

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Ten reasons to choose Apache Pulsar over Apache Kafka for Event Sourcing (CQRS)——Robert van Mölk
展开查看详情
1 .Ten reasons to choose Apache Pulsar over Apache Kafka for Event Sourcing (CQRS)
2 .Who am I? Robert van Mölken Solution Architect / Developer Blockchain / IoT / Cloud Apps Groundbreaker Ambassador Linkedin: linkedin.com/in/rvmolken Author two books including: Blog: technology.vanmolken.nl Blockchain across Oracle Twitter: @robertvanmolken Ten reasons to choose Apache Pulsar 2
3 .Ten reasons to choose Apache Pulsar over Apache Kafka For Event Sourcing (CQRS) TOPICS TO COVER What is Event Sourcing and CQRS Common problems with Kafka-based projects Introducing our ‘friend’, Pulsar Reasons why Pulsar should be your #1 pick Apache Pulsar for Event Sourcing 3
4 .What is Event Sourcing and CQRS
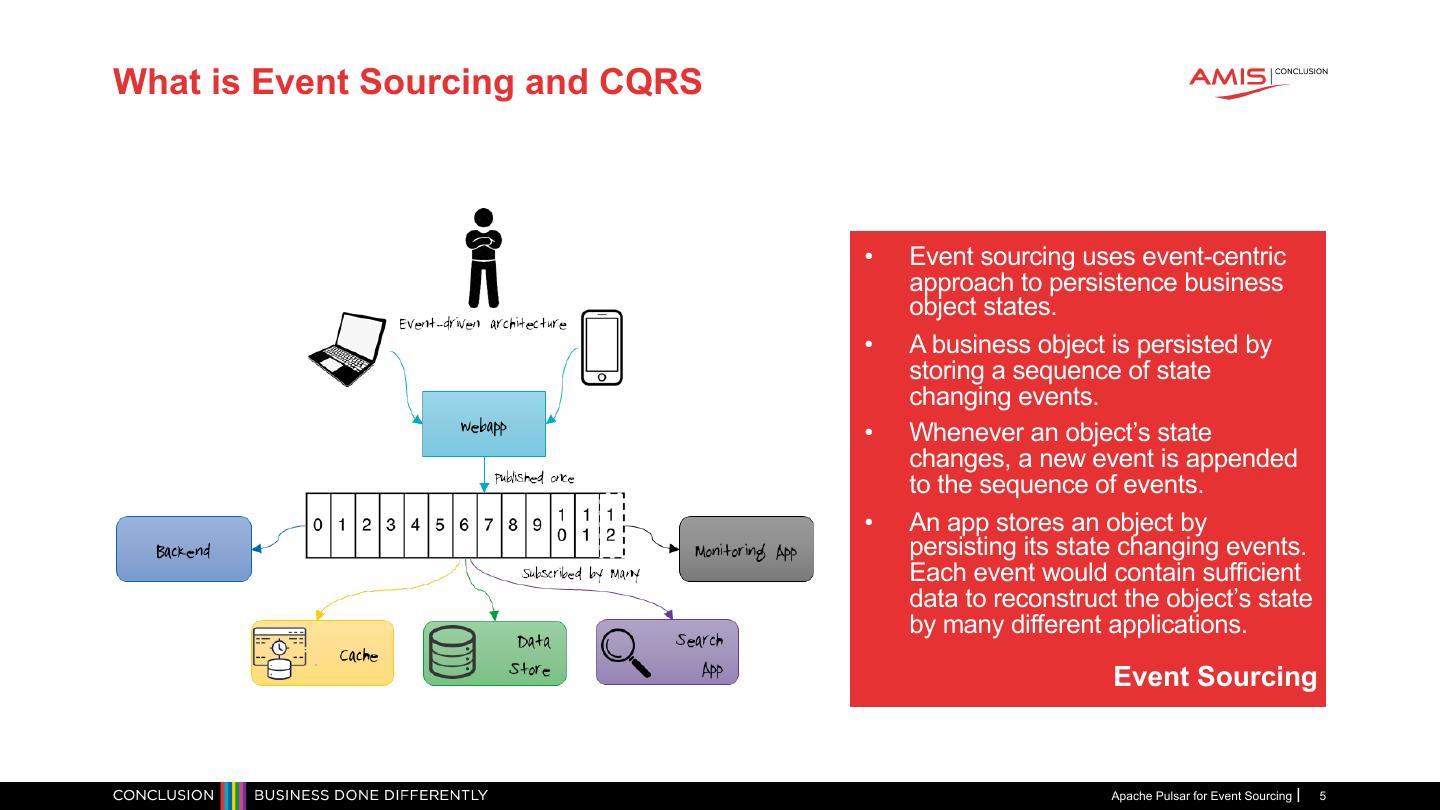
5 .What is Event Sourcing and CQRS • Event sourcing uses event-centric approach to persistence business object states. • A business object is persisted by storing a sequence of state changing events. • Whenever an object’s state changes, a new event is appended to the sequence of events. • An app stores an object by persisting its state changing events. Each event would contain sufficient data to reconstruct the object’s state by many different applications. Event Sourcing Apache Pulsar for Event Sourcing 5
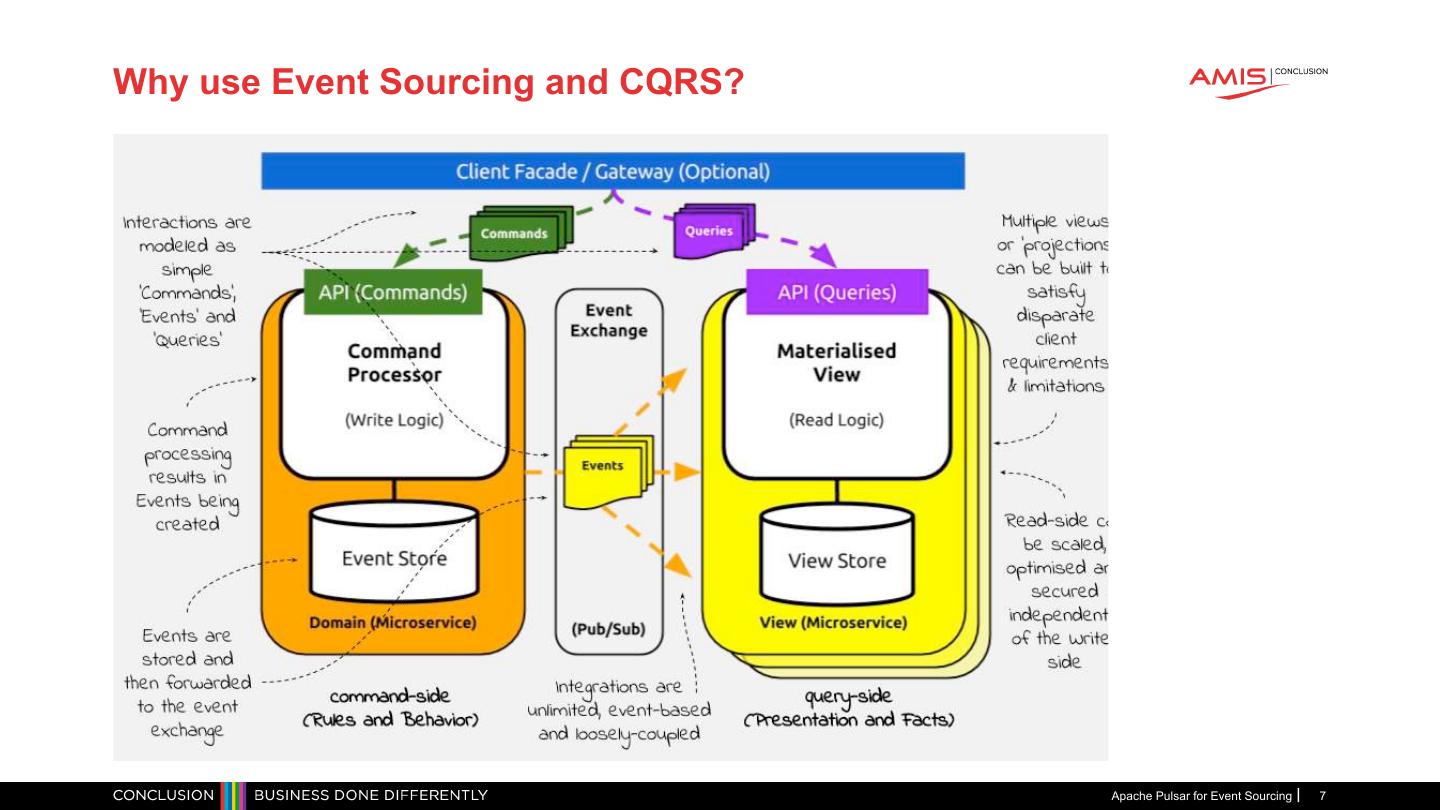
6 .What is Event Sourcing and CQRS (Cont.) Command and Query Responsibility Segregation • Architectural design pattern for developing software whereby writing and reading data are separate responsibilities • The bits of the system that are responsible for changing the system’s state are physically separated from the bits of the system that manage views • In constast, a traditional CRUD architecture is implemented by the same component • It has the responsibility for both reads (the views) and the writes (the state changes) CQRS Apache Pulsar for Event Sourcing 6
7 .Why use Event Sourcing and CQRS? Apache Pulsar for Event Sourcing 7
8 .Common problems with Kafka-based projects
9 .Common problems with Kafka-based projects Source: https://jack-vanlightly.com/sketches/2018/10/2/kafka-vs-pulsar-rebalancing-sketch Apache Pulsar for Event Sourcing 9
10 .Common problems with Kafka-based projects (Cont.) • Scaling Kafka is difficult due to the way Kafka stores data within the broker as distributed logs that stores as messaging persistence store • Changing partition sizes to allow more storage can mess the message order by conflicting the message indexes, but for CQRS order is most important • Must plan and calculate number of brokers, topics, partitions and replicas