


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
CarbonData Partition功能介绍和上汽实践分享
CarbonData Partition功能原理介绍和性能分析对比,以及上汽集团的CarbonData实践分享
展开查看详情
1 . CarbonData Partition 功能介绍 与 上汽集团 CarbonData实践分享 曹 鲁 2017.9.2
2 .关于我 曹 鲁 2010年毕业于武汉⼤学计算机学院 曾负责某⾦融⾏业公司BI、ETL系统开发,某互联⽹电商⾏业公司数据仓库 的容量管理、性能调优等 2016年加⼊上汽集团数据业务部 负责⼤数据平台架构设计与开发 关注⼤数据技术与开源社区 Mail:caolu@saicmotor.com
3 .上汽集团数据业务部 主要负责 • 规划和实施数据管理体系 • 建设⼤数据基础架构和分析平台 • 拓展和提升集团内企业数据业务能⼒ • 推动⼈⼯智能技术在集团业务中的应用 为上汽集团战略转型和创新发展提供支持和服务。
4 .议题 CarbonData Partition 功能介绍 • CarbonData背景、⽂件结构、建索引过程简介 • Partition功能将带来的改变 • PartitionTable的建表语句 • PartitionTable的数据加载过程 • PartitionTable的查询过程 • Partition 的新增(add)、拆分(split)及删除(drop) 上汽集团的CarbonData实践
5 . CarbonData Partition 功能介绍 Apache CarbonData 是⼤数据平台上⼀种带索引的列式存储数据格式 • 2016年6月由华为公司贡献⾄apache基⾦会,成为apache孵化项目 • 2017年4月正式毕业为apache顶级项目
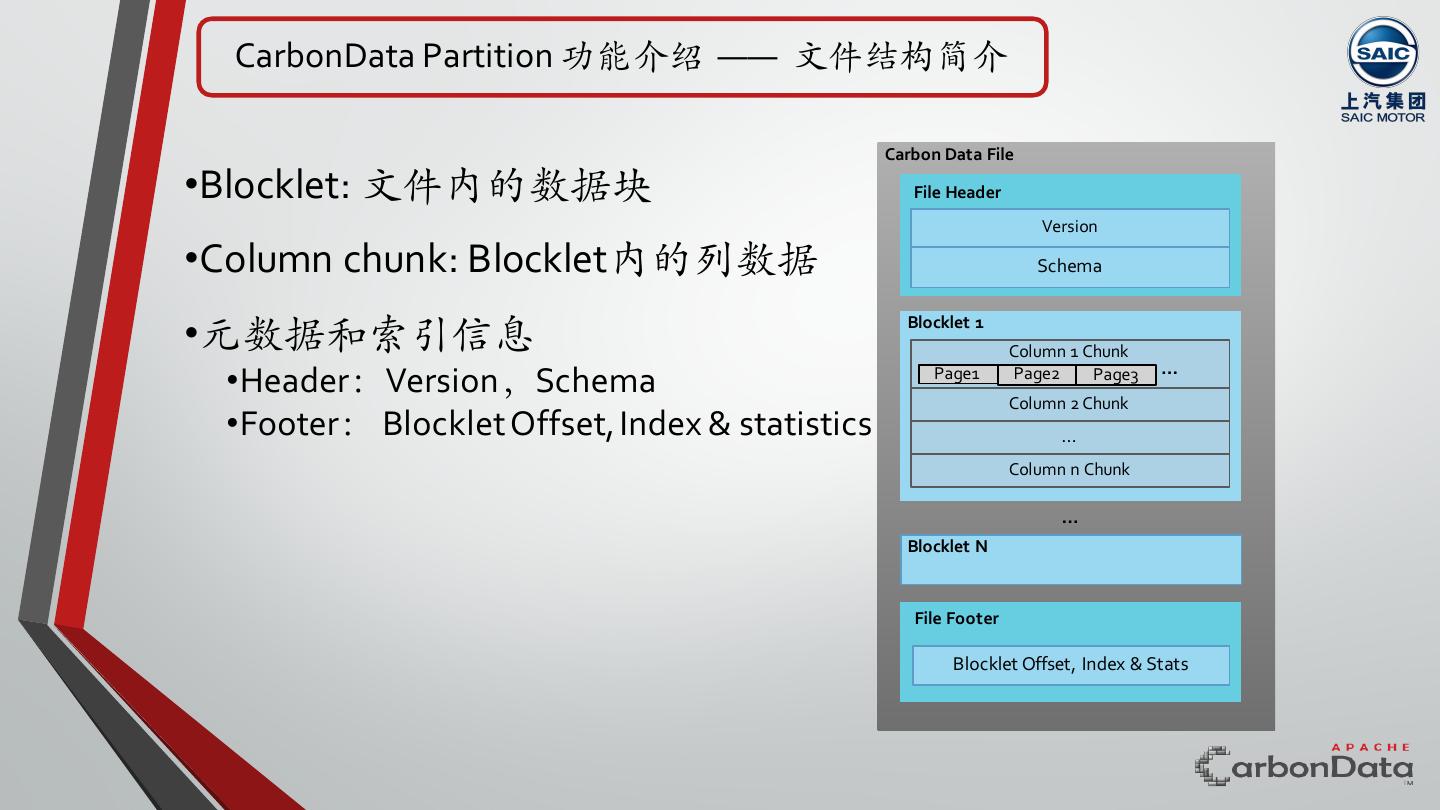
6 . CarbonData Partition 功能介绍 —— ⽂件结构简介 Carbon Data File •Blocklet: ⽂件内的数据块 File Header Version •Column chunk: Blocklet内的列数据 Schema •元数据和索引信息 Blocklet 1 Column 1 Chunk •Header:Version,Schema Page1 Page2 Page3 Column 2 Chunk … •Footer: Blocklet Offset, Index & statistics … Column n Chunk … Blocklet N File Footer Blocklet Offset, Index & Stats
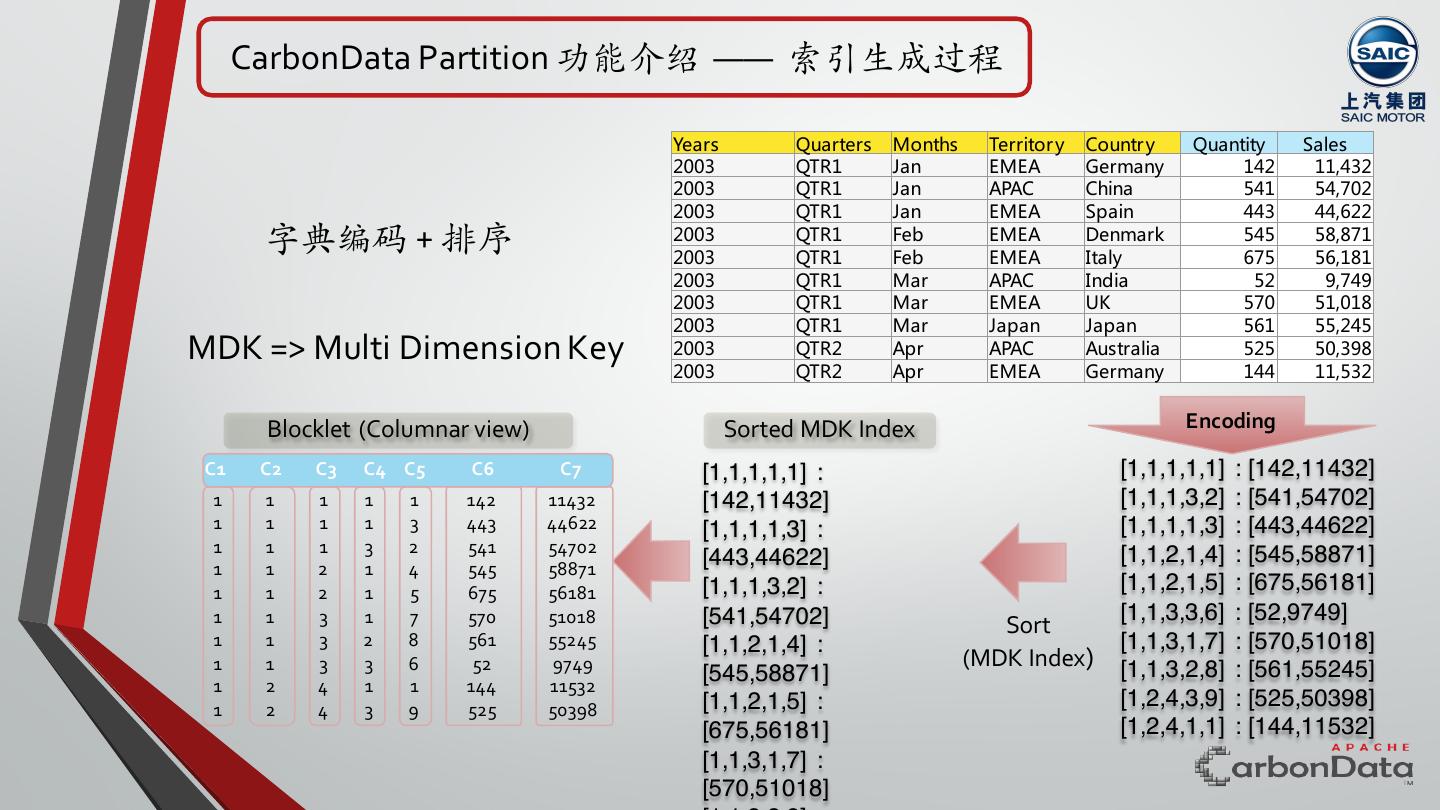
