


























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
18/12 - SASI, Cassandra on the full text search ride - Apache Bi
主要介绍 SASI的全文索引
展开查看详情
1 .SASI, Cassandra on the full text search ride DuyHai DOAN – Apache Cassandra™ Evangelist
2 .1 5 minutes introduction to Apache Cassandra™ 2 SASI introduction 3 SASI cluster-wide 4 SASI local read/write path 5 Query planner 6 Some benchmarks 7 Take away 2 @doanduyhai
3 .Trademark Policy From now on … Cassandra ⩵ Apache Cassandra™ 3 @doanduyhai
4 .5 minutes introduction to Apache Cassandra™ @doanduyhai
5 .The tokens Random hash of #partition à token = hash(#p) C* C* Hash: ] –x, x ] C* C* hash range: 264 values x = 264/2 C* C* C* C* 5 @doanduyhai
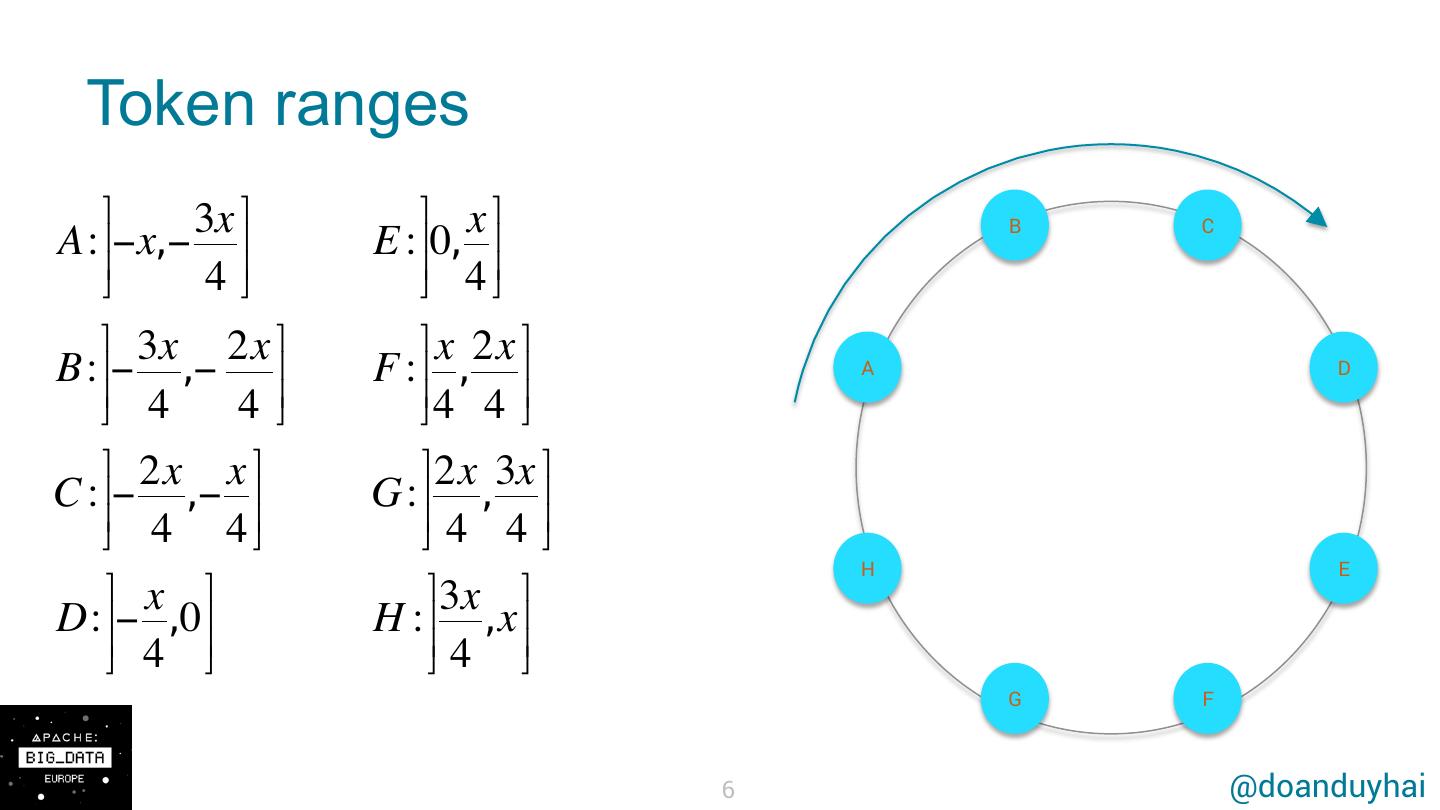
6 . Token ranges ⎤ 3x ⎤⎥ ⎤ x ⎤⎥ B C A: ⎥−x,− ⎥ ⎥ E : ⎥0, ⎥ ⎥ ⎦ 4⎦ ⎦ 4⎦ ⎤ 3x 2x ⎤⎥ ⎤ x 2x ⎤⎥ B: ⎥⎥− ,− F :⎥ , ⎥ ⎥ A D ⎦ 4 4 ⎥⎦ ⎦4 4 ⎦ ⎤ 2x x ⎤ ⎤ 2x 3x ⎤ C : ⎥⎥− ,− ⎥⎥ G : ⎥⎥ , ⎥⎥ ⎦ 4 4⎦ ⎦ 4 4 ⎦ H E ⎤ x ⎤⎥ ⎤ 3x ⎤⎥ D: ⎥− ,0 ⎥ ⎥ H : ⎥ ,x ⎥ ⎥ ⎦ 4 ⎦ ⎦ 4 ⎦ G F 6 @doanduyhai
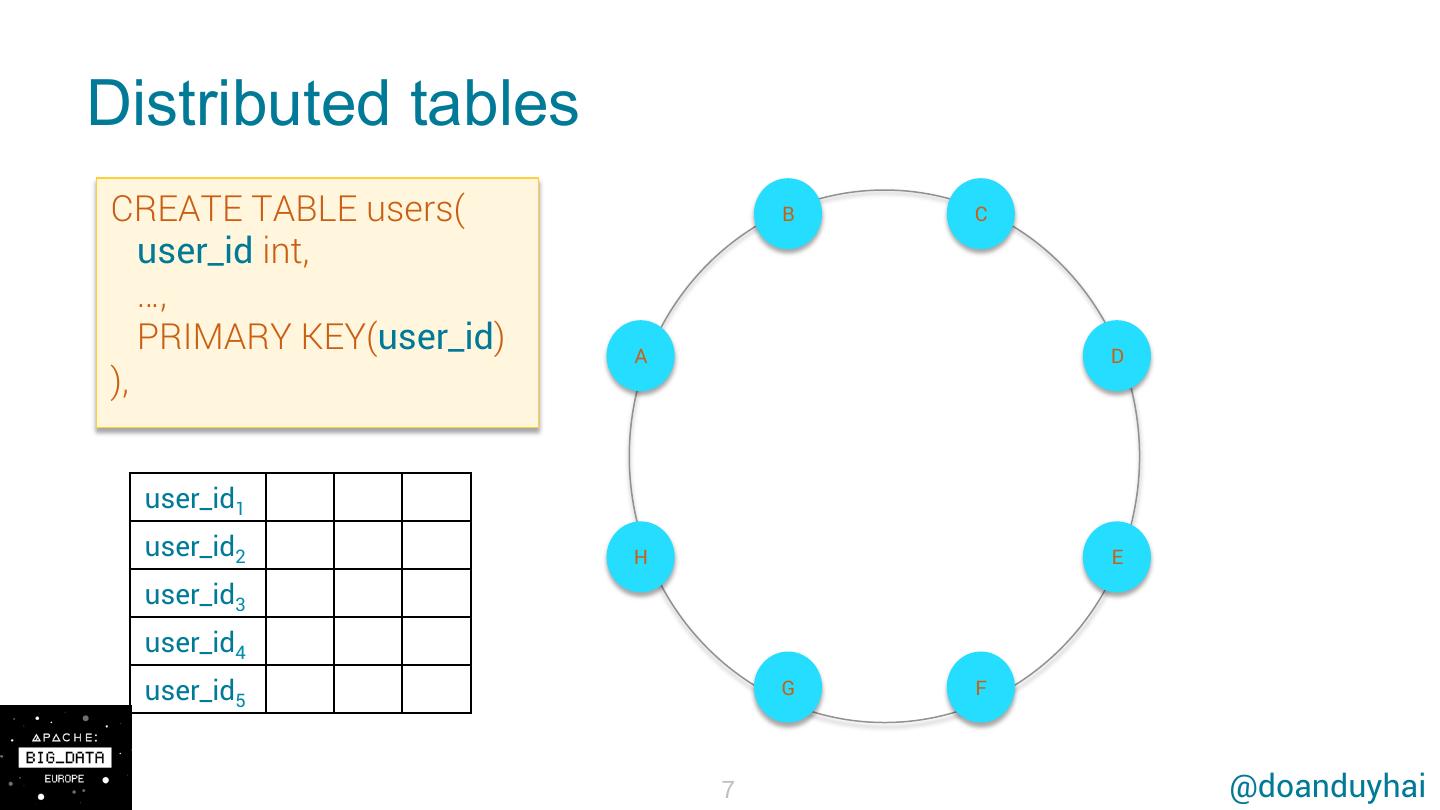
7 .Distributed tables CREATE TABLE users( B C user_id int, …, PRIMARY KEY(user_id) A D ), user_id1 user_id2 H E user_id3 user_id4 user_id5 G F 7 @doanduyhai
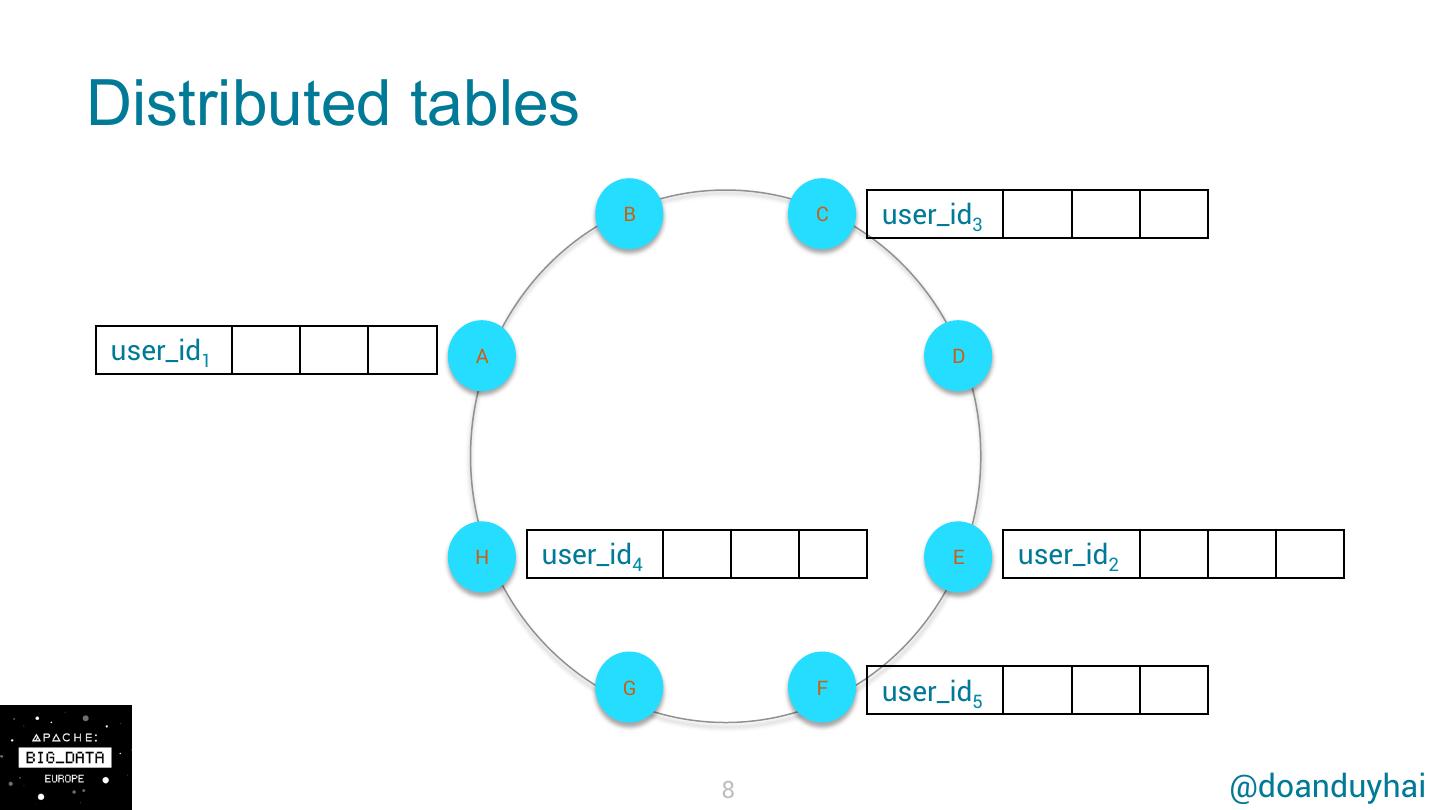
8 .Distributed tables B C user_id3 user_id1 A D H user_id4 E user_id2 G F user_id5 8 @doanduyhai
