













































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
15:11 - Real-Time Analytics with Apache Cassandra and Apache Spa
15/11 - Real-Time Analytics with Apache Cassandra and Apache Spark
展开查看详情
1 .Real-Time Analytics with Apache Cassandra and Apache Spark Guido Schmutz BÂLE BERNE BRUGG DUSSELDORF FRANCFORT S.M. FRIBOURG E.BR. GENÈVE HAMBOURG COPENHAGUE LAUSANNE MUNICH STUTTGART VIENNE ZURICH
2 .Guido Schmutz • Working for Trivadis for more than 18 years • Oracle ACE Director for Fusion Middleware and SOA • Author of different books • Consultant, Trainer Software Architect for Java, Oracle, SOA and Big Data / Fast Data • Technology Manager @ Trivadis • More than 25 years of software development experience • Contact: guido.schmutz@trivadis.com • Blog: http://guidoschmutz.wordpress.com • Twitter: gschmutz
3 .Agenda 1. Introduction 2. Apache Spark 3. Apache Cassandra 4. Combining Spark & Cassandra 5. Summary
4 . Big Data Definition (4 Vs) Characteristics of Big Data: Its Volume, Velocity and Variety in combination + Time to action ? – Big Data + Real-Time = Stream Processing
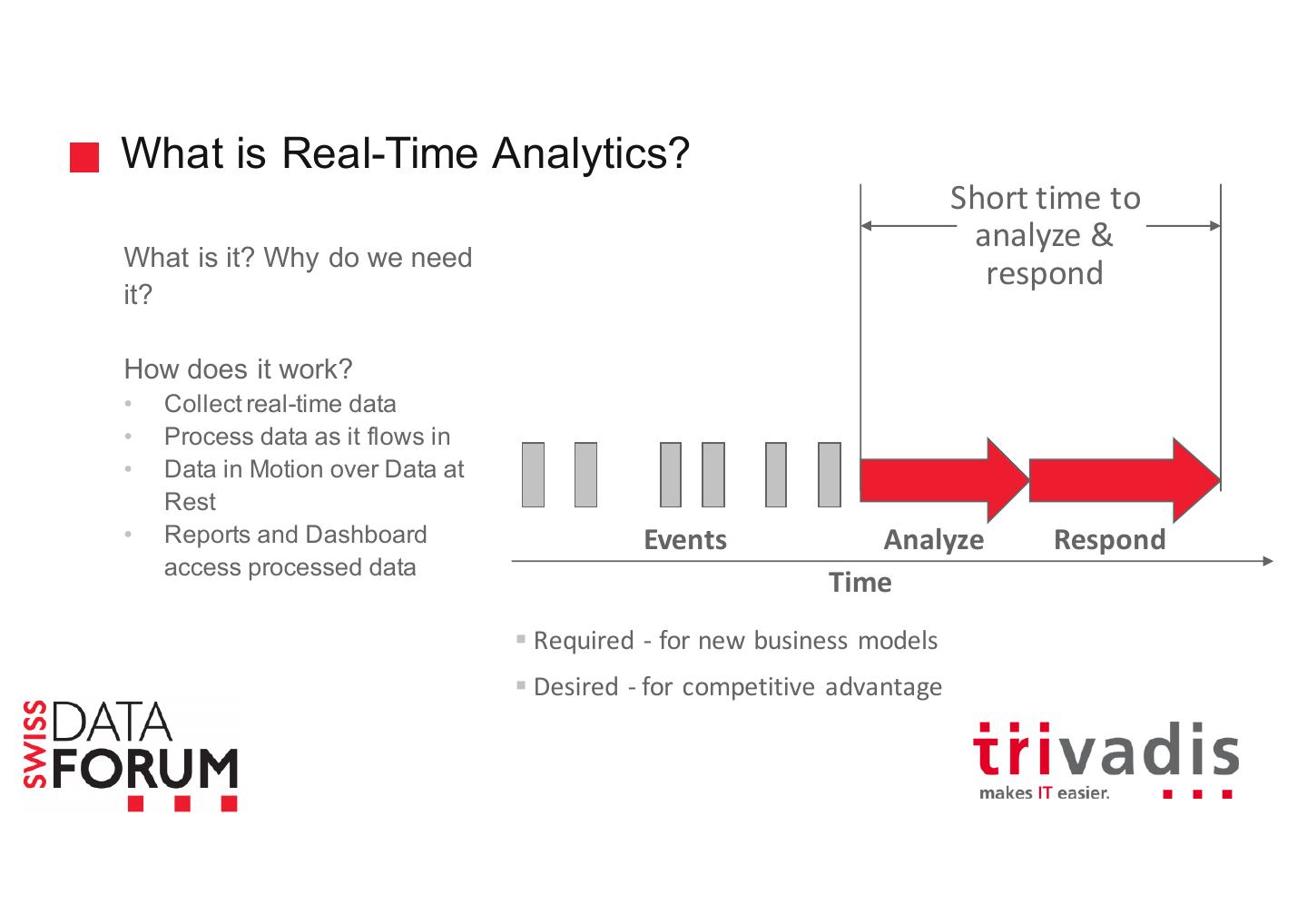
5 .What is Real-Time Analytics? Short time to analyze & What is it? Why do we need respond it? How does it work? • Collect real-time data • Process data as it flows in • Data in Motion over Data at Rest • Reports and Dashboard Events Analyze Respond access processed data Time § Required - for new business models § Desired - for competitive advantage
6 .Real Time Analytics Use Cases • Algorithmic Trading • Recommendations • Online Fraud Detection • Churn detection • Geo Fencing • Internet of Things (IoT) / Intelligence • Proximity/Location Tracking Sensors • Intrusion detection systems • Social Media/Data Analytics • Traffic Management • Gaming Data Feed • …
