
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
实战教学:Cassandra常用工具详解
1.Cassandra介绍
1.1 Cassandra优势
1.2 Cassandra架构
2.集群信息⼯工具
3.单点运维⼯工具
4.性能诊断⼯工具
5.Compaction相关⼯工具
展开查看详情
1 .实战教学:CASSANDRA常⽤用⼯工具详解 郭泽晖(索⽉月) 2019.11.07 CASSANDRA
2 .OVERVIEW 1.Cassandra介绍 1.1 Cassandra优势 1.2 Cassandra架构 2.集群信息⼯工具 3.单点运维⼯工具 4.性能诊断⼯工具 5.Compaction相关⼯工具
3 .1.1 CASSANDRA优势 海海量量数据存储 灵活的⽔水平扩展 简洁易易上⼿手的类SQL语法 总是保持在线 多语⾔言客户端⽀支持 可调节读写⼀一致性级别 垂直架构性能强劲 部署⾮非常简单
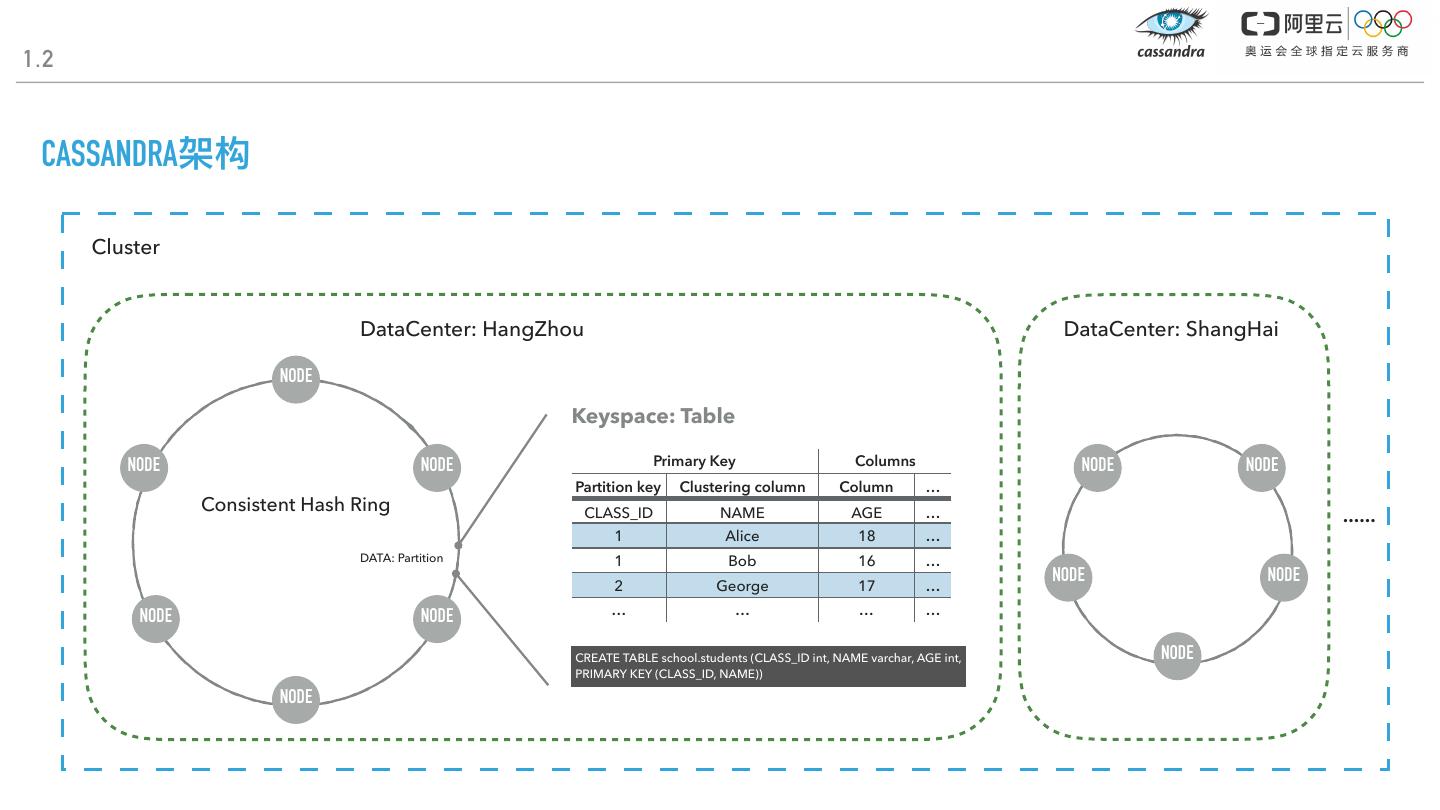
4 .1.2 CASSANDRA架构 Cluster DataCenter: HangZhou DataCenter: ShangHai NODE Keyspace: Table NODE NODE Primary Key Columns NODE NODE Partition key Clustering column Column … Consistent Hash Ring CLASS_ID NAME AGE … …… 1 Alice 18 … DATA: Partition 1 Bob 16 … NODE NODE 2 George 17 … NODE NODE … … … … CREATE TABLE school.students (CLASS_ID int, NAME varchar, AGE int, NODE PRIMARY KEY (CLASS_ID, NAME)) NODE
5 .2 2. 集群信息⼯工具
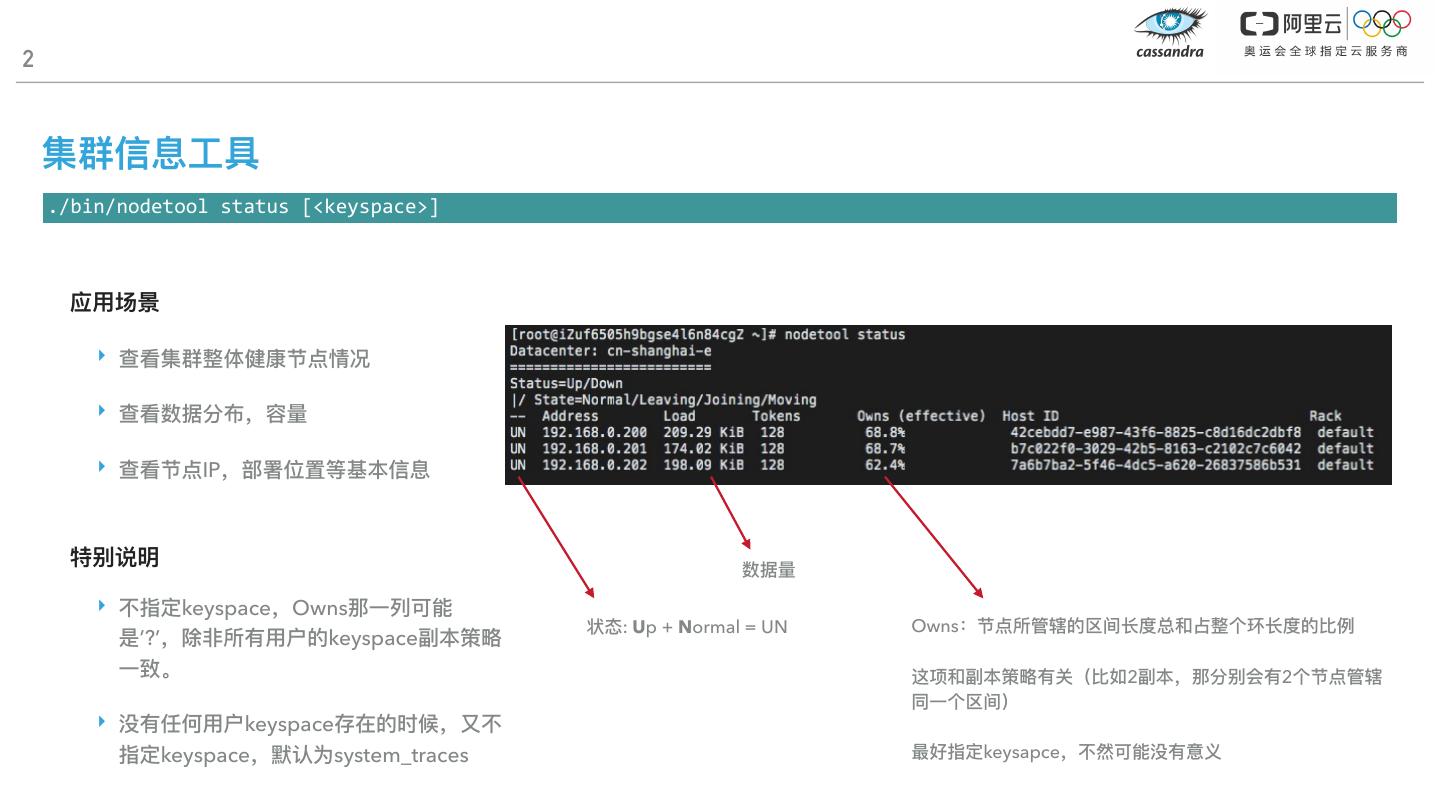
6 .2 集群信息⼯工具 ./bin/nodetool status [<keyspace>] 应⽤用场景 ‣ 查看集群整体健康节点情况 ‣ 查看数据分布,容量量 ‣ 查看节点IP,部署位置等基本信息 特别说明 数据量量 ‣ 不不指定keyspace,Owns那⼀一列列可能 状态: Up + Normal = UN Owns:节点所管辖的区间⻓长度总和占整个环⻓长度的⽐比例例 是’?’,除⾮非所有⽤用户的keyspace副本策略略 ⼀一致。 这项和副本策略略有关(⽐比如2副本,那分别会有2个节点管辖 同⼀一个区间) ‣ 没有任何⽤用户keyspace存在的时候,⼜又不不 指定keyspace,默认为system_traces 最好指定keysapce,不不然可能没有意义
