

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
19_10 - strapdata_Elassandra_cassandra_es
cassandra 与 es结合的最近进展
展开查看详情
1 . Las Vegas 2019 Consistent Cassandra schema changes in Elassandra Vincent Royer vroyer@strapdata.com Strapdata 2017-2019 © http://www.strapdata.com 1
2 . Mapping/Schema changes in Elassandra 1 What is Elassandra 2 Elasticsearch mapping management 3 Elassandra approach for schema changes 4 Conclusion Strapdata 2017-2019 ©
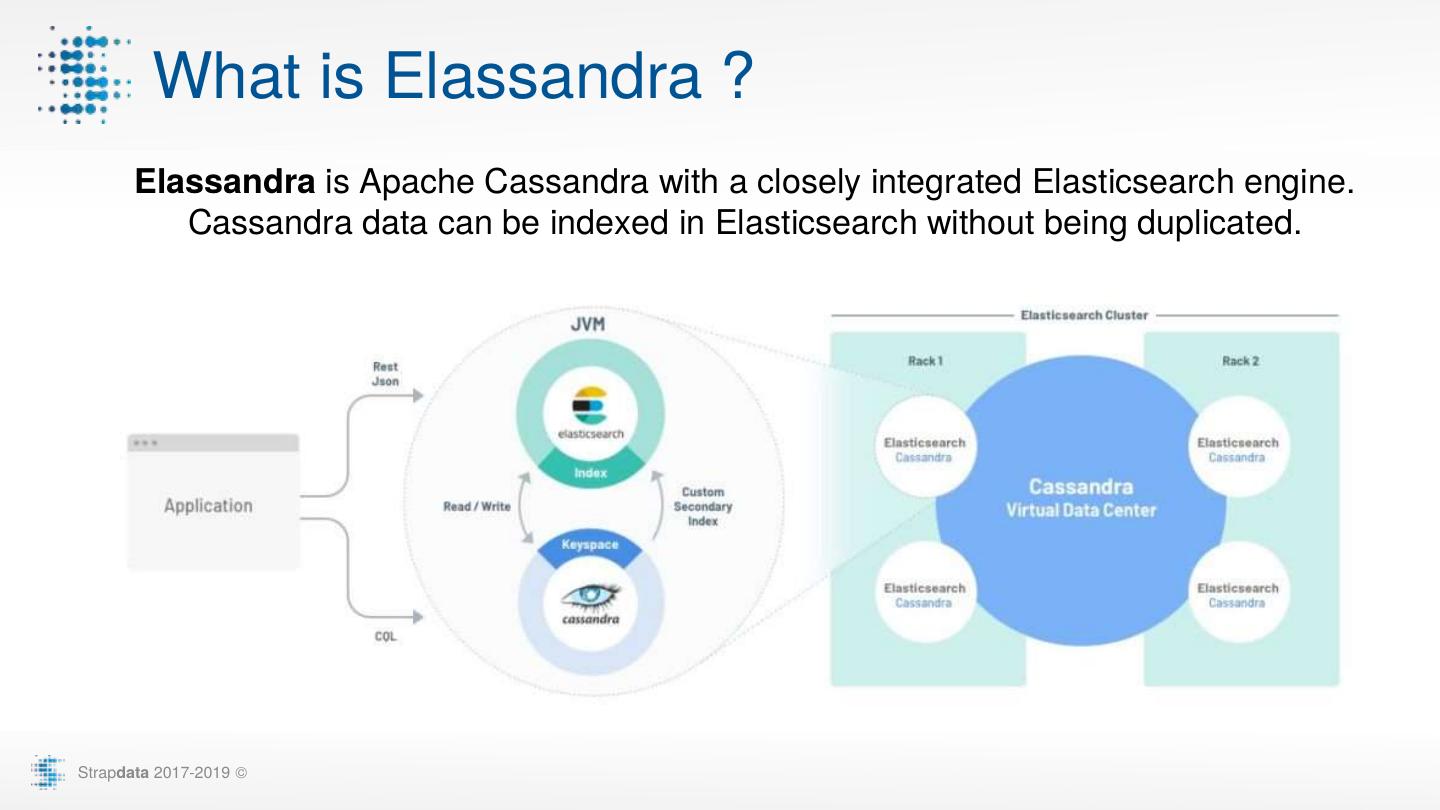
3 . What is Elassandra ? Elassandra is Apache Cassandra with a closely integrated Elasticsearch engine. Cassandra data can be indexed in Elasticsearch without being duplicated. Strapdata 2017-2019 ©
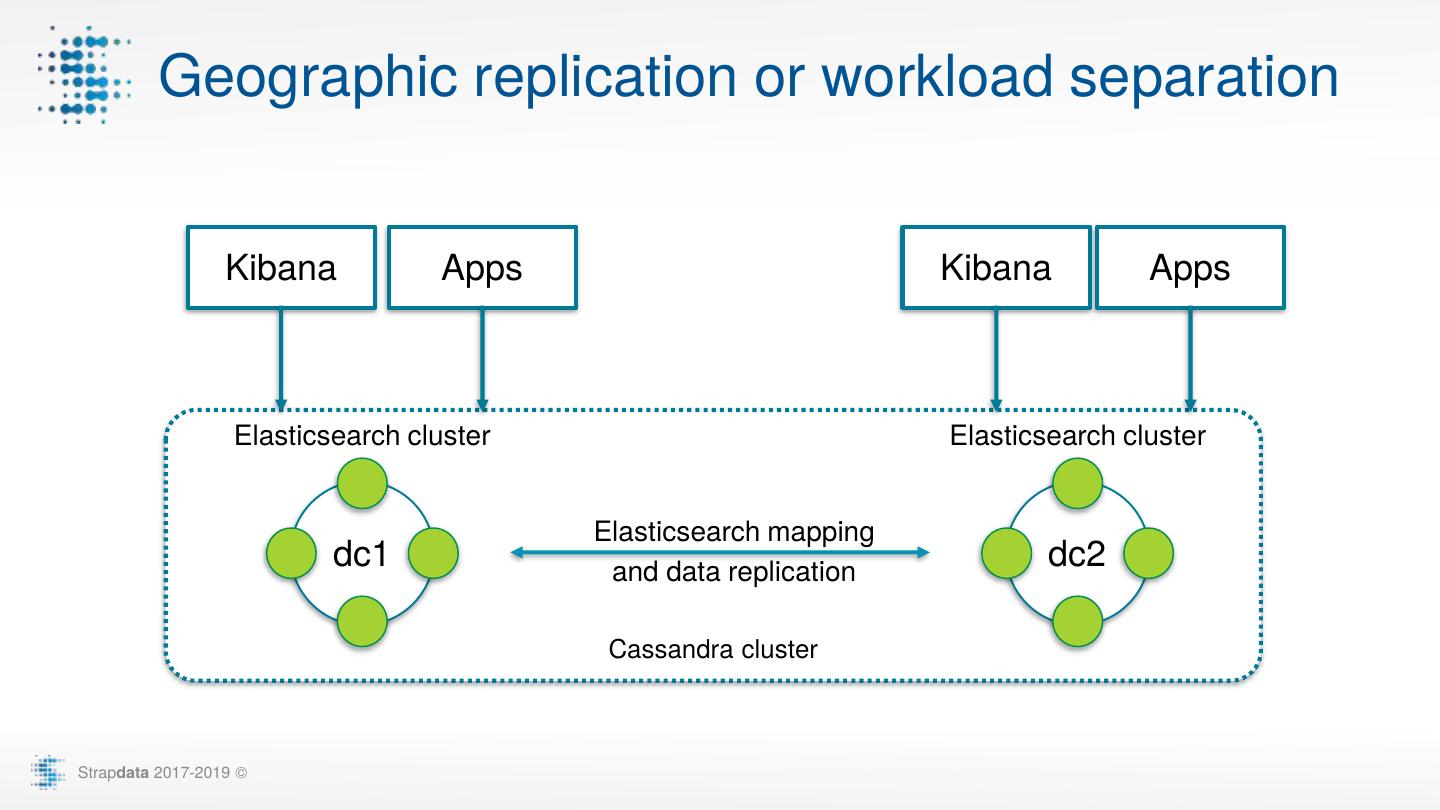
4 . Geographic replication or workload separation Kibana Apps Kibana Apps Elasticsearch cluster Elasticsearch cluster Elasticsearch mapping dc1 and data replication dc2 Cassandra cluster Strapdata 2017-2019 ©
5 . Elassandra Write Path col1 col2 col3 col4 MemTable Lucene API ElasticSecondaryIndex Lucene segments SSTables Strapdata 2017-2019 ©
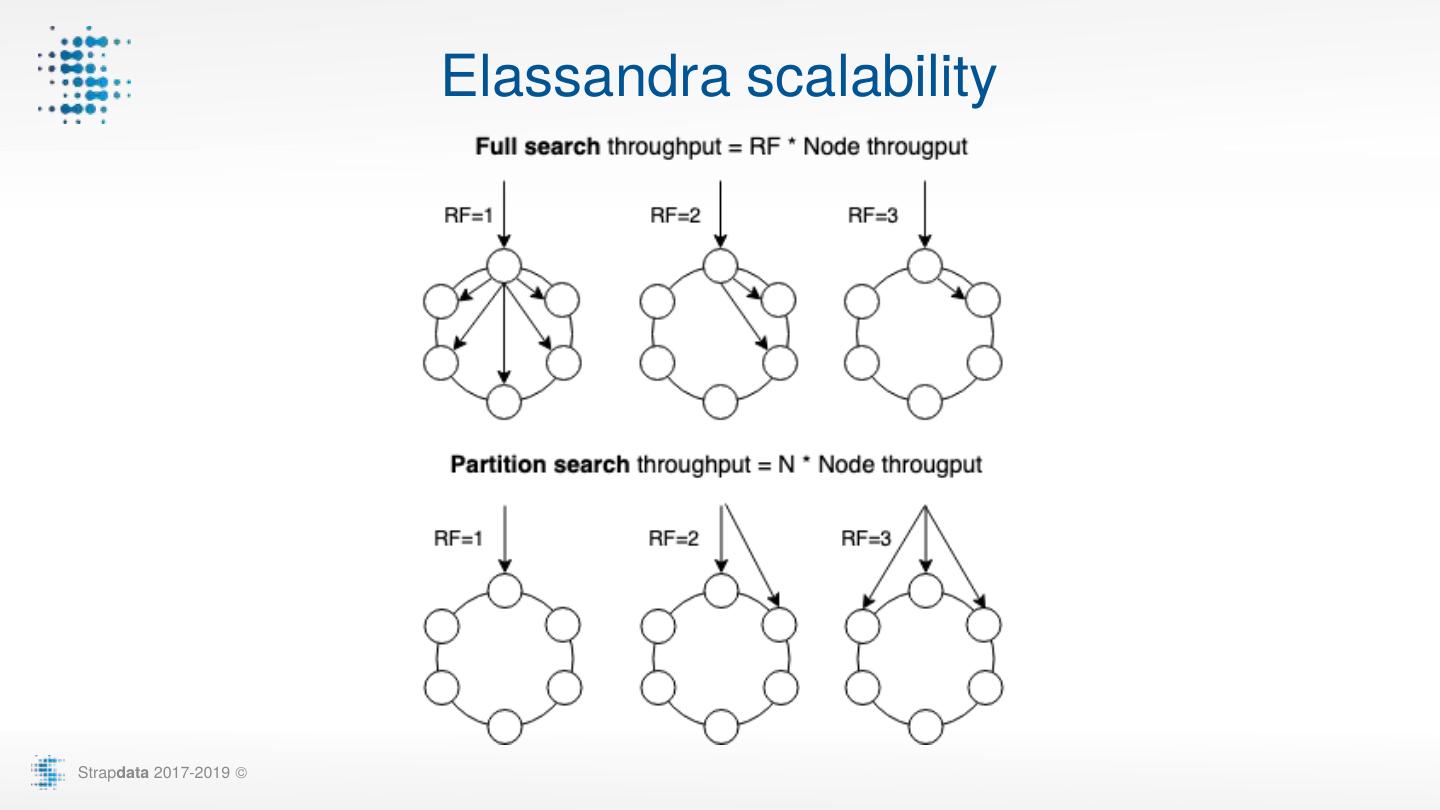
6 . Read Path: Full vs Partition search request By default, full search on a subset of nodes depending on RF curl “http://nodeX:9200/books/_search?pretty" -d’{ “query":{ … }}' Like the Elasticsearch routing, partition search targets replicas curl “http://nodeX:9200/books/_search?pretty&routing=xxx” -d’{ “query":{ … }}’ Elasticsearch query over CQL add routing when partition key is present SELECT * FROM books WHERE id=‘xxx’ AND es_query=’{"query":{ …}}' Strapdata 2017-2019 ©
7 . Elassandra scalability Strapdata 2017-2019 ©
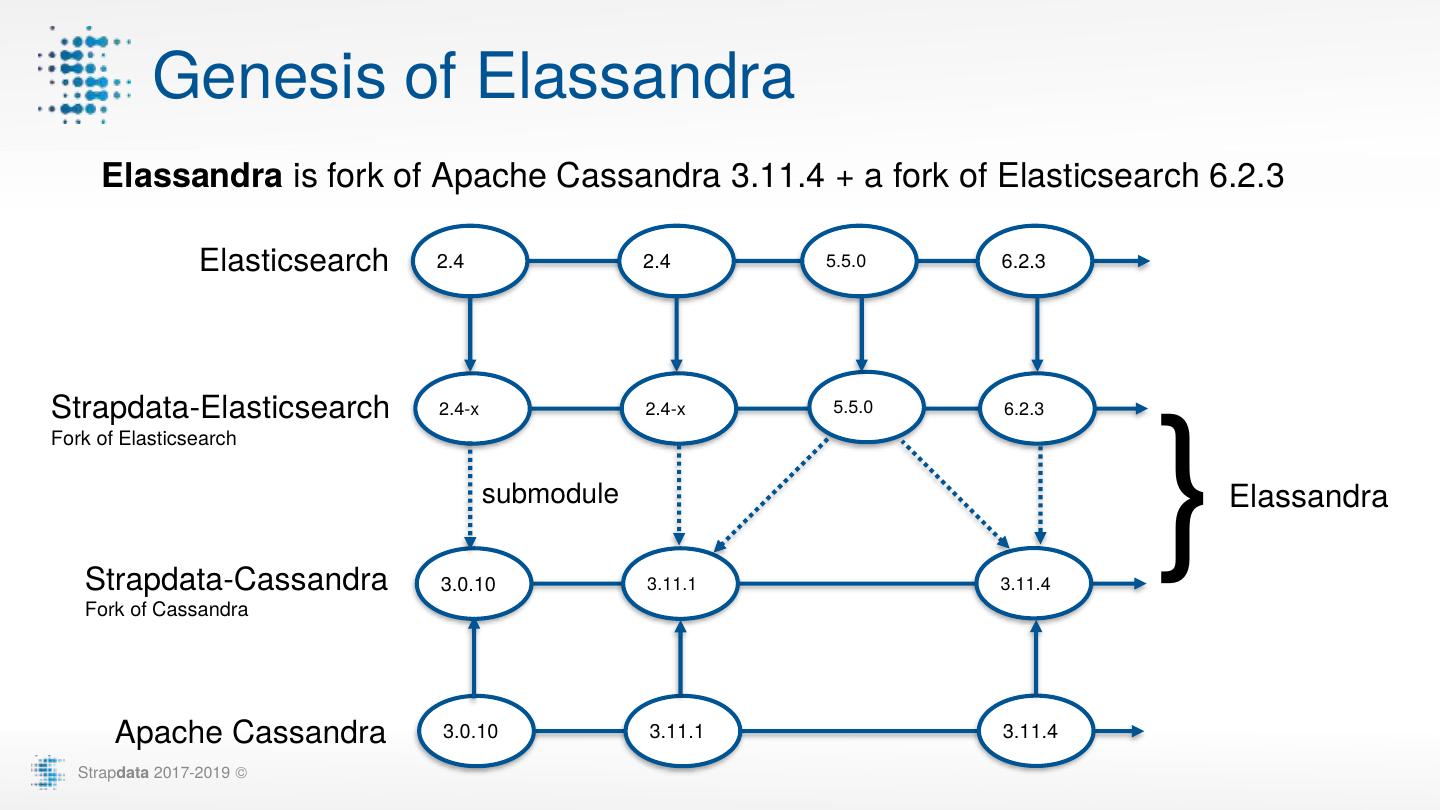
8 . Genesis of Elassandra Elassandra is fork of Apache Cassandra 3.11.4 + a fork of Elasticsearch 6.2.3 Elasticsearch 2.4 2.4 5.5.0 6.2.3 Strapdata-Elasticsearch 2.4-x 2.4-x 5.5.0 6.2.3 } Fork of Elasticsearch submodule Elassandra Strapdata-Cassandra 3.0.10 3.11.1 3.11.4 Fork of Cassandra Apache Cassandra 3.0.10 3.11.1 3.11.4 Strapdata 2017-2019 ©