7 .Apache Spark
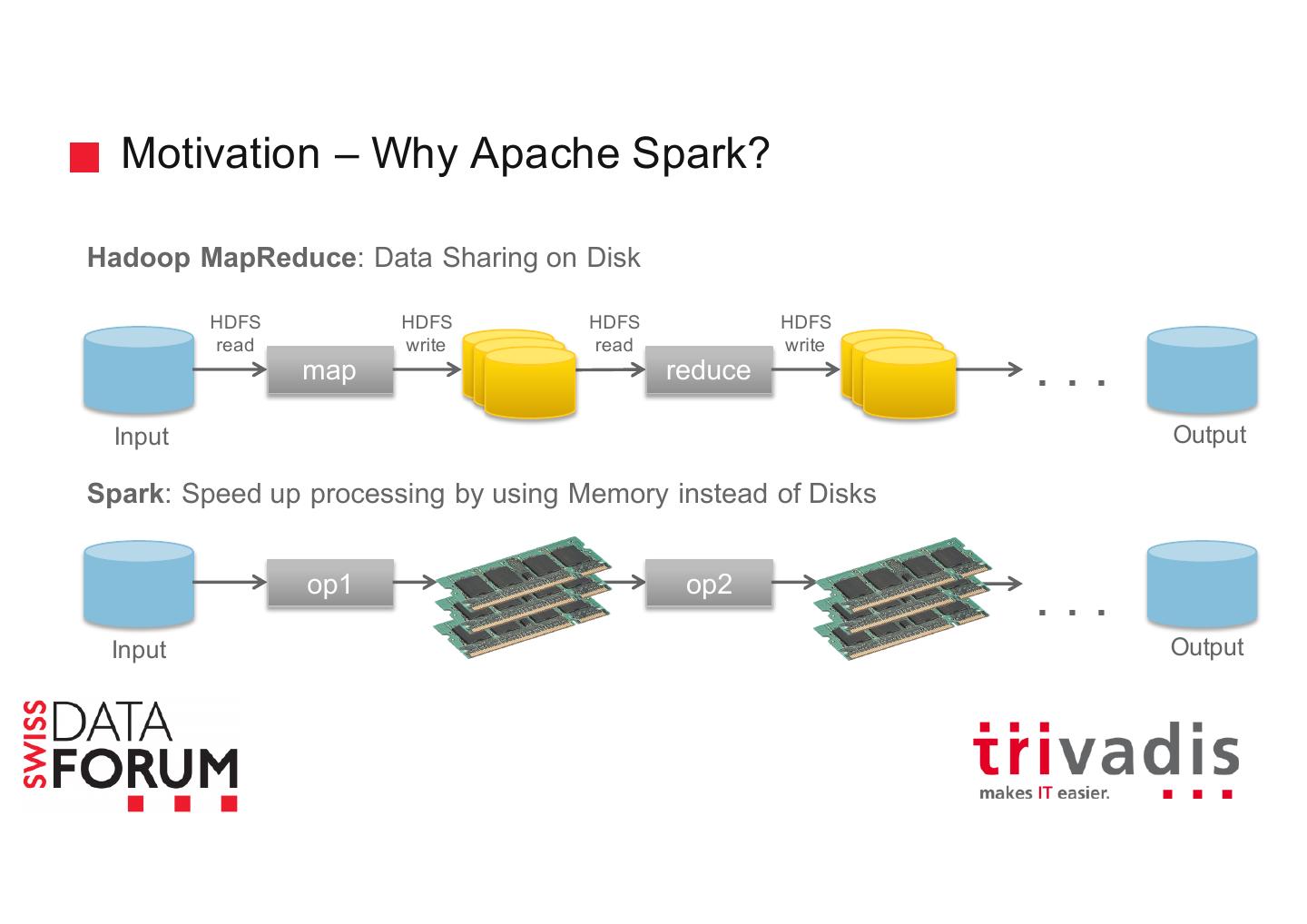
8 . Motivation – Why Apache Spark? Hadoop MapReduce: Data Sharing on Disk HDFS HDFS HDFS HDFS read write read write map reduce . . . Input Output Spark: Speed up processing by using Memory instead of Disks op1 op2 . . . Input Output
9 .Apache Spark Apache Spark is a fast and general engine for large-scale data processing • The hot trend in Big Data! • Originally developed 2009 in UC Berkley’s AMPLab • Based on 2007 Microsoft Dryad paper • Written in Scala, supports Java, Python, SQL and R • Can run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk • One of the largest OSS communities in big data with over 200 contributors in 50+ organizations • Open Sourced in 2010 – since 2014 part of Apache Software foundation
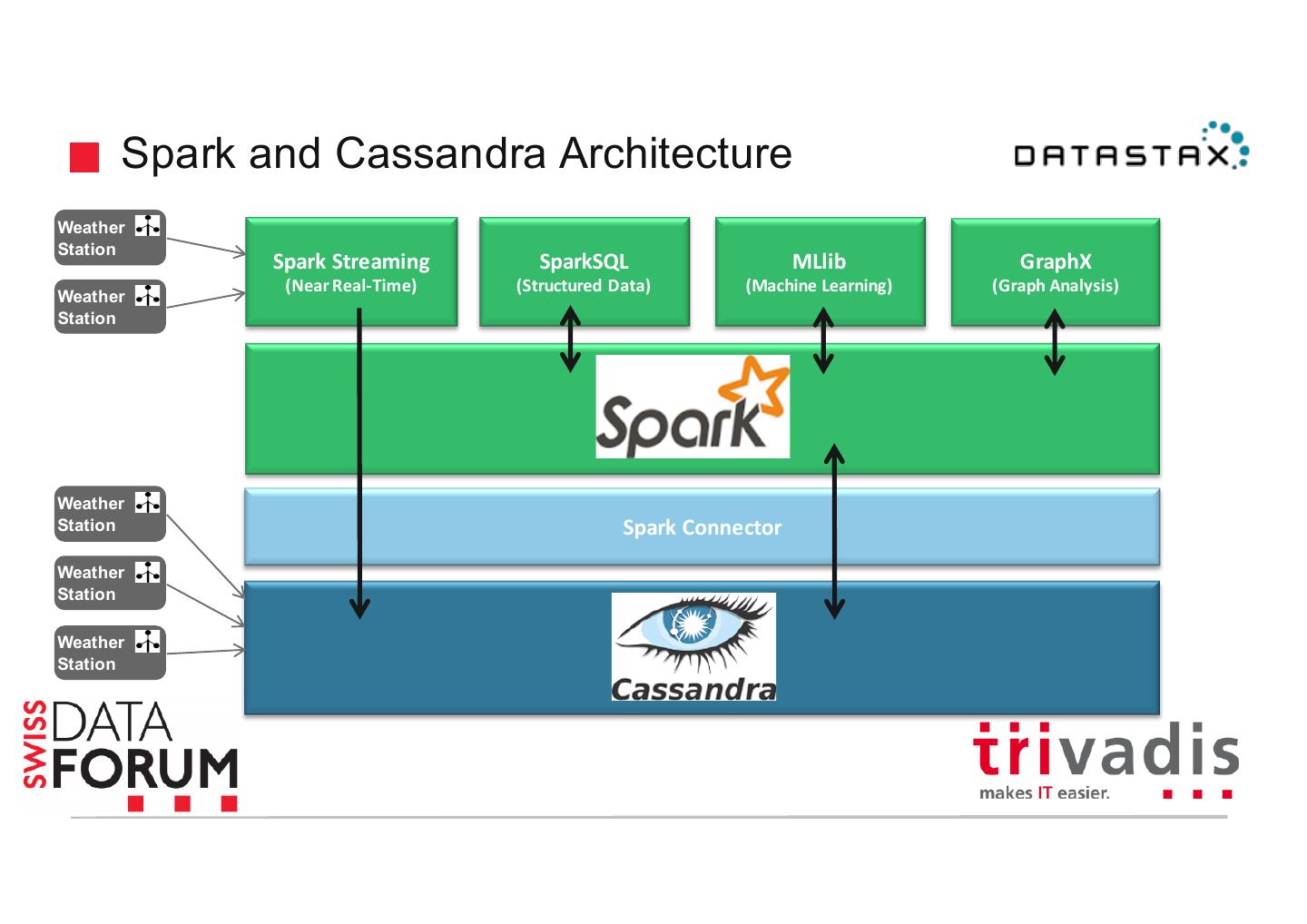