7 .2 集群信息⼯工具 ./bin/nodetool version 应⽤用场景 ‣ 升级后检查是否升级成功 ‣ ⼀一些运维脚本需要兼容不不同版本,可以依 此判断 特别说明 ‣ ⽆无
8 .2 集群信息⼯工具 ./bin/nodetool describecluster 应⽤用场景 ‣ 获取集群名 ‣ 检查各节点Schema是否⼀一致 特别说明 Schema版本:就是表结构这些元信息算出的⼀一个Hash值 ‣ Cassandra向所有节点⼴广播新的Schema需 可能会有多⾏行行,因为节点的Schema版本可能不不⼀一致 要⼀一定时间,所以如果你看到Schema版本 不不⼀一致并不不⼀一定真的有问题。如果⼀一直不不 ⼀一致,那就需要进⾏行行⼀一定⼈人⼯工⼲干预。
9 .2 集群信息⼯工具 ./bin/nodetool describering <keyspace> 应⽤用场景 ‣ 查看某个Keysspace数据分区详细信息 ‣ 可以⽤用来分析热点,知道热点数据的 partition key分布后,可以进⼀一步通过此 命令知道数据会由哪些节点负责 特别说明 ‣ ⽆无
10 .3 3. 单点运维⼯工具
11 .3 单点运维⼯工具 ./bin/nodetool netstats 应⽤用场景 ‣ 新节点扩容后,查看节点状态,数据同步 进度 ‣ 也能查看消息处理理情况,有没有堆积等 特别说明 ‣ 扩容中看到的信息会不不太⼀一样,如右图所 示
12 .3 单点运维⼯工具 ./bin/nodetool decommission 应⽤用场景 ‣ 缩容,数据会迁移到其他节点 特别说明 ‣ 执⾏行行后这个命令会⼀一直卡着,节点处于LEAVING状态,直到结 束。可以提前中断命令,因为实际过程在Server端异步执⾏行行,然 后通过netstats观察是否退役完成。 ‣ 退役后进程不不会⾃自动关闭,会进⼊入DECOMMISSIONED状态,需 要⼿手动停掉进程。
13 .3 单点运维⼯工具 ./bin/nodetool cleanup [(-j <jobs> | --jobs <jobs>)] [<keyspace> <tables>…] 应⽤用场景 ‣ 扩容后⽴立即清理理多余数据 ‣ 扩容后新节点承担了了原来部分数据,所以 旧节点上有部分数据已经不不归该节点管辖 特别说明 ‣ 这个操作会增加磁盘消耗,相当于⽴立即做compaction把多余数据 删除。 ‣ jobs参数控制并发度,cleanup执⾏行行⽤用的是Compaction线程资源 (concurrent_compactors)
14 .3 单点运维⼯工具 ./bin/nodetool drain 应⽤用场景 ‣ 停服,所有内存数据刷⼊入磁盘。 ‣ ⽐比较早的版本⽤用来优雅的停⽌止Cassandra 进程 特别说明 ‣ 执⾏行行后这个命令会⼀一直卡着,节点处于DRAINING状态, 直到结束。可以提前中断命令,因为实际过程在Server端 异步执⾏行行,然后通过netstats观察是否退役完成。 ‣ 退役后进程不不会⾃自动关闭,会进⼊入DRAINED状态,需要⼿手 动停掉进程。
