展开查看详情
1 .The Global Media Platform
Cassandra
To Infinity And Beyond
Romain Hardouin
Senior Cloud Infrastructure Engineer
�
2 .Cassandra @ Teads
About Teads
Workload
Infrastructure
Ops
Monitoring & Alerting
Data model
Why a fork?
�
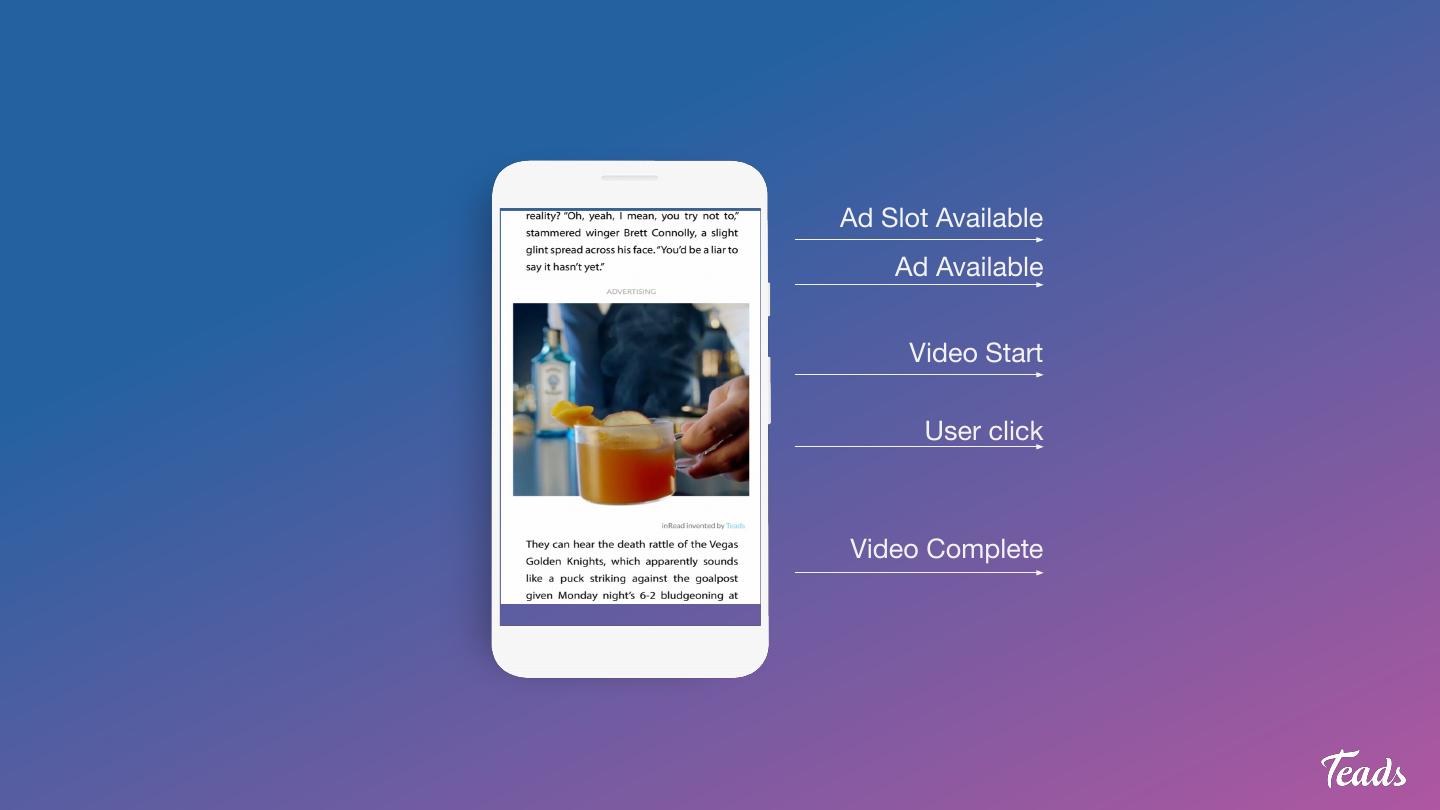
5 .Ad Slot Available
Ad Available
Video Start
User click
Video Complete
�
6 . French AdTech
AWS / GCP
Scala / JS / Go
Machine learning
Docker / CoreOS
Terraform / Chef / Debian
Cassandra / Kafka / MySQL / Redis
Spark / Flink
�
8 . Workload
Different kinds of workloads
but all of them are latency sensitive
Internet scale
Massive amount of data ingested from partners
We also create lots of data by ourselves
No more analytics
● Tons of business critical counters
● Time series
● TTL, TTL, TTL
�
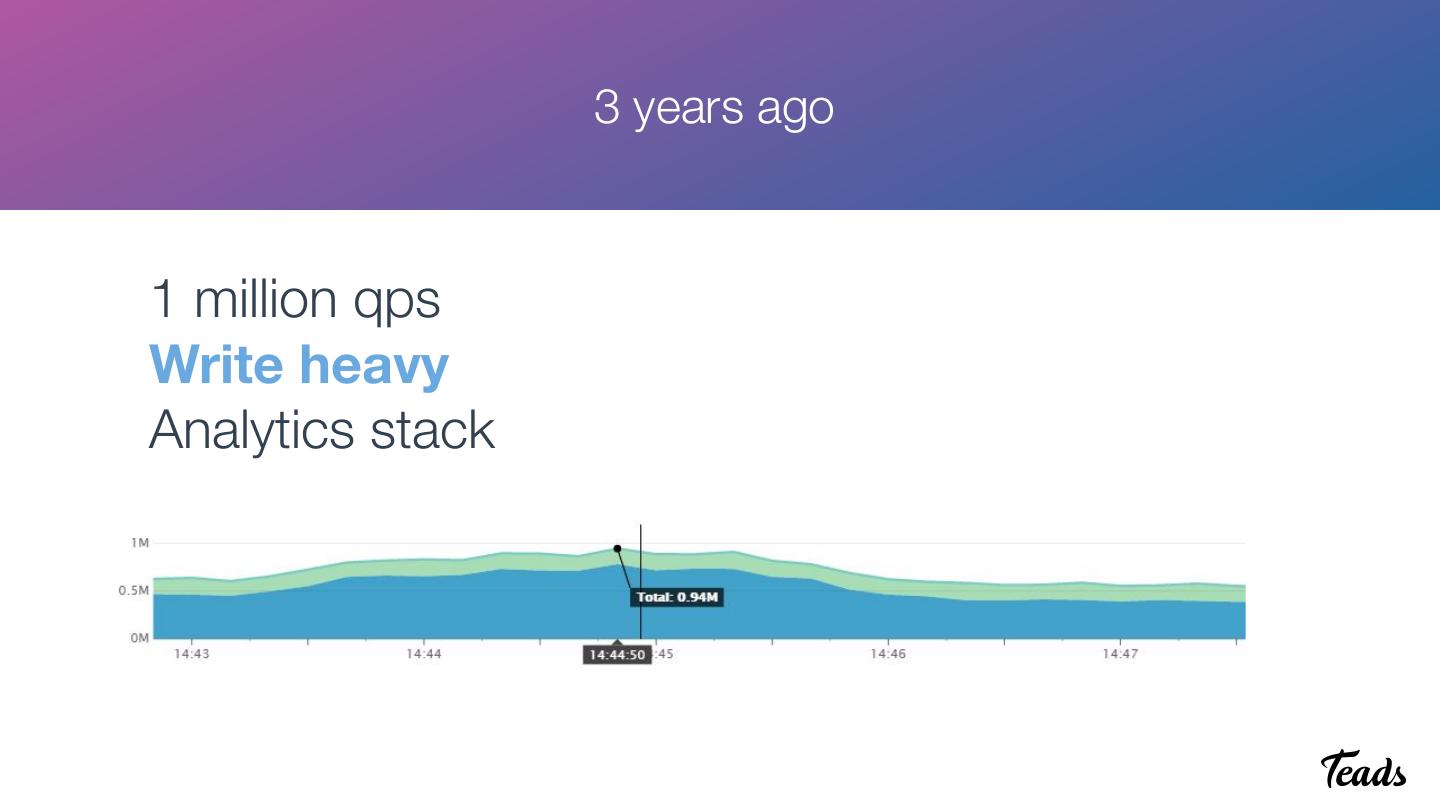
9 . 3 years ago
1 million qps
Write heavy
Analytics stack
�
10 . Now
+2 millions qps
Read heavy…
�
11 . Now
...but also lots of streamed SSTables
not counted as writes
�
13 .Gimme some figures!
