




















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16/07 - Apache Cassandra multi-dc essentials Summit16
16/07 - Apache Cassandra multi-dc essentials Summit16
展开查看详情
1 .Apache Cassandra multi-dc essentials Julien Anguenot (@anguenot) VP Software Engineering, iland cloud
2 .1 key notions & configuration 2 bootstrapping & decommissioning new DCs / nodes 3 operations pain points 4 q&a 2
3 .iland cloud? • public / private cloud provider • footprint in U.S., EU and Asia • compliance, advanced security • custom SLA • Apache Cassandra users since 1.2 C* summit 2015 presentation: http:// www.slideshare.net/anguenot/leveraging- cassandra-for-realtime-multidatacenter- public-cloud-analytics Apache Cassandra spanning 6 datacenters. • http://www.iland.com 3
4 .key notions & configuration
5 .What is Apache Cassandra? • distributed partitioned row store • physical multi-datacenter native support • tailored (features) for multi-datacenter deployment 5
6 .Why multi-dc deployments? • multi-datacenter distributed application • performances read / write isolation or geographical distribution • disaster recovery (DR) failover and redundancy • analytics 6
7 .Essentially… • sequential writes in commit log (flat files) • indexed and written in memtables (in-memory: write-back cache) • serialized to disk in a SSTable data file • writes are partitioned and replicated automatically in cluster • SSTables consolidated though compaction to clean tombstones • repairs to ensure consistency cluster wide 7
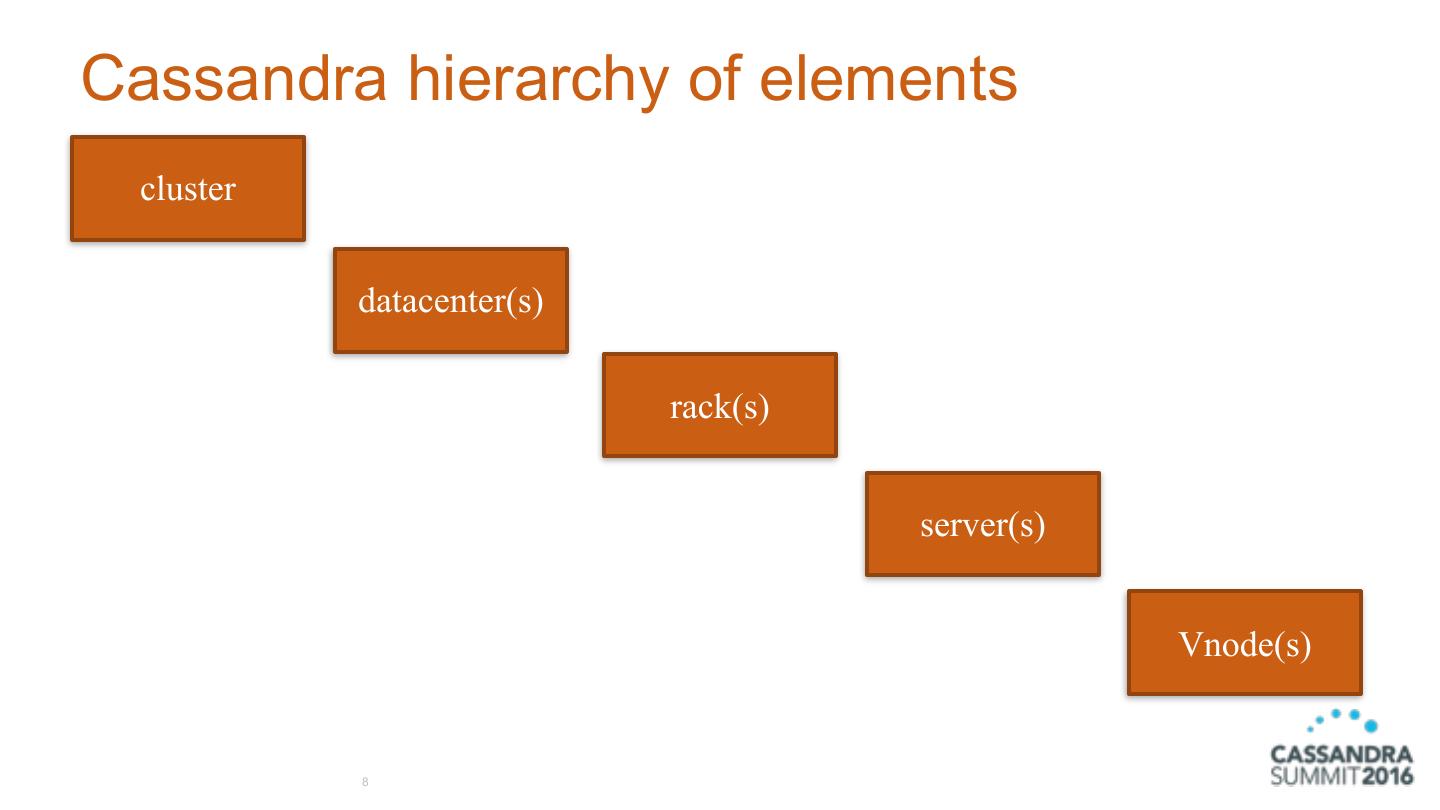
8 .Cassandra hierarchy of elements cluster datacenter(s) rack(s) server(s) Vnode(s) 8
9 .Cassandra cluster • the sum total of all the servers in your database throughout all datacenters • span physical locations • defines one or more keyspaces • no cross-cluster replication 9
10 .cassandra.yaml: `cluster_name` # The name of the cluster. This is mainly used to prevent machines in # one logical cluster from joining another. cluster_name: ‘my little cluster' 10
11 .Cassandra datacenter • grouping of nodes • synonymous with replication group • a grouping of nodes configured together for replication purposes • each datacenter contains a complete token ring • collection of Cassandra racks 11
