




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Interactive querying of streams using Apache Pulsar--Jerry Peng
展开查看详情
1 . © 2020 SPLUNK INC. Interactive Querying of Streams Using Apache Pulsar™ Pulsar Summit | June 2020 Jerry Peng Principal Software Engineer | jerryp@splunk.com Apache {Pulsar, Heron, Storm} committer and PMC member
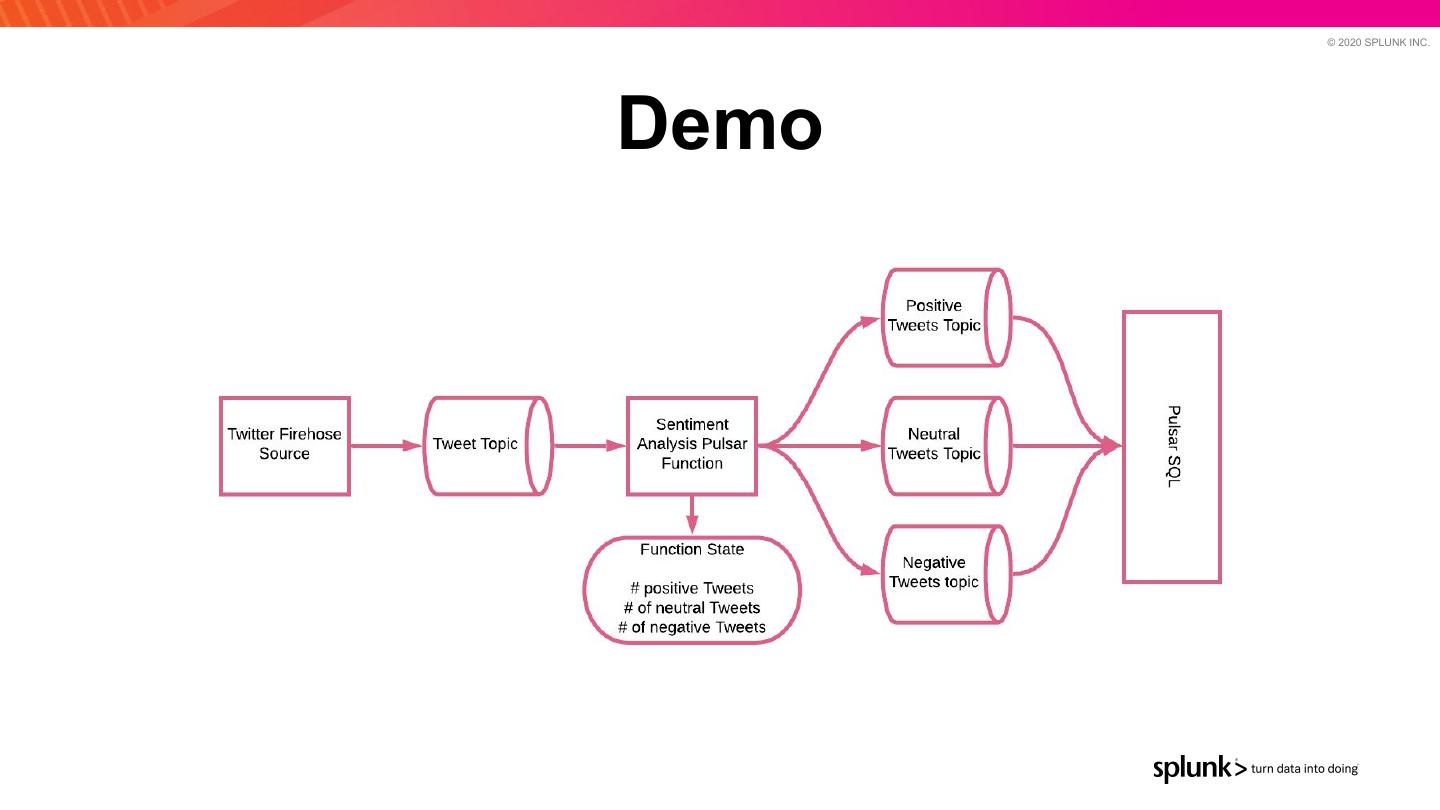
2 . © 2020 SPLUNK INC. Agenda 1) General use cases 2) Existing architectures 3) Apache Pulsar overview 4) Pulsar SQL 5) Concrete use case (Zhaoping.com) 6) Demo! 7) Questions?