10 . Apache Spark Libraries Blink DB MLlib, Spark R Spark SQL Spark Streaming GraphX (Approximate (Machine (Batch Processing) (Real-Time) (Graph Processing) Querying) Learning) Core Runtime Spark Core API and Execution Model Cluster Resource Managers Data Stores Spark Elastic MESOS YARN HDFS NoSQL S3 Standalone Search
11 .Resilient Distributed Dataset (RDD) Are Have Transformations • Produce new RDD • Immutable • Rich set of transformation available • Re-computable • filter(), flatMap(), map(), • Fault tolerant distinct(), groupBy(), union(), • Reusable join(), sortByKey(), reduceByKey(), subtract(), ... Have Actions • Start cluster computing operations • Rich set of action available • collect(), count(), fold(), reduce(), count(), …
12 . RDD RDD Input Source • File • Database .count() -> 100 • Stream • Collection Data
13 . Partitions RDD Partition 0 Server 1 Partition 1 Partition 2 Server 2 Partition 3 Partition 4 Server 3 Partition 5 Partition 6 Server 4 Partition 7 Partition 8 Server 5 Partition 9 Data
14 . Partitions RDD Partition 0 Server 1 Partition 1 Partition 2 Server 2 Partition 3 Partition 4 Server 3 Partition 5 Partition 6 Server 4 Partition 7 Partition 8 Server 5 Partition 9 Data
15 . Partitions RDD Partition 0 Partition 1 Server 2 Partition 2 Partition 3 Partition 4 Server 3 Partition 5 Partition 6 Server 4 Partition 7 Partition 8 Server 5 Partition 9 Data
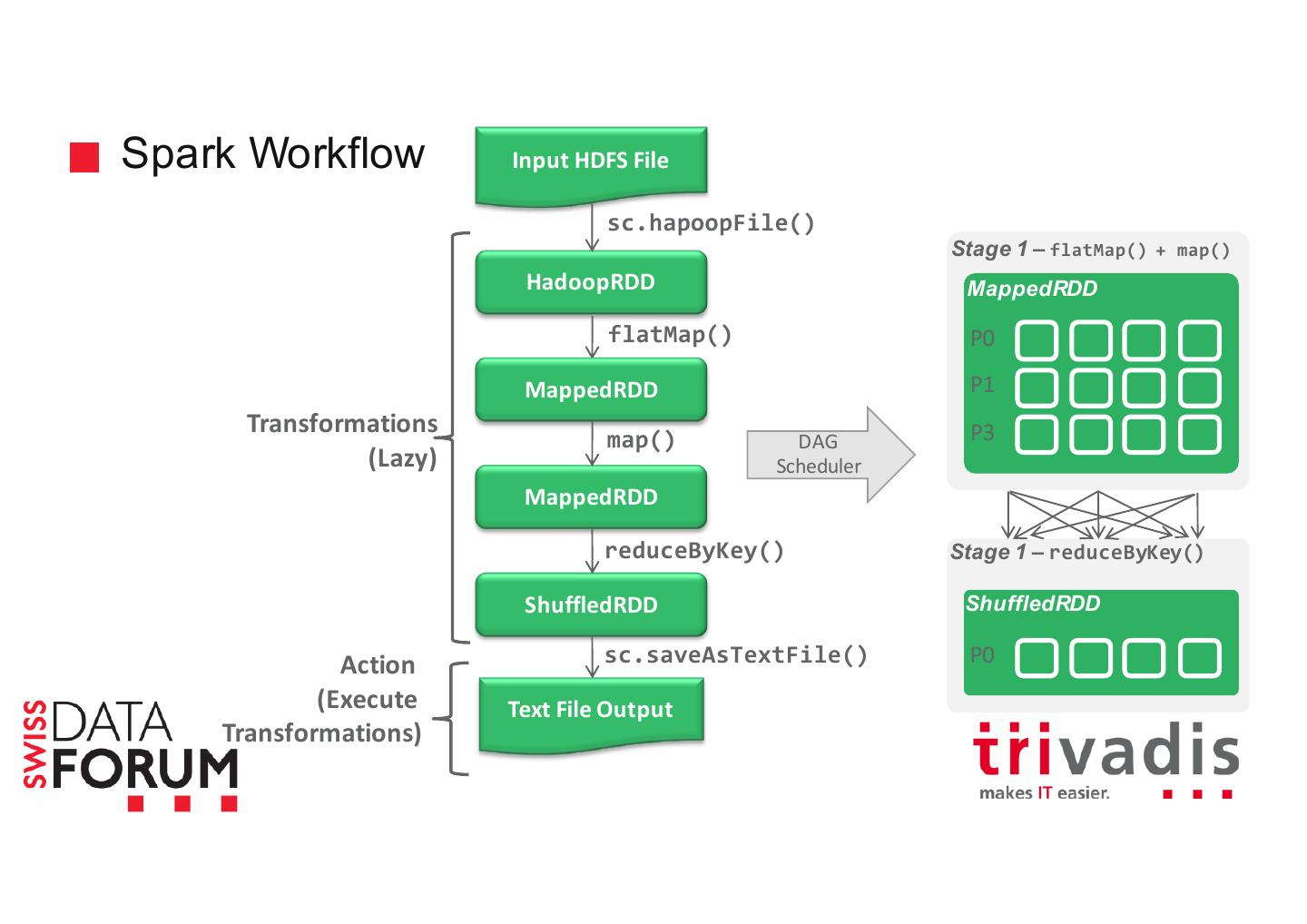
16 .Spark Workflow Input HDFS File sc.hapoopFile() Stage 1 – flatMap() + map() HadoopRDD MappedRDD flatMap() P0 MappedRDD P1 Master Transformations P3 map() DAG (Lazy) Scheduler MappedRDD reduceByKey() Stage 1 – reduceByKey() ShuffledRDD ShuffledRDD Action sc.saveAsTextFile() P0 (Execute Text File Output Transformations)
