展开查看详情
1 .Getting started with Apache
Cassandra and Python
By
Adnan Siddiqi
(http://adnansiddiqi.me)
�
2 . What is Apache Cassandra?
• According to Wikipedia:
Apache Cassandra is a free and open-source,
distributed, wide column store, NoSQL database
management system designed to handle large
amounts of data across many commodity servers,
providing high availability with no single point of
failure. Cassandra offers robust support for
clusters spanning multiple datacenters,[1] with
asynchronous masterless replication allowing low
latency operations for all clients.
�
3 . History
• Developed by two Facebook engineers to deal
with search mechanism of Inbox.
• Released as an open-source project after few
years.
• Handed over to Apache Foundation.
�
4 . Companies using Cassandra
• Apple
• Netflix
• eBay
• Weather Channel
�
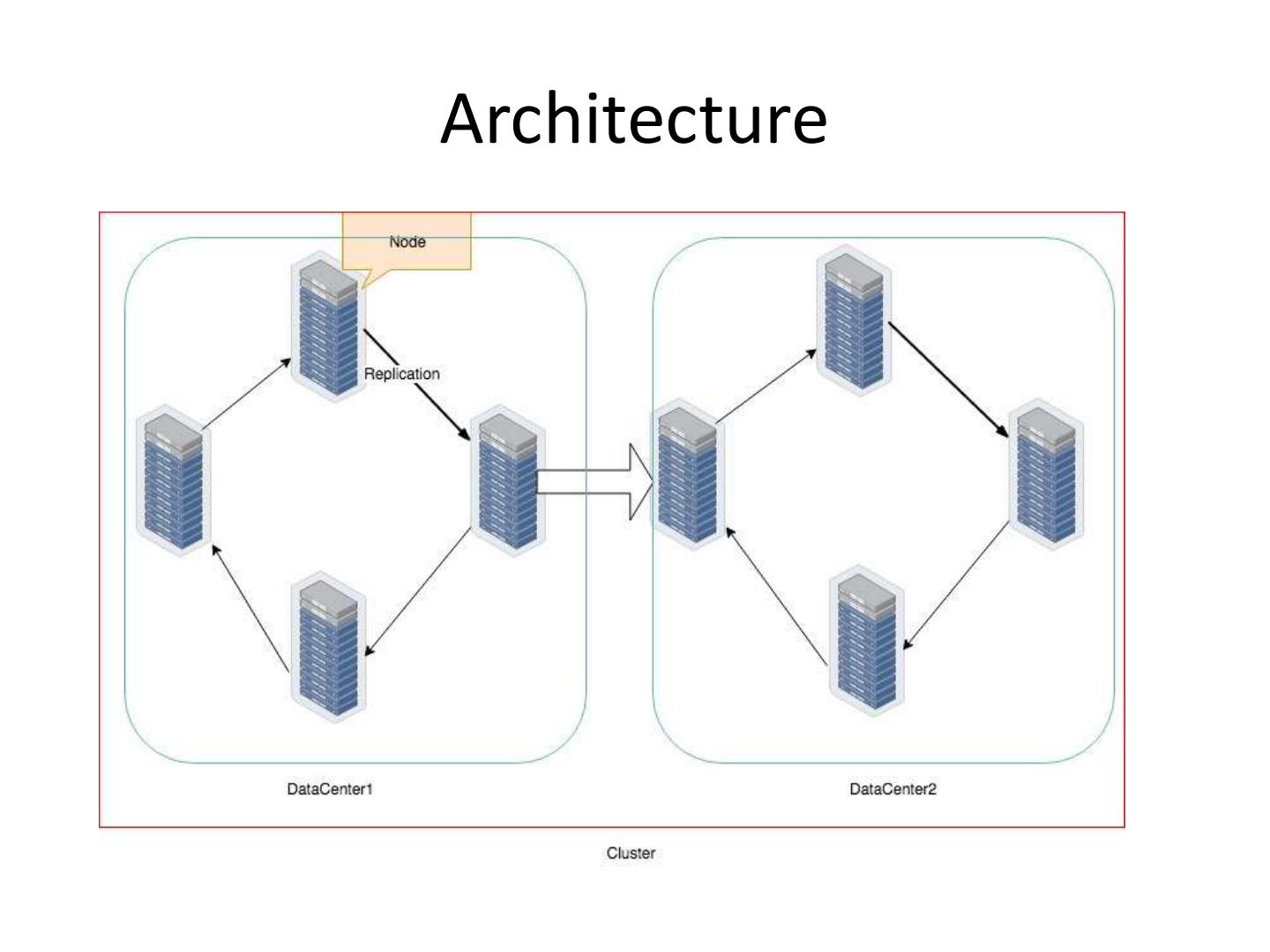
6 . Architecture(Contd…)
• Node:- The basic component of the data, a
machine where the data is stored.
