
















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
15/04 - TIme Series analysis with spark and cassandra
Time series analysis with Spark and
Cassandra
视频:https://www.youtube.com/watch?v=uERFXD1Nj6E
展开查看详情
1 .Time series analysis with Spark and Cassandra Christopher Batey Technical Evangelist for Apache Cassandra @chbatey
2 .Who am I? • Technical Evangelist for Apache Cassandra • Founder of Stubbed Cassandra • Help out Apache Cassandra users • DataStax • Builds enterprise ready version of Apache Cassandra • Previous: Cassandra backed apps at BSkyB @chbatey
3 .Agenda • Motivation • Cassandra • Replication • Fault tolerance • Data modelling • Spark • Use cases • Stream processing • Time series example: Weather station data @chbatey
4 .OLTP OLAP Batch @chbatey
5 .Weather data streaming Dashboard Incoming Producer Apache Kafka weather events Consumer NodeGuardian
6 .@chbatey
7 .@chbatey
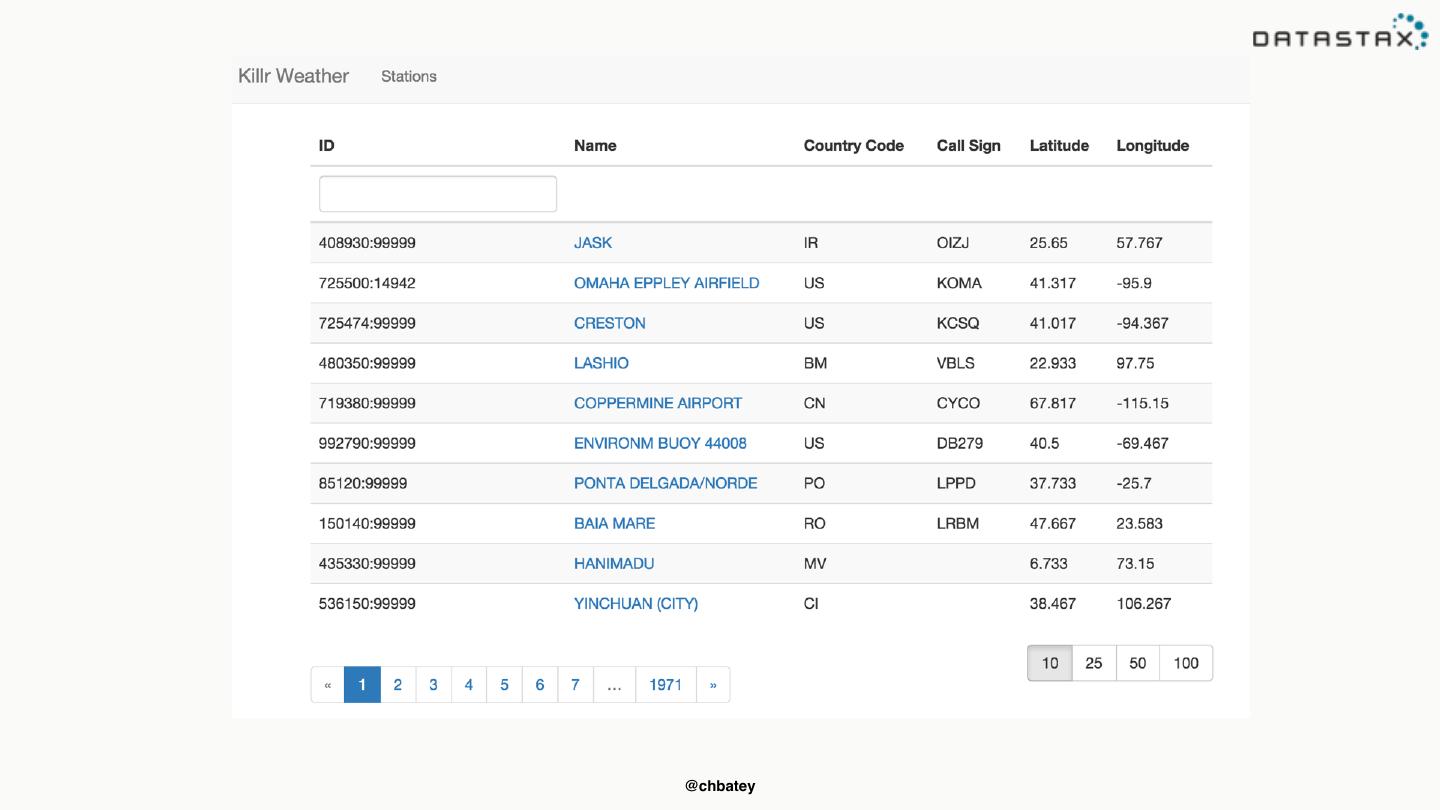
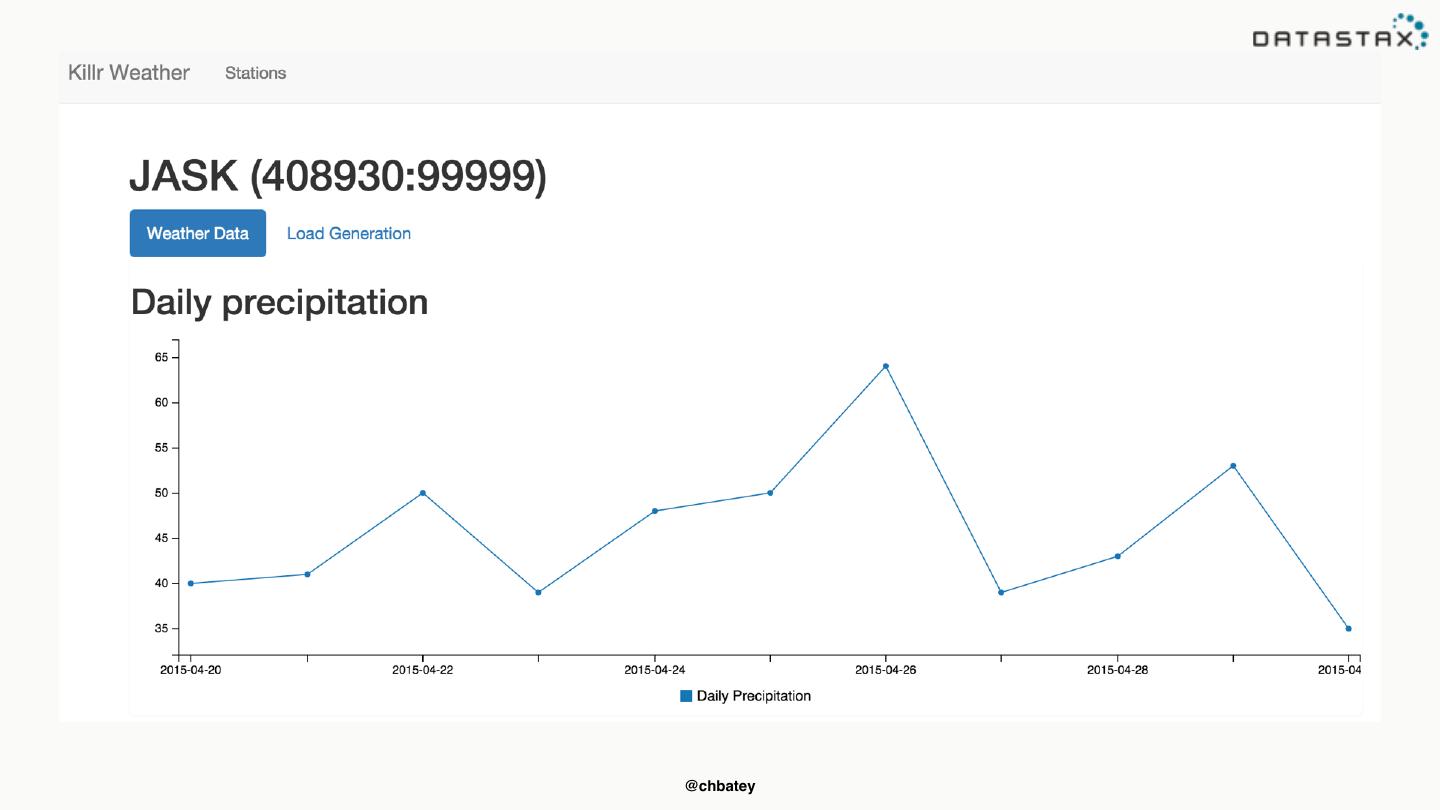
8 .Run this your self • https://github.com/killrweather/killrweather @chbatey
