展开查看详情
1 .Query Pulsar Streams using Apache Flink
Sijie Guo (@sijieg)
�
2 .Who am I
❏ Apache Pulsar PMC Member
❏ Apache BookKeeper PMC Chair
❏ StreamNative Founder
❏ Ex-Twitter, Ex-Yahoo
❏ Interested in event streaming
technologies
�
3 .What is Apache Pulsar?
�
4 . “Flexible Pub/Sub Messaging
Backed by durable log storage”
�
5 .Highlights
❏ Multi-Tenant Data System: Isolation, ACL, Policies
❏ Unified messaging model: Queuing + Streaming
❏ Infinite Segmented Stream Storage: Segment-centric, Tiered storage
❏ Structured Event Streams: Built-in schema management
❏ Cloud-Native Architecture: Simplified ops, Rebalance-free
�
6 .A brief history of Apache Pulsar
❏ 2012: Pulsar idea started at Yahoo!
❏ 5+ years on production, 100+ applications, 10+ data centers
❏ 2016/09 Yahoo open sourced Pulsar
❏ 2017/06 Yahoo donated Pulsar to ASF
❏ 2018/09 Pulsar graduated as a Top-Level project
❏ 25+ committers, 168 contributors, 1000+ forks, 4200+ stars
❏ Yahoo!, Yahoo! Japan, Tencent, Zhaopin, THG, OVH, …
http://pulsar.apache.org/en/powered-by/
�
7 .Pulsar Use Cases
❏ Billing / Payment / Trading Service