250 nodes 3 regions
Mostly ephemeral data Regional vs Worldwide
28 TB
21 DCs
100 billions keys
�
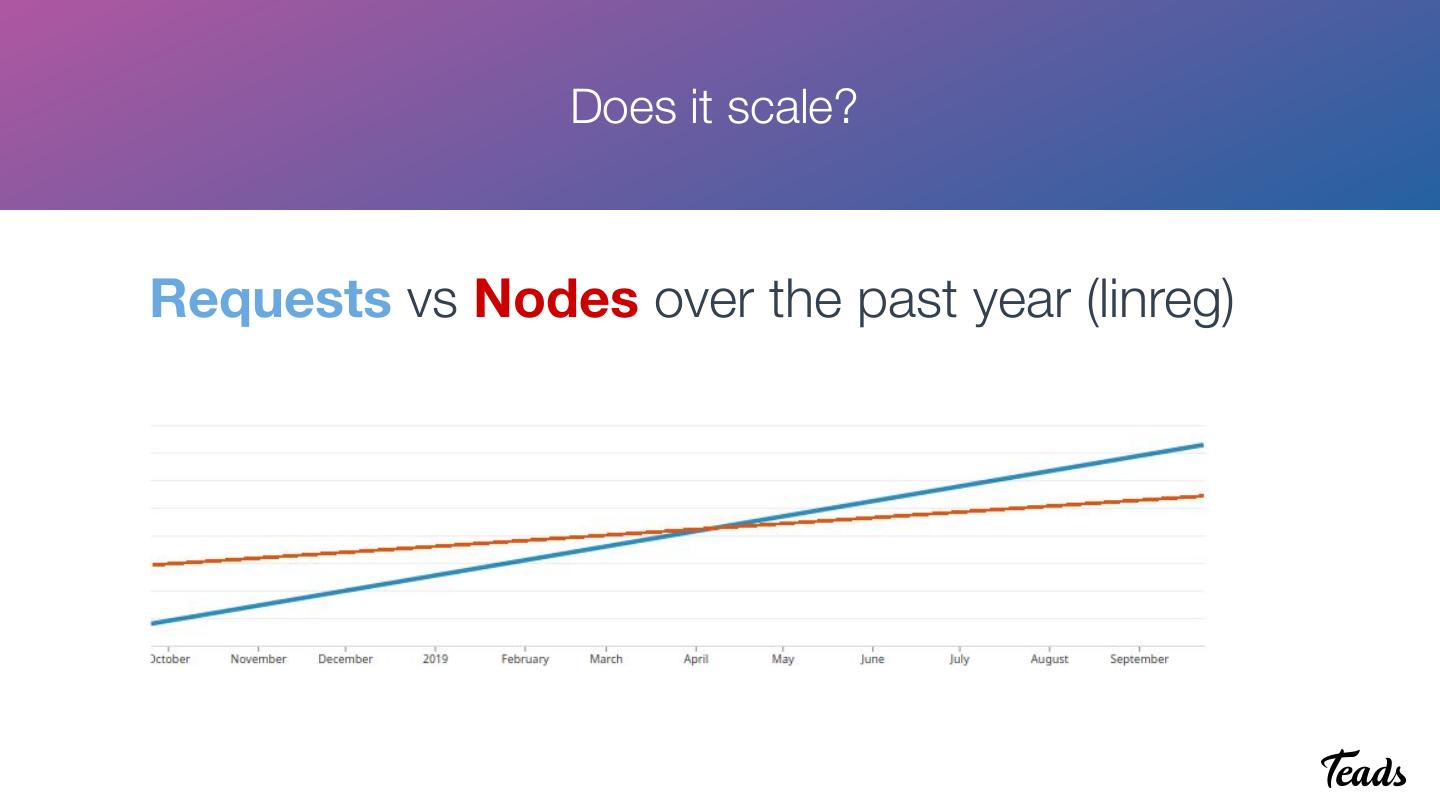
14 . Does it scale?
