















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16/07 - Maintaining Consistency Across Data Centers & Cassandra
Maintaining Consistency
Across Data Centers
or: How I Learned to Stop
Worrying About WAN Latency
展开查看详情
1 .Maintaining Consistency Across Data Centers or: How I Learned to Stop Worrying About WAN Latency Randy Fradin BlackRock
2 .About the Speaker • Part of BlackRock’s Aladdin Product Group • Core Software Infrastructure - building scalable storage, compute, and messaging systems • Joined BlackRock in 2009 • Using Cassandra since 2011 • Excited to be speaking at #CassandraSummit 2016 • Also check out my talk from Cassandra Summit 2015, “Multi-Tenancy in Cassandra at BlackRock” 2
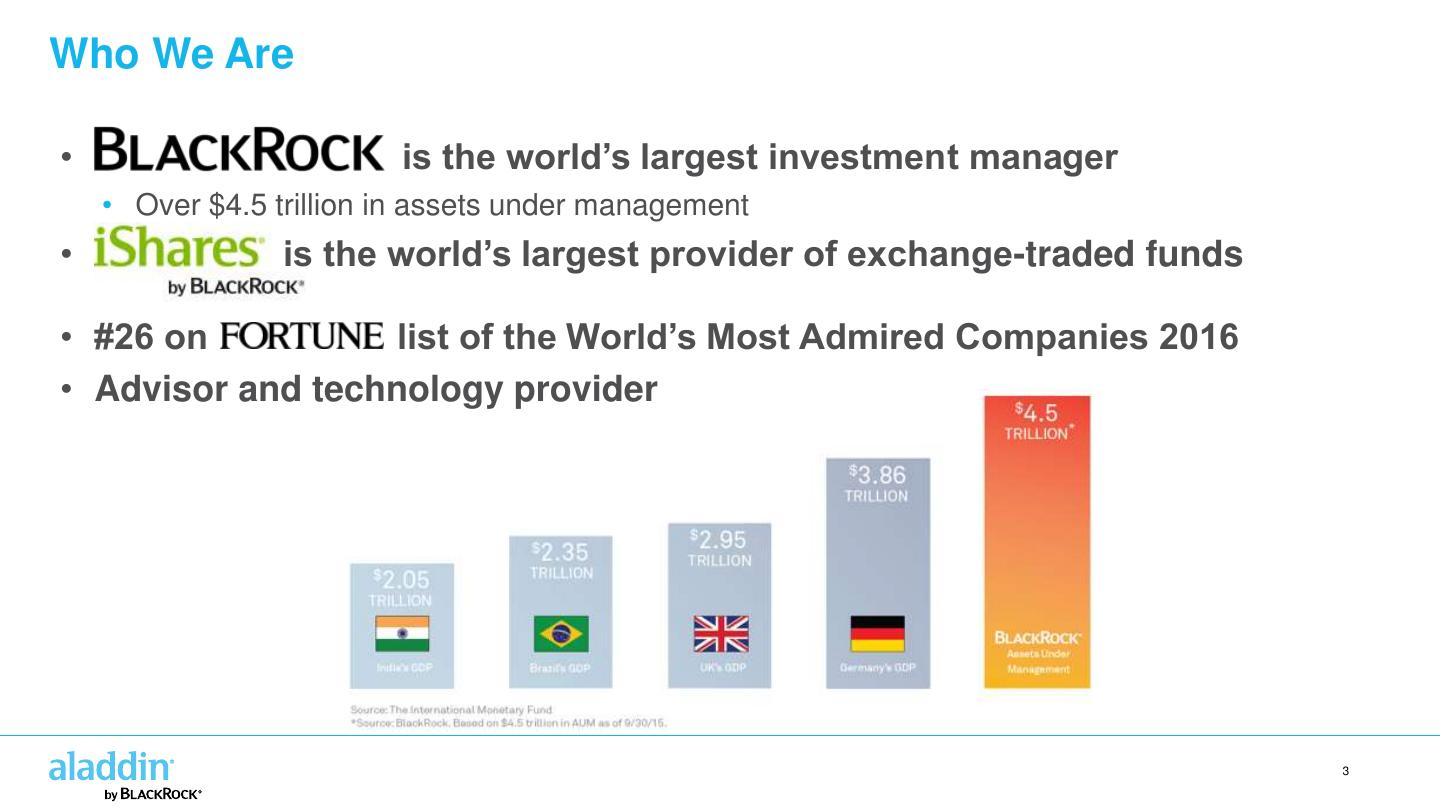
3 .Who We Are • is the world’s largest investment manager • Over $4.5 trillion in assets under management • is the world’s largest provider of exchange-traded funds • #26 on list of the World’s Most Admired Companies 2016 • Advisor and technology provider 3
