

















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
15:06 - Apache cassandra and spark. you got the the lighter, let
15/06 - Apache cassandra and spark. you got the the lighter, let's start the fire
展开查看详情
1 . Apache Cassandra and Spark You got the lighter, let’s spark the fire Patrick McFadin Chief Evangelist for Apache Cassandra @PatrickMcFadin ©2013 DataStax Confidential. Do not distribute without consent. 1
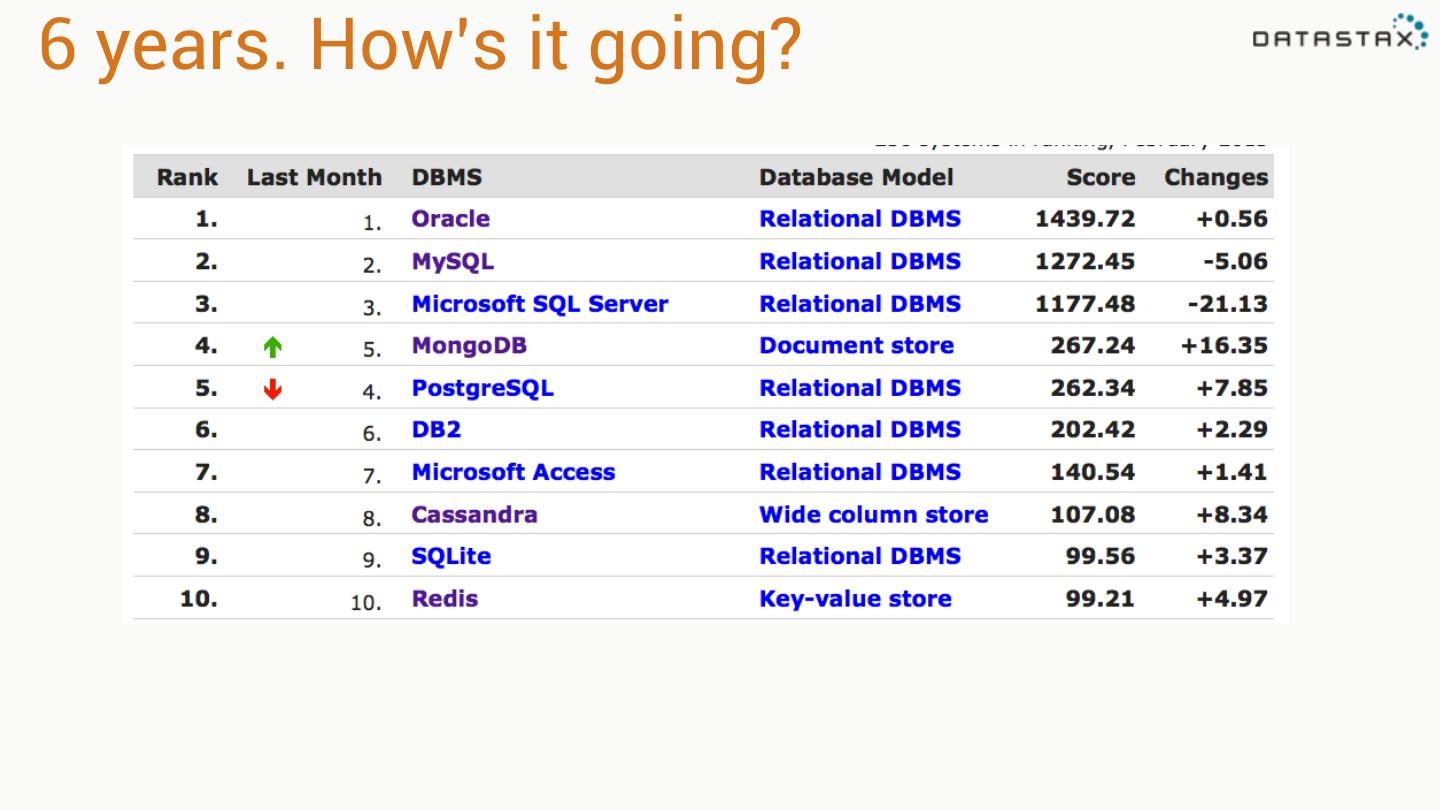
2 .6 years. How’s it going?
3 .Cassandra 3.0 & 3.1 Spring and Fall
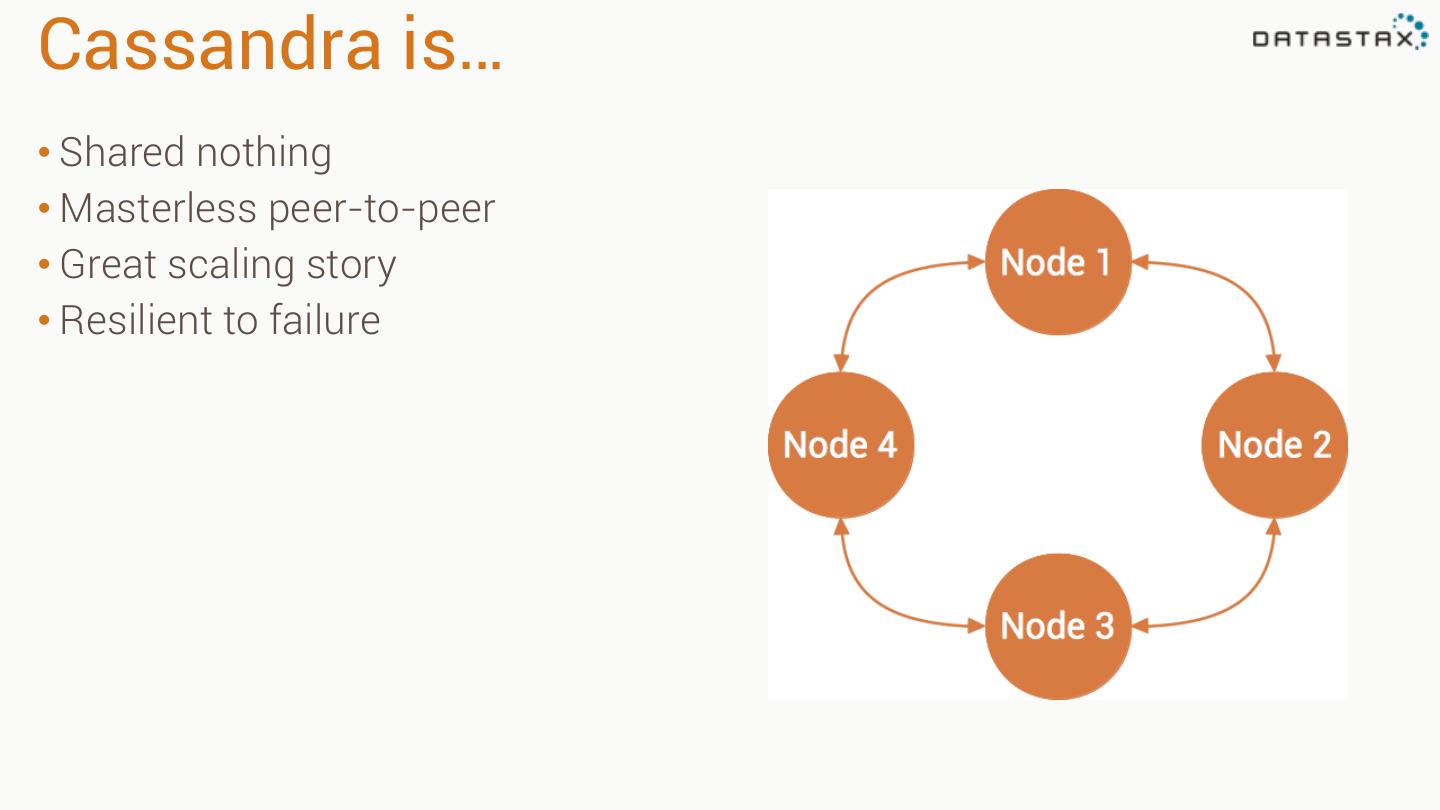
4 .Cassandra is… • Shared nothing • Masterless peer-to-peer • Great scaling story • Resilient to failure
5 .Cassandra for Applications APACHE CASSANDRA
6 . A Data Ocean , Lake or Pond. An In-Memory Database A Key-Value Store A magical database unicorn that farts rainbows
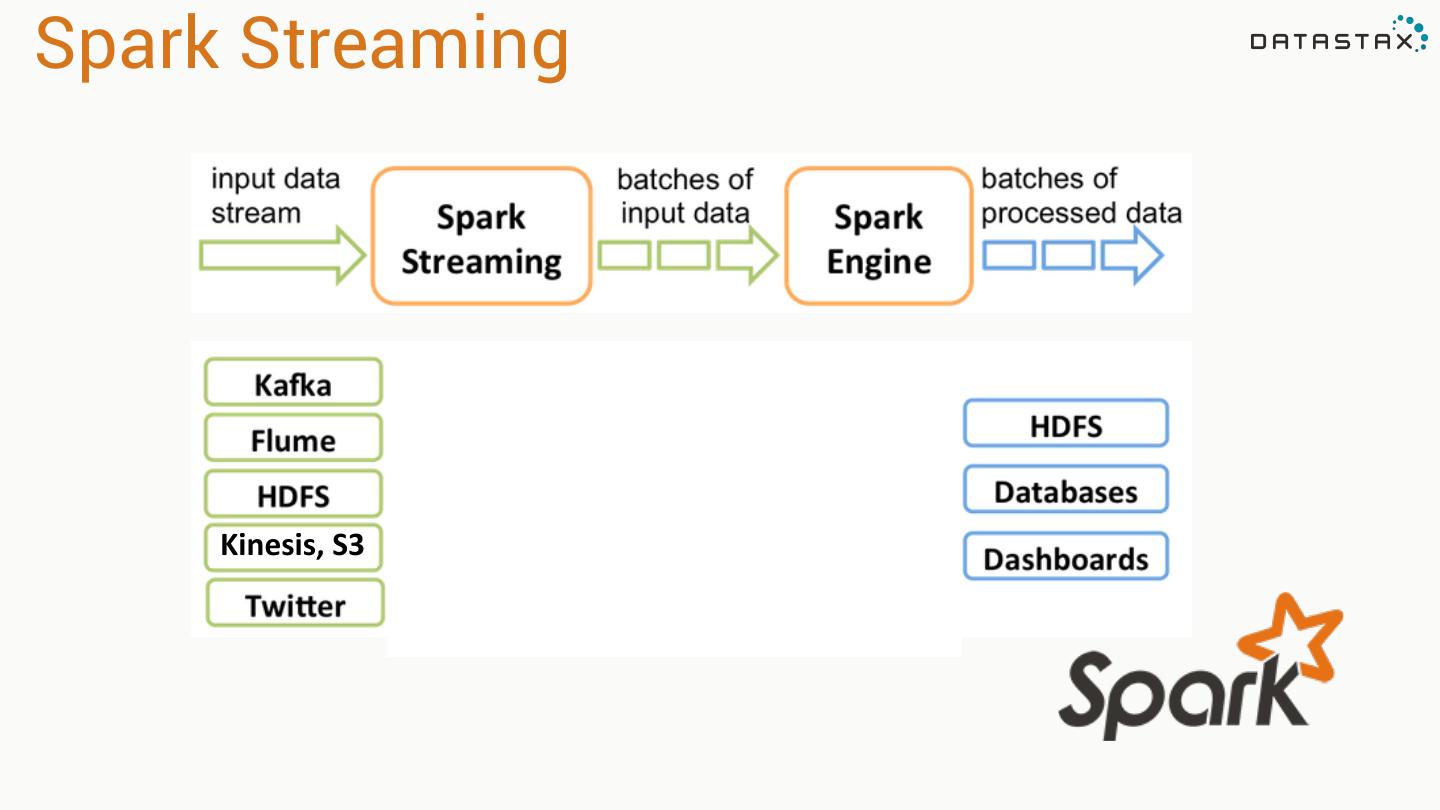
7 .Apache Spark
8 .Apache Spark • 10x faster on disk,100x faster in memory than Hadoop MR • Works out of the box on EMR • Fault Tolerant Distributed Datasets Up to 100× faster • Batch, iterative and streaming analysis (2-10× on disk) • In Memory Storage and Disk • Integrates with Most File and Storage Options 2-5× less code
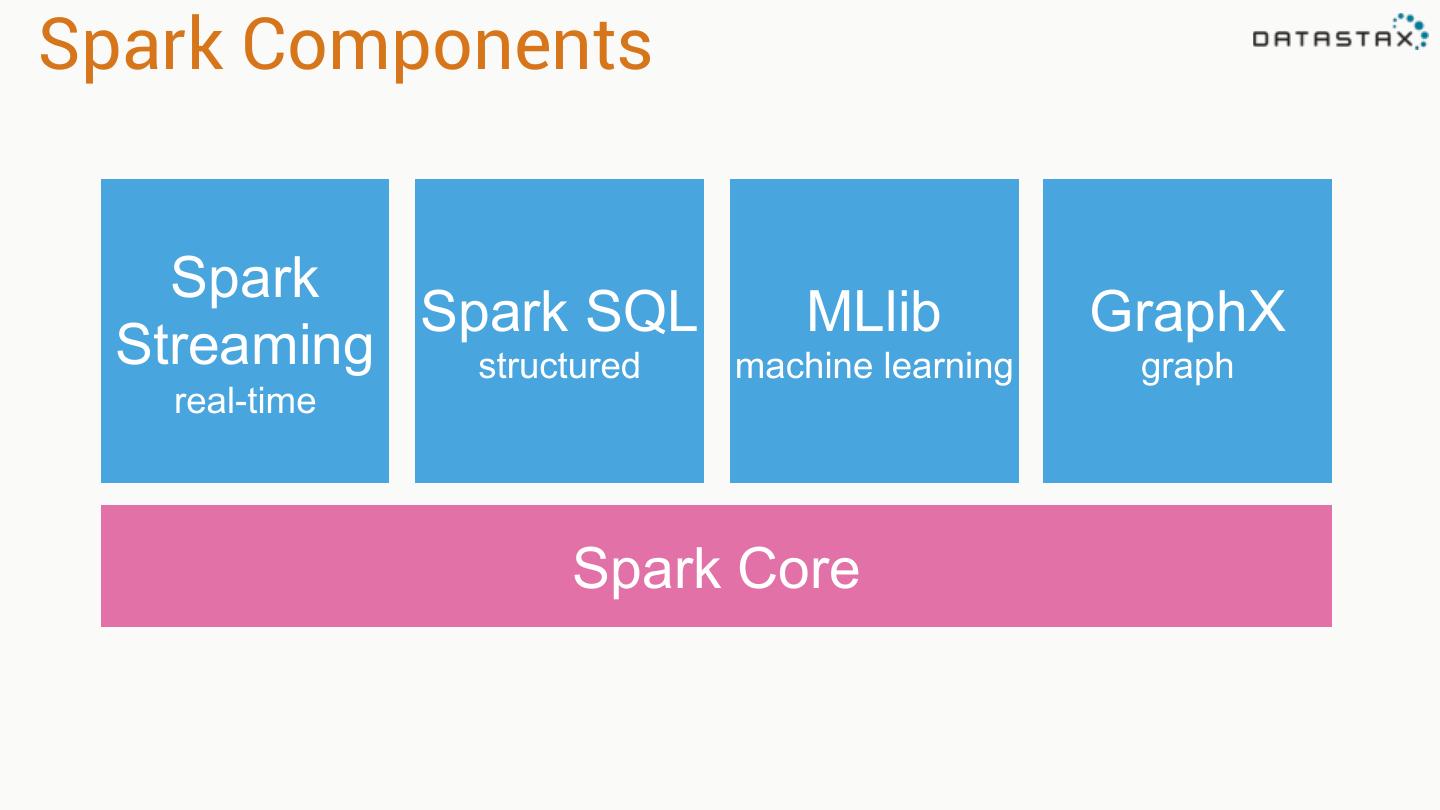
9 .Spark Components Spark Spark SQL MLlib GraphX Streaming structured machine learning graph real-time Spark Core
10 .
