








































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
CarbonData应用实践和未来规划
CarbonData原理,应用场景和调优介绍和未来计划
展开查看详情
1 .CarbonData应用实践和未来规划 李昆 2017-09
2 . Agenda • 为什么需要CarbonData • CarbonData介绍 • 应用场景和调优介绍 • 未来计划 2
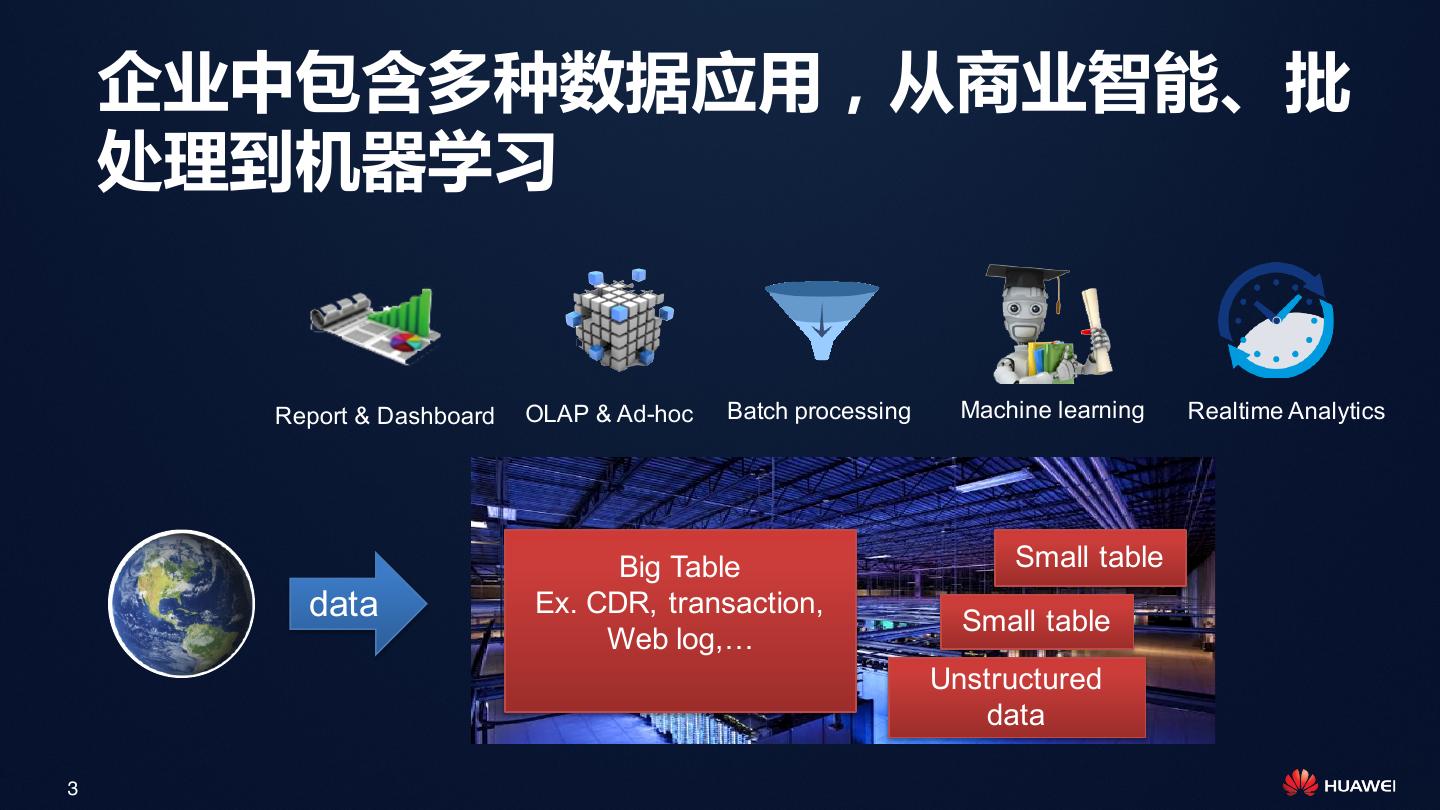
3 . 企业中包含多种数据应用,从商业智能、批 处理到机器学习 Report & Dashboard OLAP & Ad-hoc Batch processing Machine learning Realtime Analytics Big Table Small table data Ex. CDR, transaction, Small table Web log,… Unstructured data 3
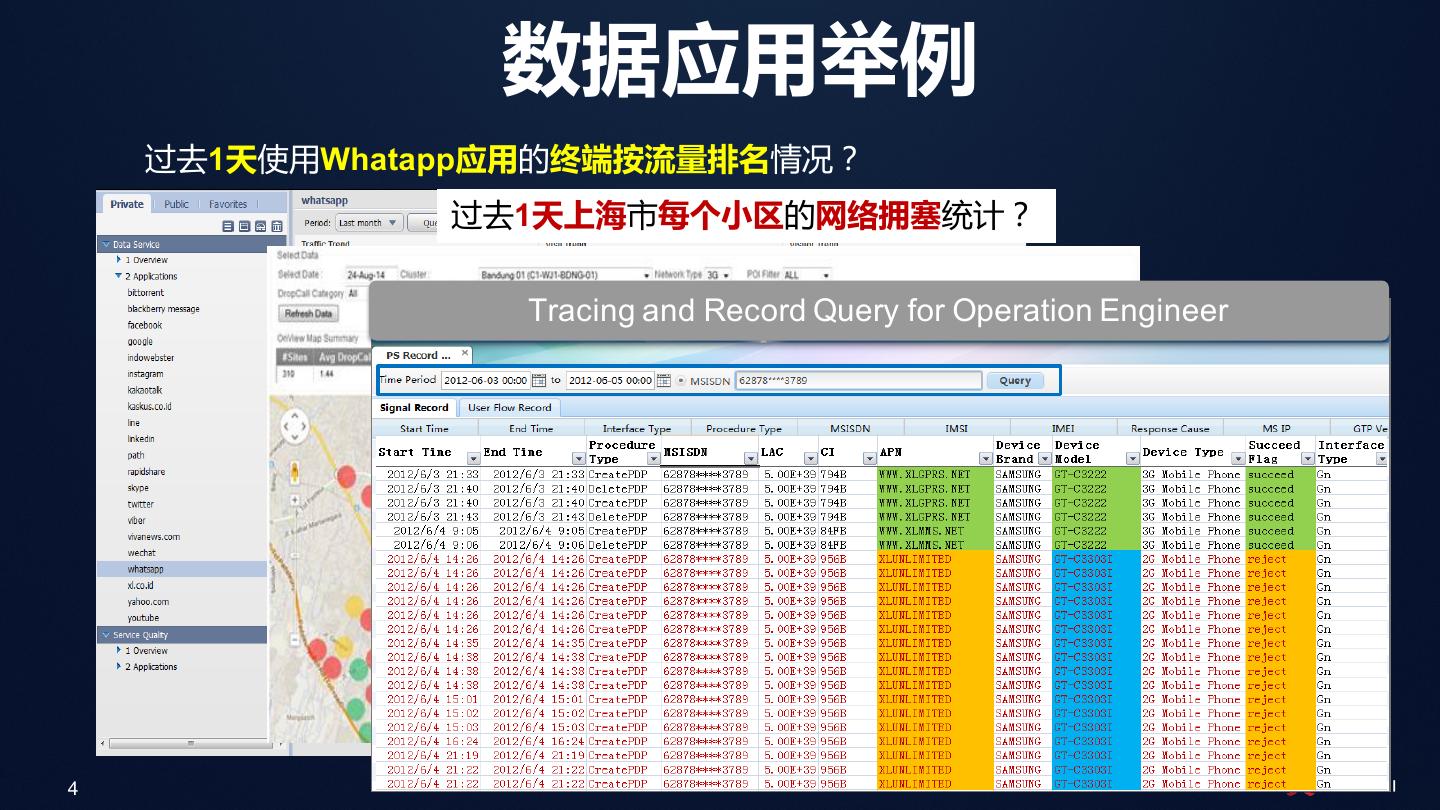
4 . 数据应用举例 过去1天使用Whatapp应用的终端按流量排名情况? 过去1天上海市每个小区的网络拥塞统计? Tracing and Record Query for Operation Engineer 4
5 . 来自数据的挑战 • Data Size 百亿级数据量 • Single Table >10 B • Fast growing • Multi-dimensional 多维度 • Every record > 100 dimension • Add new dimension occasionally • Rich of Detail 细粒度 • Billion level high cardinality • 1B terminal * 200K cell * 1440 minutes = 28800 (万亿) 5
