展开查看详情
2 .Integrating Apache Pulsar
with Big Data Ecosystem
Yijie Shen
20190817
�
3 .Data analytics with Apache Pulsar
�
4 .Why so many analytic frameworks ?
Each kind has its • Streaming
best fit
Don’t ask, I don’t know.
•
Ever running
• jobs
• Interactive Engine • Time critical
•
• Time critical
• Need scalability as well as
resilient on failures
• Medium data size
• Rerun on failure
• Serverless
•
• Batch Engine • Simple processing logic
•
• Processing data with high
• The amount of data can be velocity
very large
• Could run on a huge
�
5 .Why Apache Pulsar fits all ?
It’s a Pulsar Meetup, dude...
�
6 .Pulsar – A cloud-native architecture
Stateless Serving
Durable Storage
�
7 .Pulsar – Segment-based storage
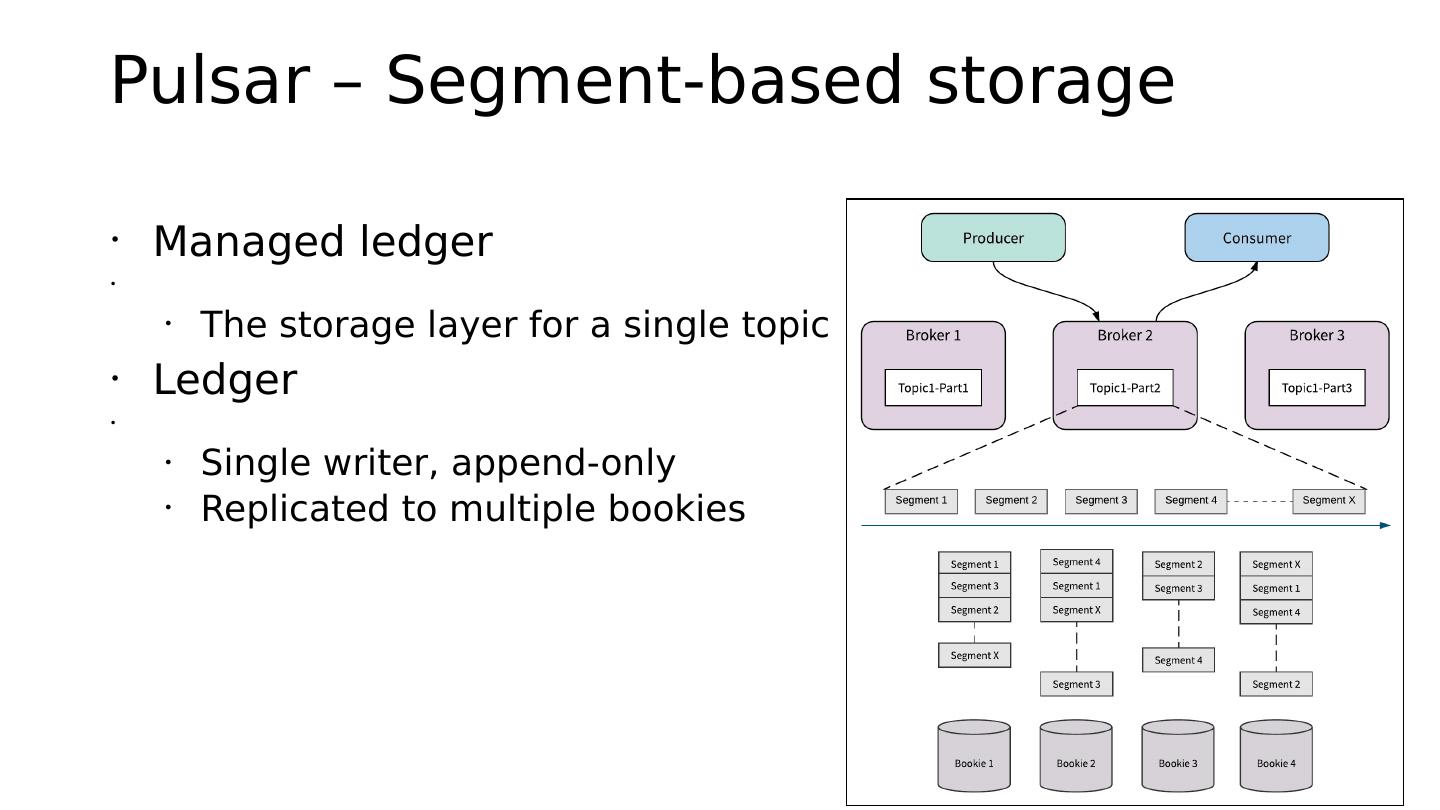
• Managed ledger
•
• The storage layer for a single topic
• Ledger
•
• Single writer, append-only
• Replicated to multiple bookies
�
8 .Pulsar – Infinite stream storage
• Reduce storage cost
•
• offloading segment to tiered storage one-by-one
�
9 .Pulsar Schema
• Consensus of data at server-side
•
• Built-in schema registry
• Data schema on a per-topic basis
• Send and receive typed message directly
•
• Validation
• Multi-version
�
10 .Durable and ordered source
• Failures are inevitable for engines
