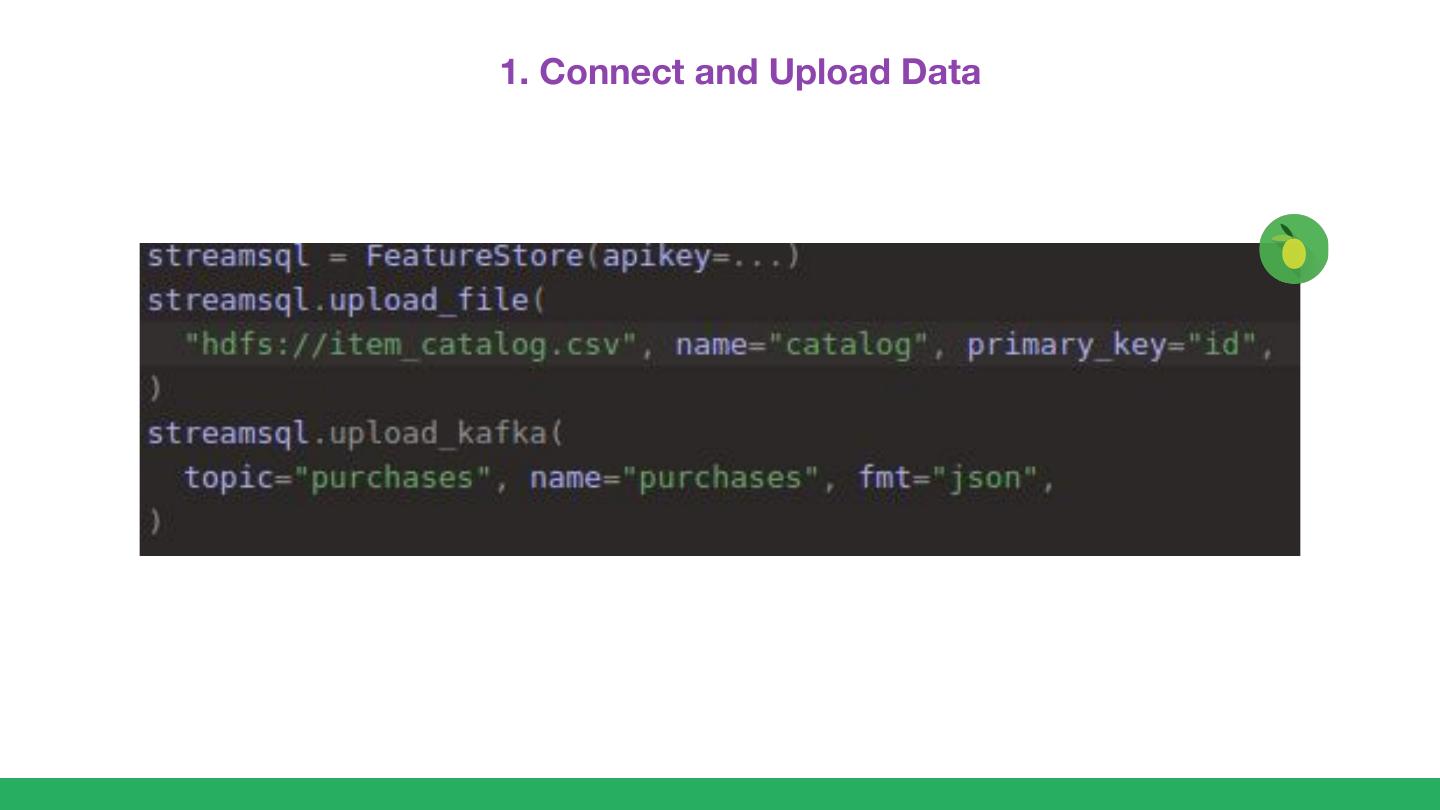
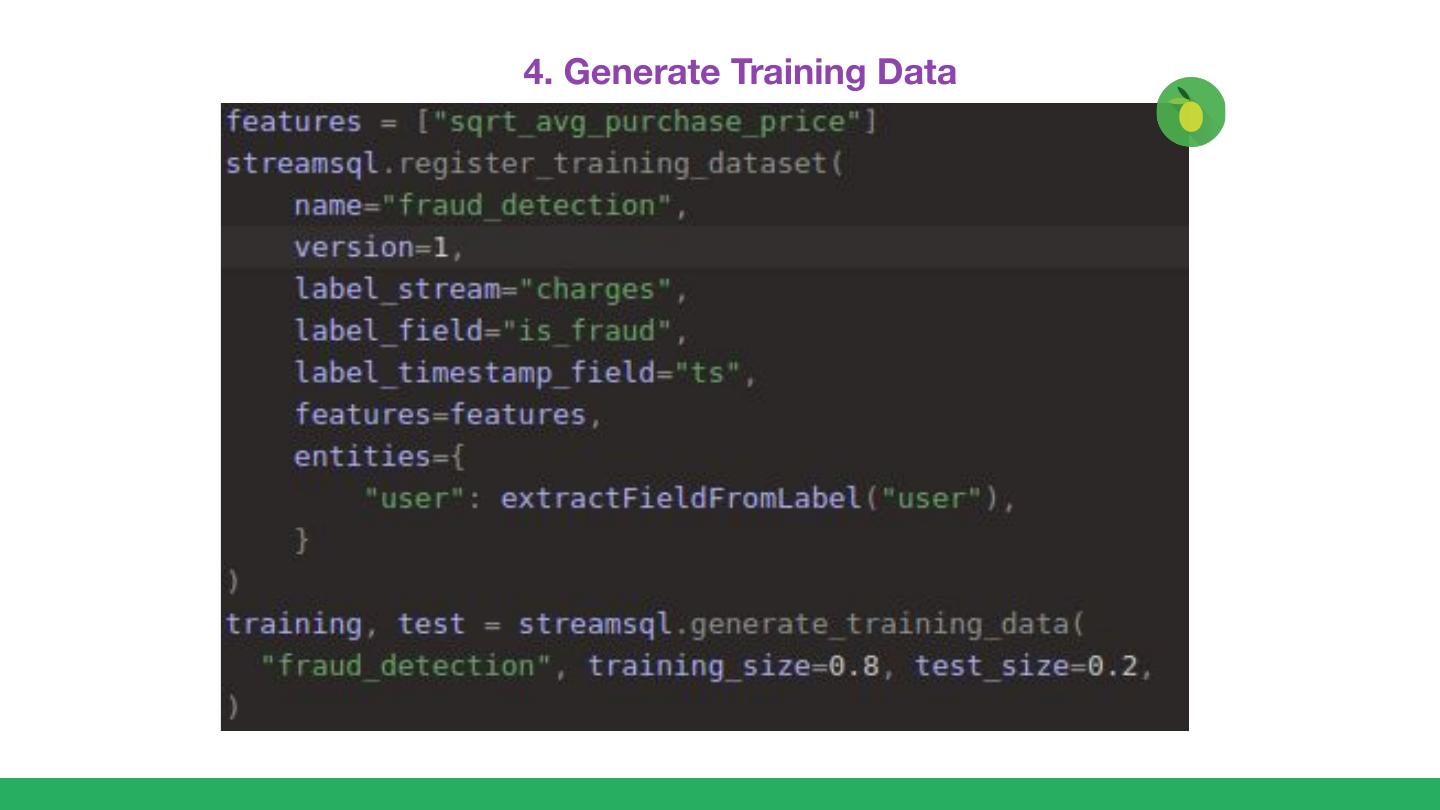
展开查看详情
1 . Feature Stores
Building ML Infrastructure on Apache Pulsar
�
2 . Simba Khadder
Co-Founder & CEO
StreamSQL.io
