































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
14/03 - Time series with Apache Cassandra - Long version
Time series with Apache Cassandra
展开查看详情
1 . Time Series with Apache Cassandra Patrick McFadin Chief Evangelist @PatrickMcFadin ©2013 DataStax Confidential. Do not distribute without consent. 1
2 .Quick intro to Cassandra • Shared nothing • Masterless peer-to-peer • Based on Dynamo
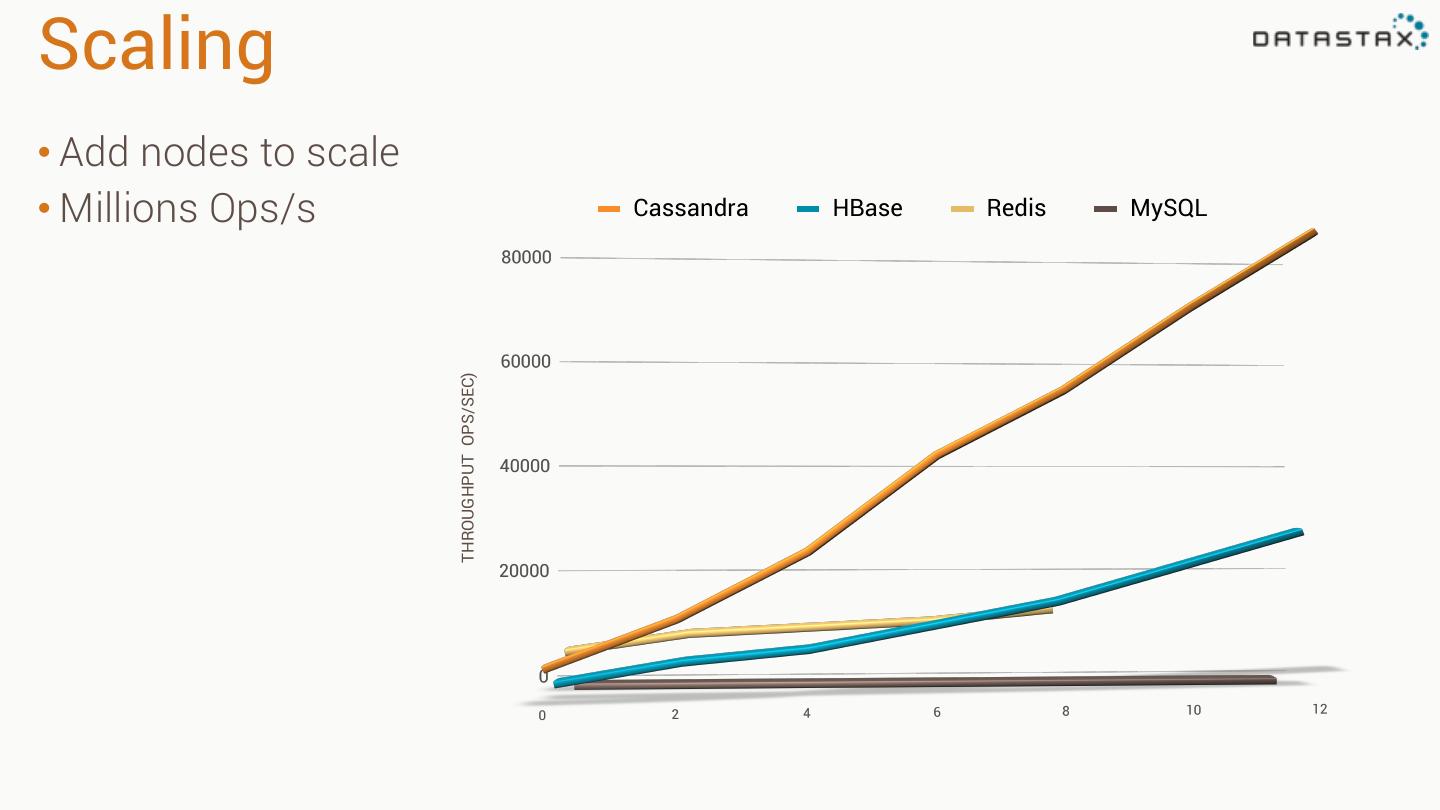
3 .Scaling • Add nodes to scale • Millions Ops/s Cassandra HBase Redis MySQL THROUGHPUT OPS/SEC)
4 .Uptime • Built to replicate • Resilient to failure • Always on NONE
5 .Easy to use CREATE TABLE users (! username varchar,! • CQL is a familiar syntax firstname varchar,! lastname varchar,! email list<varchar>,! • Friendly to programmers password varchar,! created_date timestamp,! • Paxos for locking ); PRIMARY KEY (username)! INSERT INTO users (username, firstname, lastname, ! email, password, created_date)! VALUES ('pmcfadin','Patrick','McFadin',! ['patrick@datastax.com'],'ba27e03fd95e507daf2937c937d499ab',! '2011-06-20 13:50:00');! INSERT INTO users (username, firstname, ! lastname, email, password, created_date)! VALUES ('pmcfadin','Patrick','McFadin',! ['patrick@datastax.com'],! 'ba27e03fd95e507daf2937c937d499ab',! '2011-06-20 13:50:00')! IF NOT EXISTS;
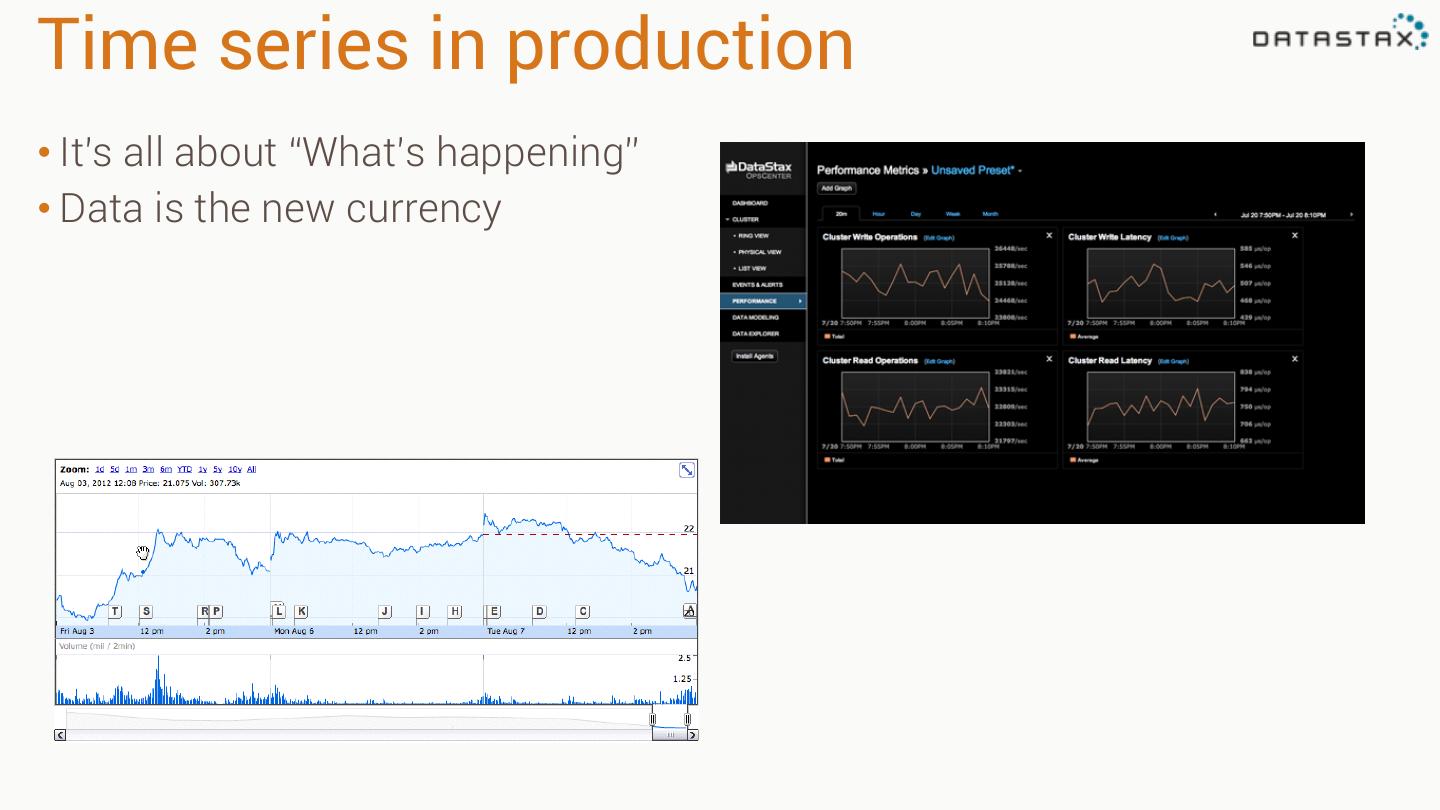
6 .Time series in production • It’s all about “What’s happening” • Data is the new currency
7 .Stack Driver • AWS and Rackspace monitoring • Quick indexes • Batch rollup results
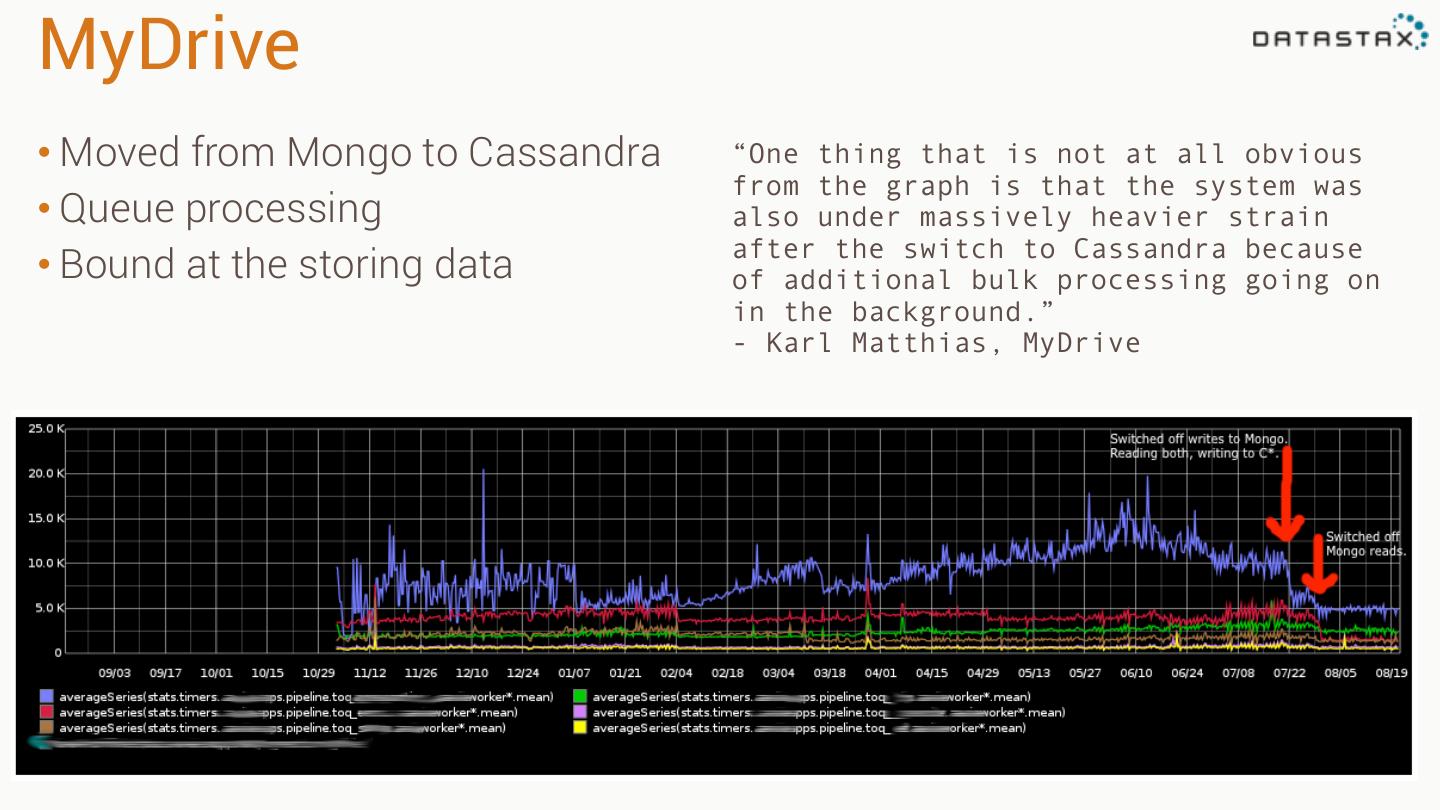
8 .MyDrive • Moved from Mongo to Cassandra “One thing that is not at all obvious from the graph is that the system was • Queue processing also under massively heavier strain after the switch to Cassandra because • Bound at the storing data of additional bulk processing going on in the background.” - Karl Matthias, MyDrive