• Re-schedule failed tasks
•
• Tasks assigned to fixed (start, end] in Spark
• Tasks recover from checkpoint (start in Flink
• Exactly-once
•
task1 task2
• Based on message order in topic
• Seek & read
• Messages ”keep-alive” by subscription
•
Durable cursor
• Move sub cursor on commit
�
11 .Two levels of reading API
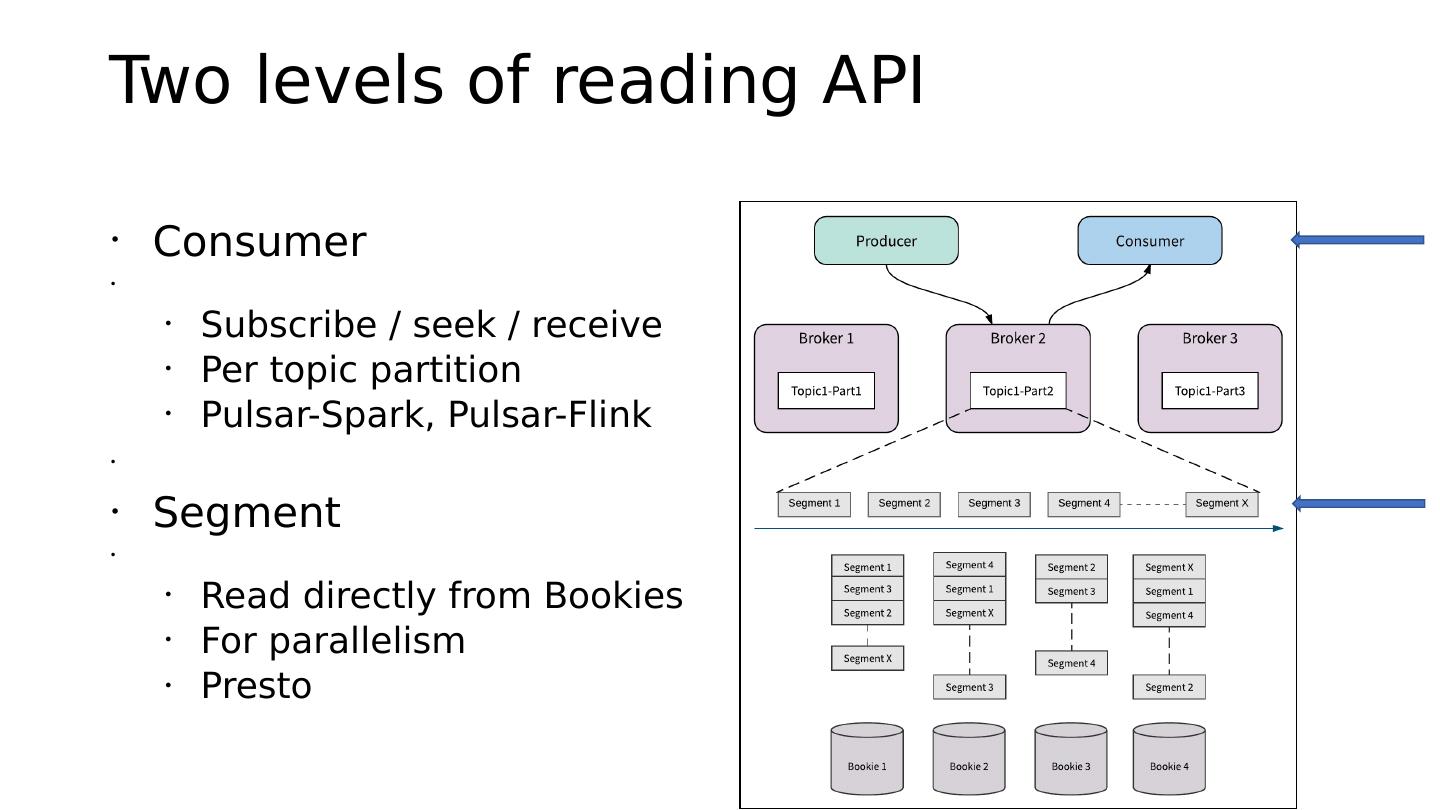
• Consumer
•
• Subscribe / seek / receive
• Per topic partition
• Pulsar-Spark, Pulsar-Flink
•
• Segment
•
• Read directly from Bookies
• For parallelism
• Presto
�
12 .Processing typed records
•
Regard Pulsar as structured storage
•
Fetching schema as the first step
•
•
With Pulsar Admin API
•
Dynamic / multi-versioned schema not supported in
Spark/Flink
•
But you could try AUTO_CONSUME
•
SerDe your messages into InternalRow / Row
•
•
Avro schema and avro/json/protobuf Message
•
Or parse the Avro record as we do in pulsar-spark[1]
•
Message metadata as metadata fields
•
•
__key, __publishTime, __eventTime, __messageId, __topic
�
13 .Topic/Partition add/delete discovery
Offset {
topicOffsets: Map[String, Message
•
Streaming jobs are long }
running
•
Topics & partitions may be Pulsar-Spark as an example
added on removed during a
•
job
•
Happens during logical
planning
•
Periodically check topic for •