Using Apache Pulsar to power our feature store for
>100m MAU
�
3 .Agenda
● The ML process
● Moving our ML Pipelines w/ Pulsar
● Building a Feature Store on top of Pulsar
● Q&A
�
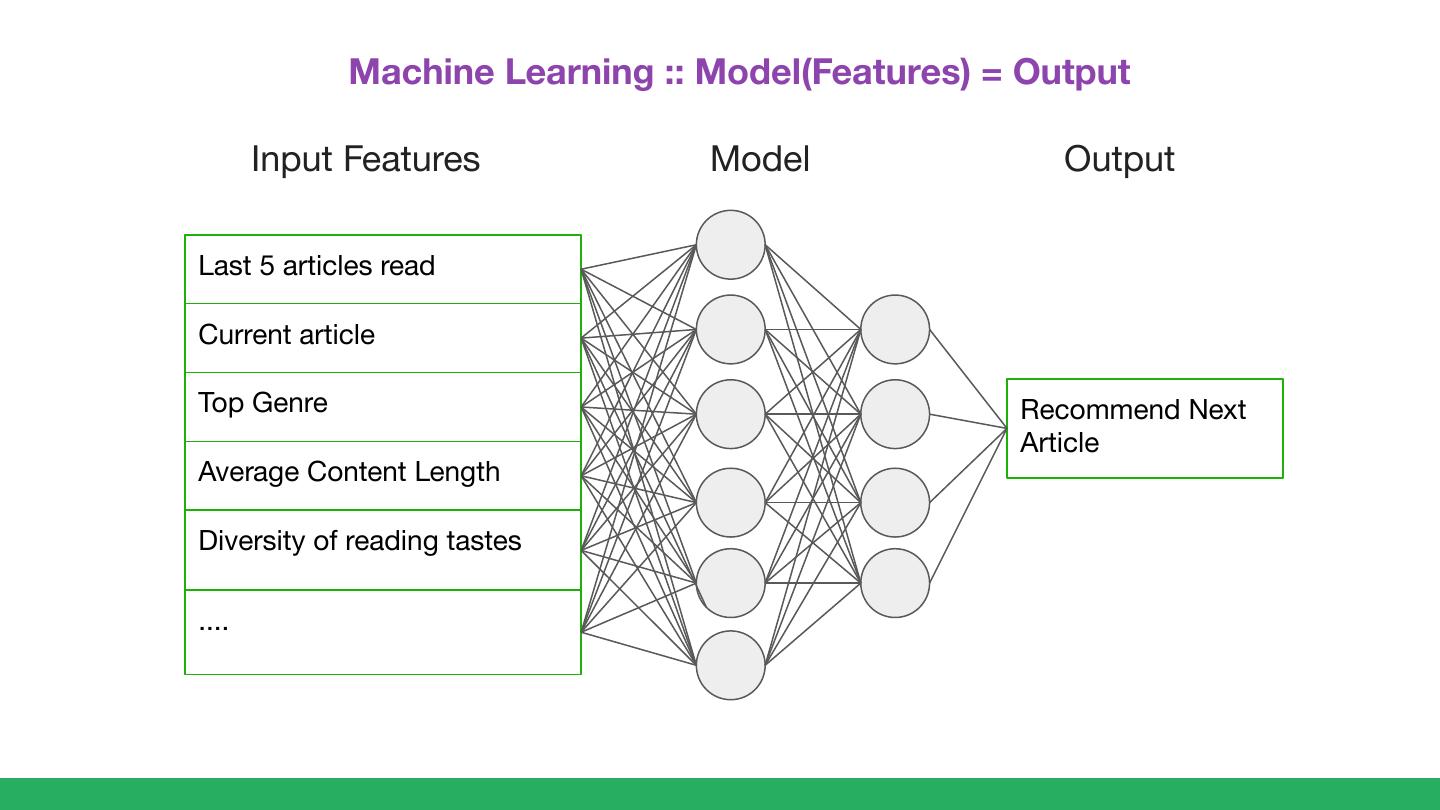
4 . Machine Learning :: Model(Features) = Output
Input Features Model Output
Last 5 articles read
Current article
Top Genre Recommend Next
Article
Average Content Length
Diversity of reading tastes
....
