











































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
CarbonData An Indexed Columnar File Format For Interactive Query
Apache CarbonData诞生的动机,基本软件架构原理以及调优手段。
展开查看详情
1 . CarbonData : An Indexed Columnar File Format For Interactive Query HUAWEI TECHNOLOGIES CO., LTD.
2 .Outline u Motivation : Why introducing a new file format? u CarbonData Deep Dive u Tuning Hint 2
3 . Big Data Network Consumer Enterprise • 54B records per day • 100 thousands of sensors • 100 GB to TB per day • 750TB per month • >2 million events per second • Data across different • Complex correlated data • Time series, geospatial data domains 3
4 .Typical Scenario Report & Dashboard OLAP & Ad-hoc Batch processing Machine learning Realtime Decision Text analysis Big Table Small table data Ex. CDR, transaction, Web Small table log,… Unstructured data 4
5 .Analytic Examples Tracing and Record Query for Operation Engineer 5
6 .Challenge - Data • Data Size • Single Table >10 B • Fast growing • Multi-dimensional • Every record > 100 dimension • Add new dimension occasionally • Rich of Detail • Billion level high cardinality • 1B terminal * 200K cell * 1440 minutes = 28800 (万亿) • Nested data structure for complex object 6
7 .Challenge - Application • Enterprise Integration • SQL 2003 Standard Syntax Multi-dimensional OLAP Query • BI integration, JDBC/ODBC • Flexible Query • Any combination of dimensions • OLAP Vs Detail Record • Full scan Vs Small scan Full Scan Query Point/Small Scan Query • Precise search & Fuzzy search 7
8 .How to choose storage? 8
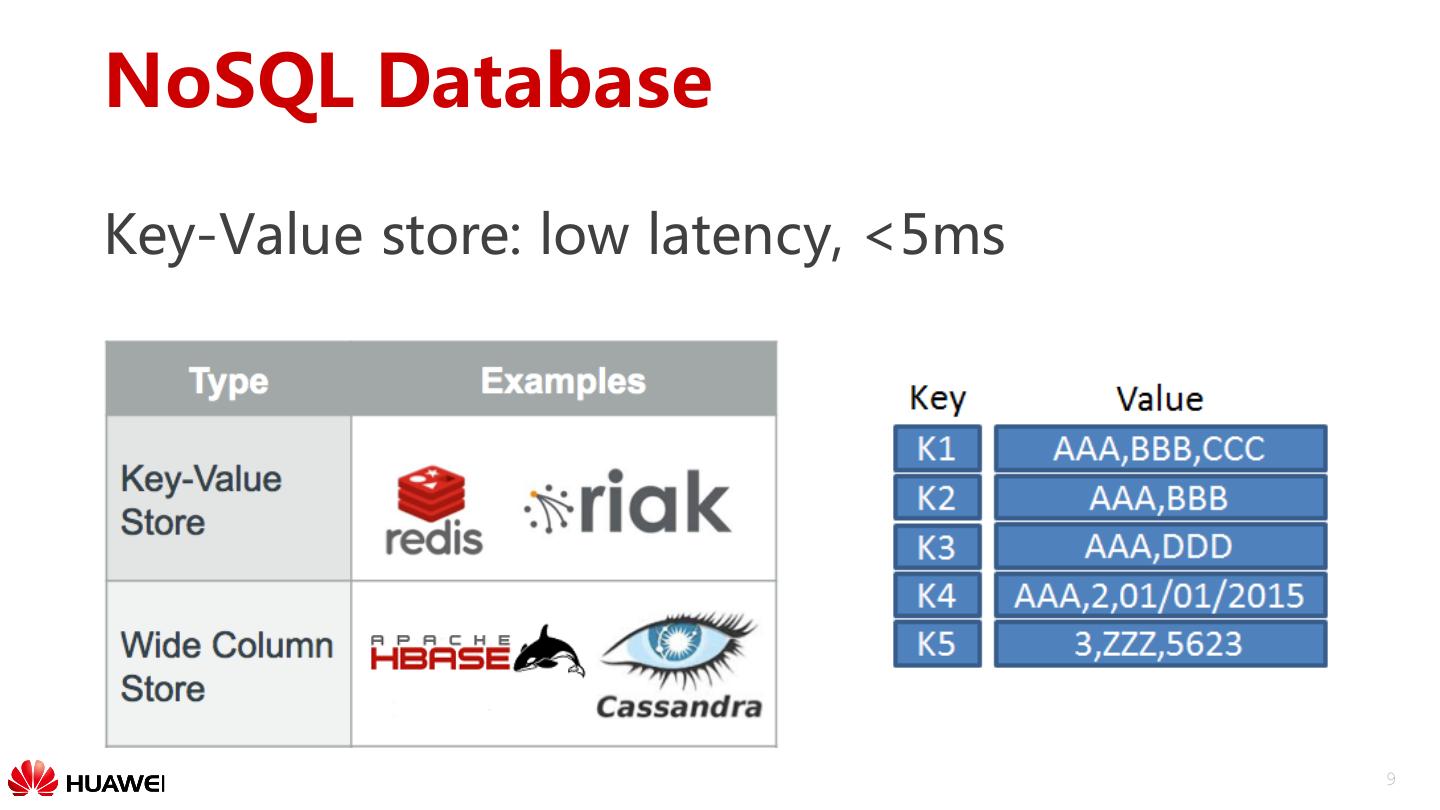
9 .NoSQL Database Key-Value store: low latency, <5ms 9
10 .Multi-dimensional problem Pre-compute all aggregation combinations Complexity: O(2^n) • Dimension < 10 • Too much space • Slow loading speed 10
