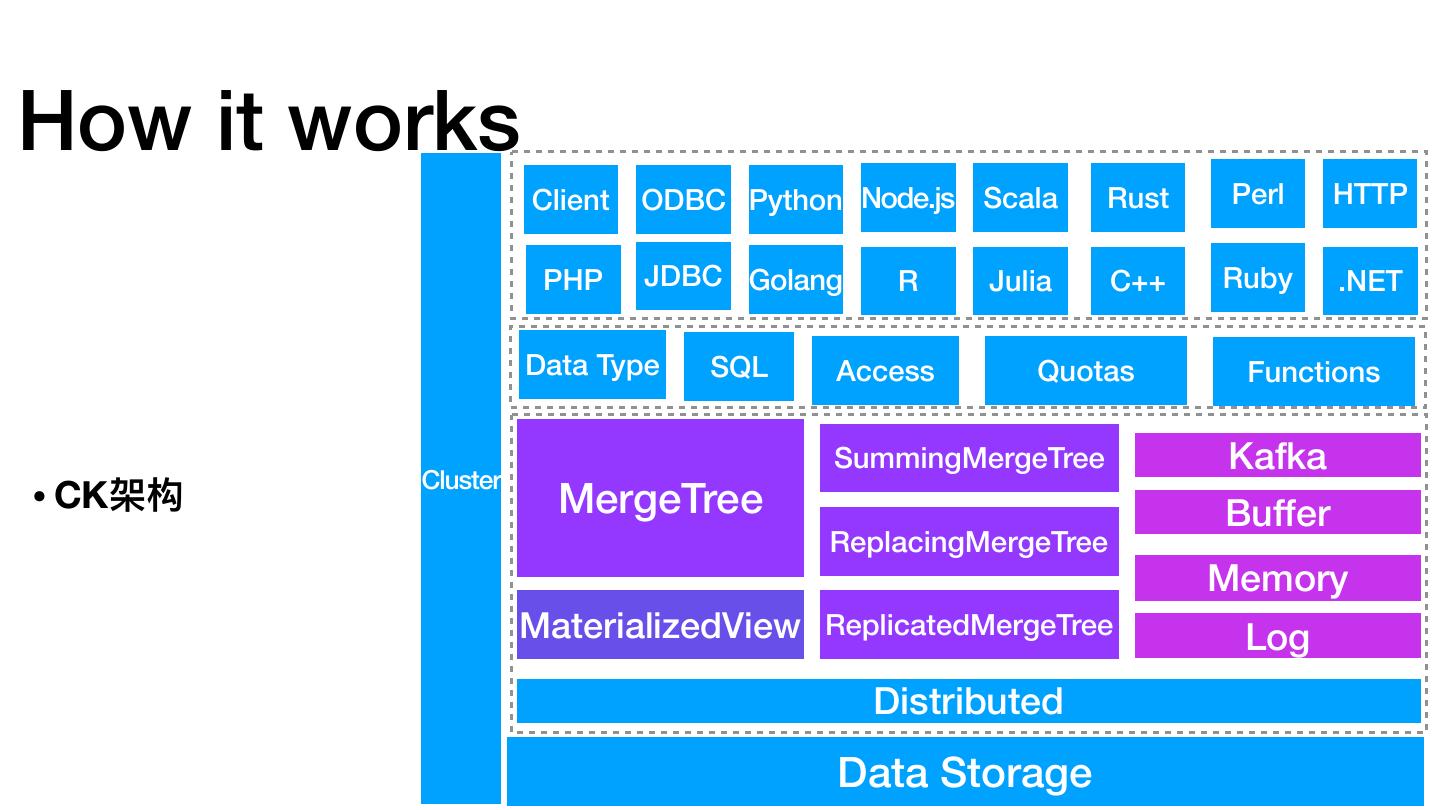
22 .How it works Client ODBC Python Node.js Scala Rust Perl HTTP PHP JDBC Golang R Julia C++ Ruby .NET Data Type SQL Access Quotas Functions SummingMergeTree Kafka Cluster • CK架构 MergeTree Buffer ReplacingMergeTree Memory MaterializedView ReplicatedMergeTree Log Distributed Data Storage