7 . CarbonData Partition 功能介绍 —— 索引⽣成过程 Years Quarters Months Territor y Countr y Quantity Sales 2003 QTR1 Jan EMEA Germany 142 11,432 2003 QTR1 Jan APAC China 541 54,702 2003 QTR1 Jan EMEA Spain 443 44,622 字典编码 + 排序 2003 2003 QTR1 QTR1 Feb Feb EMEA EMEA Denmark Italy 545 675 58,871 56,181 2003 QTR1 Mar APAC India 52 9,749 2003 QTR1 Mar EMEA UK 570 51,018 2003 QTR1 Mar Japan Japan 561 55,245 MDK => Multi Dimension Key 2003 QTR2 Apr APAC Australia 525 50,398 2003 QTR2 Apr EMEA Germany 144 11,532 Blocklet (Columnar view) Sorted MDK Index Encoding C1 C2 C3 C4 C5 C6 C7 [1,1,1,1,1] : [1,1,1,1,1] : [142,11432] 1 1 1 1 1 142 11432 [142,11432] [1,1,1,3,2] : [541,54702] 1 1 1 1 3 443 44622 [1,1,1,1,3] : [1,1,1,1,3] : [443,44622] 1 1 1 3 2 541 54702 [1,1,2,1,4] : [545,58871] 1 1 2 1 4 545 58871 [443,44622] 1 1 2 1 5 675 56181 [1,1,1,3,2] : [1,1,2,1,5] : [675,56181] 1 1 3 1 7 570 51018 [541,54702] [1,1,3,3,6] : [52,9749] Sort 1 1 3 2 8 561 55245 [1,1,2,1,4] : [1,1,3,1,7] : [570,51018] 1 1 3 3 6 52 9749 (MDK Index) [1,1,3,2,8] : [561,55245] 1 2 4 1 1 144 11532 [545,58871] 1 2 4 3 9 525 50398 [1,1,2,1,5] : [1,2,4,3,9] : [525,50398] [675,56181] [1,2,4,1,1] : [144,11532] [1,1,3,1,7] : [570,51018]