9 . Mapping/Schema changes in Elassandra 1 What is Elassandra 2 Elasticsearch mapping management 3 Elassandra approach for schema changes 4 Conclusion Strapdata 2017-2019 ©
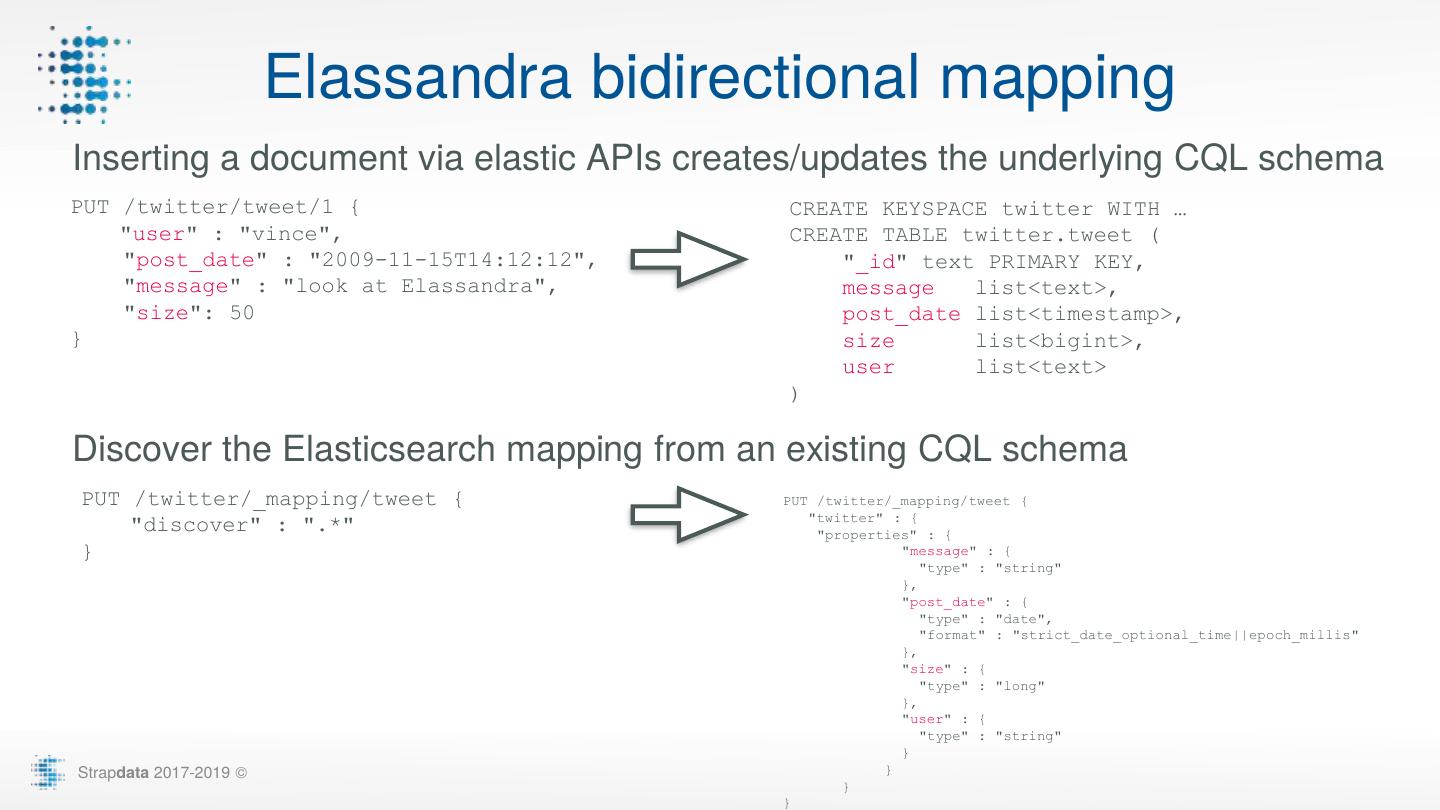
10 . Elassandra bidirectional mapping Inserting a document via elastic APIs creates/updates the underlying CQL schema PUT /twitter/tweet/1 { CREATE KEYSPACE twitter WITH … "user" : "vince", CREATE TABLE twitter.tweet ( "post_date" : "2009-11-15T14:12:12", "_id" text PRIMARY KEY, "message" : "look at Elassandra", message list<text>, "size": 50 post_date list<timestamp>, } size list<bigint>, user list<text> ) Discover the Elasticsearch mapping from an existing CQL schema PUT /twitter/_mapping/tweet { PUT /twitter/_mapping/tweet { "twitter" : { "discover" : ".*" "properties" : { } "message" : { "type" : "string" }, "post_date" : { "type" : "date", "format" : "strict_date_optional_time||epoch_millis" }, "size" : { "type" : "long" }, "user" : { "type" : "string" } Strapdata 2017-2019 © } } }
11 . Elassandra supports nested document with UDT Nested documents are stored in a Cassandra User Defined Type dynamically generated from the Elasticsearch mapping. curl -XPUT "http://$NODE:9200/directory/users/1" -d '{ "group" : "fans", "name" : { "first" : "John", "last" : "Smith" } }' CREATE KEYSPACE directory WITH replication = {'class': 'NetworkTopologyStrategy', 'dc1': '1'} AND durable_writes = true; CREATE TYPE directory.users_name ( last frozen<list<text>>, first frozen<list<text>> ); CREATE TABLE directory.users ( "_id" text PRIMARY KEY, group list<text>, name list<frozen<users_name>> ); CREATE CUSTOM INDEX elastic_users_name_idx ON directory.users () USING 'org.elasticsearch.cassandra.index.ExtendedElasticSecondaryIndex'; Strapdata 2017-2019 ©
12 . Elasticsearch mapping = CQL schema cql_xxx ES mapping attributes control the underlying CQL table schema Param Values Description cql_collection list, set or Control how the field of type X is mapped to a column list<X>, singleton set<X> or X. Default is list because Elasticsearch fields are multivalued. cql_partition_key true or false When the cql_primary_key_order >= 0, specify if the field is part of the cassandra