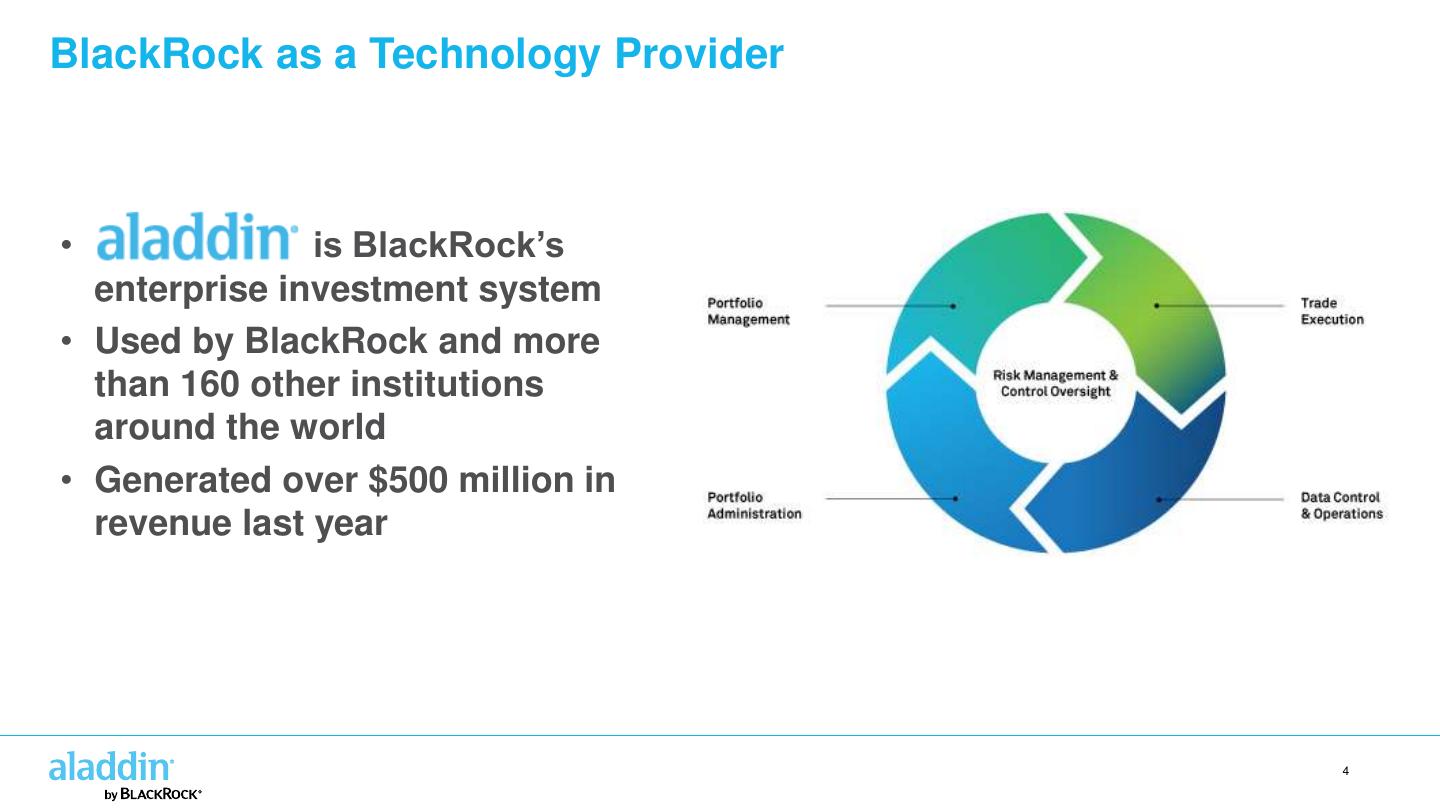
4 .BlackRock as a Technology Provider • is BlackRock’s enterprise investment system • Used by BlackRock and more than 160 other institutions around the world • Generated over $500 million in revenue last year 4
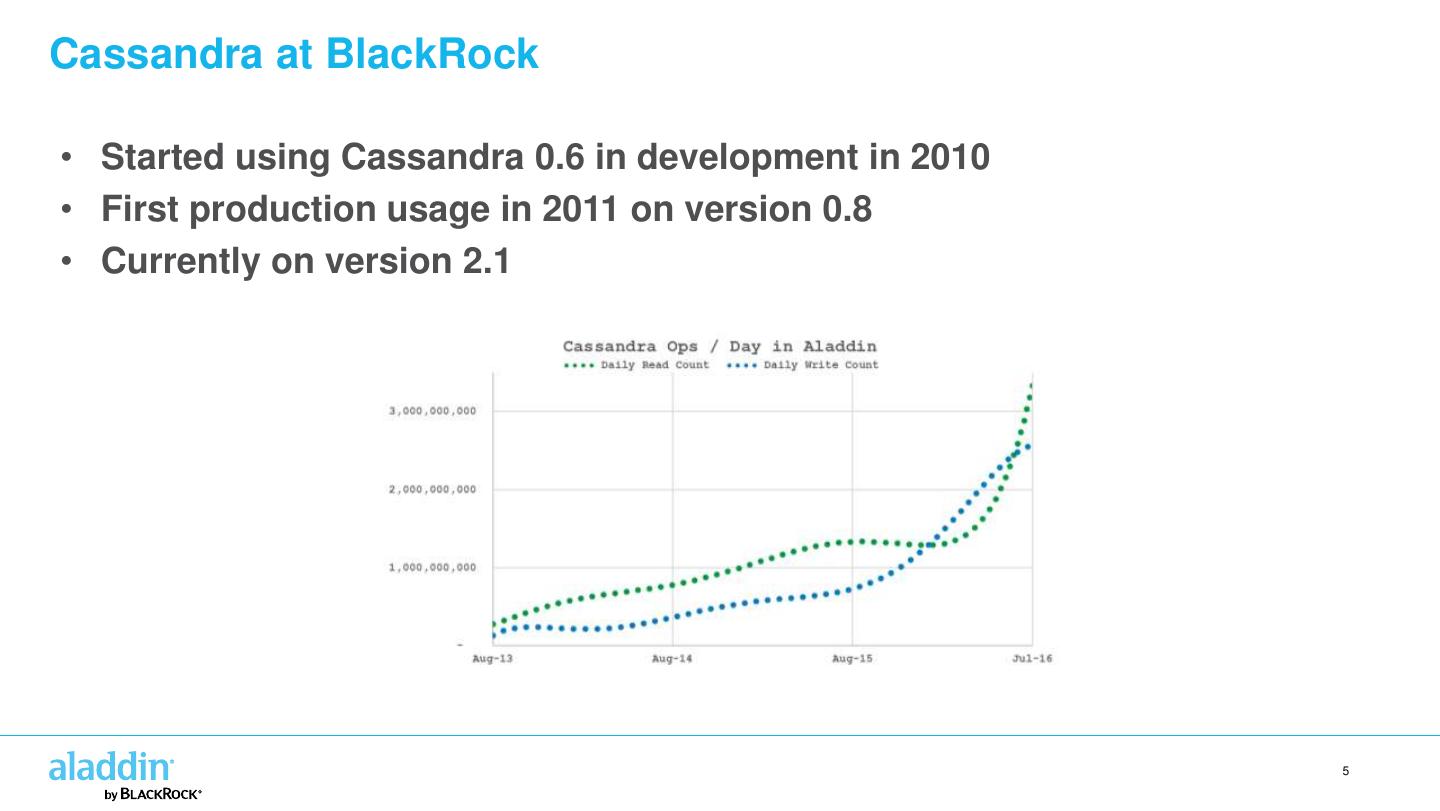
5 .Cassandra at BlackRock • Started using Cassandra 0.6 in development in 2010 • First production usage in 2011 on version 0.8 • Currently on version 2.1 5
6 .Using Cassandra in Multiple Data Centers
7 .Support for Data Centers in Cassandra • A cluster can span wide distances • Disaster recovery • Proximity to other systems • In Cassandra, “data center” == replication group • Usually you group by proximity • Can also group by type of workload SITE 1 SITE 2 production production workload workload SITE 1 SITE 2 analytic analytic workload workload 7
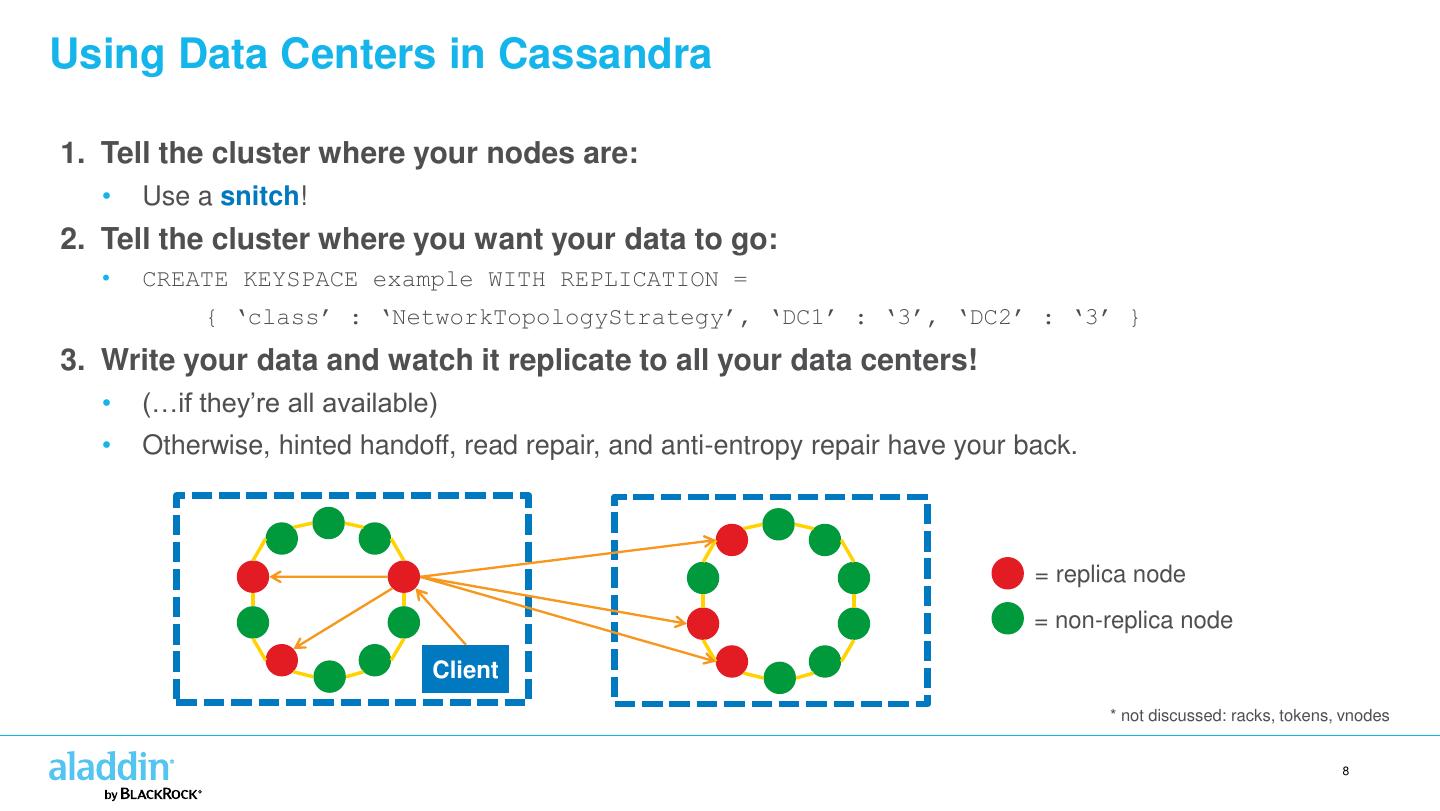