❏ Worker Queue / Push Notifications / Task Queue
❏ Unified Messaging Backbone (Queuing + Streaming)
❏ IoT
❏ Unified Data Processing
�
8 .Pulsar at Tencent
❏ Billing Service (30+ billions)
❏ 500K QPS, 10 billions transaction requests
❏ 600+ Topics
�
9 .Pulsar Use Cases
❏ Billing / Payment / Trade Service
❏ Worker Queue / Push Notifications / Task Queue
❏ Unified Messaging Backbone (Queuing + Streaming)
❏ IoT
❏ Unified Data Processing
�
10 .Pulsar Use Cases
❏ Billing / Payment / Trade Service
❏ Worker Queue / Push Notifications / Task Queue
❏ Unified Messaging Backbone (Queuing + Streaming)
❏ IoT
❏ Unified Data Processing with Flink
�
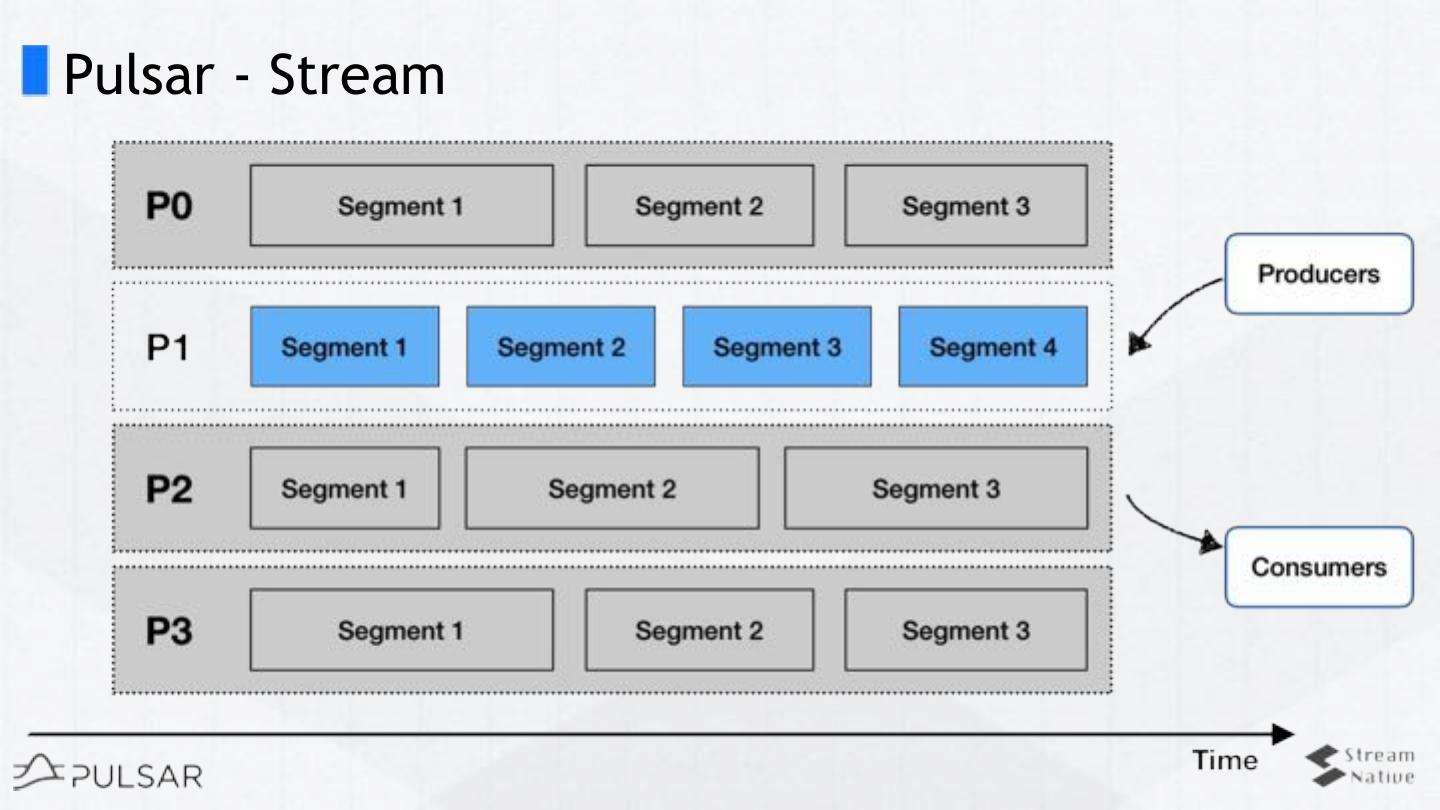
11 .A Pulsar view on data
Infinite segmented streams
(pub/sub + segment)
�
13 .Pulsar - Topic Partitions
�
16 .Pulsar - Infinite stream storage
�
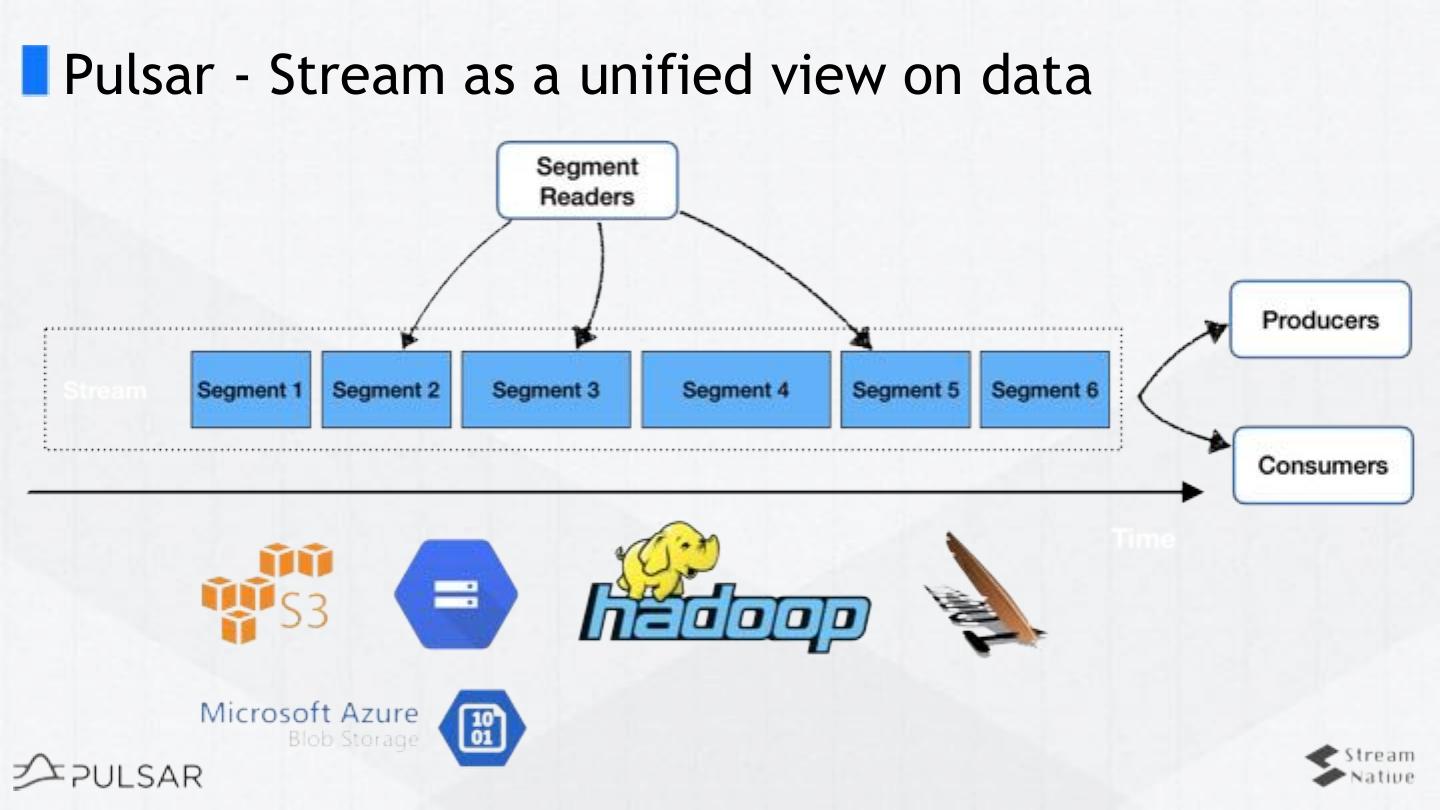
17 .Pulsar - Stream as a unified view on data
�
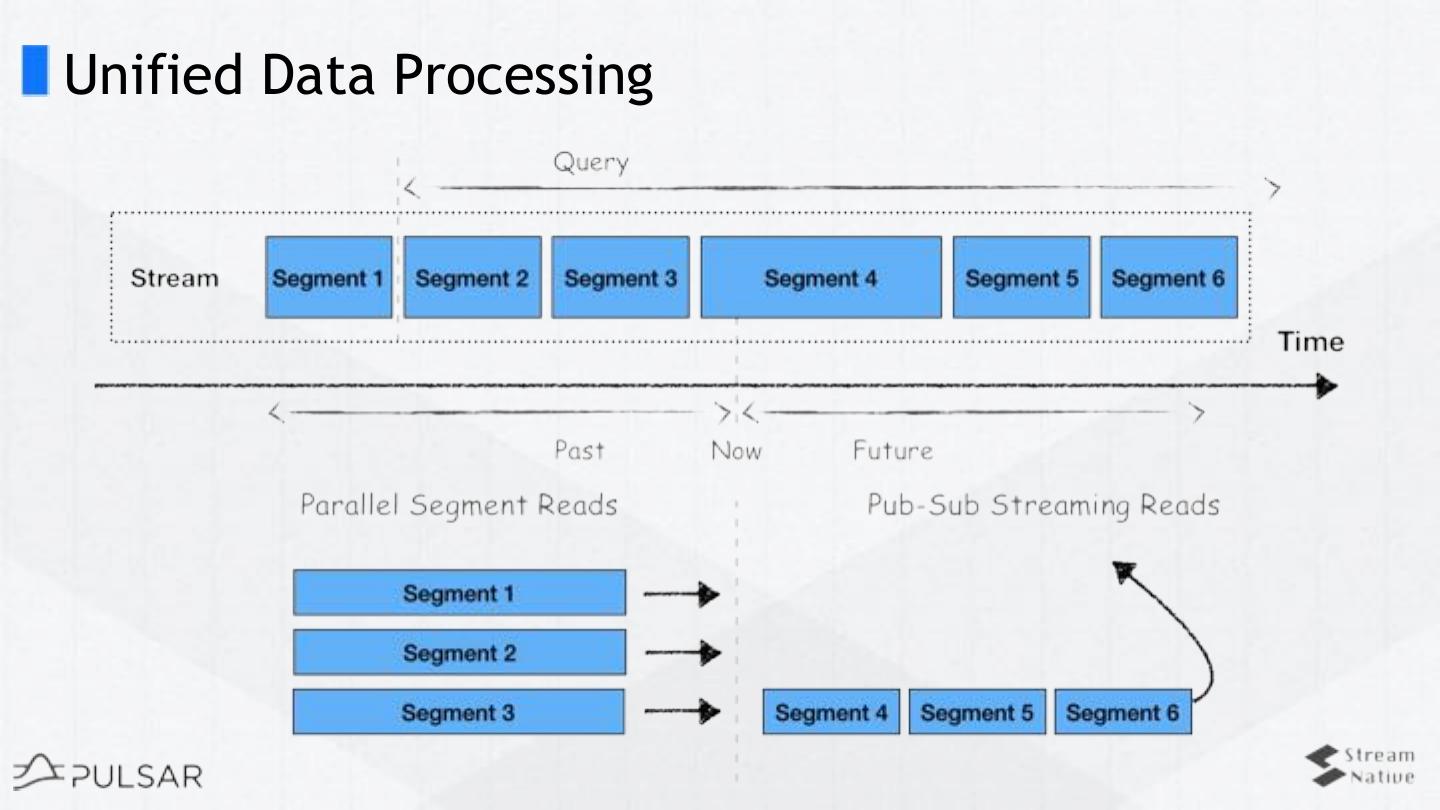
18 .Pulsar - Two levels of reading API
❏ Pub/Sub (Streaming)
❏ Read data from brokers
❏ Consume / Seek / Receive
❏ Subscription Mode - Failover, Shared, Key_Shared