partition key. Default is false meaning that the field is not part of the cassandra partition key. cql_primary_key_order integer Field position in the cassandra the primary key of the underlying cassandra table. Default is -1 meaning that the field is not part of the cassandra primary key. cql_udt_name <table_name>_< Specify the Cassandra User Defined Type name to use to store an field_name> object. By default, this is automatically build (dots in field_names are replaced by underscores) Strapdata 2017-2019 ©
13 . ES mapping stored in C* schema Since v6.2.3.10, Elasticsearch mapping is stored in the CQL schema as schema table extensions<text, blob> (blob = Smile encoded JSON) admin@cqlsh> SELECT keyspace_name, table_name, extensions FROM system_schema.tables; keyspace_name | table_name | extensions elastic_admin | metadata | {'metadata': 0x3a290a05fa886d6574612d64617461fa8676657273696f6e24010db68b636c75737465725f757569646361316664663335392d613061302d346664312d616436632d316432363035323438 3536308874656d706c61746573fa90616d646f63735f74656d706c6174653232fa846f72646572c041c28d696e6465785f7061747465726e73f84e6d795f746573745f7061747465726ef987 73657474696e6773fa84696e646578fa8a7265706c69636174696f6e444443313a3284636f6465634f6265… , 'owner': 0xa1fdf359a0a04fd1ad6c1d2605248560, 'version': 0x00000000000011bb} gmap | zones | {'elastic_admin/zones': 0x3a290a05fa847a6f6e6573fa8676657273696f6ec2847374617465436f70656e8773657474696e6773fa92696e6465782e6372656174696f6e5f646174654c313532363535313832373631 328d696e6465782e6b6579737061636543676d617092696e6465782e70726f76696465645f6e616d65447a6f6e657389696e6465782e75756964555732707a79774257523865565f56785833 4e7556417794696e6465782e76657273696f6e2e637265617465644636303230333939fb876d617070696e6773f8fa40fa865f736f75726365fa86656e61626c656423fb8970726f70657274 696573fa86636f6d6d656e74fa837479706543746578748d63716c5f636f6c6c656374696f6e4873696e676c65746f6efb836e616d65fa4e466b6579776f72644f4873696e676c65746f6e90 63716c5f706172746974696f6e5f6b6579239463716c5f7072696d6172795f6b65795f6f72646572c0fb86706f6c79676f6efa4e4867656f5f7368617065fb8770726f6772657373fa4e4564 