3 . © 2020 SPLUNK INC. What are Streams? Continuous flows of data… Almost all data originate in this form
4 . © 2020 SPLUNK INC. Interactive Querying of Streams? Querying both latest and historical data
5 . © 2020 SPLUNK INC. How is it useful? ● Speed (i.e. data-driven processing) ○ Act faster ● Accuracy ○ In many contexts the wrong decision may be made if you do not have visibility that includes the most current data ○ For example, historical data is useful to predict a user is interested in buying a particular item, but if my analytics don’t also know that the user just purchased that item two minutes ago they’re going to make the wrong recommendation ● Simplification ○ Single place to go to access current and historical data
6 . © 2020 SPLUNK INC. Debugging General use cases ● Errors and Exception ● Troubleshooting systems and networks ● Have we seen these errors before?
7 . © 2020 SPLUNK INC. Monitoring (Audit logs) General use cases ● Answering the “What, When, Who, Why” ● Suspicious access patterns ● Example ○ Auditing CDC logs in financial institutions
8 . © 2020 SPLUNK INC. Exploring General use cases ● Raw or enriched data ● Really simplifies access if data is all in one location
9 . © 2020 SPLUNK INC. Lots of use cases General use cases ● Data analytics ● Business Intelligence ● Real-time dashboards ● etc…
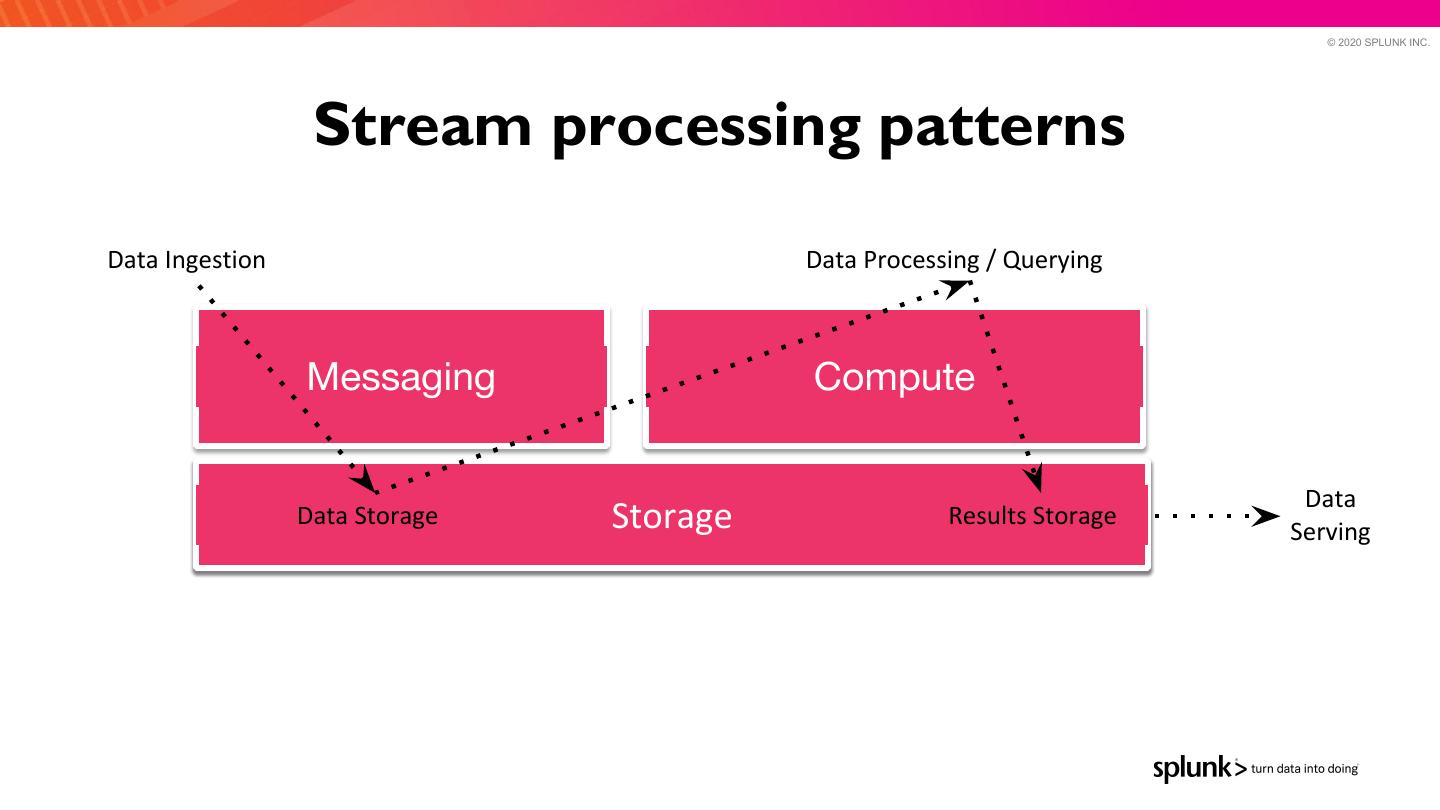
10 . © 2020 SPLUNK INC. Stream processing patterns Data Ingestion Data Processing / Querying Messaging Compute Data Data Storage Storage Results Storage Serving
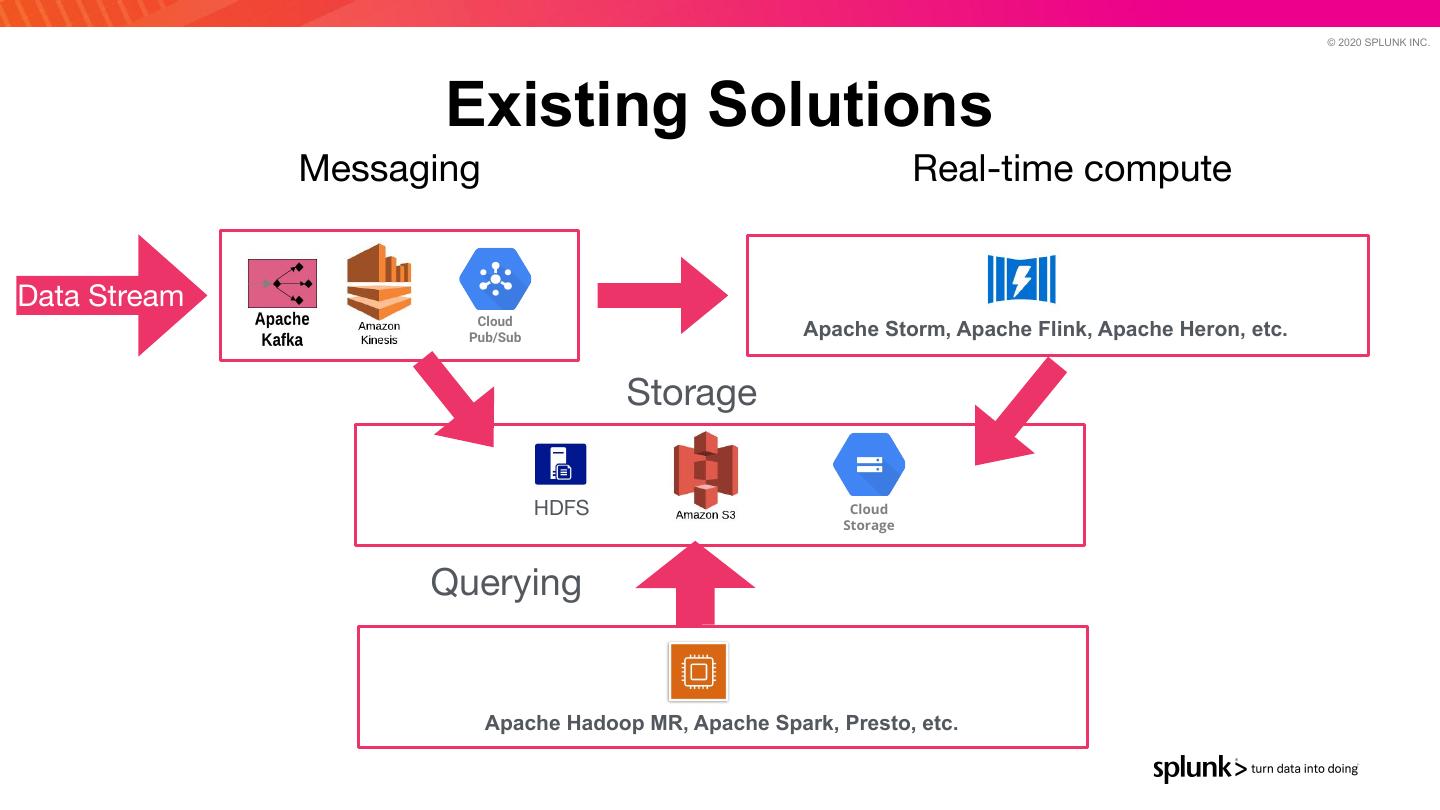
11 . © 2020 SPLUNK INC. Existing Solutions Messaging Real-time compute Data Stream Cloud Pub/Sub Apache Storm, Apache Flink, Apache Heron, etc. Storage HDFS Cloud Storage Querying Apache Hadoop MR, Apache Spark, Presto, etc.