�
5 .Feature Engineering > Model Research*
�
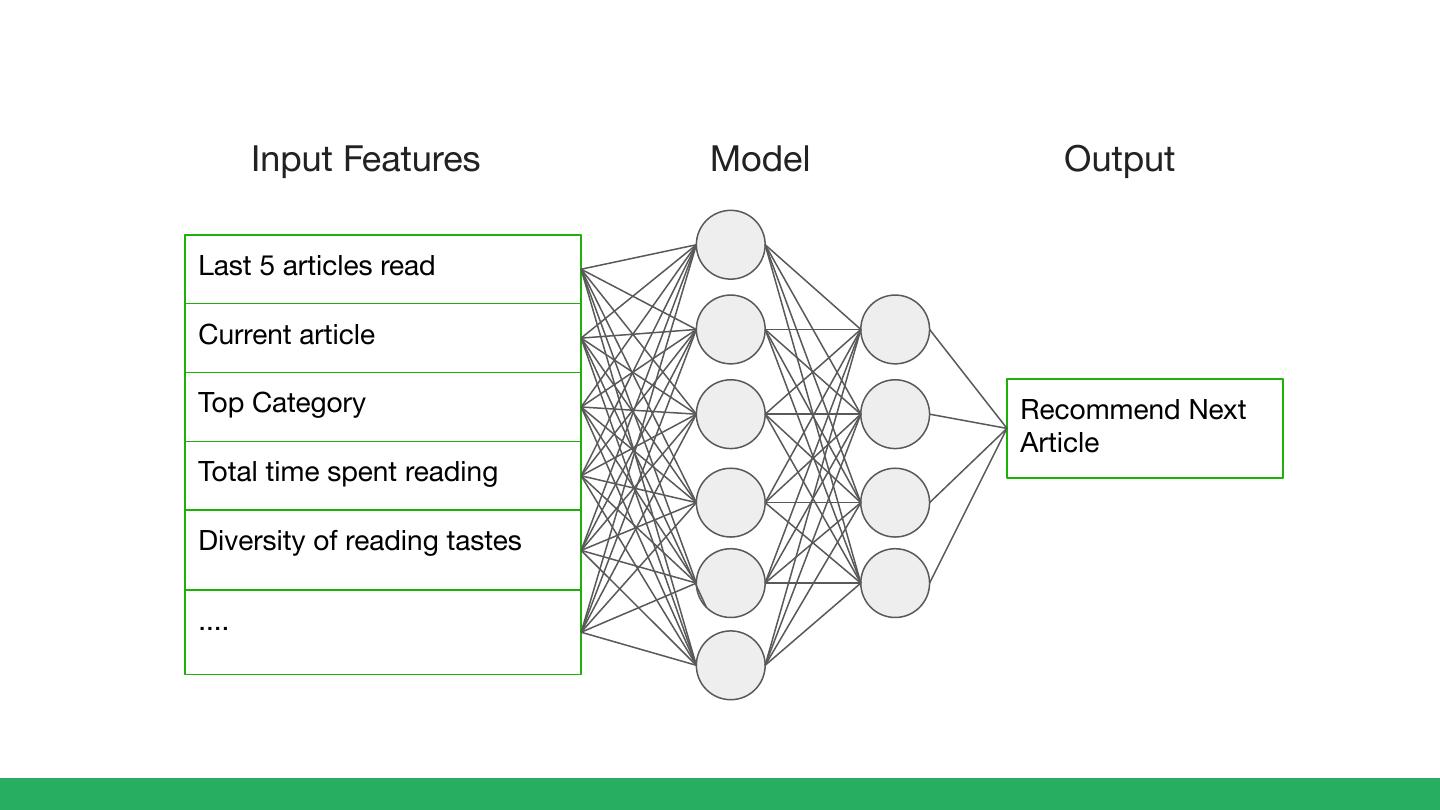
6 . Behind every great model is a set of great features
Input Features Model Output
Last 5 articles read
Current article
Top Category Recommend Next
Article
Total time spent reading
Diversity of reading tastes
....