6 . 来自应用的挑战 • Enterprise Integration 企业应用集成 • SQL 2003 Standard Syntax Multi-dimensional OLAP Query • BI integration, JDBC/ODBC 灵活查询 • Flexible Query 无固定模式 • Any combination of dimensions • OLAP Vs Detail Record Full Scan Query Small Scan Query • Full scan Vs Small scan • Precise search & Fuzzy search 6
7 . How to choose storage? 如何构建数据平台? 7
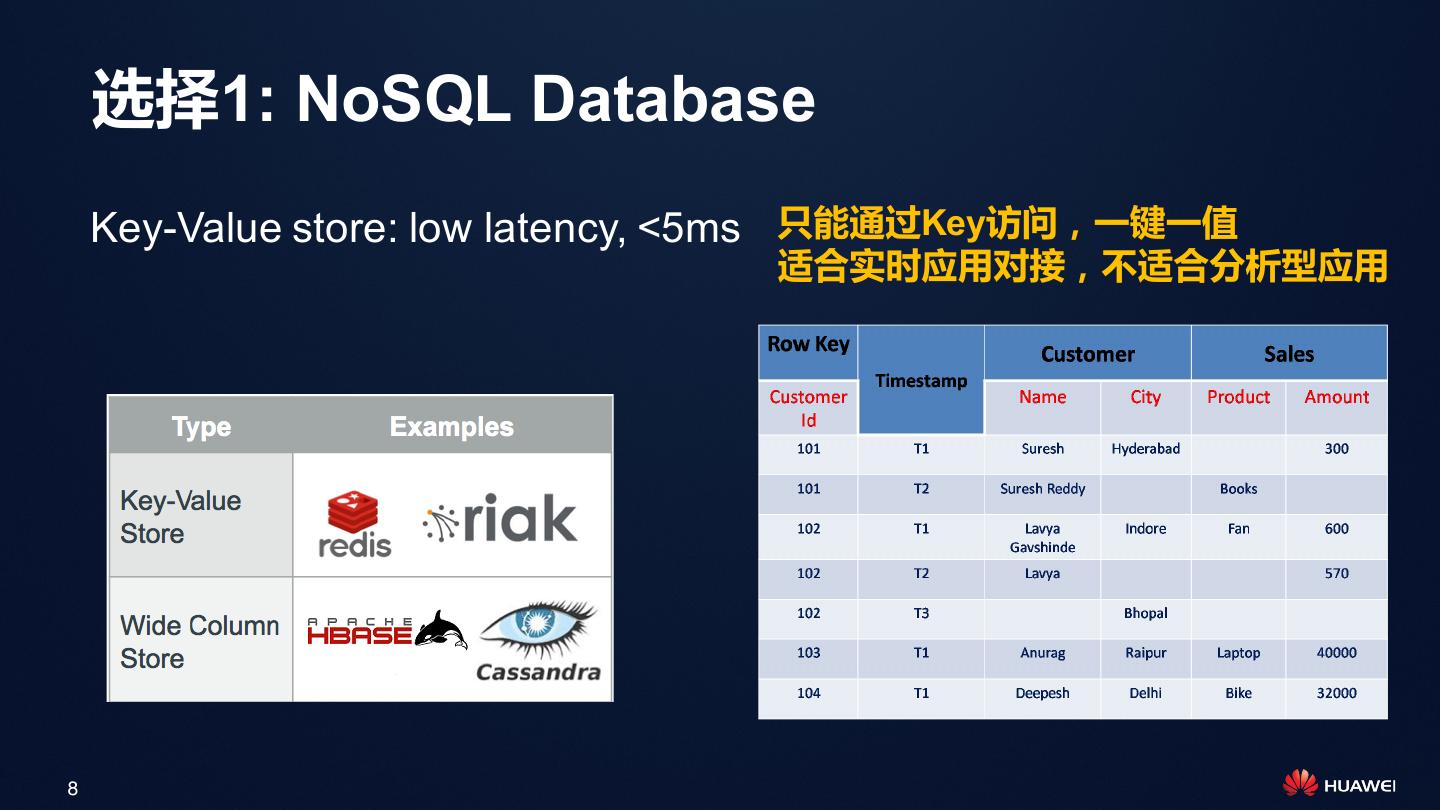
8 . 选择1: NoSQL Database Key-Value store: low latency, <5ms 只能通过Key访问,一键一值 适合实时应用对接,不适合分析型应用 8
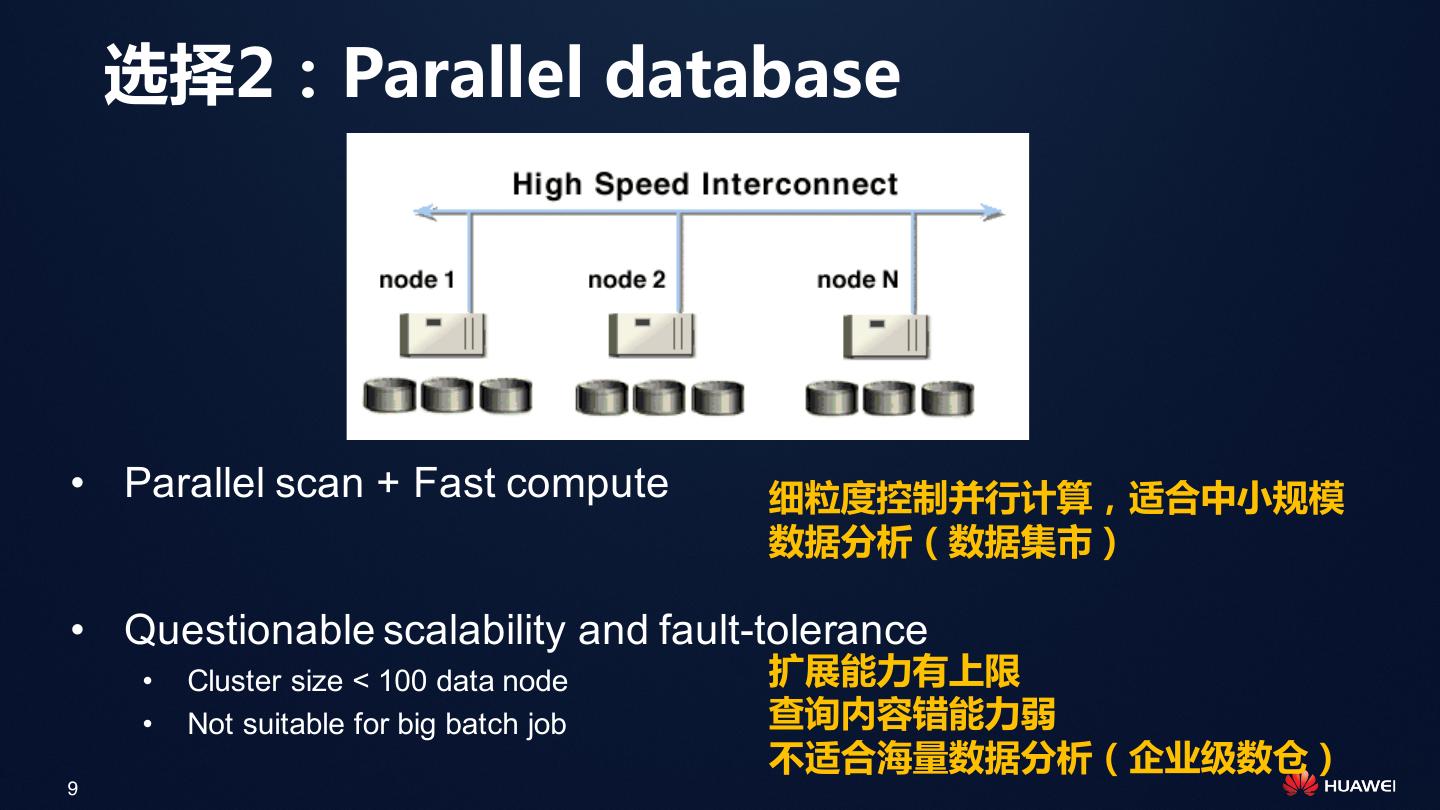
9 . 选择2:Parallel database • Parallel scan + Fast compute 细粒度控制并行计算,适合中小规模 数据分析(数据集市) • Questionable scalability and fault-tolerance • Cluster size < 100 data node 扩展能力有上限 • Not suitable for big batch job 查询内容错能力弱 不适合海量数据分析(企业级数仓) 9
10 . 选择3: Search engine •All column indexed 适合多条件过滤,文本分析 •Fast searching •Simple aggregation •Designed for search but not OLAP 无法完成复杂计算 •Not for TopN, join, multi-level aggregation •3~4X data expansion in size 数据膨胀 •No SQL support 专用语法,难以迁移 10