12 . © 2020 SPLUNK INC. Problems with existing solutions ● Multiple Systems ● Duplication of data ○ Data consistency. Where is the source of truth? ● Latency between data ingestion and when data is queryable
13 . © 2020 SPLUNK INC. THIS IS WHERE APACHE PULSAR AND PULSAR SQL COMES IN…
14 . © 2020 SPLUNK INC. Apache Pulsar™ Flexible Messaging + Streaming System backed by a durable log storage
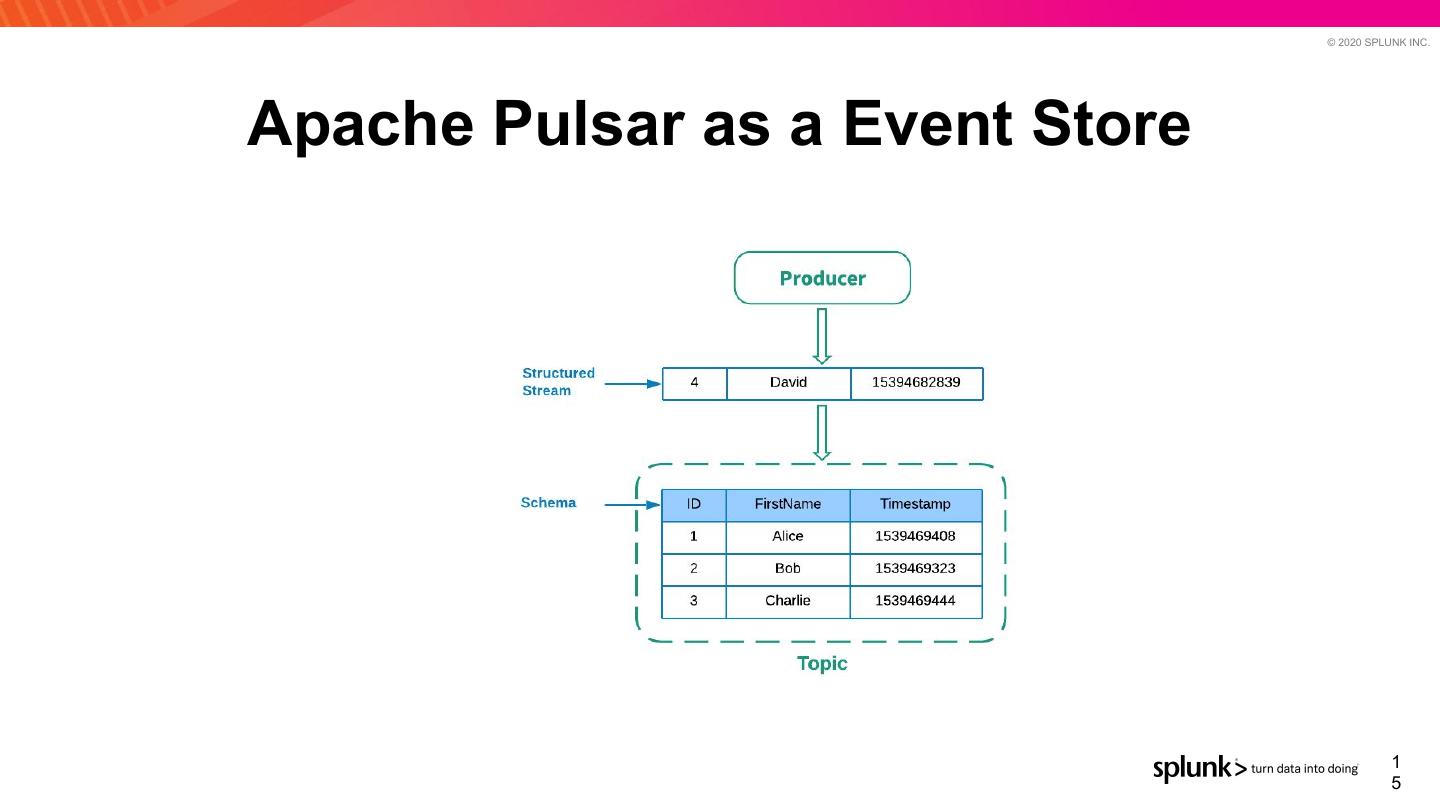