6f75626c654f4873696e676c65746f6efb85737461747573fa4e43746578744f4873696e676c65746f6efbfbfbfbf986616c6961736573fafbfbfb} For elastic_admin.metadata table: • metadata: include settings, templates, customs, • owner: the host ID of the last update • version: metadata.version For indexed tables: • elastic_admin/<index_name>: index mapping and settings Strapdata 2017-2019 ©
14 . Snapshot schema.cql includes extensions Cassandra snapshots generates a schema.cql including table extensions CREATE TABLE IF NOT EXISTS strapkube.projects ( tenant_id uuid, project_name text, created timestamp, deleted timestamp, … PRIMARY KEY (tenant_id, project_name)) WITH ID = fa3bbde0-c28c-11e9-b27d-43cc1bfdc52e AND CLUSTERING ORDER BY (project_name ASC) … AND compaction = { 'max_threshold': '32', 'min_threshold': '4', 'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy' } AND compression = { 'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor' } AND cdc = false AND extensions = { ‘elastic_admin/projects': '3a290a05fa8770726f6a65637432fa8676657273696f6ec2847374617465436f70656e8773657474696e6773fa92696e6465782e6372656174696f6e5f64 6174654c313536373639383330373037338d696e6465782e6b6579737061 63654873747261706b75626592696e6465782e70726f76696465645f6e616d654770726f6a6563743289696e6465782e757569645572696f4e66537a3953646d5f72434538372d4355444194696e6465782e76657273696f6e2e637 265617465644636303230333939fb876d617070696e6773f8fa8770726f6a65637473fa8970726f70657274696573fa8e62696c6c696e675f70726f66696c65fa8374797065456e65737465648d63716c5f636f6c6c656374696f6e48736 96e676c65746f6e8b63716c5f7564745f6e616d655362696c6c696e675f70726f66696c655f747970654bfa8661646472657373fa4d466b6579776f72644e 4873696e676c65746f6efb8d62696c6c696e675f656d61696c73fa4d466b657 9776f72644e42736574fb86636f756e747279fa4d466b6579776f72644e4873696e676c65746f6efb836e616d65fa4d466b6579776f72644e4873696e676c 65746f6efb8a746563685f656d61696c73fa4d466b6579776f72644e4273657 4fb82766174fa4d45646f75626c654e4873696e676c65746f6efbfbfb8663726561746564fa4d43646174654e4873696e676c65746f6efb8664656c657465 64fa4d43646174654e4873696e676c65746f6efb8a6465736372697074696f6 