12 .Cassandra rack • collection of servers • at least one (1) rack per datacenter • one (1) rack is the most simple and common setup 12
13 .Cassandra server • Cassandra (the software) instance installed on a machine • AKA node • contains virtual nodes (or Vnodes). 256 by default 13
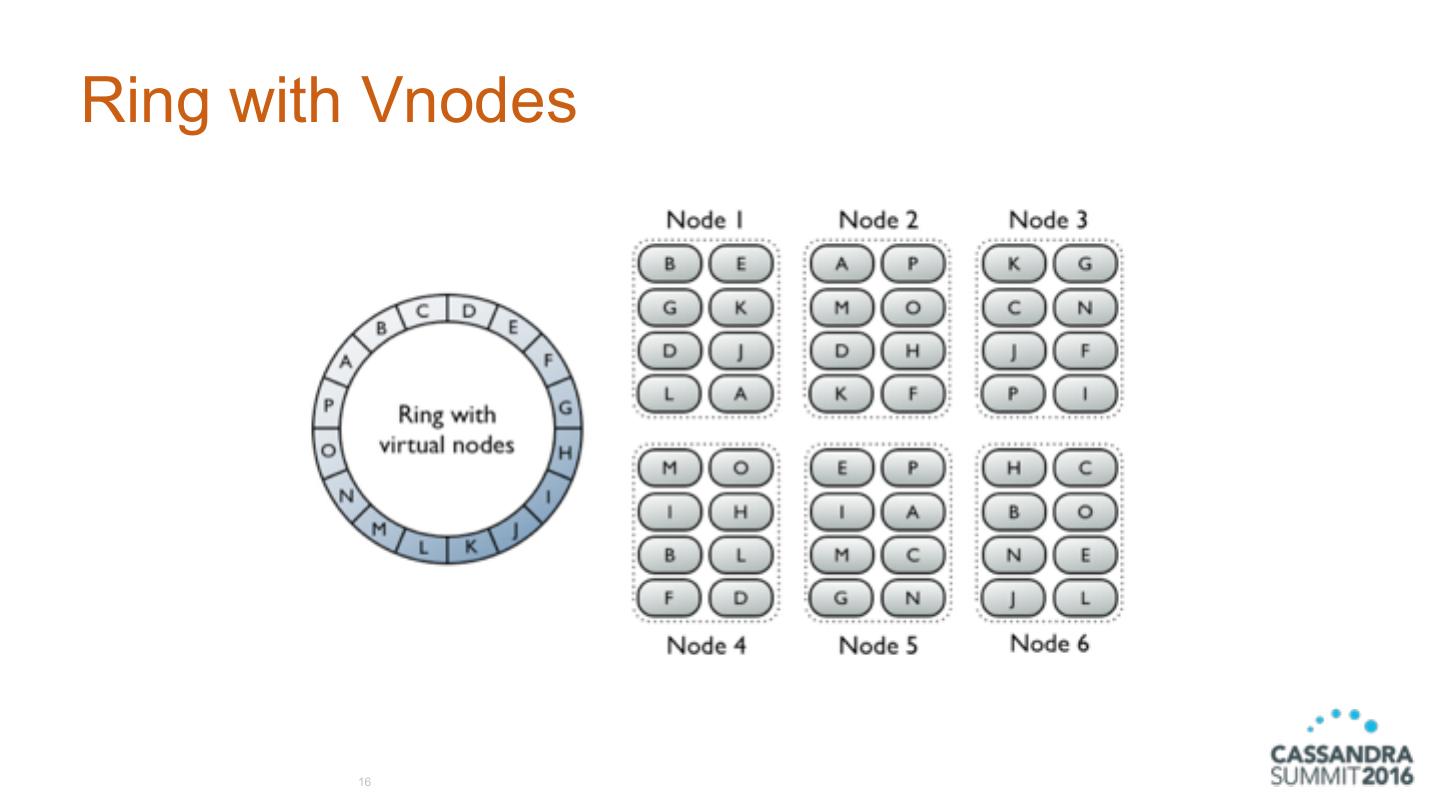
14 .Virtual nodes (Vnodes) • C* >= 1.2 • data storage layer within a server • tokens automatically calculated and assigned randomly for all Vnodes • automatic rebalancing • no manual token generation and assignment • default to 256 (num_tokens in cassandra.yaml) 14
15 .cassandra.yaml: `num_tokens` # This defines the number of tokens randomly assigned to this node on the ring # The more tokens, relative to other nodes, the larger the proportion of data # that this node will store. You probably want all nodes to have the same number # of tokens assuming they have equal hardware capability. # # If you leave this unspecified, Cassandra will use the default of 1 token for legacy compatibility, # and will use the initial_token as described