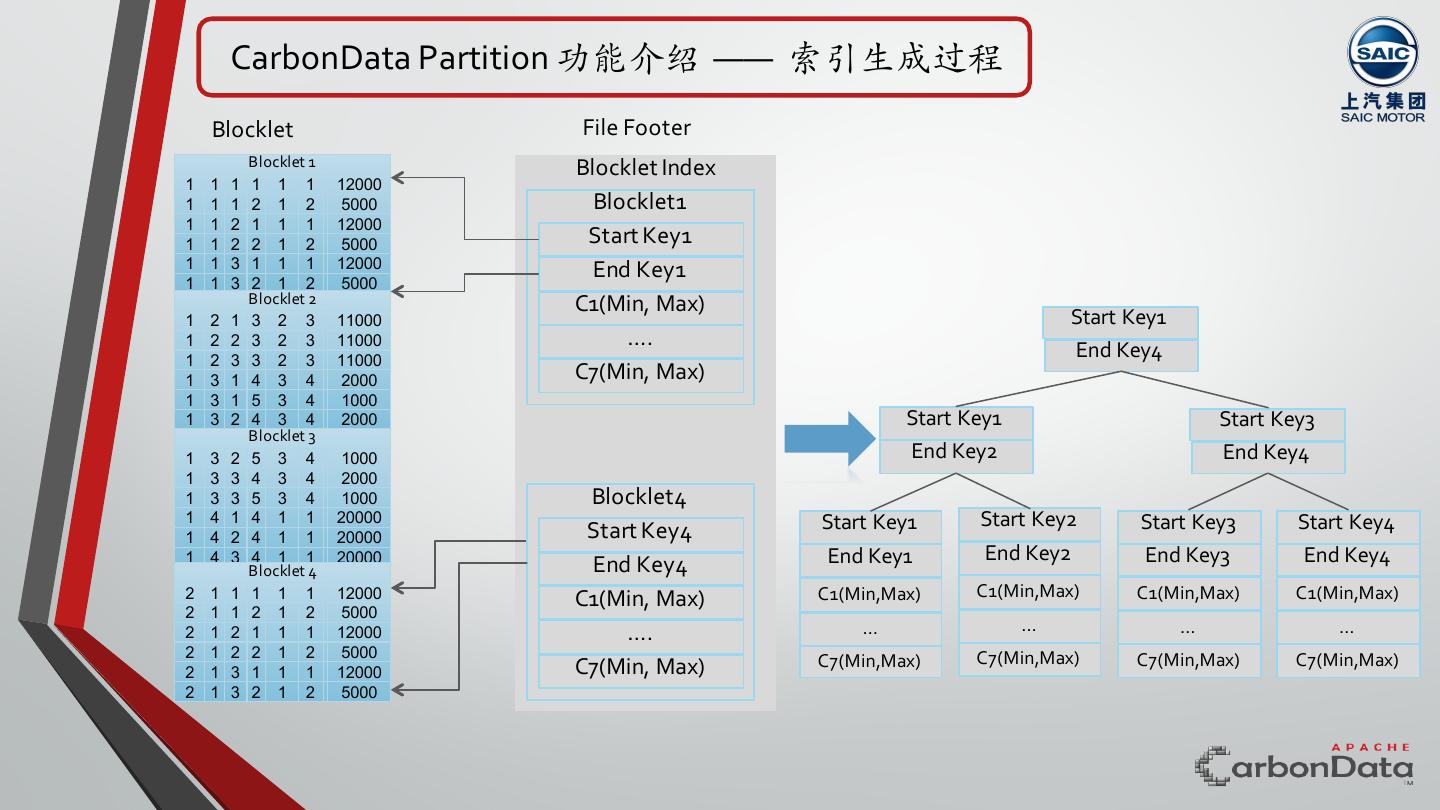
8 . CarbonData Partition 功能介绍 —— 索引⽣成过程 Blocklet File Footer Blocklet 1 Blocklet Index 1 1 1 1 1 1 12000 1 1 1 2 1 2 5000 Blocklet1 1 1 2 1 1 1 12000 1 1 2 2 1 2 5000 Start Key1 1 1 3 1 1 1 12000 End Key1 1 1 3 2 1 2 5000 Blocklet 2 C1(Min, Max) 1 2 1 3 2 3 11000 Start Key1 1 2 2 3 2 3 11000 …. 1 2 3 3 2 3 11000 End Key4 1 3 1 4 3 4 2000 C7(Min, Max) 1 3 1 5 3 4 1000 1 3 2 4 3 4 2000 Start Key1 Start Key3 Blocklet 3 1 3 2 5 3 4 1000 End Key2 End Key4 1 3 3 4 3 4 2000 1 3 3 5 3 4 1000 Blocklet4 1 4 1 4 1 1 20000 Start Key1 Start Key2 Start Key3 Start Key4 1 4 2 4 1 1 20000 Start Key4 1 4 3 4 1 1 20000 End Key1 End Key2 End Key3 End Key4 Blocklet 4 End Key4 2 1 1 1 1 1 12000 C1(Min, Max) C1(Min,Max) C1(Min,Max) C1(Min,Max) C1(Min,Max) 2 1 1 2 1 2 5000 2 1 2 1 1 1 12000 …. … … … … 2 1 2 2 1 2 5000 C7(Min,Max) C7(Min,Max) C7(Min,Max) C7(Min, Max) C7(Min,Max) 2 1 3 1 1 1 12000 2 1 3 2 1 2 5000
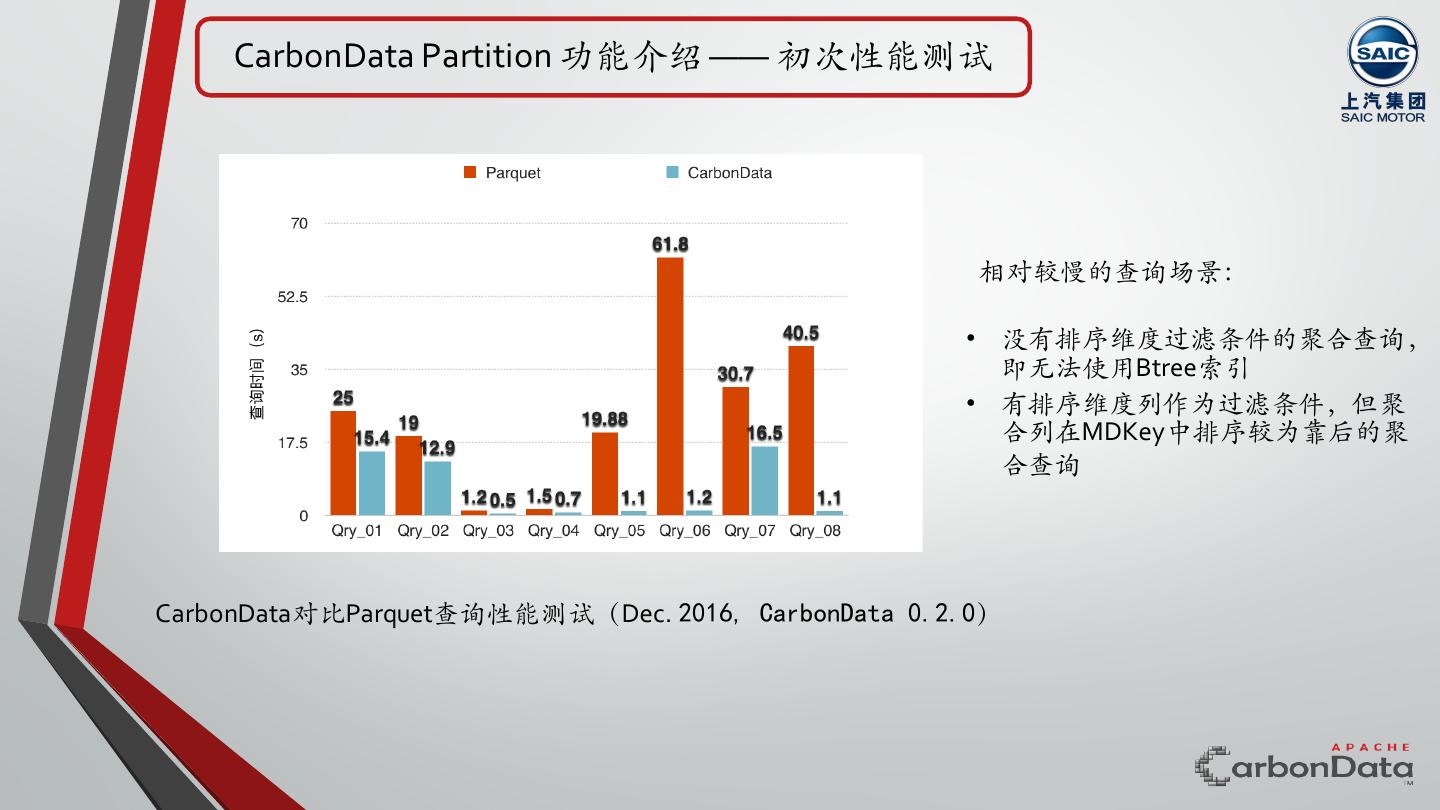
9 . CarbonData Partition 功能介绍 —— 初次性能测试 相对较慢的查询场景: • 没有排序维度过滤条件的聚合查询, 即⽆法使用Btree索引 • 有排序维度列作为过滤条件,但聚 合列在MDKey中排序较为靠后的聚 合查询 CarbonData对比Parquet查询性能测试(Dec. 2016, CarbonData 0.2.0)
10 .CarbonData Partition 功能介绍 为什么我们要做Partition功能? or Partition功能将带来哪些改变?