• Datacenter:- A collection of related nodes. It
can be a physical datacenter or virtual.
• Cluster:- A cluster contains one or more
datacenters, it could span across locations.
• Commit Log:- Every write operation is first
stored in the commit log. It is used for crash
recovery.
�
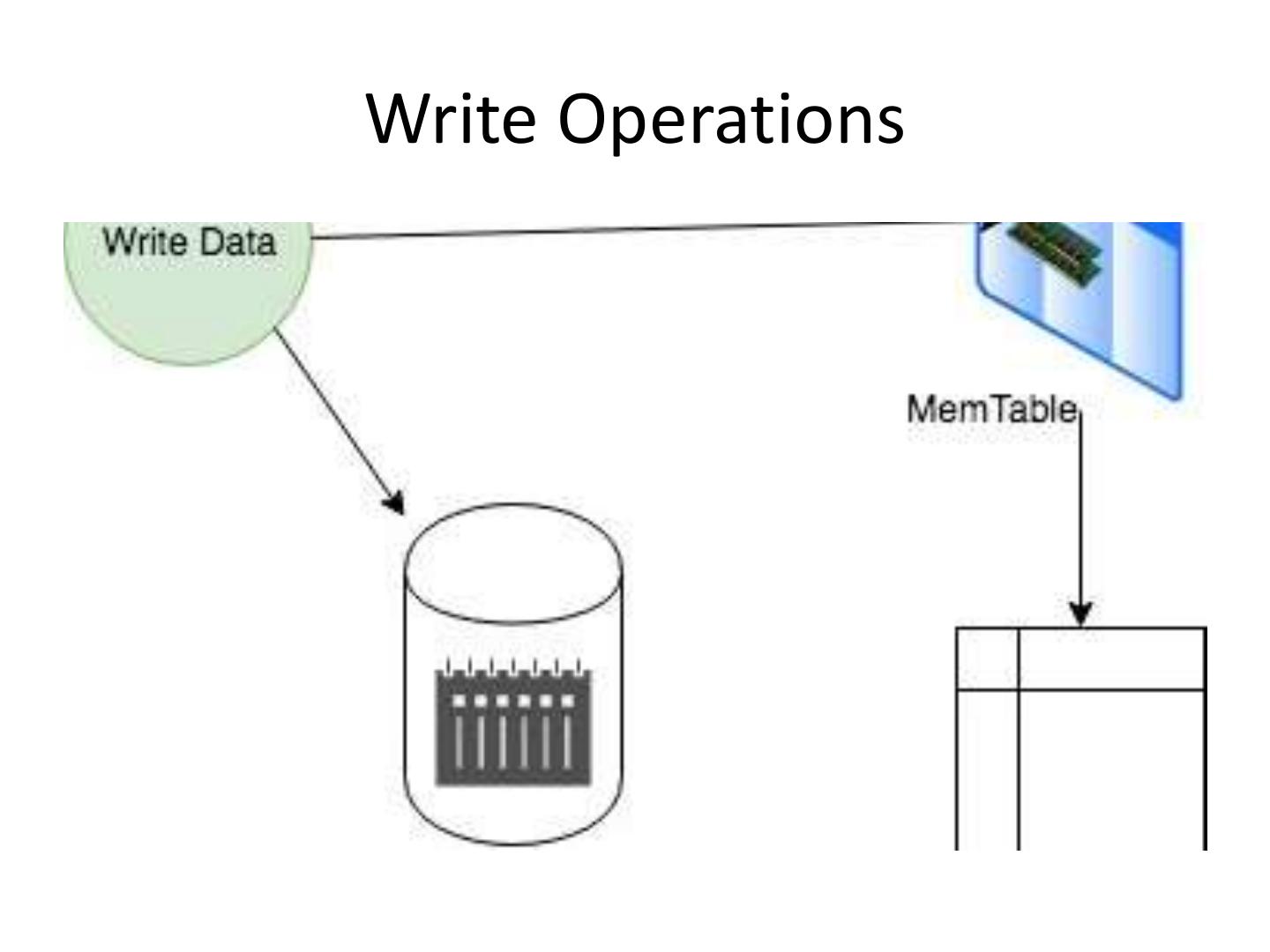
7 . Architecture(Contd…)
• Mem-Table:- After data is written to the
commit log it then is stored in Mem-
Table(Memory Table) which remains there till
it reaches to the threshold.
• SSTable:- Sorted-String Table or SSTable is a
disk file which stores data from MemTable
once it reaches to the threshold. SSTables are
stored on disk sequentially and maintained for
each database table.
�
9 . Write Operations(Contd…)
• Write request is stored in both CommitLog to
make sure that data is saved.
• Data is written in Memtable which holds data
till it reaches to threshold.
• Data is flused to SSTable once Memtable
reaches to its threshold.
• The node that accepts requests called
Coordinator.
�
10 . Read Operations
• Direct Request:- The coordinator node sends
the read request to one of the replicas.
• Digest:- The coordinator contacts the replicas
specified by the consistency level. The
contacted nodes respond with a digest
request of the required data. Comparison
takes place to make sure that the update data
is sent back.
�
11 . Replication Strategies
• Simple Strategy
• Network Topology
�
12 . Simple Strategy
• It is used when you have only one data center.
It places the first replica on the node selected
by the partitioner. A partitioner determines