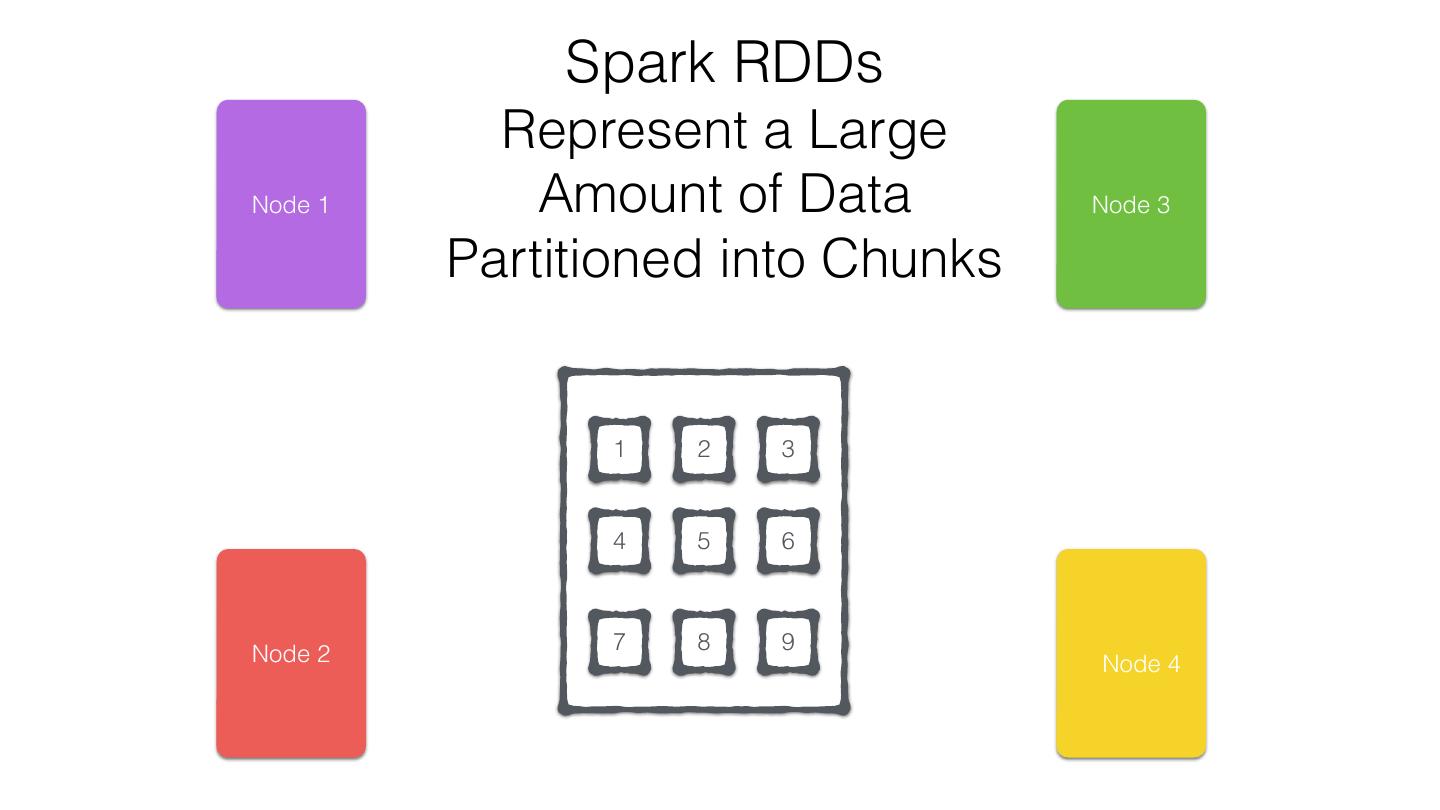
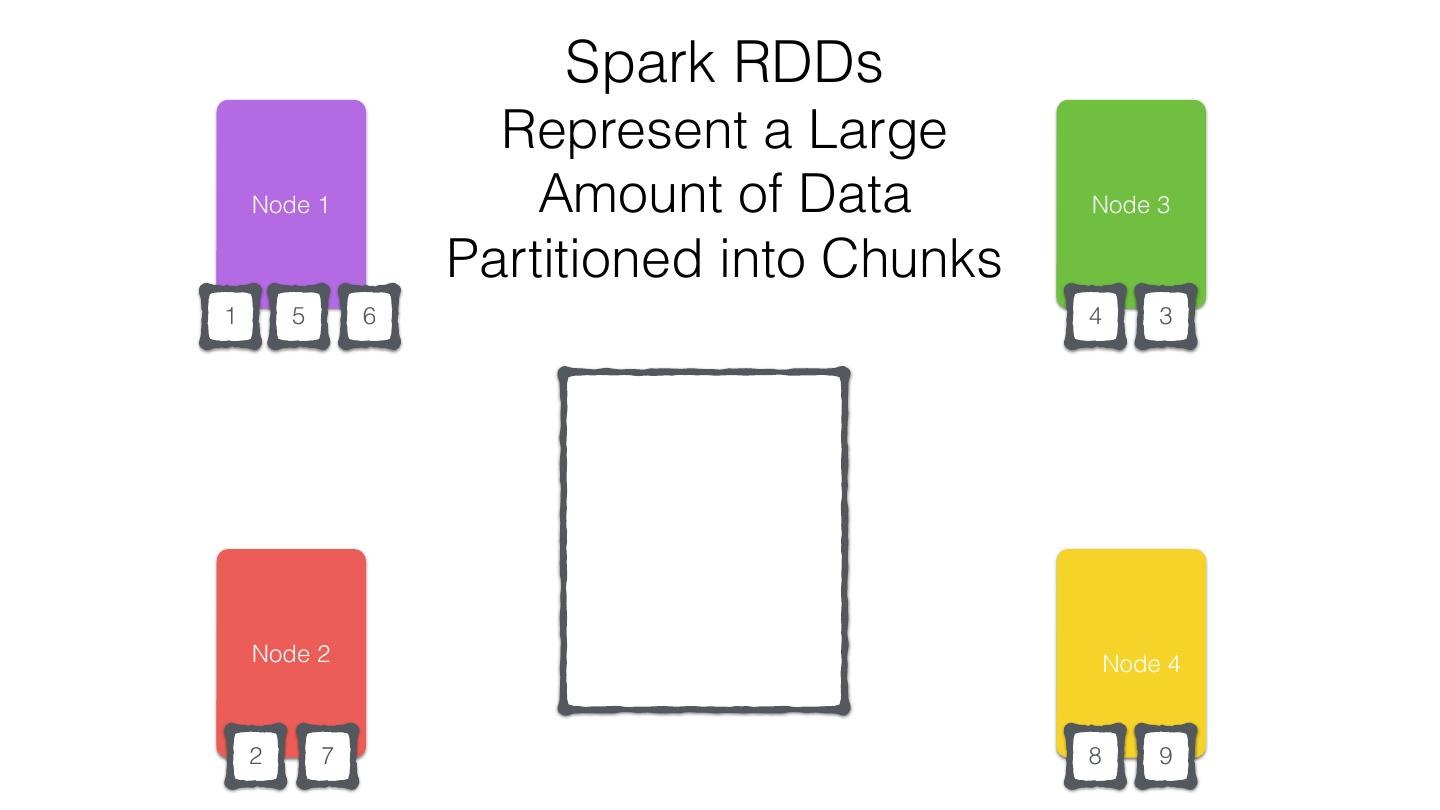
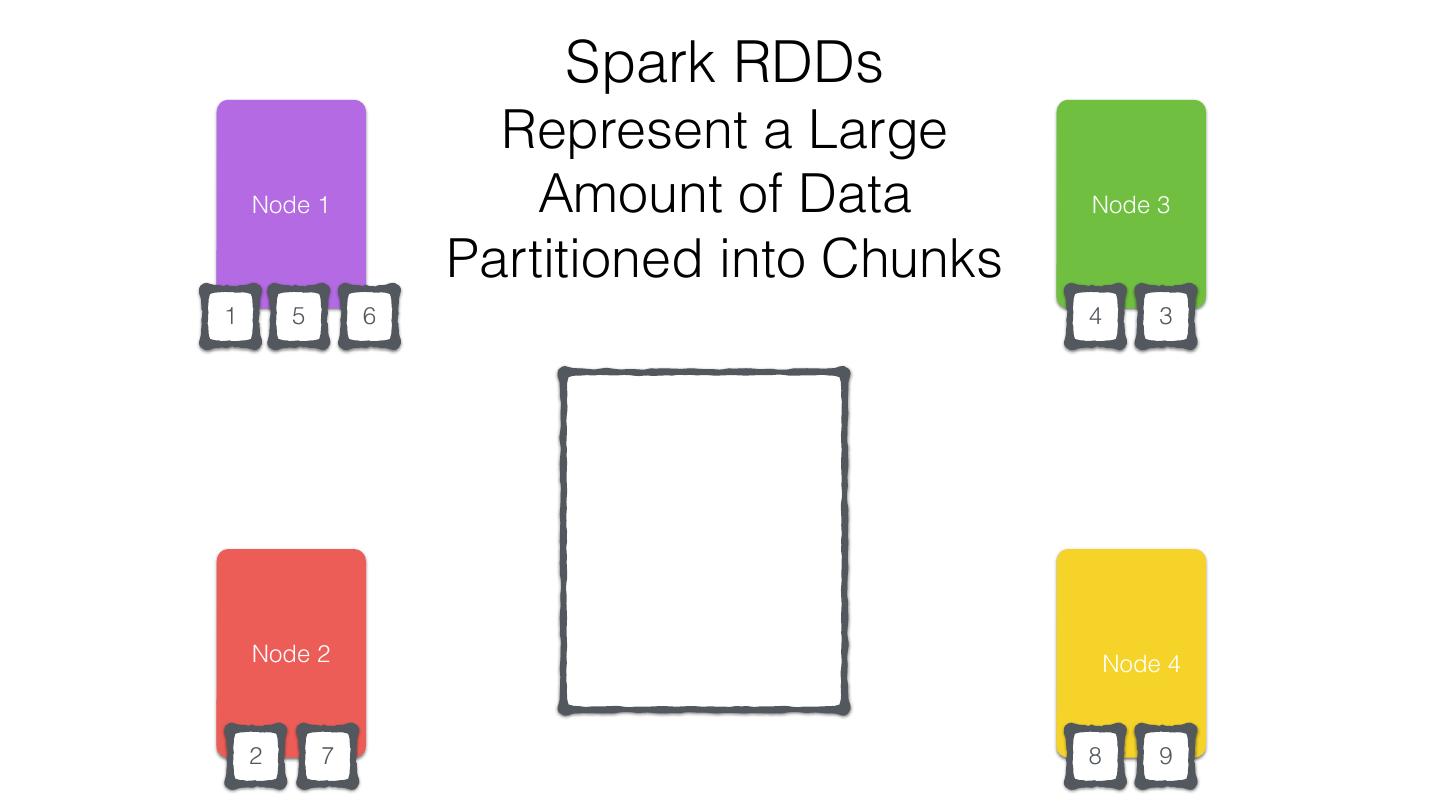
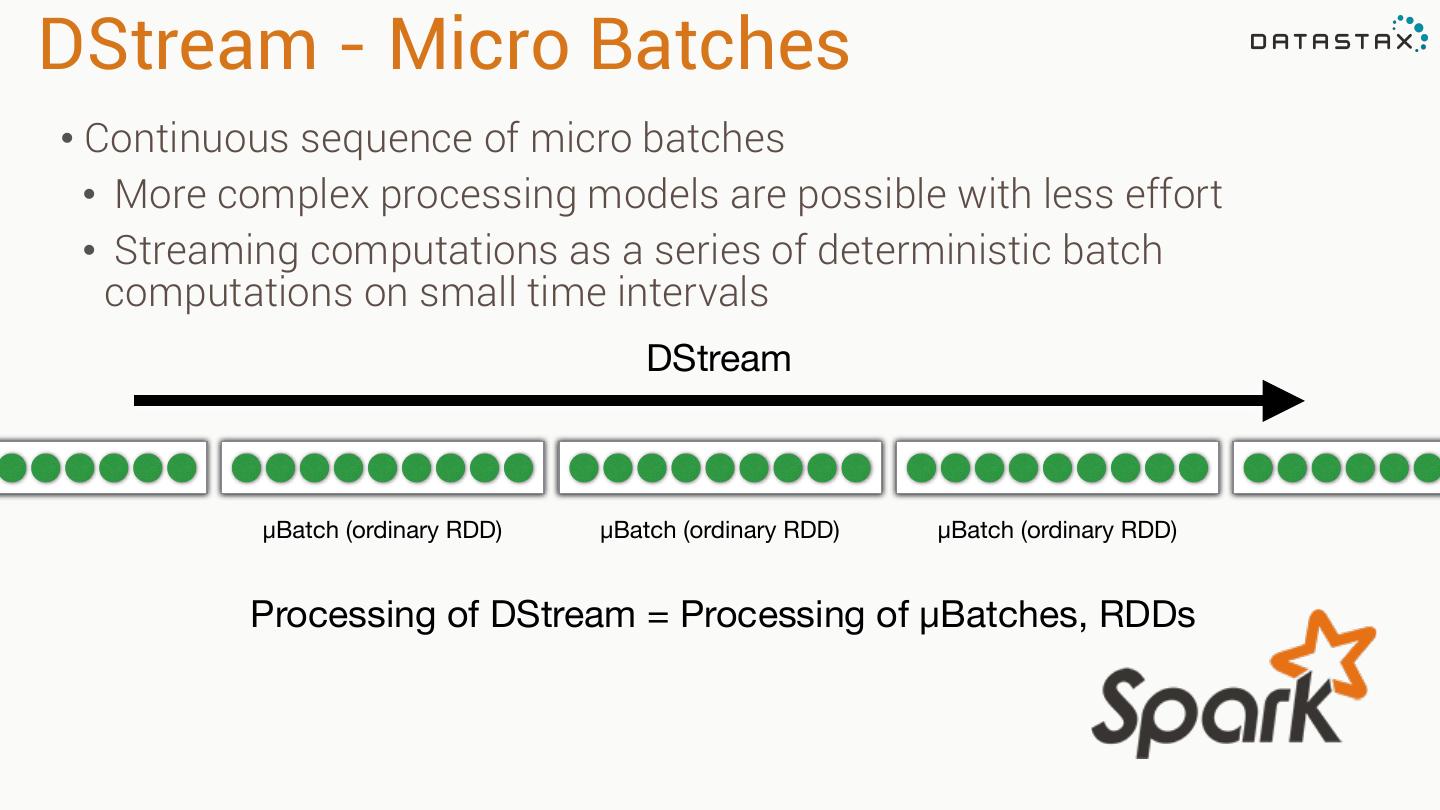
11 .org.apache.spark.rdd.RDD Resilient Distributed Dataset (RDD) •Created through transformations on data (map,filter..) or other RDDs •Immutable •Partitioned •Reusable
12 .RDD Operations •Transformations - Similar to scala collections API •Produce new RDDs • filter, flatmap, map, distinct, groupBy, union, zip, reduceByKey, subtract •Actions •Require materialization of the records to generate a value • collect: Array[T], count, fold, reduce..
13 .RDD Operations Analytic Transformation Action Analytic Search
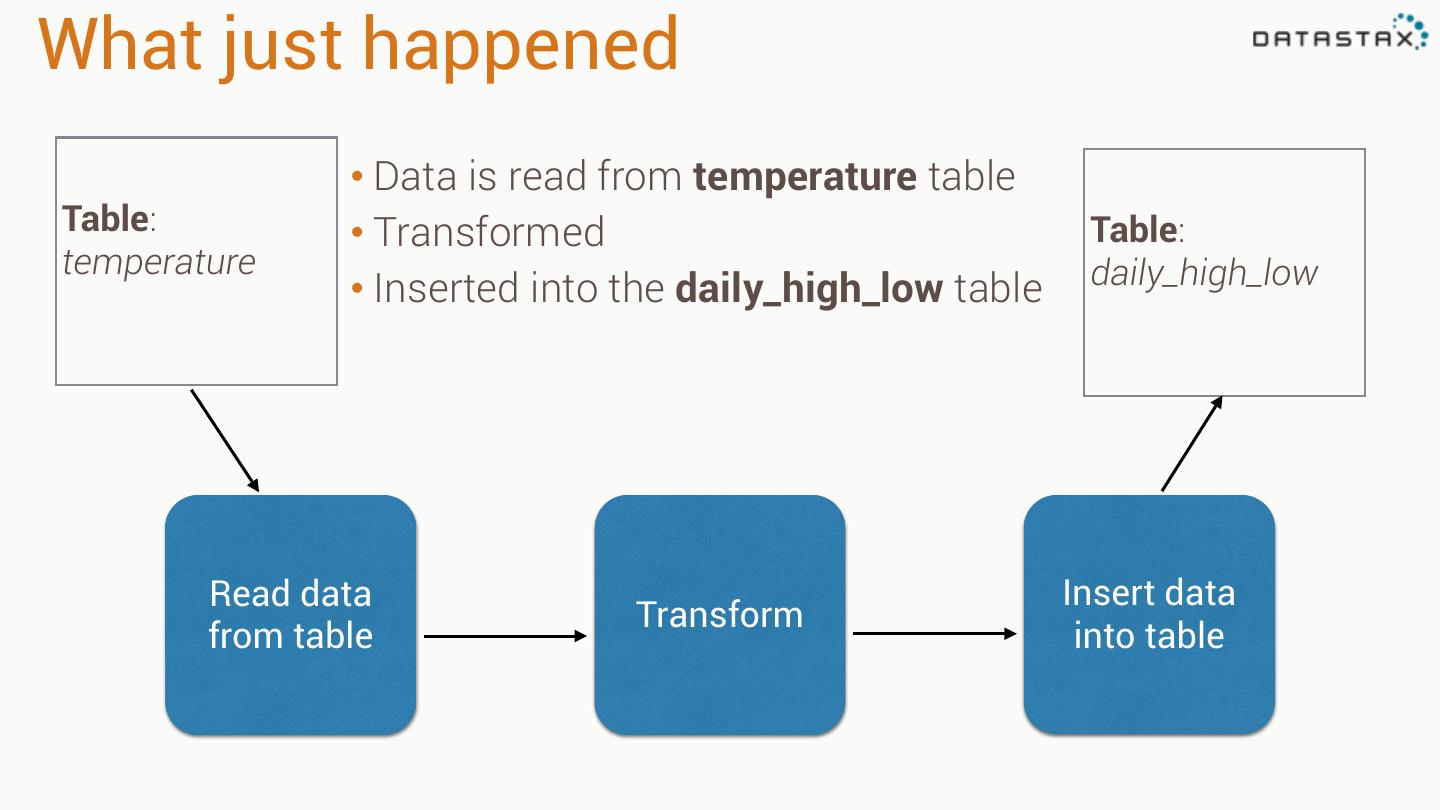
14 .Cassandra and Spark
15 .Cassandra & Spark: A Great Combo •Both are Easy to Use •Spark Can Help You Bridge Your Hadoop and Cassandra Systems •Use Spark Libraries, Caching on-top of Cassandra-stored Data •Combine Spark Streaming with Cassandra Storage Datastax: spark-cassandra-connector: https://github.com/datastax/spark-cassandra-connector
16 .Spark On Cassandra •Server-Side filters (where clauses) •Cross-table operations (JOIN, UNION, etc.) •Data locality-aware (speed) •Data transformation, aggregation, etc. •Natural Time Series Integration
17 .Apache Spark and Cassandra Open Source Stack Cassandra
18 .Spark Cassandra Connector 18
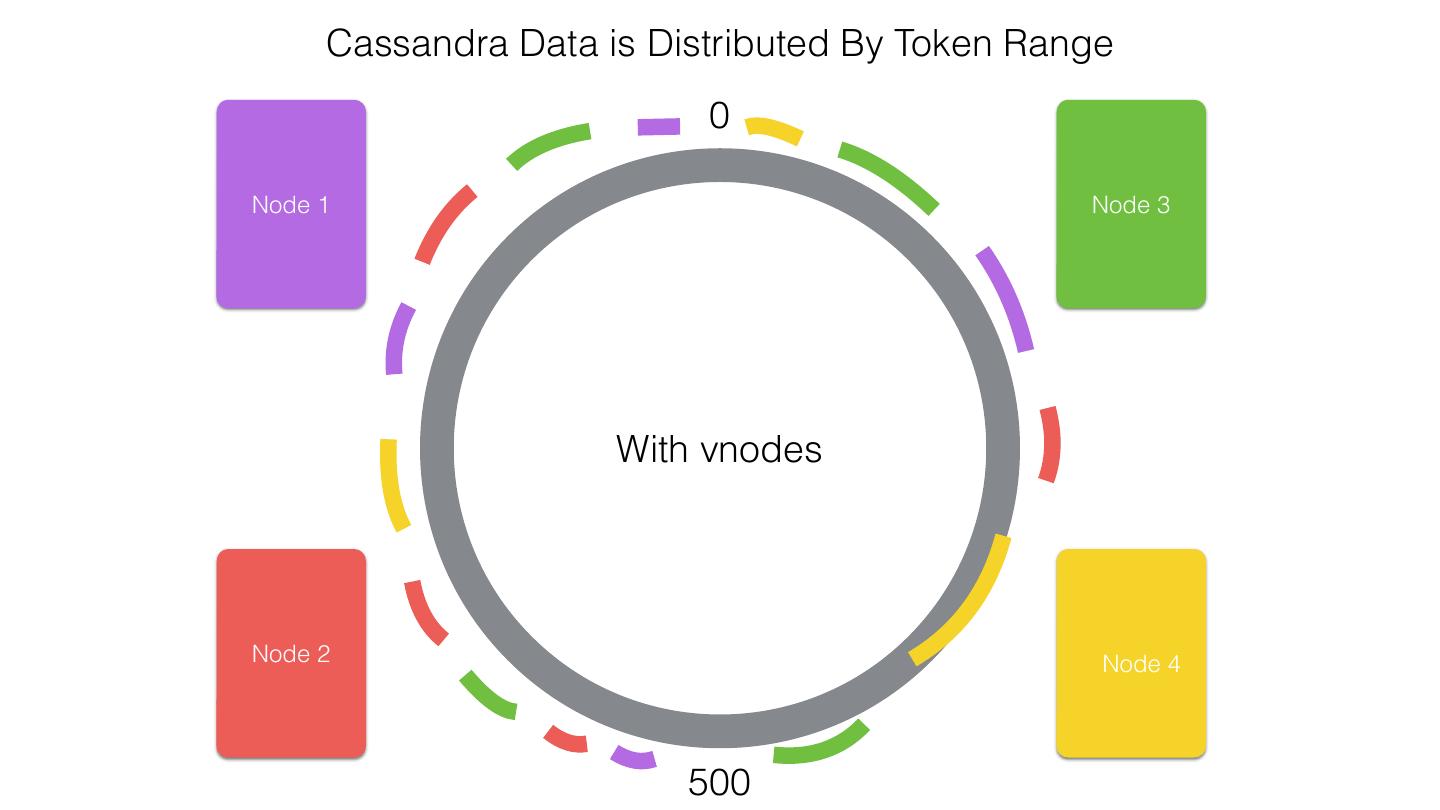
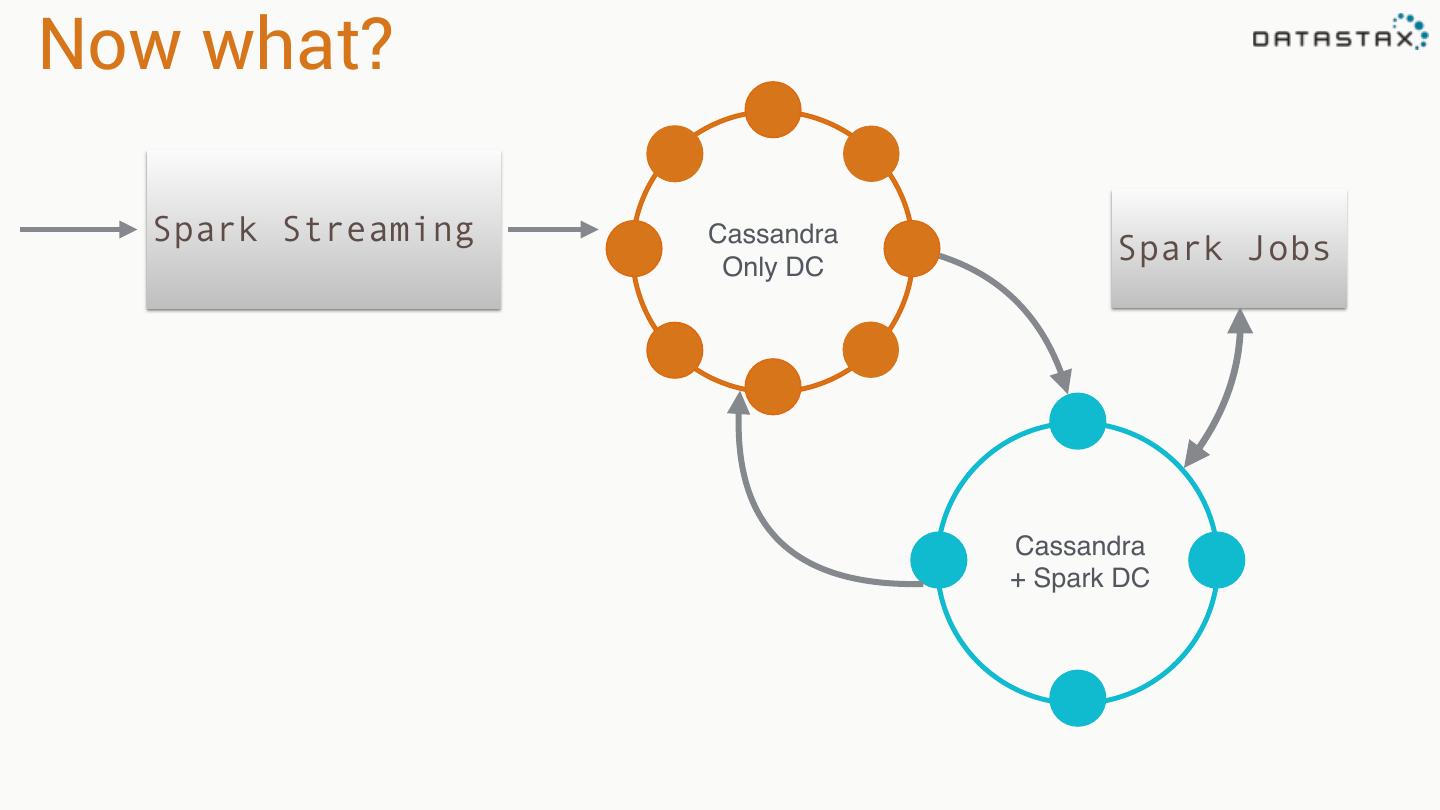
19 .Spark Cassandra Connector *Cassandra tables exposed as Spark RDDs *Read from and write to Cassandra *Mapping of C* tables and rows to Scala objects *All Cassandra types supported and converted to Scala types *Server side data selection *Virtual Nodes support *Use with Scala or Java *Compatible with, Spark 1.1.0, Cassandra 2.1 & 2.0
20 .Type Mapping CQL Type Scala Type ascii String bigint Long boolean Boolean counter Long decimal BigDecimal, java.math.BigDecimal double Double float Float inet java.net.InetAddress int Int list Vector, List, Iterable, Seq, IndexedSeq, java.util.List map Map, TreeMap, java.util.HashMap set Set, TreeSet, java.util.HashSet text, varchar String timestamp Long, java.util.Date, java.sql.Date, org.joda.time.DateTime timeuuid java.util.UUID uuid java.util.UUID varint BigInt, java.math.BigInteger *nullable values Option
21 .Connecting to Cassandra // Import Cassandra-specific functions on SparkContext and RDD objects import com.datastax.driver.spark._ // Spark connection options val conf = new SparkConf(true) .setMaster("spark://192.168.123.10:7077") .setAppName("cassandra-demo") .set("cassandra.connection.host", "192.168.123.10") // initial contact .set("cassandra.username", "cassandra") .set("cassandra.password", "cassandra") val sc = new SparkContext(conf)
22 .Accessing Data CREATE TABLE test.words (word text PRIMARY KEY, count int); INSERT INTO test.words (word, count) VALUES ('bar', 30); INSERT INTO test.words (word, count) VALUES ('foo', 20); * Accessing table above as RDD: // Use table as RDD val rdd = sc.cassandraTable("test", "words") // rdd: CassandraRDD[CassandraRow] = CassandraRDD[0] rdd.toArray.foreach(println) // CassandraRow[word: bar, count: 30] // CassandraRow[word: foo, count: 20] rdd.columnNames // Stream(word, count) rdd.size // 2 val firstRow = rdd.first // firstRow: CassandraRow = CassandraRow[word: bar, count: 30] firstRow.getInt("count") // Int = 30
23 .Saving Data val newRdd = sc.parallelize(Seq(("cat", 40), ("fox", 50))) // newRdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2] newRdd.saveToCassandra("test", "words", Seq("word", "count")) * RDD above saved to Cassandra: SELECT * FROM test.words; word | count ------+------- bar | 30 foo | 20 cat | 40 fox | 50 (4 rows)
24 .Spark Cassandra Connector https://github.com/datastax/spark-‐cassandra-‐connector Cassandra Spark RDD[CassandraRow] Keyspace Table RDD[Tuples] Bundled and Supported with DSE 4.5!