15 .3 单点运维⼯工具 ./bin/nodetool join 应⽤用场景 ‣ 扩容时候可能会使⽤用write survey模式启动 节点。之后再⽤用该命令将write survey模式 下节点加⼊入集群。 特别说明 ‣ write survey模式⽤用于测试compaction compress等不不同策 略略效果,或者测试新版等。⽤用write survey启动后相当于⼀一 个⽣生产环节的测试节点,可以安全的测试。
16 .3 单点运维⼯工具 ./bin/nodetool move <new token> 应⽤用场景 ‣ 移动节点到指定的token,只能⽤用在单个token的节点上。 ‣ 通俗的讲就是换⼀一个区间给该节点管理理,会移动数据。 ‣ ⼀一般是根据业务,⾃自⼰己设计了了分区策略略,⾃自⼰己计算token的时候可能 会⽤用到。默认每个节点是随机256个token出来,⽤用不不到这个命令。 特别说明 ‣ 移动时候节点会处于MOVING状态,可以通过netstats查 看。
17 .3 单点运维⼯工具 ./bin/nodetool removenode <status>|<force>|<ID> 应⽤用场景 ‣ ⽆无法使⽤用decommission时候才会⽤用到此命令,功能类似 decommission。 ‣ ⽐比如要下线的⽬目标节点down了了,⽆无法恢复 特别说明 ‣ 移动时候节点会处于MOVING状态,可以通过netstats查 看。
18 .3 单点运维⼯工具 ./bin/nodetool resetlocalschema 应⽤用场景 ‣ 解决节点表Schema不不⼀一致问题 特别说明 ‣ 会删除本地Schema,然后从其它节点同步。会短暂的⽆无法 查找到表的元信息。
19 .4 4. 性能诊断⼯工具
20 .4 性能诊断⼯工具 ./bin/nodetool proxyhistograms 应⽤用场景 ‣ 从Coordinator视⻆角查看最近读写延 迟 ‣ 可以⽤用来诊断慢节点 特别说明 ‣ Coordinator是负责接受⽤用户请求, 再并发读写其他集群内部节点的模块, 类似proxy。每个节点都可以作为 Coordinator
21 .4 性能诊断⼯工具 ./bin/nodetool tablehistograms <keyspace> <table> | <keyspace.table> 应⽤用场景 ‣ 查看Table级别延迟,统计的是本地执⾏行行,不不 是从Coordinator视⻆角。 ‣ 也可以⽤用来诊断Partition是否过⼤大 特别说明 ‣ ⽆无
22 .4 性能诊断⼯工具 ./bin/nodetool tablestats [<keyspace.table>] 应⽤用场景 ‣ 查看table对资源的使⽤用情况,磁盘空间,内 存等。 ‣ 查看table读写请求量量统计 ‣ 查看tombstones数量量,分析读性表现太差的 原因 特别说明 ‣ ⽆无