�
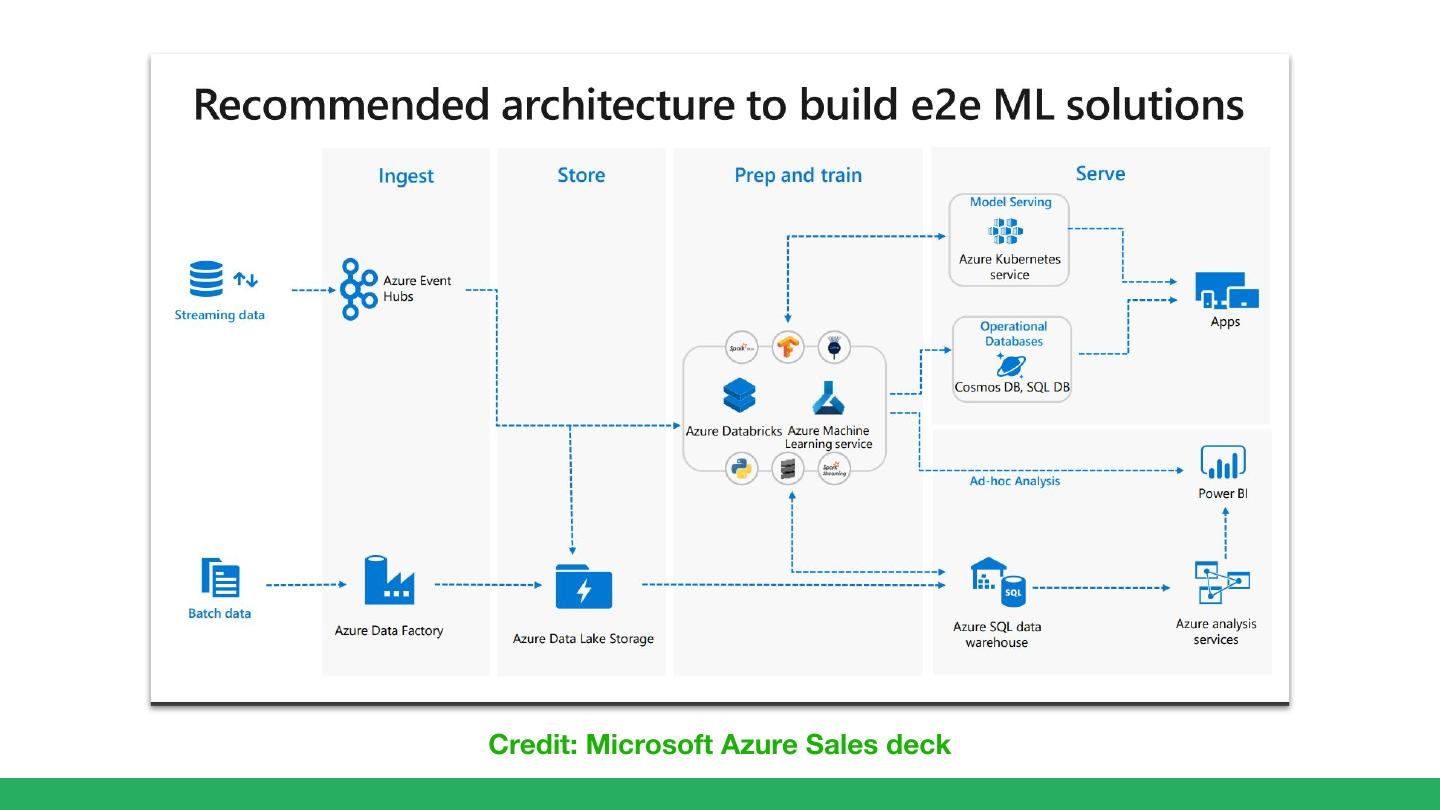
8 .Credit: Microsoft Azure Sales deck
�
9 .Our ML teams spent >80% of their time
building and maintaining ML pipelines for
feature generation and feature
engineering.
�
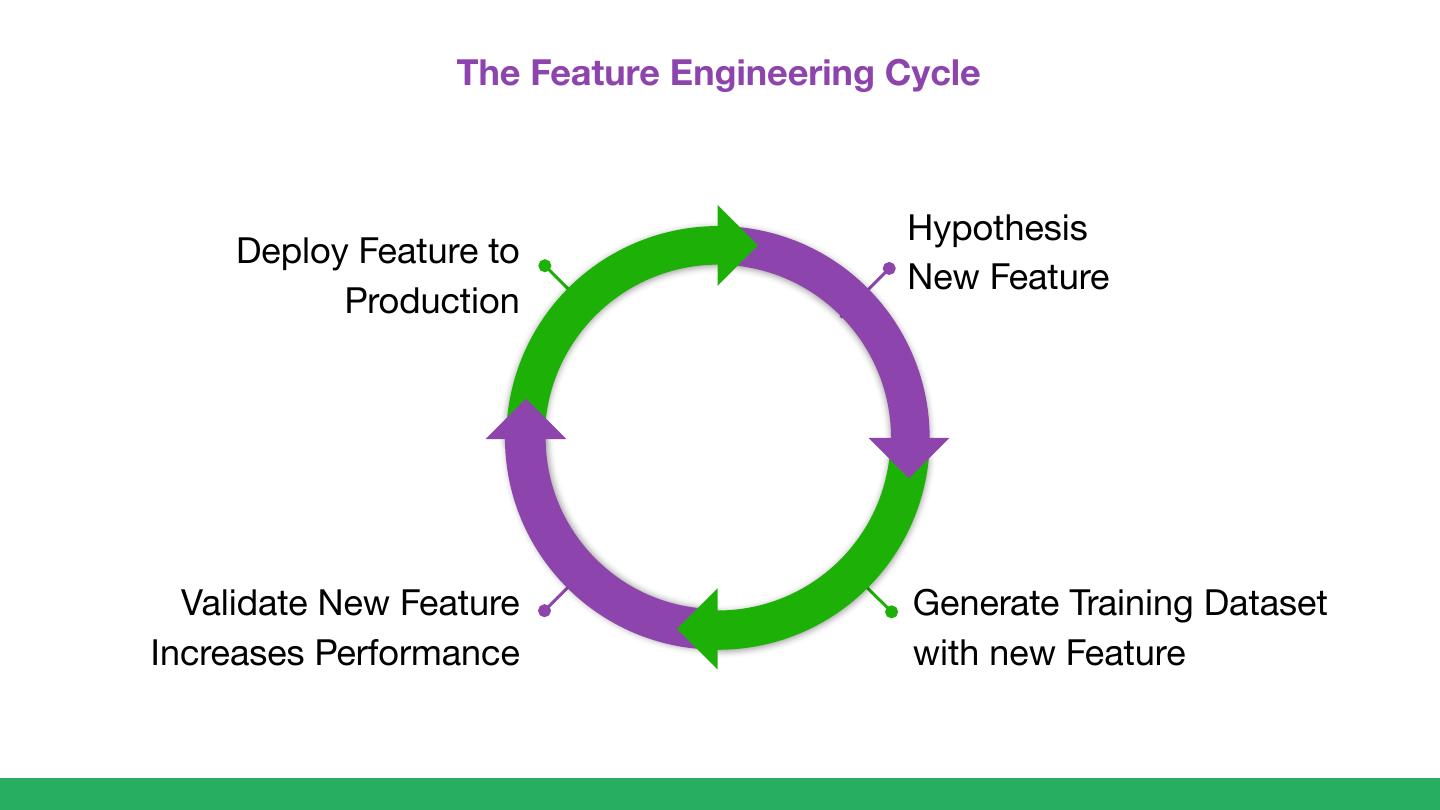
10 . The Feature Engineering Cycle
Hypothesis
Deploy Feature to
New Feature
Production
Validate New Feature Generate Training Dataset
Increases Performance with new Feature
�
11 .Online Features Serving
User ID
Feature Set
Training Data
Arr([FeatureSet, Actual])
Train
�
12 . Input Features Model Output
Last 5 articles read
Current article
Top Category Recommend Next
Article
Total time spent reading
Diversity of reading tastes
....
�
13 . Generating Point-in-Time Correct Training Data
Events Storage Training Data
Features at Features at Features at
timestamp timestamp timestamp
read read read
Time
�
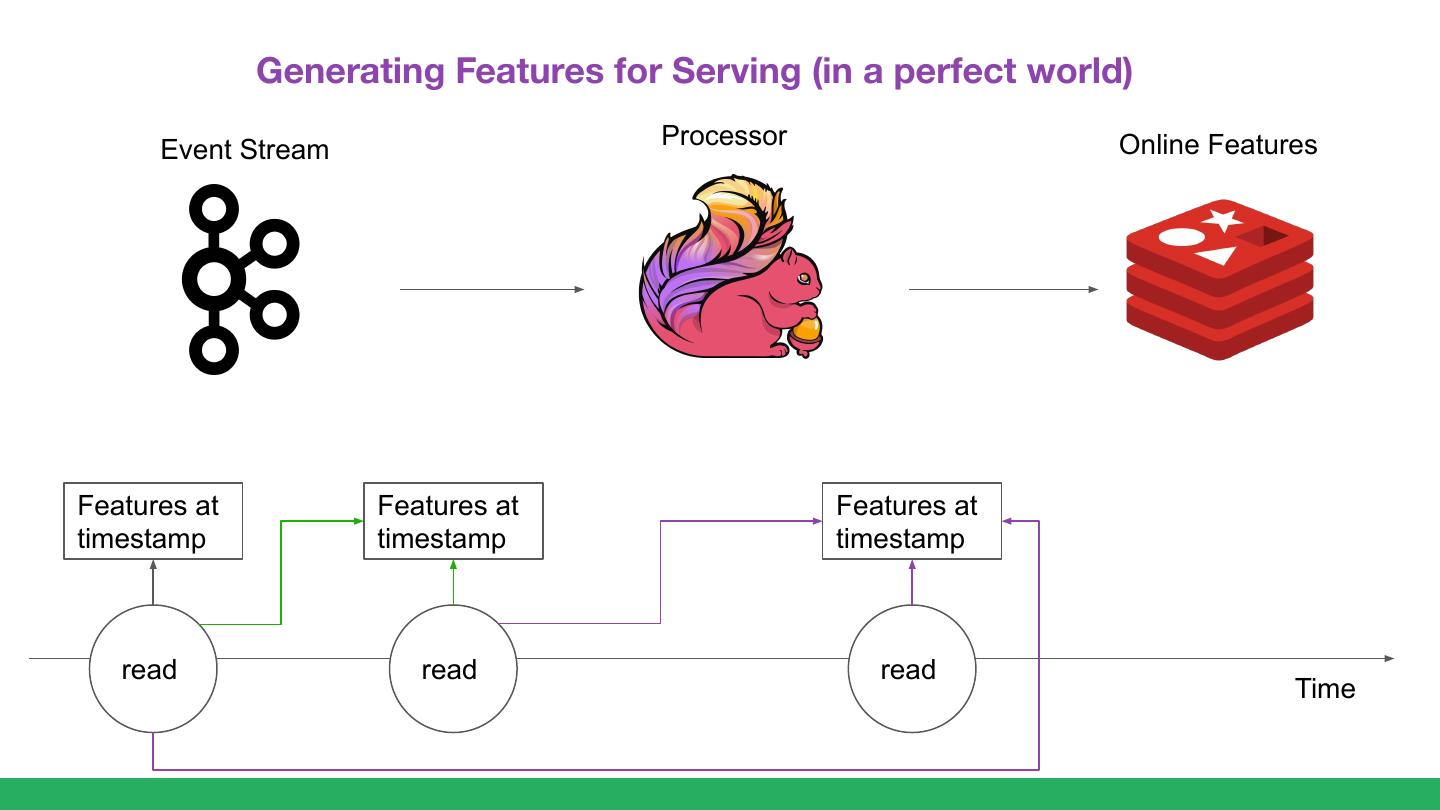
14 . Generating Features for Serving (in a perfect world)
Processor Online Features
Event Stream