Requests vs Nodes over the past year (linreg)
�
16 .AWS instances
c5d.4xlarge
16 vCPU @ 3.00GHz
32 GB RAM
400 GB NVMe
�
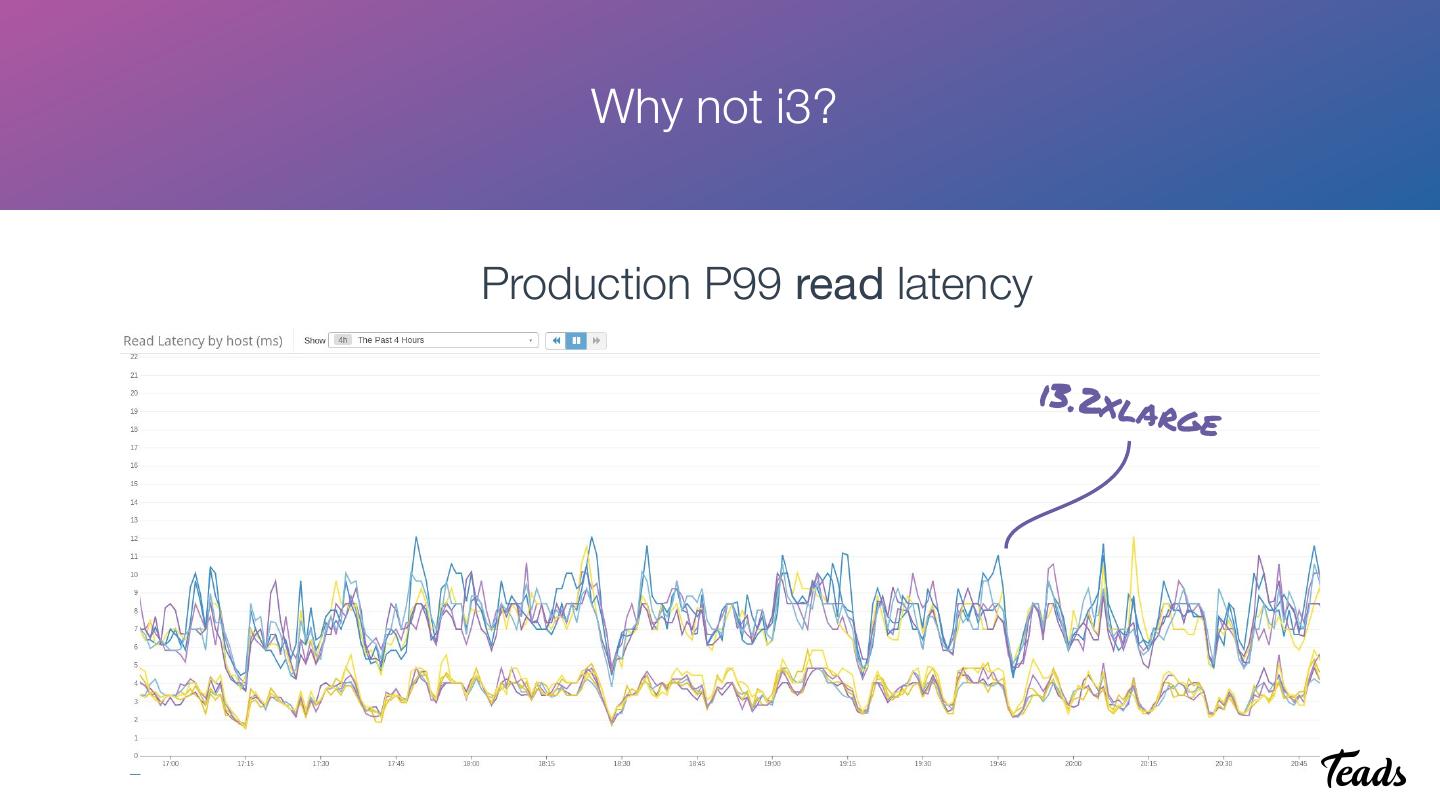
17 . Why not i3?