11 . 选择4: SQL on Hadoop •Modern distributed architecture, scale well in computation. •Pipeline based: Impala, Drill, Flink, … 并行扫描+并行计算 适合海量数据计算 •BSP based: Hive, SparkSQL •BUT, still using file format designed for batch job 仍然使用为批处理设 计的存储,场景受限 •Focus on scan only •No index support, not suitable for point or small scan queries 11
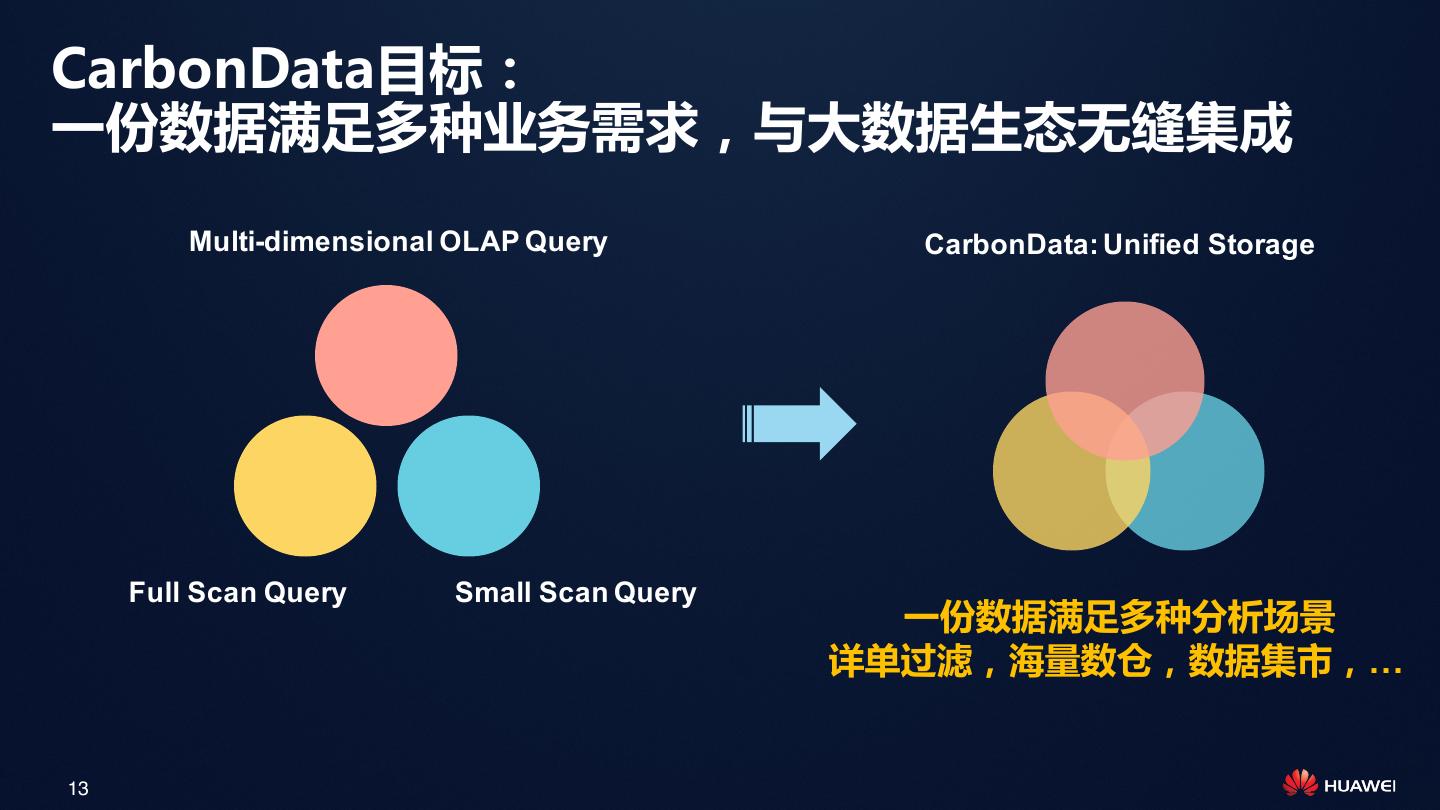
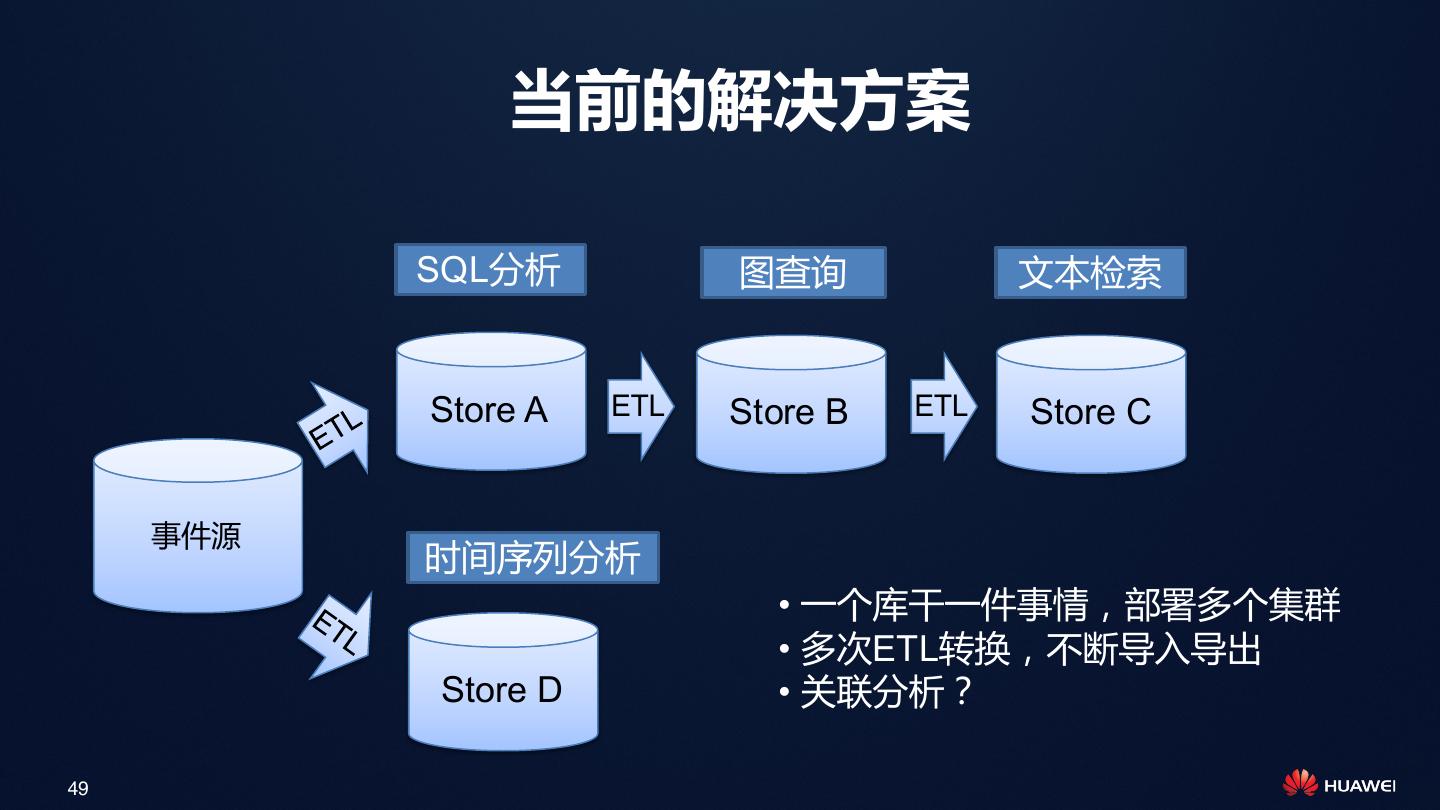
12 . 架构师如何选择? Choice 1: Compromising Choice 2: Replicating of data 做出妥协,只满足部分应用 复制多份数据,满足所有应用 App1 App2 App3 App1 App2 App3 Loading Replication Data Data 12
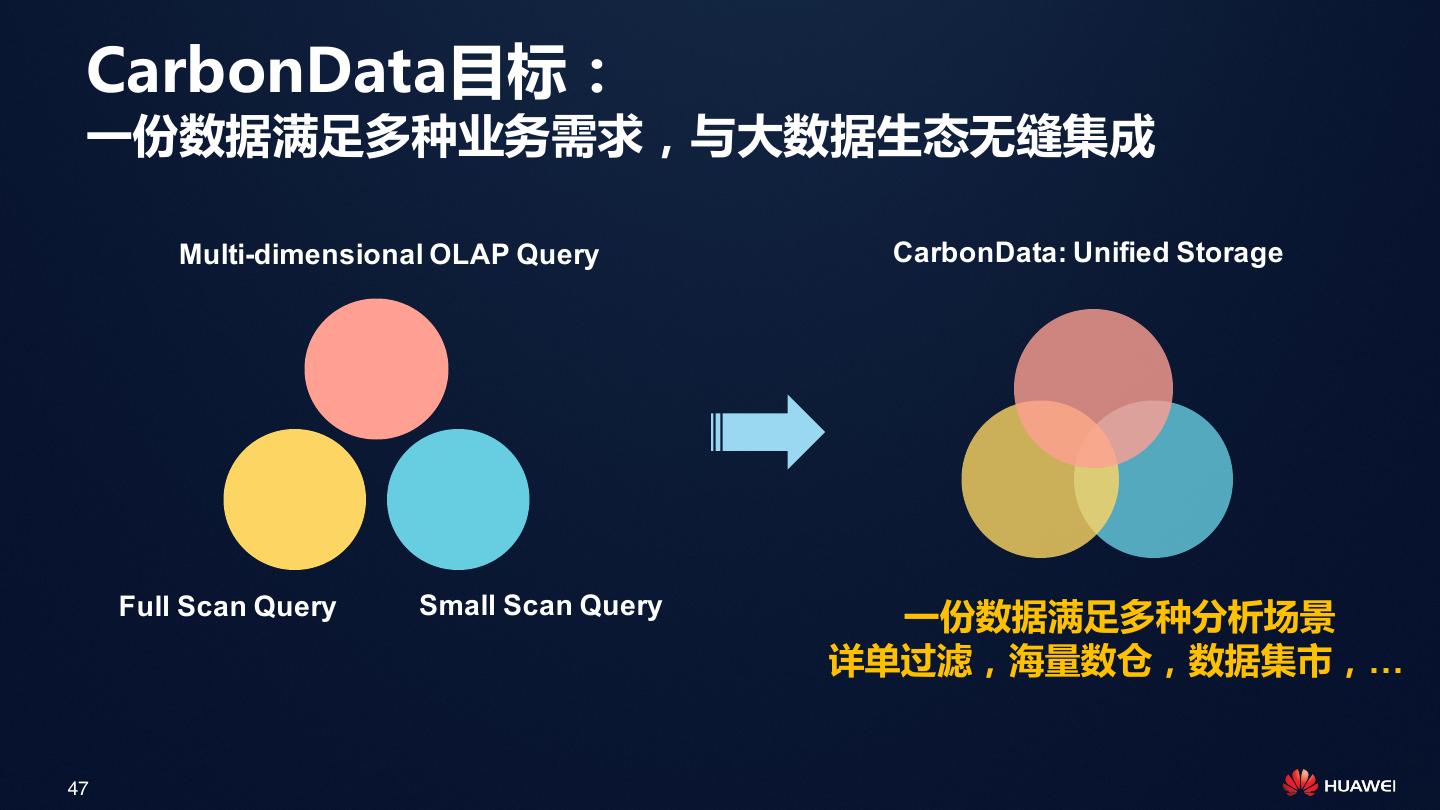
13 .CarbonData目标: 一份数据满足多种业务需求,与大数据生态无缝集成 Multi-dimensional OLAP Query CarbonData: Unified Storage Full Scan Query Small Scan Query 一份数据满足多种分析场景 详单过滤,海量数仓,数据集市,… 13
14 . CarbonData原理介绍 打造大数据交互式分析引擎 14
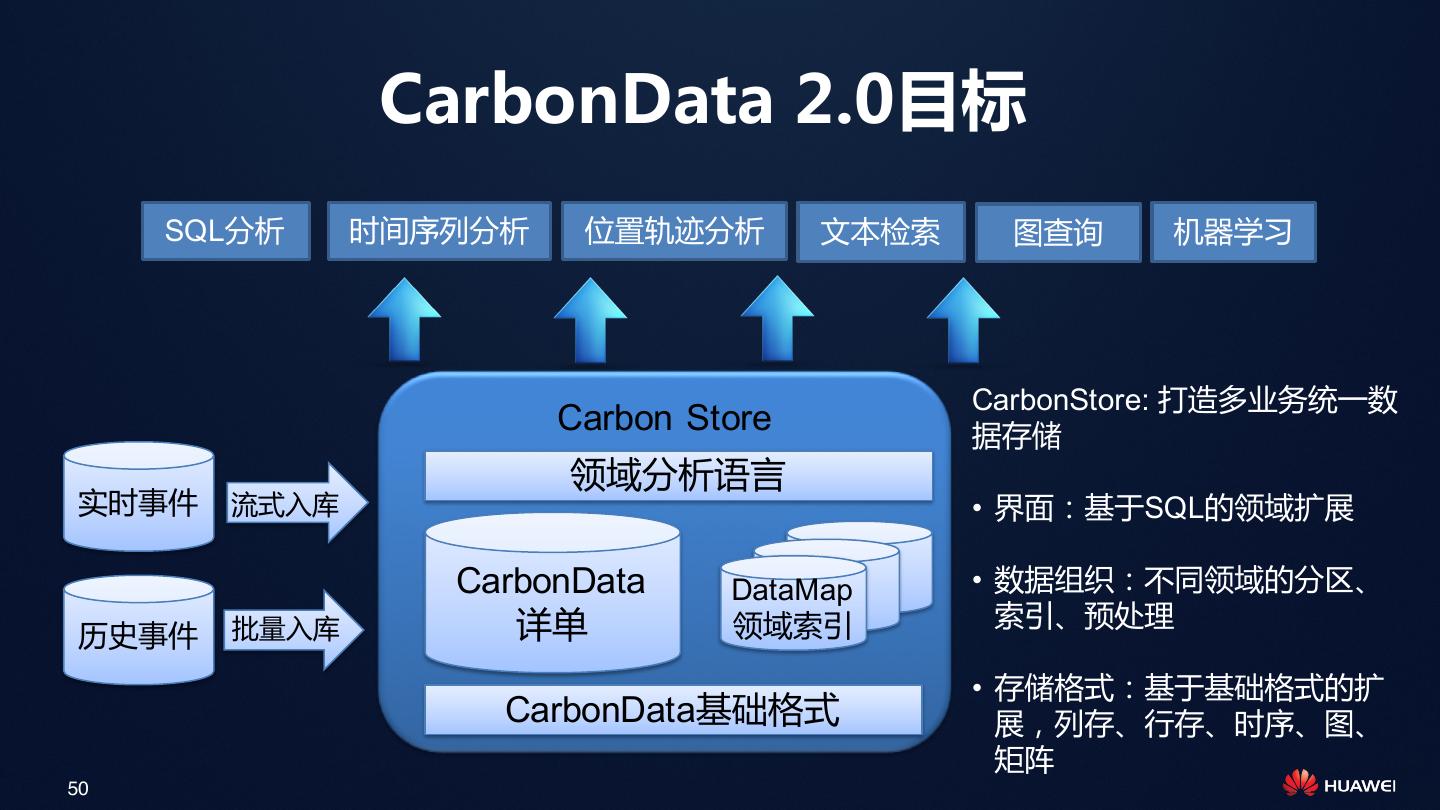