15 . © 2020 SPLUNK INC. Apache Pulsar as a Event Store 1 5
16 . © 2020 SPLUNK INC. Apache Pulsar Overview
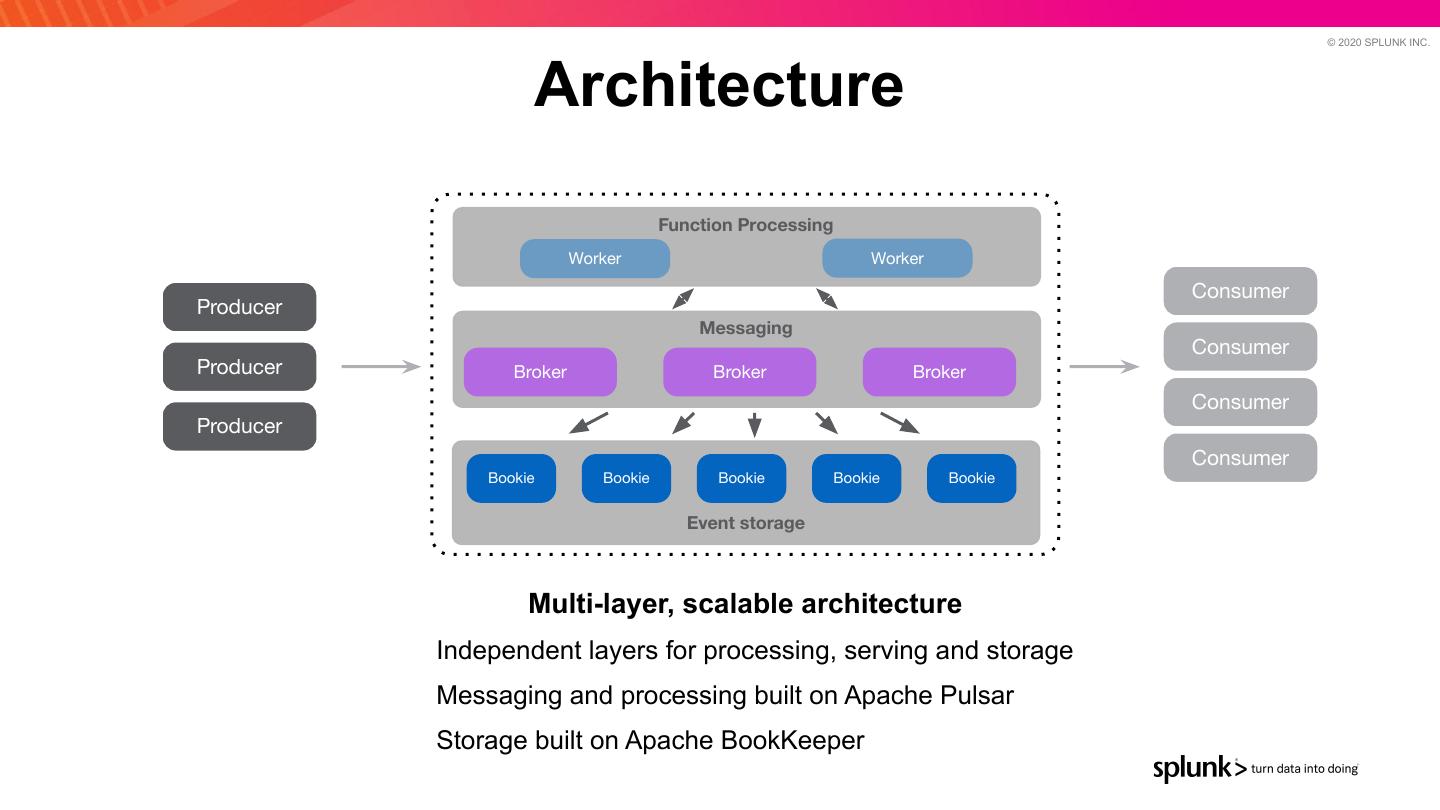
17 . © 2020 SPLUNK INC. Architecture Function Processing Worker Worker Consumer Producer Messaging Consumer Producer Broker Broker Broker Consumer Producer Consumer Bookie Bookie Bookie Bookie Bookie Event storage Multi-layer, scalable architecture Independent layers for processing, serving and storage