Features at Features at Features at
timestamp timestamp timestamp
read read read
Time
�
15 . Most Features are Stateful
Input Features Model Output
Last 5 articles read
Current article
Top Category Recommend Next
Article
Total time spent reading
Diversity of reading tastes
....
�
16 . Stateful Features must be Bootstrapped
Input Features Model Output
Total time spent reading
�
17 . Bootstrapping Stateful Features with
Historical Data in S3
SELECT user, SUM(readtime) FROM read_events GROUP BY user;
�
18 . Time
Persisted in S3 Not in S3, but in Kafka
retention period
MsgID
�
19 . Finish bootstrapping & start
stream processing from Kafka
SELECT user, SUM(readtime) FROM read_events GROUP BY user;
�
20 .Full Feature Deployment Process
�
22 . Combine Batch & Stream Processing with an Immutable Ledger
● Each new event appends to the end of the ledger
● Cut at an arbitrary point, and the ledger looks like a
batch problem
● Only read from the head of the ledger and it looks
like streaming problem
�
23 .Pulsar Based Architecture with Infinite Retention
�
24 .Pulsar’s offloading makes Event-Sourcing achievable
�
25 .Pulsar’s Tiered Architecture enhances Processing on
Infinite Retention
�
26 .Feature are the building blocks of
ML models; however, they are
developed and maintained in
ad-hoc ways.
They lack a dedicated system of
management.
�
27 . ML Pipelines < Feature Stores
● No concrete feature definitions, feature logic is split
across Flink jobs.
● No feature versioning and rollback.
● No feature sharing, re-use, and discovery.
● No integrations into Tensorflow, Jupyter, etc.
�
28 .A Platform for features allows for teams to work together.
Features are easily defined, shared, and re-used.
There exists a single source of truth for features.
�
29 . Models across an organization may benefit from
some of these features.
Input Features Model Output
Last 5 articles read
Current article
Top Category Recommend Next
Article
Total time spent reading
Diversity of reading tastes
....
