

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16_07 - cassandrasummit2016-runningcassandraonapachemesosacrossm
可以参考文章: https://www.infoq.cn/article/how-uber-using-mesos-and-cassandra
讲述 uber cassandra在跨机房的应用
展开查看详情
1 .Running Cassandra on Apache Mesos across multiple datacenters at Uber Abhishek Verma (verma@uber.com)
2 .About me ● MS (2010) and PhD (2012) in Computer Science from University of Illinois at Urbana-Champaign ● 2 years at Google, worked on Borg and Omega and first author of the Borg paper ● ~ 1 year at TCS Research, Mumbai ● Currently at Uber working on running Cassandra on Mesos © DataStax, All Rights Reserved. 2
3 .“Transportation as reliable as running water, everywhere, for everyone”
4 . 99.99% “Transportation as reliable as running water, everywhere, for everyone”
5 .“Transportation as reliable as running water, everywhere, for everyone” efficient
6 .Cluster Management @ Uber ● Statically partitioned machines across different services ● Move from custom deployment system to everything running on Mesos ● Gain efficiency by increasing machine utilization ○ Co-locate services on the same machine ○ Can “Large-scale leadmanagement cluster to 30% fewer machines at Google 1 EuroSys 2015 with Borg”, ● Build stateful service frameworks to run on Mesos © DataStax, All Rights Reserved. 6
7 .Apache Mesos ● Mesos abstracts CPU, memory, storage away from machines ○ program like it’s a single pool of resources ● Linear scalability ● High availability ● Native support for launching containers ● Pluggable resource isolation ● Two level 7 scheduling
8 .Apache Cassandra ● Horizontal scalability ○ Scales reads and writes linearly as new nodes are added ● High availability ○ Fault tolerant with tunable consistency levels ● Low latency, solid performance ● Operational simplicity ○ Homogeneous cluster, no SPOF ● Rich data model 8
9 .DC/OS Cassandra Service https://github.com/mesosphere/dcos-cassandra-service Mesosphere Uber ● Chris Lambert ● Abhishek Verma ● Gabriel Hartmann ● Karthik Gandhi ● Keith Chambers ● Matthias Eichstaedt ● Kenneth Owens ● Varun Gupta ● Mohit Soni ● Zhitao Li 9
