




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache CarbonData OpenSource Journey of Becoming Top Level Proj
CarbonData从开源到Apache的顶级项目的历程,分析OLAP领域的应用场景,挑战以及CarbonData的核心技术和解决方案,Apache开源项目的角色和社区合作模式,以及CarbonData在开源社区的相关数据和未来发展路线图。
展开查看详情
1 .Apache CarbonData Open Source journey of becoming Top Level Project
2 .I am … raghunandan@apache.org Raghunandan S Chief Architect at Huawei’s India R&D centre’s BigData group • Heads of the technical team working on Bigdata technologies including Hadoop, Spark, HBase, CarbonData and ZooKeeper • Systems Group leader of the team which developed BI solution based on MOLAP • Project Manager of the CarbonData team with responsibility to cleanup, re-architect, Incubate into Apache and support till it reaches Top Level Project • Prior experience in NMS, Softswitch products
3 .Use cases & Challenges Unified Data Analytics CarbonData Technology & Solution OpenSourcing CarbonData CarbonData Roadmap
4 .Use Cases and Challenges Background of Huawei’s CarbonData project
5 .Data analysis use cases User behavior Report & Dashboard Fraud detection Network Graph analysis • 54B records per day • 750TB per month • Complex correlated Home automation data OLAP & Ad-hoc Consumer Failure Time series • 100 thousands of sensors detection analysis Data • >2 million events per second Batch processing • Time series, geospatial data Traffic analysis Geo spatial and Enterprise & Banking position analysis Real Time Analytics • 100 GB to TB per day • Data across different regions Advertising Textual Machine learning matching and analysis
6 .Big Data and Analytics Challenges Ø Data Size Ø Reporting • Single Table >10 billion rows § Big Scan Ø Multi-dimensional § Distributed Compute • Wide table: > 100 dimensions Ø Searching Ø Rich of Detail • Located Scan • High cardinality (> 1 billion) • Isolated Compute • 1B terminal * 200K cell / minute Ø AI Ø Real Time • Iterative Scan • Time Series streaming data • Iterative Compute TXT 6 5 4 3 Data Warehouse Document store 2 1 Data stores 0 Input 2015201620172018 No-SQL HO Query Analysis T COLD Processing Sources Time series Storage database ETL pipelines Real time • Multiple Stores for specific analysis • Complex data pipe lines and high maintenance cost
7 .Unified Data Analytics Solution for data silos; data redundancy; Multiple use cases
8 .Unified data analytics Unified data analysis and Unified storage format What is Apache CarbonData? 6 35 5 30 4 25 20 Query Processing 3 15 2 10 5 1 0 (History + Real time) 0 8 8 8 8 8 1 1 1 1 1 20 20 20 20 20 15 16 17 18 5/ 6/ 7/ 8/ 9/ 20 20 20 20 1/ 1/ 1/ 1/ 1/ Analysis 5 4 Real time data 3 2 1 0 ER HI AI E AD R N YD EL O AB EN AL D H G C N BA H Data maps Data CarbonData format Indexes Indexes Store in CarbonData format and Analyze on need basis.