below. # # Specifying initial_token will override this setting on the node's initial start, # on subsequent starts, this setting will apply even if initial token is set. # # If you already have a cluster with 1 token per node, and wish to migrate to # multiple tokens per node, see http://wiki.apache.org/cassandra/Operations num_tokens: 256 15
16 .Ring with Vnodes 16
17 .Partition • individual unit of data • partitions are replicated across multiple Vnodes • each copy of the partition is called a replica 17
18 .Vnodes and consistent hashing • allows distribution of data across a cluster • Cassandra assigns a hash value to each partition key • each Vnode in the cluster is responsible for a range of data based on the hash value • Cassandra places the data on each node according to the value of the partition key and the range that the node is responsible for 18
19 .Partitioner (1/2) • partitions the data across the cluster • function for deriving a token representing a row from its partition key • hashing function • each row of data is then distributed across the cluster by the value of the token 19
20 .Partitioner (2/2) • Murmur3Partitioner (default C* >= 1.2) uniformly distributes data across the cluster based on MurmurHash hash values • RandomPartitioner (default C* < 1.2) uniformly distributes data across the cluster based on MD5 hash values • ByteOrderedPartitioner (BBB) keeps an ordered distribution of data lexically by key bytes 20
21 .cassandra.yaml: `partitioner` # The partitioner is responsible for distributing groups of rows (by # partition key) across nodes in the cluster. You should leave this # alone for new clusters. The partitioner can NOT be changed without # reloading all data, so when upgrading you should set this to the # same partitioner you were already using. # # Besides Murmur3Partitioner, partitioners included for backwards # compatibility include RandomPartitioner, ByteOrderedPartitioner, and # OrderPreservingPartitioner. # partitioner: org.apache.cassandra.dht.Murmur3Partitioner 21
22 .Partitioner example (1/4) Credits to Datastax. Extract from documentation. 22
23 .Partitioner example (2/4) Credits to Datastax. Extract from documentation. 23