Production P99 read latency
i3.2xl
arge
�
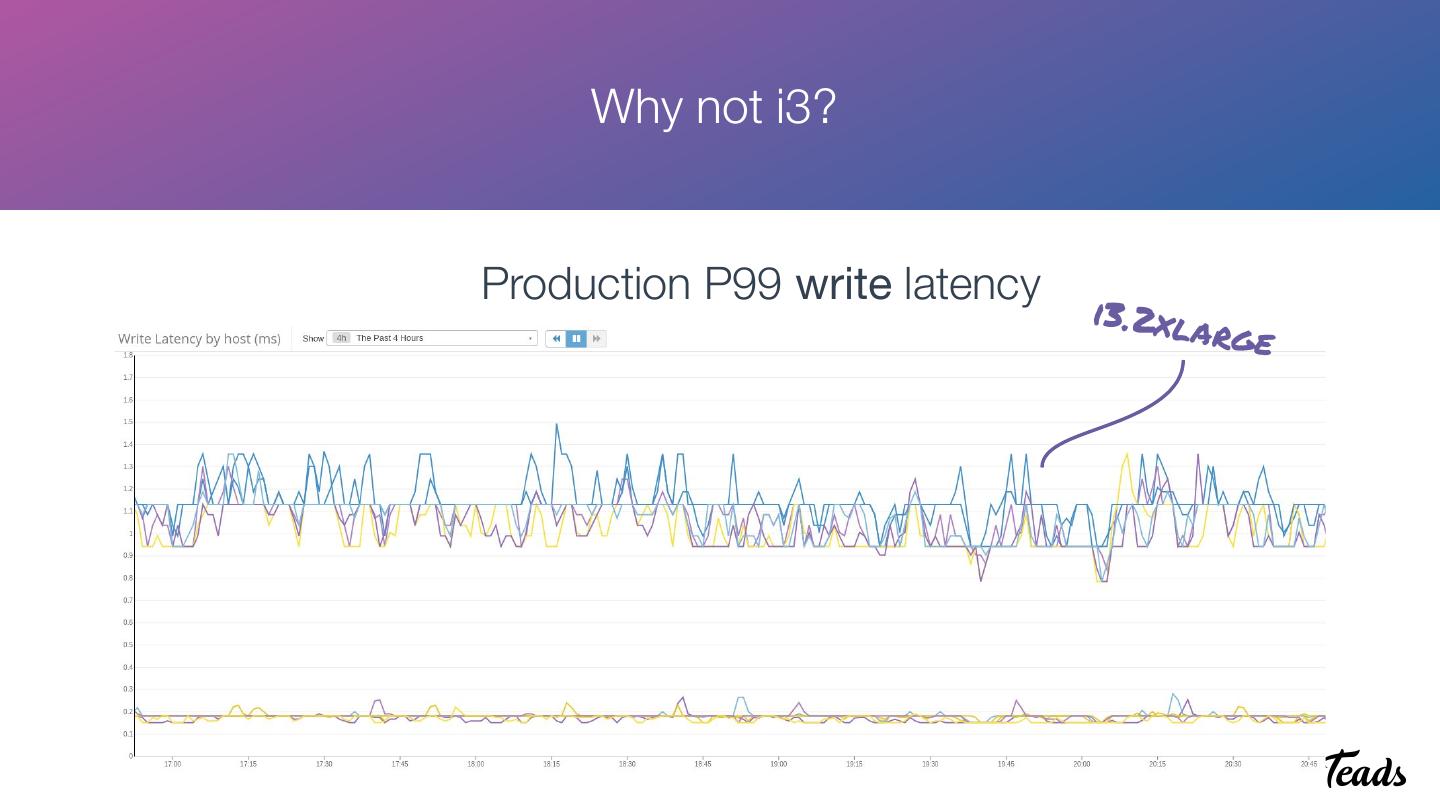
18 . Why not i3?
Production P99 write latency
i3.2xl
arge
�
19 .Why not EBS?