how data is distributed across the nodes in the
cluster (including replicas). After that,
remaining replicas are placed in a clockwise
direction in the Node ring.
�
13 .Simple Strategy(Contd…)
�
14 . Network Topology Strategy
• Deployments across multiple Datacenters.
• This strategy places replicas in the same
datacenter by traversing the ring clockwise
until reaching the first node in another rack.
• This strategy is highly recommended for
scalability purpose and future expansion.
�
15 .Network Topology Strategy(Contd…)
�
16 . Installation and Setup
• Dockerized Version.
• docker pull cassandra
• Make sure to set the Docker memory to 4GB
atleast to avoid 137 exit error code.
�
17 . Installation and Setup(Contd…)
• data docker exec -it cas1
nodetool status
�
20 .Cassandra Data Modeling
�
21 .Cassandra Data Modeling
�
22 . Cassandra Data Modeling
• Keyspace:- It is the container collection of
column families. You can think of it as a
Database in the RDBMS world.
• Column Family:- A column family is a
container for an ordered collection of rows.
Each row, in turn, is an ordered collection of
columns. Think of it as a Table in the RDBMS
world.
�
23 .Cassandra Data Modeling(Contd…)
�
24 .Cassandra Data Modeling(Contd…)
�
25 . Creating KeySpace
• Creating Keyspace with name CityInfo.
• create keyspace CityInfo with
replication = {'class' :
'SimpleStrategy',
'replication_factor':2}
�
26 . Designing Modeling Goals
• Evenly spread of data in a cluster.
• Minimize the number of Reads.
�
29 . Cassandra and Python
• pip install cassandra-driver