11 .Shared nothing database • Parallel scan + distributed compute • Multi-dimensional OLAP • Index management problem • Questionable scalability and fault-tolerance • Cluster size < 100 data node • Not suitable for big batch job 11
12 .Search engine • All column indexed • Fast searching • Simple aggregation • Designed for search but not OLAP • complex computation: TopN, join, multi-level aggregation • 3~4X data expansion in size • No SQL support 12
13 .SQL on Hadoop • Modern distributed architecture, scale well in computation. • Pipeline based: Impala, Drill, Flink, … • BSP based: Hive, SparkSQL • BUT, still using file format designed for batch job • Focus on scan only • No index support, not suitable for point or small scan queries 13
14 . Capability Matrix Type Store Good Bad KV Store HBase, Multi-dimensional OLAP Query Cassandra, … Parallel Greenplum, database Vertica, … Search Solr, engine ElasticSearch, … SQL on Impala, Hadoop - HAWQ, Pipeline Drill, … Full Scan Query Point/Small Scan Query SQL on Hive, Hadoop - SparkSQL BSP 14
15 .Architect’s choice Choice 1: Compromising Choice 2: Replicating of data App1 App2 App3 App1 App2 App3 Loading Replication Data Data 15
16 .CarbonData: An Unified Data Storage in Hadoop Ecosystem 16
17 .Motivation Multi-dimensional OLAP Query CarbonData: Unified Storage Full Scan Query Point/Small Scan Query 17
18 .Apache CarbonData • An Apache Incubating Project • Incubation start in June, 2016 Compute • Goal: • Make big data simple • High performance Storage • Current Status: • First stable version released • Focus on indexed columnar file format • Deep query optimization with Apache Spark 18
19 .Community • First Stable Version Released in Aug, 2016! • Welcome contribution: • Code: https://github.com/apache/incubator-carbondata • JIRA: https://issues.apache.org/jira/browse/CARBONDATA • Maillist: dev@carbondata.incubator.apache.org • Contributor from: Huawei, Talend, Intel, eBay, Inmobi, MeiTuan(美团) 19