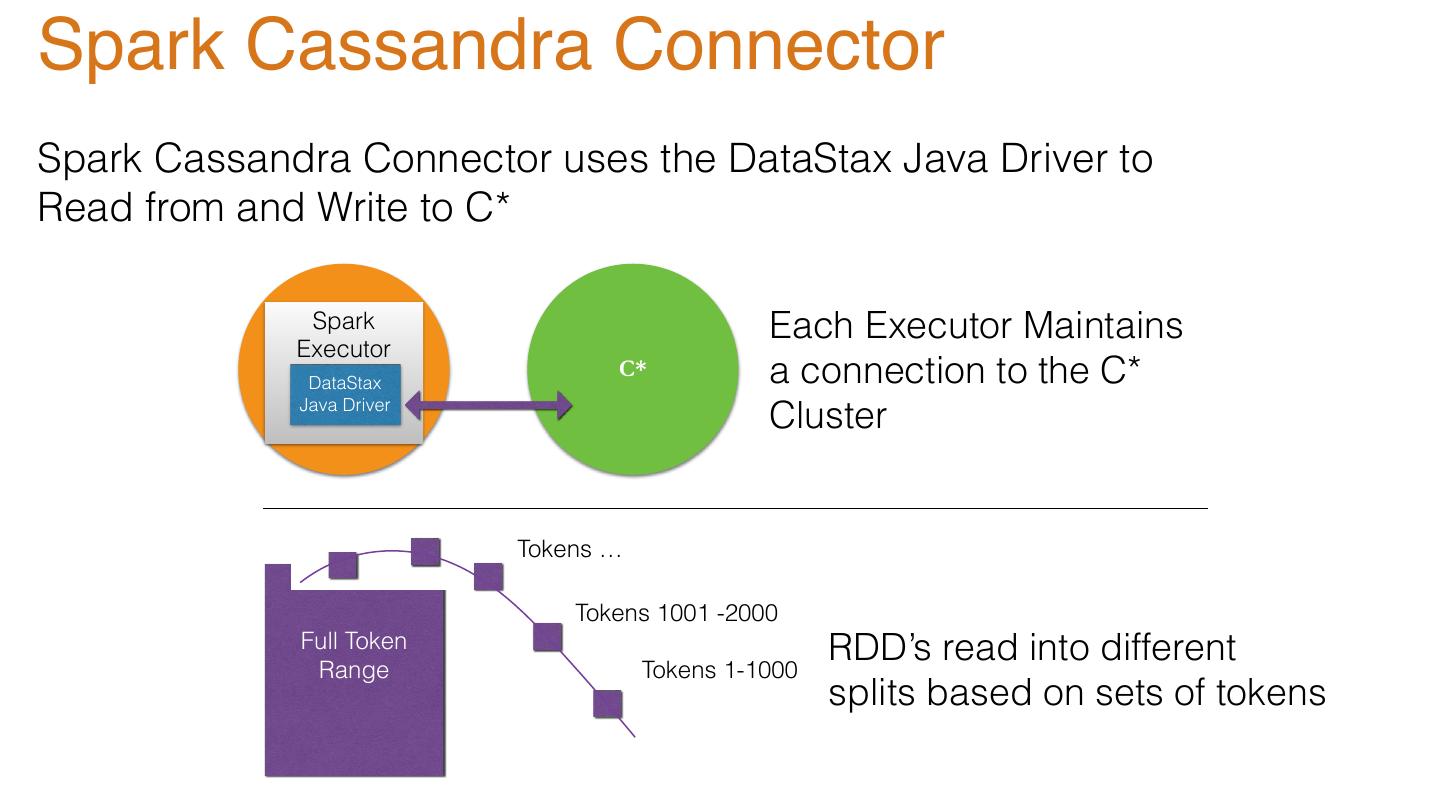
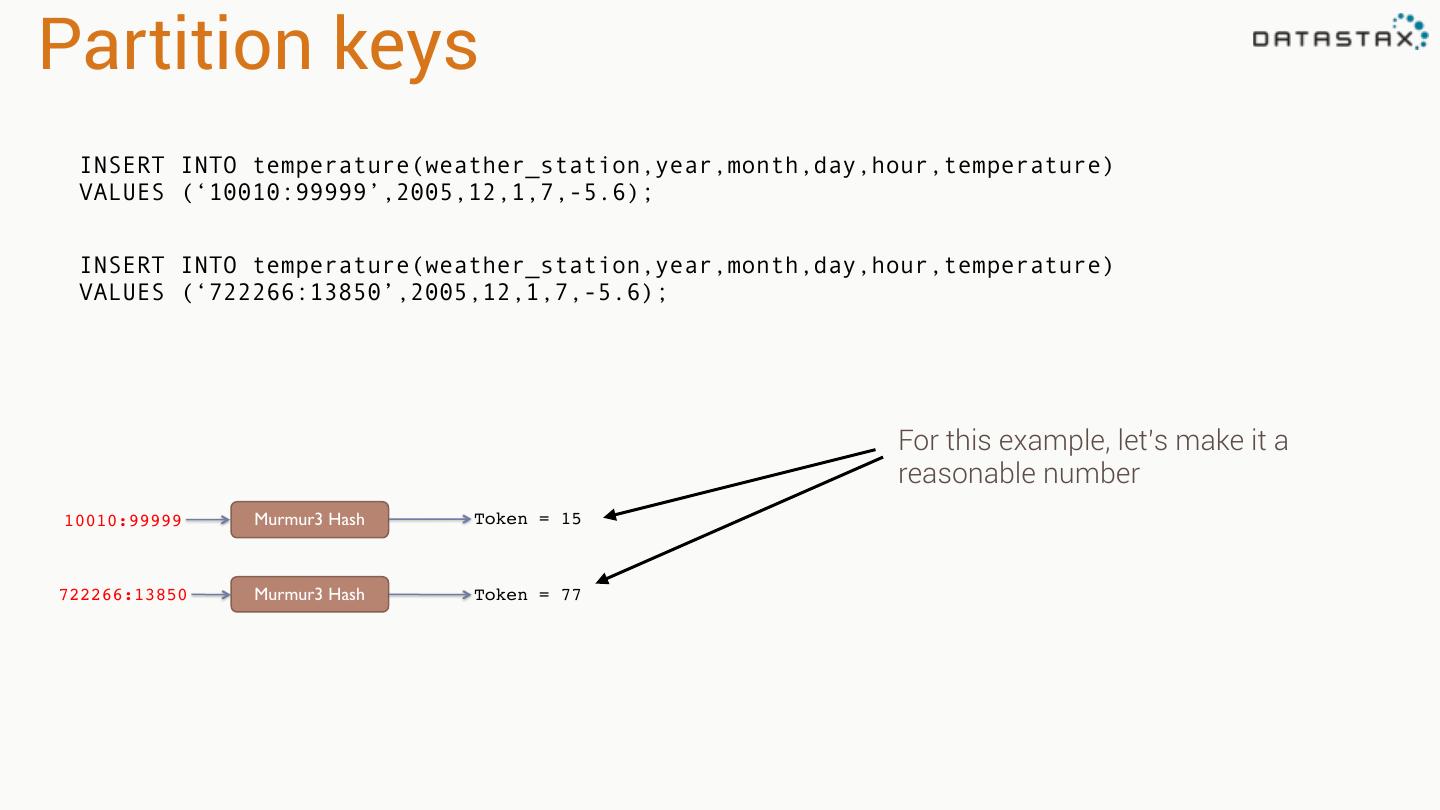
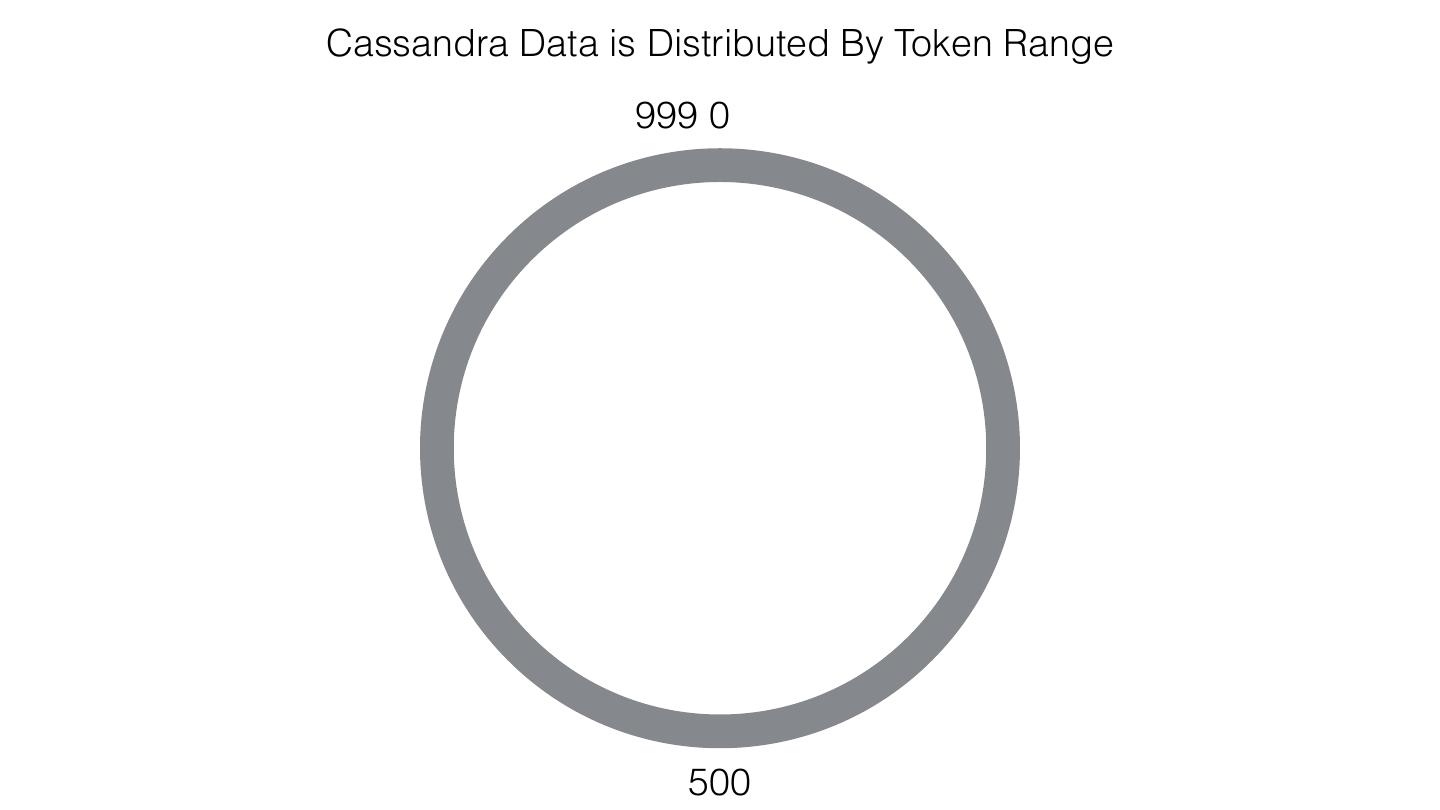
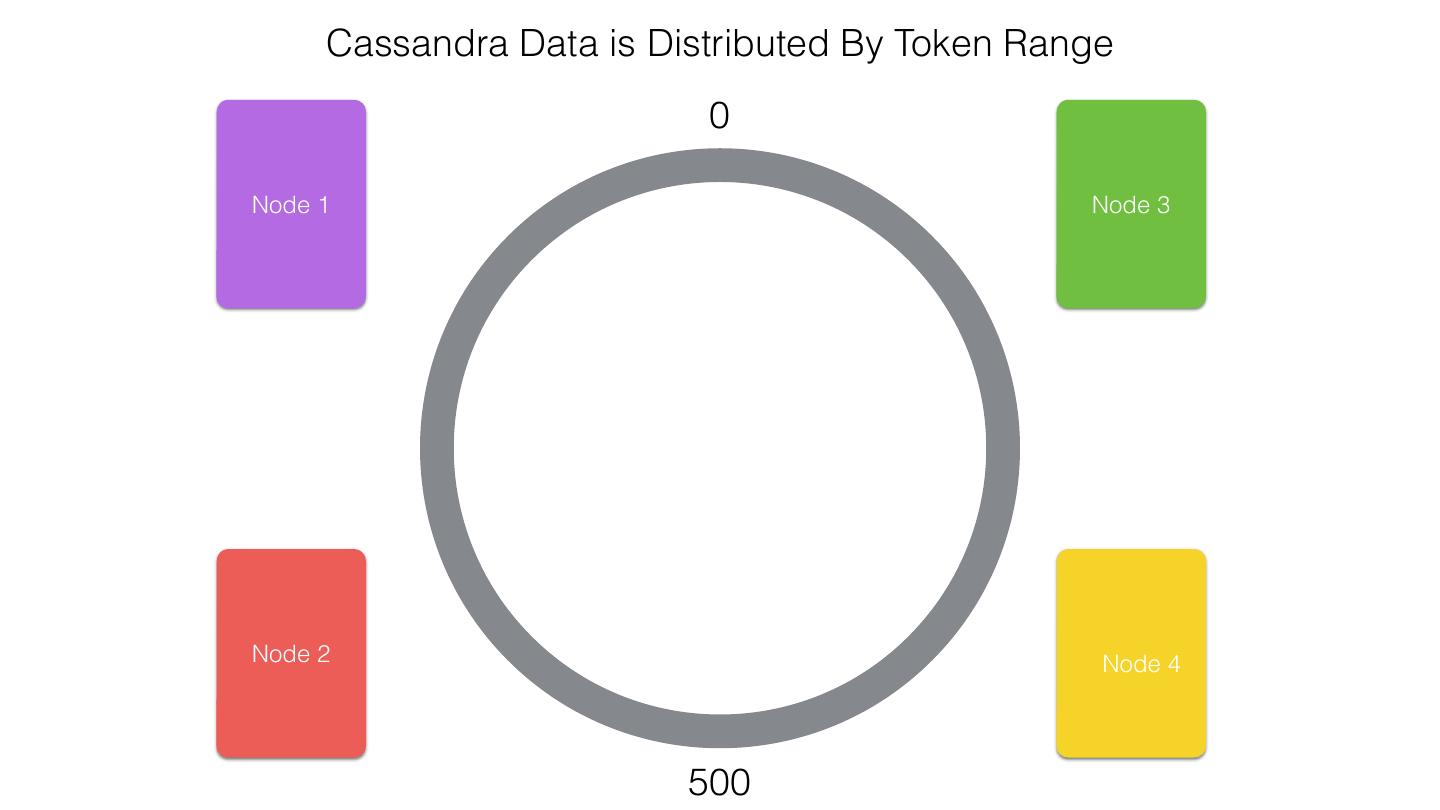
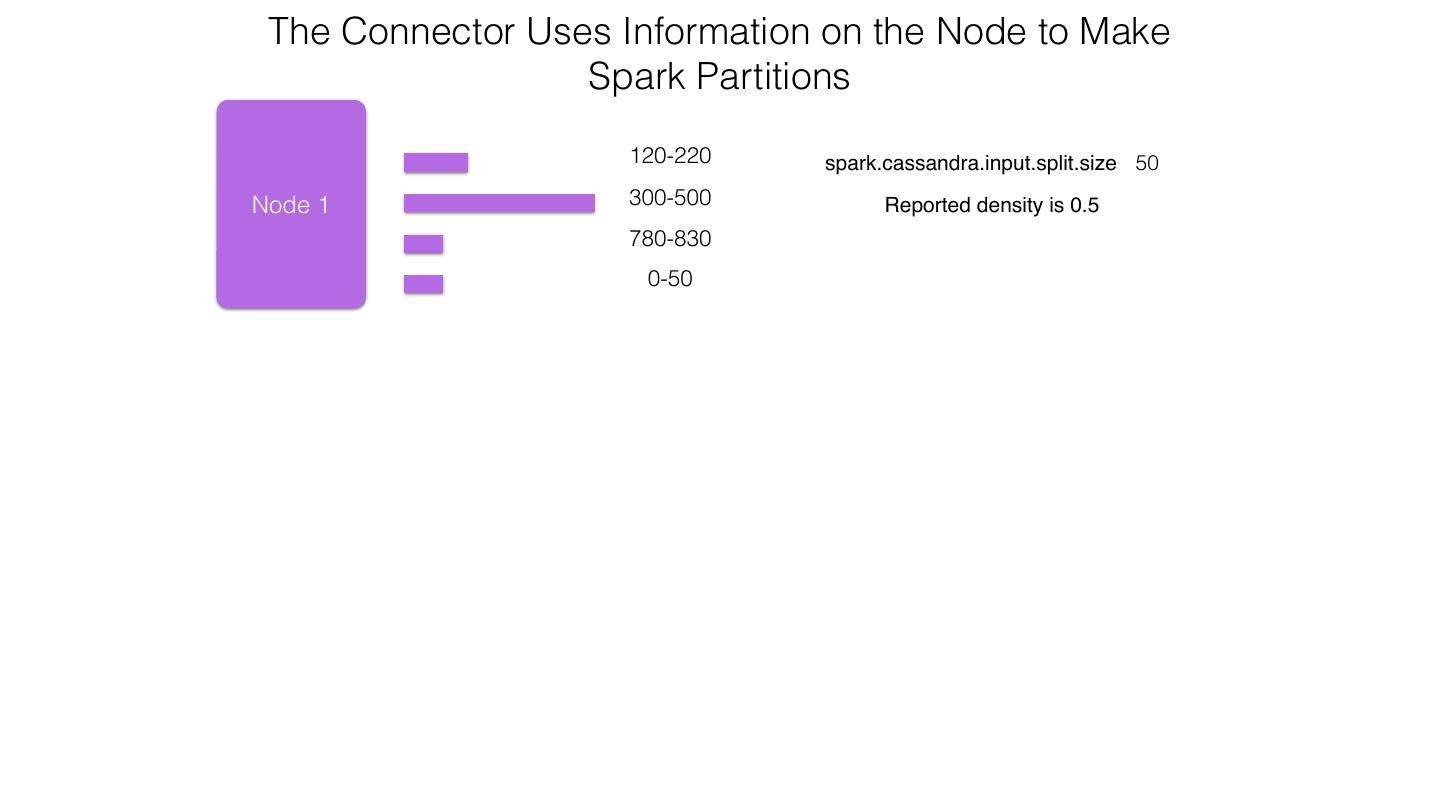
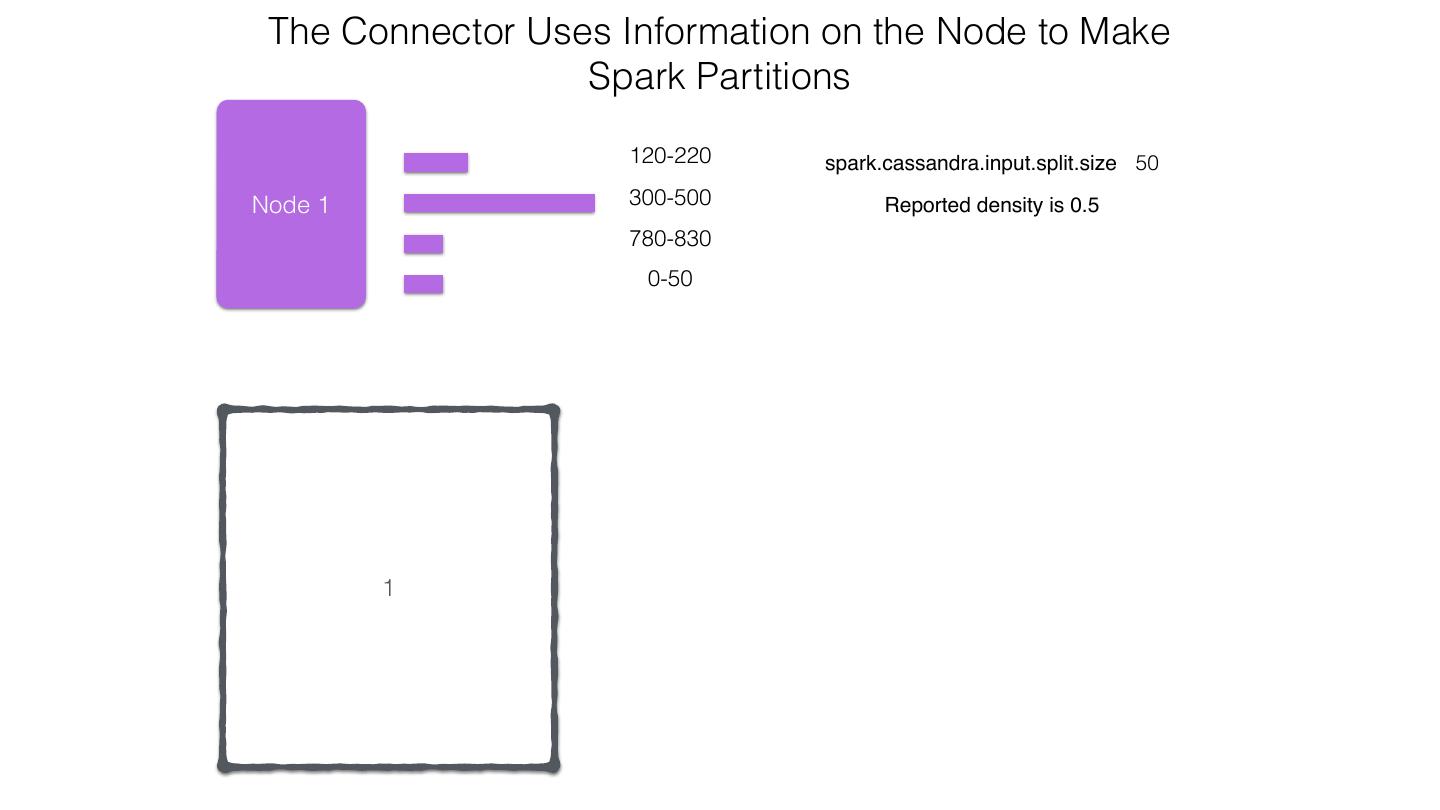
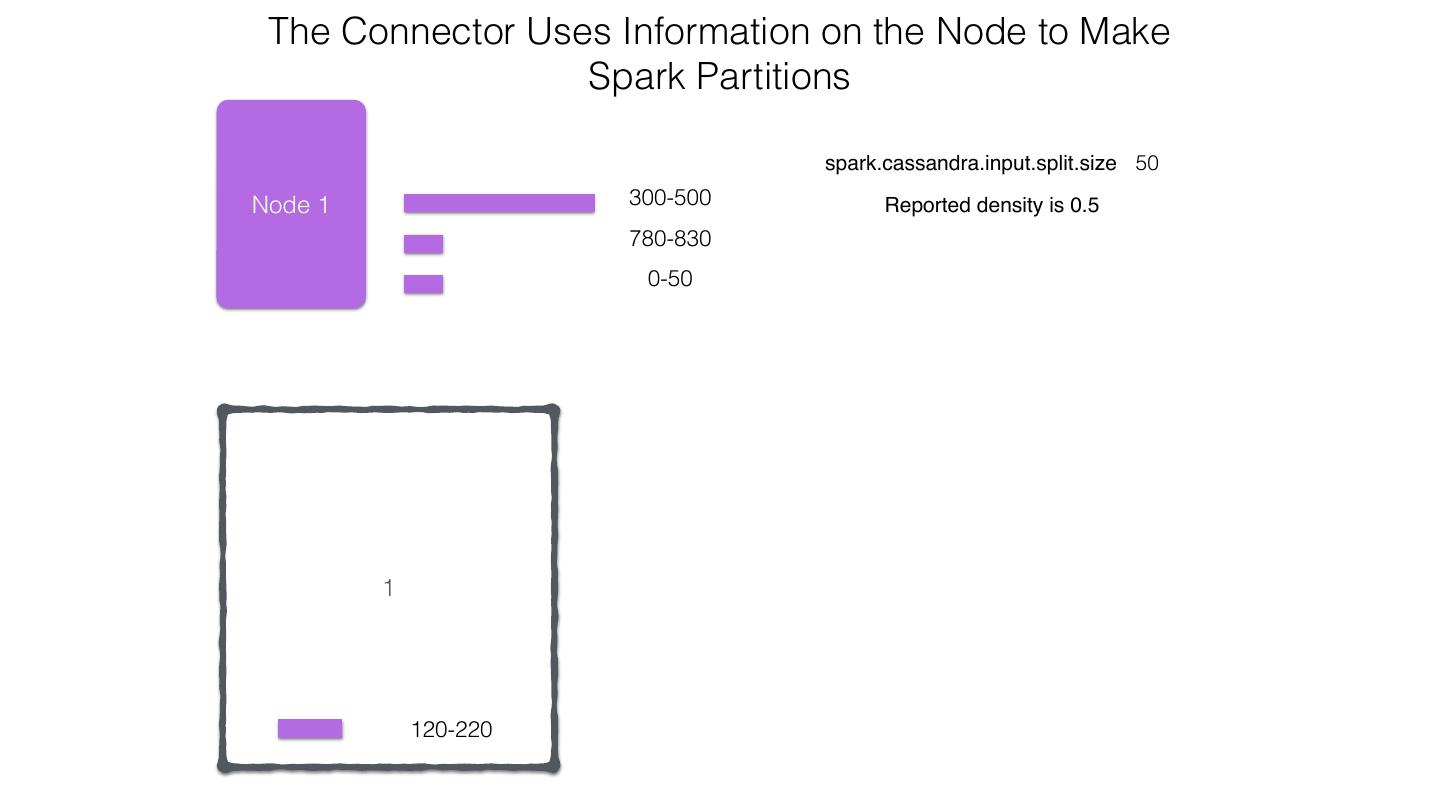
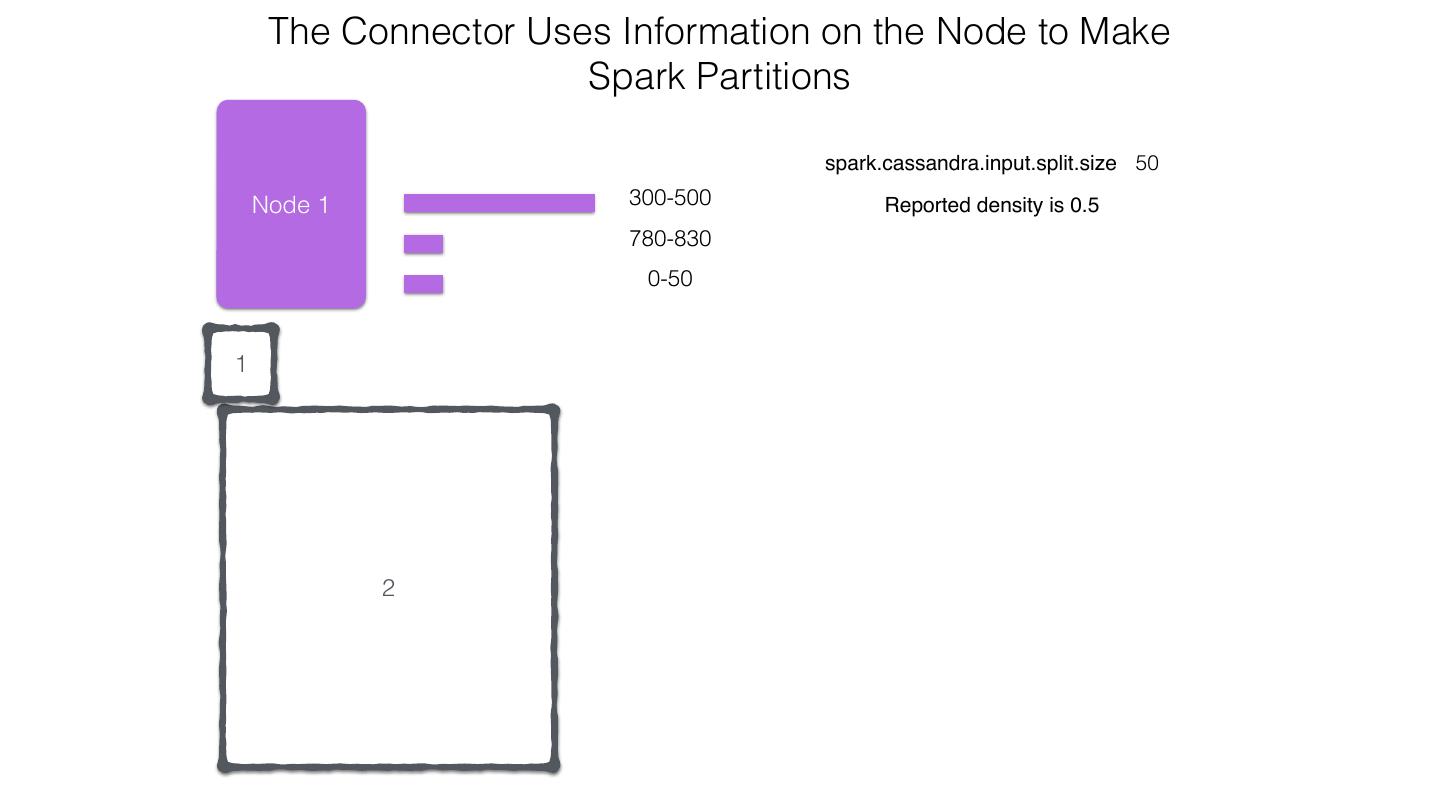
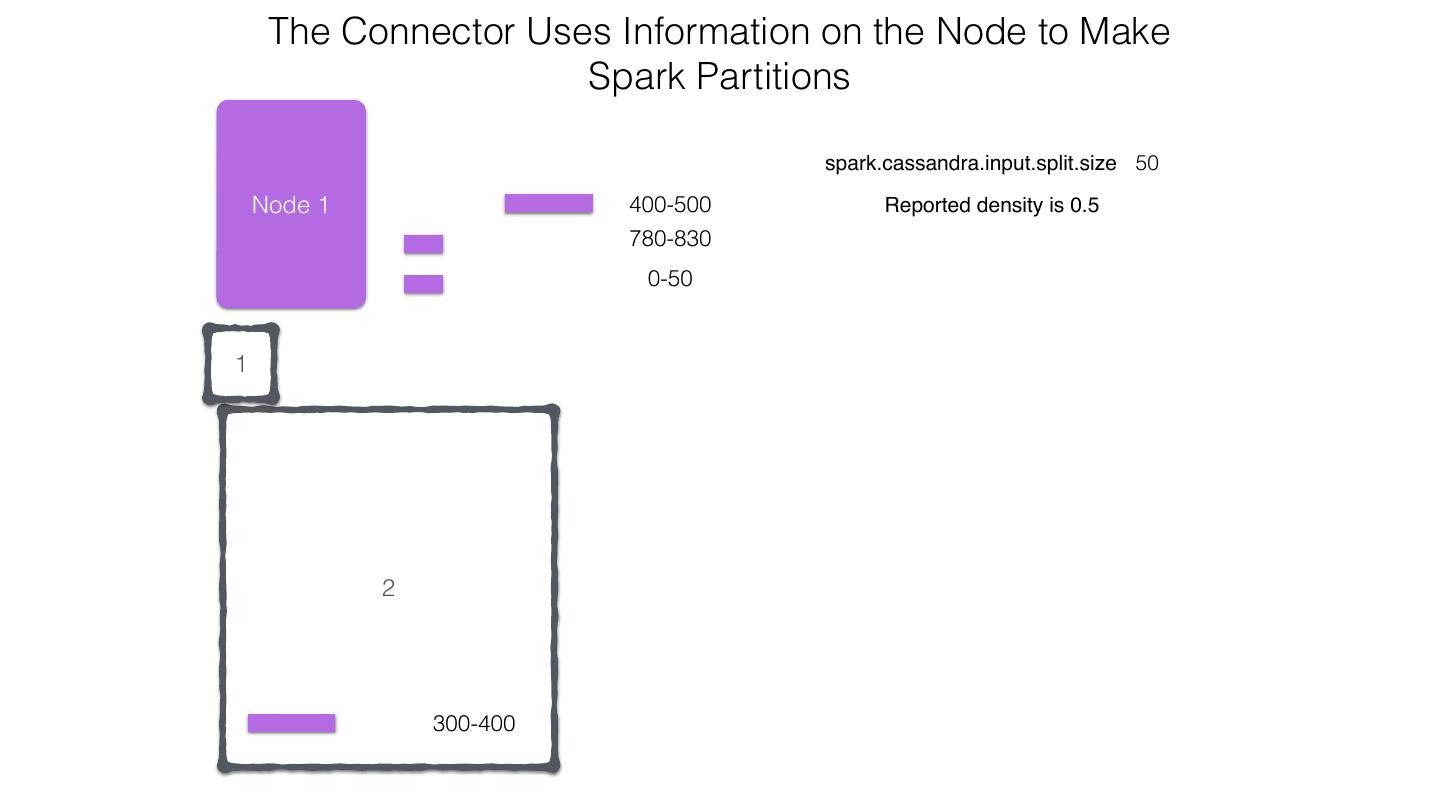