17 .Spark Workflow HDFS File Input 1 SparkContext.hadoopFile() HDFS File Input 2 HadoopRDD filter() SparkContext.hadoopFile() Transformations FilteredRDD HadoopRDD (Lazy) map() map() MappedRDD MappedRDD join() ShuffledRDD SparkContext.saveAsHadoopFile() Action HDFS File Output (Execute Transformations)
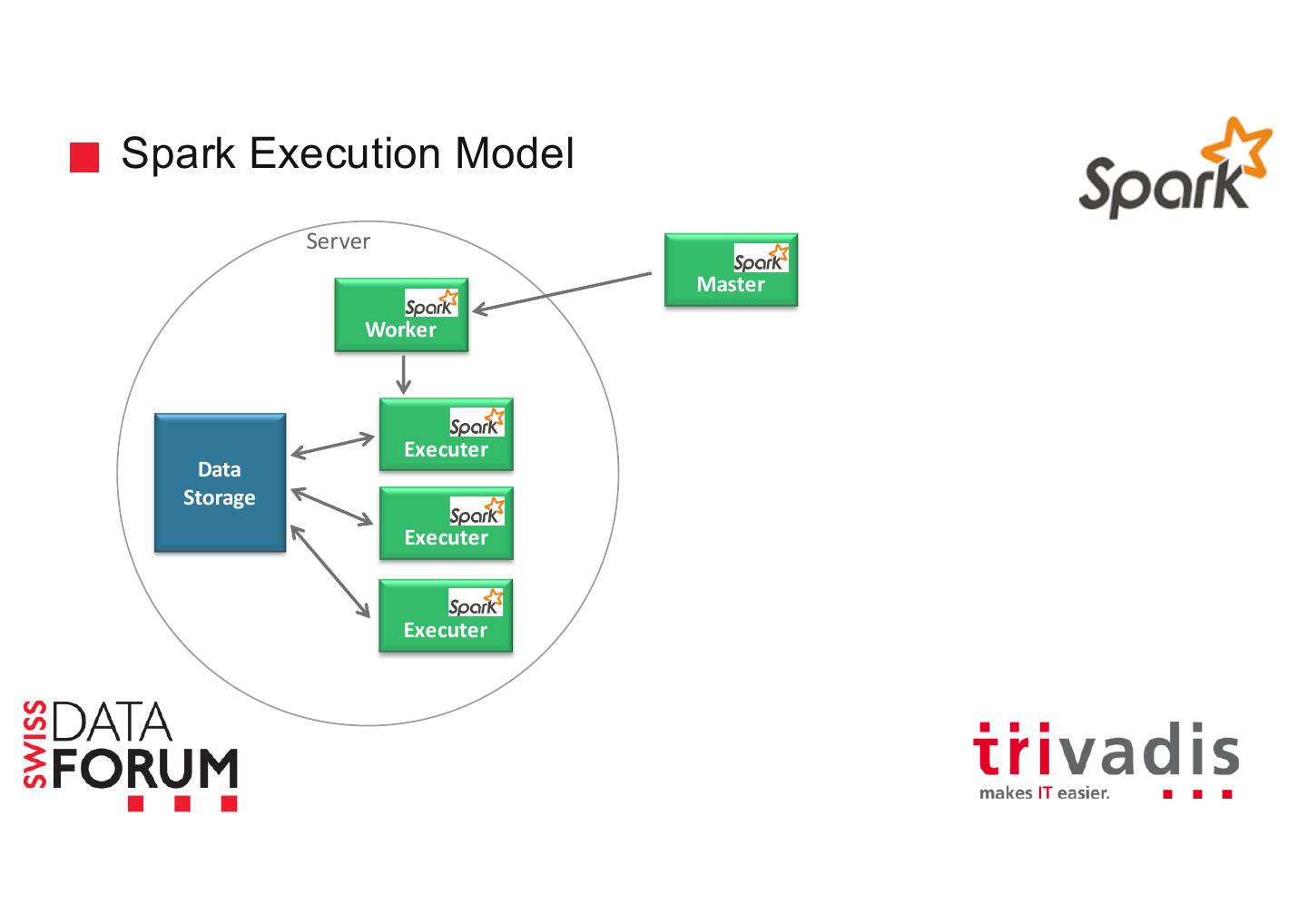
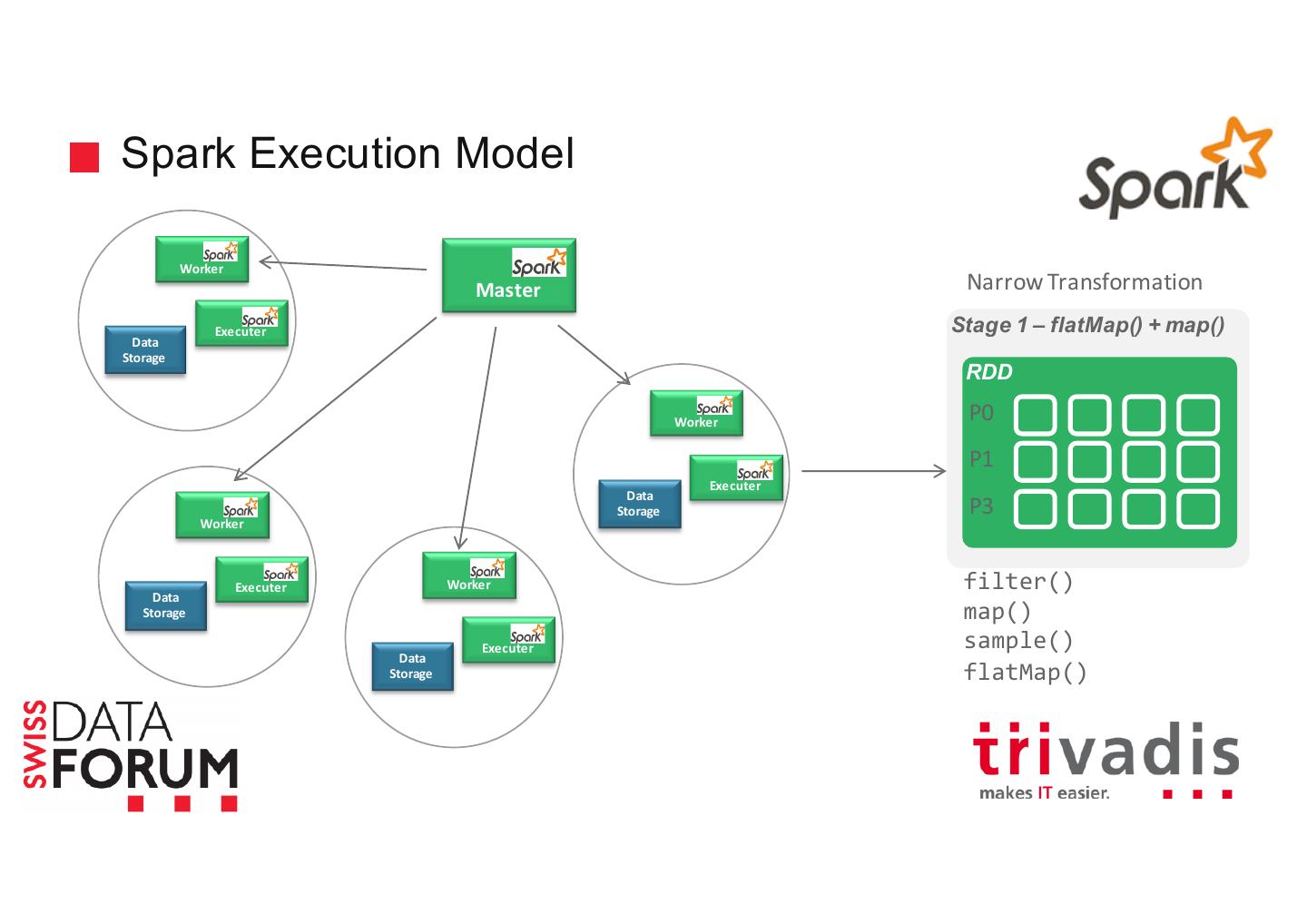
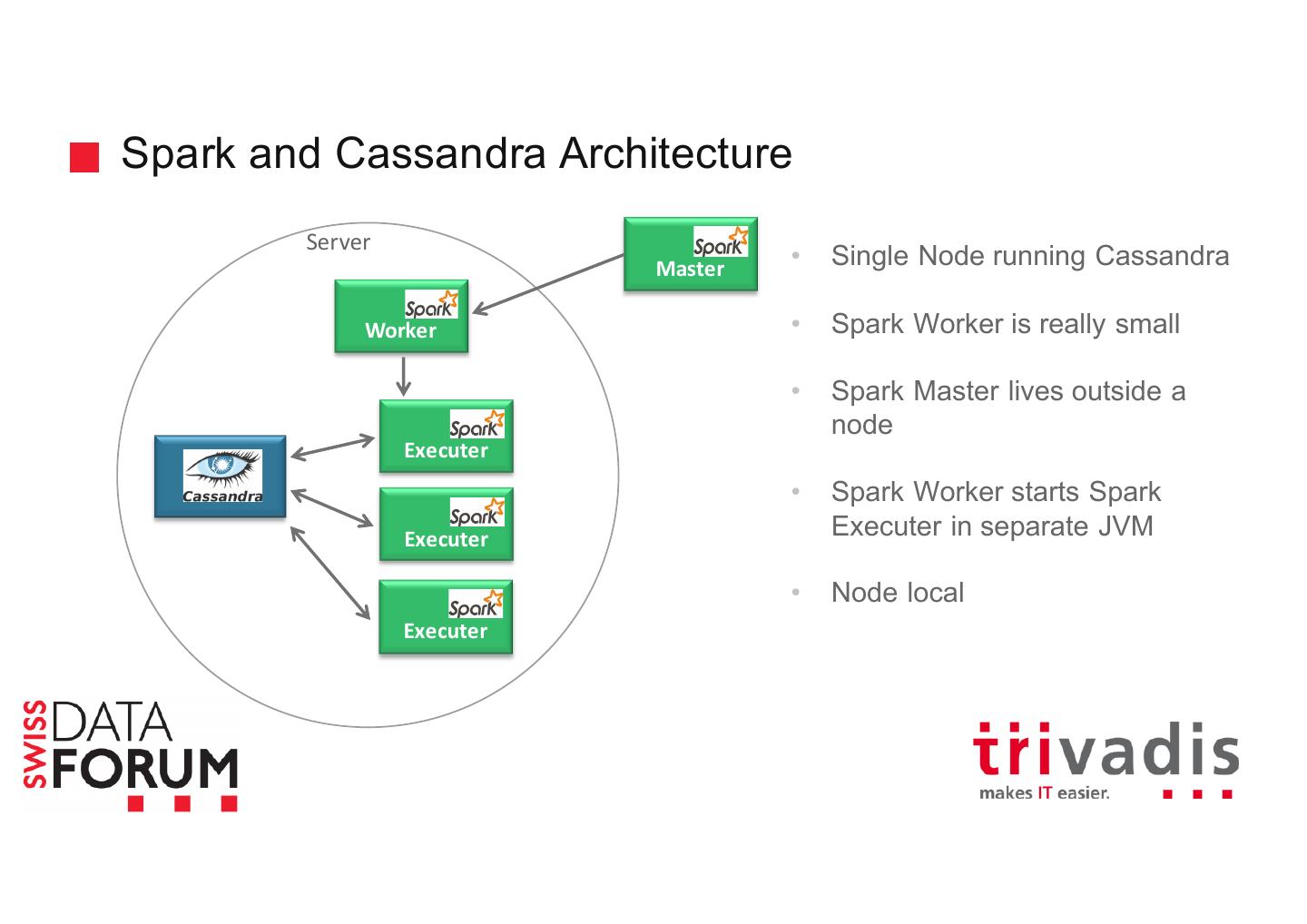
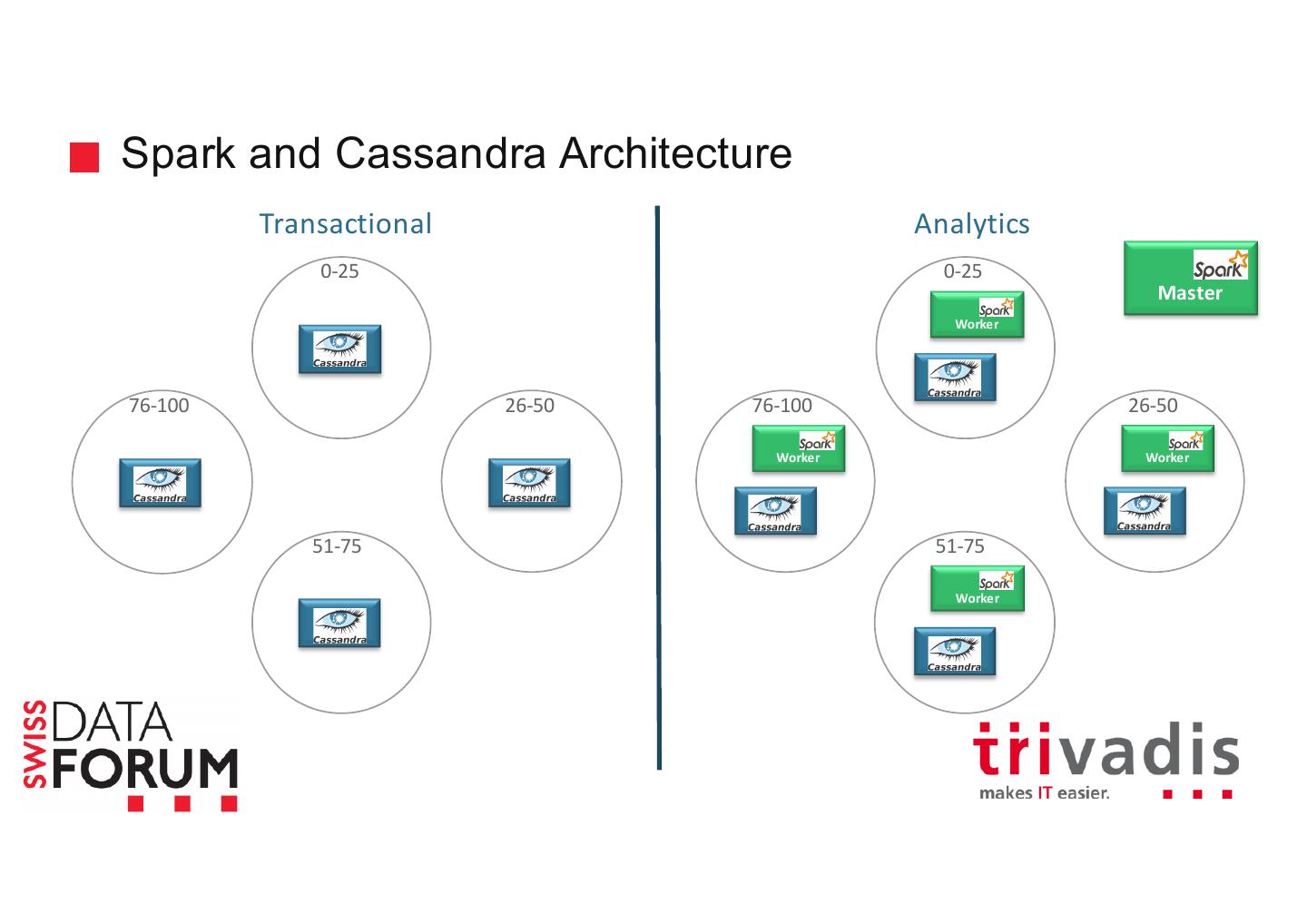
18 .Spark Execution Model Server Master Worker Executer Data Storage Executer Executer
19 .Spark Execution Model Worker Master Narrow Transformation Executer Stage 1 – flatMap() + map() Data Storage RDD Worker P0 P1 Executer Master Data Storage P3 Worker Executer Worker filter() Data Storage map() Executer sample() Data Storage flatMap()