efa4d466b6579776f72644e4873696e676c65746f6efb8c6d6f6e74686976657273617279fa4d46696e74656765724e4873696e676c65746f6efb8b70726f 6a6563745f6e616d65fa4d466b6579776f72644e4873696e676c65746f6e94 63716c5f7072696d6172795f6b65795f6f72646572c2fb8b736f757263655f6369647273fa4d456e65737465644e427365744f48636964725f747970654bf a50fa4d4169704e4873696e676c65746f6efb866e65746d61736bfa4d46696e 74656765724e4873696e676c65746f6efbfbfb8874656e616e745f6964fa4d466b6579776f72644e4873696e676c65746f6e9063716c5f706172746974696f6e5f6b6579235bc0fbfbfbfbf986616c6961736573fafbfbfb' }; Restoring a table also restore its Elasticsearch mapping. Strapdata 2017-2019 ©
15 . Elasticsearch dynamic mapping Elasticsearch Dynamic Mapping detects new indices, new fields dynamically: • Index template defines rules for new indices • Dynamic field mappings govern field detection • Dynamic templates are rules to configure the mapping for dynamically added fields Elasticsearch dynamic mapping is a great feature for logs ingestion Strapdata 2017-2019 ©
16 . ES Mapping updates involve schema update But wait, Cassandra dynamic schema is an anti-pattern ! Elassandra introduce batched schema change transaction Elassandra manage concurrent schema changes with a PAXOS transaction Strapdata 2017-2019 ©
17 . Mapping/Schema changes in Elassandra 1 What is Elassandra 2 Elasticsearch mapping management 3 Elassandra approach for schema changes 4 Conclusion Strapdata 2017-2019 ©
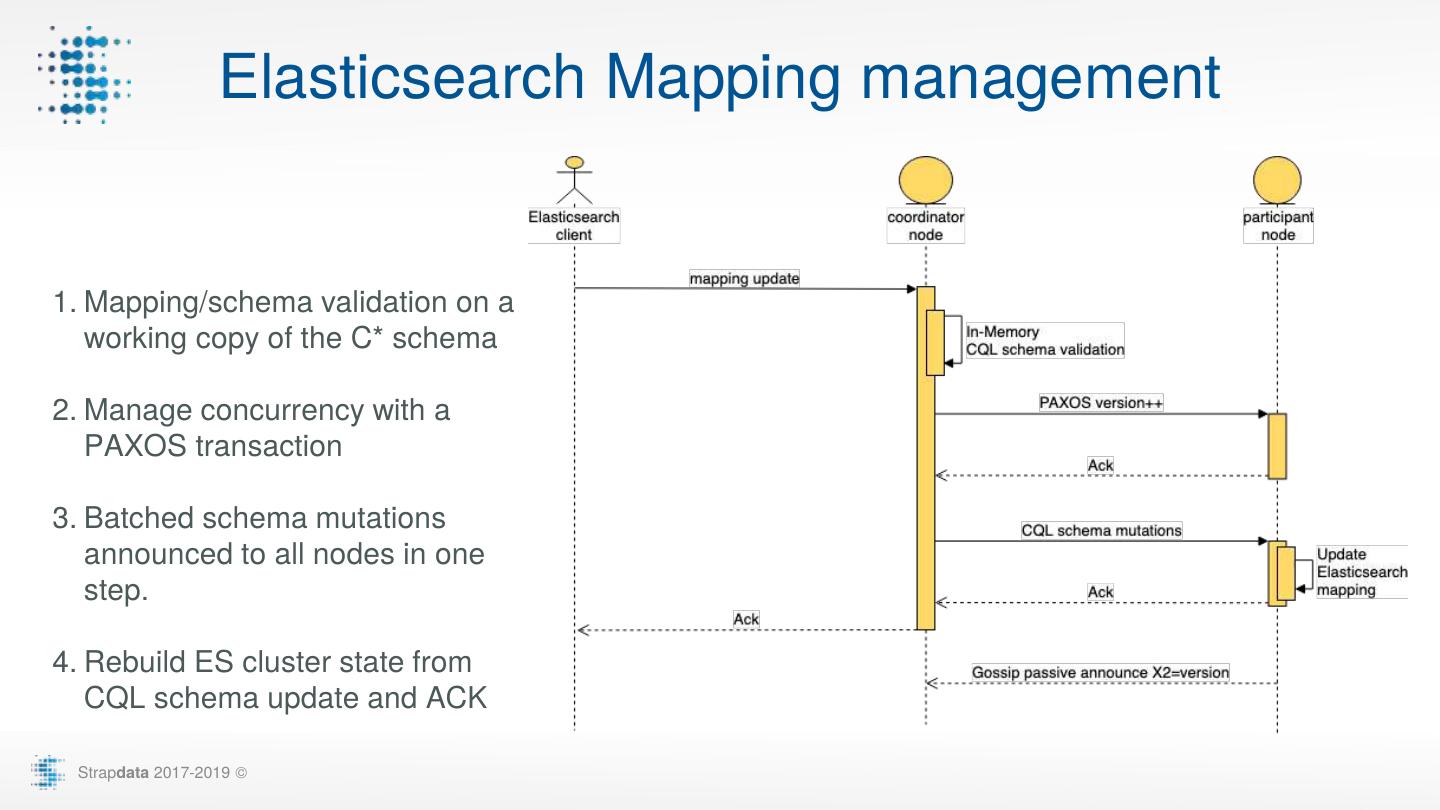
18 . Elasticsearch Mapping management 1. Mapping/schema validation on a working copy of the C* schema 2. Manage concurrency with a PAXOS transaction 3. Batched schema mutations announced to all nodes in one step. 4. Rebuild ES cluster state from CQL schema update and ACK Strapdata 2017-2019 ©
19 . Step 1 - Cassandra DDL Scripts Cassandra DDL scripts involve a schema change one each statement (=> MigrationStage++) CREATE TYPE A …. => announce to other nodes CREATE TYPE B…. => announce to other nodes CREATE TABLE my_table …. => failure Cassandra does not rollback if a DDL statement failed. Strapdata 2017-2019 ©