Messaging and processing built on Apache Pulsar Storage built on Apache BookKeeper
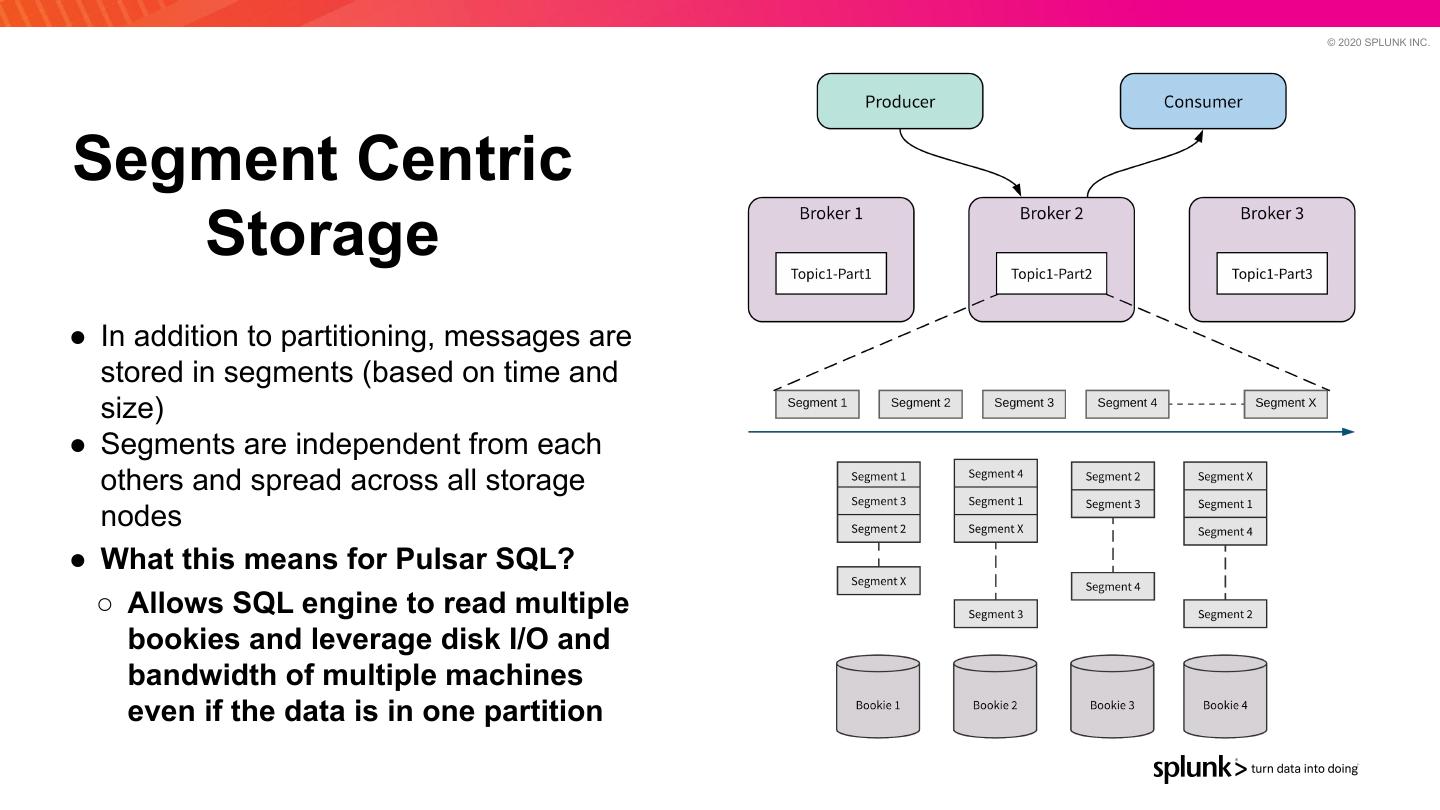
18 . © 2020 SPLUNK INC. Segment Centric Storage ● In addition to partitioning, messages are stored in segments (based on time and size) ● Segments are independent from each others and spread across all storage nodes ● What this means for Pulsar SQL? ○ Allows SQL engine to read multiple bookies and leverage disk I/O and