15 . CarbonData大数据生态 • 支持Spark、Hive、Presto、Flink • 内置Hadoop和Spark深度优化 • Hadoop: > 2.2 Data Query • Spark 1.5, 1.6, 2.1 Management Optimization • 接口 • SQL Read/Write/Update • DataFrame API • 支持操作: Carbon File Carbon File Carbon File • 查询:支持SparkSQL优化器 • 数据管理:批量入库、更新、删除、合并 (Compaction)、增删列 15
16 .使用方式:入库 • SQL CREATE TABLE tablename (name String, PhoneNumber String) STORED BY “carbondata” TBLPROPERTIES (...) LOAD DATA [LOCAL] INPATH 'folder path' [OVERWRITE] INTO TABLE tablename OPTIONS(...) INSERT INTO TABLE tablennme select_statement1 FROM table1; • Dataframe df.write .format(“carbondata") .options("tableName“, “t1")) .mode(SaveMode.Overwrite) .save() 16
17 .使用方式:查询 • SQL SELECT project_list FROM t1 WHERE cond_list GROUP BY columns ORDER BY columns • Dataframe df = sparkSession.read .format(“carbondata”) .option(“tableName”, “t1”) .load(“path_to_carbon_file”) df.select(…).show 17
18 .使用方式:更新和删除 Modify one column in table1 UPDATE table1 A phone, 70 60 SET A.REVENUE = A.REVENUE - 10 car,100 WHERE A.PRODUCT = ‘phone’ phone, 30 20 Modify two columns in table1 with values from table2 UPDATE table1 A SET (A.PRODUCT, A.REVENUE) = ( SELECT PRODUCT, REVENUE FROM table2 B table1 table2 WHERE B.CITY = A.CITY AND B.BROKER = A.BROKER ) WHERE A.DATE BETWEEN ‘2017-01-01’ AND ‘2017-01-31’ Delete records in table1 DELETE FROM table1 A 123, abc WHERE A.CUSTOMERID = ‘123’ 456, jkd 18
19 . CarbonData原理介绍 • 数据组织 • 索引 • 扫描过程 19
20 . CarbonData文件格式 Carbon Data File •数据布局 File Header •Block:一个HDFS文件,256MB Version •Blocklet:文件内的列存数据块,是最小的IO读取单元 Schema •Column chunk: Blocklet内的列数据 •Page:Column chunk内的数据页,是最小的解码 Blocklet 1 单元 Column 1 Chunk Page1 Page2 Page3 … Column 2 Chunk •元数据信息 … Column n Chunk •Header:Version,Schema •Footer: Blocklet Offset, Index & 文件级统计信息 … Blocklet N •内置索引和统计信息 •Blocklet索引:B Tree startkey, endkey File Footer •Blocklet级和Page级统计信息:min,max等 Blocklet Offset, Index & Stats 20
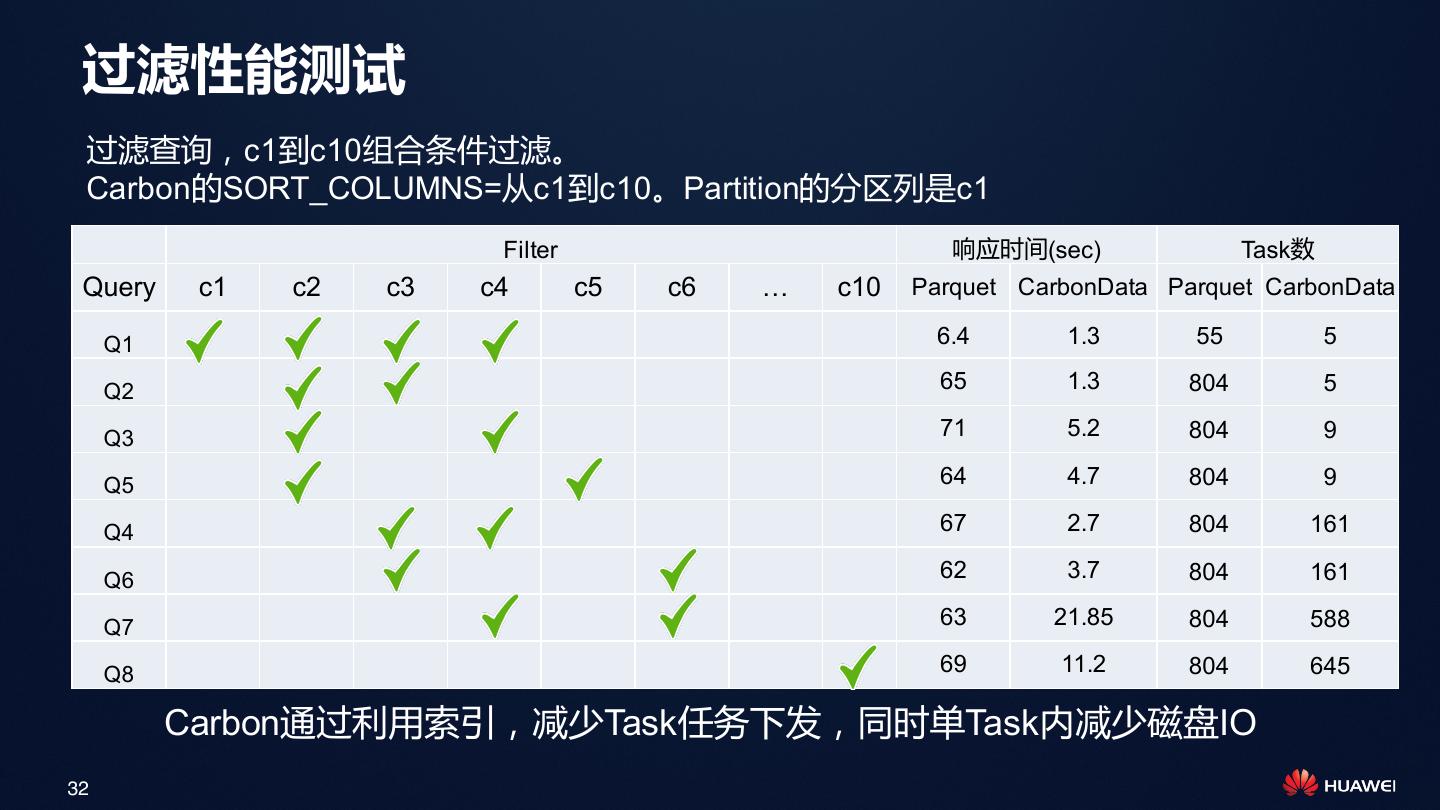