8 .Using Data Centers in Cassandra 1. Tell the cluster where your nodes are: • Use a snitch! 2. Tell the cluster where you want your data to go: • CREATE KEYSPACE example WITH REPLICATION = { ‘class’ : ‘NetworkTopologyStrategy’, ‘DC1’ : ‘3’, ‘DC2’ : ‘3’ } 3. Write your data and watch it replicate to all your data centers! • (…if they’re all available) • Otherwise, hinted handoff, read repair, and anti-entropy repair have your back. = replica node = non-replica node Client * not discussed: racks, tokens, vnodes 8
9 .Cross-Data Center Optimizations Data moving between data centers is optimized: • Cross-data center forwarding • inter_dc_tcp_nodelay • inter_dc_stream_throughput_outbound_megabits_per_sec = data = data + forwarding addresses Client 9
10 .Data Centers & Consistency Levels • Every write or read is forwarded to corresponding replicas • “consistency” = # of replies needed to succeed • Reads reflect the latest writes (“strong consistency”) when: read consistency + write consistency > replica count • Some consistency levels are “aware” of data centers, others not: Data center “oblivious” Data center “aware” • ANY • LOCAL_ONE • ONE • LOCAL_QUORUM • TWO • EACH_QUORUM • THREE • QUORUM • ALL 10
11 .Strong Consistency Across Data Centers
12 .Why Strong Consistency Across Data Centers? • Typical Cassandra use cases prioritize low latency and high throughput. • But, sometimes high availability and strong consistency are more important! • Requirements: 1. Non-stop availability 2. Never lose data 12
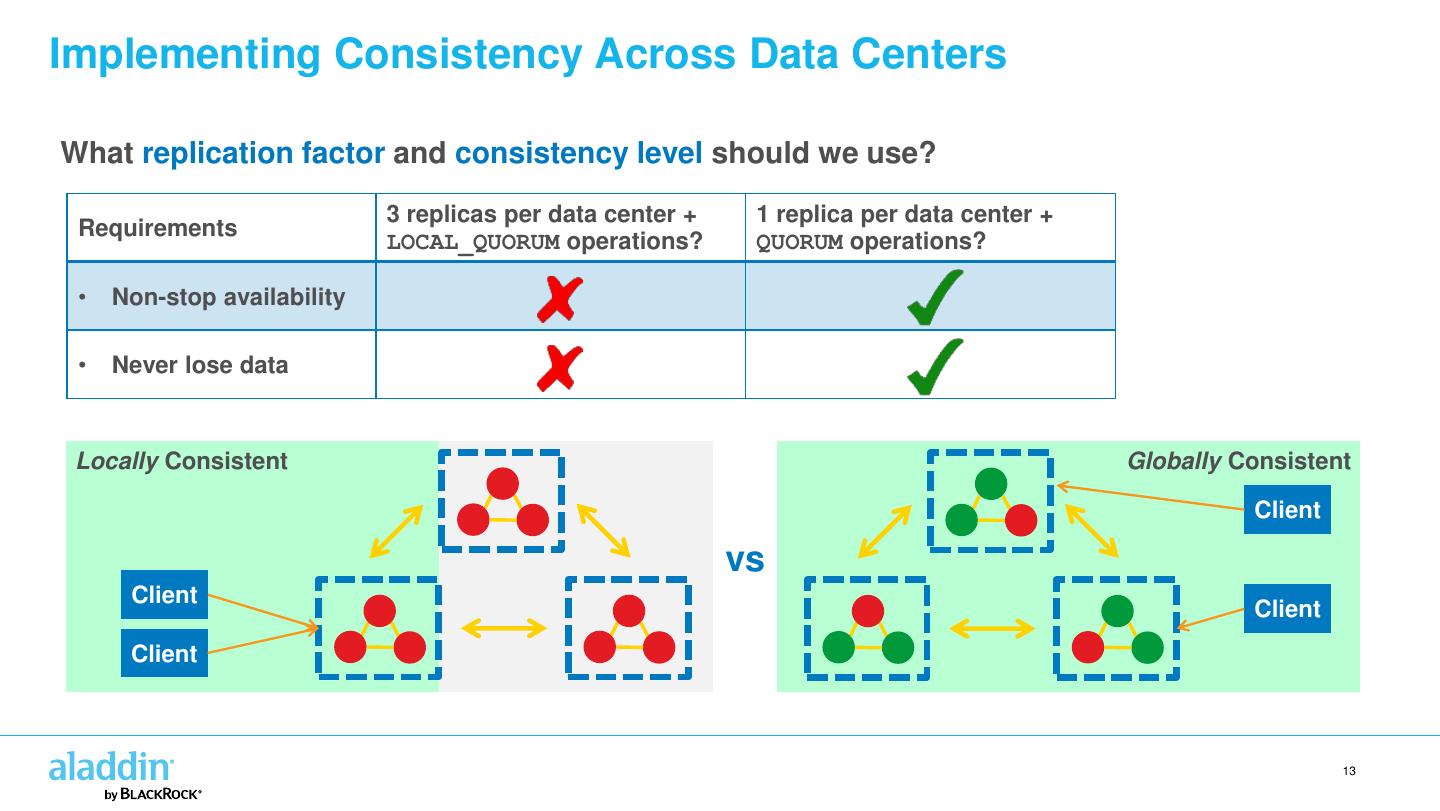
13 .Implementing Consistency Across Data Centers What replication factor and consistency level should we use? 3 replicas per data center + 1 replica per data center + Requirements LOCAL_QUORUM operations? QUORUM operations? • Non-stop availability • Never lose data Locally Consistent Globally Consistent Client vs Client Client Client 13
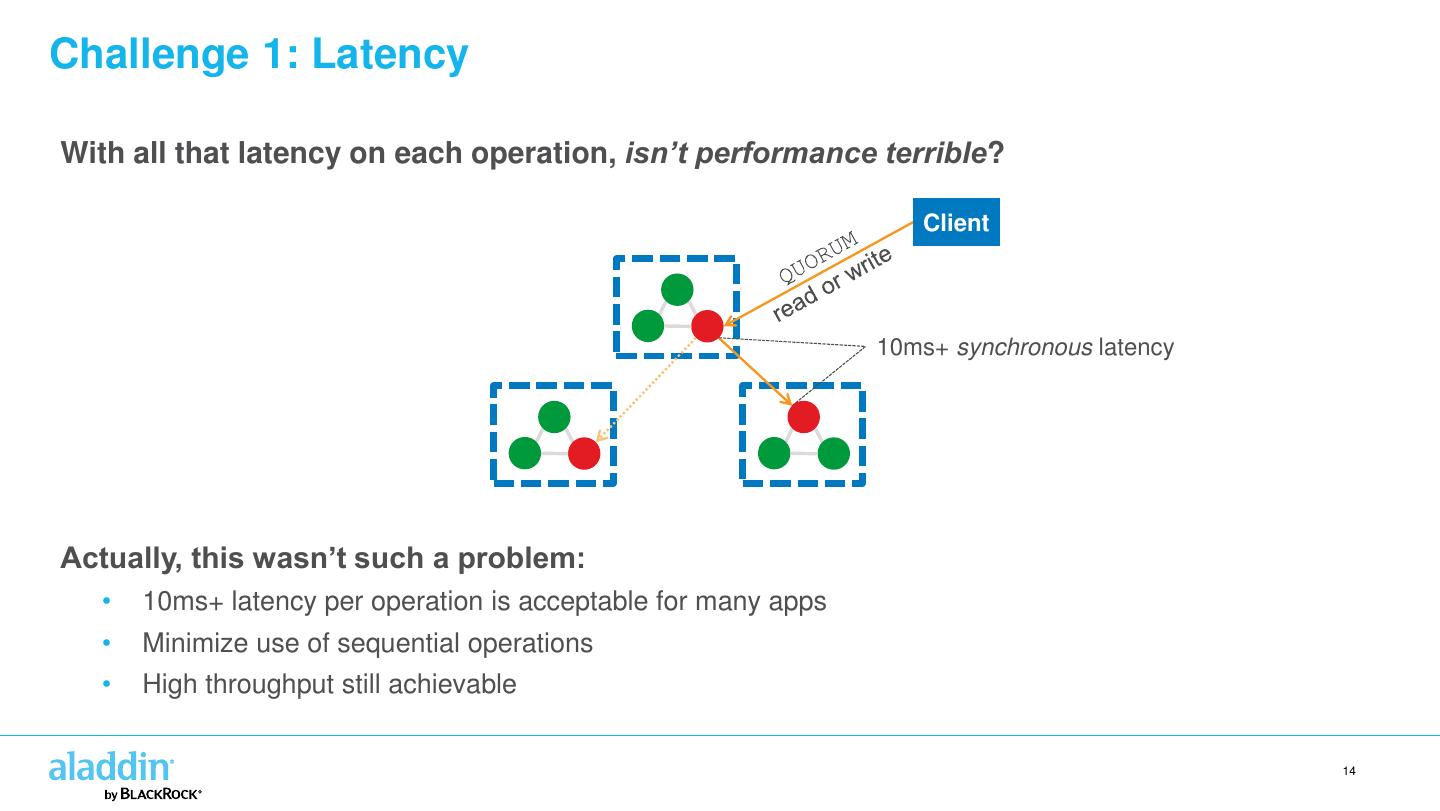