9 .CarbonData Solution Technology, Features, Design adopted for Unified Storage
10 . CarbonData Solution & Features AI Reporting Searching Unified Fast: Construct multi-dimension Faster: Based on fast Efficient data compression: Concurrent data import: Storage indexes intelligent scanning dictionary encoding Spark parallel task Fast Query Execution Multi level Index High Scalability • Filters based on Multi-level Indexes • Supports Multi– • Storage and processing • Columnar format dimensional Btree separated • Query processing on dictionary • Min-max and inverted • Suitable for cloud encoded values. indexes Data consistency Insert - Update - Delete External Indexes for ACID • Support bulk Insert, Update, Optimizations • No intermediate data on failures Deletes • Supported for every operation on data • External Indexes like (Query, IUD, Indexes, Data maps, Lucene for text Streaming) 0II00010II000 Real time + History data • MV Data maps for 0I00I0110 • real time and history data into same aggregate tables, time Decoupled Storage & Processing table series queries • Query can combine results • Query auto selects the • Data in CarbonDataFormat automatically required data map • Processing in Distributed frameworks • Auto handoff to columnar format
11 .CarbonData use cases in production Largest Deployment Cluster:178 machines, 1368 • Bank cores, 5550 GB Mem – Fraud detection Data Size:3 PB, 10+ trillion rows – Risk analysis Scenario: Half year of telecom data in one state Response Time (% of 200B records) Cluster: 70 machines, 1120 cores • Telco 500% Data: 200 to 1000 Billion Rows, 80 columns 450% – Churn Analysis Carbon Table Index built on c1~c8 400% 350% – VIP Care Workload: 300% Q1: filter (c1~c4), select * 250% 200% • Monitoring Q2: filter (c1,c5), big result set 150% Q3: filter (c3) 100% – IOV 50% Q4: filter (c1) and aggregate 0% – Unusual Human behavior analysis Q5: full scan aggregate 200B 400B 600B 800B 1000B Q1 Q2 Q3 Q4 Q5 • Internet Observation – Video access analysis – Device size; resolution When data grows: – Server loads l Index is efficient to reduce response time: Q1, Q3 l When selectivity is low or full scan, query response time is linear: Q2, Q5 l Spark compute time scale linearly: Q4
12 .Open Sourcing CarbonData Motivation, Corporate Process, Preparation
13 .Why to Open Source CarbonData • Build CarbonData as a standard and unified data format/storage • The data does not have lock-in, customer is assured of security problem • Build the CarbonData ecosystem • Improve the influence of open source • Improve development efficiency • Contribute back • Embrace Open Source culture to benefit each other
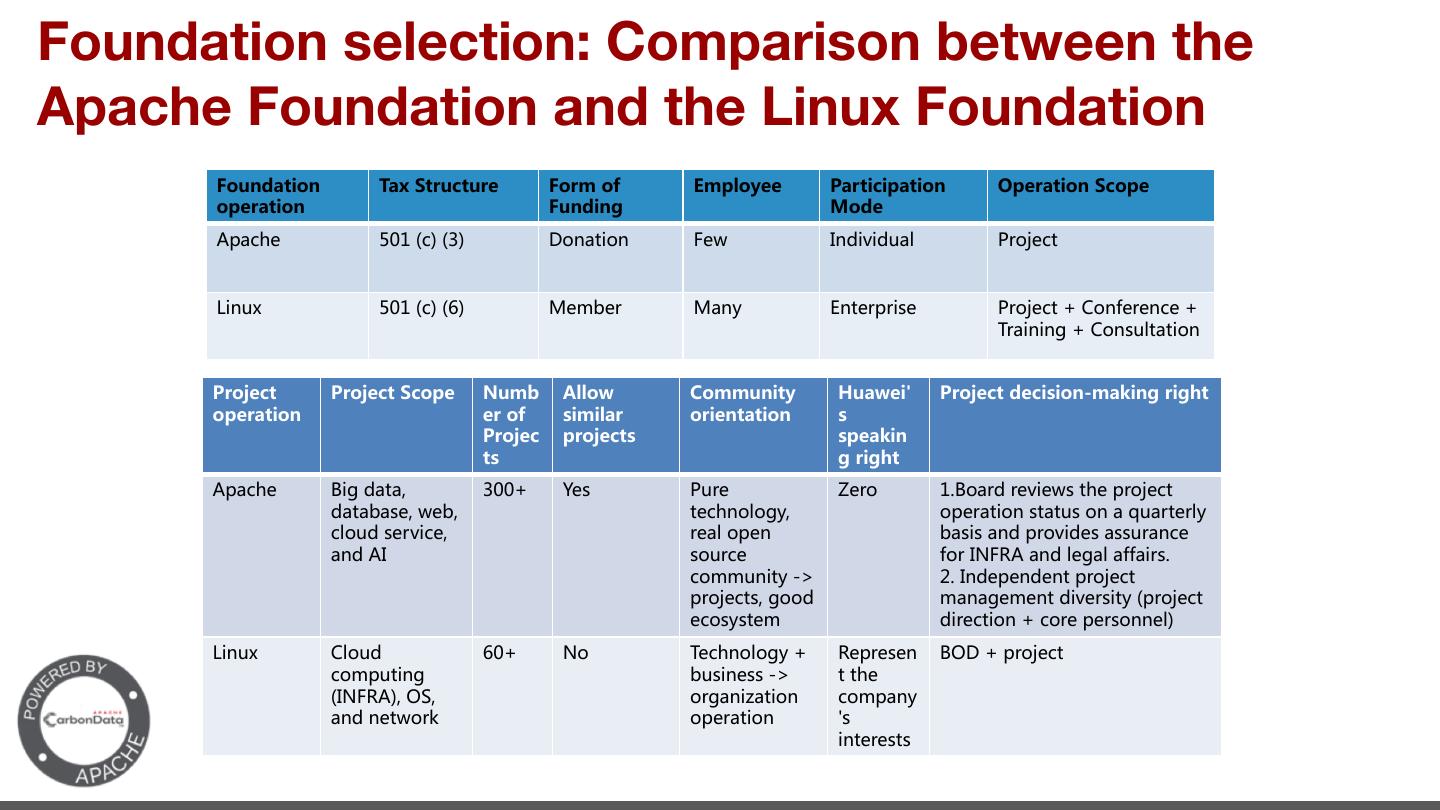
14 .Foundation selection: Comparison between the Apache Foundation and the Linux Foundation ' - -- - ' - - - B ' -I NCI 0 >CPC>O F 5LID N 1C OR ' ( 2 L 2 S . N L LCM 5LID N ,I L L C C A ,I MOFN NCI - - ' - - - - - - - - - - B +CA > N M 5OL LI +I L> L PC M NB LID N > N M N B IFIAS I L NCI MN NOM I O LN LFS FIO> M LPC L FI MCM > LIPC> M MMOL > 0 MIOL IL 03 6 >F A F CLM I O CNS ) 0 > > N LID N LID NM AII> A N >CP LMCNS LID N IMSMN >CL NCI IL LMI F 1C OR ,FIO> ( 3I B IFIAS 6 L M + - LID N I ONC A OMC MM ) N NB 03 6 ILA CT NCI I S > N ILE I L NCI M C N L MNM