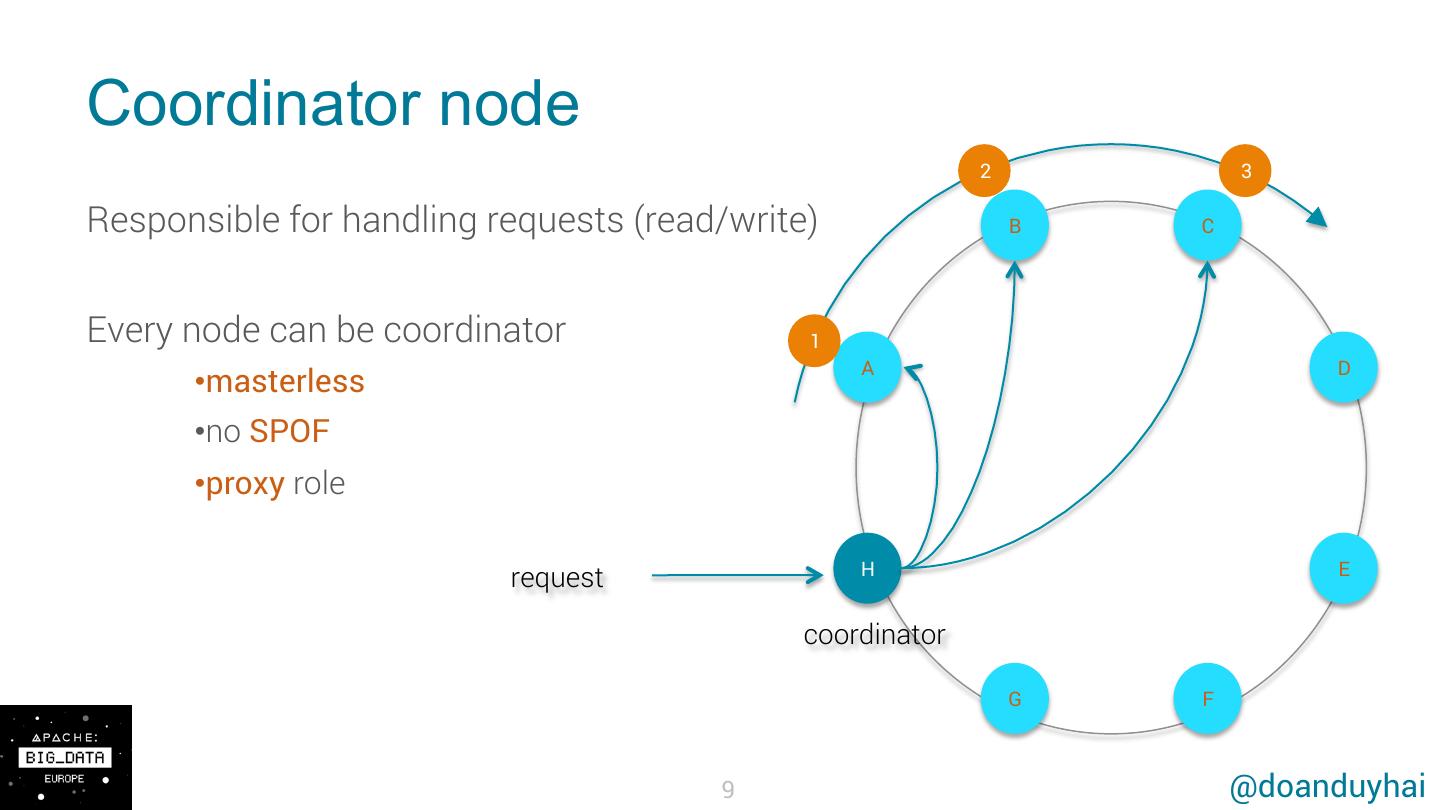
9 .Coordinator node 2 3 Responsible for handling requests (read/write) B C Every node can be coordinator 1 A D •masterless •no SPOF •proxy role H E request coordinator G F 9 @doanduyhai
10 .!" Q&A 10 @doanduyhai
11 .SASI introduction @doanduyhai
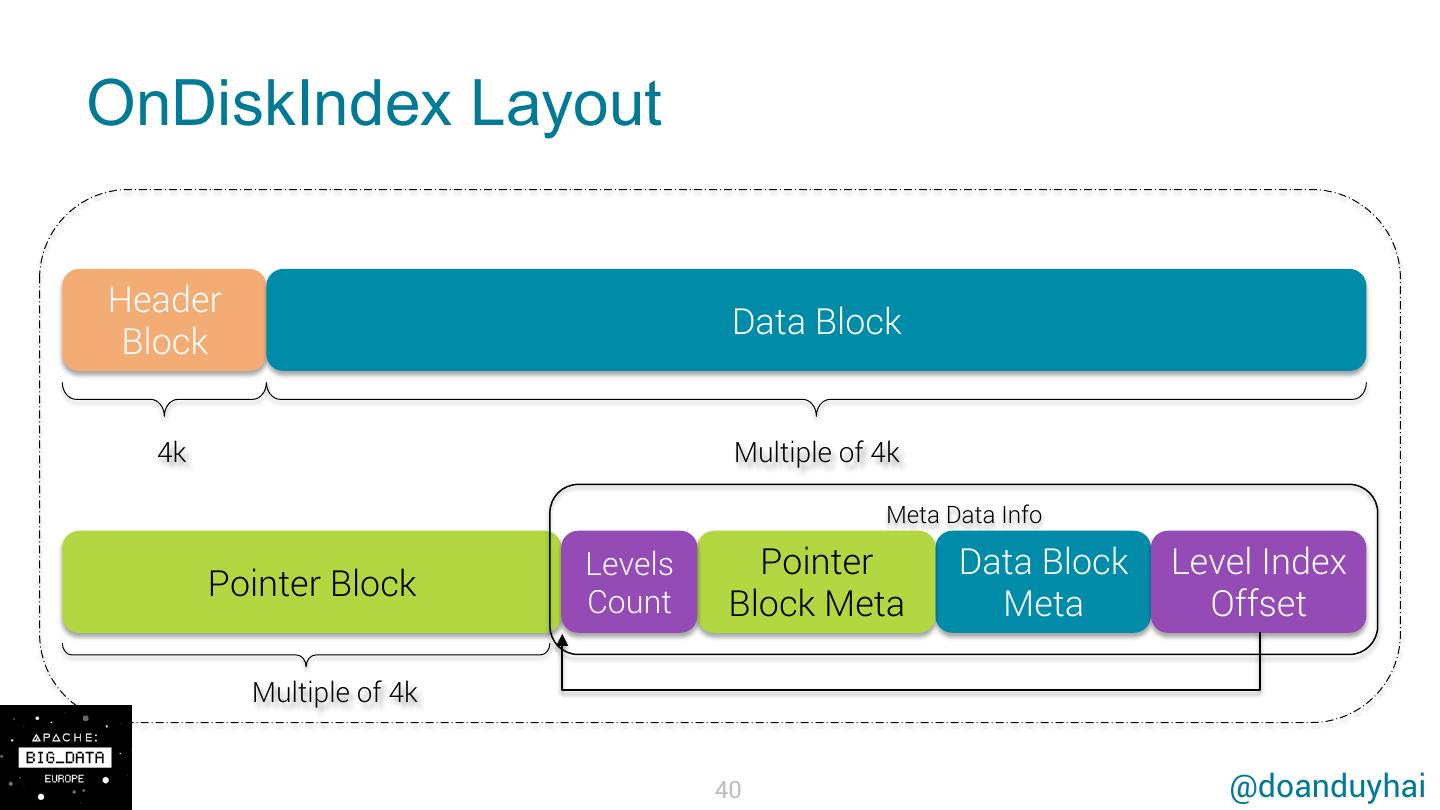
12 .What is SASI ? • SSTable-Attached Secondary Index à new 2nd index impl that follows SSTable life-cycle • Objective: provide more performant & capable 2nd index 12 @doanduyhai
13 .Who created it ? Open-source contribution by an engineers team 13 @doanduyhai