No more EBS
Cheap storage, great for STCS
Snapshots (S3 backup)
No coupling between disks and CPU/RAM
High latency, high I/O wait
Throughput: 160 MB/s
Unsteady performances
�
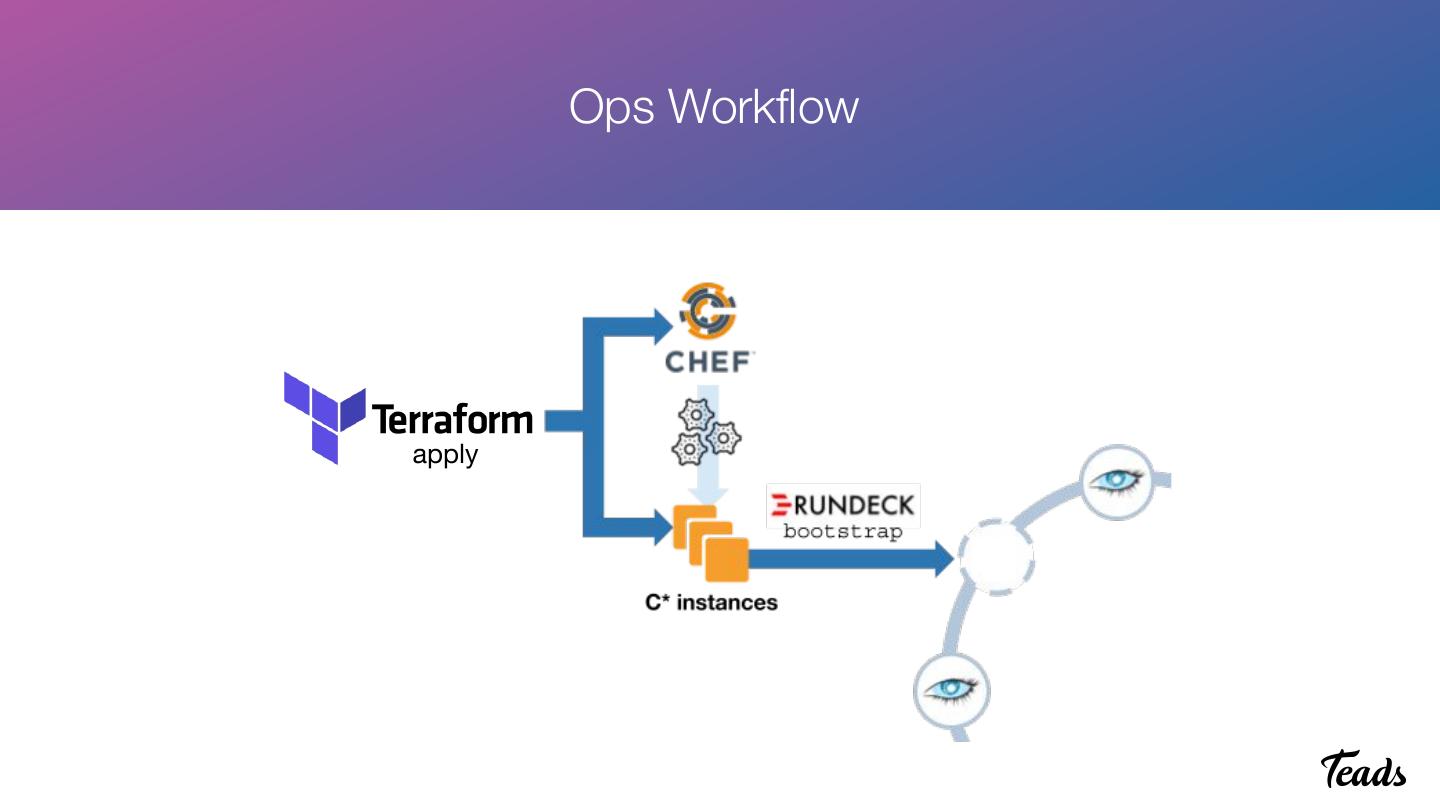
21 . Ops Workflow
e o u t
Scal n
a l e i
S c n g es
h a
Any c
More on https://medium.com/teads-engineering/easy-cassandra-scaling-with-terraform-chef-rundeck-9443e0375aa7
�
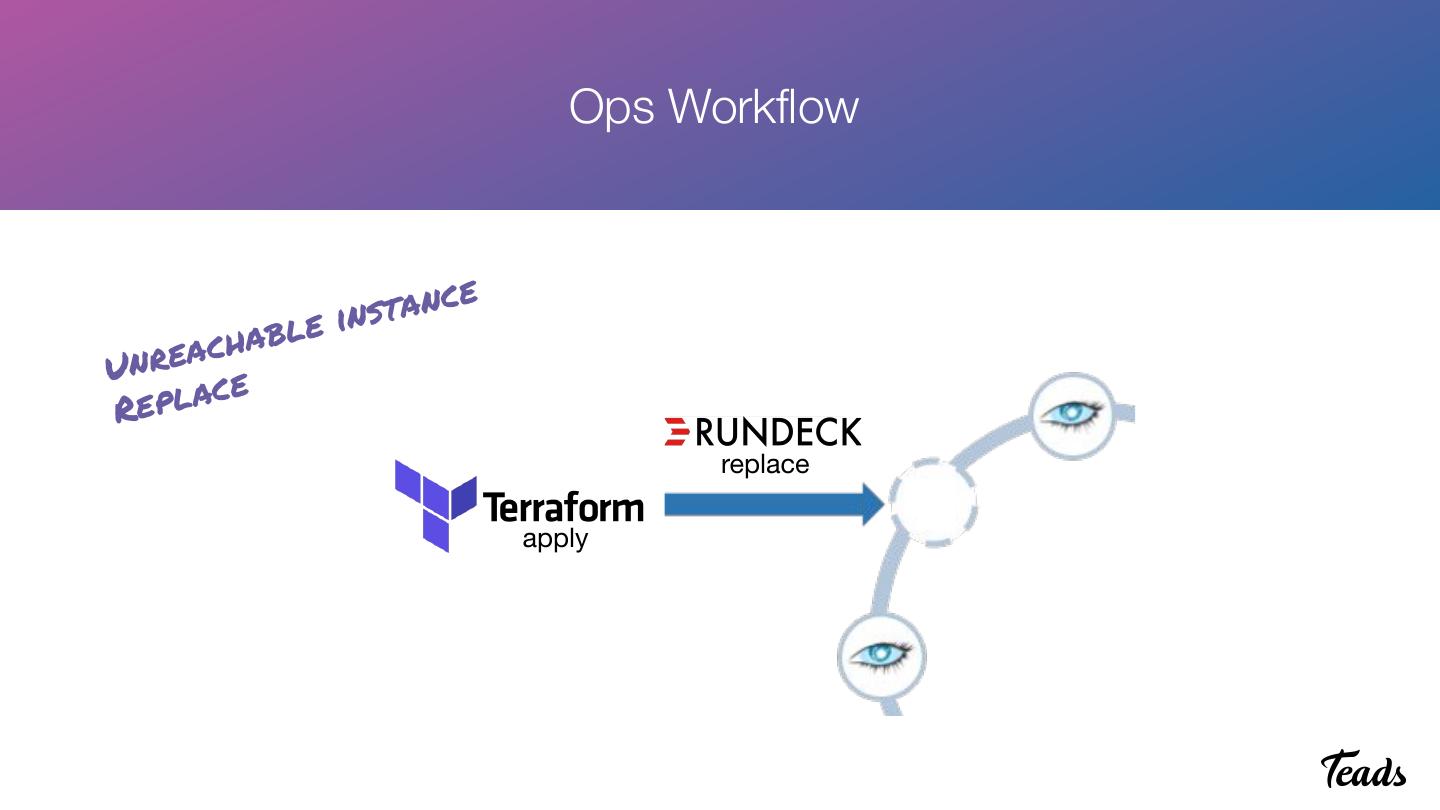
23 . Ops Workflow
t a n ce