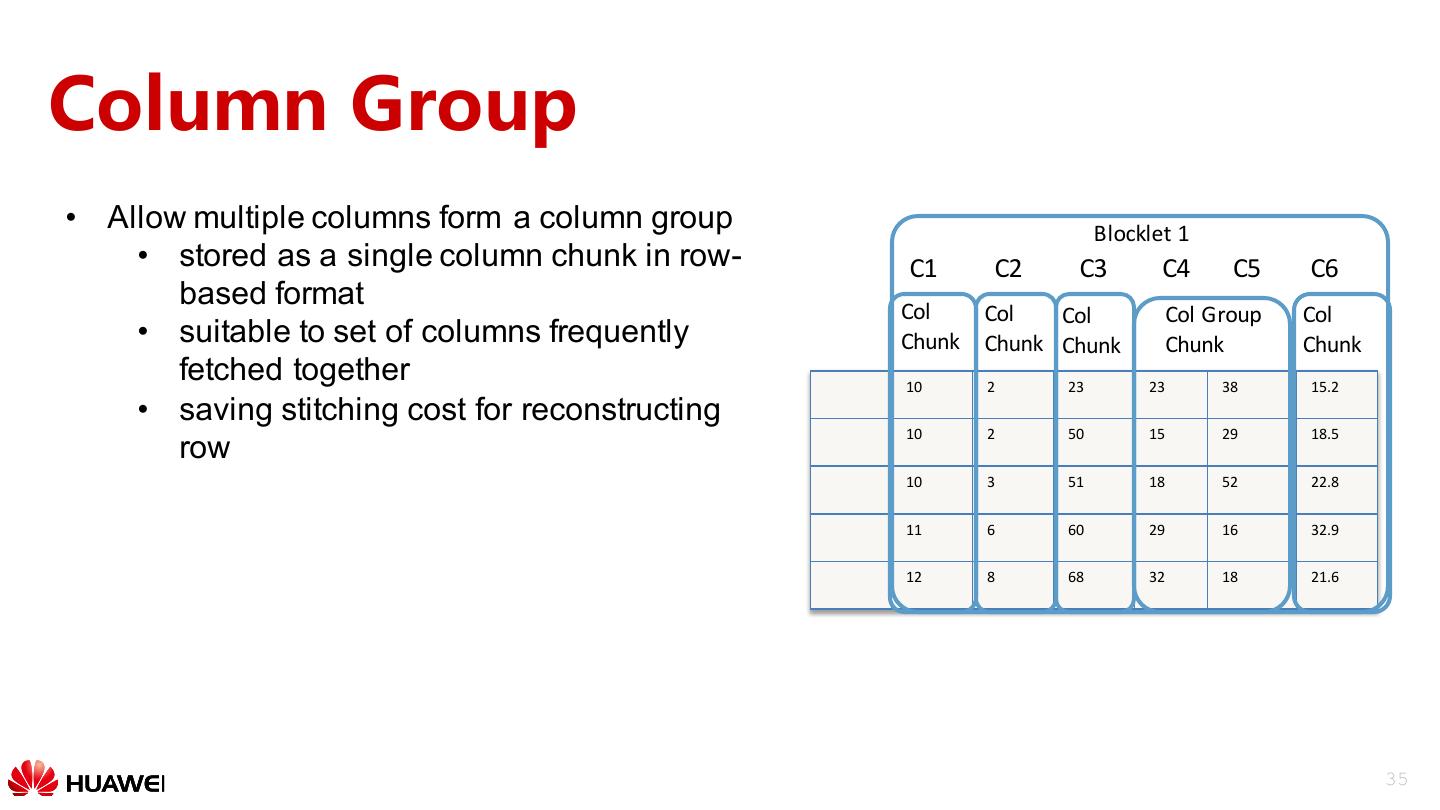
20 .Feature Introduction • Table level feature • File level feature 20
21 .Carbon-Spark Integration • Built-in Spark integration • Spark 1.5, 1.6 Data Query • Interface Management Optimization • SQL • DataFrame API • Query Optimization Reader/Writer • Data Management • Bulk load/Incremental load Carbon File Carbon File Carbon File • Delete load • Compaction 21
22 .Integration with Spark • Query CarbonData Table • DataFrame API carbonContext.read With late decode optimization and .format(“carbondata”) .option(“tableName”, “table1”) carbon-specific SQL command .load() support sqlContext.read .format(“carbondata”) .load(“path_to_carbon_file”) • Spark SQL Statement CREATE TABLE IF NOT EXISTS T1 (name String, PhoneNumber String) STORED BY “carbondata” LOAD DATA LOCAL INPATH ‘path/to/data’ INTO TABLE T1 • Support schema evolution of Carbon table via ALTER TABLE • Add, Delete or Rename Column 22