20 .Spark Execution Model Worker Master Executer Data join() Storage reduceByKey() union() Shuffle ! Worker groupByKey() Executer Data Worker Storage Wide Transformation Stage 2 – reduceByKey() Executer Worker Data Storage RDD Executer P0 Data Storage
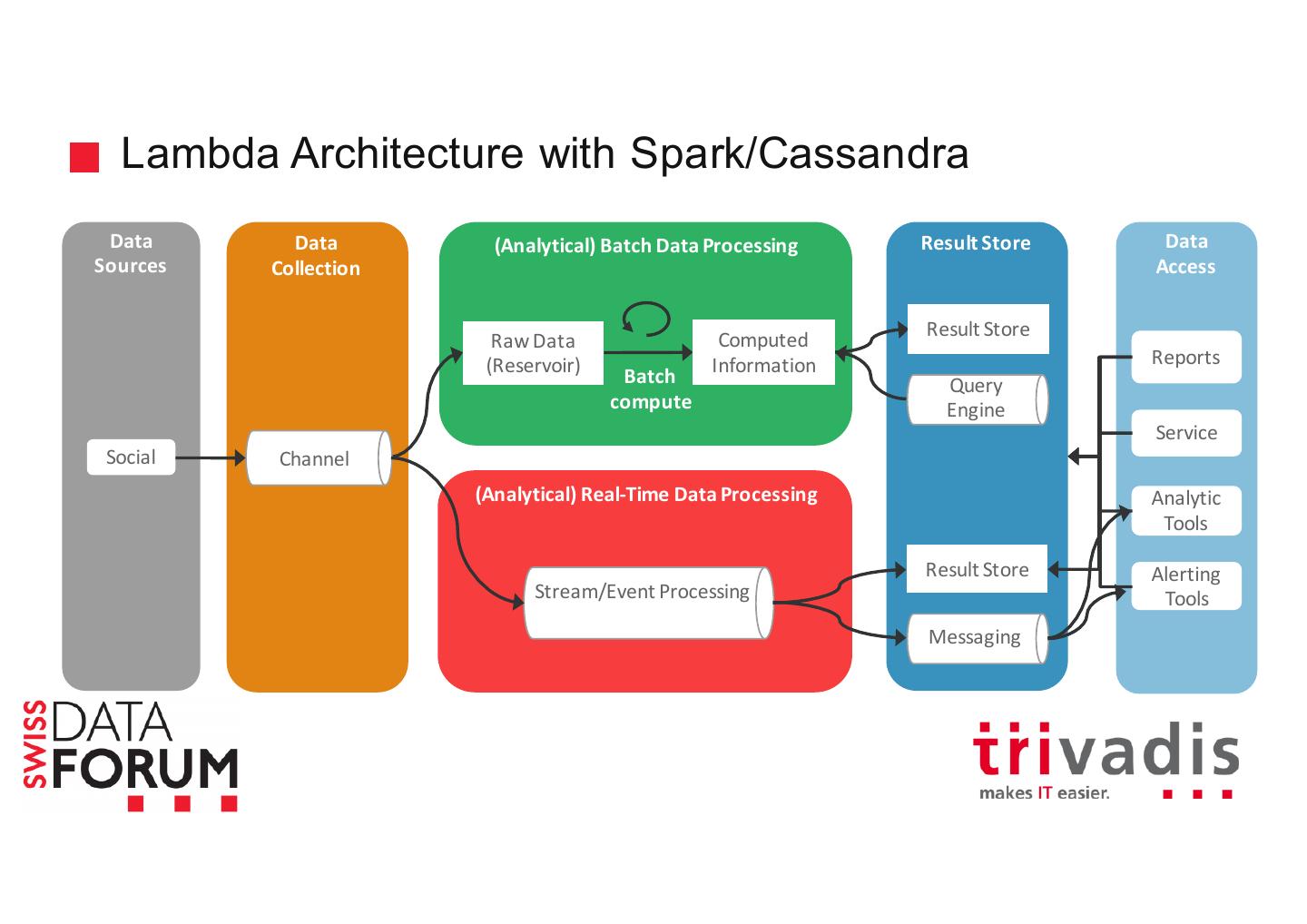
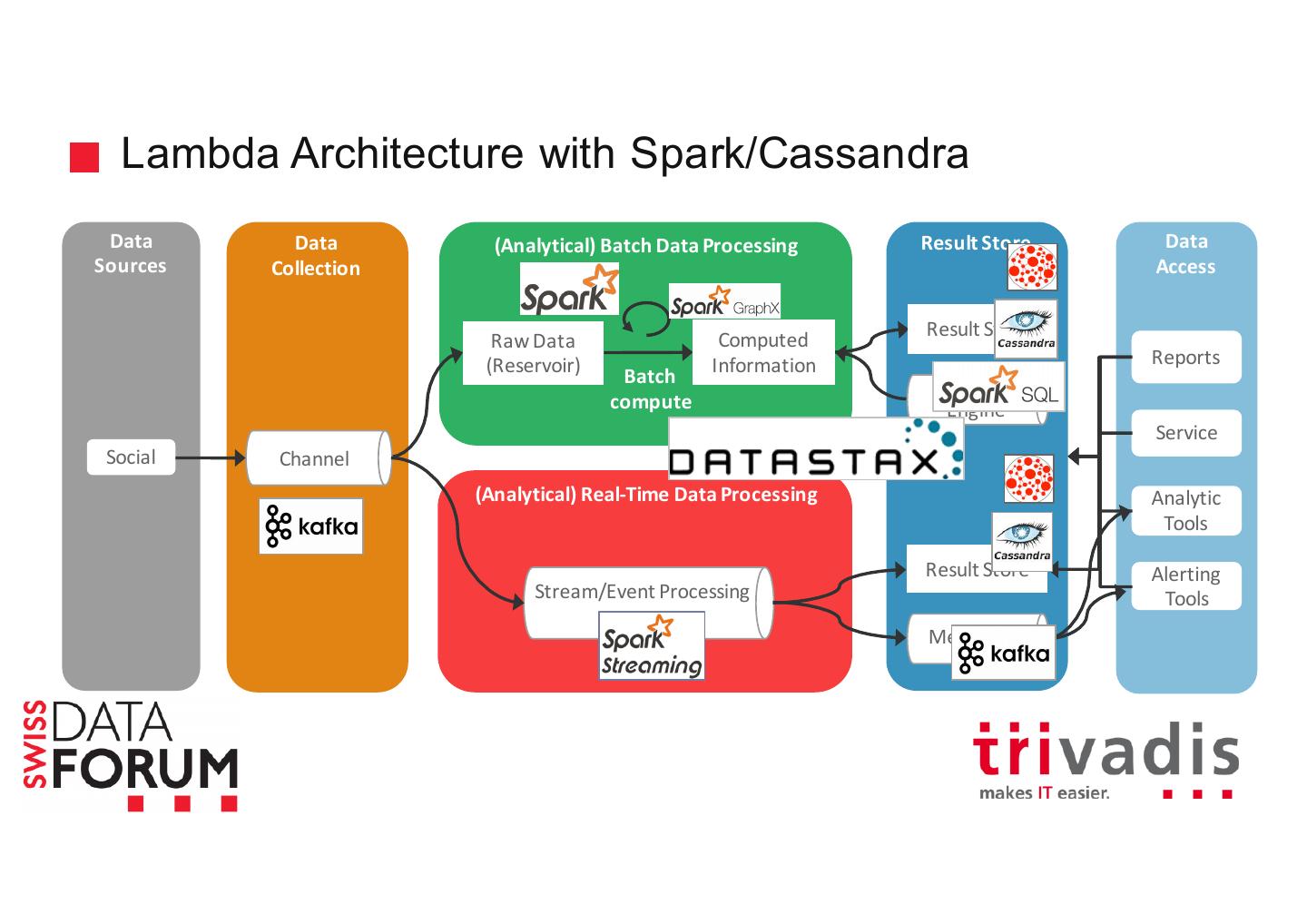
21 .Batch vs. Real-Time Processing Per Second Gigabytes Petabytes of Data
22 .Various Input Sources
23 .Apache Kafka distributed publish-subscribe messaging system Designed for processing of real time activity stream data (logs, metrics collections, social media streams, …) Initially developed at LinkedIn, now part of Apache Producer Producer Producer Does not use JMS API and standards Kafka Cluster Kafka maintains feeds of messages in topics Consumer Consumer Consumer
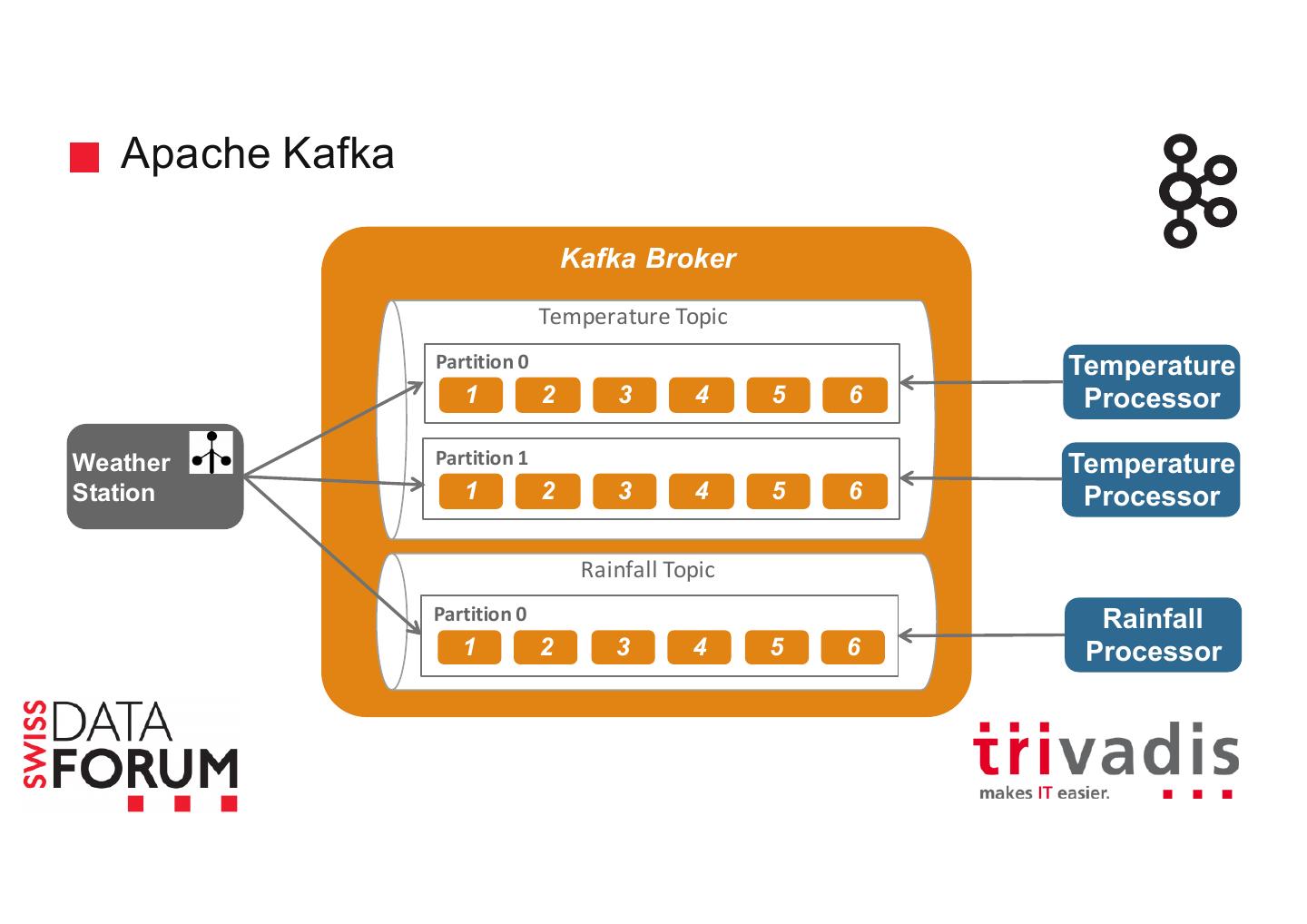
24 . Apache Kafka Kafka Broker Temperature Topic Temperature 1 2 3 4 5 6 Processor Weather Station Rainfall Topic Rainfall 1 2 3 4 5 6 Processor