9 .Cassandra @chbatey
10 .Cassandra for Applications APACHE CASSANDRA @chbatey
11 .Common use cases • Ordered data such as time series - Event stores - Financial transactions - IoT e.g Sensor data @chbatey
12 .Common use cases • Ordered data such as time series - Event stores - Financial transactions - IoT e.g Sensor data • Non functional requirements: - Linear scalability - High throughout durable writes - Multi datacenter including active-active - Analytics without ETL @chbatey
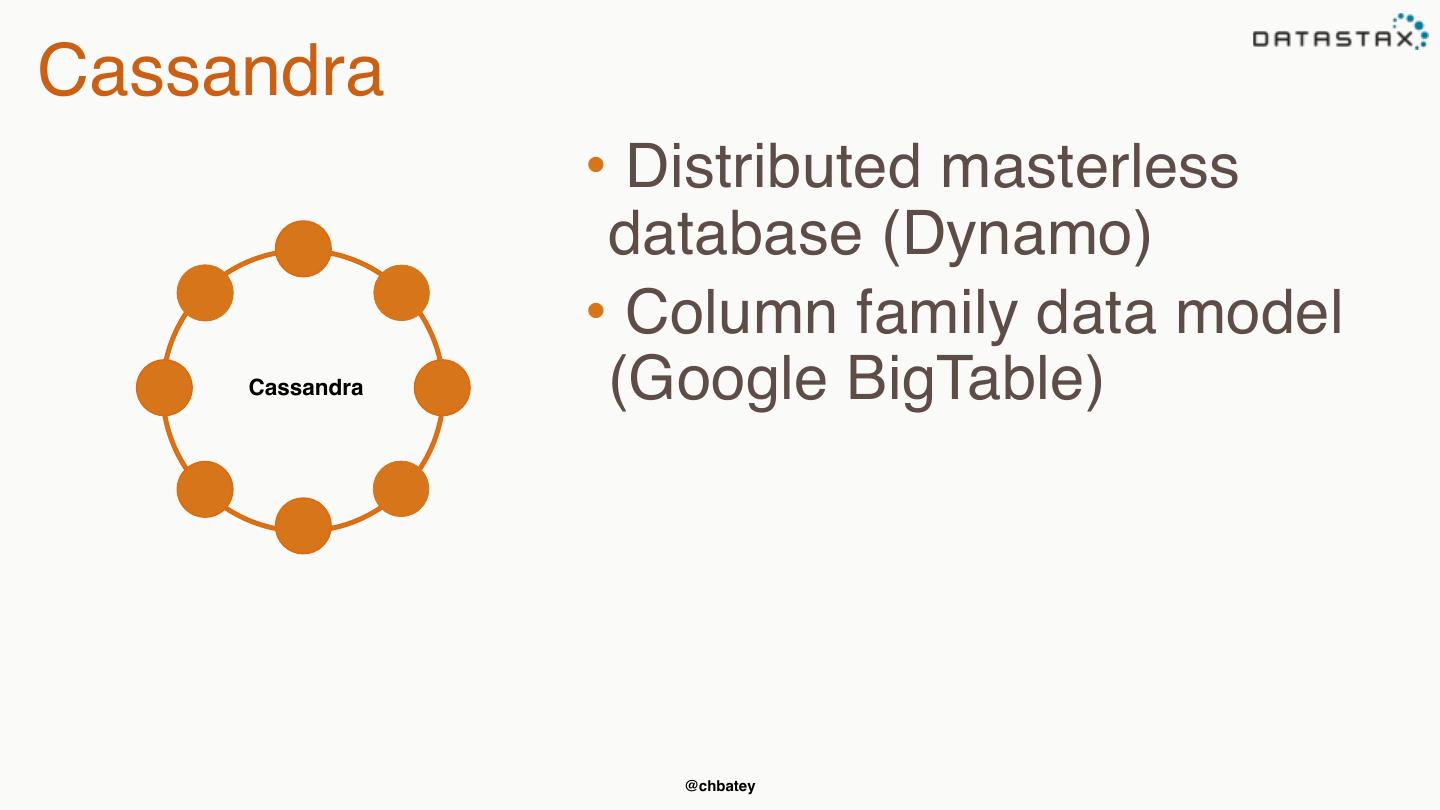