14 .Why is it better than native 2nd index ? • follow SSTable life-cycle (flush, compaction, rebuild …) à more optimized • new data-strutures • range query (<, ≤, >, ≥) possible • full text search options 14 @doanduyhai
15 .Demo 15 @doanduyhai
16 .SASI cluster-wide @doanduyhai
17 . Distributed index On cluster level, SASI works exactly like native 2nd index B C UK user87 user176 … user987 A D UK user1 user102 … user493 US user54 user483 … user938 UK user17 user409 … user787 H E G F 17 @doanduyhai
18 .Distributed search algorithm B C A D 1st round Concurrency factor = 1 H E coordinator G F 18 @doanduyhai
19 .Distributed search algorithm B C A D Not enough results ? H E coordinator G F 19 @doanduyhai
20 .Distributed search algorithm B C 2nd round Concurrency factor = 2 A D H E coordinator G F 20 @doanduyhai
21 .Distributed search algorithm B C A D Still not enough results ? H E coordinator G F 21 @doanduyhai
22 .Distributed search algorithm B C A D 3rd round Concurrency factor = 4 H E coordinator G F 22 @doanduyhai
23 .Concurrency factor formula • more details at: http://www.doanduyhai.com/blog/?p=13191 23 @doanduyhai
24 .Caveat 1: non restrictive filters B C Hit all nodes A D eventually L H E coordinator G F 24 @doanduyhai
25 .Caveat 1 solution : always use LIMIT B C SELECT * FROM … A D WHERE ... LIMIT 1000 H E coordinator G F 25 @doanduyhai
26 .Caveat 2: 1-to-1 index (user_email) B C A D Not found WHERE user_email = ‘xxx' H E coordinator G F 26 @doanduyhai
27 .Caveat 2: 1-to-1 index (user_email) B C A D WHERE user_email = ‘xxx' H E Still no result coordinator G F 27 @doanduyhai
28 .Caveat 2: 1-to-1 index (user_email) B C A D WHERE user_email = ‘xxx' At best 1 user found At worst 0 user found H E coordinator G F 28 @doanduyhai
29 .Caveat 2 solution: materialized views For 1-to-1 index/relationship, use materialized views instead CREATE MATERIALIZED VIEW user_by_email AS SELECT * FROM users WHERE user_id IS NOT NULL and user_email IS NOT NULL PRIMARY KEY (user_email, user_id) But range queries ( <, >, ≤, ≥) not possible … 29 @doanduyhai
3秒后跳转登录页面
去登陆