9 .Paddy Power • Real-time product and pricing • Much like stock tickers • Active-active across two data centers “Specifically for Cassandra and Datastax, the ability to process time-series data is something that lots of companies have done in the past, not something that we were very aware of, and that was one of the reasons why we chose this as the first use case for Cassandra.” - John Turner, Paddy Power
10 .Internet Of Things • 15B devices by 2015 • 40B devices by 2020!
11 .Why Cassandra for Time Series Scales Resilient Good data model Efficient Storage Model What about that?
12 .Example 1: Weather Station • Weather station collects data • Cassandra stores in sequence • Application reads in sequence
13 .Use case Needed Queries • Get all data for one weather station • Get data for a single date and time • Get data for a range of dates and times Data Model to support queries • Store data per weather station • Store time series in order: first to last
14 .Data Model CREATE TABLE temperature ( weatherstation_id text, • Weather Station Id and Time event_time timestamp, are unique temperature text, PRIMARY KEY (weatherstation_id,event_time) • Store as many as needed ); INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:01:00','72F'); ! INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:02:00','73F'); ! INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:03:00','73F'); ! INSERT INTO temperature(weatherstation_id,event_time,temperature) VALUES ('1234ABCD','2013-04-03 07:04:00','74F');
15 .Storage Model - Logical View SELECT weatherstation_id,event_time,temperature FROM temperature WHERE weatherstation_id='1234ABCD'; weatherstation_id event_time temperature 2013-04-03 07:01:00 1234ABCD 72F 2013-04-03 07:02:00 1234ABCD 73F 2013-04-03 07:03:00 1234ABCD 73F 2013-04-03 07:04:00 1234ABCD 74F
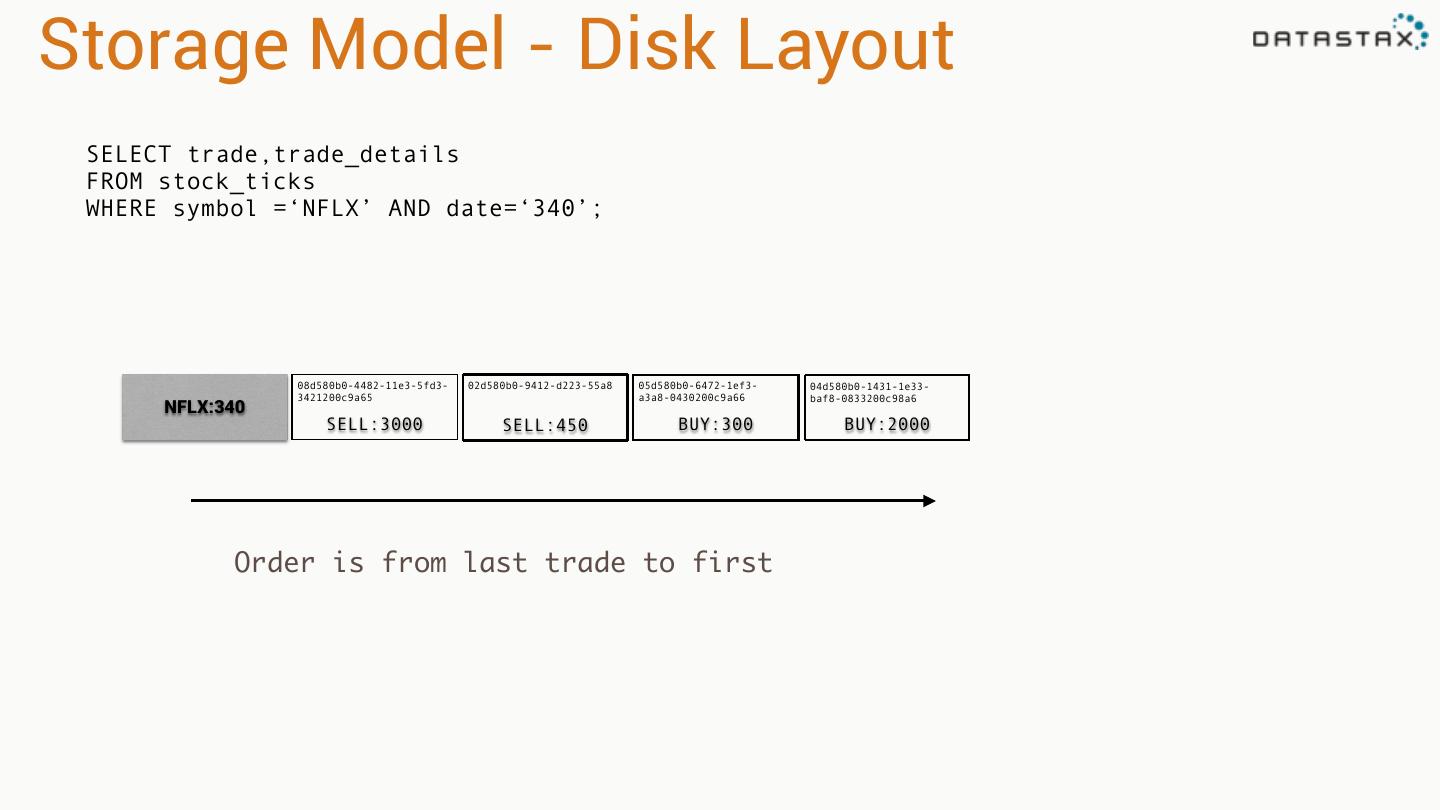