11 .CarbonData Partition 功能介绍 —— Partition带来的改变 改变1:数据将基于Partition列更为集中存储,查询时可过滤掉 ⼤量block,减少spark task数量 查询引擎 P1 P2 P3 P4
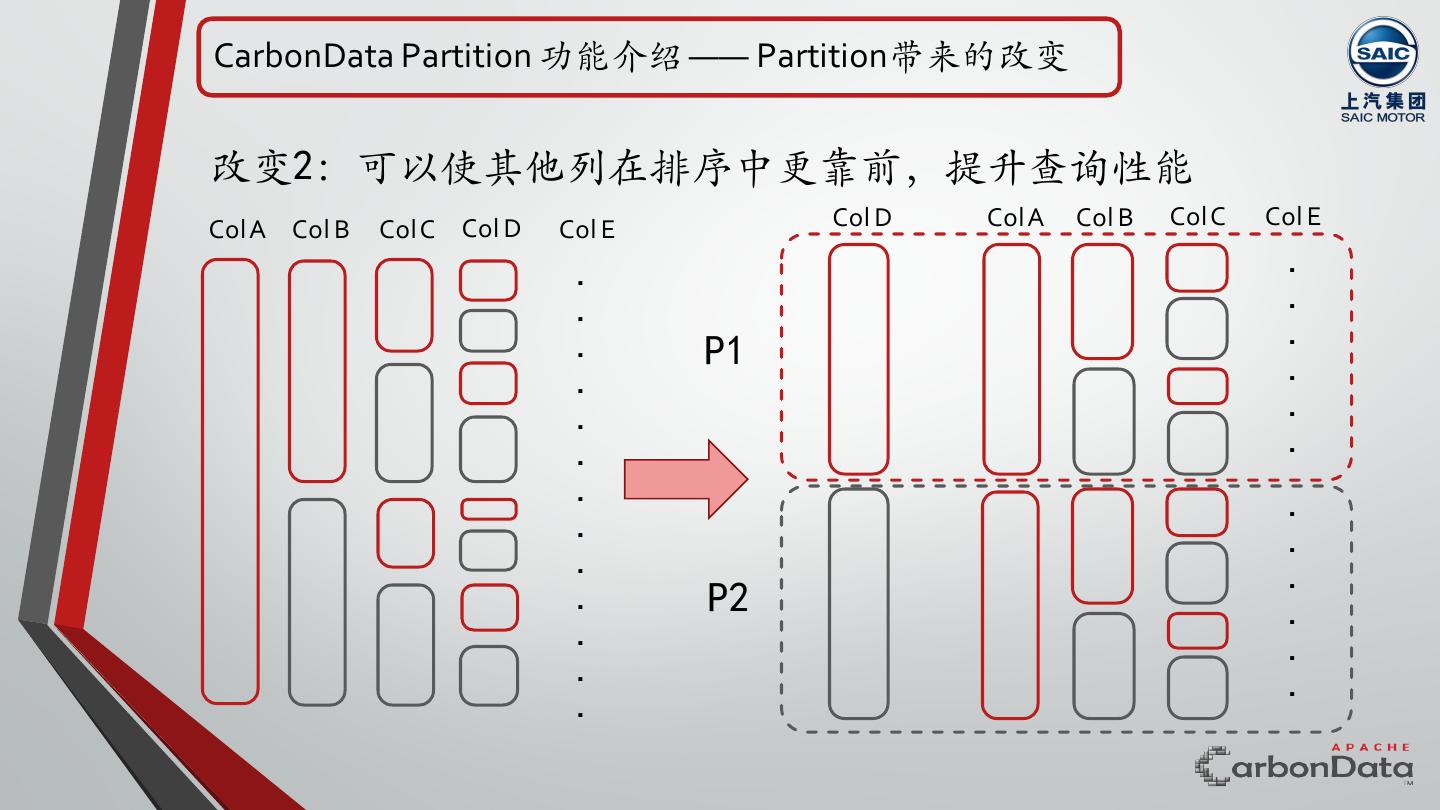
12 .CarbonData Partition 功能介绍 —— Partition带来的改变 改变2:可以使其他列在排序中更靠前,提升查询性能 Col A Col B Col C Col D Col E Col D Col A Col B Col C Col E . . . . . . P1 . . . . . . . . . . . . . P2 . . . . . .
13 .CarbonData Partition 功能介绍 目前支持三种类型Partition Table: • Hash Partition • Range Partition • List Partition • Range Interval(Developing)
14 . CarbonData Partition 功能介绍 Hash Partition DDL Syntax CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type , ...)] PARTITIONED BY (partition_col_name data_type) STORED BY 'carbondata' [TBLPROPERTIES ('PARTITION_TYPE'='HASH', 'PARTITION_NUM'='N' ...)] //N is the number of hash partitions create table if not exists hash_partition_table( Example col_A String, col_B Int, col_C Long, col_D Decimal(10,2), col_F Timestamp ) partitioned by (col_E Long) stored by 'carbondata' tblproperties('partition_type'='Hash','partition_num'='9')
15 . CarbonData Partition 功能介绍 Range Partition DDL Syntax CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type , ...)] PARTITIONED BY (partition_col_name data_type) STORED BY 'carbondata' [TBLPROPERTIES ('PARTITION_TYPE'='RANGE', 'RANGE_INFO'='2014-01-01, 2015-01-01, 