





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16/07 - C* for Deep Learning by summit16
• Artificial Intelligence products for businesses
• Combining Deep Learning / Neural
Networks and traditional Machine Learning
• AI using Deep Learning has surpassed
human intelligence:
– Go
– Image Recognition
展开查看详情
1 .C* for Deep Learning
2 .Tractable • Artificial Intelligence products for businesses • Combining Deep Learning / Neural Networks and traditional Machine Learning • AI using Deep Learning has surpassed human intelligence: – Go – Image Recognition 2
3 .Deep Learning 101 Deep Learning A branch of machine learning based on a set of algorithms that attempt to model high-level abstractions in data by using a deep graph with multiple processing layers, composed of multiple linear and non-linear transformations. 1. Requires large amounts of data to train networks 2. Computations made feasible by use of GPUs for dramatic speedup 3
4 .Semantic Image Search Search in the meaning of the image NOT search on the image itself Similar object Similar Image 4
5 .Semantic Image Search Similar object Similar Image 5
6 .Semantic Search 2 • Intent can vary! • With training AI can do both of these tasks Same • Semantic search is more than just object classification: – Ranking within a classification – Search for things that are not classification categories Same style 6
7 .Feature Extraction Feature Vector V1 V2 Trained Deep Net . . . Vn-1 Vn 1 Image 4000 dimension vector 1 TB Images 300 GB of features 7
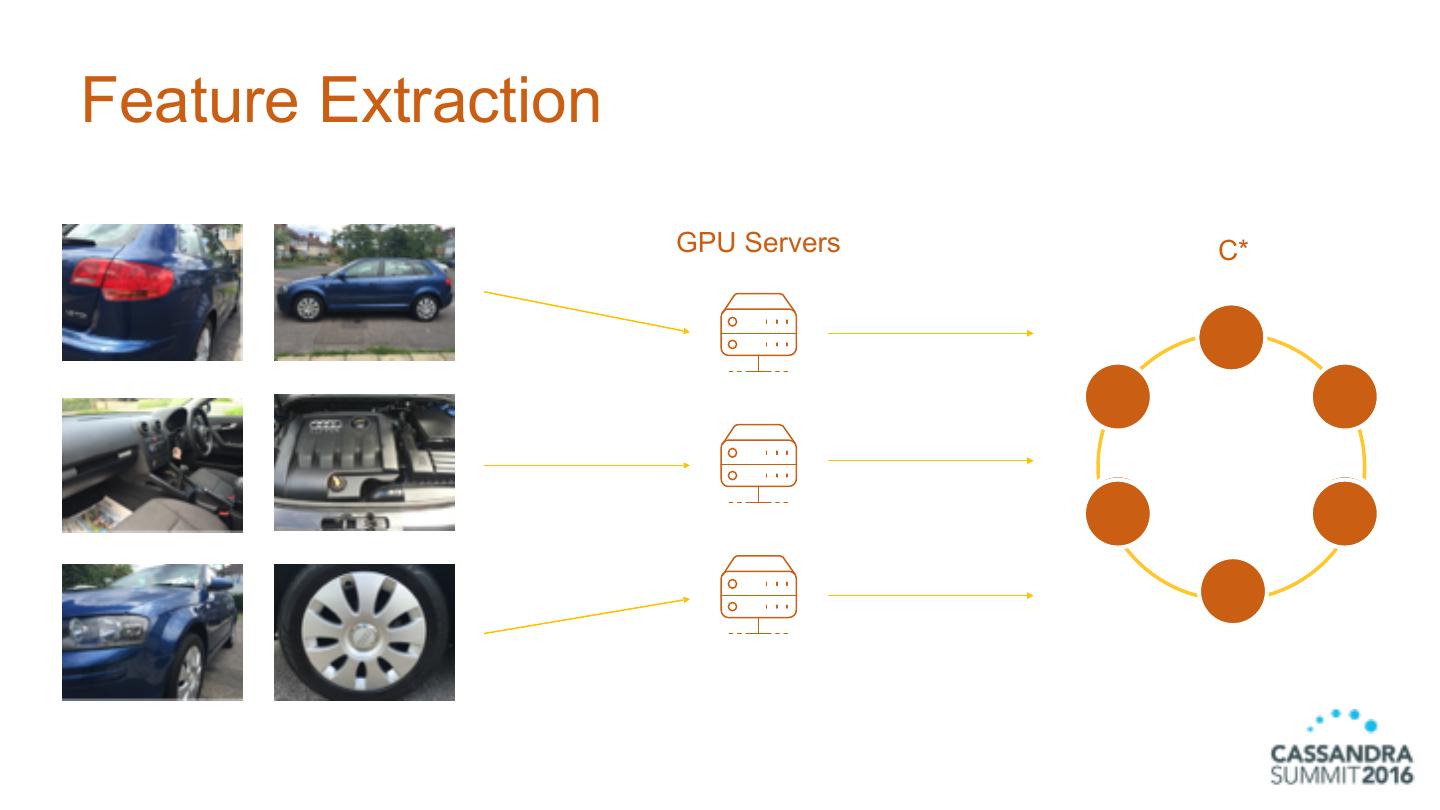
8 .Feature Extraction GPU Servers C*
9 .Feature Extraction • Processing images at CREATE TABLE features 5 GigaBytes per second listing_id uuid, image_id uuid, • Features generated at feature_vector blob, 1.6 GigaBytes per second PRIMARY KEY ((listing_id), image_id) 9