16 .Storage Model - Disk Layout SELECT weatherstation_id,event_time,temperature FROM temperature WHERE weatherstation_id='1234ABCD'; 2013-04-03 07:01:00 2013-04-03 07:02:00 2013-04-03 07:03:00 2013-04-03 07:04:00 2013-04-03 07:05:00 2013-04-03 07:06:00 ! ! 1234ABCD ! ! 72F 73F 73F 74F 74F 75F Merged, Sorted and Stored Sequentially
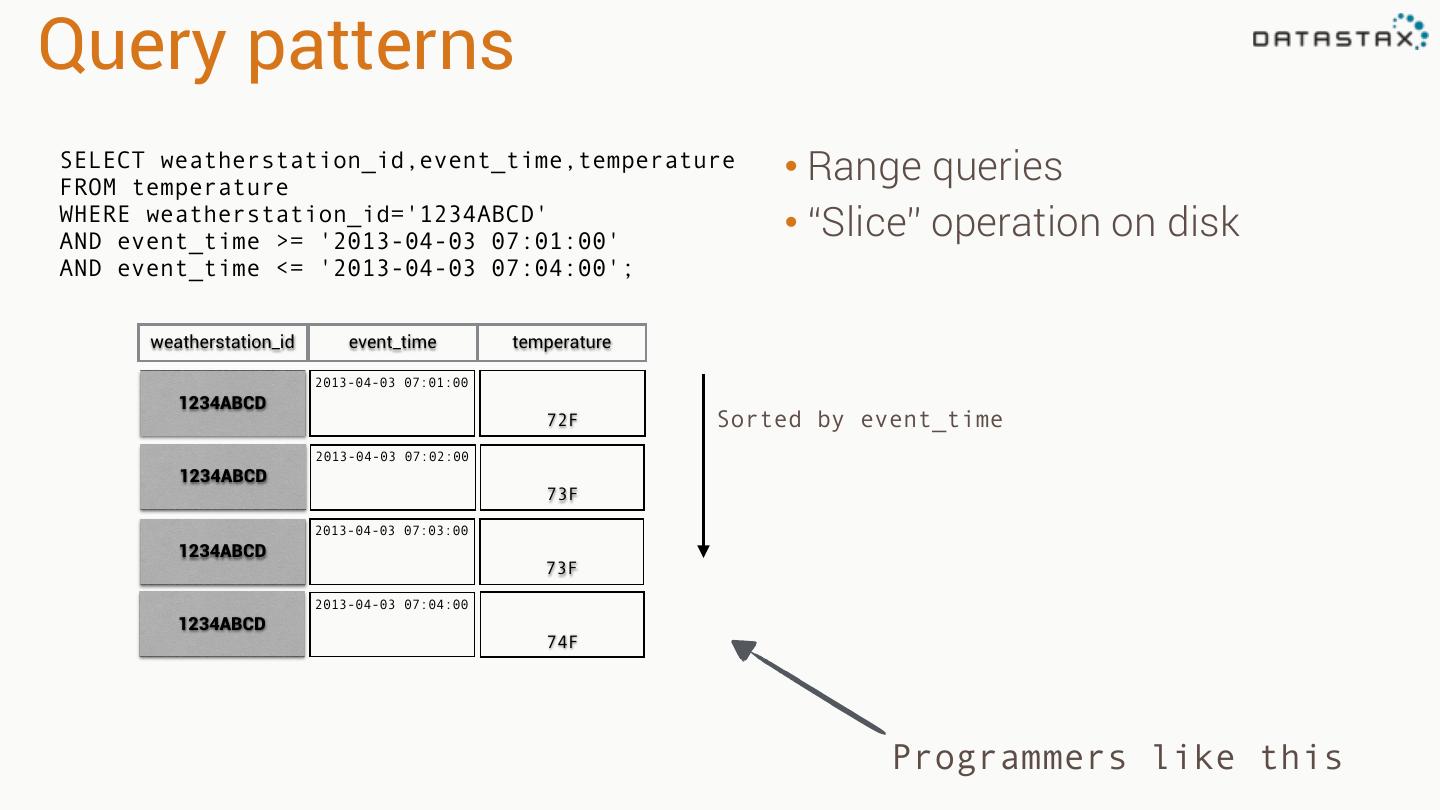
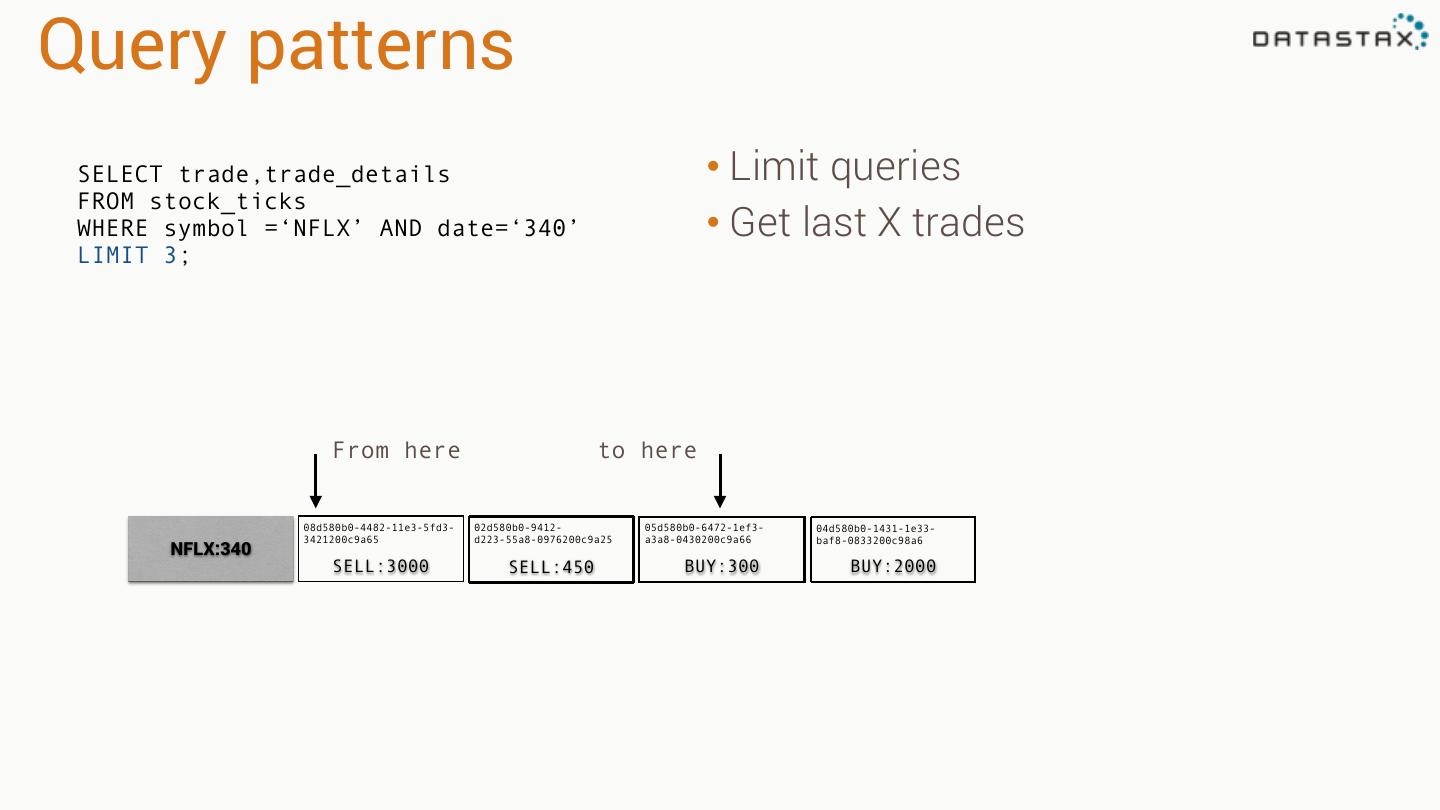
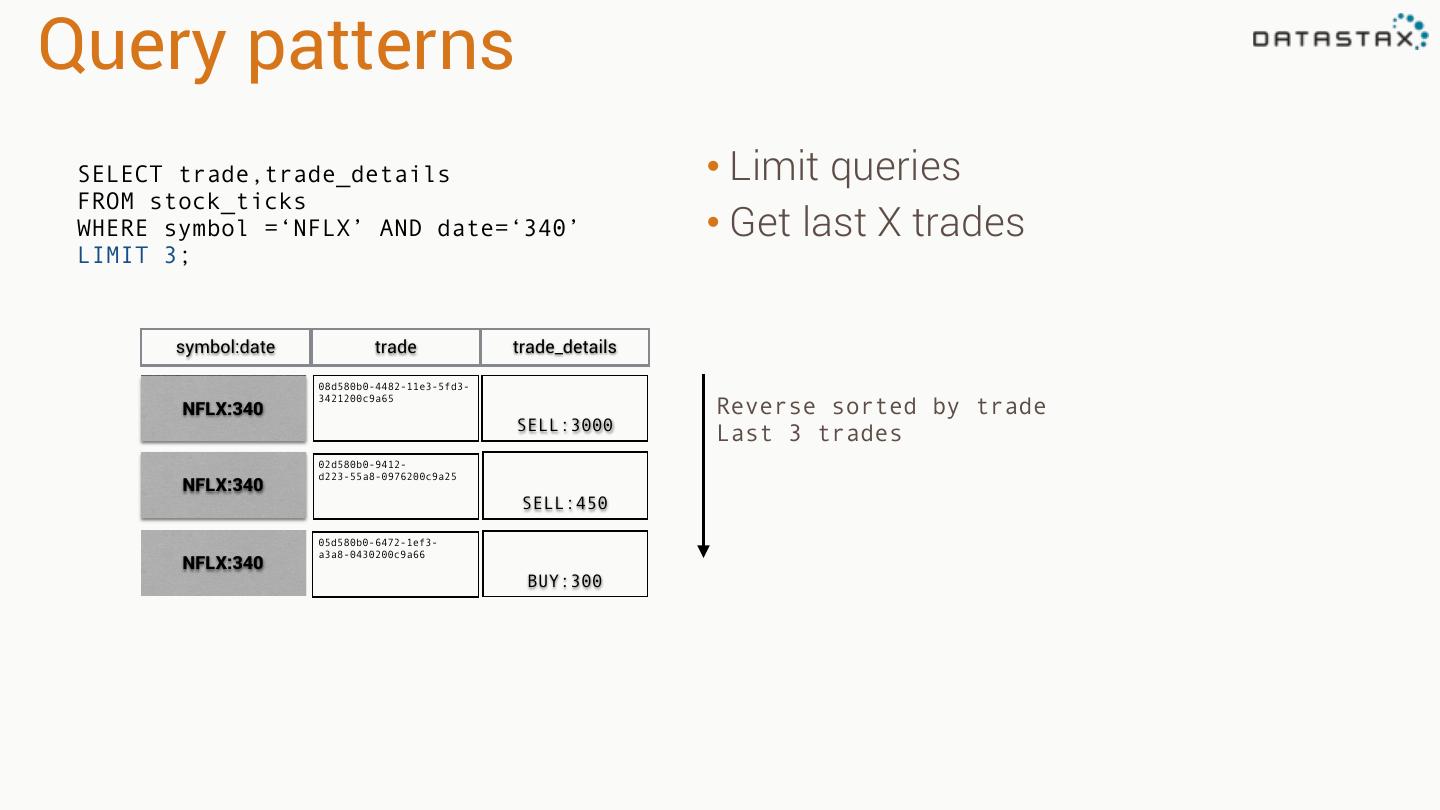
17 .Query patterns SELECT weatherstation_id,event_time,temperature FROM temperature • Range queries WHERE weatherstation_id='1234ABCD' AND event_time >= '2013-04-03 07:01:00' • “Slice” operation on disk AND event_time <= '2013-04-03 07:04:00'; Single seek on disk 2013-04-03 07:01:00 2013-04-03 07:02:00 2013-04-03 07:03:00 2013-04-03 07:04:00 2013-04-03 07:05:00 2013-04-03 07:06:00 ! ! 1234ABCD ! ! 72F 73F 73F 74F 74F 75F
18 .Query patterns SELECT weatherstation_id,event_time,temperature FROM temperature • Range queries WHERE weatherstation_id='1234ABCD' AND event_time >= '2013-04-03 07:01:00' • “Slice” operation on disk AND event_time <= '2013-04-03 07:04:00'; weatherstation_id event_time temperature 2013-04-03 07:01:00 1234ABCD 72F Sorted by event_time 2013-04-03 07:02:00 1234ABCD 73F 2013-04-03 07:03:00 1234ABCD 73F 2013-04-03 07:04:00 1234ABCD 74F Programmers like this
19 .Additional help on the storage engine
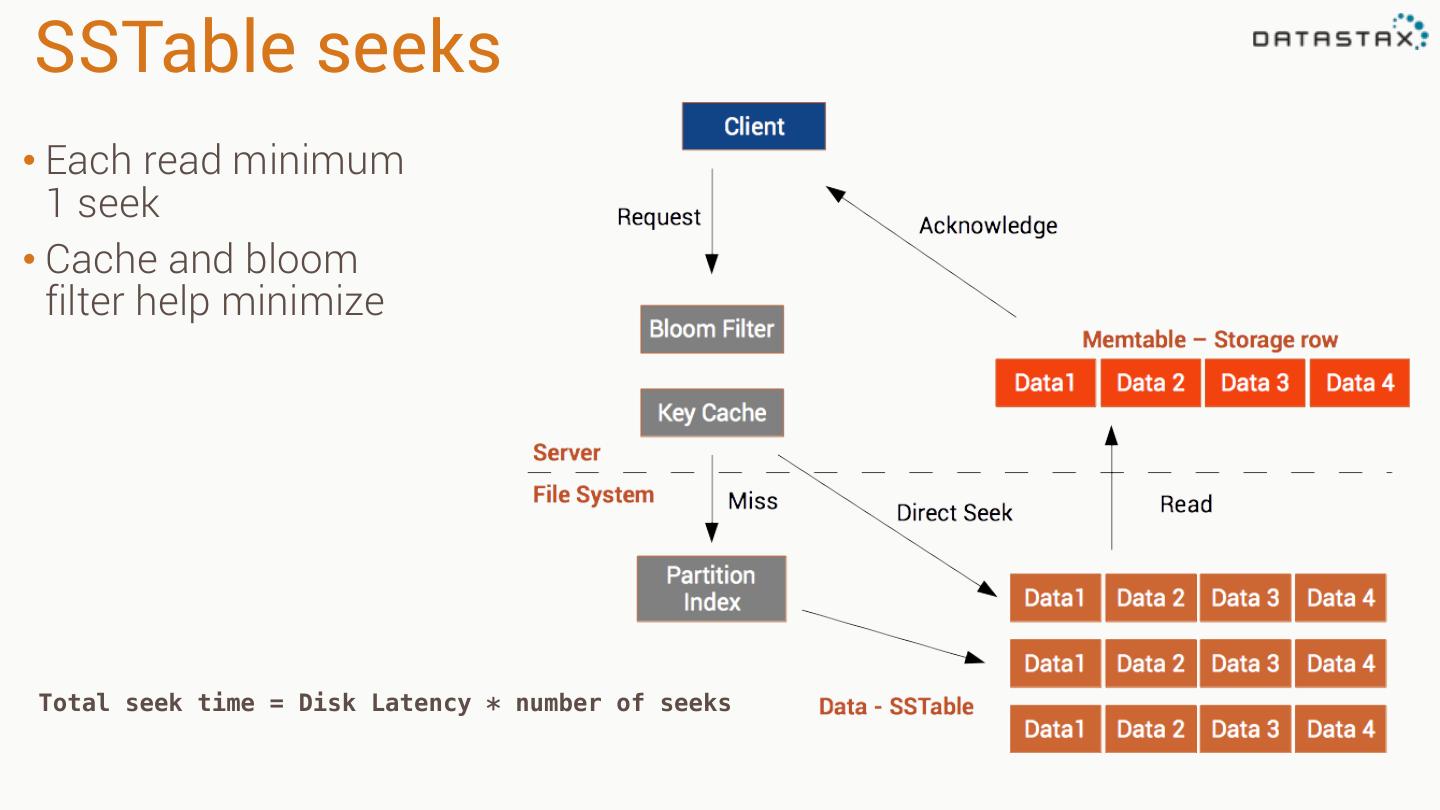
20 .SSTable seeks • Each read minimum 1 seek • Cache and bloom filter help minimize Total seek time = Disk Latency * number of seeks
21 .The key to speed Use the first part of the primary key to get the node (data localization) Minimize seeks for SStables (Bloom Filter,Key Cache up-to-date) Find the data fast in the SSTable (Indexes)
22 .Min/Max Value Hint • New since 2.0 • Range index on primary key values per SSTable • Minimizes seeks on range data SELECT temperature FROM event_time,temperature WHERE weatherstation_id='1234ABCD' AND event_time => '2013-04-03 