2016-01-01' ...)] Example create table if not exists range_partition_table( col_A String, col_B Int, col_C Long, col_D Decimal(10,2), col_E Long ) RangeInfo 必须为升序 partitioned by (col_F Timestamp) stored by 'carbondata' tblproperties('partition_type'='Range', 'range_info'='2015-01-01, 2016-01-01, 2017-01-01, 2017-02-01')
16 . CarbonData Partition 功能介绍 List Partition DDL Syntax CREATE TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type , ...)] PARTITIONED BY (partition_col_name data_type) STORED BY 'carbondata' [TBLPROPERTIES ('PARTITION_TYPE'='LIST', 'LIST_INFO'='A, B, C' ...)] Example create table if not exists list_partition_table( col_B Int, col_C Long, col_D Decimal(10,2), col_E Long, ListInfo支持One Level Group col_F Timestamp ) partitioned by (col_A String) stored by 'carbondata' tblproperties('partition_type'='List', 'list_info'='aaaa, bbbb, (cccc, dddd), eeee')
17 . CarbonData Partition 功能介绍 —— Show Partition Syntax: SHOW PARTITIONS [db_name.]table_name Hash Partition Range Partition List Partition +--------------------+ +-------------------------------------+ +--------------------------+ |partition | |partition | |partition | +--------------------+ +-------------------------------------+ +--------------------------+ |vin = HASH_NUMBER(5)| |0, logdate = DEFAULT | |0, country = DEFAULT | +--------------------+ |1, logdate < 2014/01/01 | |1, country = China | |2, 2014/01/01 <= logdate < 2015/01/01| |2, country = UK, US | |3, 2015/01/01 <= logdate < 2016/01/01| |3, country = Japan | +-------------------------------------+ |7, country = Canada | |8, country = Russia | |9, country = Fiji | |5, country = Korea | |6, country = India | +--------------------------+ Partition Id
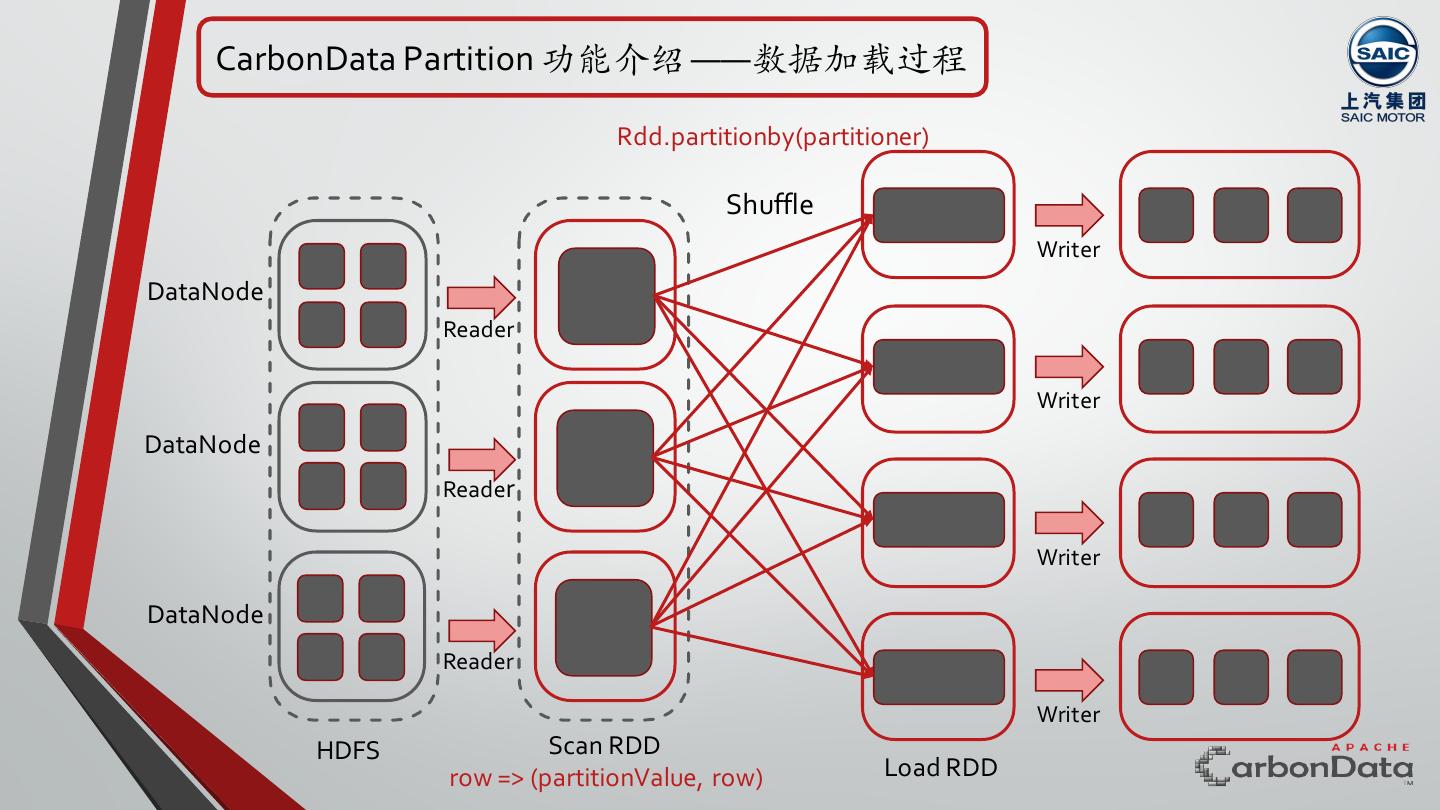
18 . CarbonData Partition 功能介绍 ——数据加载过程 Rdd.partitionby(partitioner) Shuffle Writer DataNode Reader Writer DataNode Reader Writer DataNode Reader Writer HDFS Scan RDD row => (partitionValue, row) Load RDD
19 .CarbonData Partition 功能介绍 ——查询过程 1. 根据SQL中的过滤条件=, <=, <, >, >=, in, not in以及表达式右值 确定命中的partitionId Example: 某表A以年龄为分区字段,创建range partition table 分区信息为(’range_info’ = ‘10, 20, 30, 40, 50, 60, 70, 80’) SQL过滤条件: age >= 20 and age < 40 得到命中的分区ID为3, 4 2. 如果有其他在排过序的维度列有过滤条件,则在driver端根据Btree索引 获取blocklet 所在的⽂件名,如没有则获取全部,再根据⽂件名中的 partitionId,筛选得到需要读取的⽂件,最后再下发spark task进⾏读取 Partition Id
20 . CarbonData Partition 功能介绍 —— Add Partition Syntax: ALTER TABLE [db_name].table_name ADD PARTITION('new_partition') Process: 1. 修改PartitionInfo 0 1 2 3 …... N Max 2. 读取默认分区(PartitionId为0)数据并根据新的 PartitionInfo重新导⼊数据 0 0 3. 删除旧的默认分区数据⽂件 Max 0 1 2 3 …... N Max