23 . Data Ingestion LOAD DATA [LOCAL] INPATH 'folder path' • Bulk Data Ingestion [OVERWRITE] INTO TABLE tablename • CSV file conversion OPTIONS(property_name=property_value, ...) • MDK clustering level: load level vs. node level INSERT INTO TABLE tablennme AS select_statement1 FROM table1; • Save Spark dataframe as Carbon data file df.write .format(“carbondata") .options("tableName“, “tbl1")) .mode(SaveMode.Overwrite) .save() 23
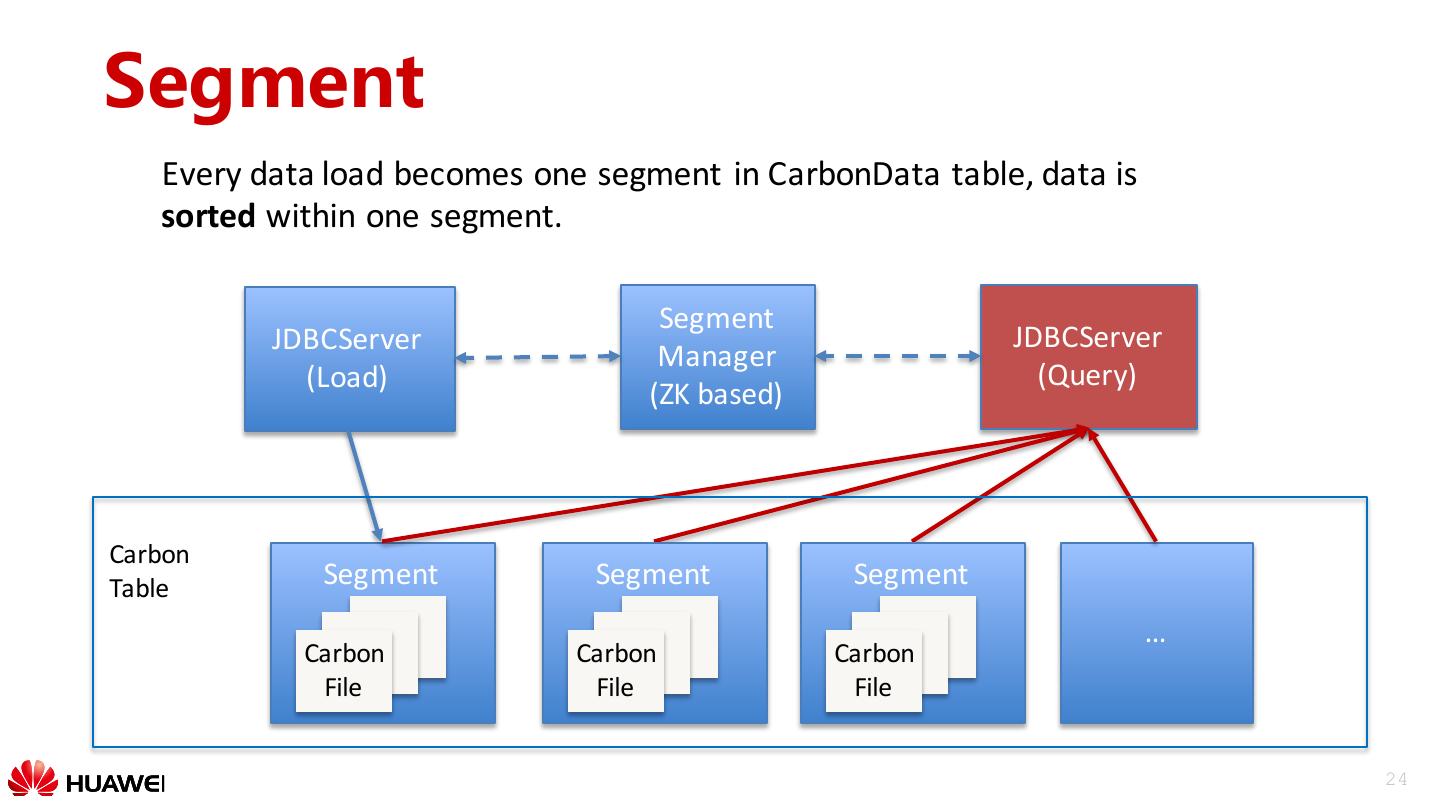
24 .Segment Every data load becomes one segment in CarbonData table, data is sorted within one segment. Segment JDBCServer JDBCServer Manager (Load) (Query) (ZK based) Carbon Table Segment Segment Segment … Carbon Carbon Carbon File File File 24
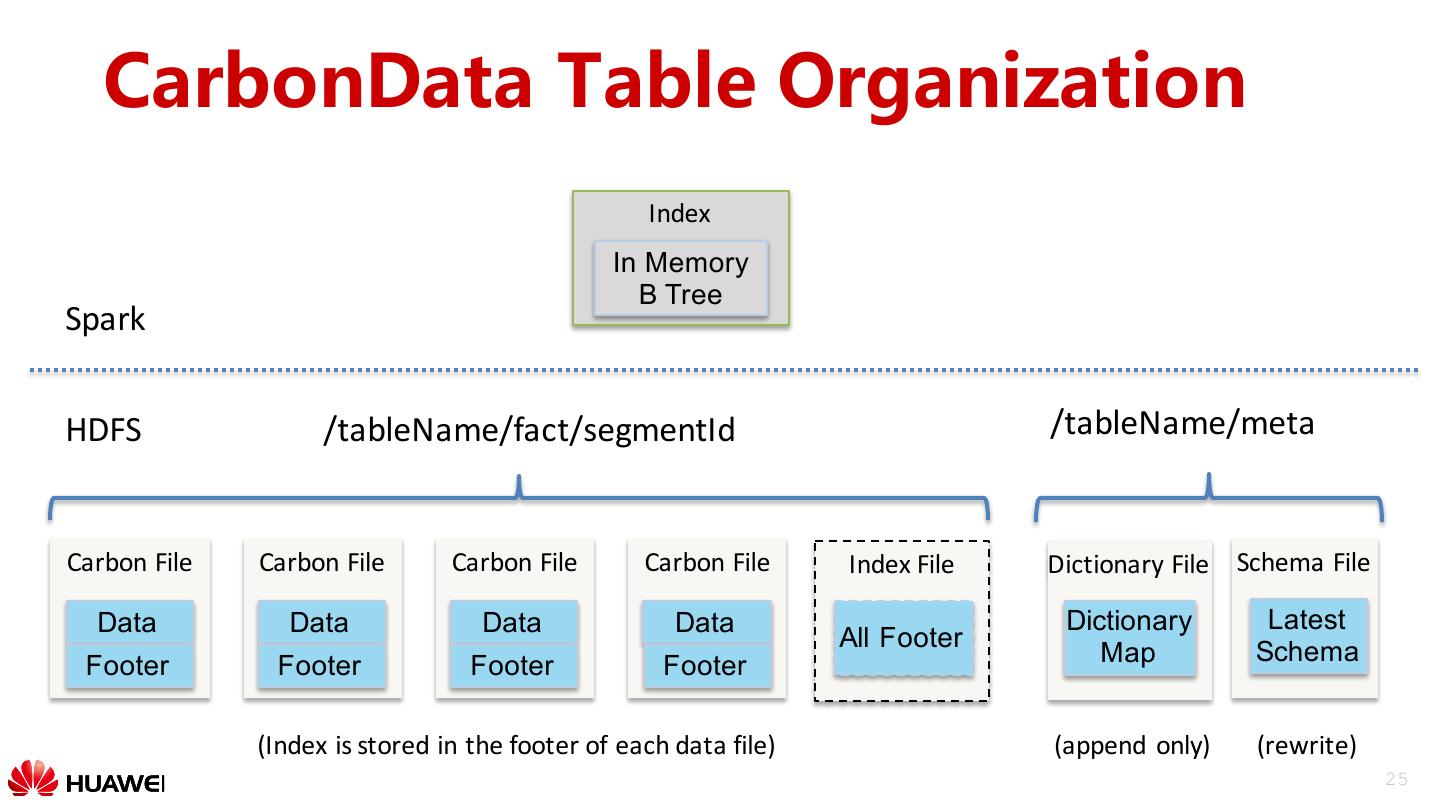
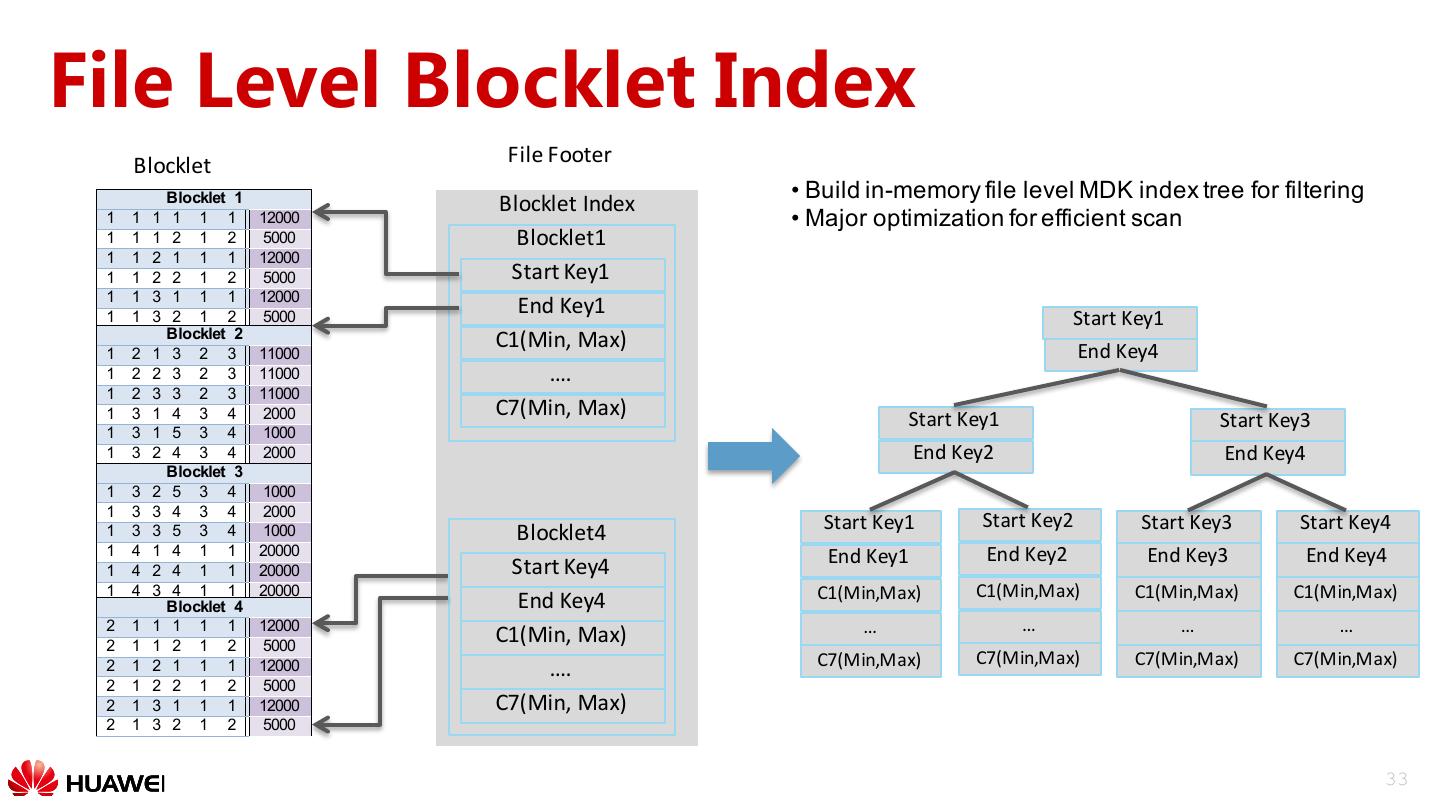