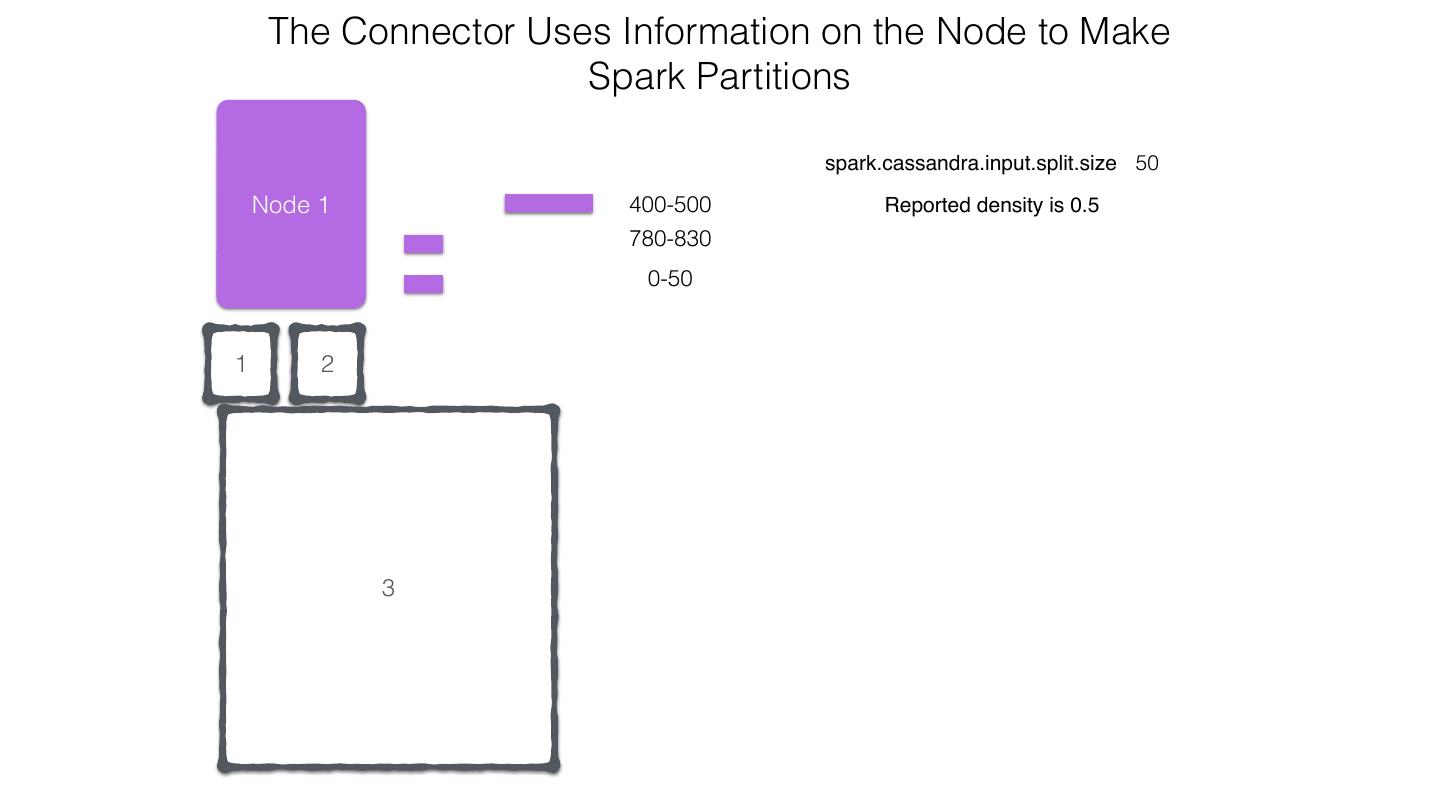
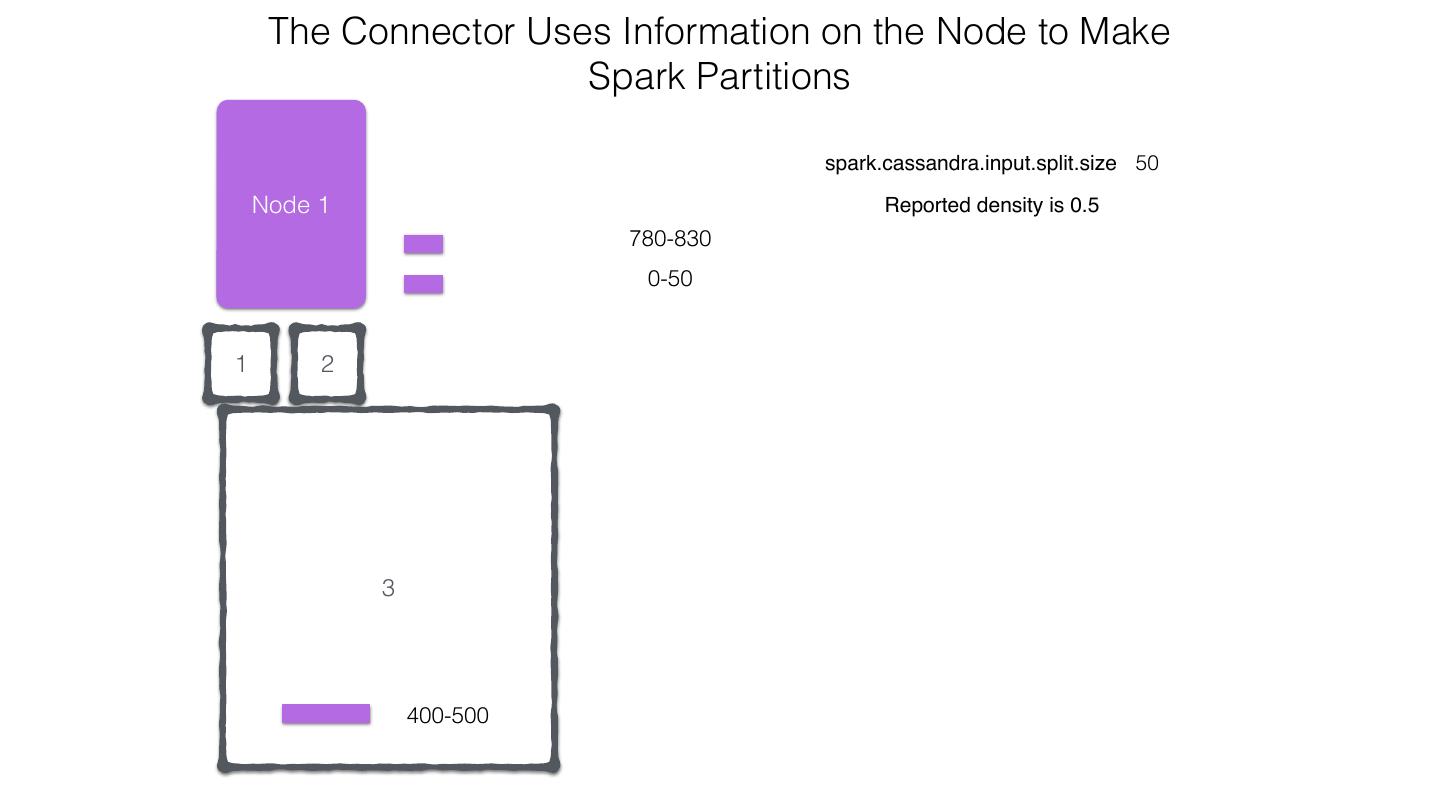
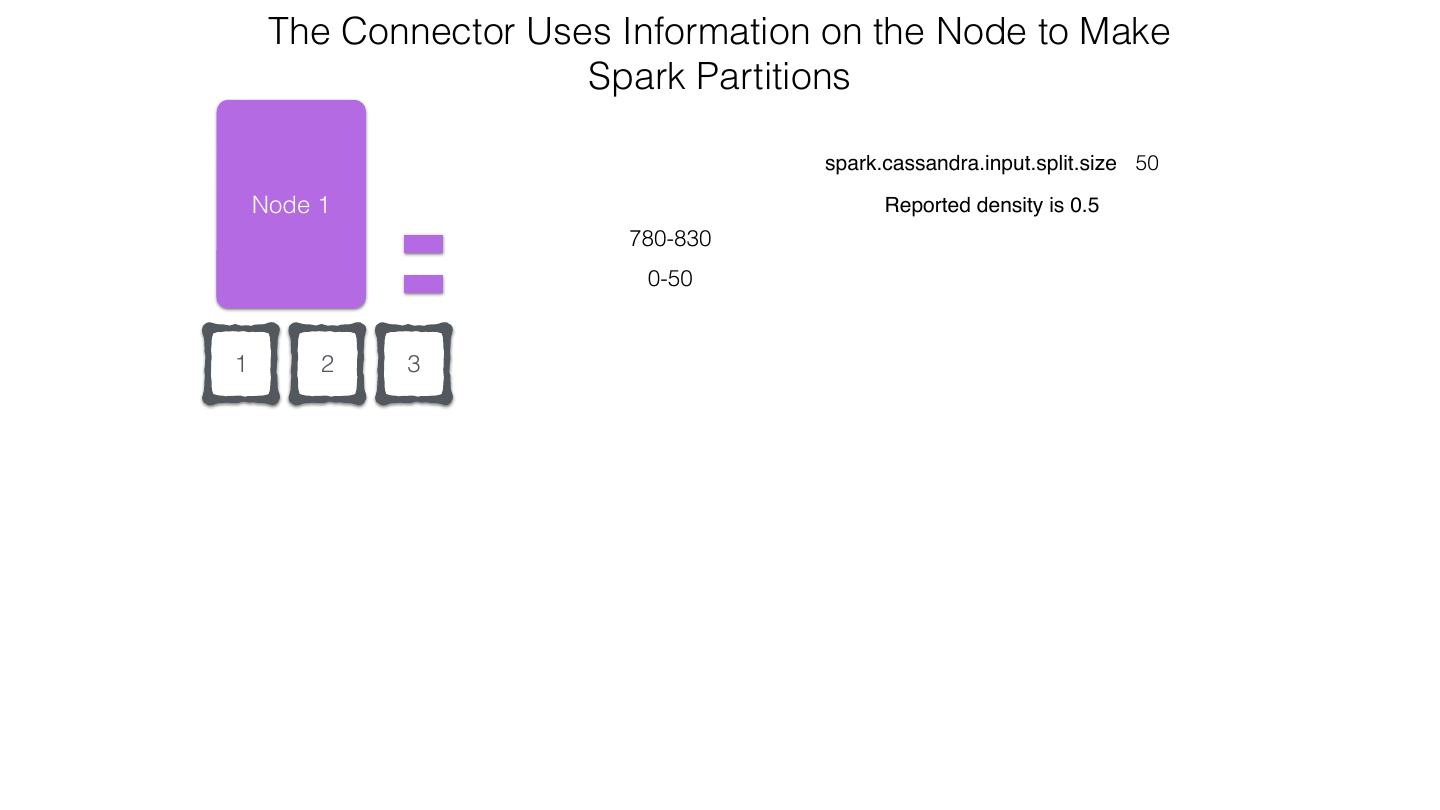
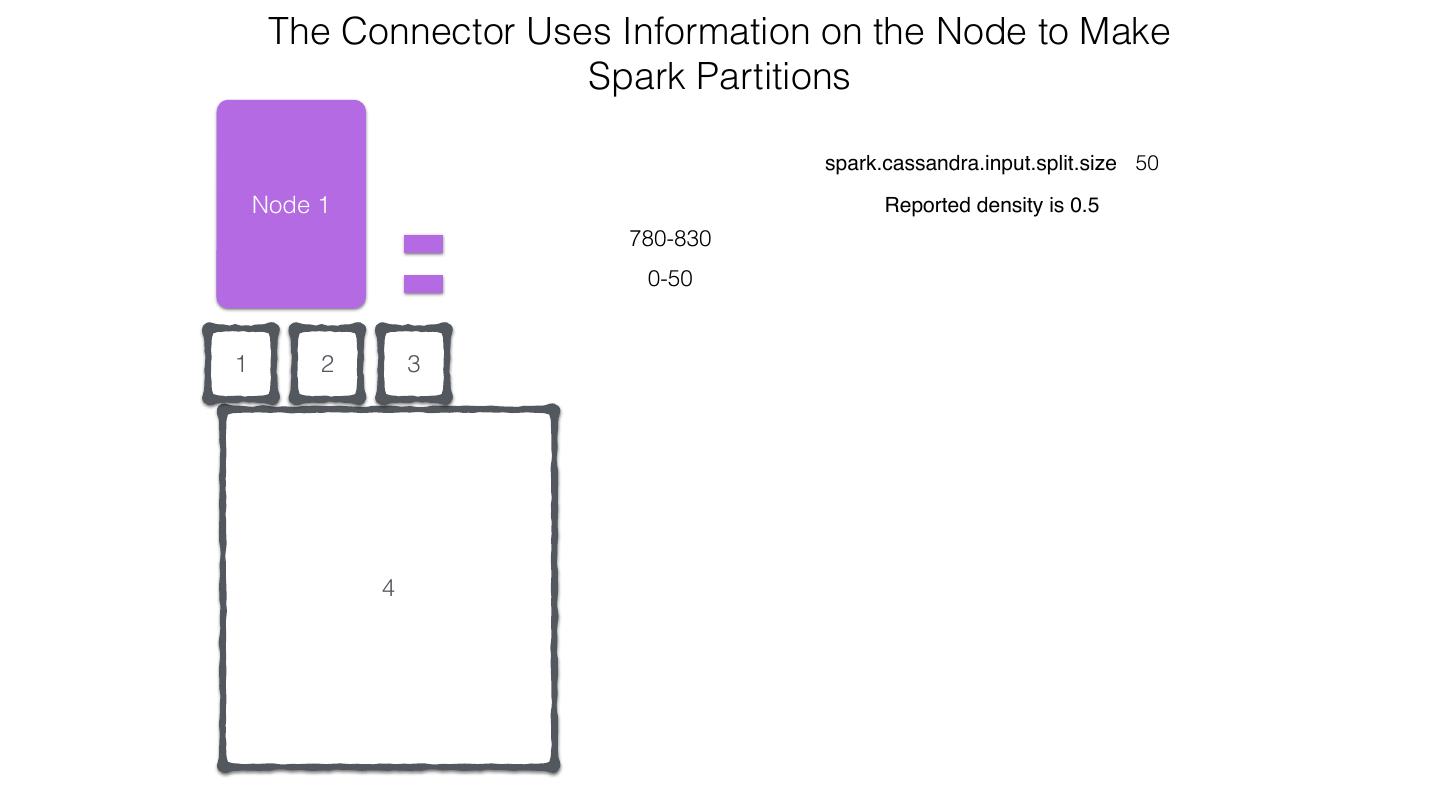
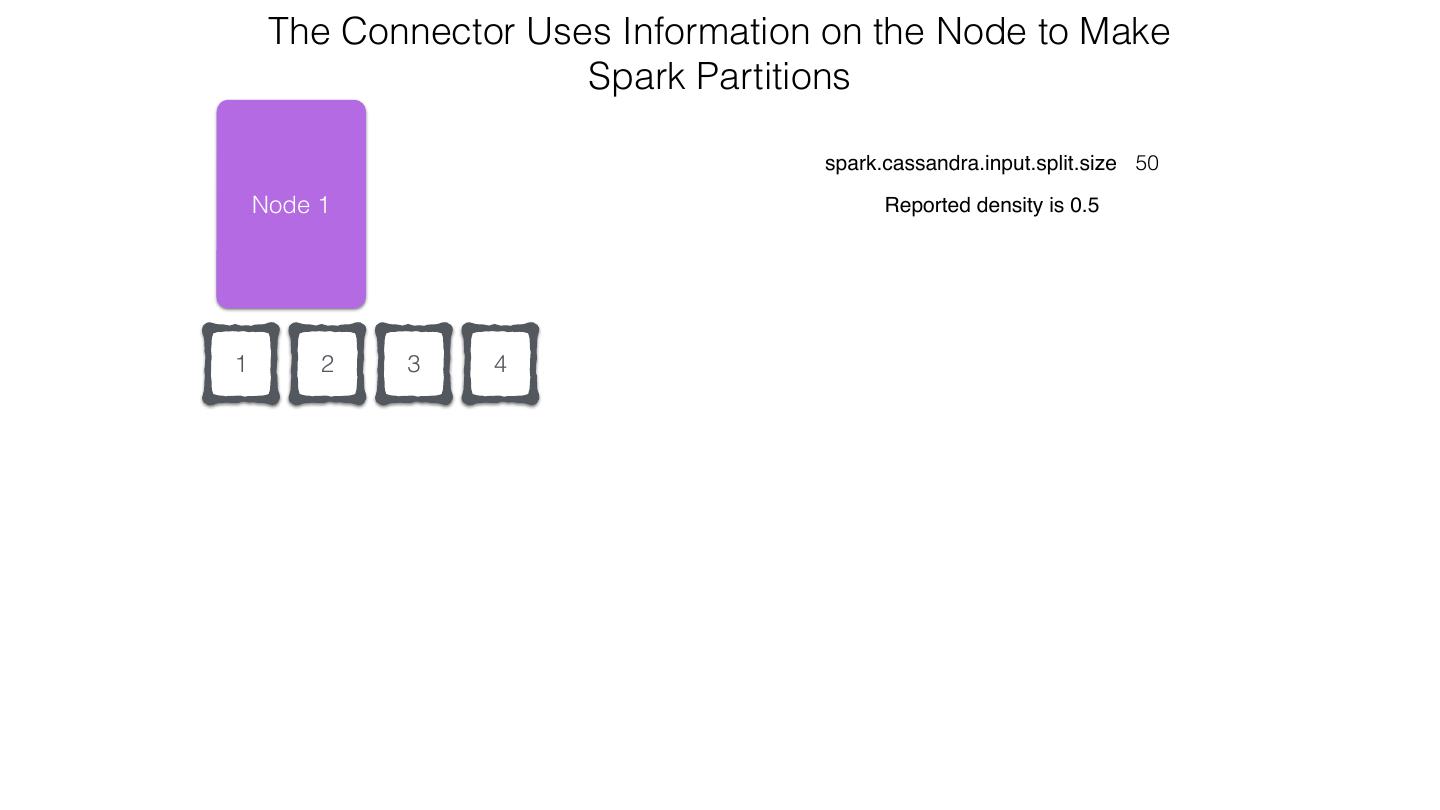
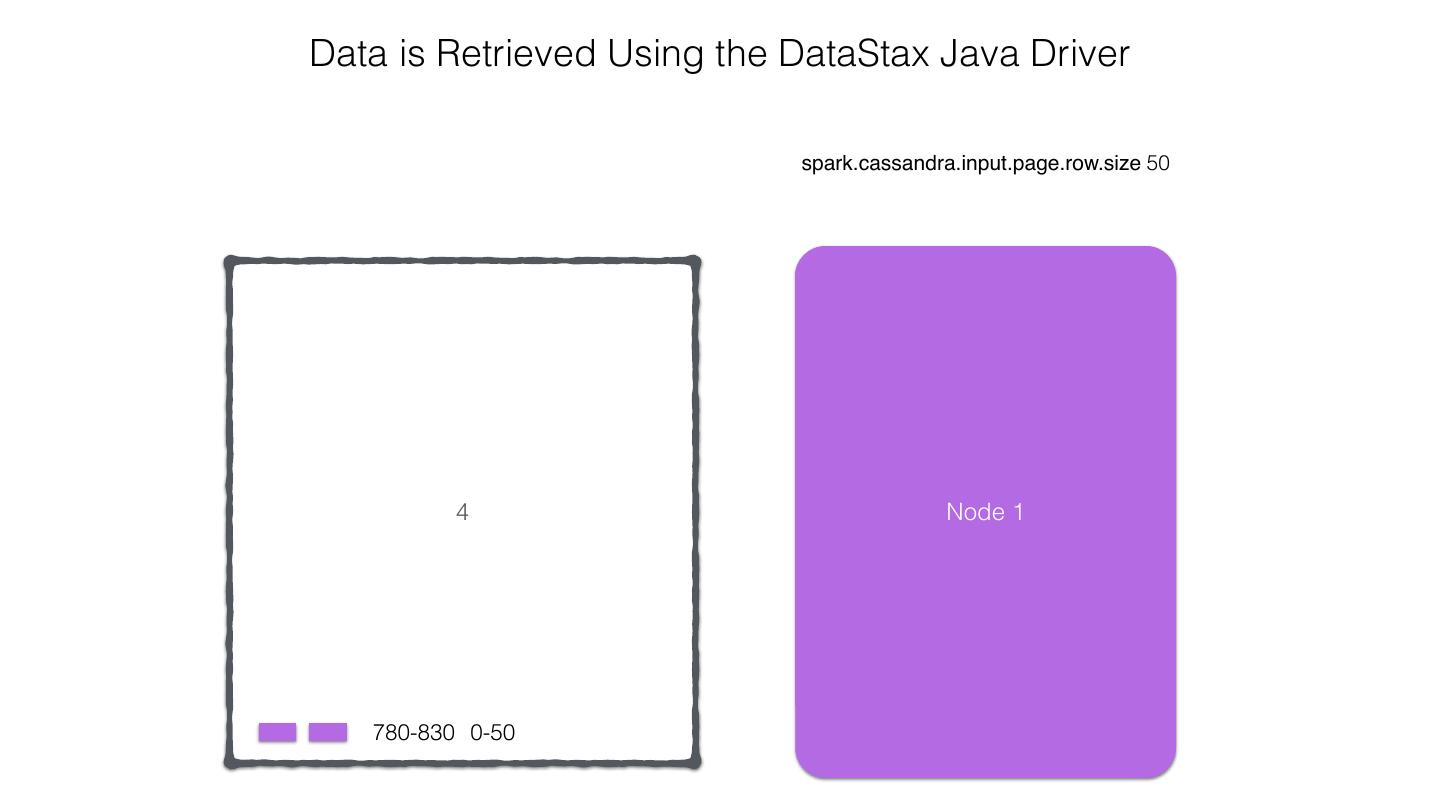
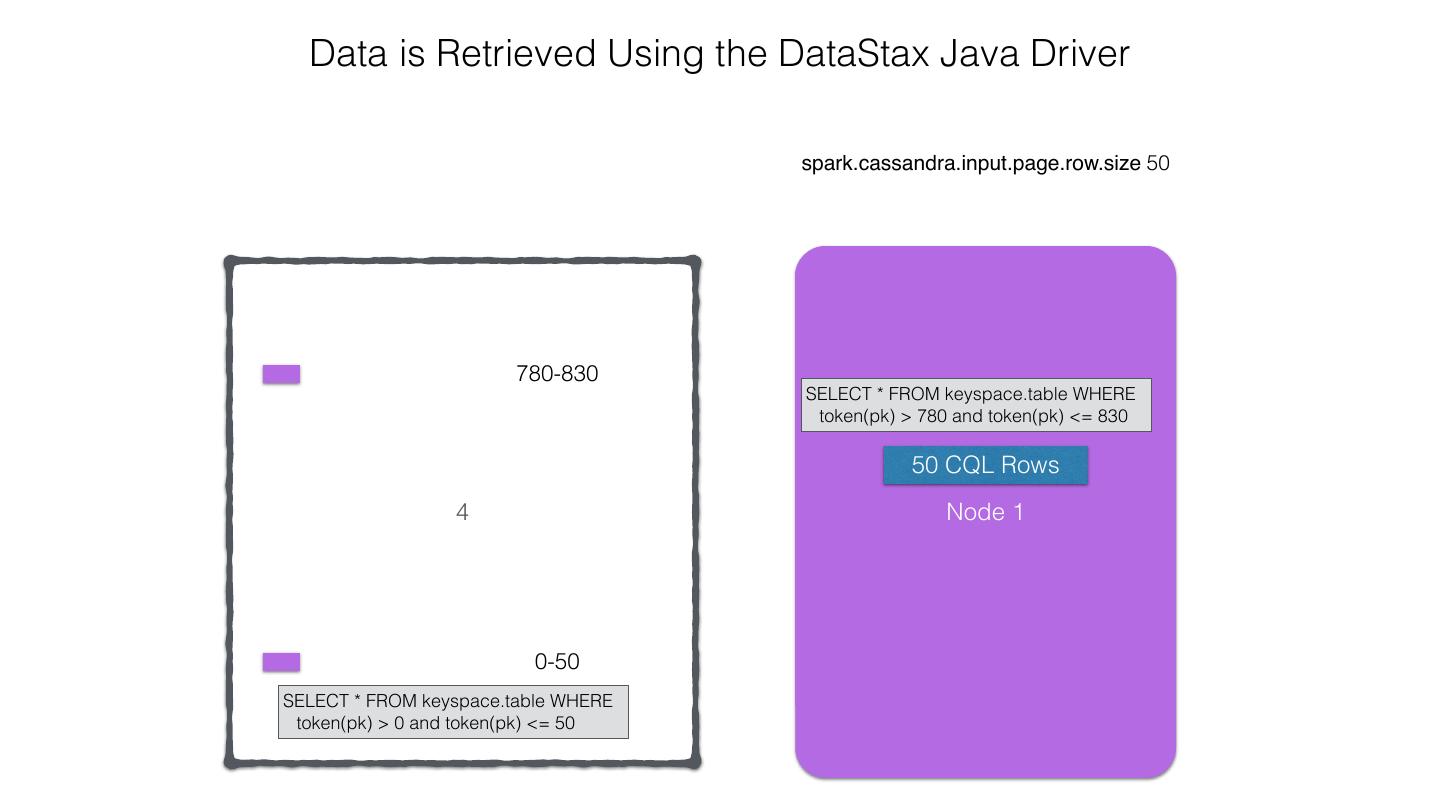
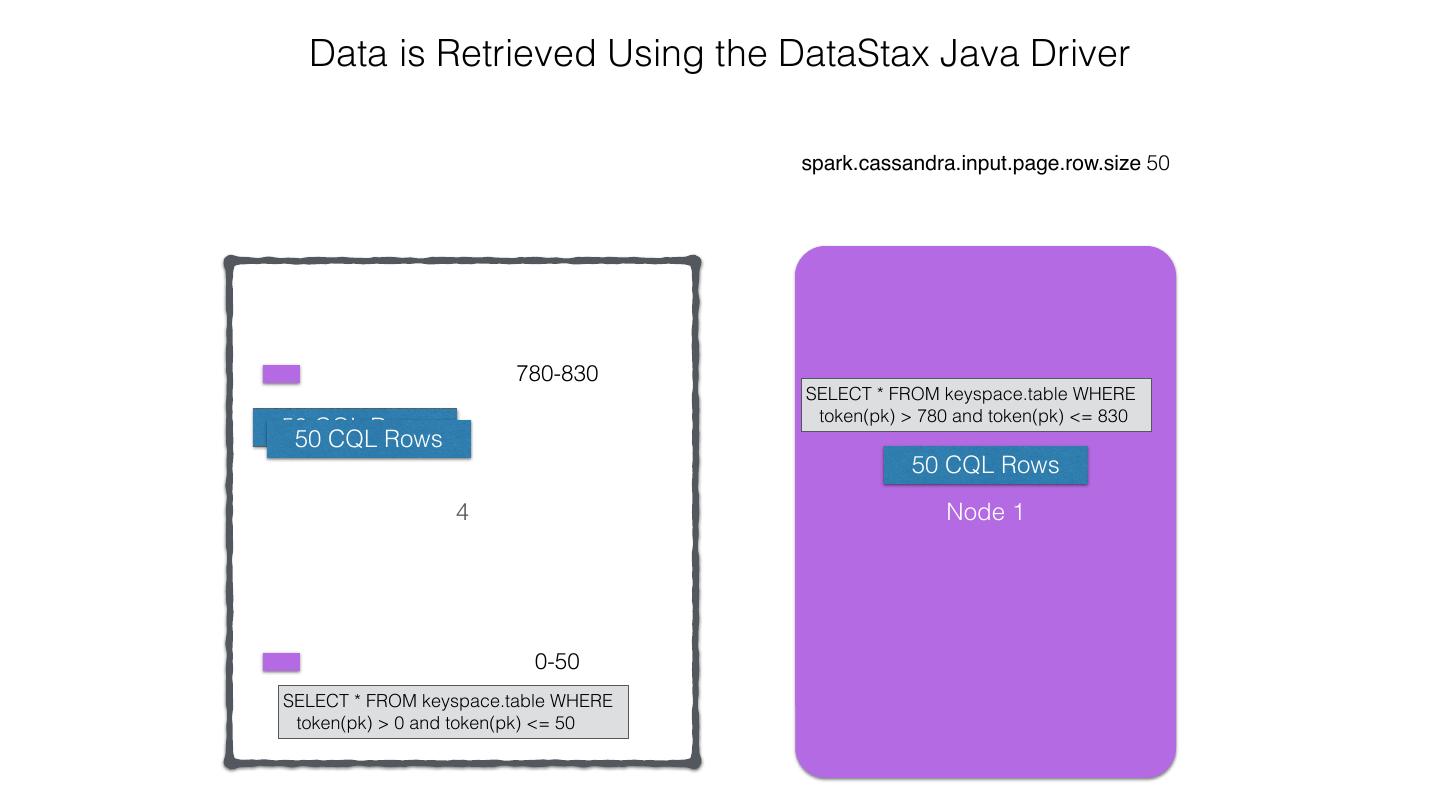