10 .Search “I want a truck like this” • 300 GB of features • Millions of rows in C* 10
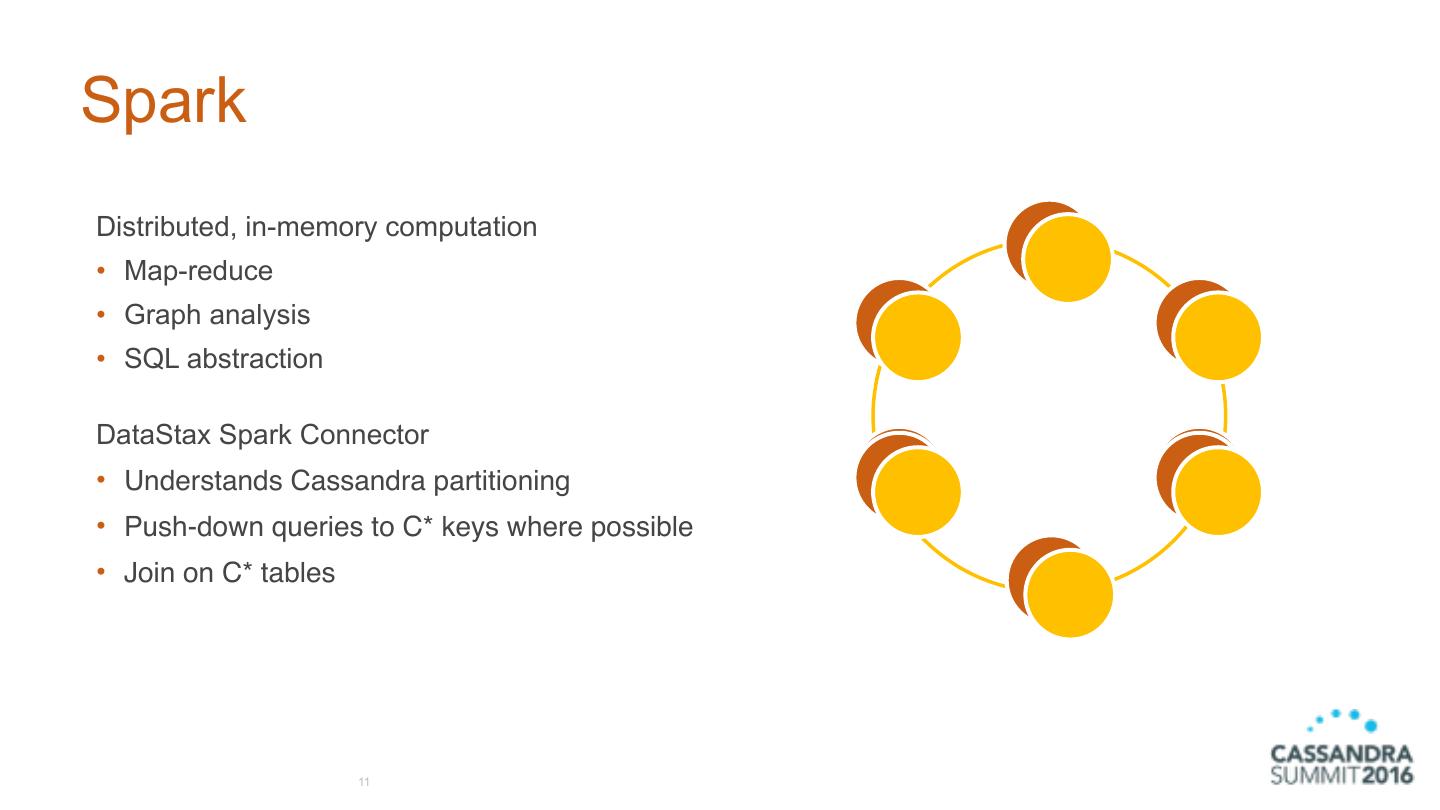
11 .Spark Distributed, in-memory computation • Map-reduce • Graph analysis • SQL abstraction DataStax Spark Connector • Understands Cassandra partitioning • Push-down queries to C* keys where possible • Join on C* tables 11
12 .Spark Similarity Search CREATE TABLE features listing_id uuid, 1. Cache our 300GB features in Spark image_id uuid, feature_vector blob, 2. Score every feature vector with our search PRIMARY KEY ((listing_id), image_id) image CREATE TABLE stock_level 3. Aggregate score for images in each listing listing_id uuid, inventory int, 4. (optional) Join on ‘live’ C* data etag uuid, PRIMARY KEY (listing_id) 5. Write result back to C* CREATE TABLE query_results query_id uuid, listing_id uuid, score float, PRIMARY KEY ((query_id), score) 12