23 .How it works • 列列式存储,异步merge,集群模式 • 向量量引擎+SIMD,超越tight loop • CK为什什么这么快? • ⽀支持有限的delete操作 • 数据压缩,减少IO • 不不⽀支持事务 • 引擎给⼒力力
24 .How it works • MergeTree的Merge 类似LSM Tree,但是没有内存表,不不记录事务⽇日志 图:LSMTree原理理图、LevelDB原理理图
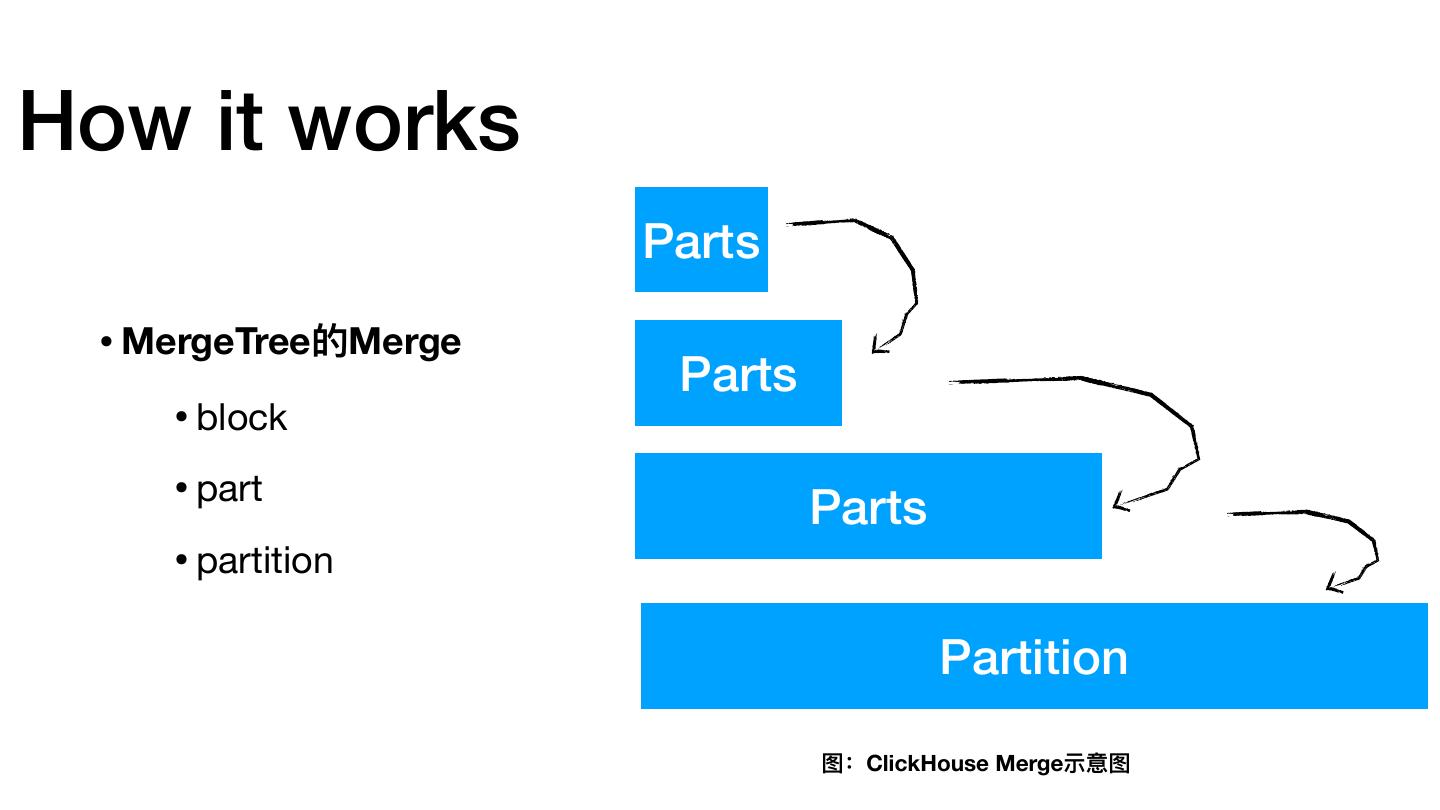