25 . CarbonData Table Organization Index In Memory B Tree Spark HDFS /tableName/fact/segmentId /tableName/meta Carbon File Carbon File Carbon File Carbon File Index File Dictionary File Schema File Data Data Data Data Dictionary Latest All Footer Footer Footer Footer Footer Map Schema (Index is stored in the footer of each data file) (append only) (rewrite) 25
26 .Data Compaction • Data compaction is used to merge small files • Re-clustering across loads for better performance • Two types of compactions supported - Minor compaction • Compact adjacent segment based on number of segment - Major compaction • Compact segments based on size ALTER TABLE [db_name.]table_name COMPACT ‘MINOR/MAJOR’ 26
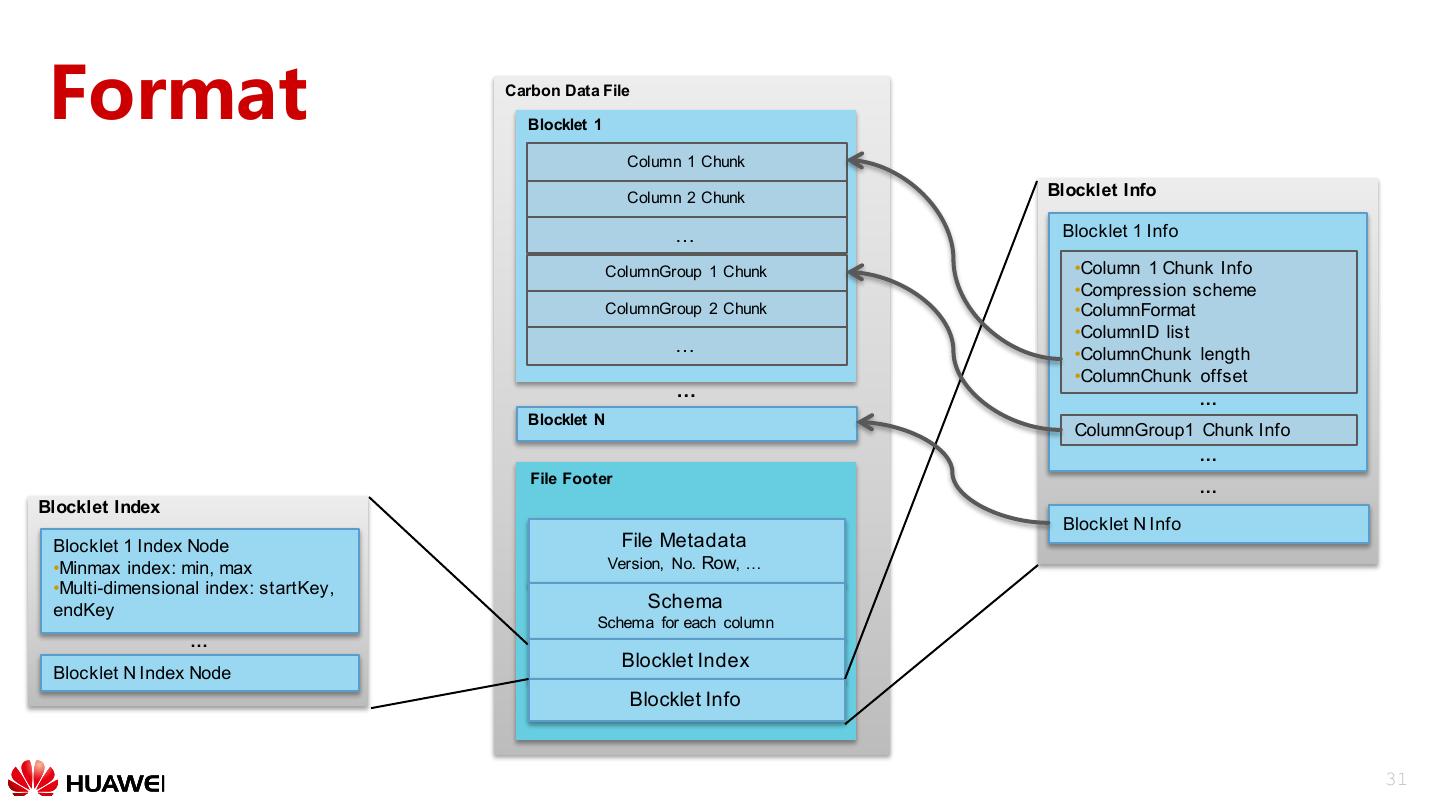
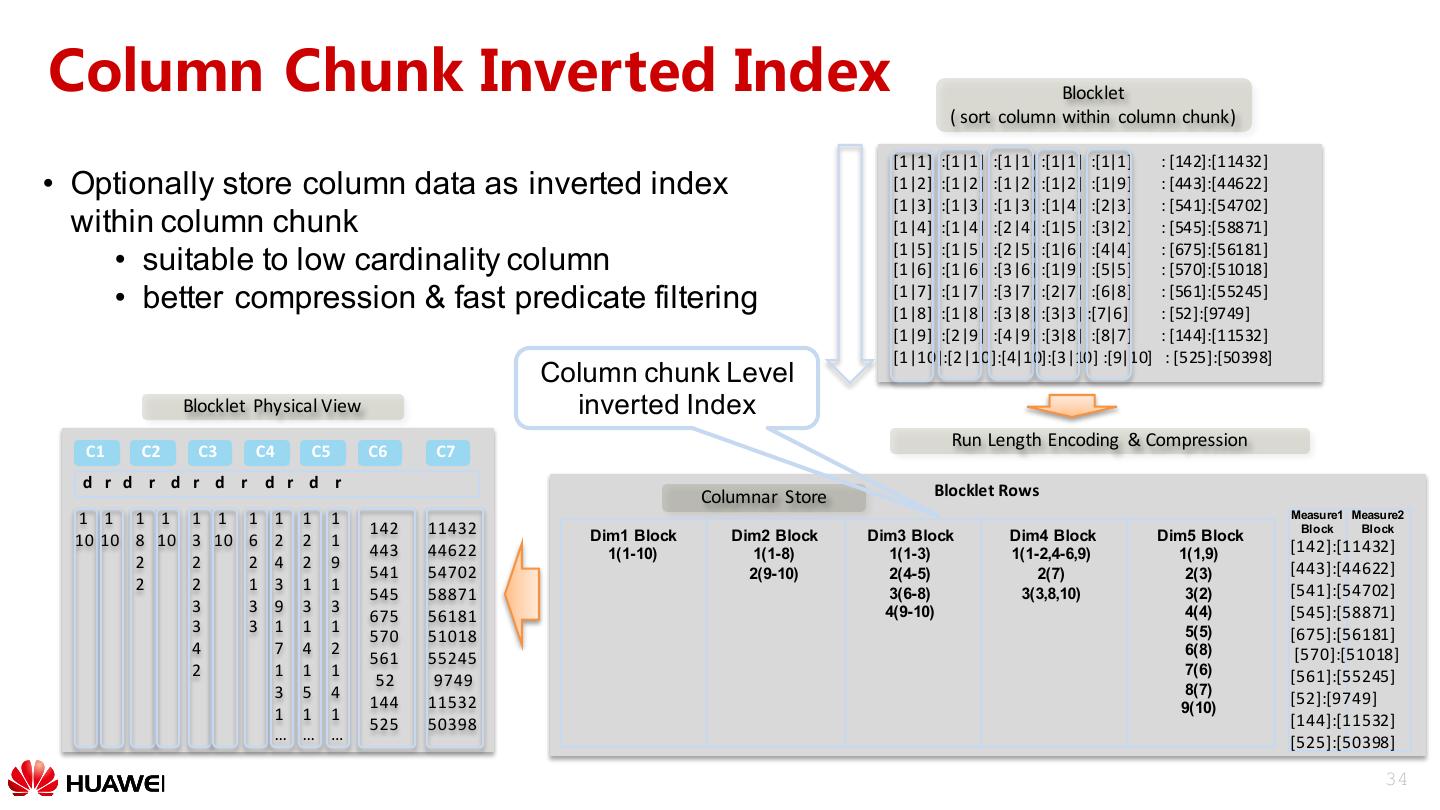
27 . Query Optimization: Index Spark Driver Multi-level indexes: •Table level index: global B+ tree Catalyst index, used to filter blocks Table Level Index •File level index: local B+ tree Executor Executor index, used to filter blocklet File Level Index File Level Index •Column level index: inverted & Scanner & Scanner index within column chunk Carbon File Carbon File Carbon File Column Data Data Data Level Index Footer Footer Footer 27
28 .Block Pruning Spark Driver side CarbonData index (table level) • Query optimization • Leveraging multi-level indexes for effective predicate push- down • Column Pruning • Late materialization for aggregation through deferred decoding Blocklet HDFS C1 C2 C3 C4 C5 C6 C7 C9 Block Block Block Block Inverted Blocklet Blocklet Blocklet Blocklet Index … Blocklet Blocklet Blocklet Blocklet … Footer Footer Footer Footer 28
29 .Query Optimization: Late Decode Original plan Optimized plan Translate DictionaryDecode dictionary key to value Aggregation Aggregation Groupby on dictionary key Filter Filter Scan Scan 29
3秒后跳转登录页面
去登陆