b l e ins
e a c ha
Unr
e p l a ce
R
replace
apply
�
24 .Repair
No incremental repair
Scheduled with Reaper
http://cassandra-reaper.io
�
25 .Monitoring & Alerting
�
26 . Monitoring
Overview dashboards
Advanced dashboards for troubleshooting
Alerting dashboards
Outliers
Compare a node to average
Compare 3 DCs (multi regions)
�
27 . Monitoring
Ratio cross DCs/Clusters to grasp workloads
Examples:
● R/W Spread: ( (maxqps-minqps)/maxqps)*100
● P99/95 jitter factor: ( P99 - P95 ) / P99
● Memory cached / disk ratio
�
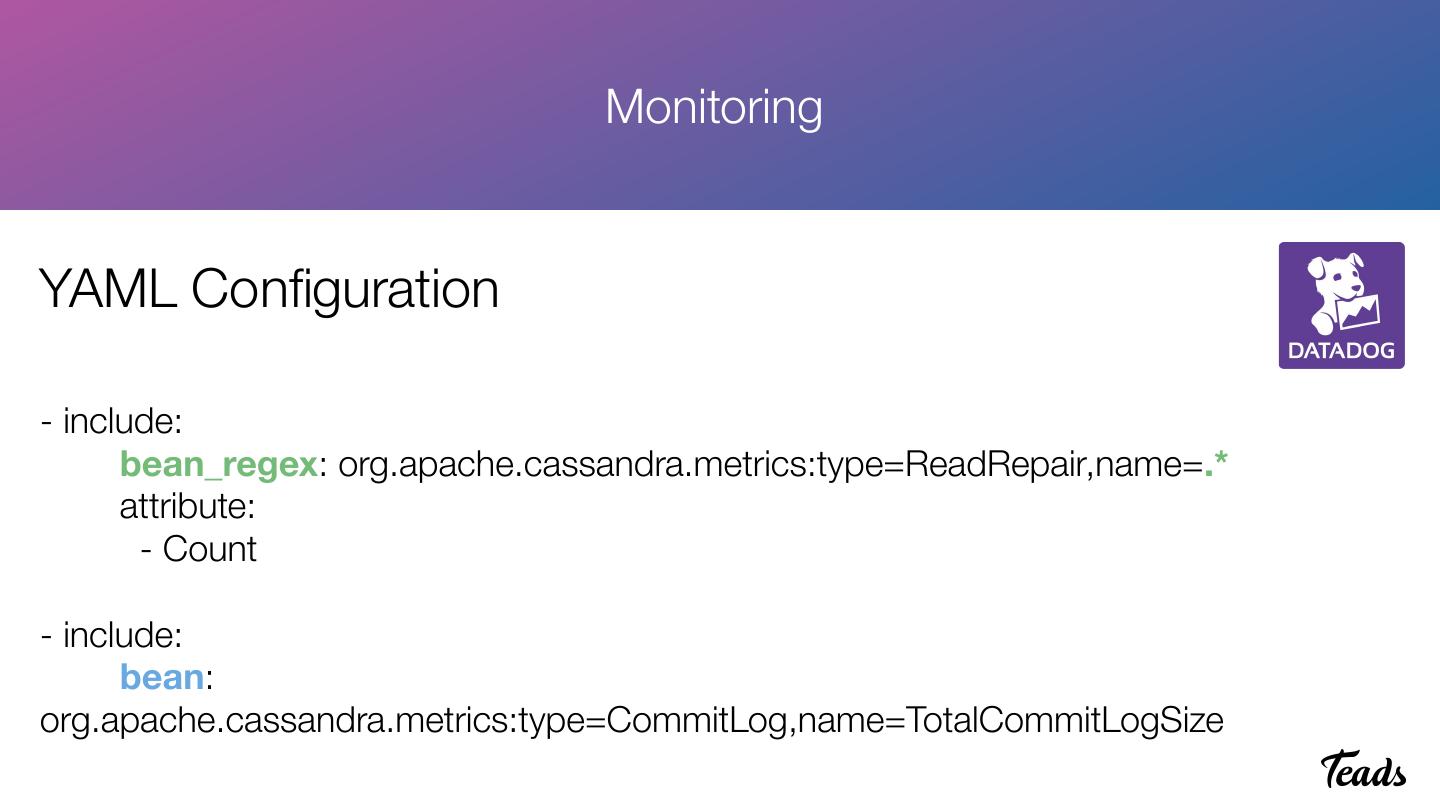
28 . Monitoring
YAML Configuration
- include:
bean_regex: org.apache.cassandra.metrics:type=ReadRepair,name=.*
attribute:
- Count
- include:
bean:
org.apache.cassandra.metrics:type=CommitLog,name=TotalCommitLogSize
�
29 . Alerting
Down node
Exceptions
Commitlog size
High latency
High pendings tasks
Many hints
Clock out of sync
IO Wait
Disk space
...