13 .Search Search returns results within 5 seconds 100x Speedup from holding data in-memory in Spark 10x Speedup from co-locating Spark and C* 20x Speedup from partitioning on the group key (listing id) 5x Speedup from “Cassandra sort” 13
14 .Search Results 14
15 .Search Results 15
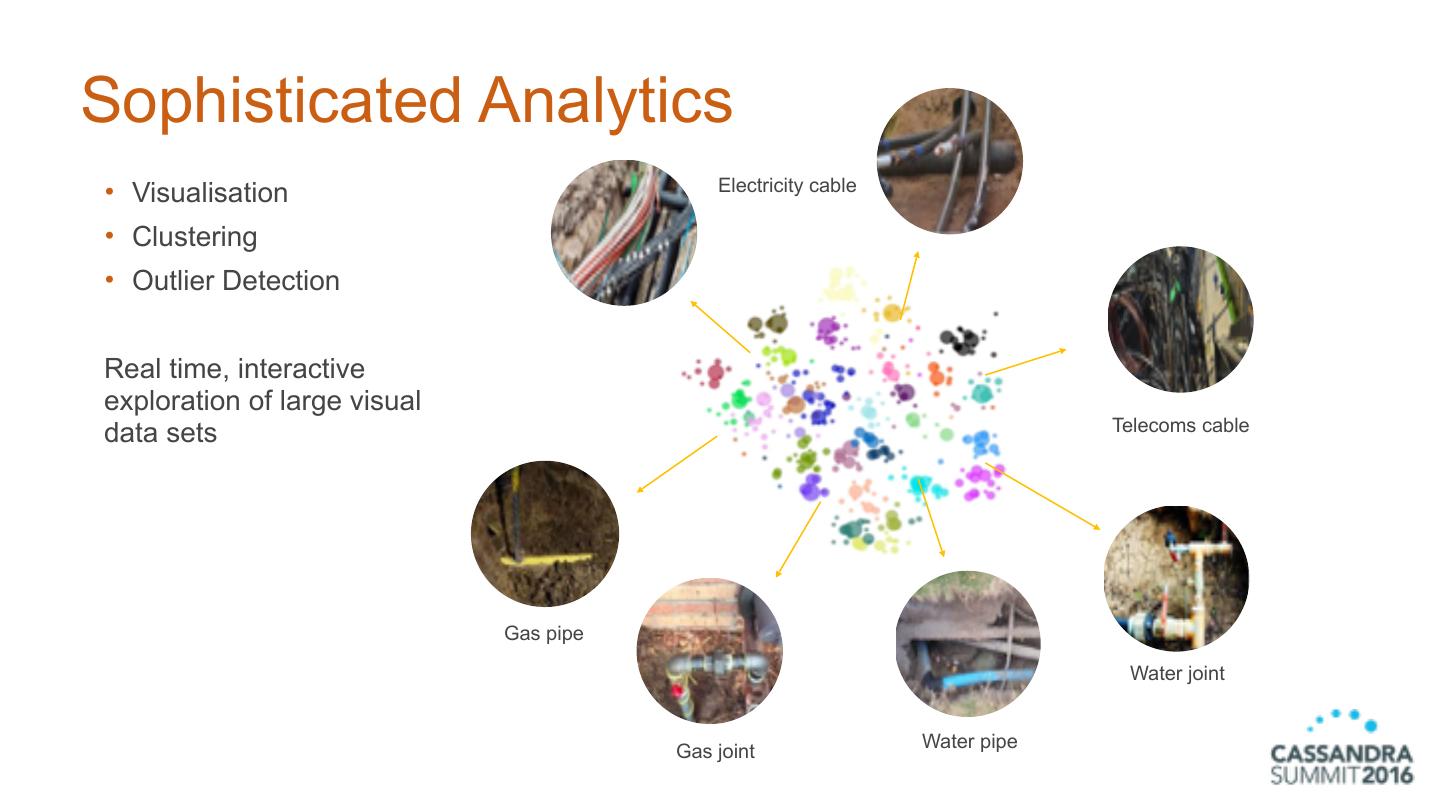
16 .Sophisticated Analytics • Visualisation • Clustering • Outlier Detection Real time, interactive exploration of large visual data sets
17 .Sophisticated Analytics • Visualisation Electricity cable • Clustering • Outlier Detection Real time, interactive exploration of large visual Telecoms cable data sets Gas pipe Water joint Water pipe Gas joint
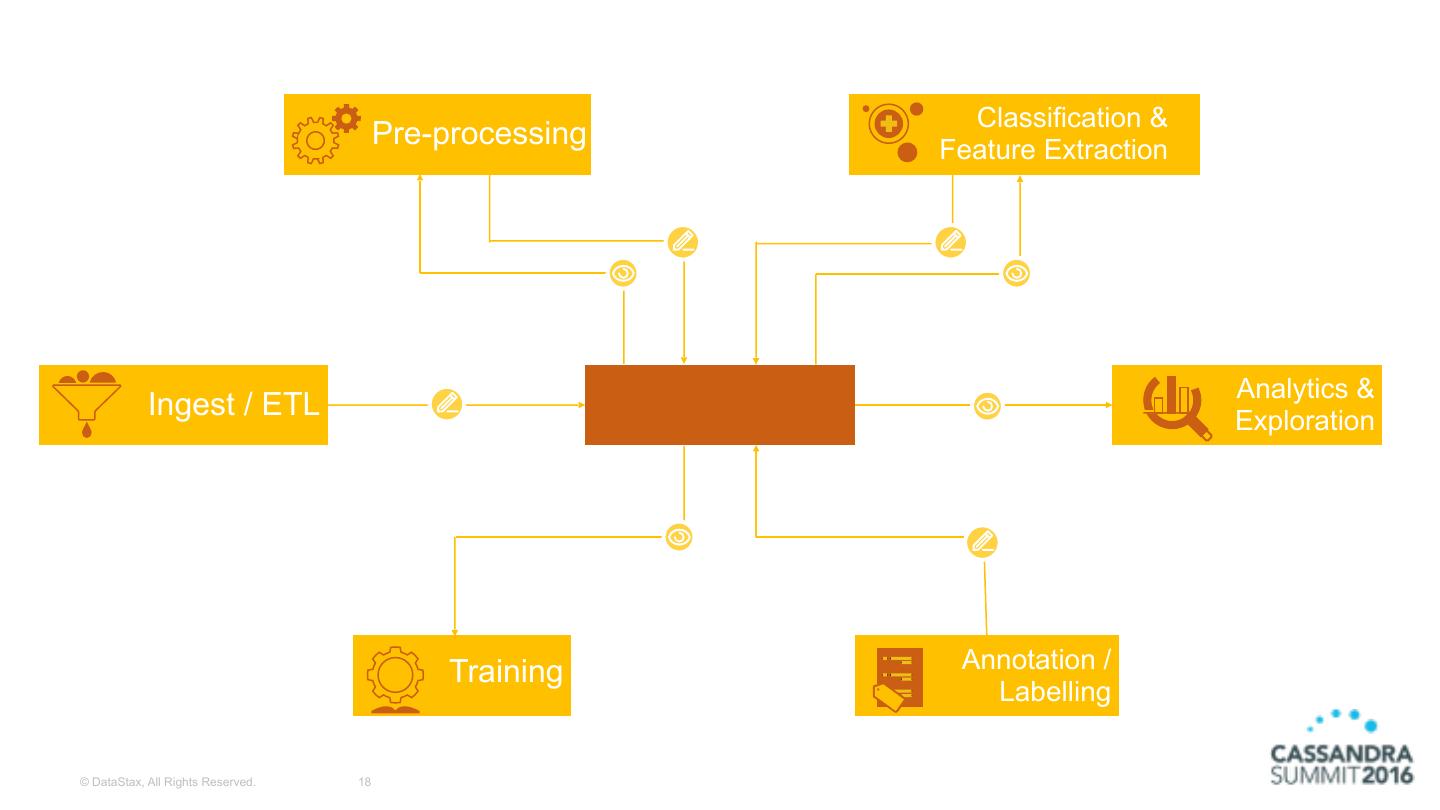
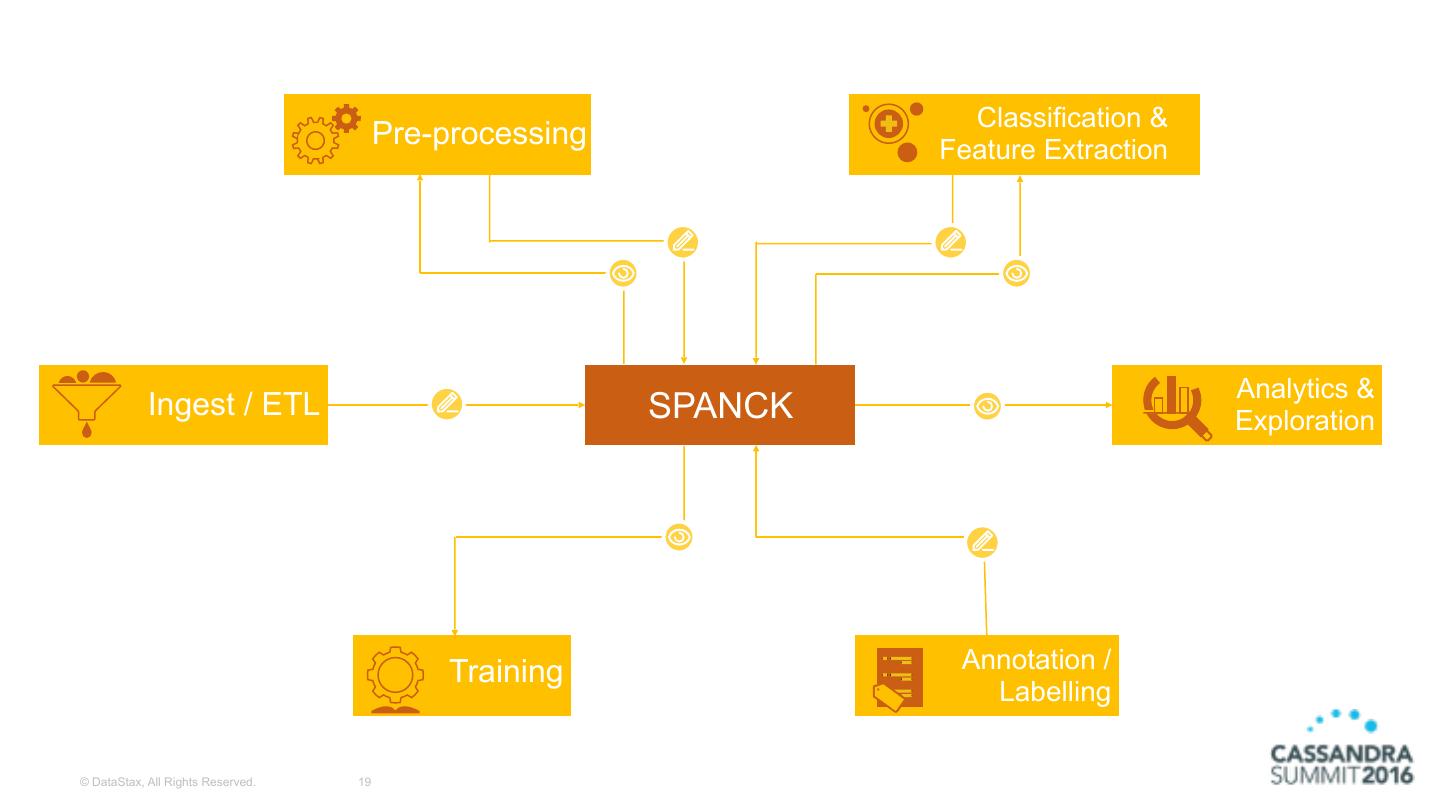
18 . Classification & Pre-processing Feature Extraction Analytics & Ingest / ETL Exploration Training Annotation / Labelling © DataStax, All Rights Reserved. 18