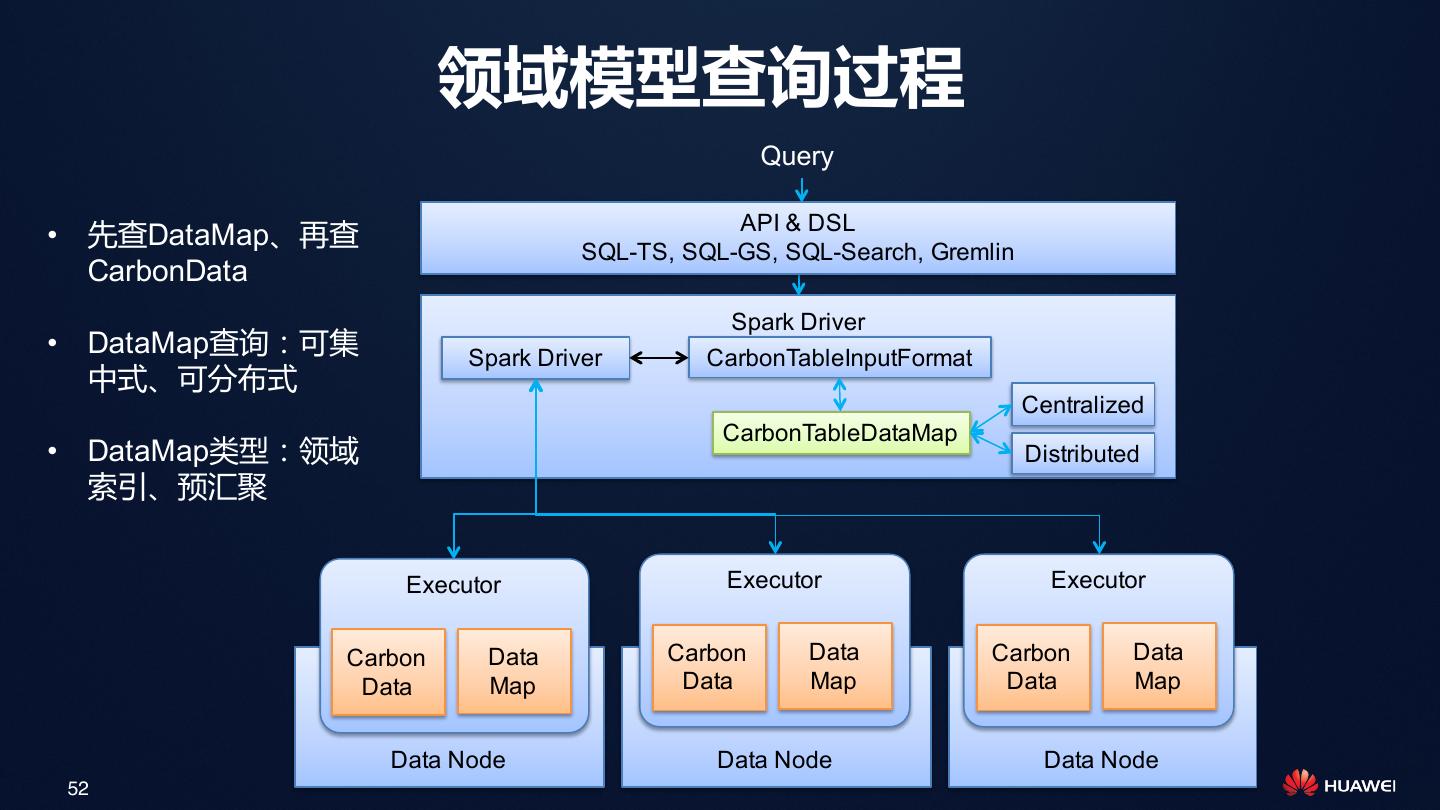
21 . 利用两级索引架构减少Spark Task数和磁盘IO Spark Driver • 第一级:文件级索引 用于过滤文件(HDFS Block), Catalyst 避免扫描不必要的文件,减少多 Block Index 达95%的Spark Task Executor Executor • 第二级:Blocklet索引 Blocklet Index Blocklet Index 用于过滤文件内部的Blocklet, 避免扫描不必要的Blocklet,减 少磁盘IO Carbon File Carbon File Carbon File Data Data Data Footer Footer Footer 21
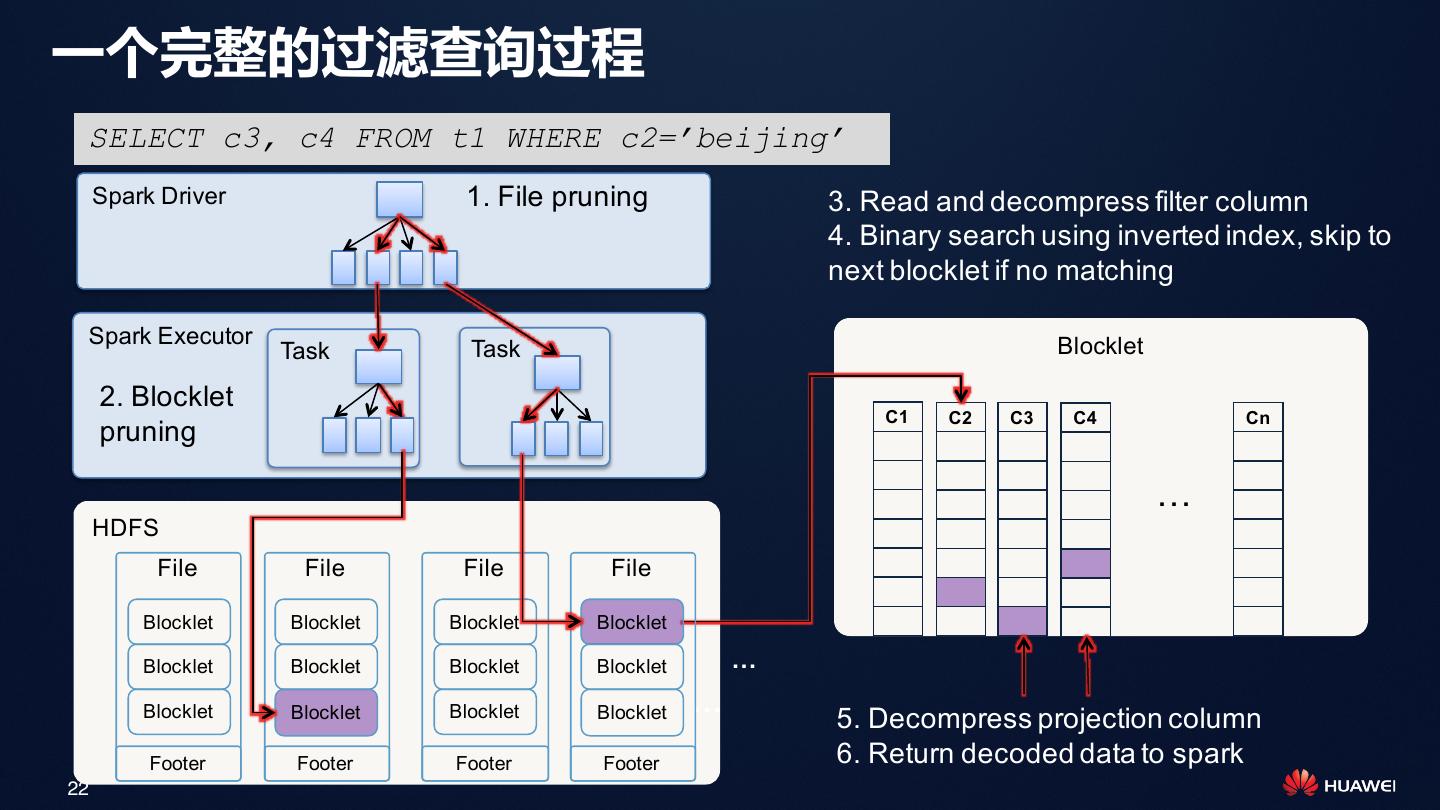
22 .一个完整的过滤查询过程 SELECT c3, c4 FROM t1 WHERE c2=’beijing’ Spark Driver 1. File pruning 3. Read and decompress filter column 4. Binary search using inverted index, skip to next blocklet if no matching Spark Executor Blocklet Task Task 2. Blocklet C1 C2 C3 C4 Cn pruning … HDFS File File File File Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet … Blocklet Blocklet Blocklet Blocklet … 5. Decompress projection column Footer Footer Footer Footer 6. Return decoded data to spark 22