20 . Step 1 - Schema validation on a working copy Elasticsearch validate the DDL on a working copy: • Add copy() to Keyspace, Table, Type & View • In [CreatelAlter|Drop] [Table|Type] Statements, split validation and modification to work on a KeyspaceMetadata parameter. • The modification methods collect schema mutations done on the working copy. If validation or modification failed => give-up the working copy Strapdata 2017-2019 ©
21 . Step 2 - Concurrent CREATE TABLE issue 1/2 Simultaneously create a table one several nodes (ex: with csshx: admin@cqlsh> create table apachecon.t1 (a text primary key, b int); Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers. => Schema disagreement: # nodetool describecluster Cluster Information: Name: trial_cluster Snitch: org.apache.cassandra.locator.GossipingPropertyFileSnitch DynamicEndPointSnitch: enabled Partitioner: org.apache.cassandra.dht.Murmur3Partitioner Schema versions: 520692e4-64ab-3a59-9d23-e98ccf08f7ad: [10.0.24.5] 66d35f9c-d535-39ad-90c2-eaeb290d64bc: [10.0.24.4, 10.0.24.6] => Column family ID mismatch: 2019-09-08 12:55:23,613 ERROR [InternalResponseStage:28] MigrationTask.java:95 response Configuration exception merging remote s chema org.apache.cassandra.exceptions.ConfigurationException: Column family ID mismatch (found c5db2b20-d237-11e9-bfe3-e7b419aab59c; expected c5d6be50-d237-11e9- baa6-25d01efb136c) at org.apache.cassandra.config.CFMetaData.validateCompatibility(CFMetaData.java:947) at org.apache.cassandra.config.CFMetaData.apply(CFMetaData.java:901) at org.apache.cassandra.config.Schema.updateTable(Schema.java:703) at org.apache.cassandra.schema.SchemaKeyspace.updateKeyspace(SchemaKeyspace.java:1512) at org.apache.cassandra.schema.SchemaKeyspace.mergeSchema(SchemaKeyspace.java:1465) at org.apache.cassandra.schema.SchemaKeyspace.mergeSchema(SchemaKeyspace.java:1431) at org.apache.cassandra.schema.SchemaKeyspace.mergeSchemaAndAnnounceVersion(SchemaKeyspace.java:1403) at org.apache.cassandra.schema.SchemaKeyspace.mergeSchemaAndAnnounceVersion(SchemaKeyspace.java:1398) at org.apache.cassandra.service.MigrationTask$1.response(MigrationTask.java:91) at org.apache.cassandra.net.ResponseVerbHandler.doVerb(ResponseVerbHandler.java:53) Strapdata 2017-2019 ©