25 .How it works Parts • MergeTree的Merge Parts • block • part Parts • partition Partition 图:ClickHouse Merge示意图
26 .How it works • MergeTree的Tree 图:MergeTree引擎原理理
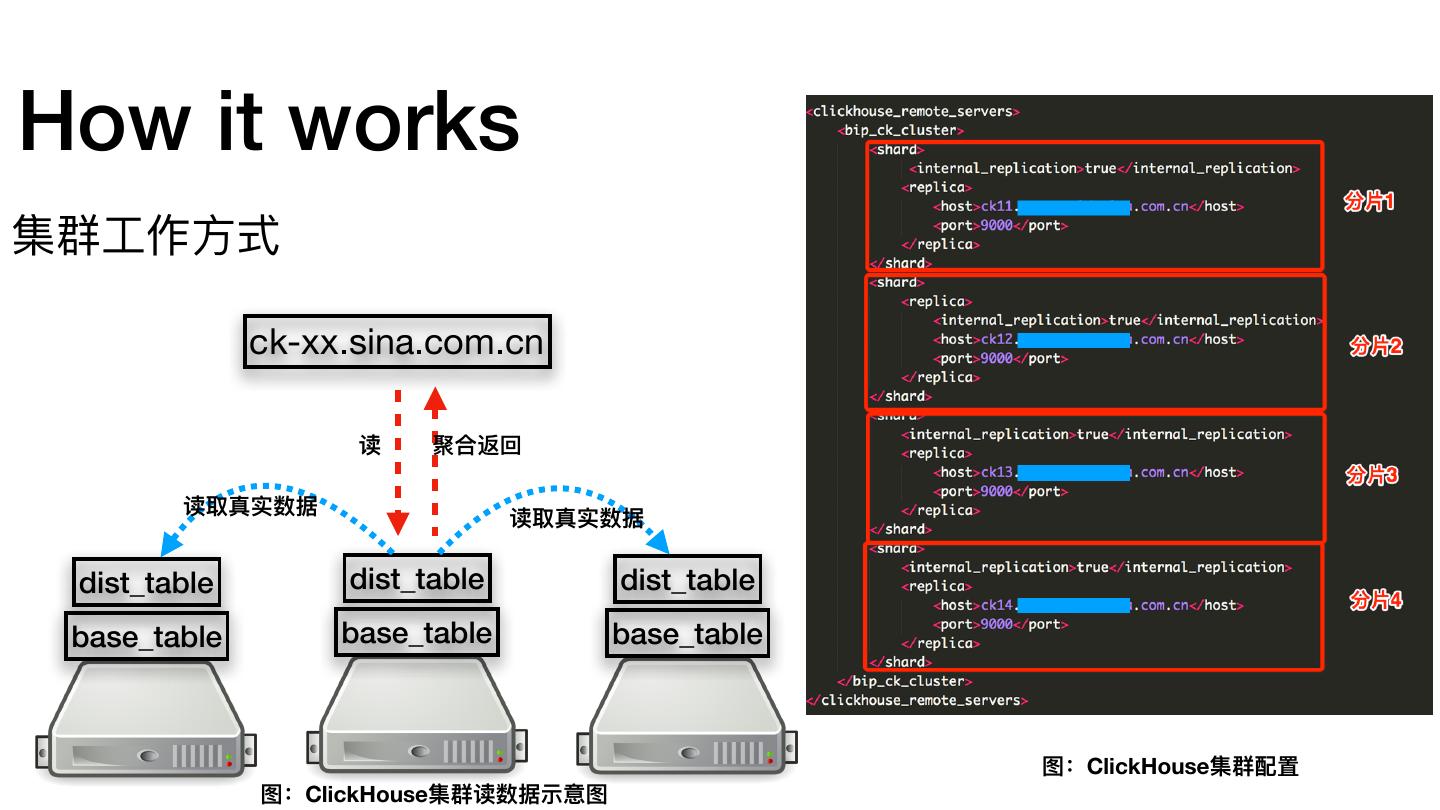
27 .How it works 集群⼯工作⽅方式 ck-xx.sina.com.cn 读 聚合返回 读取真实数据 读取真实数据 dist_table dist_table dist_table base_table base_table base_table 图:ClickHouse集群配置 图:ClickHouse集群读数据示意图