bandwidth of multiple machines even if the data is in one partition
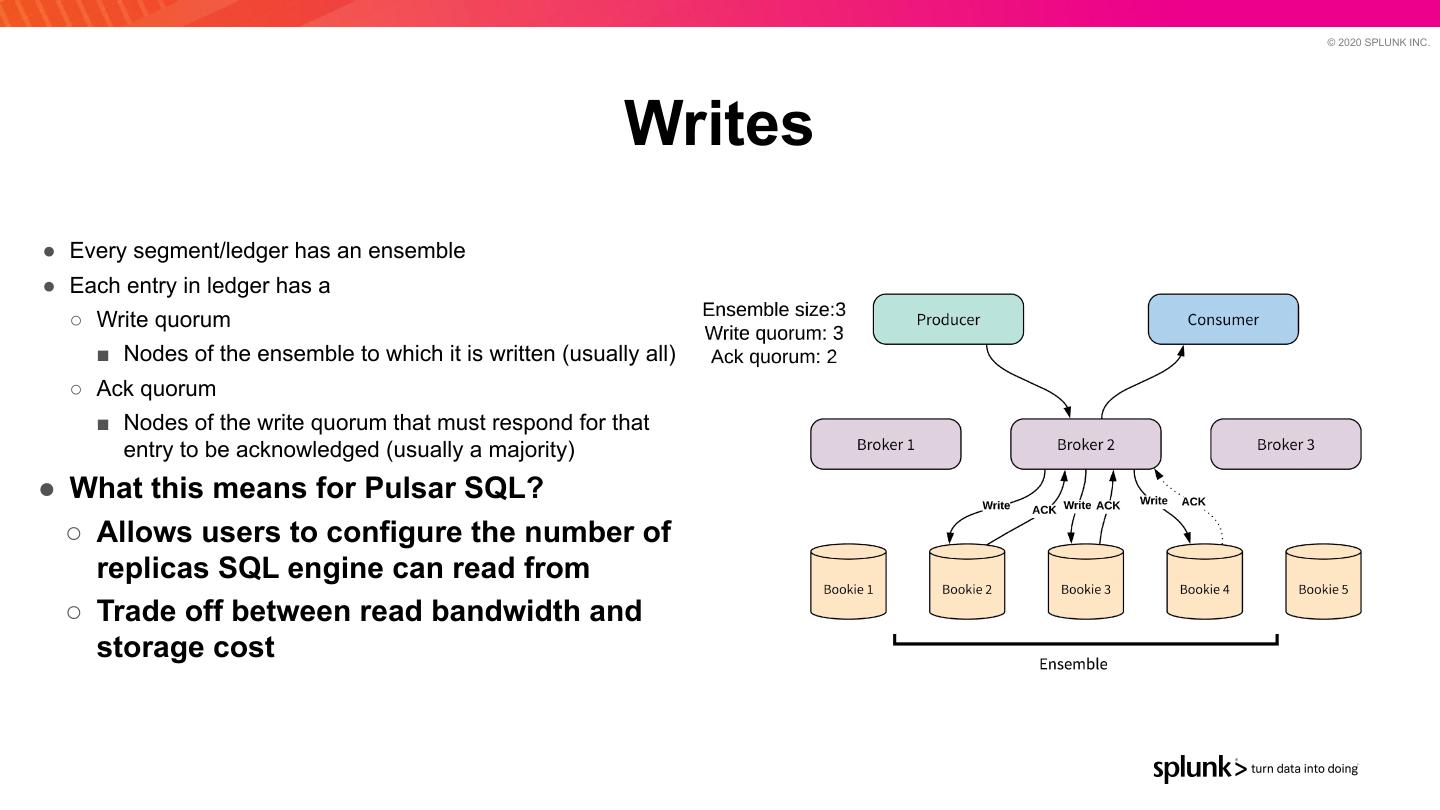
19 . © 2020 SPLUNK INC. Writes ● Every segment/ledger has an ensemble ● Each entry in ledger has a ○ Write quorum ■ Nodes of the ensemble to which it is written (usually all) ○ Ack quorum ■ Nodes of the write quorum that must respond for that entry to be acknowledged (usually a majority) ● What this means for Pulsar SQL? ○ Allows