15 .Apache Roles Ø Users q Those who want to use the software Ø Contributors q Those who contribute to development of project; Including documentation, Test, promotions, …. Ø Committers q Those who can merge the code into the repository Ø Project Management Committee q vote for releases q Represent project to Apache board q Elect new Committers / PMC members q Ensure project is following Apache ways Ø Apache Members q Caretakers of the Apache foundation q Play Champion roles for new Projects; Guide Incubating projects to Top Level Project q Be Shepherds for projects Ø Apache Board q Board of 9 members governing the foundation
16 .Apache Way of Development 1 Meritocracy 2 Community & No-Affiliation 3 Consensus & Respect for developers 4 Collaborative development 5 Open, Transparent & Pragmatic Ideas borrowed from Shane CurCuru’s slides and webpage
17 . Meritocracy • The more you do, the more you earn • Recognition for what you do and not what you are Everybody wants you https://www.learningexperiences.org/ Glamour.com https://www.huffingtonpost.com/
18 .Community & No-Affiliation • Great communities can create better code • Long living • Many Minds. Better Security
19 . Consensus • Decision by Consensus; Not Majority or BDFL • Everybody has a stake. Feel involved; committed • Voting only for formal consensus recording
20 . Respect for Developers • All are equal; No insults; Every opinion counts and weighted equal • Opportunity to learn • Learning to listen to different perspectives https://www.cbc.ca/ http://www.quora.com http://www.codeandcircuit.org/
21 . Collaborative Development • All discussions open; Discussion in mailing lists; Equal representation • Opinion of multiple people cannot go wrong • Different minds thinking various aspects from different perspective • Right priority to topics http://www.pretzellogic.org https://www.agilesparks.com https://www.accreditedschoolsonline.org
22 . Pragmatic • Roadmap, milestones are transparent and agreed upon • No favoring to anyone • Free to use, customize and sell • Practical decisions based on known knowledge
23 .Open Sourcing CarbonData Execution
24 .OpenSourcing CarbonData Incubation Stages to reach Top Project Period Preparation Background • Incubation work v Report the project maturity to Apache on a regular basis. • Proposal v Activeness of the project v Identify Champion v Plan releases at regular intervals v Identify Mentors v Encourage outside contributors & Community Building • Legal affairs v Submit Proposal Users v Identify the brand name v Select the foundation • Write technical Blogs • Attend Meetups and Development present • Benchmark and showcase • Clean up code; refactor APIs • Encourage external • Make it as open as possible contributors • Remove dependency on non- • Accept external Infrastructure setup apache projects requirements and Team Activities • Revisit design documents suggestions • Start writing wiki, user guide • Invite all to attend the • Setup project on github • Add extensive examples weekly call and • Setup JIRA, mailing list • Release every 1.5 to 2 months participate Roles • Setup test framework, Automation • Test driven development • Setup Release CI • All discussions in mailing list • Identify future committers and weekly conference calls • Session for contributors on Apache roles & working way