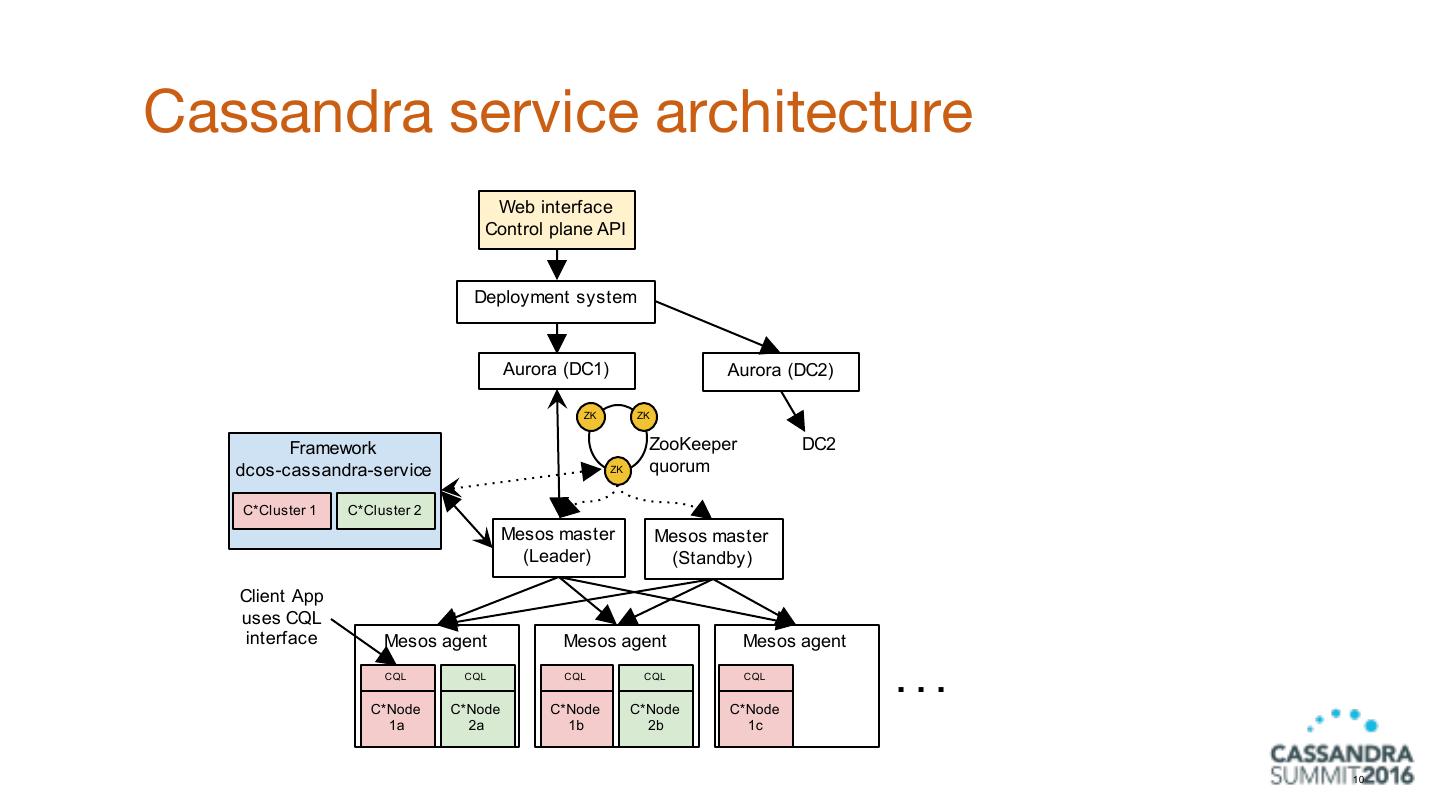
10 .Cassandra service architecture Web interface Control plane API Deployment system Aurora (DC1) Aurora (DC2) ZK ZK Framework ZooKeeper DC2 dcos-cassandra-service ZK quorum C*Cluster 1 C*Cluster 2 Mesos master Mesos master (Leader) (Standby) Client App uses CQL interface Mesos agent Mesos agent Mesos agent CQL CQL CQL CQL CQL ... C*Node C*Node C*Node C*Node C*Node 1a 2a 1b 2b 1c 10
11 .Cassandra Mesos primitives ● Mesos containerizer ● Override 5 ports in configuration (storage_port, ssl_storage_port, native_transport_port, rpc_port, jmx_port) ● Use persistent volumes ○ Data stored outside of the sandbox directory ○ Offered to the same task if it crashes and restarts ● Use dynamic reservation 11
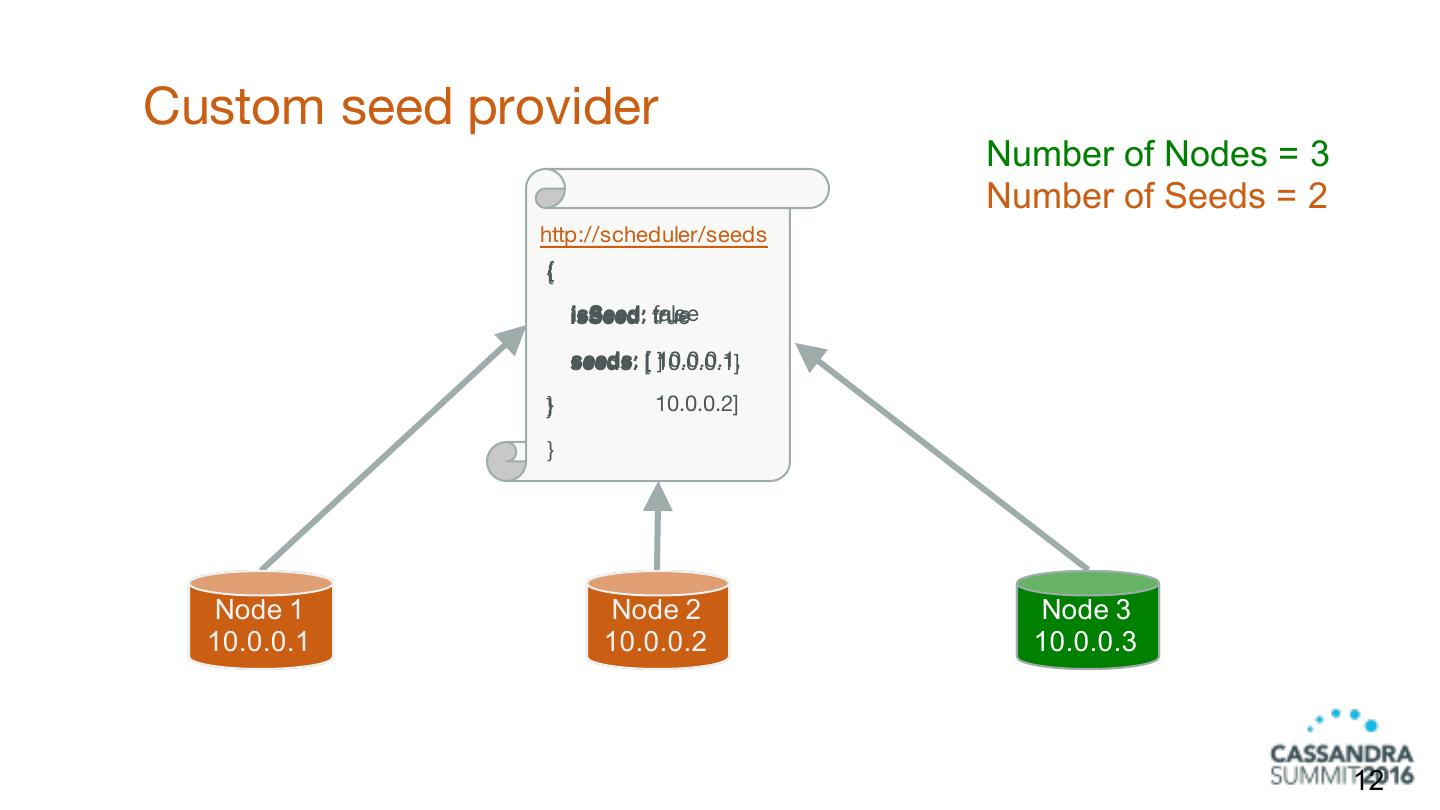
12 .Custom seed provider Number of Nodes = 3 Number of Seeds = 2 http://scheduler/seeds { false isSeed: true seeds: [ 10.0.0.1] 10.0.0.1, ] } 10.0.0.2] } Node 1 Node 2 Node 3 10.0.0.1 10.0.0.2 10.0.0.3 12