in first place to avoid scaling problems • Cluster rebalancing can impact performance of connected producers and consumers. Brokers must synchronize state from others that contain replicas of its partitions. • No native authorization on events/commands and no native event analyzer tool (you would for example need Apache Spark or Heron) • Kafka’s geo replication mechanism is notoriously problematic, even within just two data centers, resulting in delayed data delivery or complete loss of data Apache Pulsar for Event Sourcing 10
11 .Let’s talk about our “friend”, Pulsar Apache Pulsar for Event Sourcing 11
12 .What is Apache Pulsar? Apache Pulsar is an open source pub-sub messaging platform backed by durable storage (Apache Bookkeeper) with the following cool features: Apache Pulsar for Event Sourcing 12
13 .Apache Pulsar for Event Sourcing 13
14 .#1 Streaming and Queing come together Kafka Pulsar • Kafka is a event streaming platform (only) • Pulsar started as message queing platform, but can also handle high-rate • It implements the concept of topics real-time (event sourcing) use case • Pub/sub system, permanent storage, processing event streams, Avro message • It implements the concept of topics validation shema • Pub/sub, distributed + cold storage, event processing, and multiple message validation • Based on a distributed commit log schemas (incl. AVRO, JSON, raw) • Capable of handling trillions of events a day • And standard message queuing patterns • Competing consumers, fail-over subscriptions, and message fan out • Based on distributed legder / log segments Apache Pulsar for Event Sourcing 14
15 . #2 Logs versus distributed ledgers Kafka logs are append-only and sequential, so data can be written to and extracted from them quickly But simple logs can get you into trouble when they get large – storage, scale up / out, replication … Apache Pulsar for Event Sourcing 15
16 . #2 Logs versus distributed ledgers Pulsar avoids the problem of copying large logs by breaking the log into segments. It distributes those segments across multiple servers while the data is being written by using BookKeeper as its storage layer For event sourcing and CQRS it is important to distribute events quickly to all consumers even when loads get high! Apache Pulsar for Event Sourcing 16
17 .#2 Logs versus distributed ledgers Apache Pulsar for Event Sourcing 17
18 . #3 Tiered Storage (plus for Event Sourcing) With Pulsar tiered storage you can automatically push old messages into practically infinite, cheap cloud storage and retrieve them just like you do those newer, fresh messages For event sourcing it is important to be able to replay messages that already been consumed. For example when the application got an unexpected exception or you build a new application. So keeping then forever! Sounds great right? Apache Pulsar for Event Sourcing 18