22 . Step 2 - Concurrent CREATE TABLE issue 2/2 A node has in-memory Column family ID different from the one actually in the CQL schema. => Cannot apply schema modification from other nodes => Schema diverge until the node reboot (or resetlocalschema) admin@cqlsh> alter table apachecon.table2 add c int; Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers. => CASSANDRA-10699 Make schema alterations strongly consistent, suggest usage of PAXOS => Concurrent Elasticsearch mapping in Elassandra are applied if a PAXOS update succeed => If PAXOS transaction is not applied, retry it on next cluster state update. Strapdata 2017-2019 ©
23 . Step 2 - Concurrent mapping changes Try PAXOS update on each mapping change UPDATE elastic_admin.metadata SET owner = <my_host_id>, version = N+1 WHERE cluster_name = ‘my_cluster’ IF version = N Strapdata 2017-2019 ©
24 . Step -3 Batched schema migration transaction 1.Schema mutations collected at step 1 are sent to all nodes => MigrationStage++ Strapdata 2017-2019 ©
25 . Step - 4 Rebuild mapping on schema update 1. Elassandra introduce transaction for schema migration public abstract class MigrationListener { /** * Start a schema merge transaction. * This helps to manage a batch of schema mutations together. */ public void onBeginTransaction() { } /** * End a schema merge transaction. */ public void onEndTransaction() { } 2. Add event public class listeners on begin/end migration MigrationManager { public void notifyBeginTransaction(Collection<MigrationListener> inhibitedListeners) { for (MigrationListener listener : listeners) if (!inhibitedListeners.contains(listener)) listener.onBeginTransaction(); } public void notifyEndTransaction(Collection<MigrationListener> inhibitedListeners) { for (MigrationListener listener : listeners) if (!inhibitedListeners.contains(listener)) listener.onEndTransaction(); } Strapdata 2017-2019 ©