❏ Reprocessing data by rewinding (seeking) the cursors
❏ Segment (Batch)
❏ Read data from storage (bookkeeper or tiered storage)
❏ Fine-grained Parallelism
❏ Predicate pushdown (publish timestamp)
�
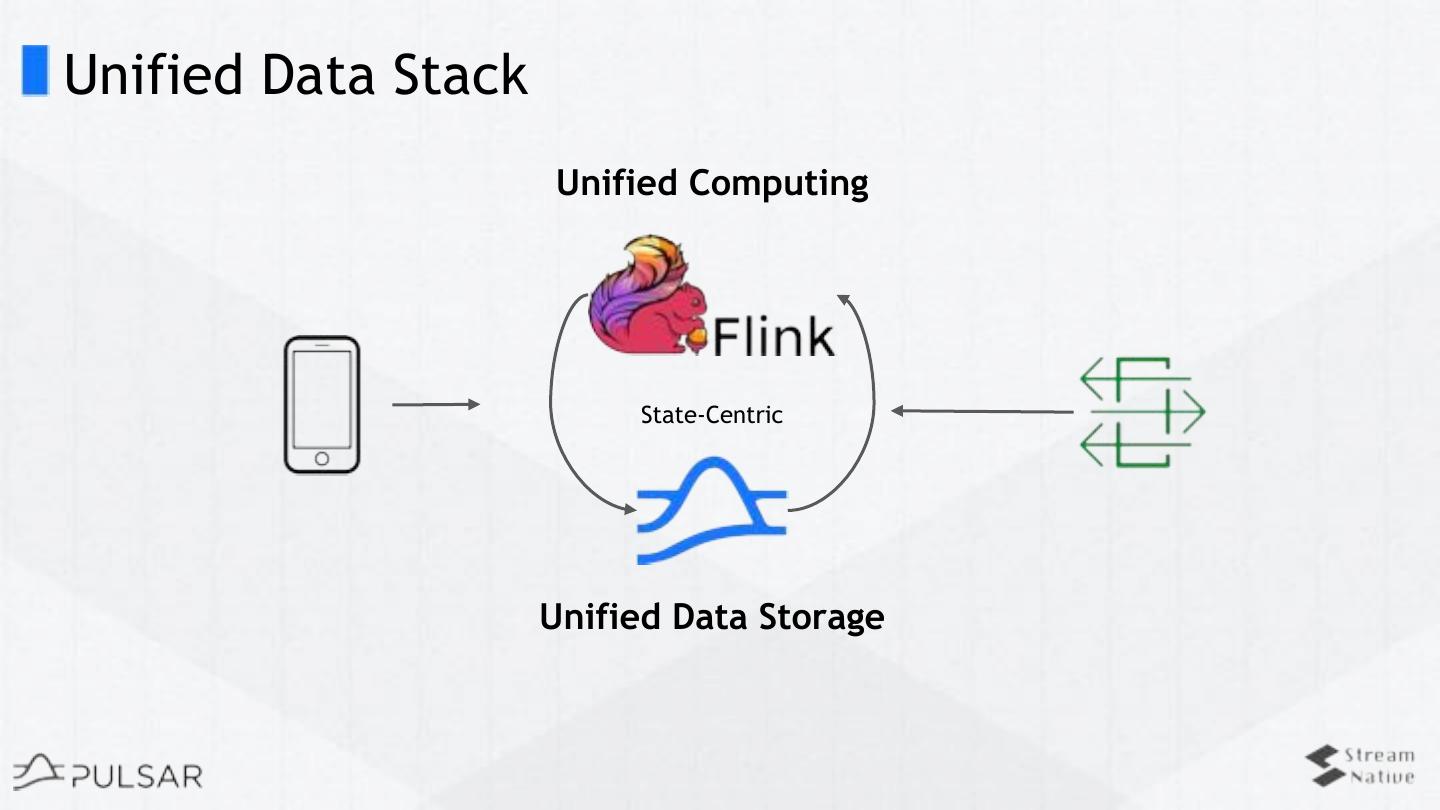
19 .Unified data processing on Pulsar
�
20 .Unified Data Processing
�
21 .Flink 1.6 Integration
❏ Available Connectors
❏ Streaming Source
❏ Streaming Sink
❏ Table Sink
When Flink & Pulsar come together: https://flink.apache.org/2019/05/03/pulsar-flink.html
�
23 .But that’s not cool ...