19 .#3 Tiered Storage (plus for Event Sourcing) Plus for ES/CQRS: New tenants (bookkeepers) can easily sync data and consumers can easily get all events via same API without difference Apache Pulsar for Event Sourcing 19
20 .#4 Stateful vs Stateless brokers Kafka Pulsar • Kafka uses stateful brokers • Pulsar uses stateless brokers • Every broker contains the complete log for each • Pulsar holds state, but just not in the broker of its partitions. • Brokering of data is separated from storing • If a broker fails, the work can’t be taken over by • Brokers accept data (from producers) just any broker. Also when load is getting to high • Brokers send data (to consumers) • Data is separate stored in BookKeeper • Brokers must synchronize state from other brokers that contain replicas of its partitions. • If load gets high can easily add a new broker • No data to load so starts immediately • Syncing large logs takes time to distribute • Plus for ES/CQRS: always garantee data is available to consumer in real-time (in high load) Apache Pulsar for Event Sourcing 20
21 .#4 Stateful vs Stateless brokers Plus for ES/CQRS: Always garantee data is available to consumer in real-time (e.g. in high load) Source: https://www.xenonstack.com/ Apache Pulsar for Event Sourcing 21
22 . #5 Schema registry and message validation In Pulsar Type safety is paramount in communication between the producer and the consumer. For safety in messaging, pulsar adopted both client-side as server-side schema/message validation. For CQRS it is important that clients send only (known) commands that can be validated. Kafka only support message validation using AVRO schemas. Additionally, messages need to be encoded and decoded in code Apache Pulsar for Event Sourcing 22
23 .#5 Schema registry and message validation - how it works? • Pulsar schema is applied and enforced at the topic level. Producers and consumers upload schemas to pulsar are asked to conform to the following: • The Pulsar schema message consists of : { • Name: name is the topic to which the schema is applied. "name": "test-string-schema", • Type: the schema format "type": "STRING", • Schema: binary representation of the schema. "schema": "", "properties": {} • User-defined properties as a string/string map } • It supports the following schema payload formats in: • JSON • Protobuf • Avro • string (used for UTF-8-encoded lines) • raw bytes (if no schema is defined) Apache Pulsar for Event Sourcing 23
24 .5 more reasons to choice Pulsar Apache Pulsar for Event Sourcing 24
25 .Thanks for attending!
3秒后跳转登录页面
去登陆