13 .Cassandra • Distributed masterless database (Dynamo) • Column family data model Cassandra (Google BigTable) @chbatey
14 .Datacenter and rack aware • Distributed master less Europe database (Dynamo) • Column family data model (Google BigTable) • Multi data centre replication built in from the start USA @chbatey
15 .Cassandra • Distributed master less Online database (Dynamo) • Column family data model (Google BigTable) • Multi data centre replication built in from the start Analytics • Analytics with Apache Spark @chbatey
16 .Dynamo 101 @chbatey
17 .Dynamo 101 • The parts Cassandra took - Consistent hashing - Replication - Gossip - Hinted handoff - Anti-entropy repair • And the parts it left behind - Key/Value - Vector clocks @chbatey
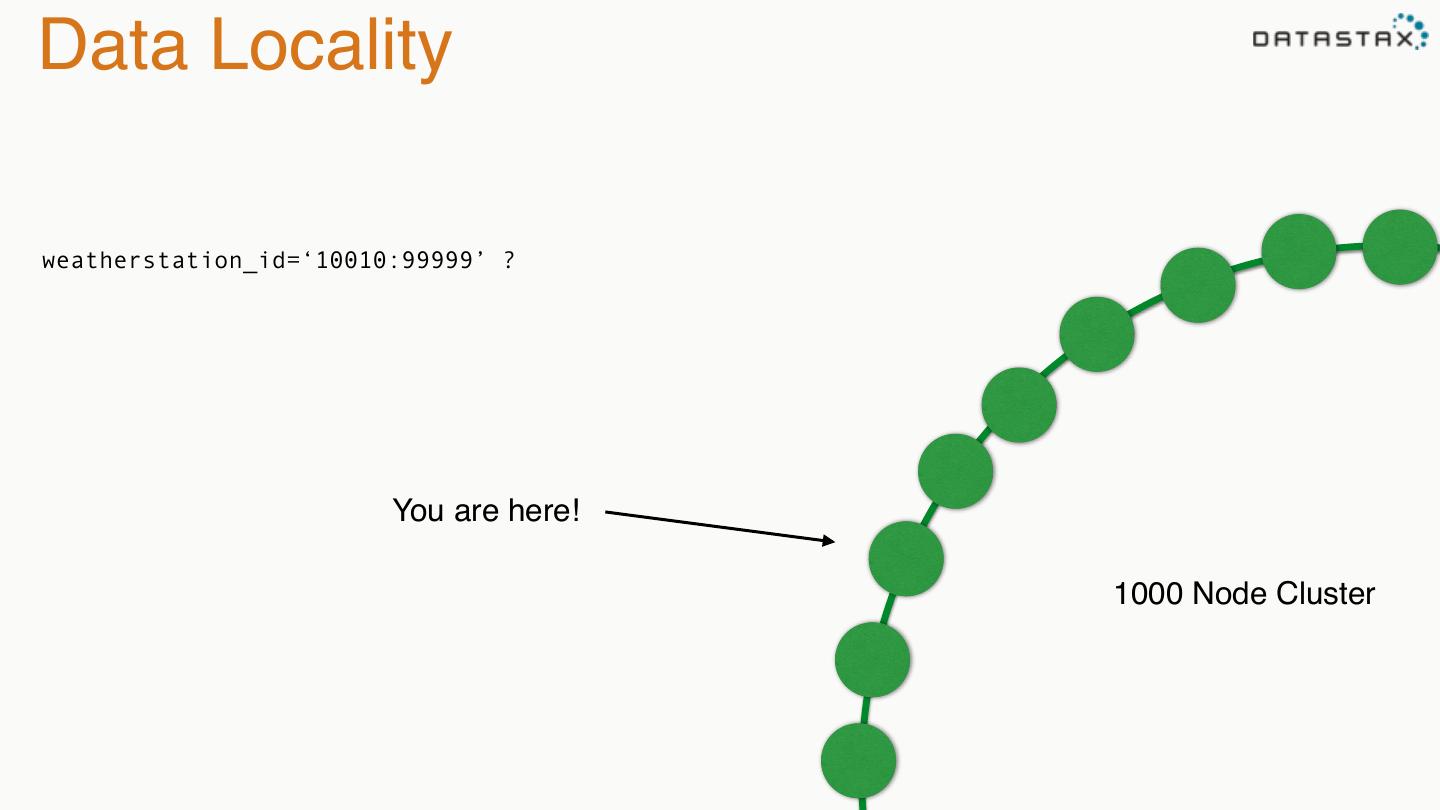
18 .Picking the right nodes • You don’t want a full table scan on a 1000 node cluster! • Dynamo to the rescue: Consistent Hashing @chbatey
19 .Murmer3 Example Primary Key • Data: jim age: 36 car: ford gender: M carol age: 37 car: bmw gender: F johnny age: 12 gender: M suzy: age: 10 gender: F • Murmer3 Hash Values: Primary Key Murmur3 hash value jim 350 carol 998 johnny 50 suzy 600 Real hash range: -9223372036854775808 to 9223372036854775807 @chbatey
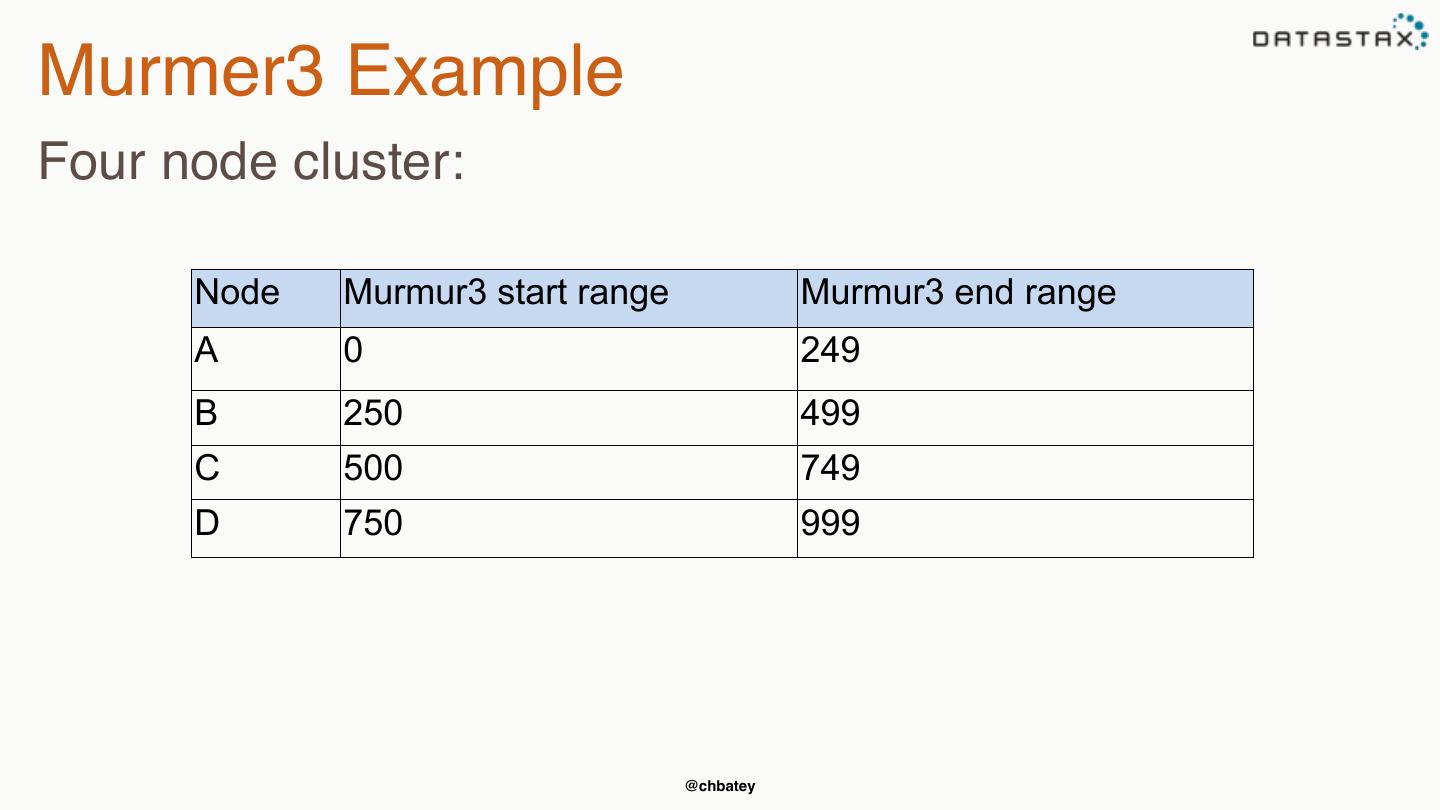
20 .Murmer3 Example Four node cluster: Node Murmur3 start range Murmur3 end range A 0 249 B 250 499 C 500 749 D 750 999 @chbatey
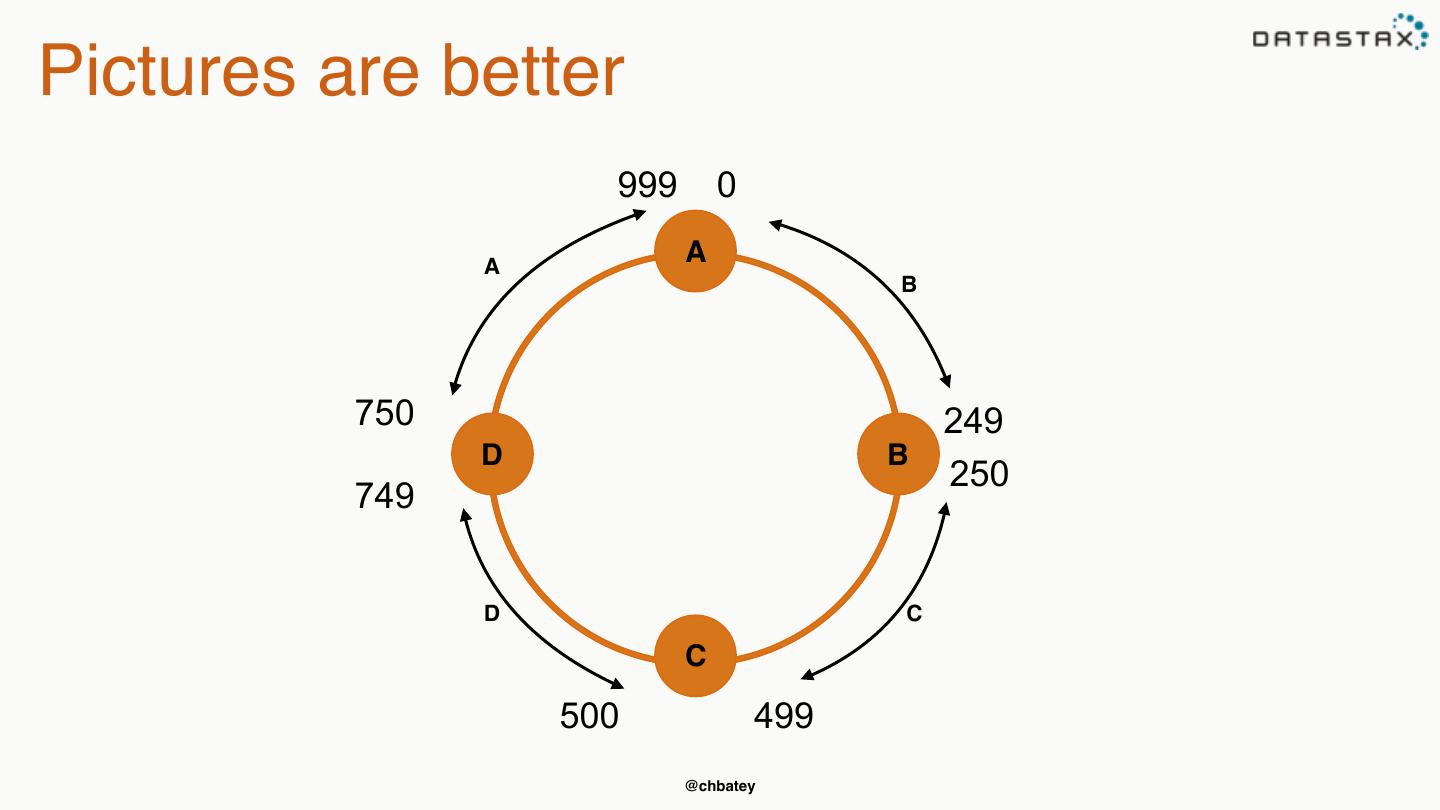
21 .Pictures are better 999 0 A A B 750 249 D B 250 749 D C C 500 499 @chbatey
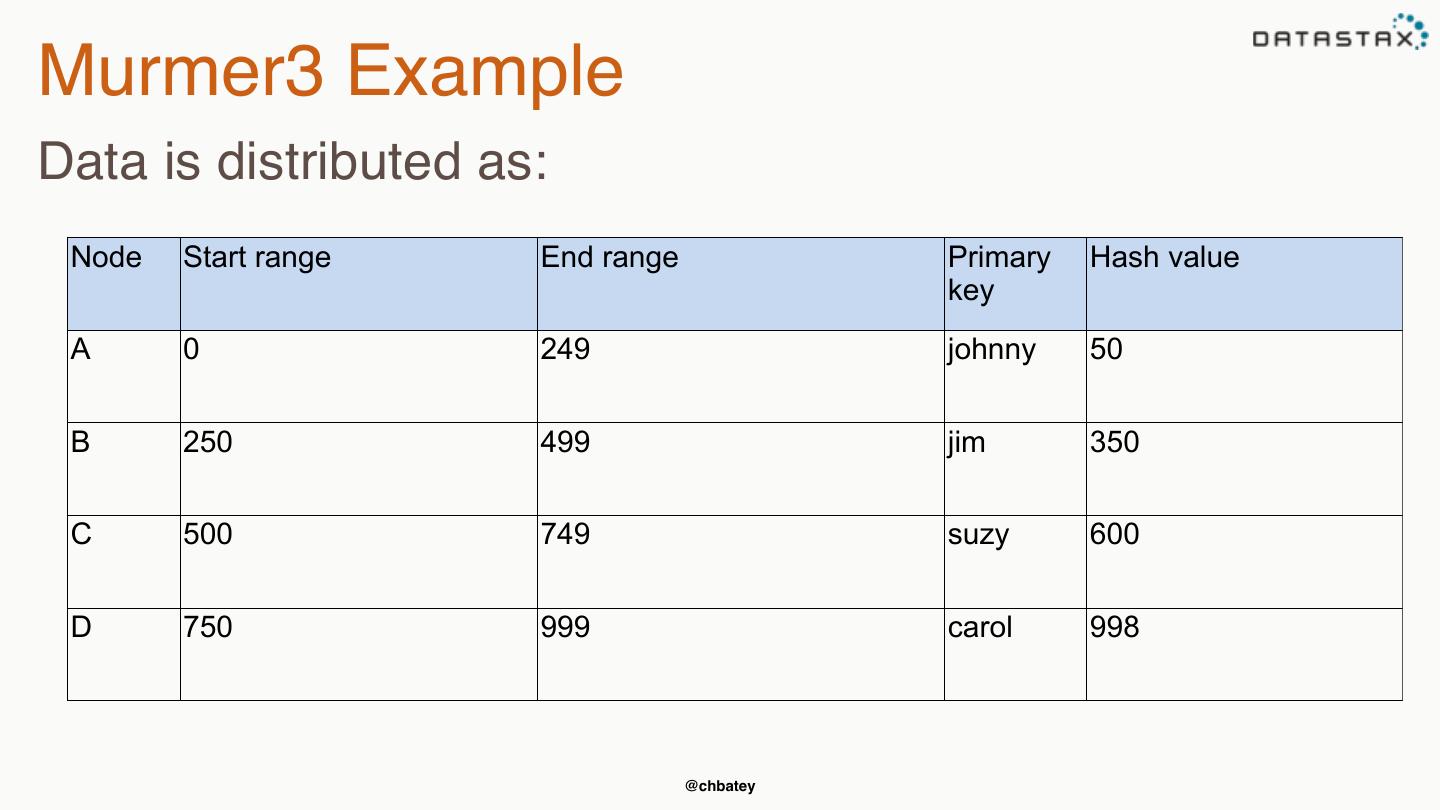