25 . Apache Kafka Kafka Broker Temperature Topic Partition 0 Temperature 1 2 3 4 5 6 Processor Weather Partition 1 Temperature Station 1 2 3 4 5 6 Processor Rainfall Topic Partition 0 Rainfall 1 2 3 4 5 6 Processor
26 . Apache Kafka Broker Temperature Topic Kafka P 0 1 2 3 4 5 P 1 1 2 3 4 5 Rainfall Topic P 0 1 2 3 4 5 Temperature Processor Weather Station Temperature Kafka Broker Processor Temperature Topic P 0 1 2 3 4 5 P 1 1 2 3 4 5 Rainfall Processor Rainfall Topic P 0 1 2 3 4 5
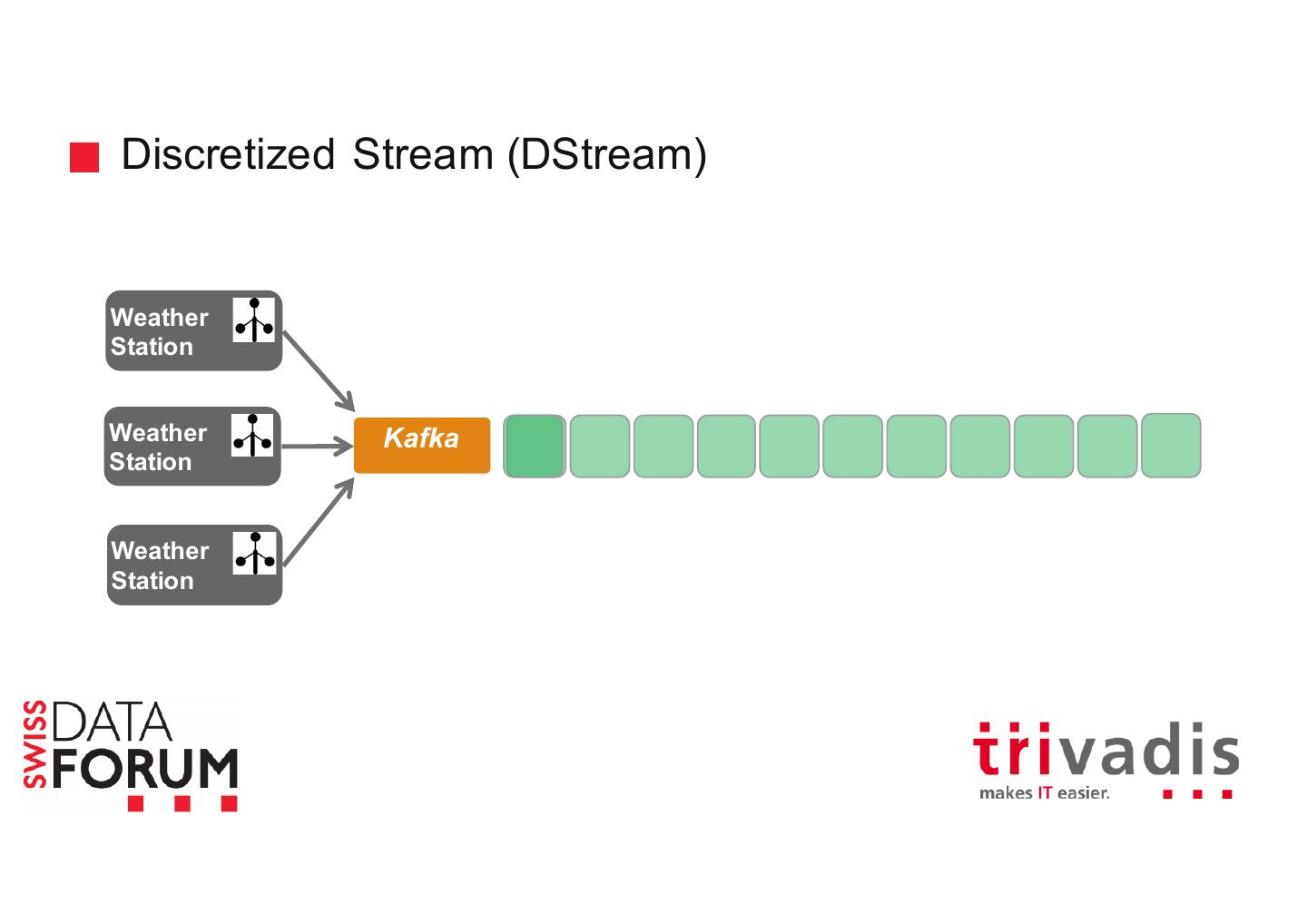
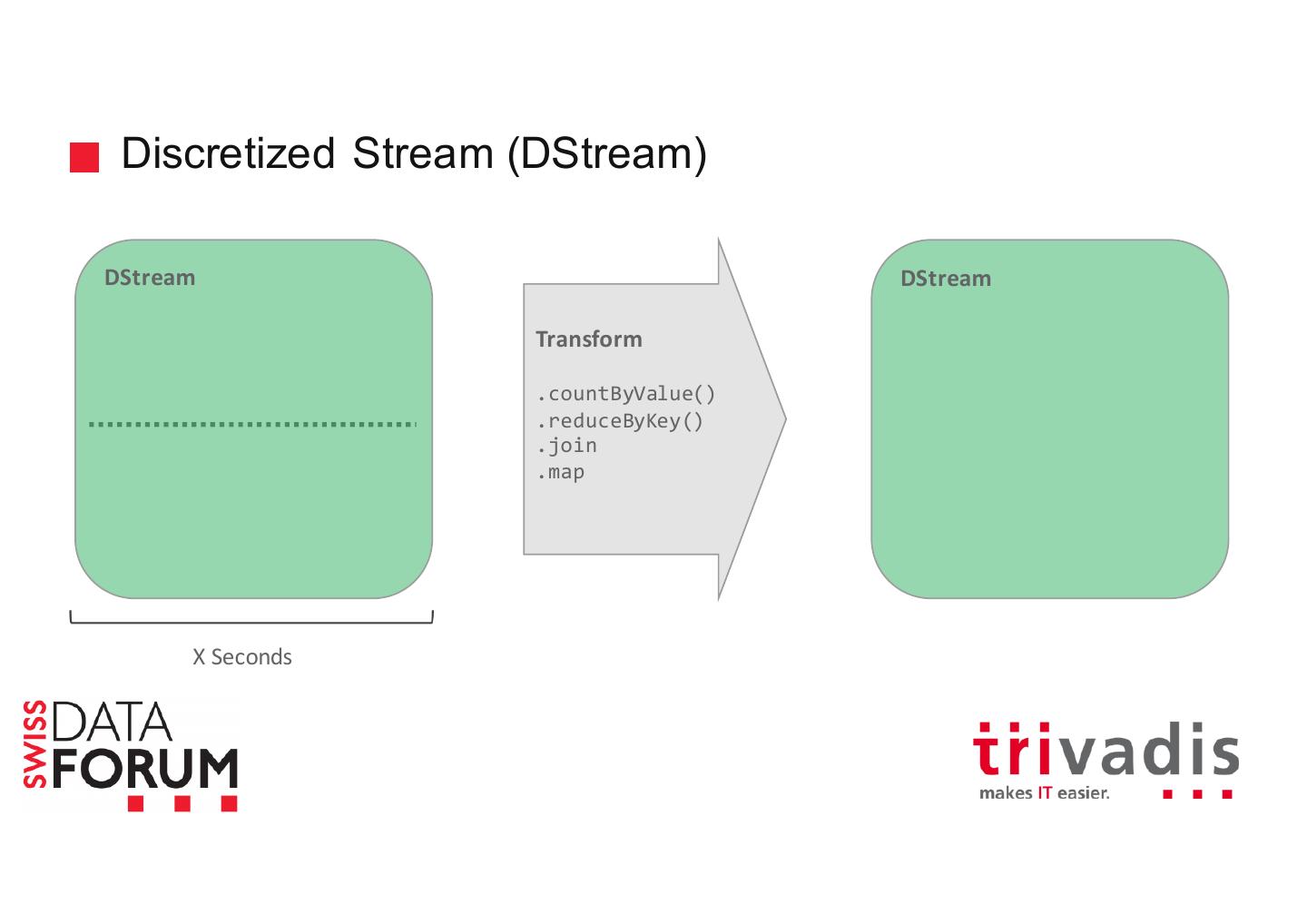
27 .Discretized Stream (DStream) Weather Station Weather Kafka Station Weather Station
28 .Discretized Stream (DStream) Weather Station Weather Kafka Station Weather Station
29 .Discretized Stream (DStream) Weather Station Weather Kafka Station Weather Station
3秒后跳转登录页面
去登陆