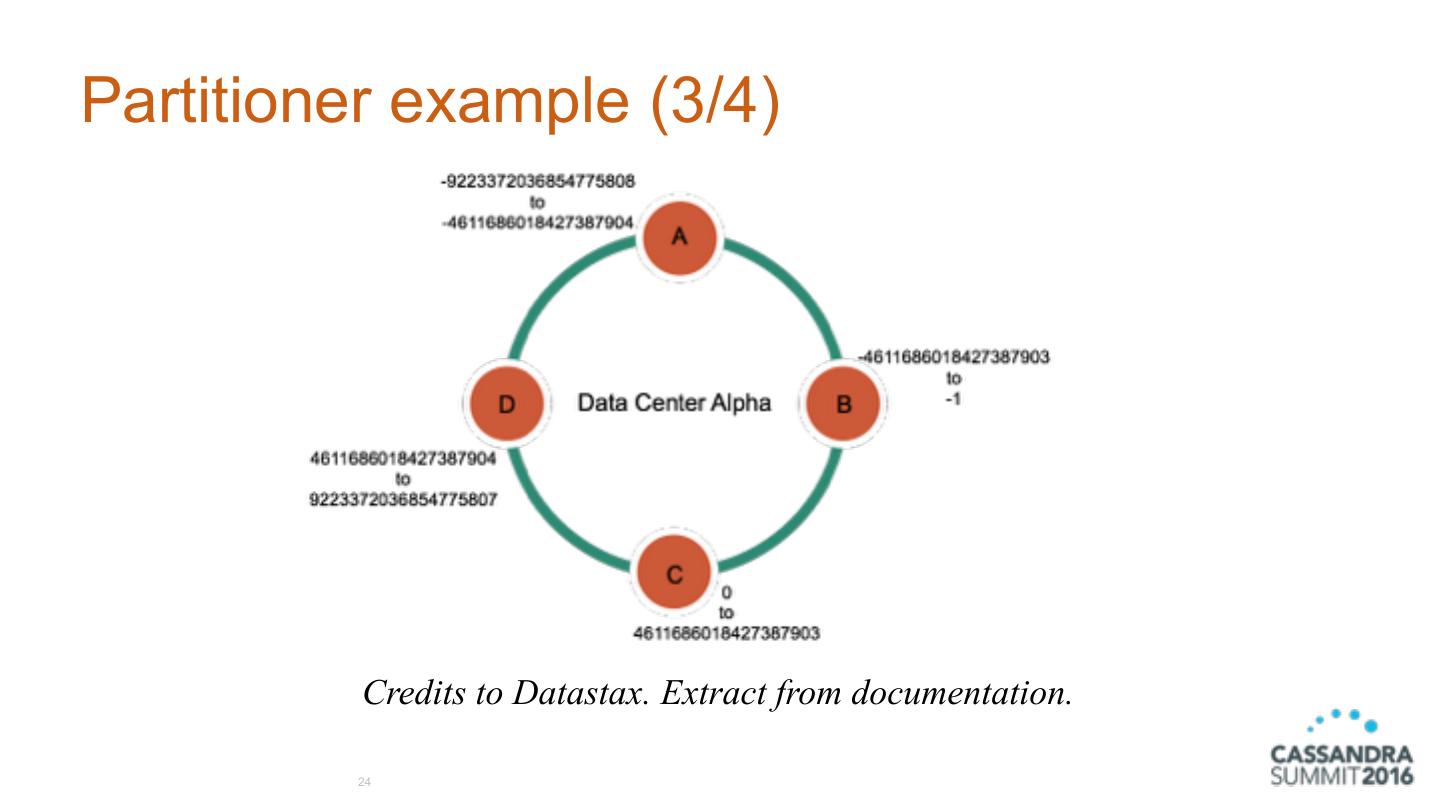
24 .Partitioner example (3/4) Credits to Datastax. Extract from documentation. 24
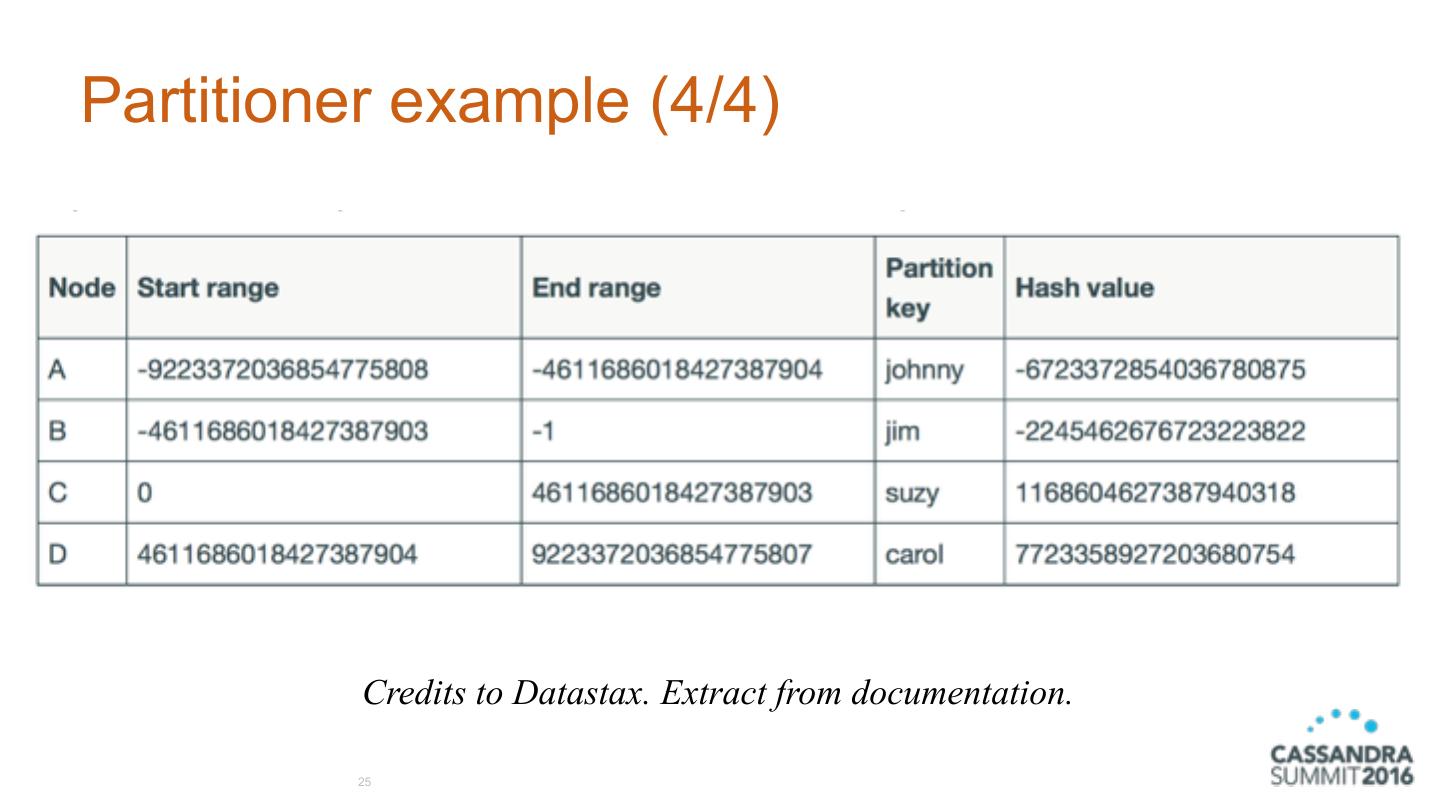
25 .Partitioner example (4/4) Credits to Datastax. Extract from documentation. 25
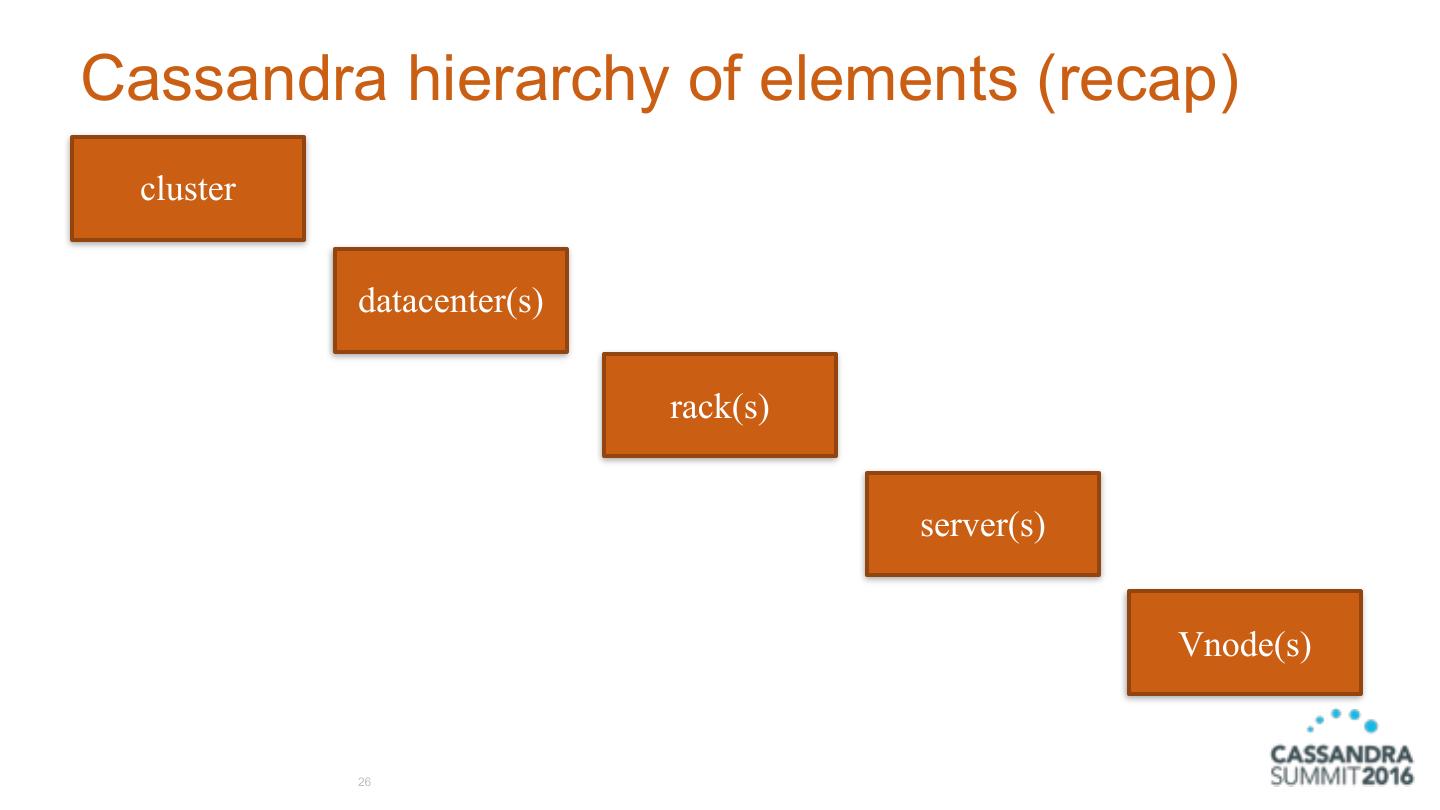
26 .Cassandra hierarchy of elements (recap) cluster datacenter(s) rack(s) server(s) Vnode(s) 26
27 .Cassandra Keyspace (KS) • namespace container that defines how data is replicated on nodes • cluster defines KS • contains tables • defines the replica placement strategy and the number of replicas 27
28 .Data replication • process of storing copies (replicas) on multiple nodes • KS has a replication factor (RF) and replica placement strategy • max (RF) = max(number of nodes) in one (1) data center • data replication is defined per datacenter 28
29 .Replica placement strategy there are two (2) available replication strategies: 1. SimpleStrategy (single DC) 2. NetworkTopologyStrategy (recommended cause easier to expand) choose strategy depending on failure scenarios and application needs for consistency level 29
3秒后跳转登录页面
去登陆