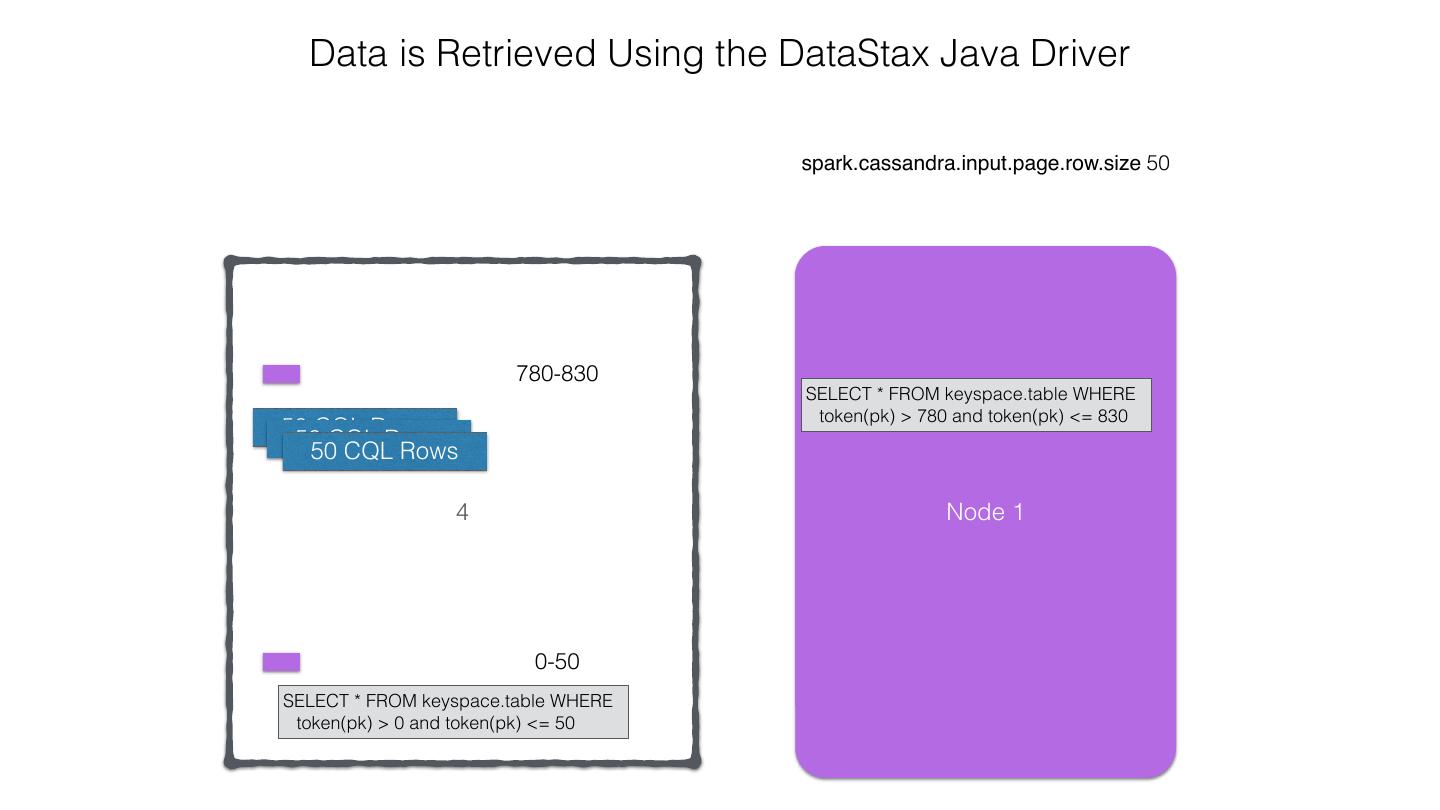
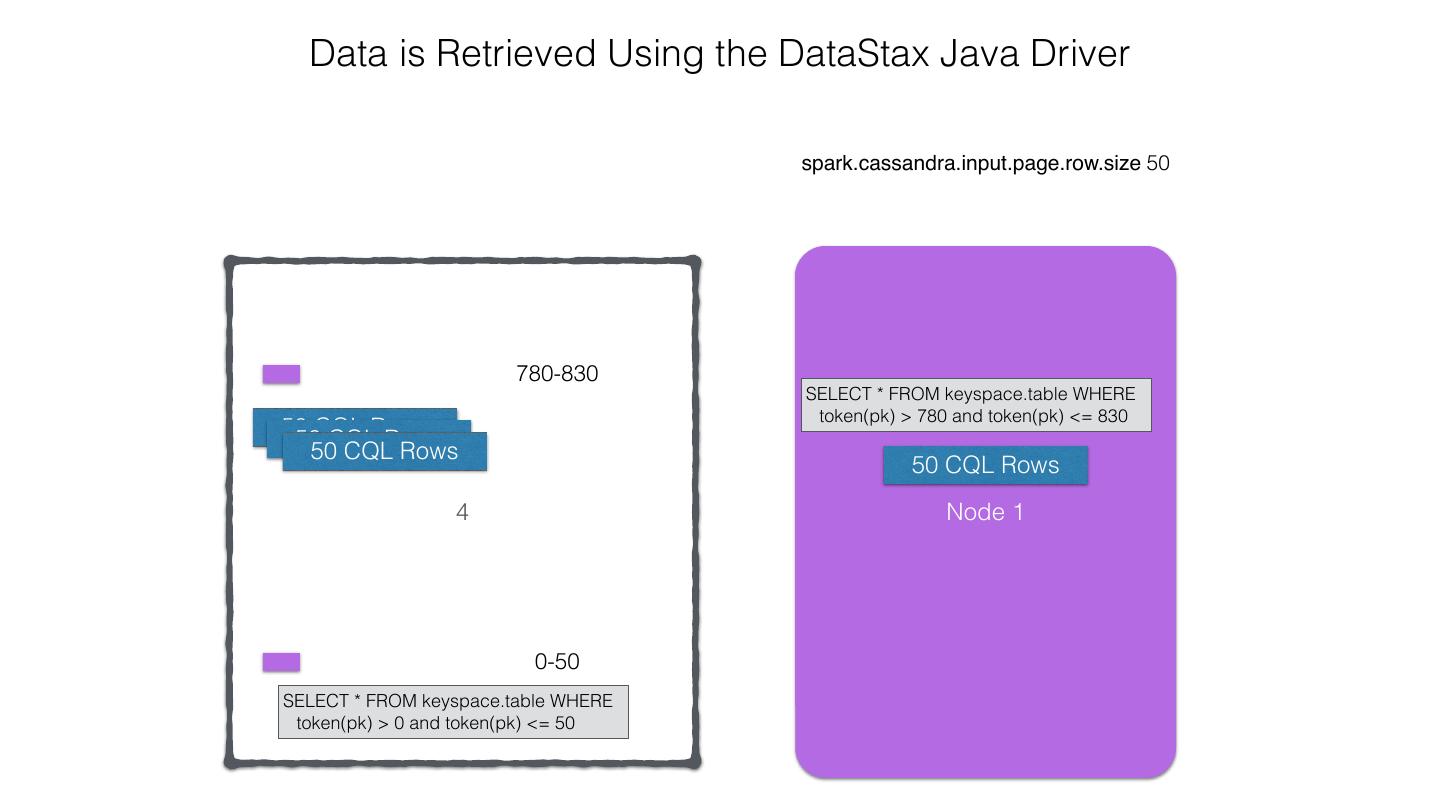
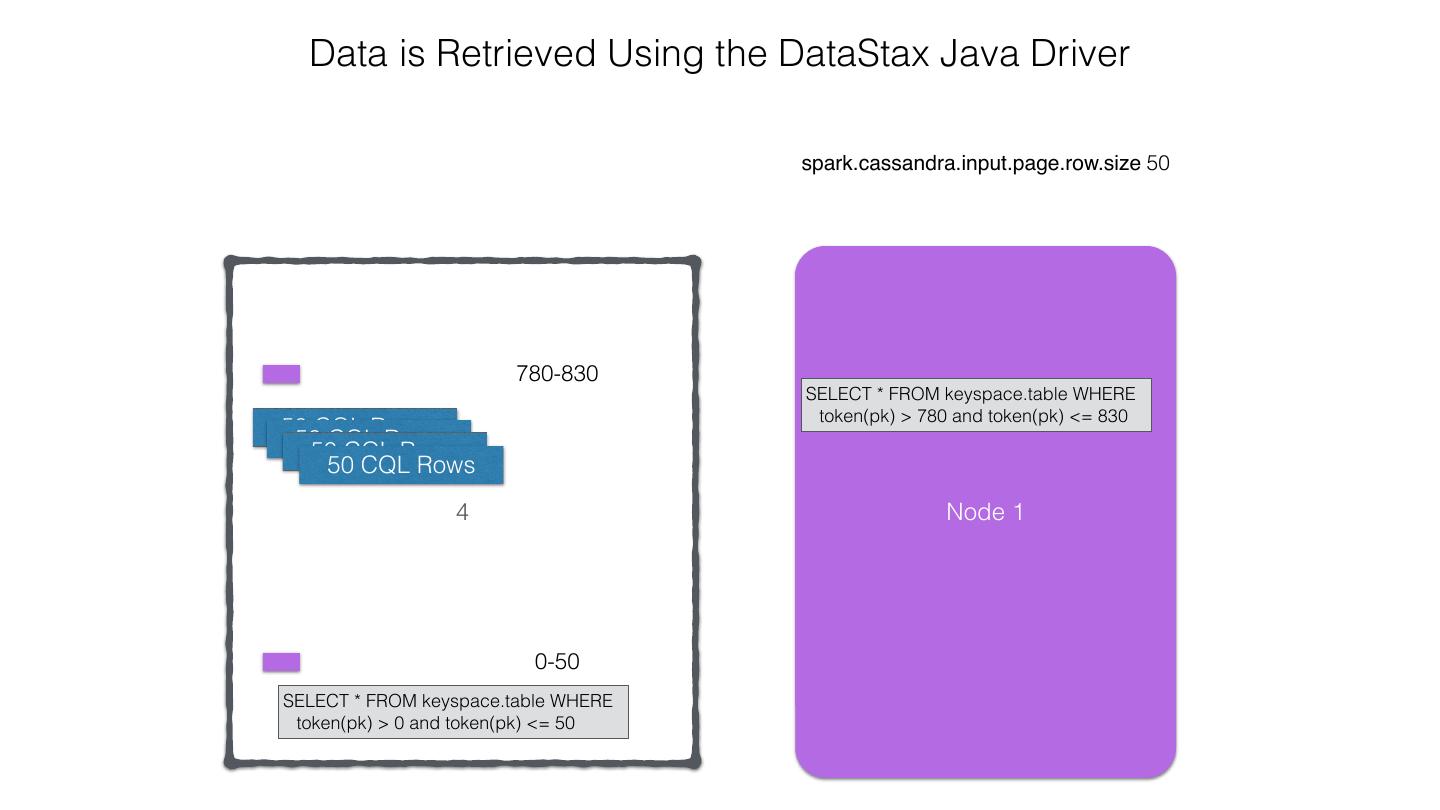
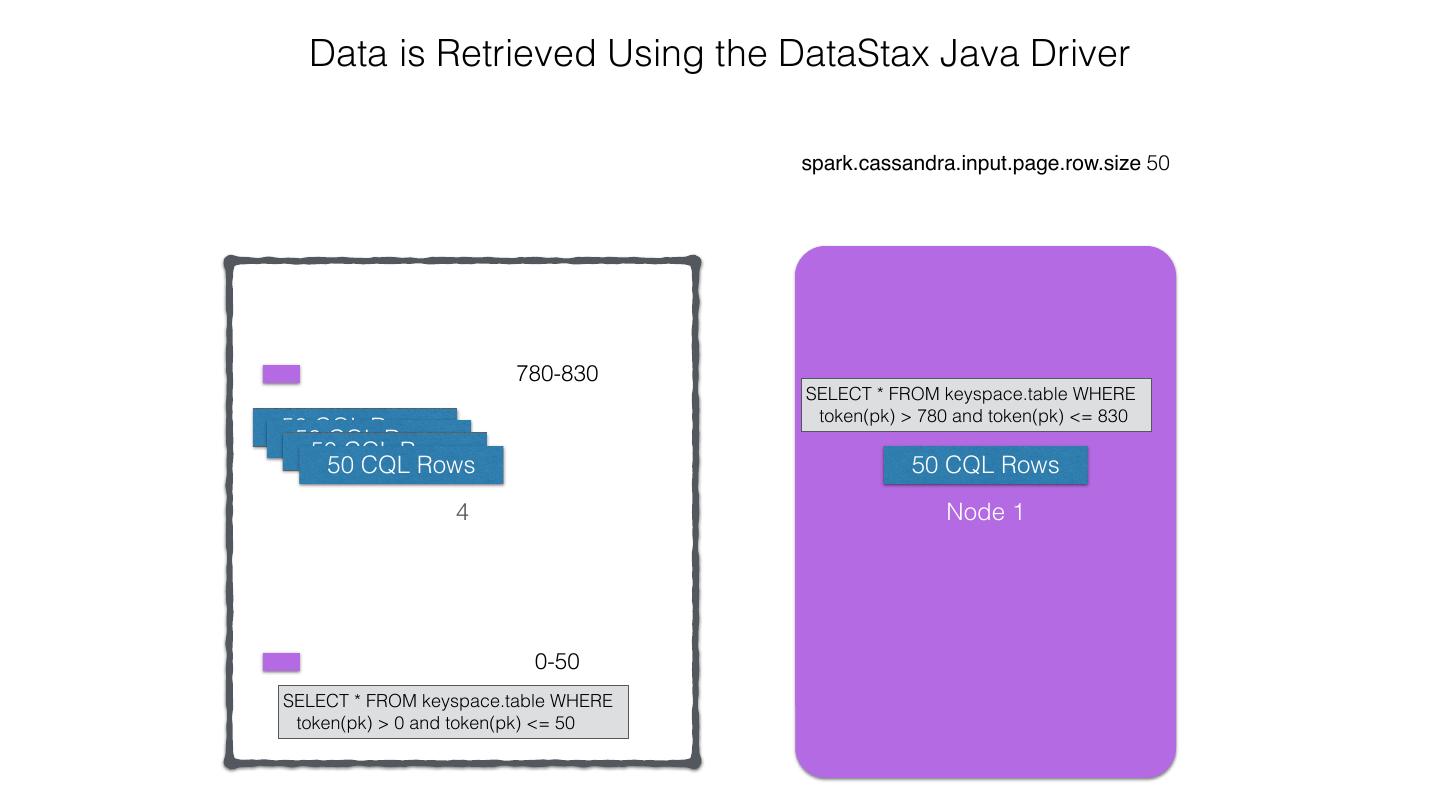
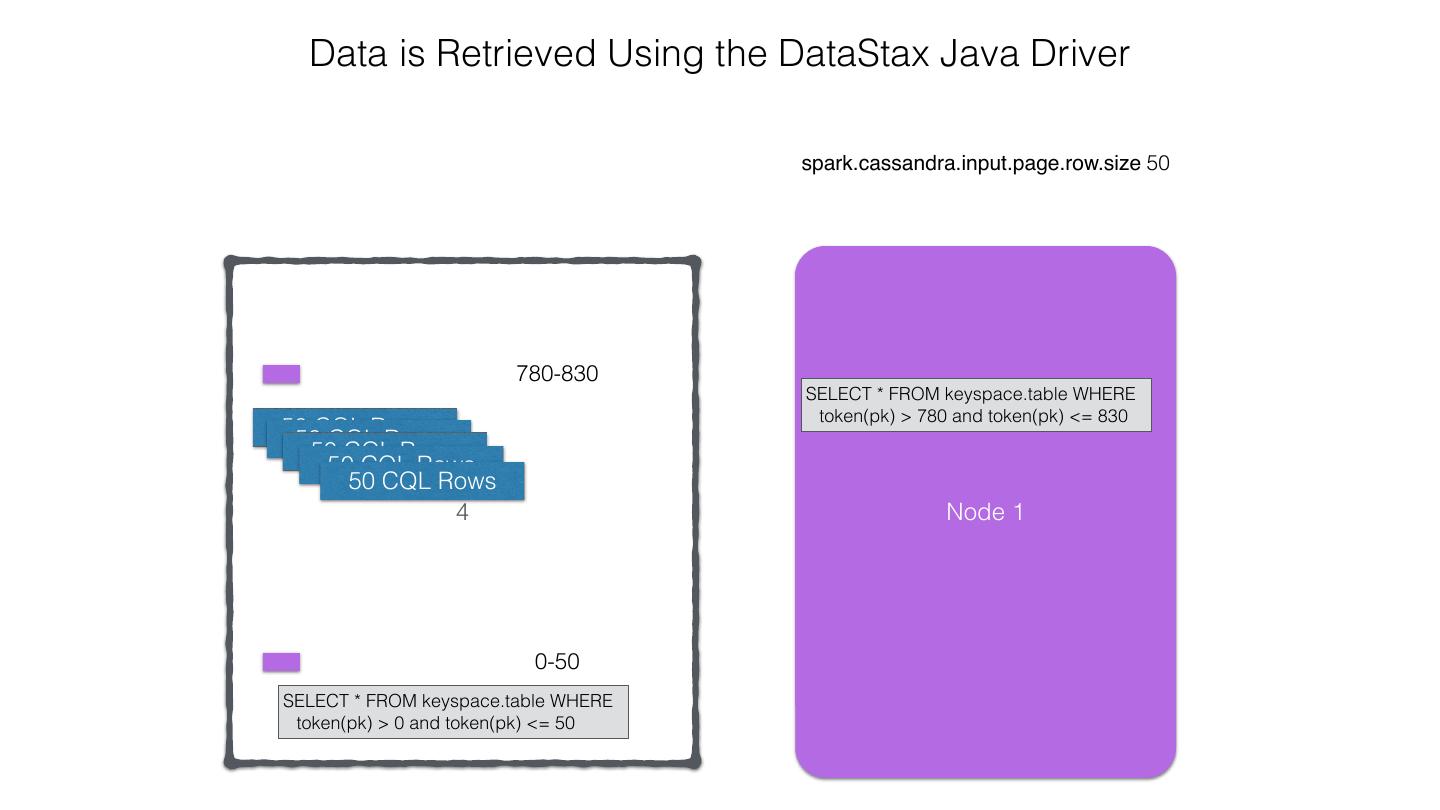
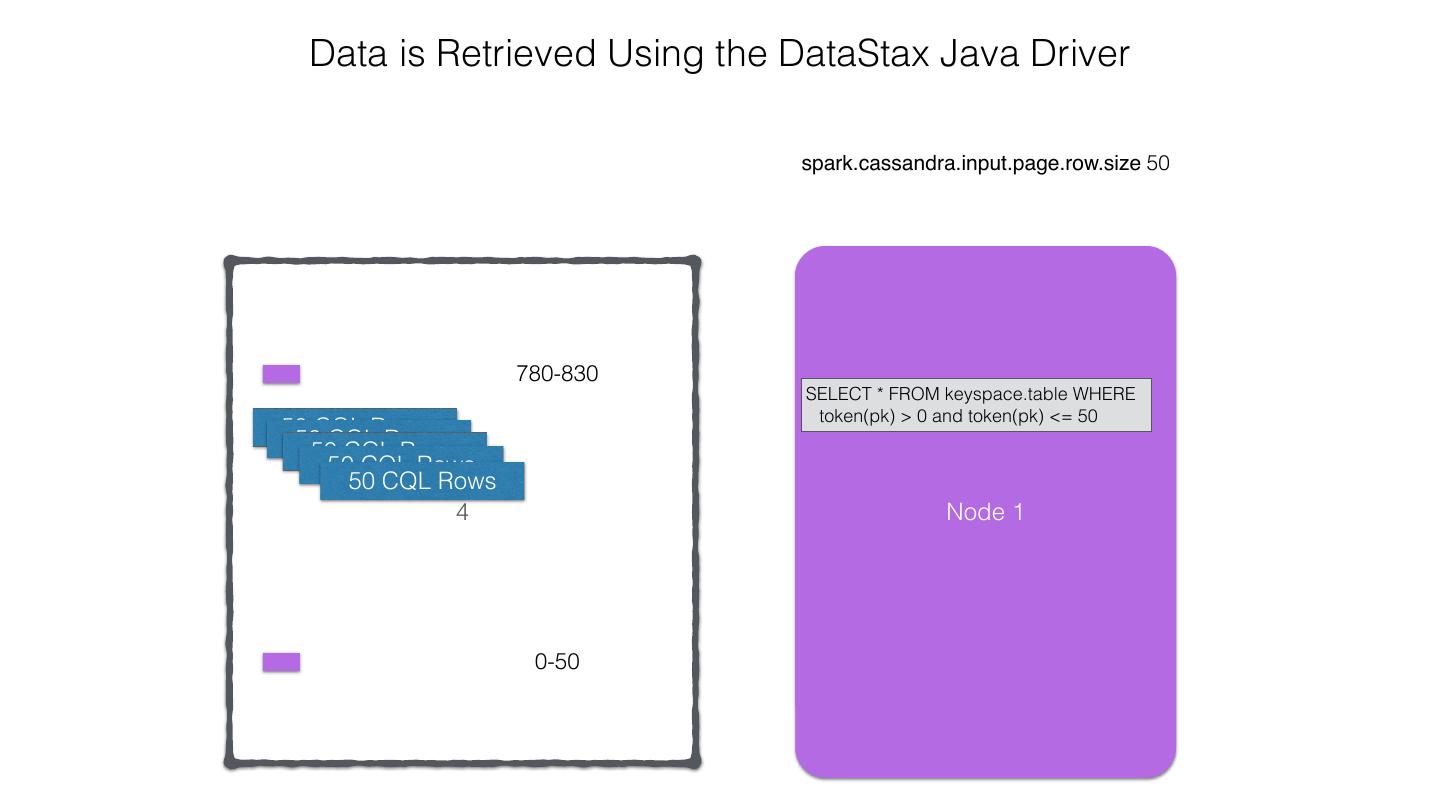
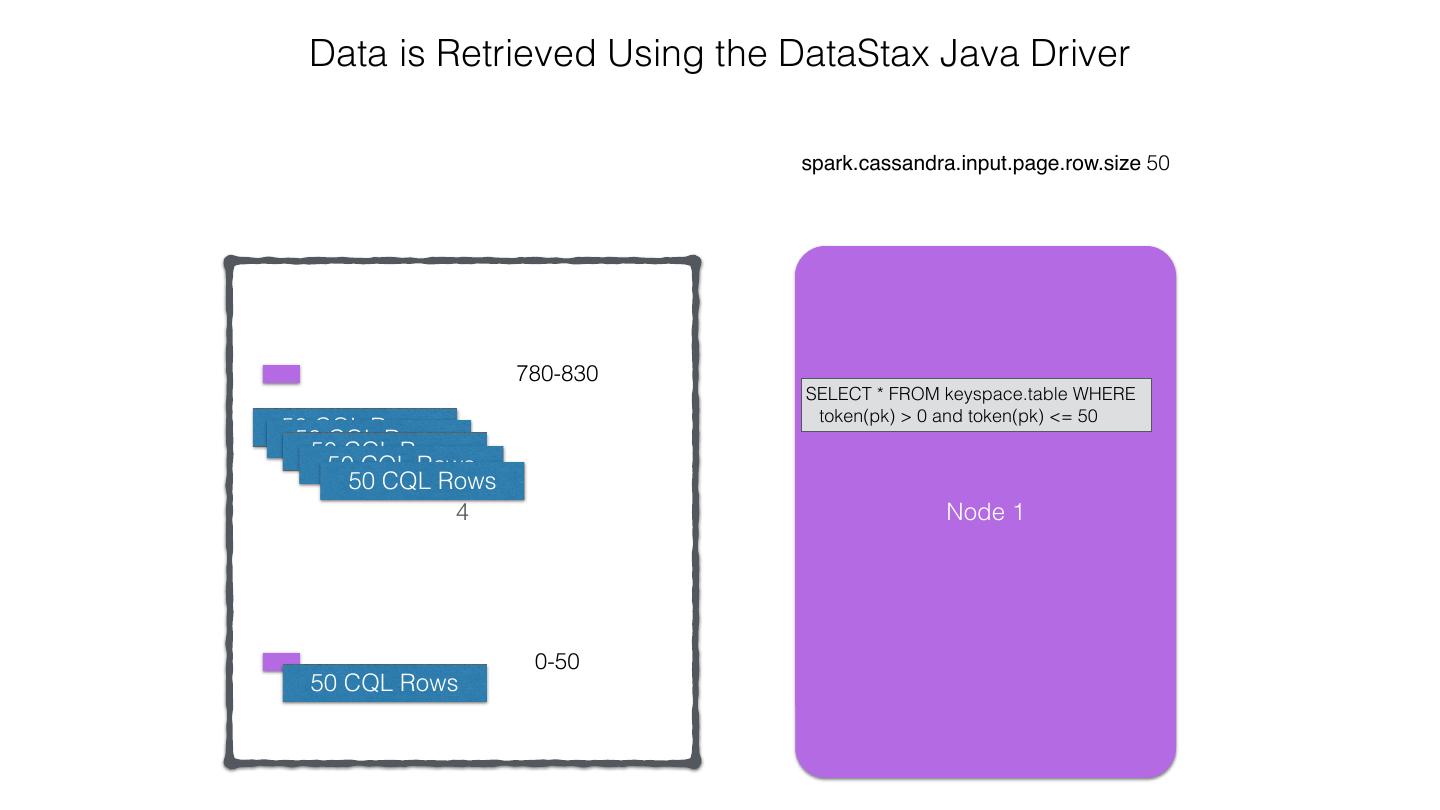
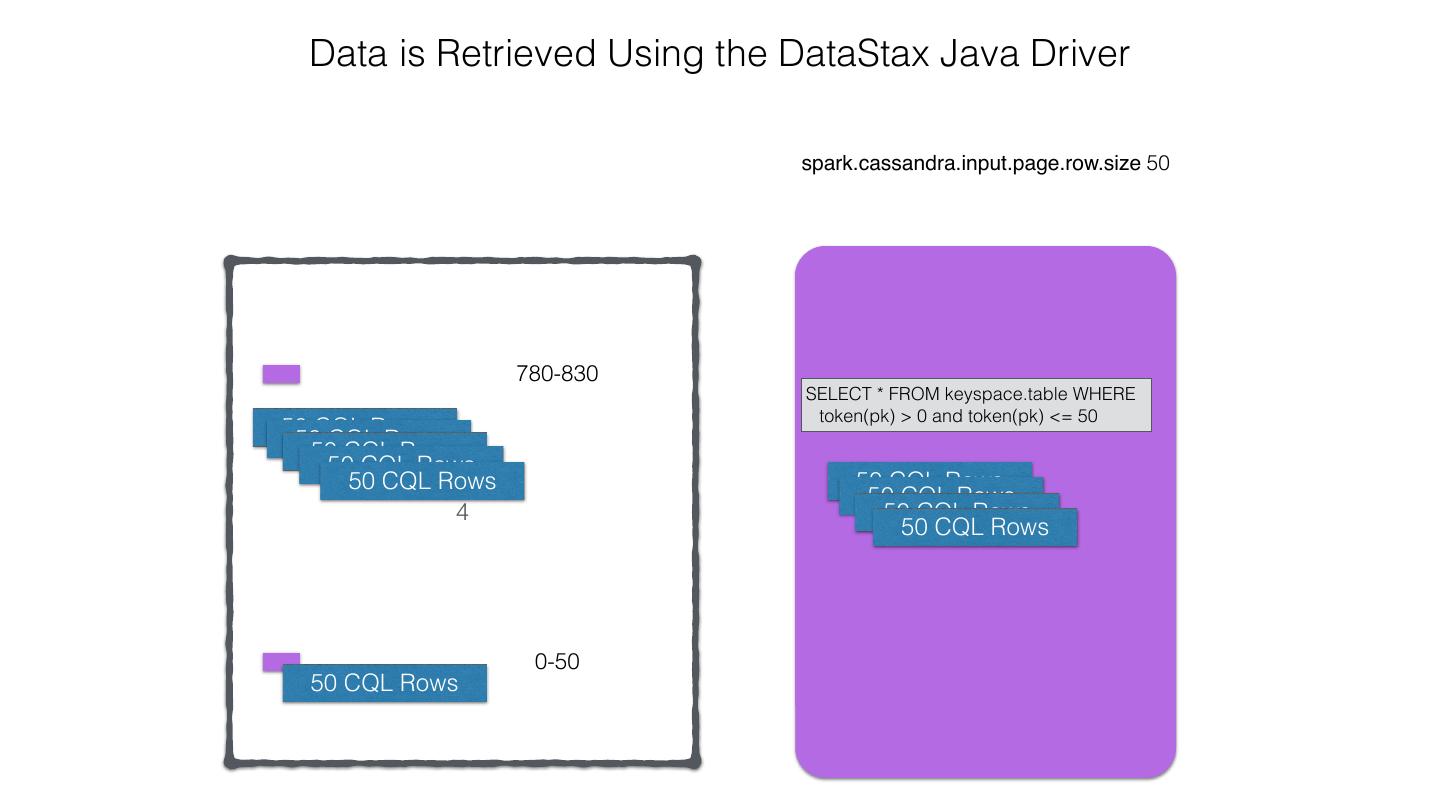
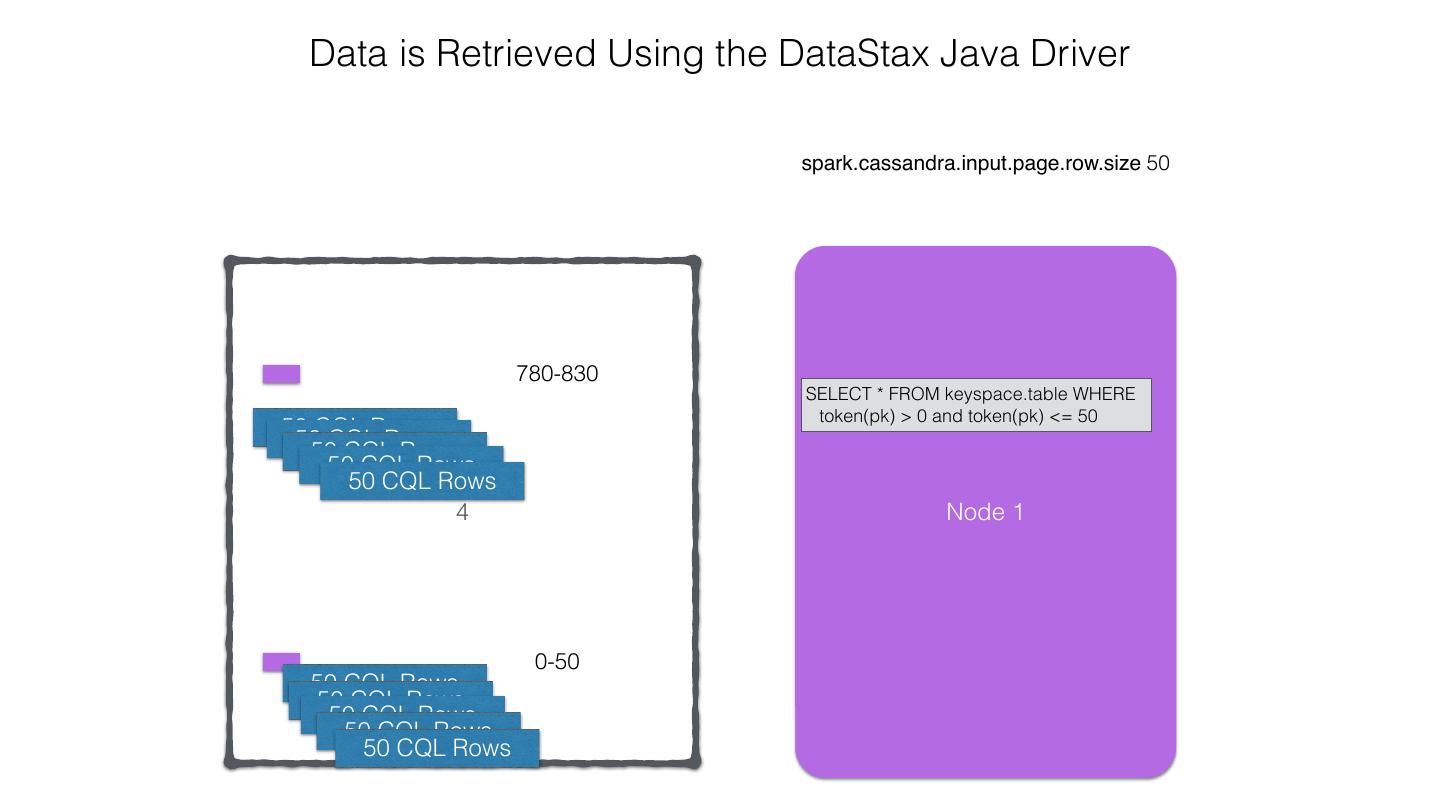