26 . Step - 4 Rebuild mapping on schema update 1. An Elasticsearch SchemaListener rebuild the mapping on mergeSchema() private static synchronized void mergeSchema(Keyspaces before, Keyspaces after, Collection<MigrationListener> inhibitedListeners) { // notify begin of schema update transaction. MigrationManager.instance.notifyBeginTransaction(inhibitedListeners); MapDifference<String, KeyspaceMetadata> keyspacesDiff = before.diff(after); // dropped keyspaces for (KeyspaceMetadata keyspace : keyspacesDiff.entriesOnlyOnLeft().values()) { … } // new keyspaces for (KeyspaceMetadata keyspace : keyspacesDiff.entriesOnlyOnRight().values()) { … } // updated keyspaces for (Map.Entry<String, MapDifference.ValueDifference<KeyspaceMetadata>> diff : keyspacesDiff.entriesDiffering().entrySet()) updateKeyspace(diff.getKey(), diff.getValue().leftValue(), diff.getValue().rightValue()); // notify begin of schema update transaction. MigrationManager.instance.notifyEndTransaction(inhibitedListeners); } 2. Publish the new Elasticsearch cluster state with the new metadata.version and acknowledge the coordinator node (Elasticseach messaging) => Faster than the passive gossip announce done every seconds Strapdata 2017-2019 ©
27 . Mapping/Schema changes in Elassandra 1 What is Elassandra 2 Elasticsearch mapping management 3 Elassandra approach for schema changes 4 Conclusion Strapdata 2017-2019 ©
28 . Benefits • Elasticsearch is properly saved in the CQL schema => Elasticsearch can starts before replaying commit logs or stream data. • Concurrent mapping is protected by PAXOS LWT. • Complex mapping generates only one schema mutation. • You create a dummy index if you need to safely create a tables, types…. Strapdata 2017-2019 ©
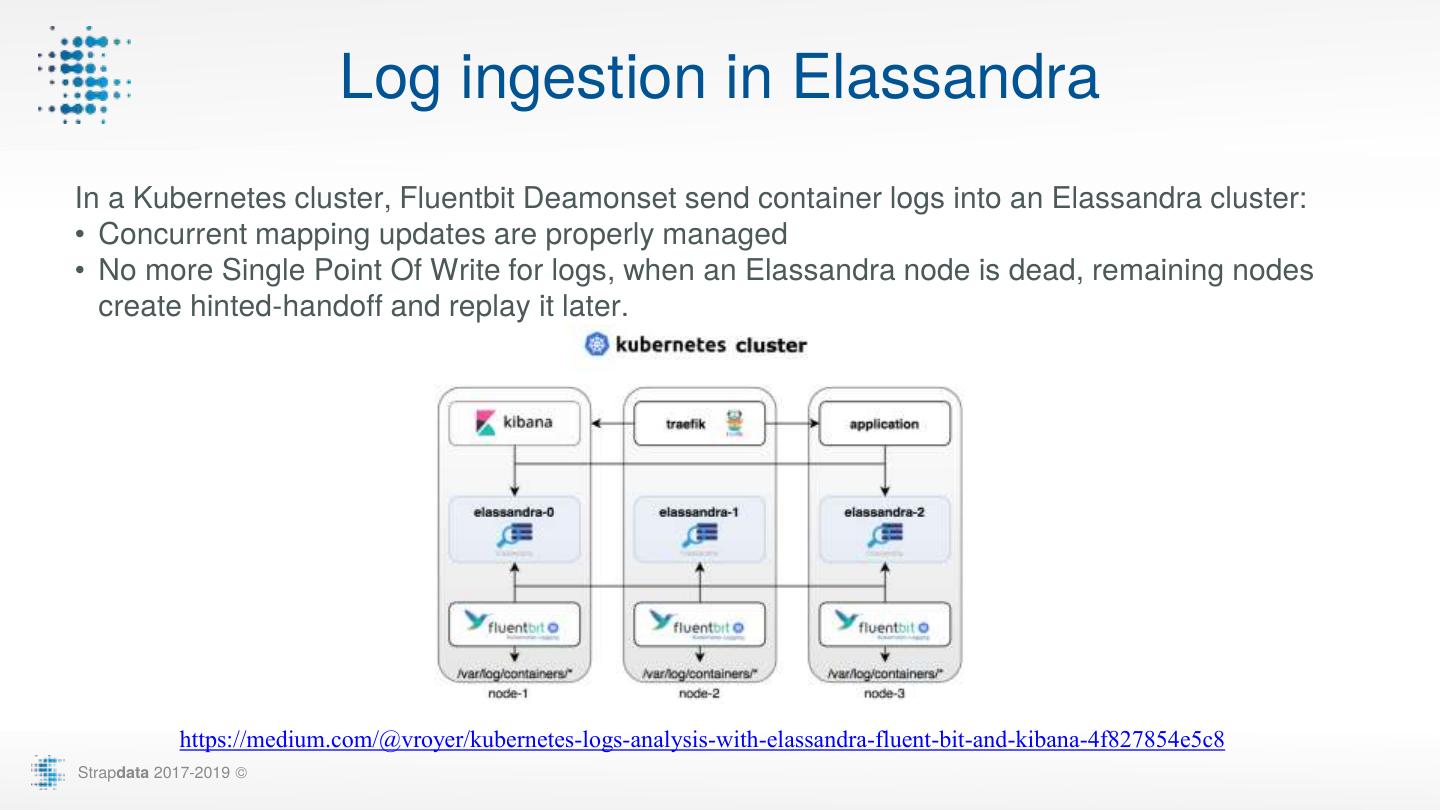
29 . Log ingestion in Elassandra In a Kubernetes cluster, Fluentbit Deamonset send container logs into an Elassandra cluster: • Concurrent mapping updates are properly managed • No more Single Point Of Write for logs, when an Elassandra node is dead, remaining nodes create hinted-handoff and replay it later. https://medium.com/@vroyer/kubernetes-logs-analysis-with-elassandra-fluent-bit-and-kibana-4f827854e5c8 Strapdata 2017-2019 ©
3秒后跳转登录页面
去登陆