13 .Cassandra Service: Features ● Custom seed provider ● Increasing cluster size ● Changing Cassandra configuration ● Replacing a dead node ● Backup/Restore ● Cleanup ● Repair 13
14 .Plan, Phases and Blocks ● Plan ○ Phases ■ Reconciliation ■ Deployment ■ Backup ■ Restore ■ Cleanup ■ Repair 14
15 .Spinning up a new Cassandra cluster https://www.youtube.com/watch?v=gbYmjtDKSzs 15
16 .Automate Cassandra operations ● Repair ○ Synchronize all data across replicas ■ Last write wins ○ Anti-entropy mechanism ○ Repair primary key range node-by-node ● Cleanup ○ Remove data whose ownership has changed ■ Because of addition or removal of nodes 16
17 .Cleanup operation https://www.youtube.com/watch?v=VxRLSl8MpYI 17
18 .Failure scenarios ● Executor failure ○ Restarted automatically ● Cassandra daemon failure ○ Restarted automatically ● Node failure ○ Manual REST endpoint to replace node ● Scheduling framework failure ○ Existing nodes keep running, new nodes cannot be added 18
19 .Experiments 19
20 .Cluster startup For each node in the cluster: 1.Receive and accept offer 2.Launch task 3.Fetch executor, JRE, Cassandra binaries from S3/HDFS 4.Launch executor 5.Launch Cassandra daemon 6.Wait for it’s mode to transition STARTING -> JOINING -> NORMAL 20
21 .Cluster startup time Framework can start ~ one new node per minute 21
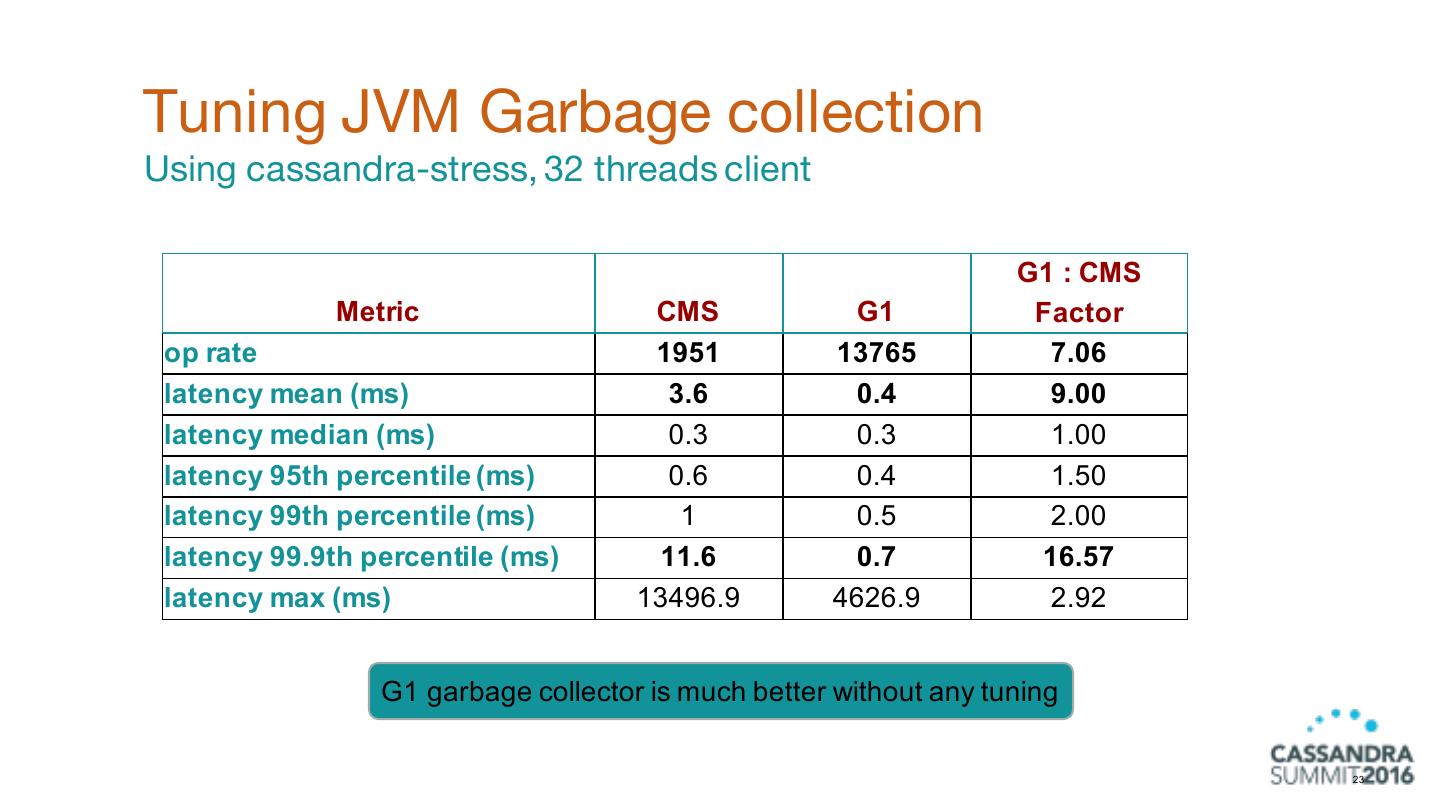
22 . Tuning JVM Garbage collection Changed from CMS to G1 garbage collector Left: https://github.com/apache/cassandra/blob/cassandra-2.2/conf/cassandra-env.sh#L213 Right: https://docs.datastax.com/en/cassandra/2.1/cassandra/operations/ops_tune_jvm_c.html?scroll=concept_ds_sv5_k4w_dk__tuning-java-garbage-collection 22
23 .Tuning JVM Garbage collection Using cassandra-stress, 32 threads client G1 : CMS Metric CMS G1 Factor op rate 1951 13765 7.06 latency mean (ms) 3.6 0.4 9.00 latency median (ms) 0.3 0.3 1.00 latency 95th percentile (ms) 