getBatch(start:
status Option[Offset], end: Offset)
• •
•
Spark: during incremental •
Discovery topic differences
planning between start and end
•
•
Flink: with a monitoring •
Start – last end
thread in each task •
End – getOffset()
•
Connector
•
•
provide available offset for all
topic/partitions for each
�
14 . Various APIs use Pulsar as source
Spark Presto
val df = spark .read .format("pulsar")
.option("service.url", "pulsar://...") show tables in pulsar."public/default";
.option("admin.url", "http://...") select * from
.option("topic", "topic1") .load() pulsar."public/default".generator_test;
Flink val prop = new Properties()prop.setProperty(“service.url”,
serviceUrl)prop.setProperty(“admin.url”, adminUrl)
prop.setProperty(“partitionDiscoveryIntervalMillis”, "5000")
prop.setProperty(“startingOffsets”, "earliest")
env.addSource(new FlinkPulsarSource(sourceProps))
�
15 .Pulsar-Spark and Pulsar-Flink
• Pulsar-Spark based on Spark 2.4 is now open sourced
• https://github.com/streamnative/pulsar-spark
• Pulsar-Flink based on Flink 1.9 will open-source soon
•
• Roadmaps for these two projects
•
• End-to-end exactly once with pulsar transaction support
• Fine-grained batch parallelism on segment level
•
• Pulsar-spark / Pulsar-flink