23 .文件内扫描优化,与Spark向量化处理对接 Spark向量化处理 + Whole Stage CodeGen ColumnBatch 结构 大颗粒IO单元(Carbon V3格式): •Blocklet内部一个Column Chunk 是一个IO单元, 向量化CarbonReader Blocklet按大小切分,默认64MB,大概有100万行记 录。大颗粒顺序读提升扫描性能。 Header Version Schema Timestamp 跳跃解码(Carbon V3格式) : Blocklet 1 •增加数据页Page概念,按Page进行过滤和解码,减 PageHeader … 少不必要的解码解压缩,提升CPU利用率 C1 PageData … PageHeader … 向量化解码 + Spark向量化处理 C2 PageData … •解码和解压缩采用向量化处理,与Spark2.1向量化、 Codegen结合,在扫描+聚合场景下提升性能4X Blocklet 2 … 堆外内存: •处理大结果集时,解码解压缩过程中堆外完成,减 Footer BlockletHeader … 少GC 23
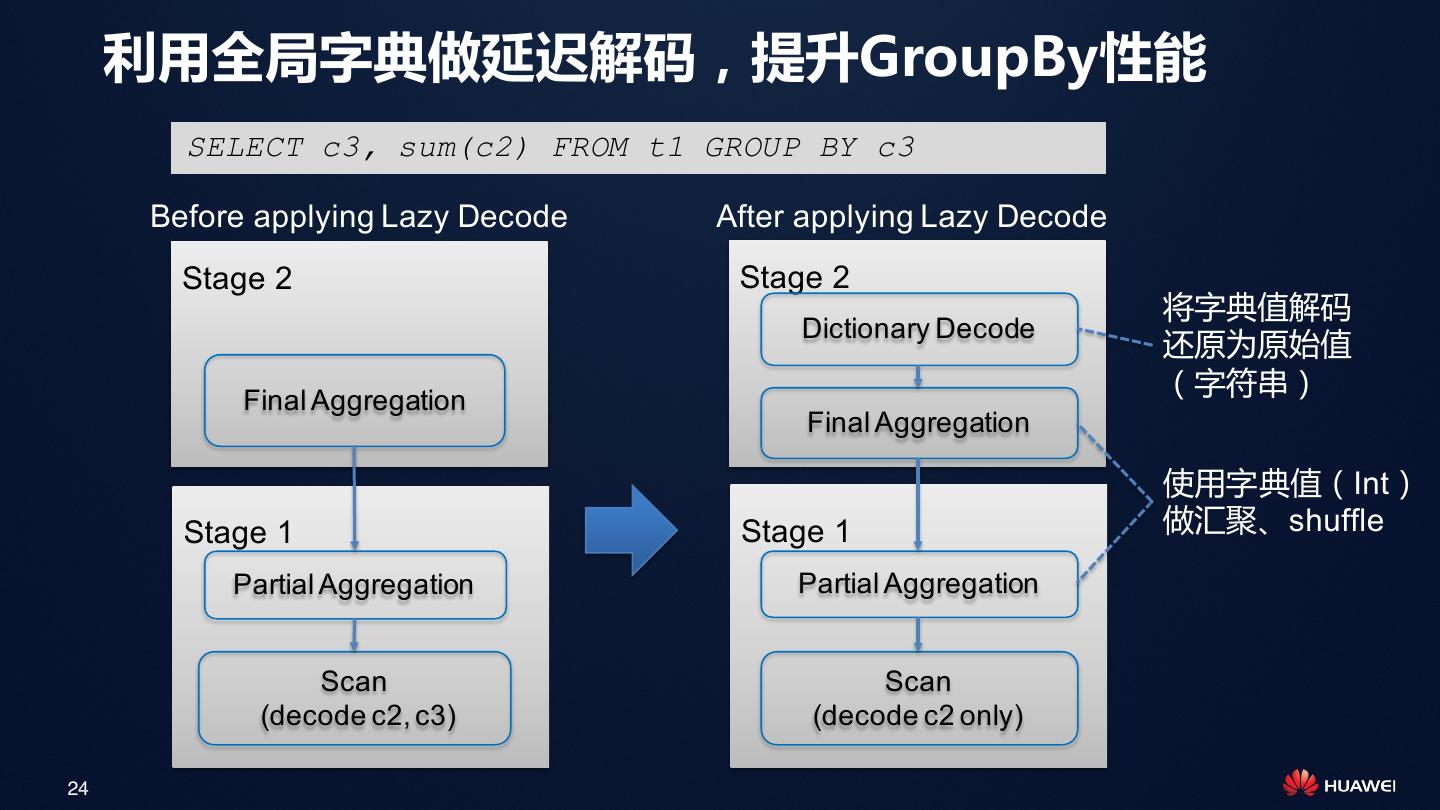
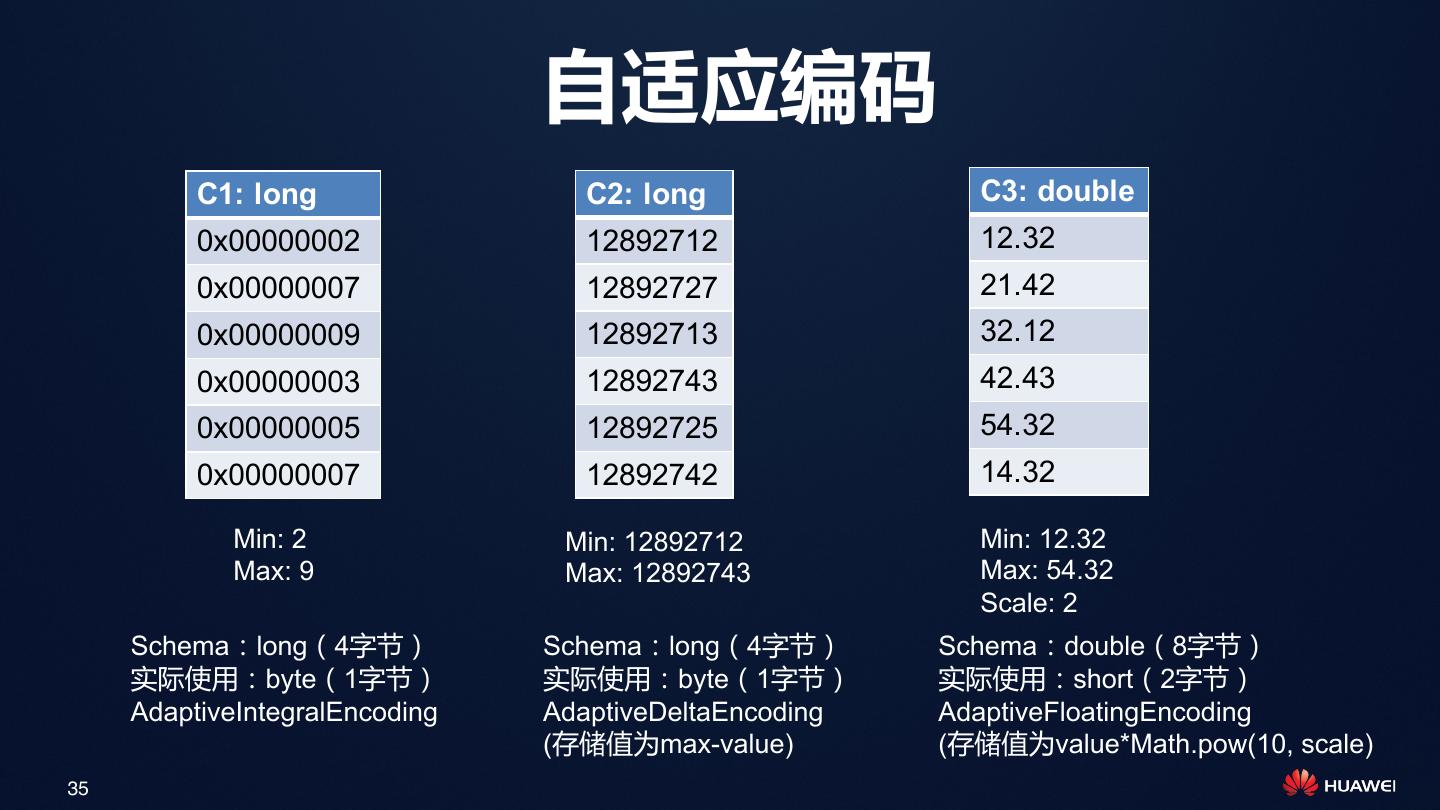
24 . 利用全局字典做延迟解码,提升GroupBy性能 SELECT c3, sum(c2) FROM t1 GROUP BY c3 Before applying Lazy Decode After applying Lazy Decode Stage 2 Stage 2 将字典值解码 Dictionary Decode 还原为原始值 Final Aggregation (字符串) Final Aggregation 使用字典值(Int) Stage 1 Stage 1 做汇聚、shuffle Partial Aggregation Partial Aggregation Scan Scan (decode c2, c3) (decode c2 only) 24
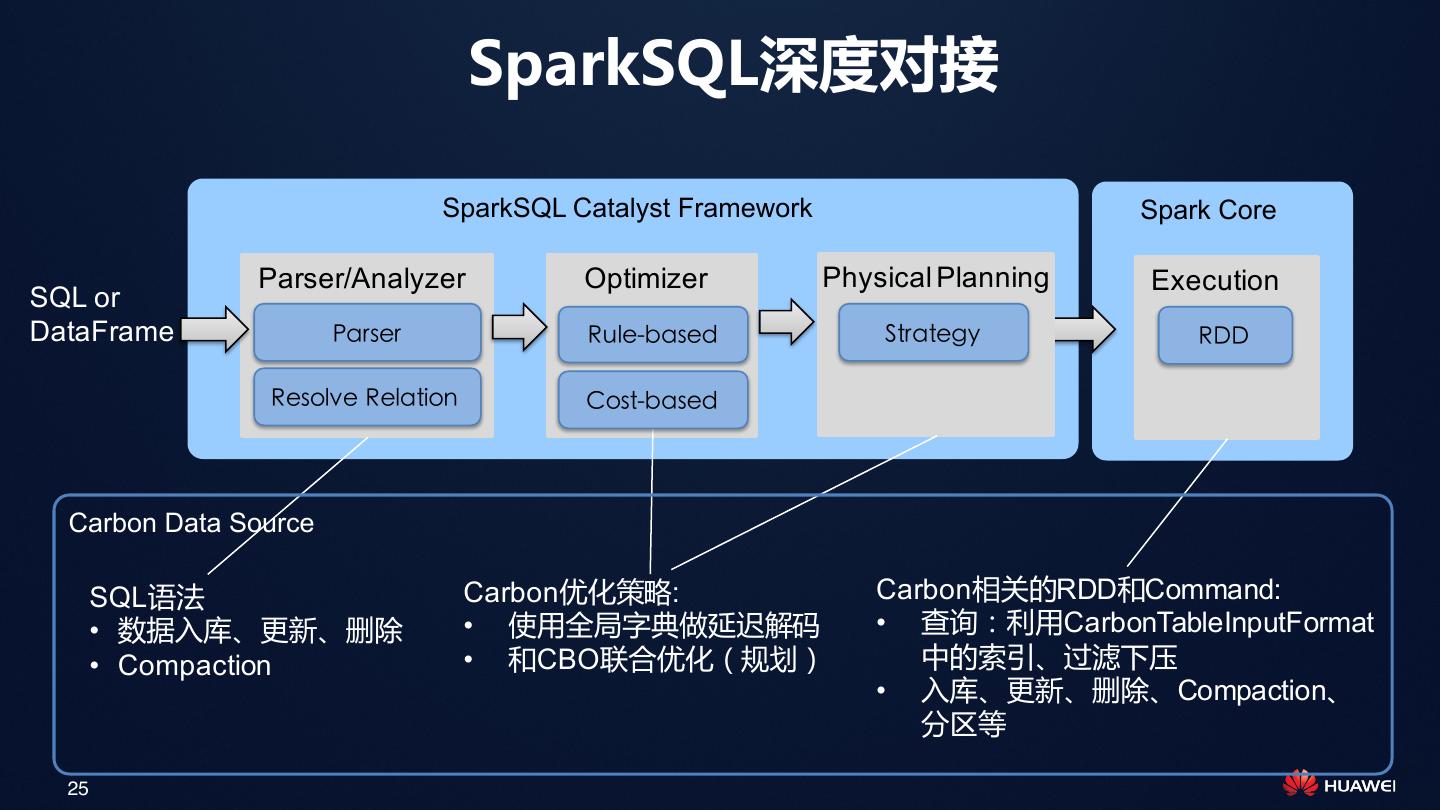