07:01:00' AND event_time =< '2013-04-03 07:04:00'; ? Row Key: 1234ABCD Min event_time: 2013-03-27 00:00:00 Max event_time: 2013-03-31 23:59:59 Row Key: 1234ABCD This one Min event_time: 2013-04-01 00:00:00 Max event_time: 2013-04-04 23:59:59 Row Key: 1234ABCD Min event_time: 2013-04-05 00:00:00 Max event_time: 2013-04-09 23:59:59 CASSANDRA-5514 if you are interested in details
23 .Ingestion models • Apache Kafka • Apache Flume • Storm Apache Kafka • Spark Streaming • Custom Applications Your totally! killer! application
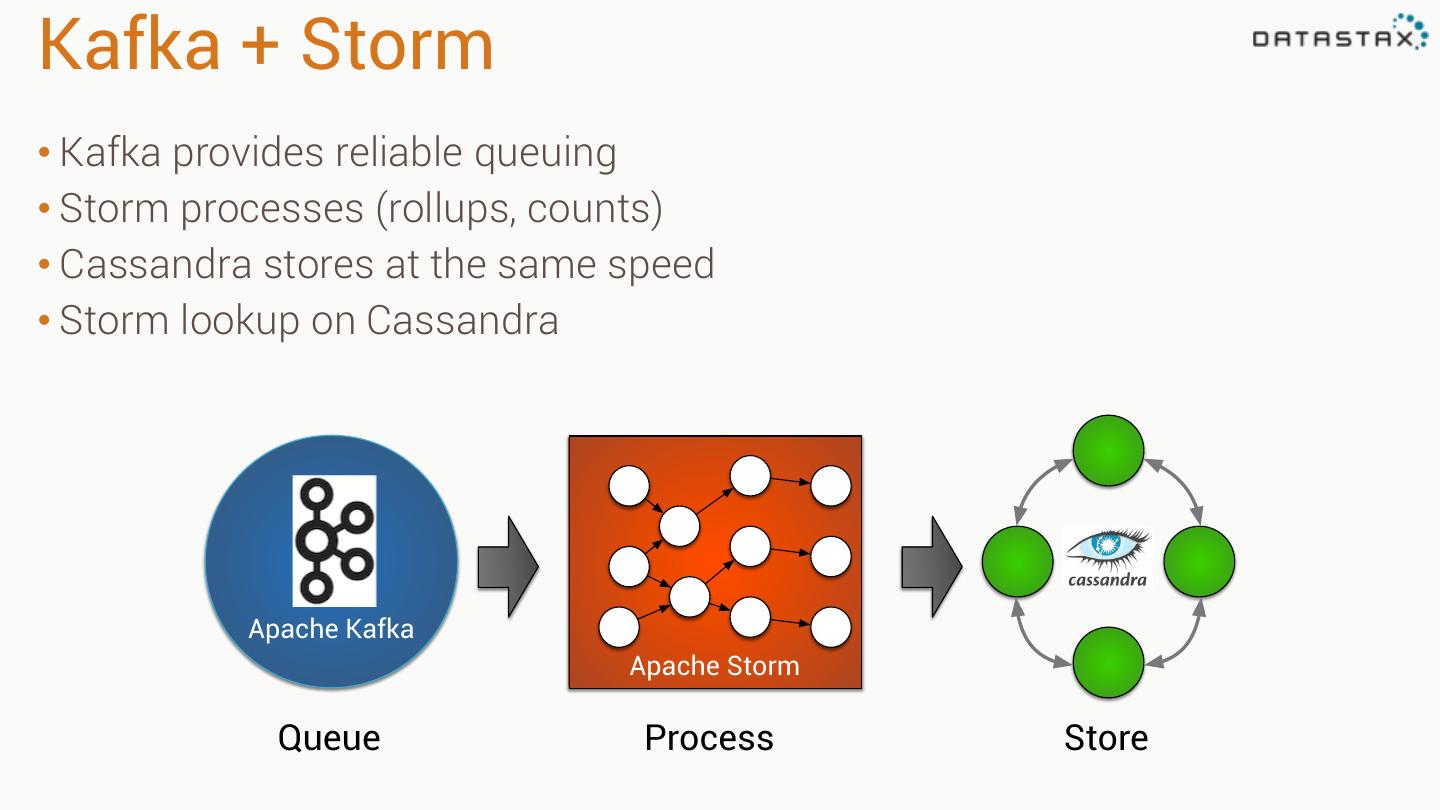
24 .Kafka + Storm • Kafka provides reliable queuing • Storm processes (rollups, counts) • Cassandra stores at the same speed • Storm lookup on Cassandra Apache Kafka Apache Storm Queue Process Store
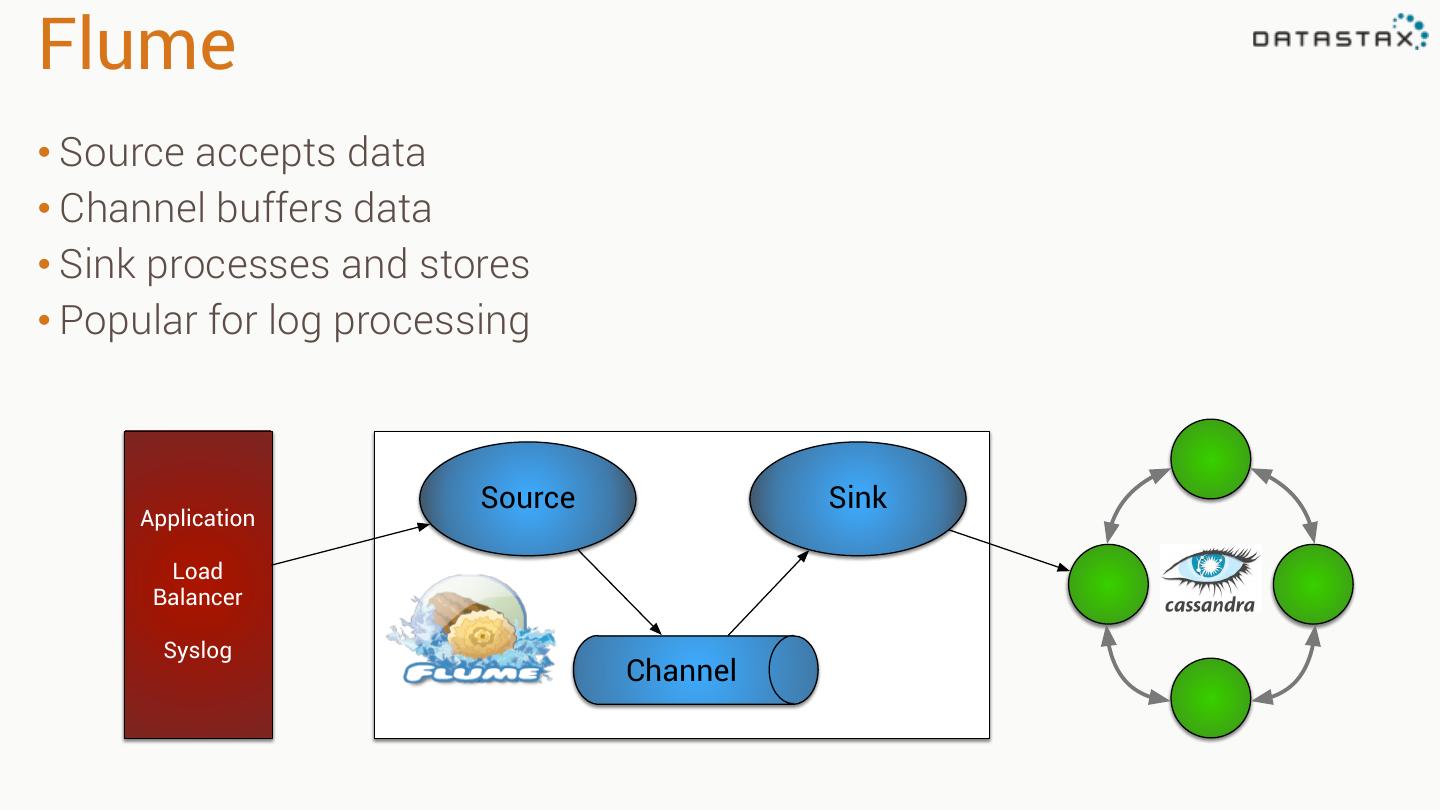
25 .Flume • Source accepts data • Channel buffers data • Sink processes and stores • Popular for log processing Source Sink Application Load Balancer Syslog Channel