25 .Spark Cassandra Connector Spark Cassandra Connector uses the DataStax Java Driver to Read from and Write to C* Spark Each Executor Maintains Executor Spark DataStax C* a connection to the C* Java Driver Cluster Tokens … Tokens 1001 -2000 Full Token RDD’s read into different Range Tokens 1-1000 splits based on sets of tokens
26 . Co-locate Spark and C* for Best Performance Spark Worker Running Spark Workers on C* Spark Spark the same nodes as your Master Worker C* Cluster will save C* Spark C* network hops when Worker reading and writing C*
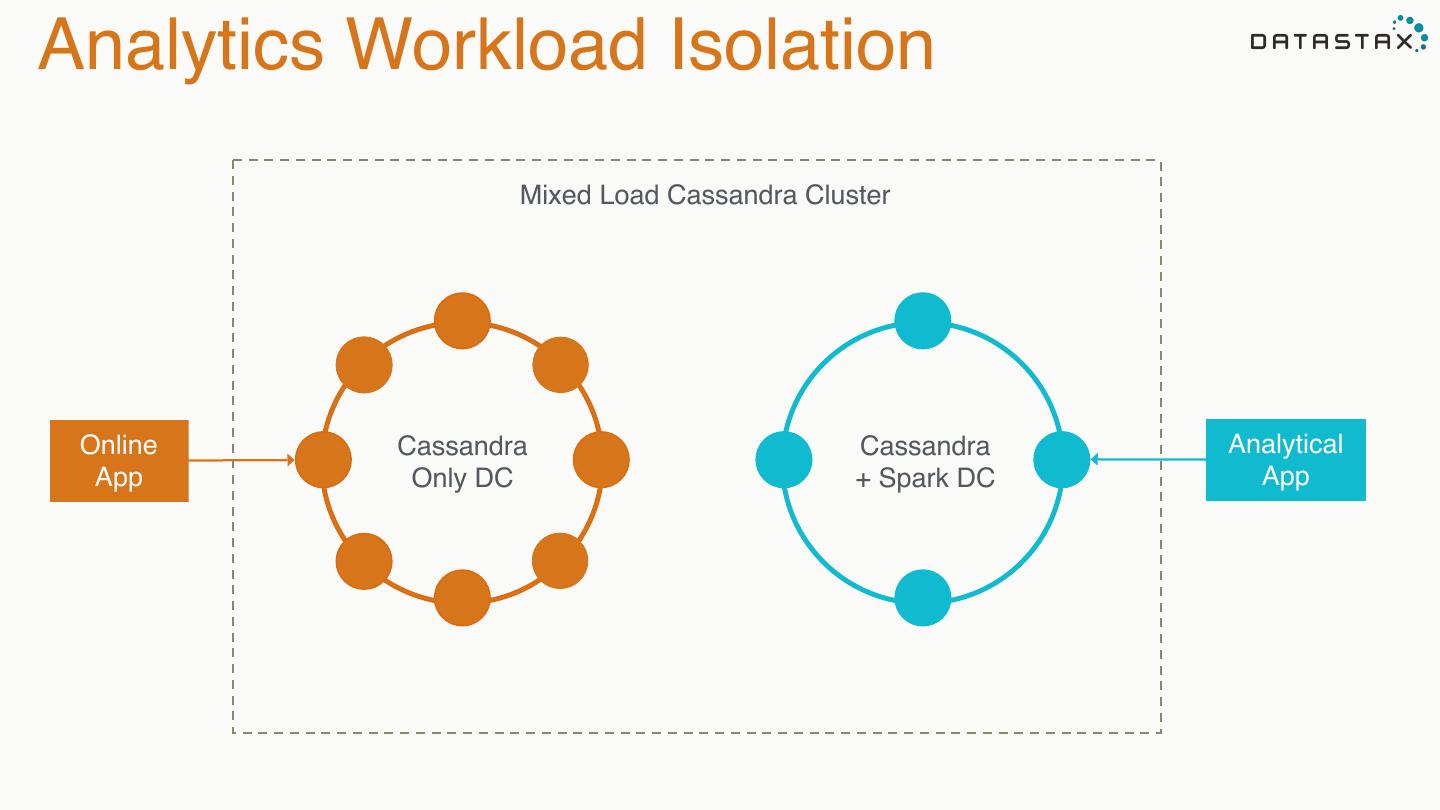
27 .Analytics Workload Isolation Mixed Load Cassandra Cluster Online Cassandra Cassandra Analytical App Only DC + Spark DC App