21 . CarbonData Partition 功能介绍 —— Split Partition Syntax: ALTER TABLE [db_name].table_name SPLIT PARTITION(partition_id) INTO('new_partition1', 'new_partition2'...) Process: 0 1 2 3 4 5 6 1. 修改PartitionInfo 0 1 2 7 8 4 5 6 Note:不能Split 0分区(默认分区)
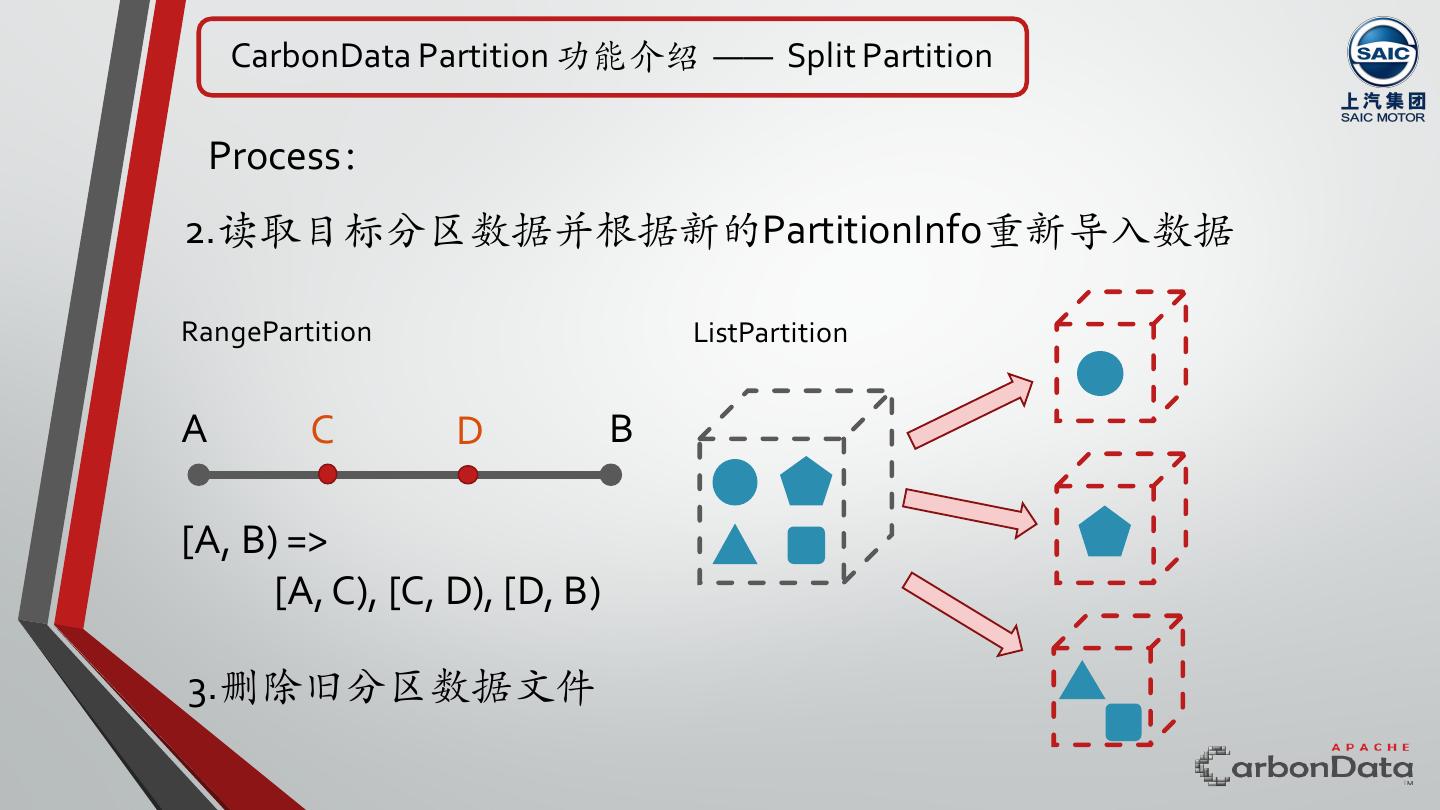
22 . CarbonData Partition 功能介绍 —— Split Partition Process: 2.读取目标分区数据并根据新的PartitionInfo重新导⼊数据 RangePartition ListPartition A C D B [A, B) => [A, C), [C, D), [D, B) 3.删除旧分区数据⽂件
23 . CarbonData Partition 功能介绍 —— Drop Partition Syntax: //Drop partition definition only and keep data ALTER TABLE [db_name].table_name DROP PARTITION(partition_id) //Drop both partition definition and data ALTER TABLE [db_name].table_name DROP PARTITION(partition_id) WITH DATA Process: 1. 修改PartitionInfo 0 1 2 3 4 5 6 0 1 2 3 4 5 6
24 . CarbonData Partition 功能介绍 —— Drop Partition Process: 2a. Drop Partition 但保留数据 —— RangePartition Drop最后⼀个partition 0 1 2 3 4 5 6 数据merge到default partiton 1 2 3 4 5 0 Drop非最后partition 0 1 2 3 4 5 6 数据merge到 next partition 0 1 2 5 6 4
25 . CarbonData Partition 功能介绍 —— Drop Partition Process: 2a. Drop Partition 但保留数据 —— ListPartition 数据merge到default partiton 0 1 2 3 4 5 6 1 2 3 5 6 0 2b. Drop Partition 不保留数据 0 1 2 3 4 5 6 0 1 2 4 5 6