14 .Challenge 1: Latency With all that latency on each operation, isn’t performance terrible? Client 10ms+ synchronous latency Actually, this wasn’t such a problem: • 10ms+ latency per operation is acceptable for many apps • Minimize use of sequential operations • High throughput still achievable 14
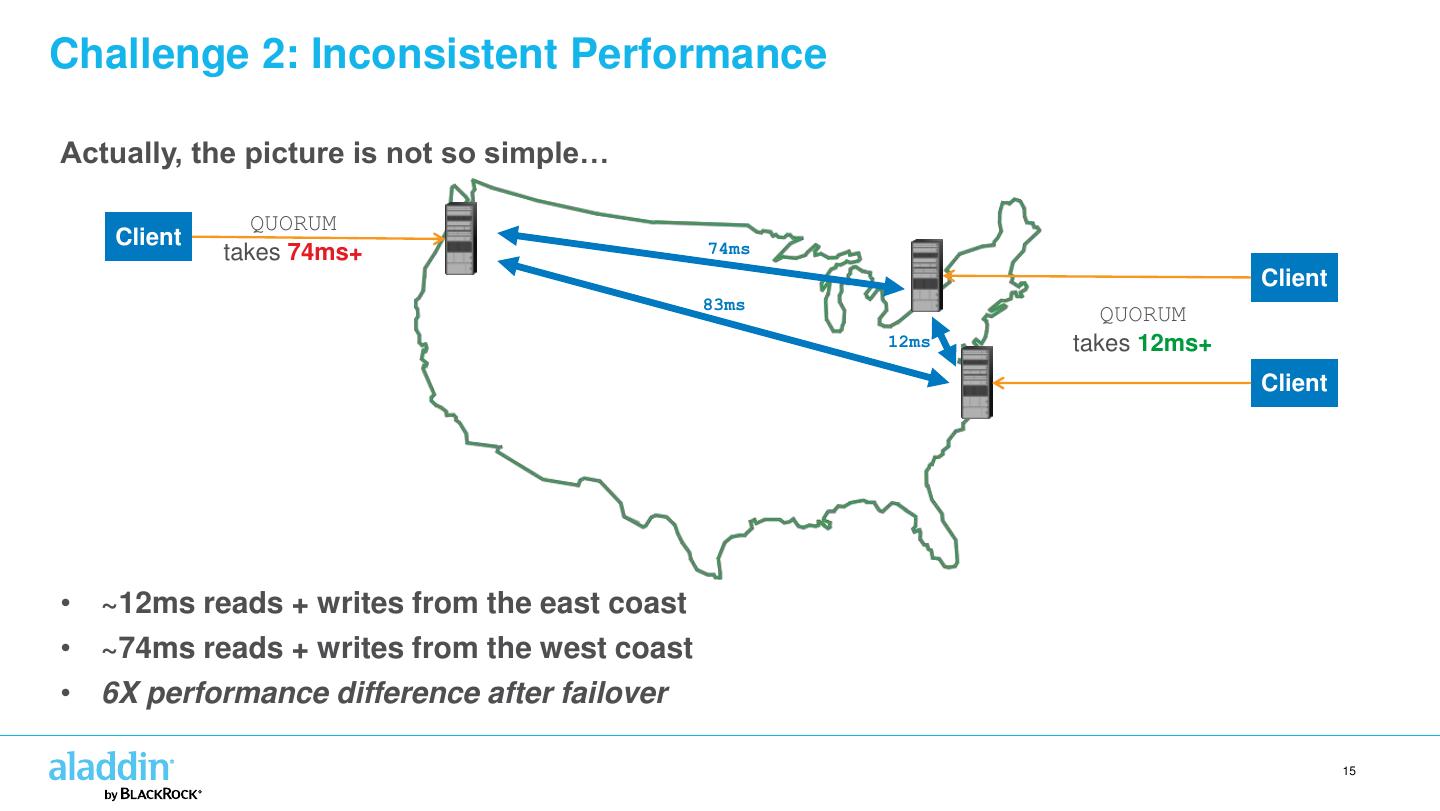
15 .Challenge 2: Inconsistent Performance Actually, the picture is not so simple… QUORUM Client 74ms takes 74ms+ Client 83ms QUORUM 12ms takes 12ms+ Client • ~12ms reads + writes from the east coast • ~74ms reads + writes from the west coast • 6X performance difference after failover 15
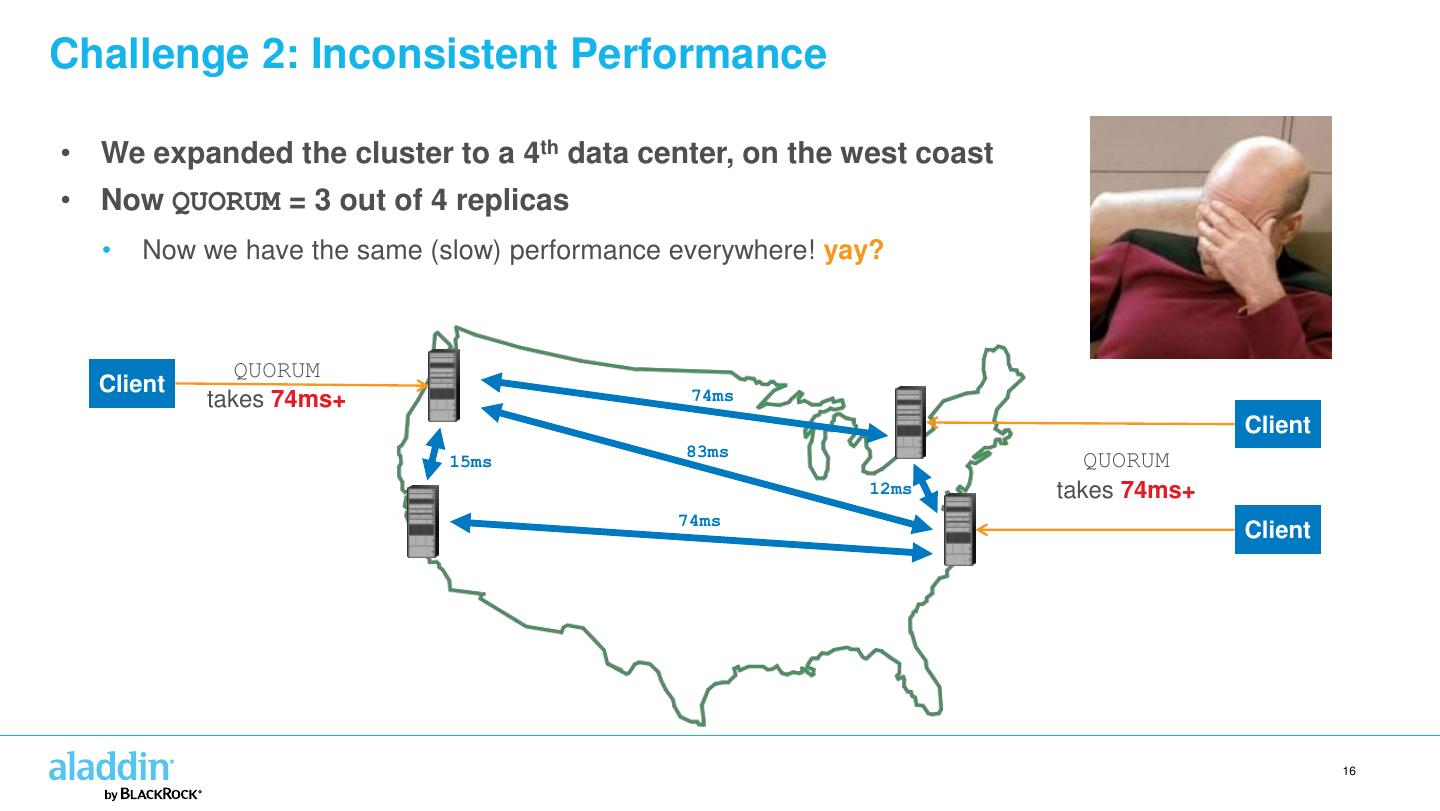
16 .Challenge 2: Inconsistent Performance • We expanded the cluster to a 4th data center, on the west coast • Now QUORUM = 3 out of 4 replicas • Now we have the same (slow) performance everywhere! yay? QUORUM Client 74ms takes 74ms+ Client 83ms 15ms QUORUM 12ms takes 74ms+ 74ms Client 16
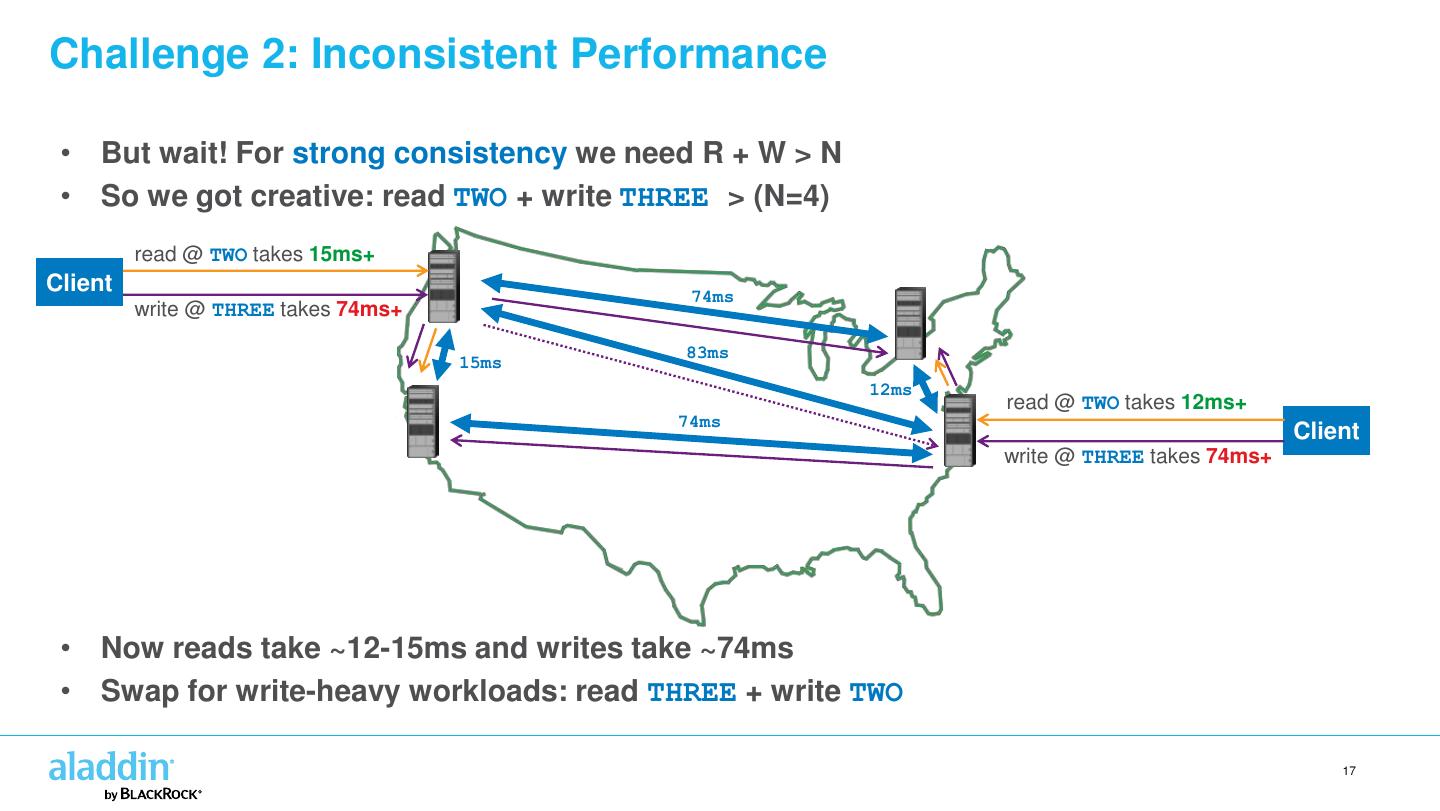