25 . Global Collaboration • Architecture USA Feature • Design Discussion in Mailing list • Industry Trends Use cases from around the world CarbonData India Decision by Consensus Community • Design Release & voting • Development All Collaborative China • Releases Public Development • Test • Community Incremental design • Design development proposal JIRA for all • Use cases changes • Community development All roles represented Before Open Sourcing CarbonData After Open Sourcing CarbonData
26 . Images from: True Popular Global Community Gettyimages.com Dreamstime.com Biletall.com Contributors from many countries in the world Use English as the only communication language Users from many continents Very Active mailing list with over 60000+ replies More than 130+ contributors in very short time HBase has 200 contributors Hadoop has 145 contributors
27 . Roadmap Releases, road Ahead, usage in Huawei Public Cloud
28 . Release milestones, Features Jun-2018 Aug-2016 Jan-2017 Sep-2017 • Query Performance improvements • Indexed Columnar • Kettle Dependency • Presto support • Compaction performance Store on HDFS removal • Sort columns improvements • Integration with • Spark 2.1 support configuration • Data loading performance Apache Spark • IUD support for Spark 1.6 • Partition support improvements • Bulk load support • Adaptive compression • Datamaps • SDK support • V2 Format of CarbonData • IUD support for Spark 2.1 • Streaming on pre-agg , partitioned • Vectorized readers • Dynamic property tables • Off-heap memory support configuration • MV support • Single Pass loading • RLE codec support • Bloom filter • Compaction performance • Write to S3 support 0.1.0- 0.1.1- 0.2.0- 1.0.0- 1.1.0 1.1.1 1.2.0 1.3.0 1.3.1 1.4.0 1.4.1 incubating incubating incubating incubating Nov-2016 May-2017 Feb-2018 Aug-2018 • MR support • CarbonData V3 format • Spark 2.2.1 support • Local Dictionary support • Spark DataFrame support • Alter Table • Streaming • Query performance • Configurable block size • Range Filter • Pre-aggregate tables improvements • Performance Improvements • Large cluster optimizations • CTAS • Custom compaction • Code refactoring • Code refactoring • Support varchar • Performance improvements • Code refactoring • Read from S3 support • Hadoop 2.8.3 support Oct-2018 • Spark 2.3.2 support • Hadoop 3.1.1 support • C++ reader through SDK 1.5.0 • StreamingSQL from Kafka • Data Summary Tool • Better Avro compliance with more datatypes • Adaptive encoding for all numeric columns • LightWeight integration with Spark(fileformat)
29 .Road Ahead Towards Objectives / Goals In near future Ø Unify CarbonData for more use cases Ø DataMaps and MVs to strengthen more use Ø Performance enhancements cases (GeoSpatial, Graph, Rtrees, Time Ø Broader ecosystem Integration Series) Ø Auto tuning storage Ø Easy Data Maintenance Ø In-Memory Caching Ø Compliance to Spark Data Source V2 Ø Continuous Streaming Ø Improve cloud storage performance Ø More encodings Ø ML SQL
3秒后跳转登录页面
去登陆