19 . Classification & Pre-processing Feature Extraction Analytics & Ingest / ETL SPANCK Exploration Training Annotation / Labelling © DataStax, All Rights Reserved. 19
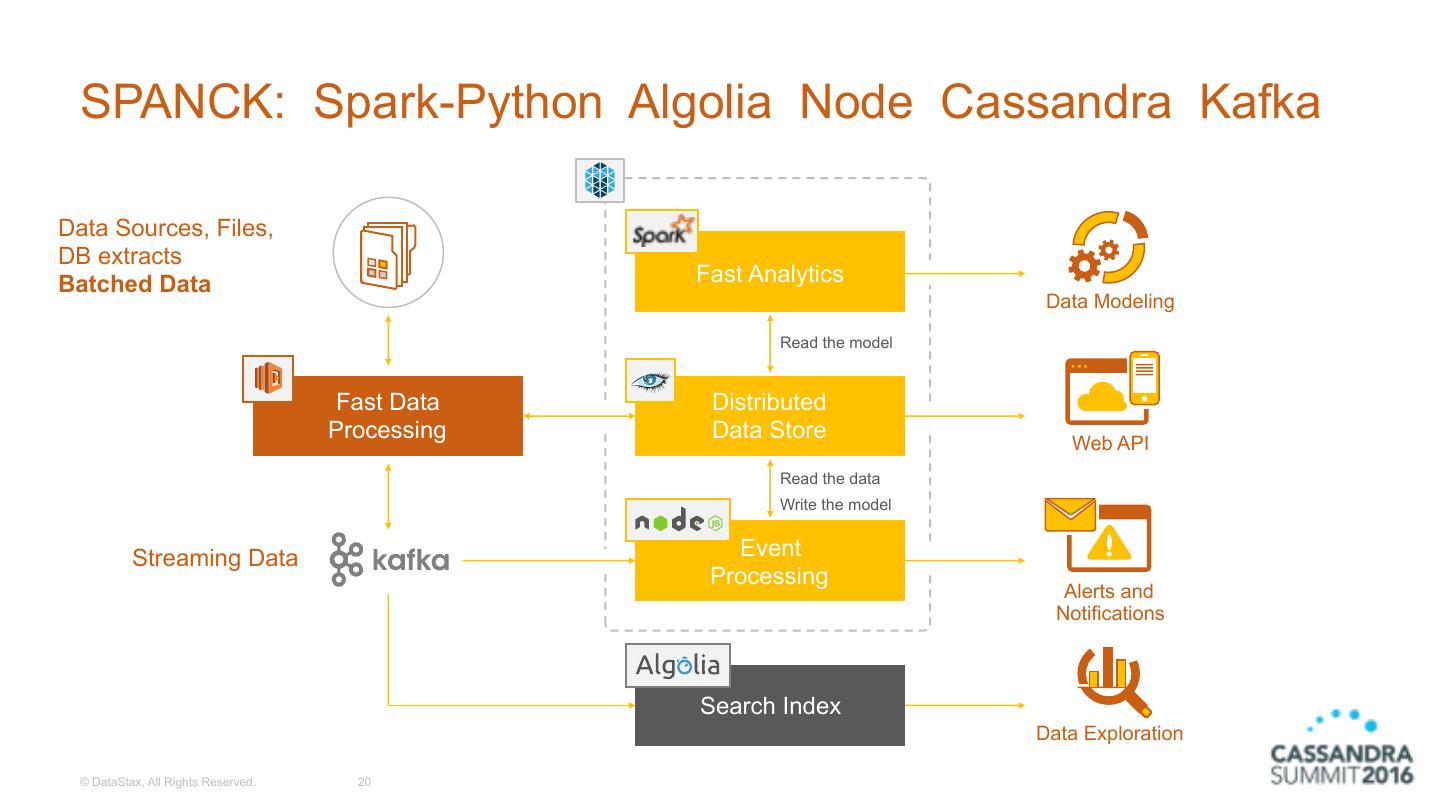
20 . SPANCK: Spark-Python Algolia Node Cassandra Kafka Data Sources, Files, DB extracts Batched Data Fast Analytics Data Modeling Read the model Fast Data Distributed Processing Data Store Web API Read the data Write the model Streaming Data Event Processing Alerts and Notifications Search Index Data Exploration © DataStax, All Rights Reserved. 20
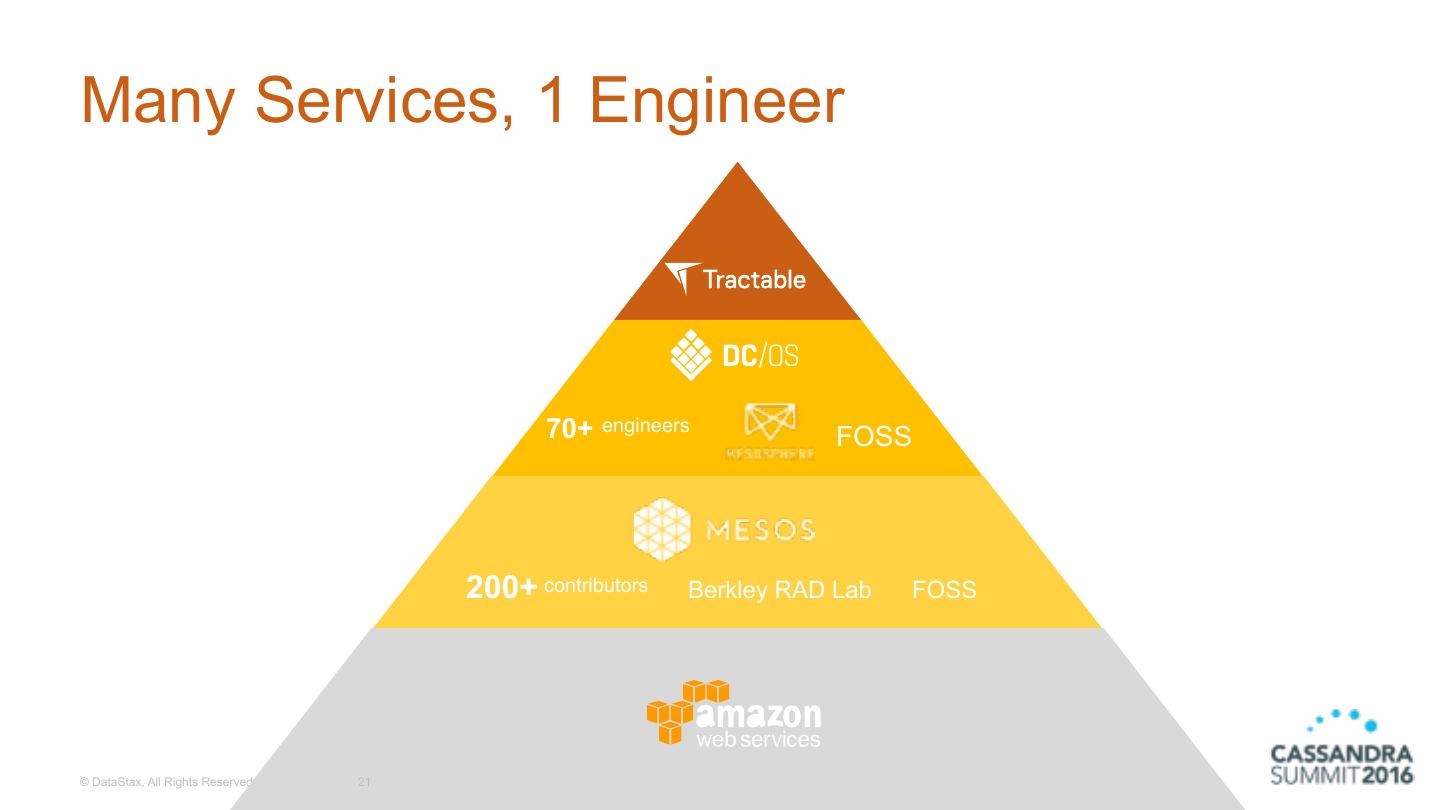
21 .Many Services, 1 Engineer 70+ engineers FOSS 200+ contributors Berkley RAD Lab FOSS © DataStax, All Rights Reserved. 21
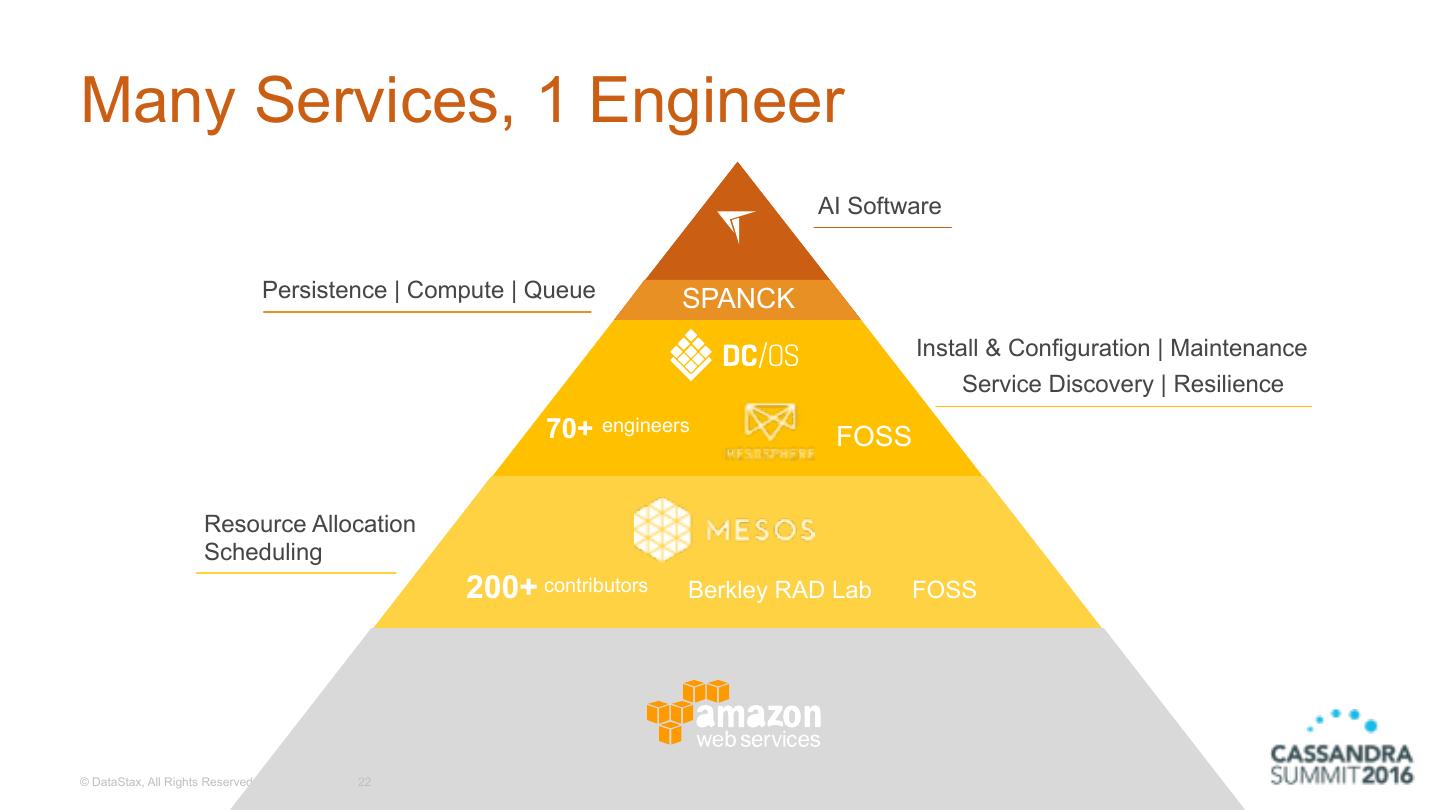
22 .Many Services, 1 Engineer AI Software Persistence | Compute | Queue SPANCK Install & Configuration | Maintenance Service Discovery | Resilience 70+ engineers FOSS Resource Allocation Scheduling 200+ contributors Berkley RAD Lab FOSS © DataStax, All Rights Reserved. 22