0.6 0.4 1.50 latency 99th percentile (ms) 1 0.5 2.00 latency 99.9th percentile (ms) 11.6 0.7 16.57 latency max (ms) 13496.9 4626.9 2.92 G1 garbage collector is much better without any tuning 23
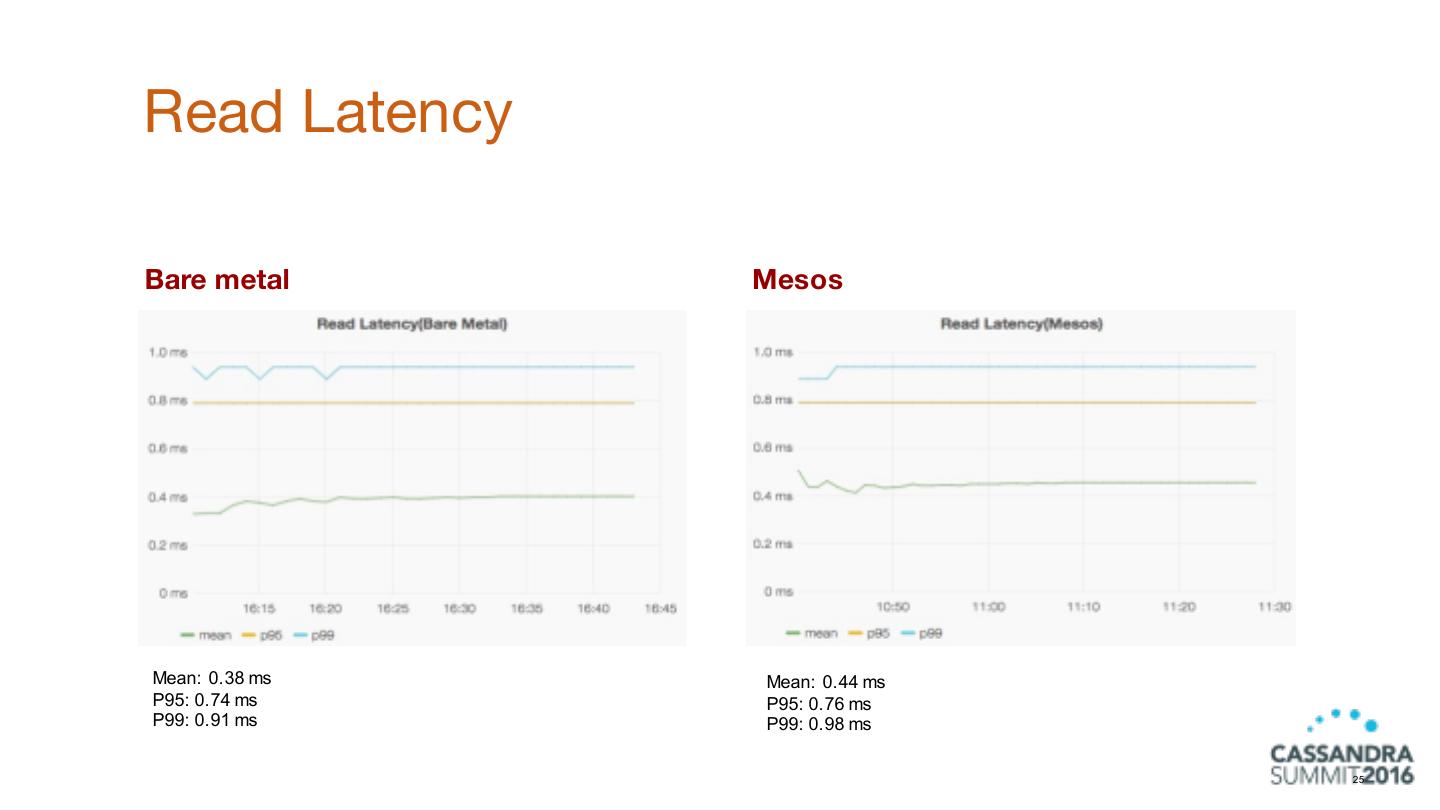
24 .Cluster Setup ● 3 nodes ● Local DC ● 24 cores, 128 GB RAM, 2TB SAS drives ● Cassandra running on bare metal ● Cassandra running in a Mesos container 24
25 .Read Latency Bare metal Mesos Mean: 0.38 ms Mean: 0.44 ms P95: 0.74 ms P95: 0.76 ms P99: 0.91 ms P99: 0.98 ms 25
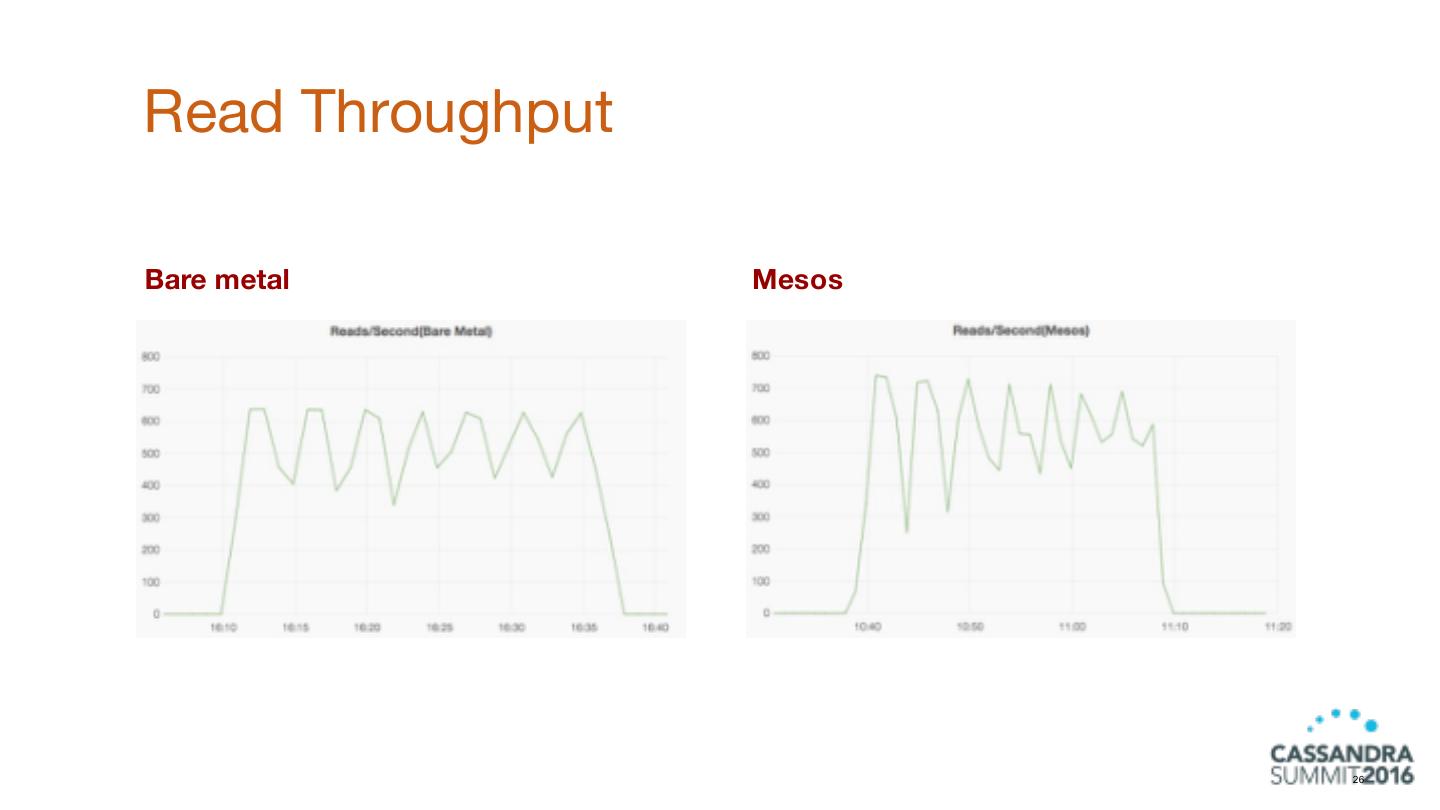
26 .Read Throughput Bare metal Mesos 26
27 .Write Latency Bare metal Mesos Mean: 0.43 ms Mean: 0.48 ms P95: 0.94 ms P95: 0.93 ms P99: 1.05 ms P99: 1.26 ms 27
28 .Write Throughput Bare metal Mesos 28
29 .Running across datacenters ● Four datacenters ○ Each running dcos-cassandra-service instance ○ Sync datacenter phase ■ Periodically exchange seeds with external dcs ● Cassandra nodes gossip topology ○ Discover nodes in other datacenters 29
3秒后跳转登录页面
去登陆