26 .上汽集团CarbonData实践分享 集群环境:1台Spark client server 6台DataNode server 启用资源: 测试数据样本: spark-shell 荣威RX5 2017年1月1日~1月30日数据 --master yarn 每天3~5亿条,19~30G --deploy-mode client 30天共109亿条,约667G --num-executors 6 --driver-memory 10g --executor-memory 50g --executor-cores 5
27 . 上汽集团CarbonData实践分享 建表语句: CREATE TABLE IF NOT EXISTS rx5_carbon_partition_test( Id string, create_time timestamp, Field_C Int, Field_D String, … ... 共51个字段,其中绝⼤部分为维度 Field_XX ) PARTITIONED BY (create_time_hour int) STORED BY 'carbondata' TBLPROPERTIES('PARTITION_TYPE' = 'RANGE', 'RANGE_INFO' = '1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24', 'SORT_COLUMNS' = 'Id, Field_C, Field_D ')
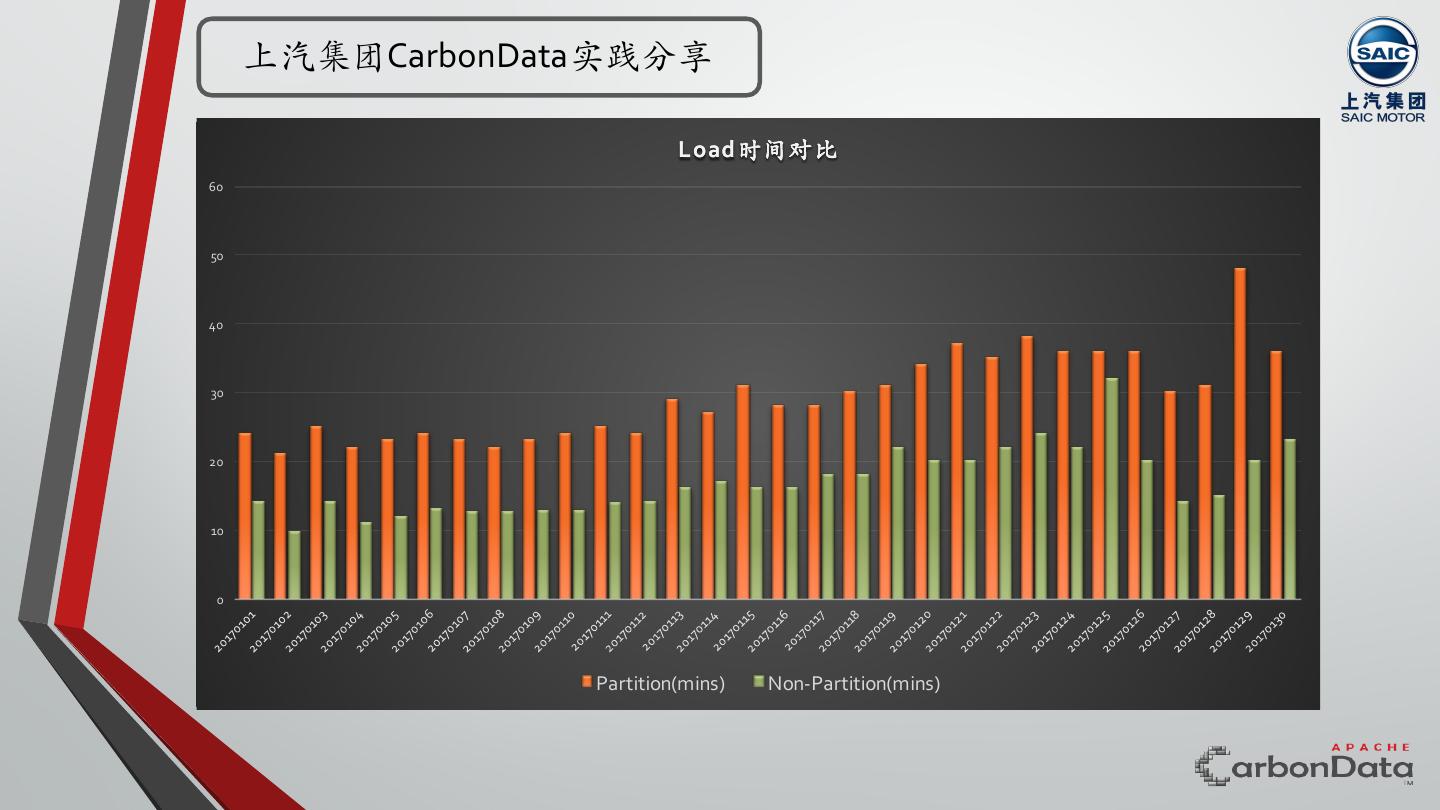
28 . 上汽集团CarbonData实践分享 Load时间对比 60 50 40 30 20 10 0 Partition(mins) Non-Partition(mins)
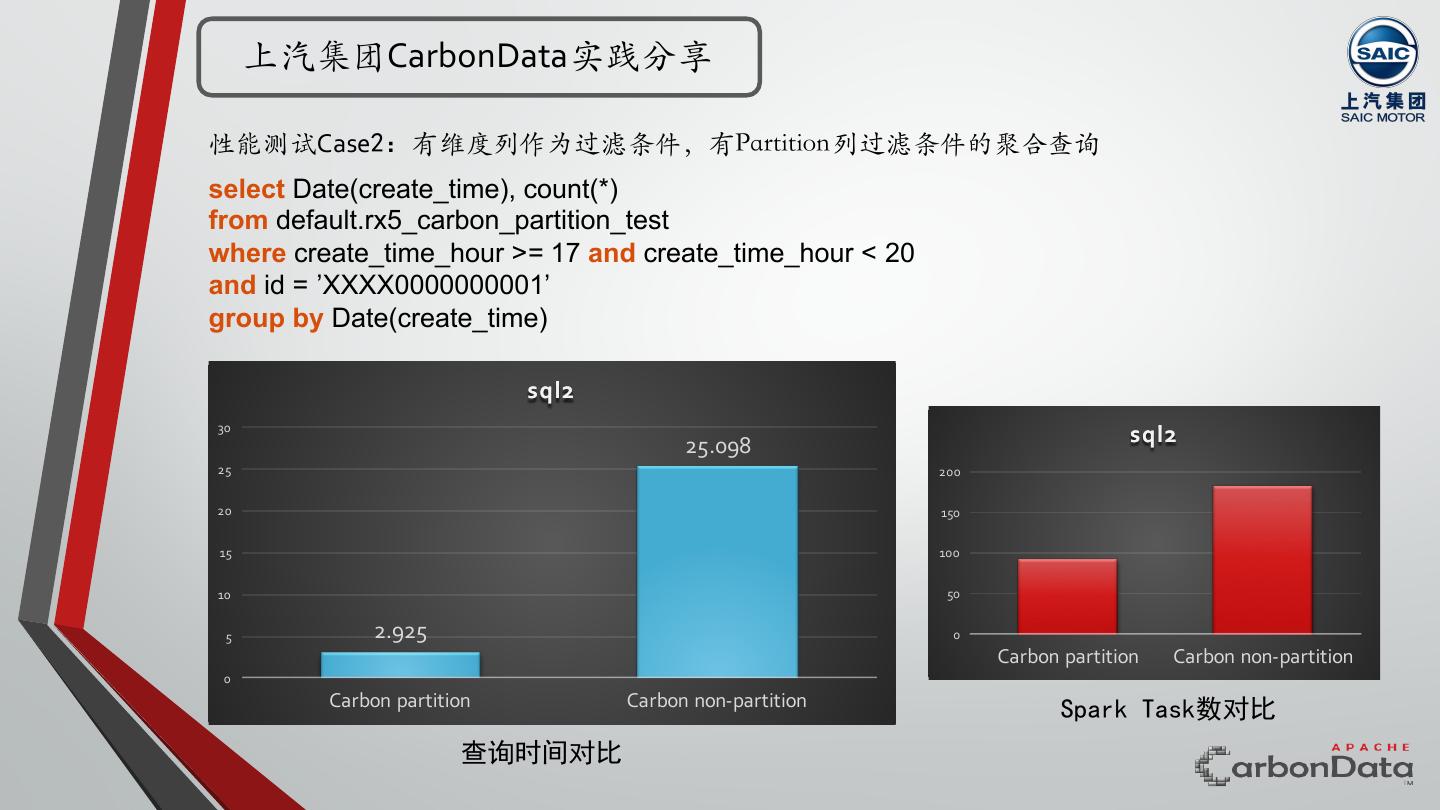
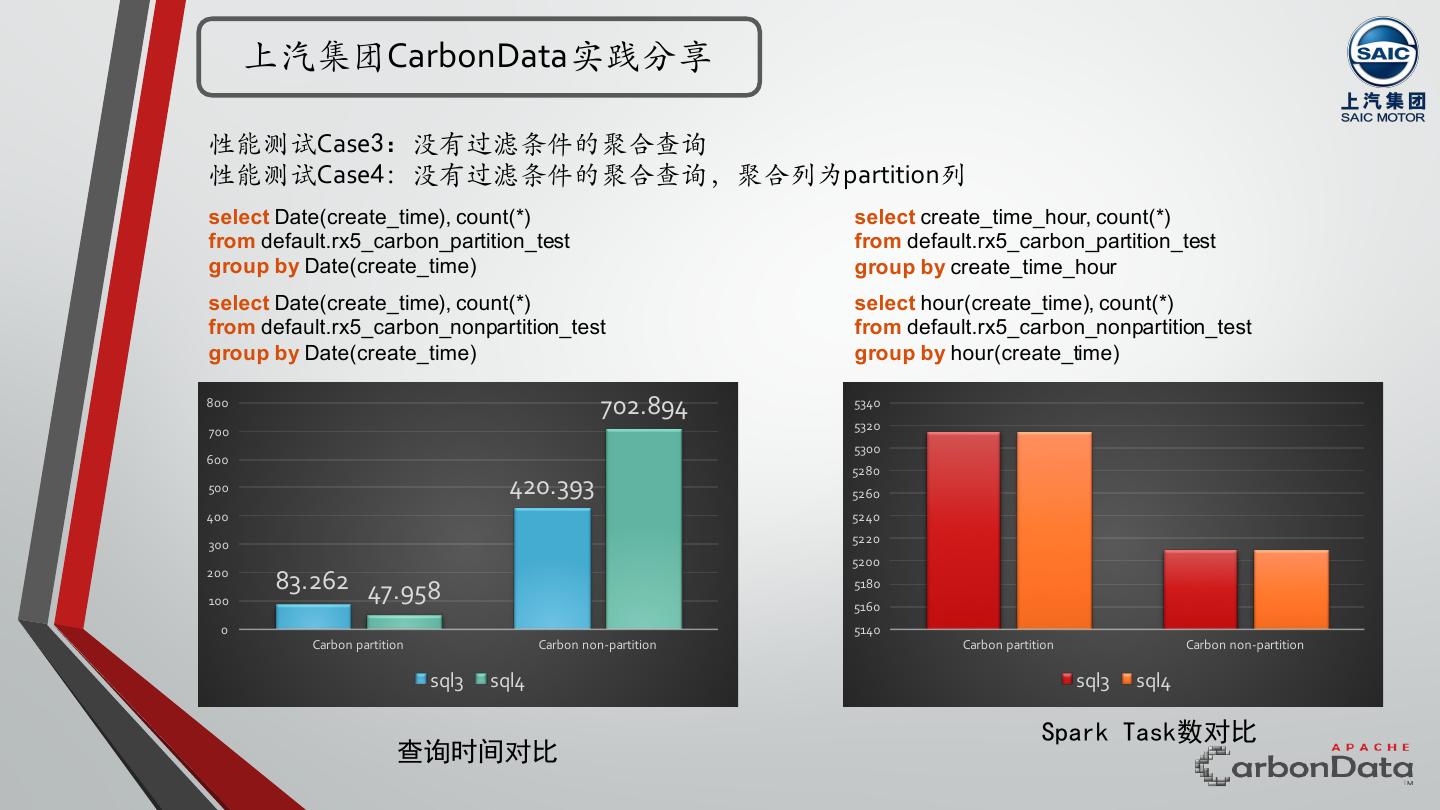
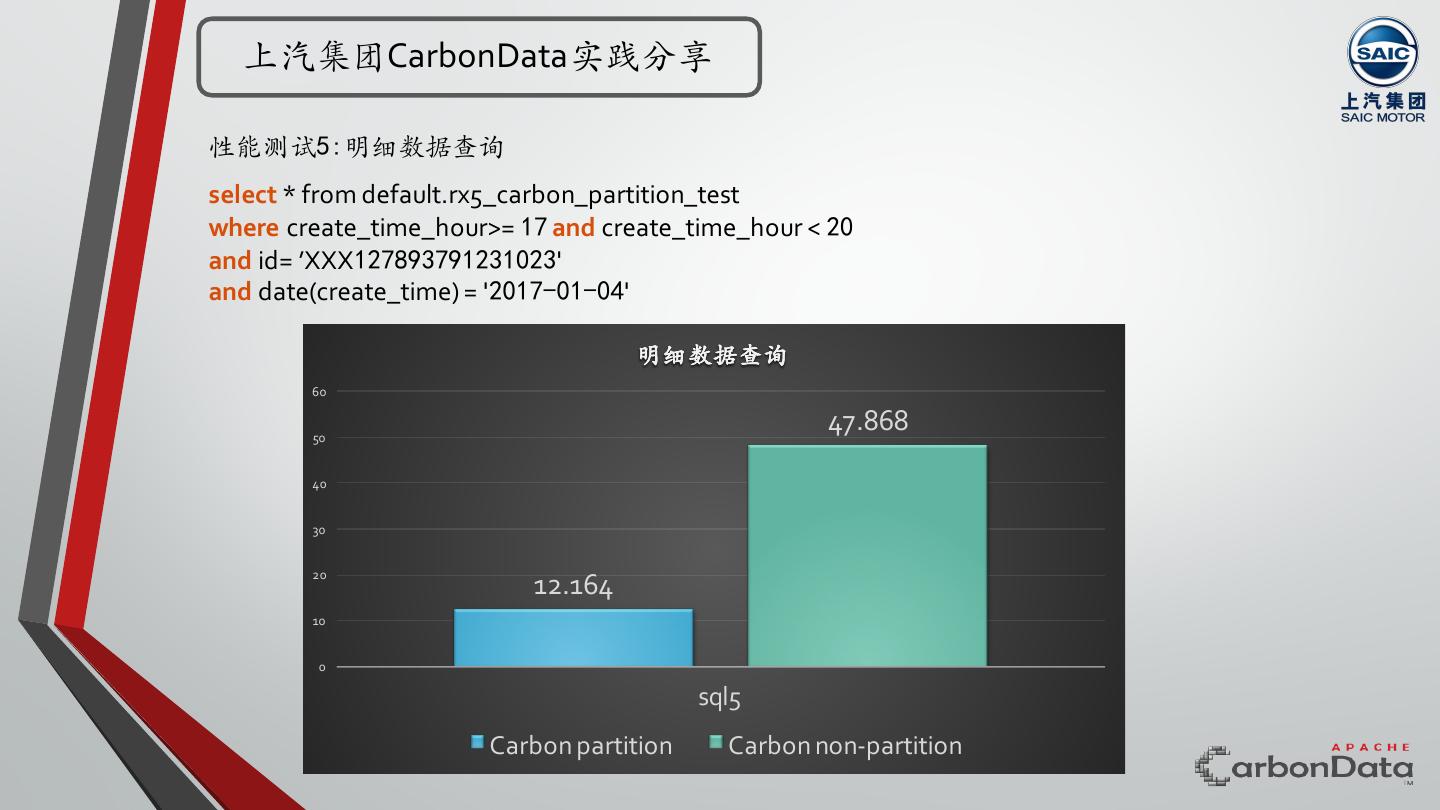
29 . 上汽集团CarbonData实践分享 性能测试Case1:⽆排序维度列作为过滤条件,有partition列上的范围过滤条件的聚合查询 select Date(create_time), count(distinct ID) from default.rx5_carbon_partition_test where create_time_hour >= 17 and create_time_hour < 20 ⽆法应用索引 group by Date(create_time) 或在索引中排序位置较为靠后 sql1 1200 1105.728 sql1 1000 6000 5208 5000 800 4000 600 3000 400 2000 969 1000 200 0 45.253 Carbon partition Carbon non-partition 0 Carbon partition Carbon non-partition Spark Task数对比 查询时间对比
3秒后跳转登录页面
去登陆