17 .Challenge 2: Inconsistent Performance • But wait! For strong consistency we need R + W > N • So we got creative: read TWO + write THREE > (N=4) read @ TWO takes 15ms+ Client 74ms write @ THREE takes 74ms+ 83ms 15ms 12ms read @ TWO takes 12ms+ 74ms Client write @ THREE takes 74ms+ • Now reads take ~12-15ms and writes take ~74ms • Swap for write-heavy workloads: read THREE + write TWO 17
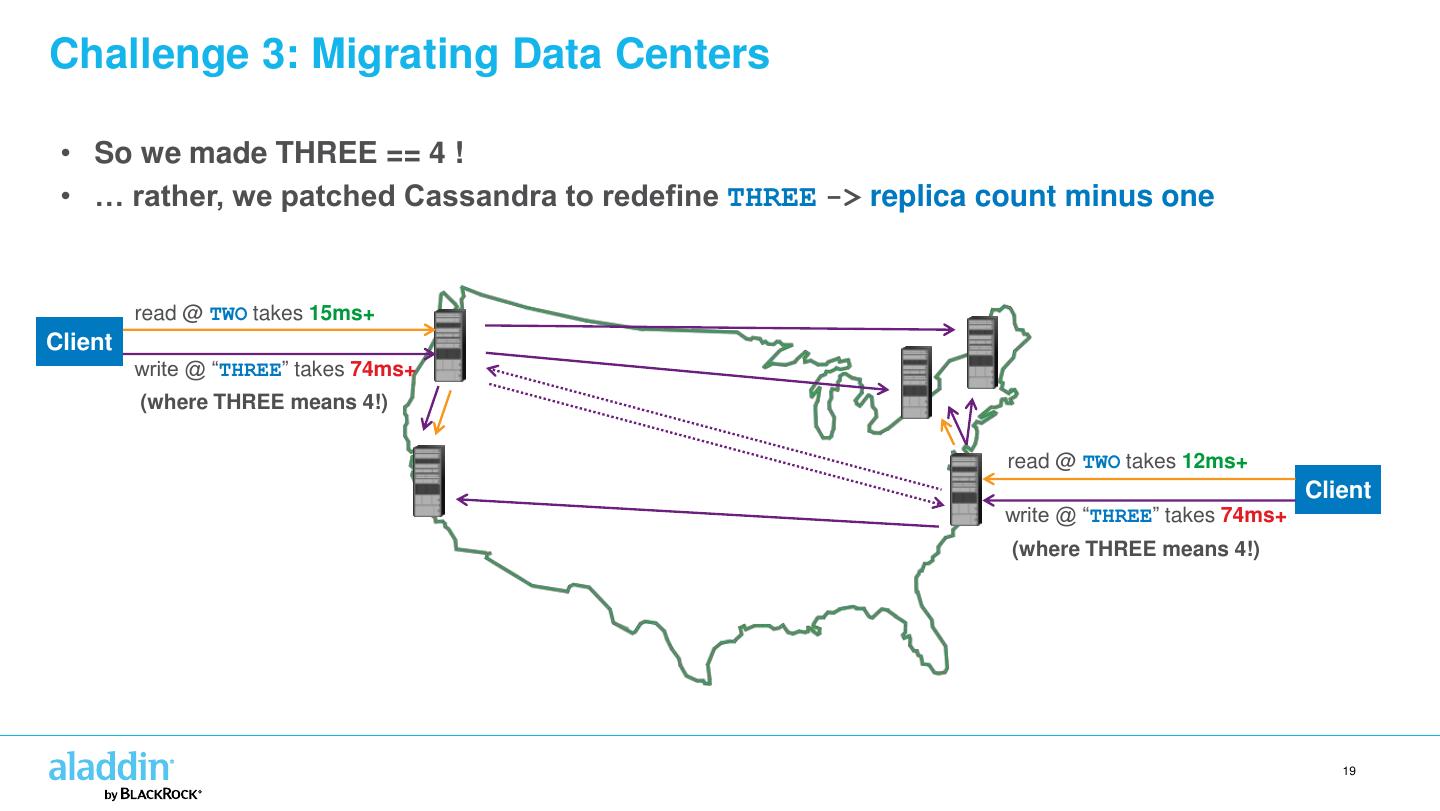
18 .Challenge 3: Migrating Data Centers • Last year we migrated one of the east coast data centers • Temporarily increased replica count from 4 to 5 • But TWO + THREE is not > 5 ! This violates strong consistency! • What we really wanted was TWO + ALL_BUT_ONE • But there is no ALL_BUT_ONE… 18
19 .Challenge 3: Migrating Data Centers • So we made THREE == 4 ! • … rather, we patched Cassandra to redefine THREE -> replica count minus one read @ TWO takes 15ms+ Client write @ “THREE” takes 74ms+ (where THREE means 4!) read @ TWO takes 12ms+ Client write @ “THREE” takes 74ms+ (where THREE means 4!) 19