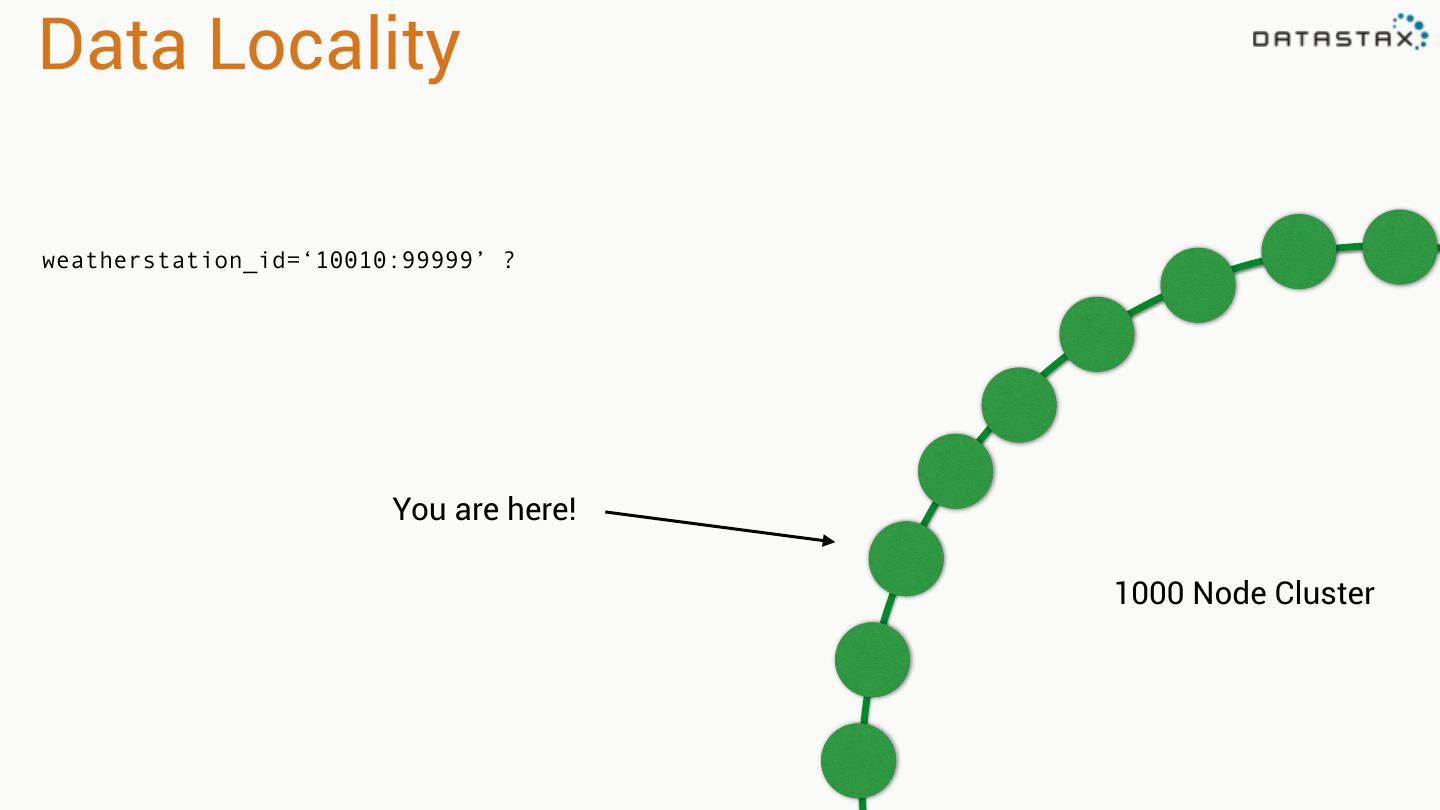
28 .Data Locality
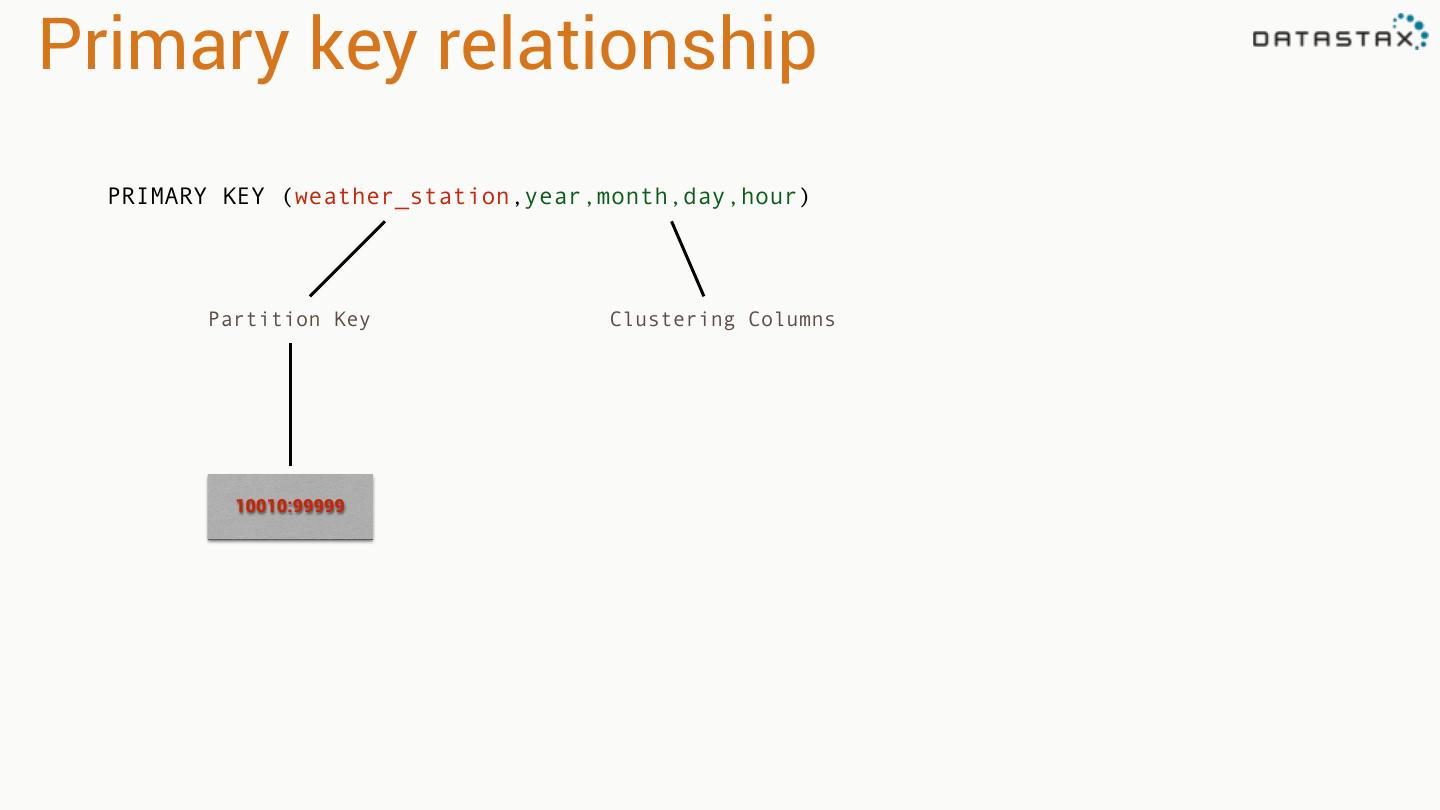
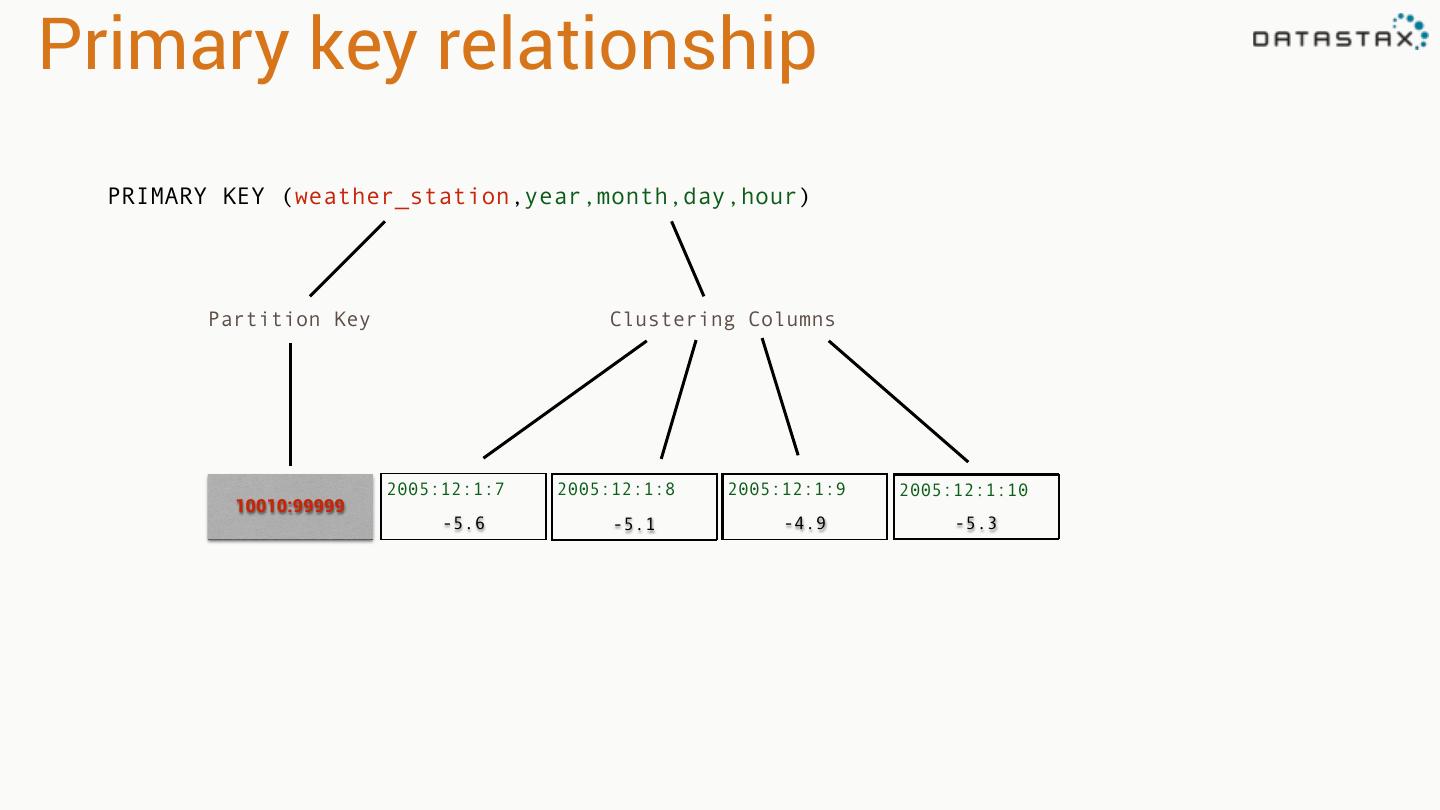
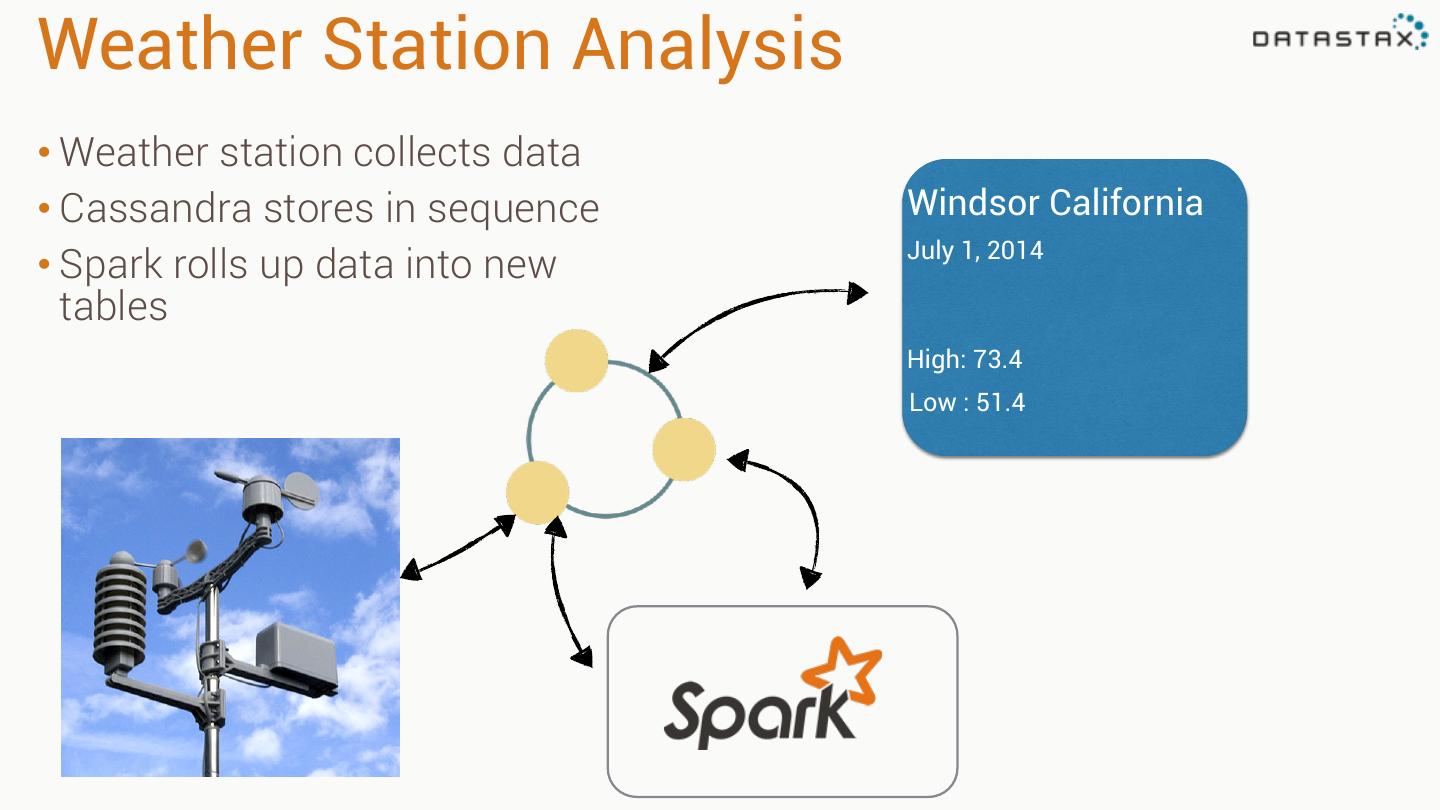
29 .Example 1: Weather Station • Weather station collects data • Cassandra stores in sequence • Application reads in sequence
3秒后跳转登录页面
去登陆