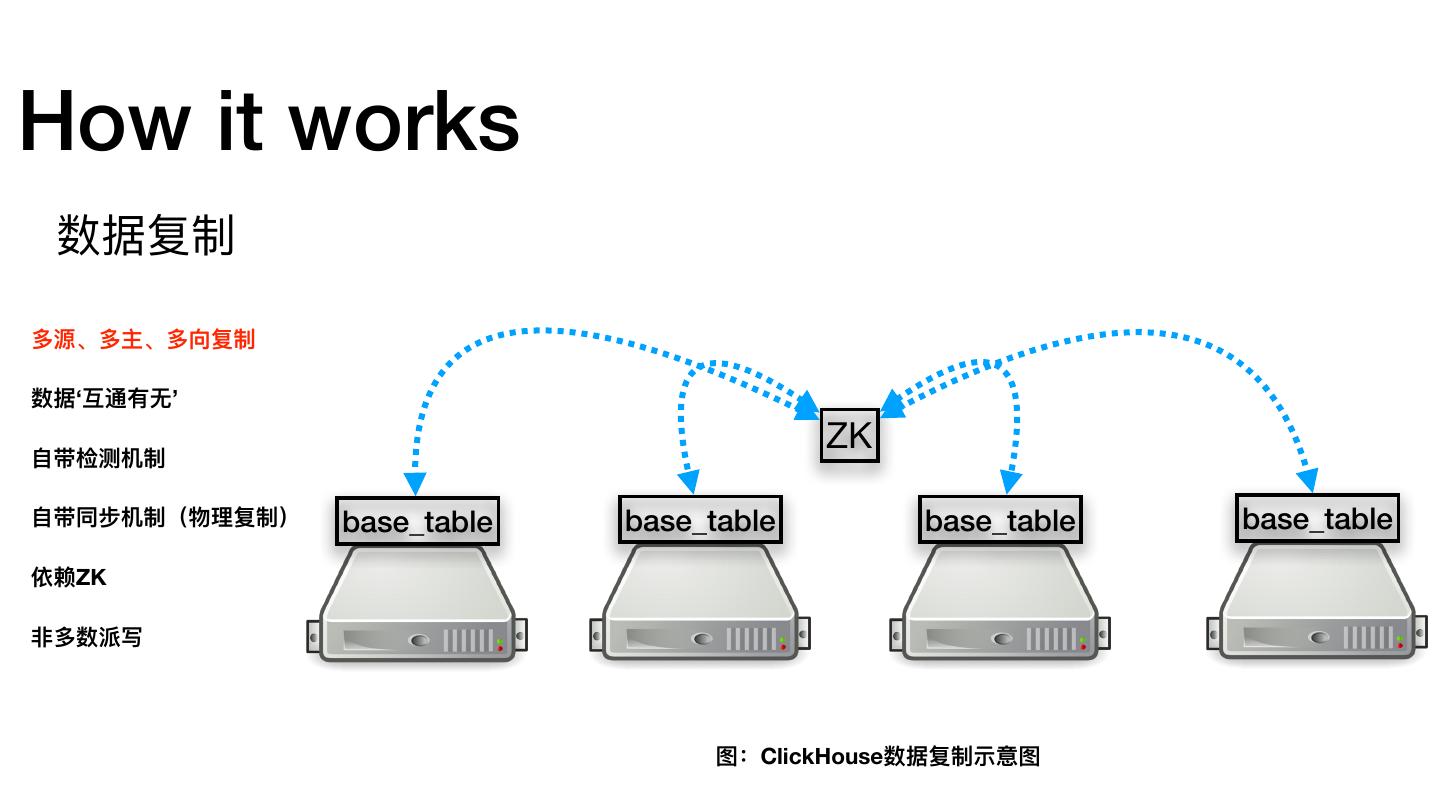
28 .How it works 数据复制 多源、多主、多向复制 数据‘互通有⽆无’ ZK ⾃自带检测机制 ⾃自带同步机制(物理理复制) base_table base_table base_table base_table 依赖ZK ⾮非多数派写 图:ClickHouse数据复制示意图
29 .How it works 1-1 N-1 1-2 N-2 • 令⼈人苦恼的复制架构 …… 1-3 N-3 1-4 N-4 Cluster 1 Cluster N 图:ClickHouse数据复制示意图
3秒后跳转登录页面
去登陆