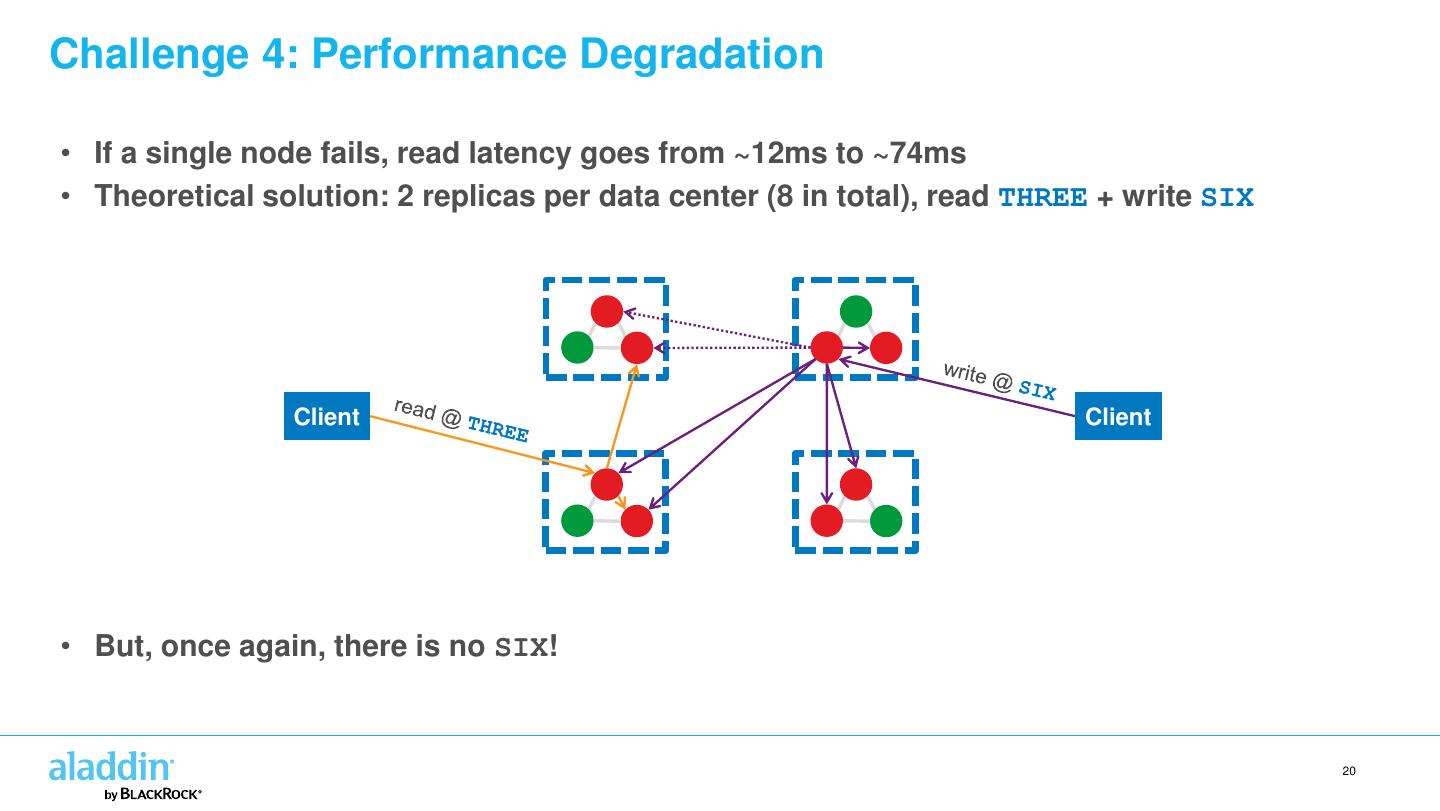
20 .Challenge 4: Performance Degradation • If a single node fails, read latency goes from ~12ms to ~74ms • Theoretical solution: 2 replicas per data center (8 in total), read THREE + write SIX Client Client • But, once again, there is no SIX! 20
21 .Challenge 5: Isolating Different Workloads It’s useful to isolate analytic workloads from production workloads … … but this isn’t possible if “production” is doing quorum across all replicas. 21
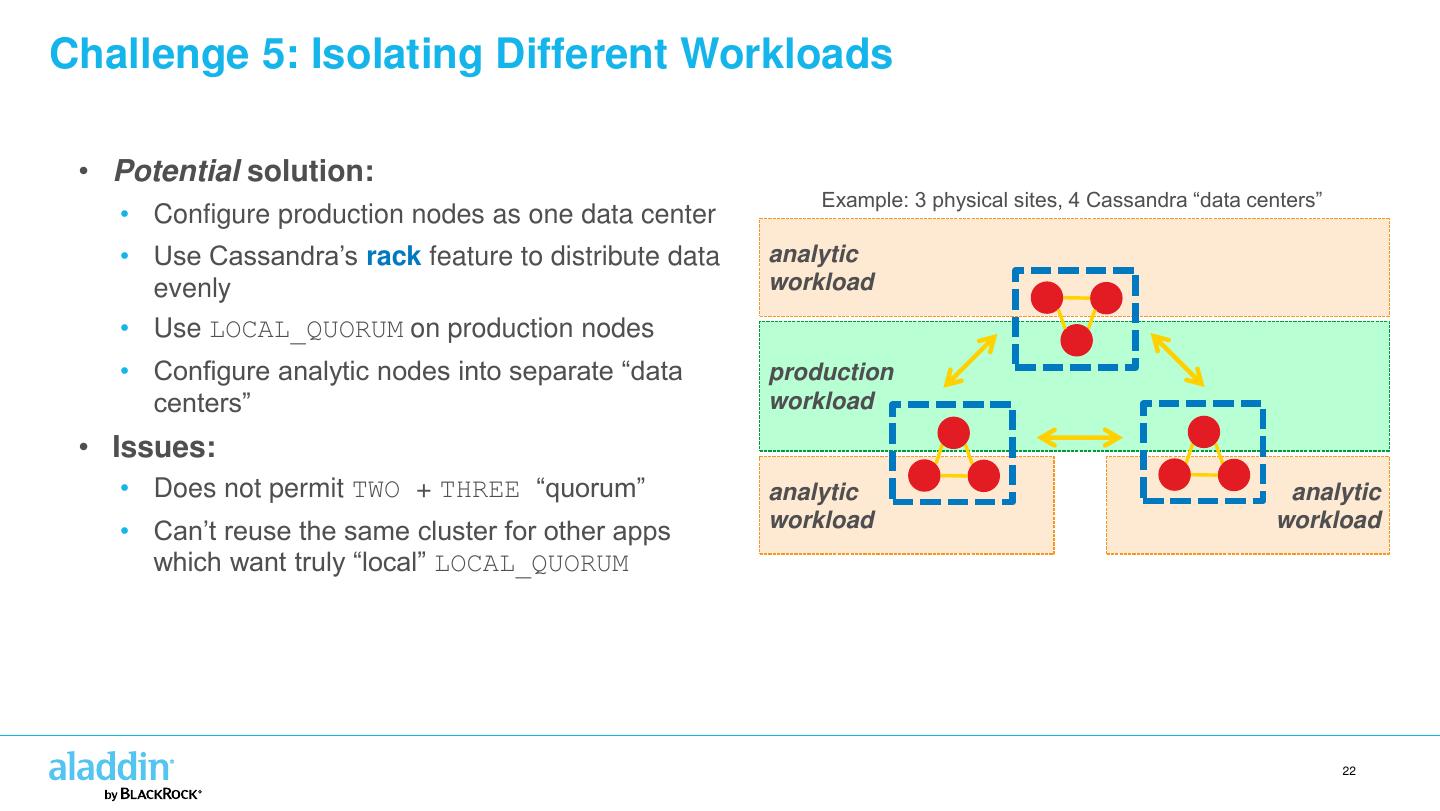
22 .Challenge 5: Isolating Different Workloads • Potential solution: Example: 3 physical sites, 4 Cassandra “data centers” • Configure production nodes as one data center • Use Cassandra’s rack feature to distribute data analytic evenly workload • Use LOCAL_QUORUM on production nodes • Configure analytic nodes into separate “data production centers” workload • Issues: • Does not permit TWO + THREE “quorum” analytic analytic • Can’t reuse the same cluster for other apps workload workload which want truly “local” LOCAL_QUORUM 22
23 .Making Consistency Pluggable Many challenges could be solved if consistency were pluggable: • Quorum across a subset of data centers • “Uneven” quorums: – read 2 + write N-1 – read (N+1)/2 + write (N/2)+1 – and so on… • Local consistency with extra resiliency: – LOCAL_QUORUM + X remote replicas – LOCAL_QUORUM in 2 data centers Consistency levels should be: • User-definable • Fully configurable • Simple for operators to deploy Discussion is ongoing: CASSANDRA-8119 23
24 .Other Tips for Success • Consider implications for fault-tolerance • Two nodes offline in different data centers can cause failures • Build a custom snitch to explicitly favor nearby data centers • Increase native_transport_max_threads • Enable inter_dc_tcp_nodelay • Check your TCP window size settings 24
25 .http://rockthecode.io/ @rockthecodeIO
3秒后跳转登录页面
去登陆