23 .4 性能诊断⼯工具 ./bin/nodetool info 应⽤用场景 ‣ 查看读Cache命中率,调优性能。如 果命中率很低,业务可以通过提升命 中率改善读延迟。如果命中率本身很 ⾼高,可以尝试增加读Cache获得更更多 收益。 特别说明 ‣ ⽆无
24 .4 性能诊断⼯工具 ./bin/nodetool toppartitions <keyspace> <cfname> <duration> 应⽤用场景 ‣ 分析热点⽤用,通过抽样统计⼀一段时间,得出最热的那 些partition key 特别说明 ‣ 没请求的时候⽆无法统计,会输出右上 图所示 ‣ 统计不不是完全精确的,是近似
25 .4 性能诊断⼯工具 ./bin/nodetool getendpoints <keyspace> <table> <key> 应⽤用场景 ‣ 计算某个partition key会分布在哪些节点上 ‣ 分析热点或者过⼤大的partition时,进⼀一步定位受影响的节点。 ‣ 可以⽤用来预测业务数据均衡情况。当你设计好key后,可以⽣生成 ⼀一些key,看看是否会均匀分布在不不同节点上。 特别说明 ‣ ⽆无
26 .4 性能诊断⼯工具 ./bin/nodetool tpstats 应⽤用场景 ‣ 查看所有线程池的运⾏行行情况,可以观察某些任务是否 有阻塞现象,以此推断⼀一些问题。 特别说明 ‣ ⽆无
27 .5 5. COMPACTION相关⼯工具
28 .5 COMPACTION相关⼯工具 ./bin/nodetool compact [<keyspace> <tables>…] 应⽤用场景 ‣ ⼿手动触发Major Compaction,⽤用以优化读性能和清理理 被删除的数据释放空间。 ‣ 可以带上—split-output参数防⽌止STCS策略略的表⽣生成1 个超⼤大SSTable 特别说明 ‣ 这个属于major compaction,会选取所有SSTable在⼀一个 CompactionTask中。可能会临时导致性能衰退,并且需要⾜足够 的空间磁盘空间。 ‣ 除⾮非你有⾜足够的理理由,并且很清楚⾃自⼰己在做什什么,不不然不不推荐 ⼿手动执⾏行行compaction。
29 .5 COMPACTION相关⼯工具 ./bin/nodetool compactionhistory 应⽤用场景 ‣ 查看compaction任务压缩历史,保留留7天 ‣ 可以观察compaction效果,释放空间多少,以及数据 重复情况。 特别说明 ‣ rows_merged 含义: {rows: count},rows是说某⼀一⾏行行由多少⾏行行合并⽽而 成。相当于这次compaction涉及的SSTable中,有 rows个SSTable包含了了这⼀一⾏行行的数据。count就是这 样的⾏行行有多少个。如果rows很⼤大,count也很⼤大, 说明业务数据重叠情况很多,可能经常更更新。
3秒后跳转登录页面
去登陆