25 . SparkSQL深度对接 SparkSQL Catalyst Framework Spark Core Parser/Analyzer Optimizer Physical Planning Execution SQL or DataFrame Parser Rule-based Strategy RDD Resolve Relation Cost-based Carbon Data Source SQL语法 Carbon优化策略: Carbon相关的RDD和Command: • 数据入库、更新、删除 • 使用全局字典做延迟解码 • 查询:利用CarbonTableInputFormat • Compaction • 和CBO联合优化(规划) 中的索引、过滤下压 • 入库、更新、删除、Compaction、 分区等 25
26 .总结:CarbonData的优秀DNA 查询: • 两级索引,减少IO:适合ad-hoc查询,任意维度组合查询场景 • 延迟解码,向量化处理:适合全表扫描、汇总分析场景 数据管理: • 增量入库,多级排序可调:由用户权衡入库时间和查询性能 • 增量更新,批量合并:支持快速更新事实表或维表,闲时做Compaction合并 大规模: • 计算与存储分离:支持从GB到PB大规模数据,万亿数据秒级响应 部署: • Hadoop Native格式:与大数据生态无缝集成,利用已有Hadoop集群资产 26
27 . 应用场景和调优介绍 27
28 . 应用场景 • 场景1:详单分析 • 场景2:数仓BI分析 28
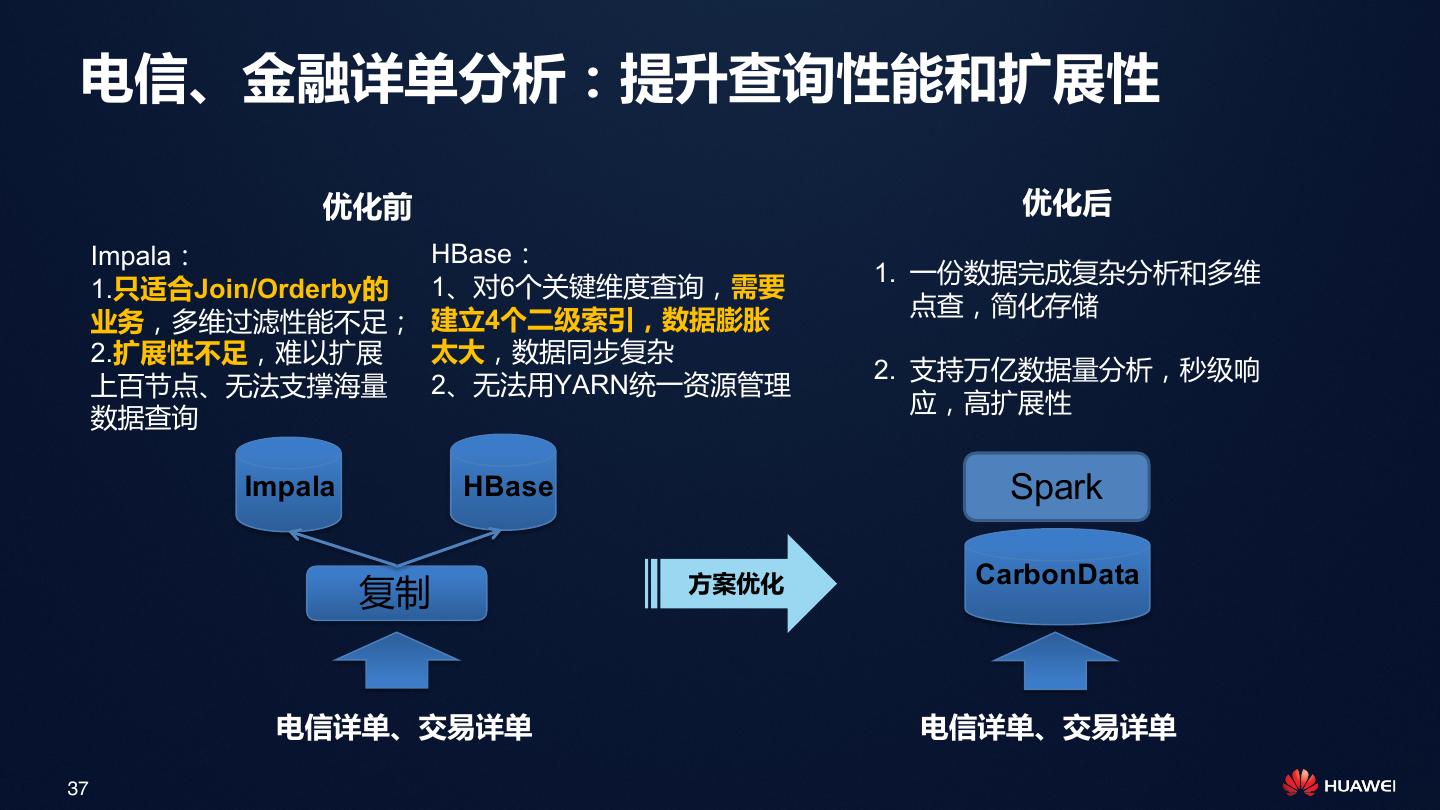
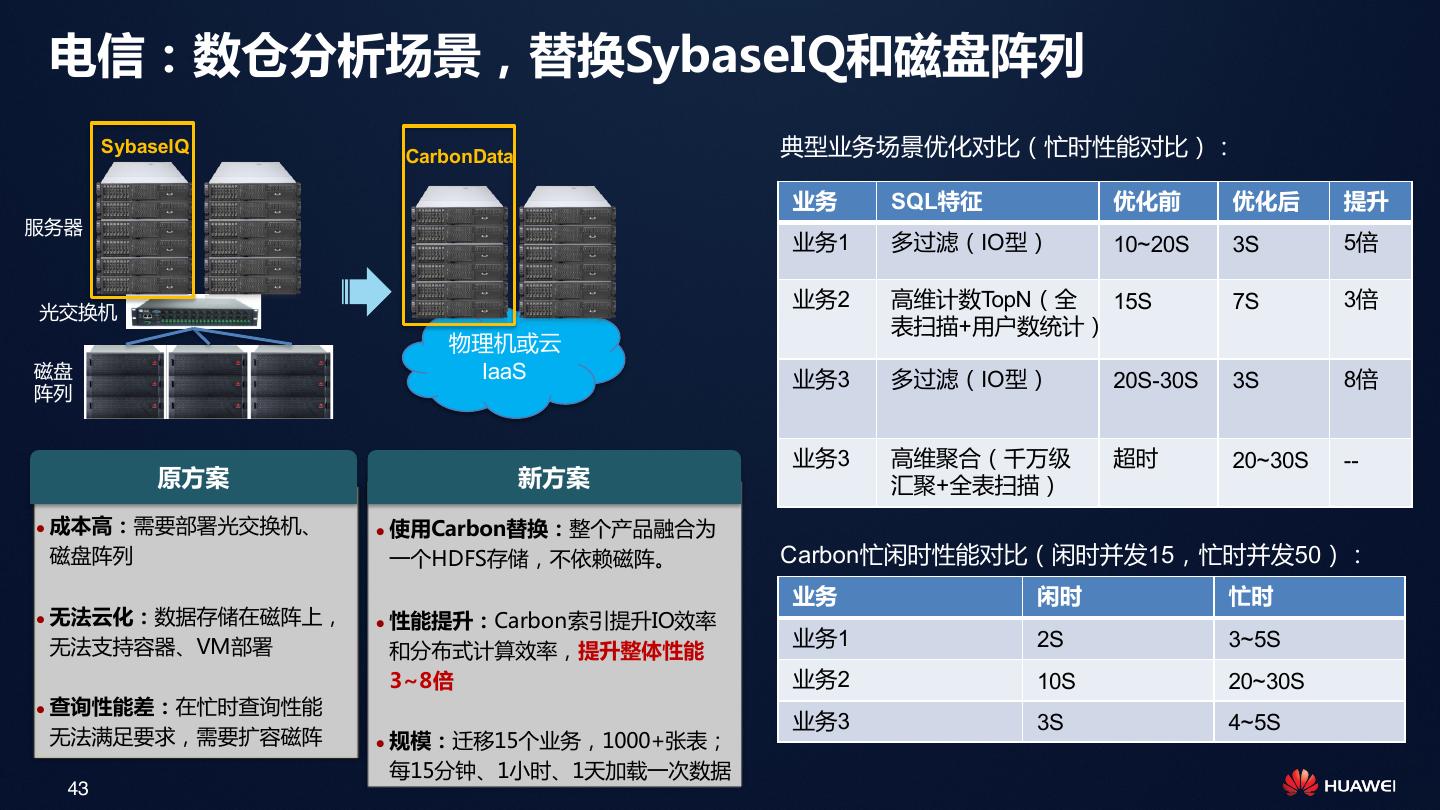
29 . 应用场景1:详单分析 业务:详单分析(明细数据ad-hoc查询),例如:事件日志分析,用户行为分析,流水表查询 业务诉求: • 入库:详单来得快,要快速入库,>10万记录每秒每节点 • 存储:单表数据量大,存储N年数据,压缩率越高越好,存储成本压力大 • 查询: • 多条件灵活过滤,一般提供界面让用户选择条件 • 精确匹配,模糊匹配 • 事实表Join维度表,例如替换用户ID • 最终输出:明细数据或对结果轻度汇总 分钟级入库 29
3秒后跳转登录页面
去登陆