22 .Murmer3 Example Data is distributed as: Node Start range End range Primary Hash value key A 0 249 johnny 50 B 250 499 jim 350 C 500 749 suzy 600 D 750 999 carol 998 @chbatey
23 .Replication @chbatey
24 .Replication strategy • Simple - Give it to the next node in the ring - Don’t use this in production • NetworkTopology - Every Cassandra node knows its DC and Rack - Replicas won’t be put on the same rack unless Replication Factor > # of racks - Unfortunately Cassandra can’t create servers and racks on the fly to fix this :( @chbatey
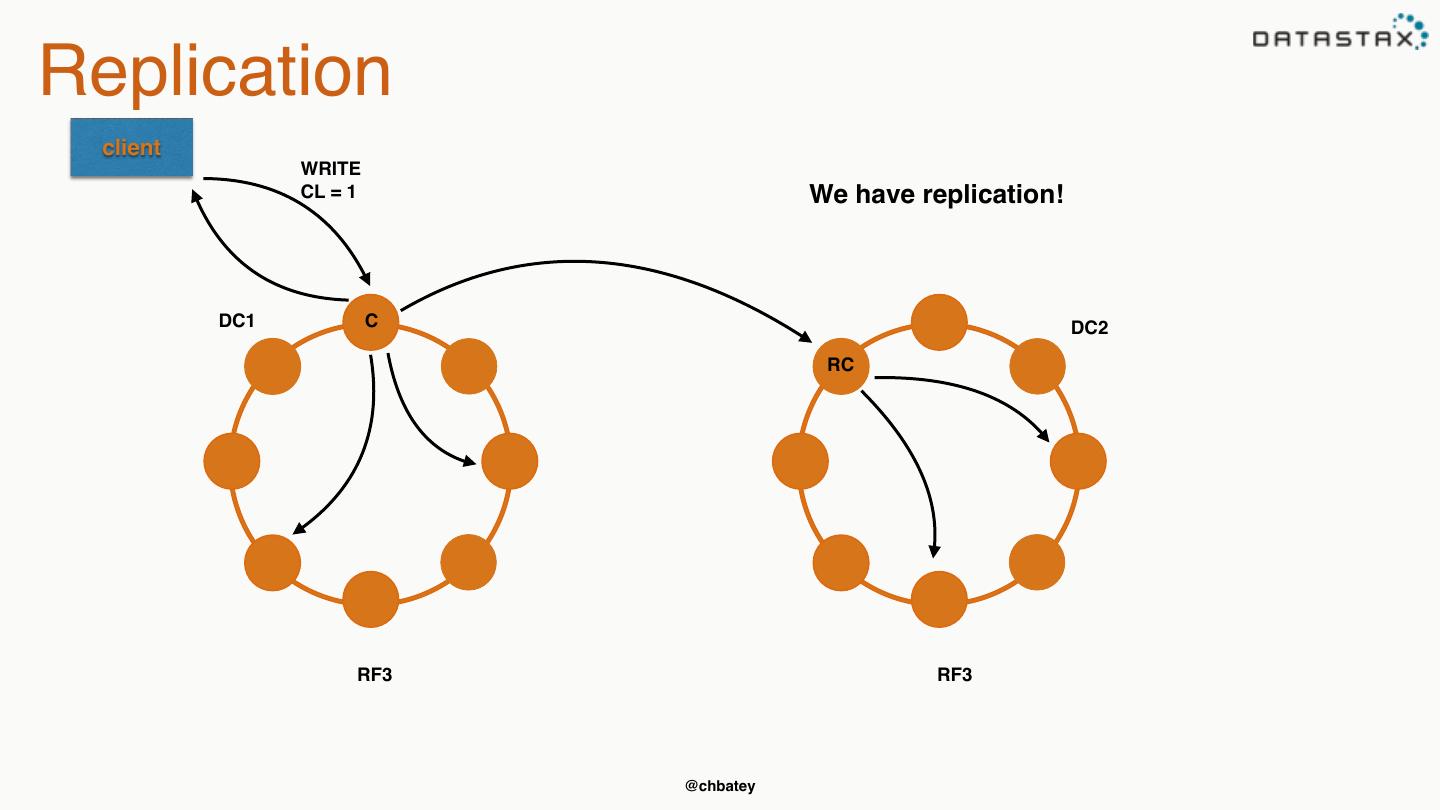
25 .Replication client WRITE CL = 1 We have replication! DC1 C DC2 RC RF3 RF3 @chbatey
26 .26
27 .Tunable Consistency • Data is replicated N times • Every query that you execute you give a consistency - ALL - QUORUM - LOCAL_QUORUM - ONE • Christos Kalantzis Eventual Consistency != Hopeful Consistency: http:// youtu.be/A6qzx_HE3EU?list=PLqcm6qE9lgKJzVvwHprow9h7KMpb5hcUU @chbatey
28 .Scaling shouldn’t be hard • Throw more nodes at a cluster • Bootstrapping + joining the ring • For large data sets this can take some time @chbatey
29 .Spark Time @chbatey
3秒后跳转登录页面
去登陆