�
25 .Flink 1.9 Integration
❏ Pulsar Schema Integration
❏ Table API as first-class citizens
❏ Exactly-once source
❏ At-least-once sink
❏ Flink Catalog Integration
�
26 .Demo - Pulsar Catalog
�
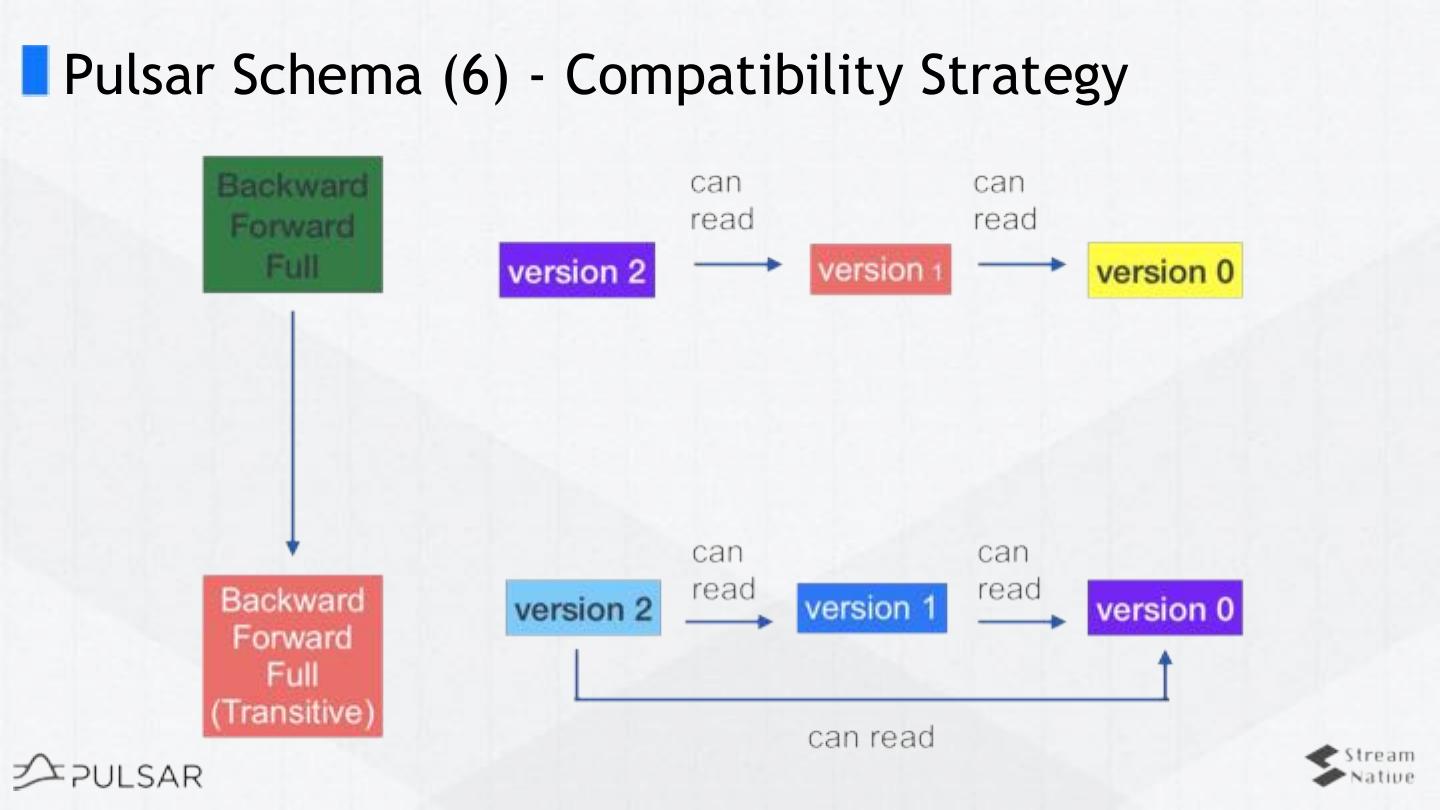
27 .Pulsar Schema (1)
❏ Consensus of data at server-side
❏ Built-in schema registry
❏ Data schema on a per-topic basis
❏ Send and receive typed messages directly
❏ Validation
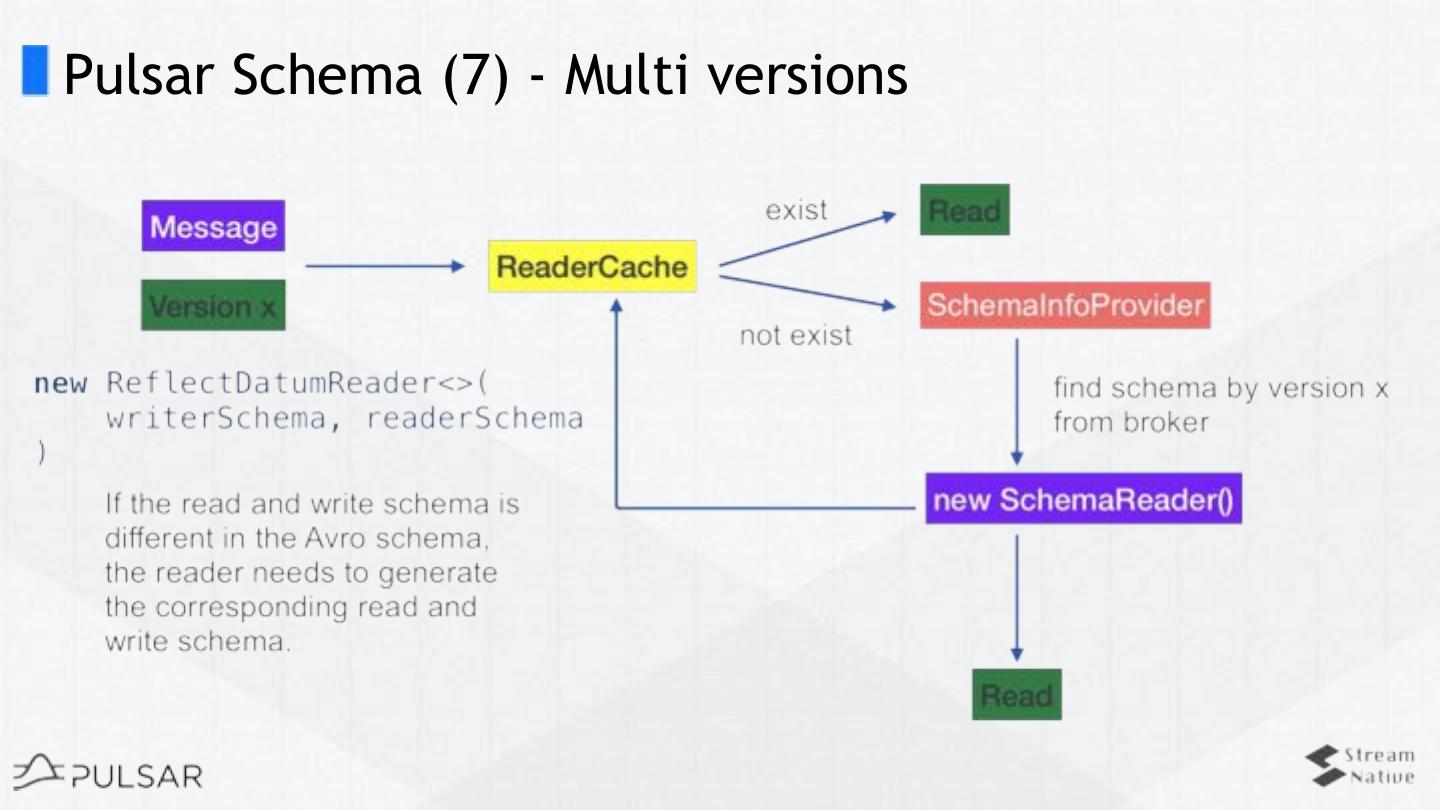
❏ Multi-version
❏ Schema evolution & compatibilities
�
28 .Pulsar Schema (2)
// Create producer with Struct schema and send messages
Producer<User> producer = client.newProducer(Schema.AVRO(User.class)).create();
producer.newMessage()
.value(User.builder()
.userName("pulsar-user")
.userId(1L)
.build())
.send();
// Create consumer with Struct schema and receive messages
Consumer<User> consumer = client.newConsumer(Schema.AVRO(User.class)).create();
consumer.receive();
�
29 .Pulsar Schema (3) - SchemaInfo
{ {
"type": "JSON", \"name\":\"file2\",
"schema": "{ \"type\":\"string\",
\"default\":null
\"type\":\"record\", },
\"name\":\"User\", {
\"name\":\"file3\",
\"namespace\":\"com.foo\", \"type\":[\"null\",\"string\"],
\"fields\":[ \"default\":\"dfdf\"
{ }
]
\"name\":\"file1\", }",
\"type\":[\"null\",\"string\"], "properties": {}
\"default\":null }
},