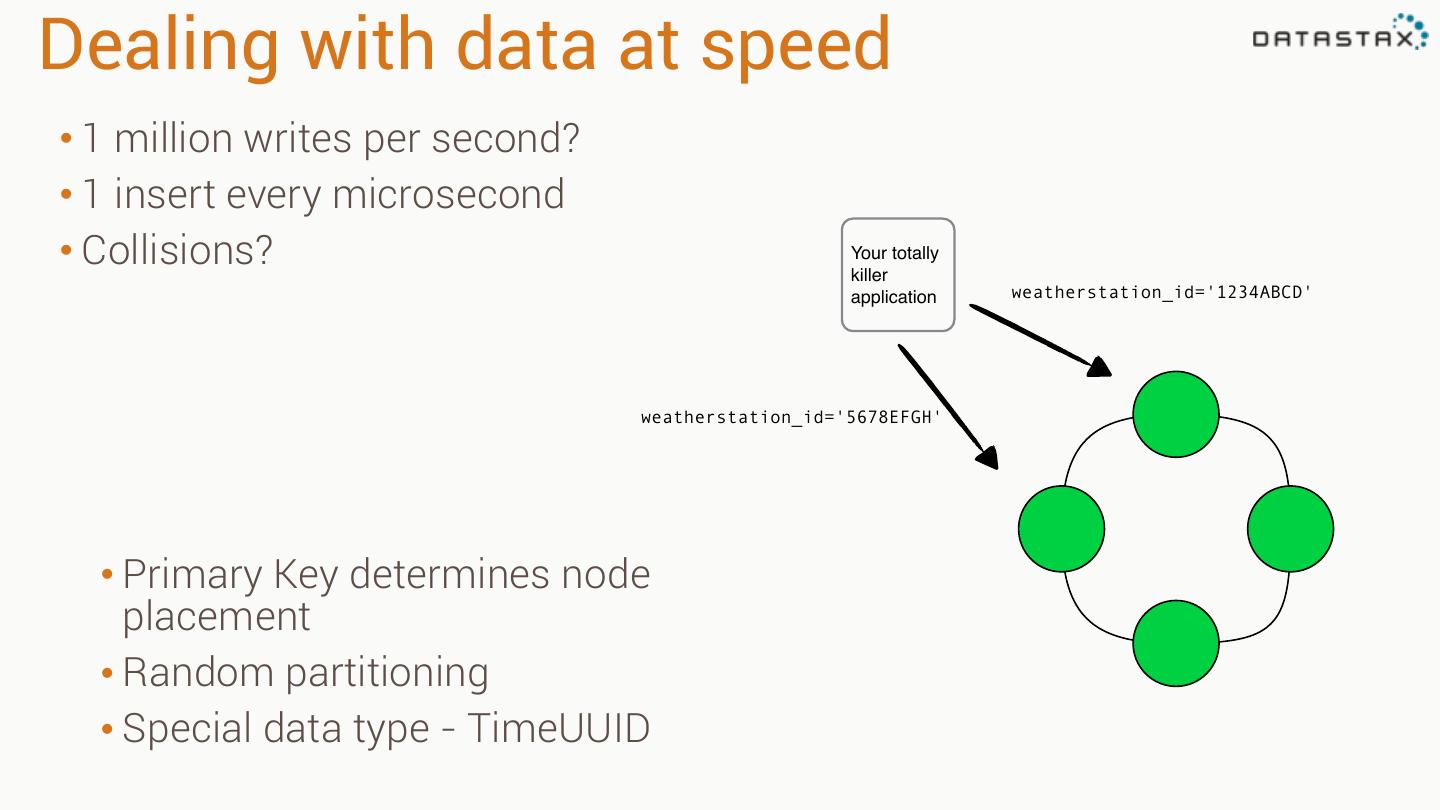
26 .Dealing with data at speed • 1 million writes per second? • 1 insert every microsecond • Collisions? Your totally! killer! application weatherstation_id='1234ABCD' weatherstation_id='5678EFGH' • Primary Key determines node placement • Random partitioning • Special data type - TimeUUID
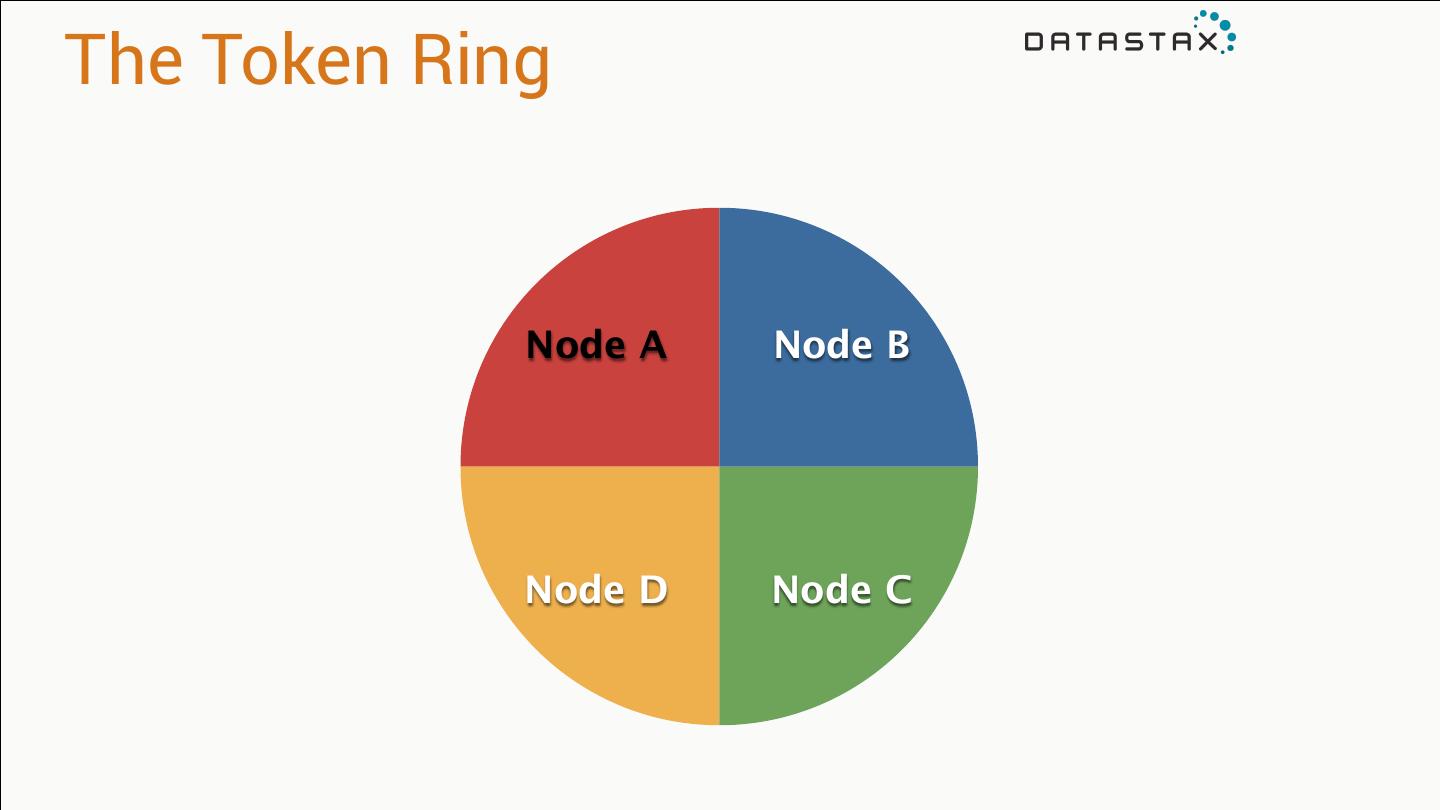
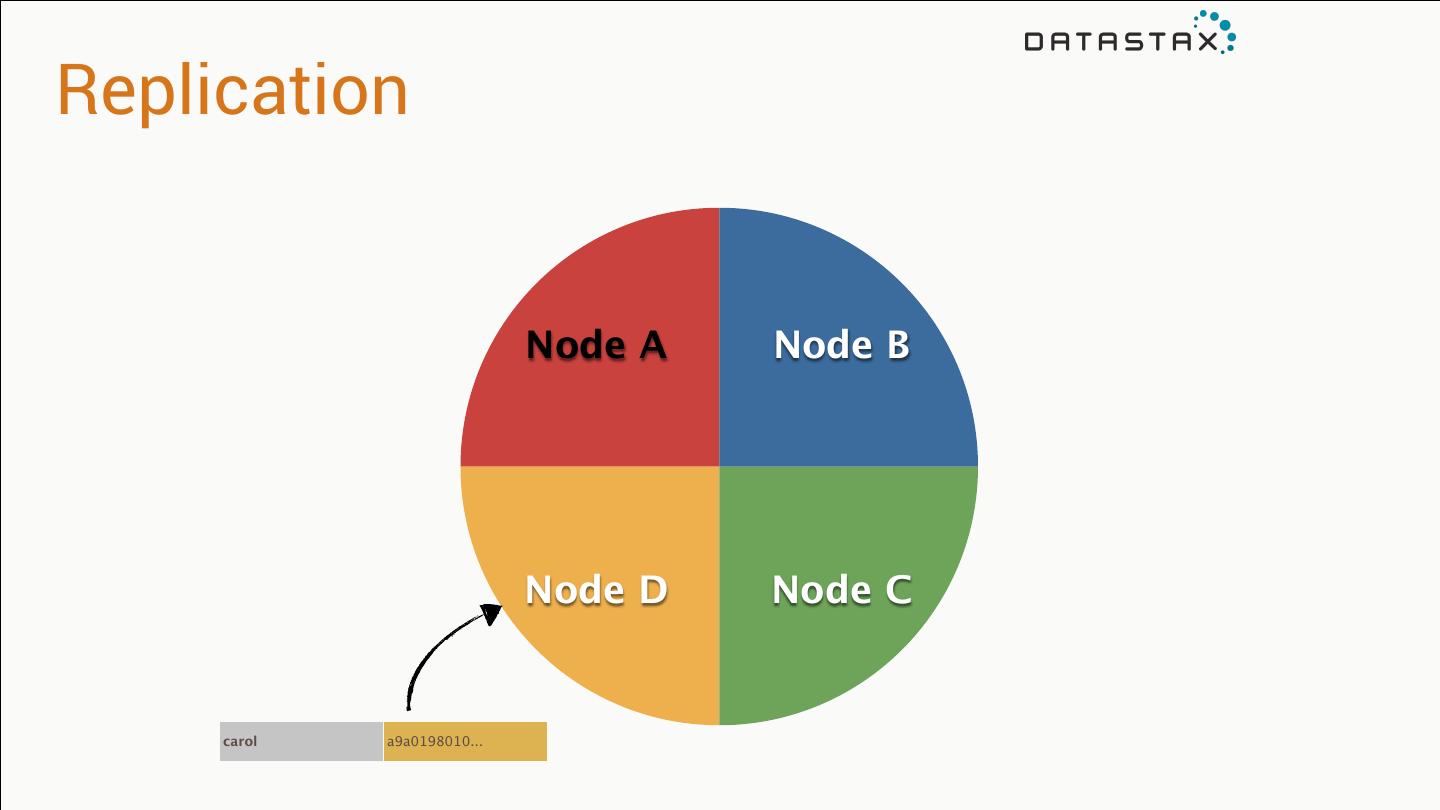
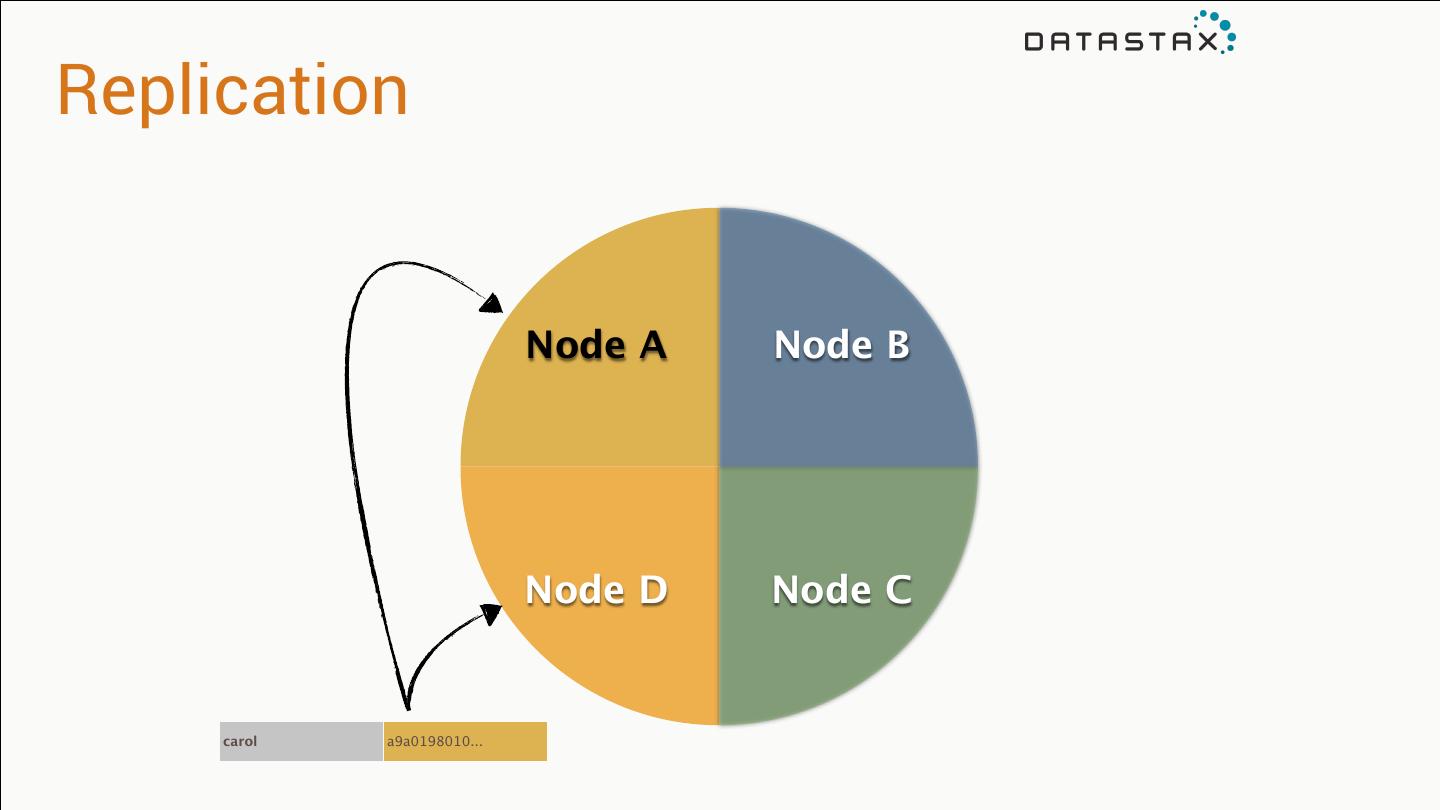
27 .How does data replicate?
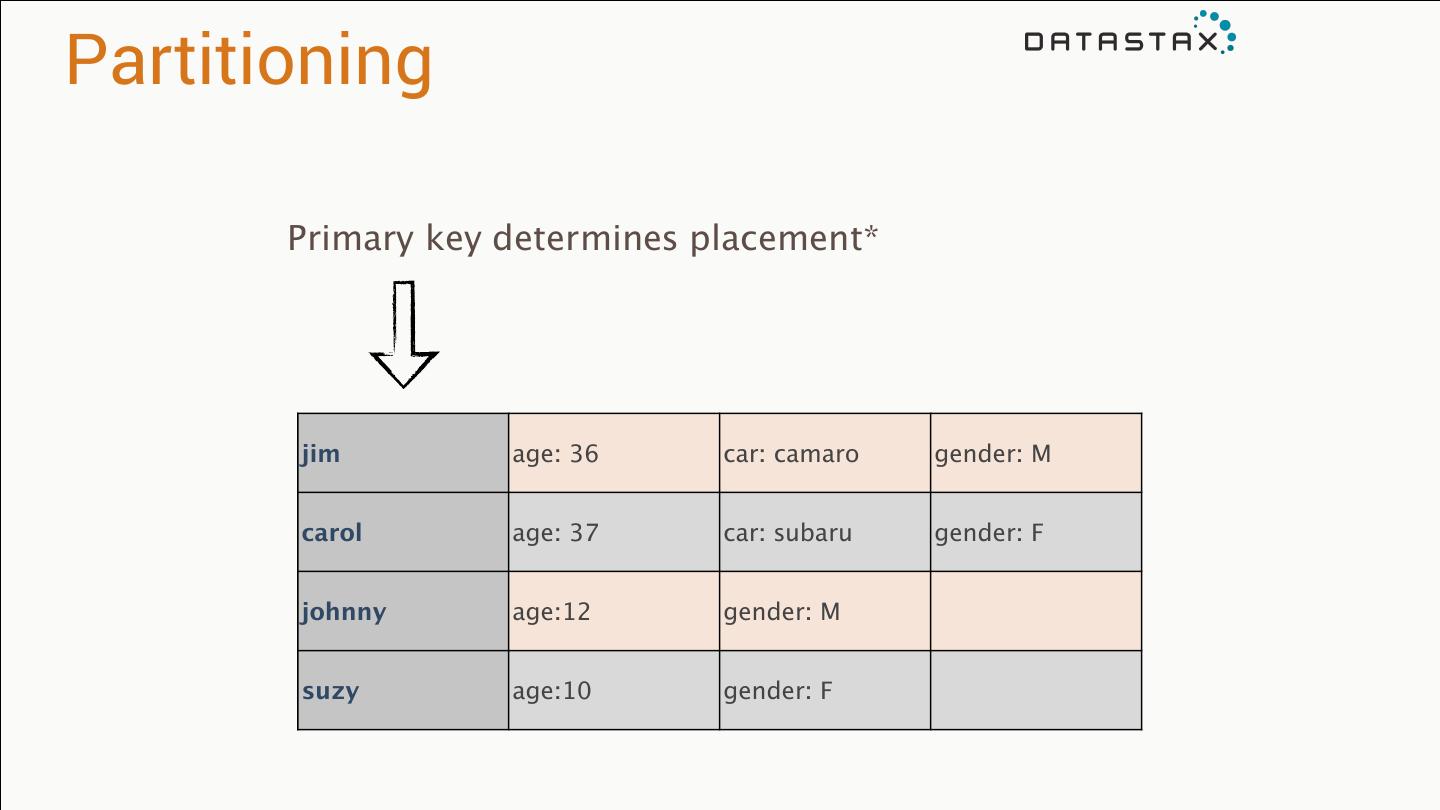
28 .Partitioning Primary key determines placement* jim age: 36 car: camaro gender: M carol age: 37 car: subaru gender: F johnny age:12 gender: M suzy age:10 gender: F
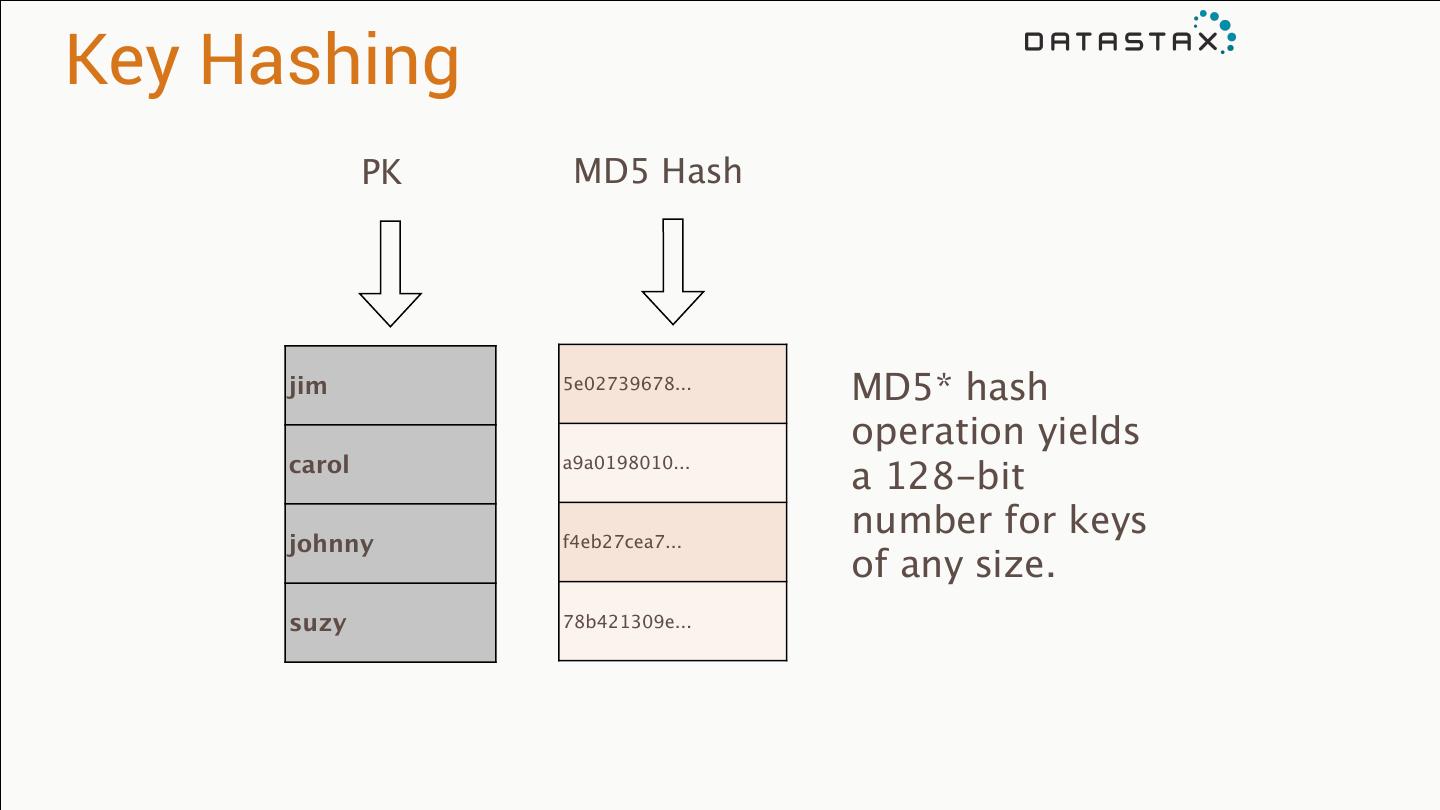
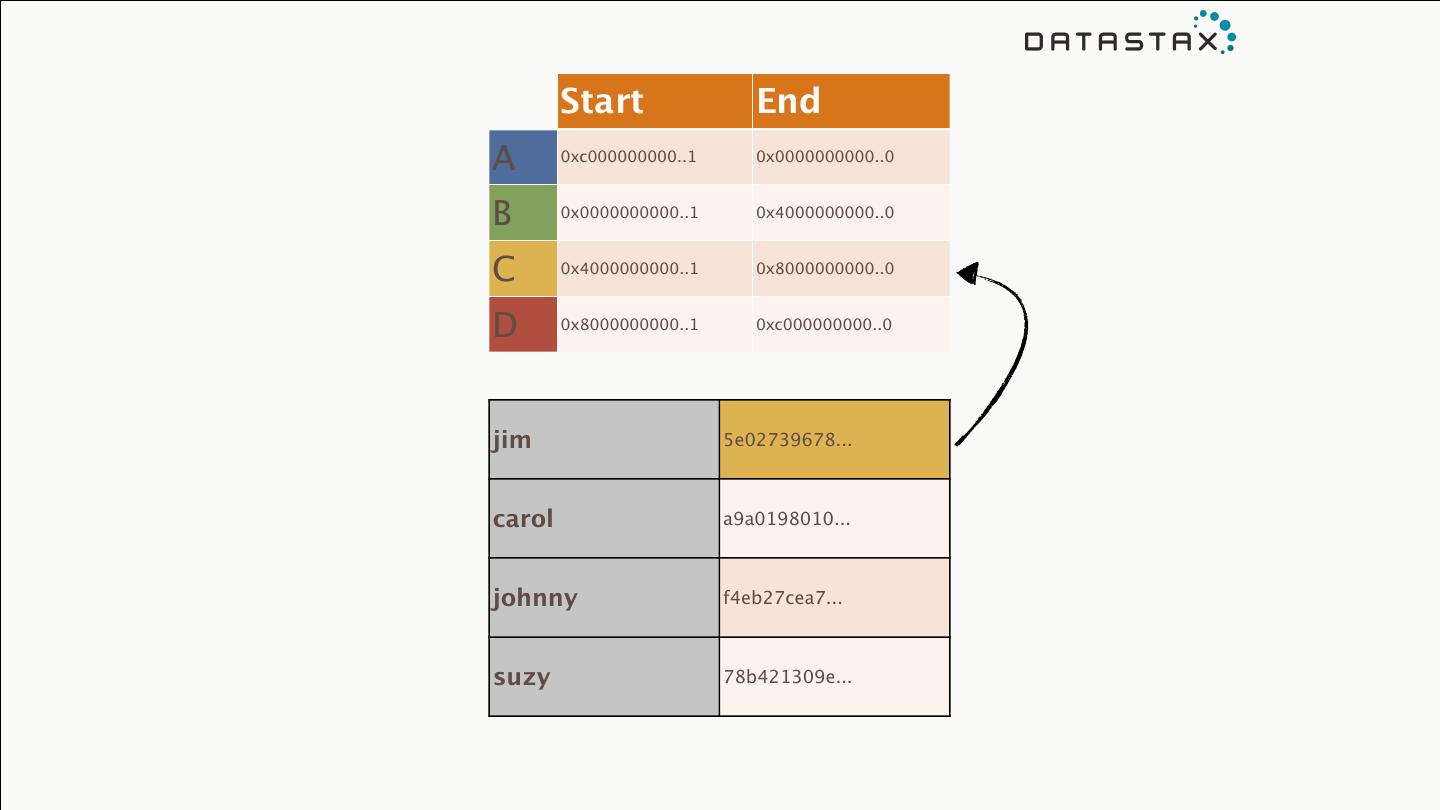
29 .Key Hashing PK MD5 Hash jim 5e02739678... MD5* hash operation yields carol a9a0198010... a 128-bit number for keys johnny f4eb27cea7... of any size. suzy 78b421309e...
3秒后跳转登录页面
去登陆