23 . DCOS Frameworks Easy Install { "nodes": { "count": 12, $ dcos package install kafka -- "cpus": 9, options kafka-options.json "mem": 30000, "disk": 400000, $ dcos package install cassandra -- "heap": { options cassandra-options.json "size": 8000, "new": 1500 } }, "cassandra": { "row_cache_size_in_mb": 12000, "row_cache_save_period": 600, "commitlog_segment_size_in_mb": 64, "concurrent_reads": 24, "concurrent_writes": 64, "memtable_allocation_type": "offheap_objects", "compaction_throughput_mb_per_sec": 128 } } © DataStax, All Rights Reserved. 23
24 .DCOS Frameworks Service Discovery function fetchMarathonServiceBaseUrl(serviceName){ var dns_url = ['_' + serviceName, "_tcp.marathon.mesos"].join('.'); return resolveSrv(dns_url).then(function(addresses){ • 0 configuration files return "http://" + addresses[0].name + ":" + addresses[0].port; }) • 0 configuration / orchestration systems } • Works ever time, in every environment fetchCassandraNodes = (mesosHost, authToken) -> mesosDns.fetchMarathonServiceBaseUrl('cassandra').then (baseUrl) -> request( url: baseUrl + "/v1/nodes/connect", headers: headers ).then (result) -> result = JSON.parse(result) return _.pluck(result.nodes, “ip") © DataStax, All Rights Reserved. 24
25 .DCOS Frameworks Maintenance and Admin DCOS Command Line Tools • Replace a C* node dcos cassandra —name=cassandra \ • Backup / Restore C* to AWS S3 cleanup —key_spaces=dev,test • Run C* repair / cleanup • Restart C* nodes • Replace a Kafka broker dcos cassandra —name=cassandra \ • Rebalance Kafka brokers replace node-4 • Restart Kafka brokers dcos kafka broker replace 3 © DataStax, All Rights Reserved. 25
26 .DCOS Frameworks { "id": "/my-app", "cpus": 1, Shipping Docker Apps "mem": 2048, "instances": 1, 1 JSON file "env": { "NODE_ENV": "dev" 1 CLI command }, "container": { "type": "DOCKER", "docker": { Apps include "image": "tractableio/my-app:0.1", "network": "BRIDGE" • Spark Drivers } }, • Web Servers "healthChecks": [ { • Kafka Producers "path": "/healthy", "maxConsecutiveFailures": 2 • Kafka Consumers } ] • APIs } *JSON Slightly simplified © DataStax, All Rights Reserved. 26
27 .DCOS Cluster in 15 minutes 1. Deploy DCOS cluster into AWS using CloudFormation template 2. Install Cassandra & Kafka 3. Deploy app docker containers into DCOS 4. Profit! 27
28 .Conclusion • Cassandra’s high write speeds allow it to ingest features from Deep Networks • Cassandra and Spark provides a powerful compute+storage system • Spark, Cassandra and Kafka can provide a versatile data backbone that supports a range of use cases • Mesosphere DCOS is a low-effort, high-reward way of running distributed systems 28
3秒后跳转登录页面
去登陆