users to configure the number of replicas SQL engine can read from ○ Trade off between read bandwidth and storage cost
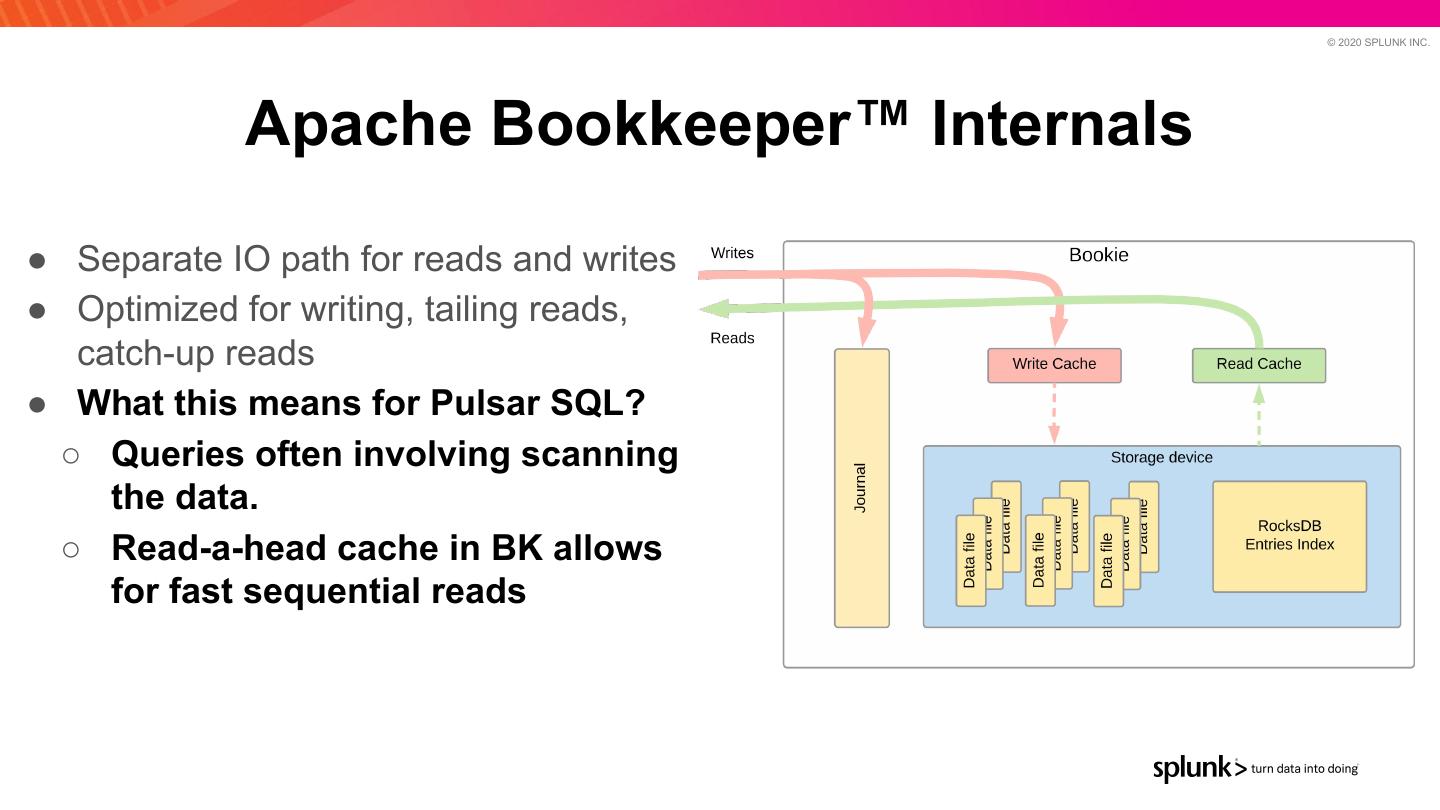
20 . © 2020 SPLUNK INC. Apache Bookkeeper™ Internals ● Separate IO path for reads and writes ● Optimized for writing, tailing reads, catch-up reads ● What this means for Pulsar SQL? ○ Queries often involving scanning the data. ○ Read-a-head cache in BK allows for fast sequential reads
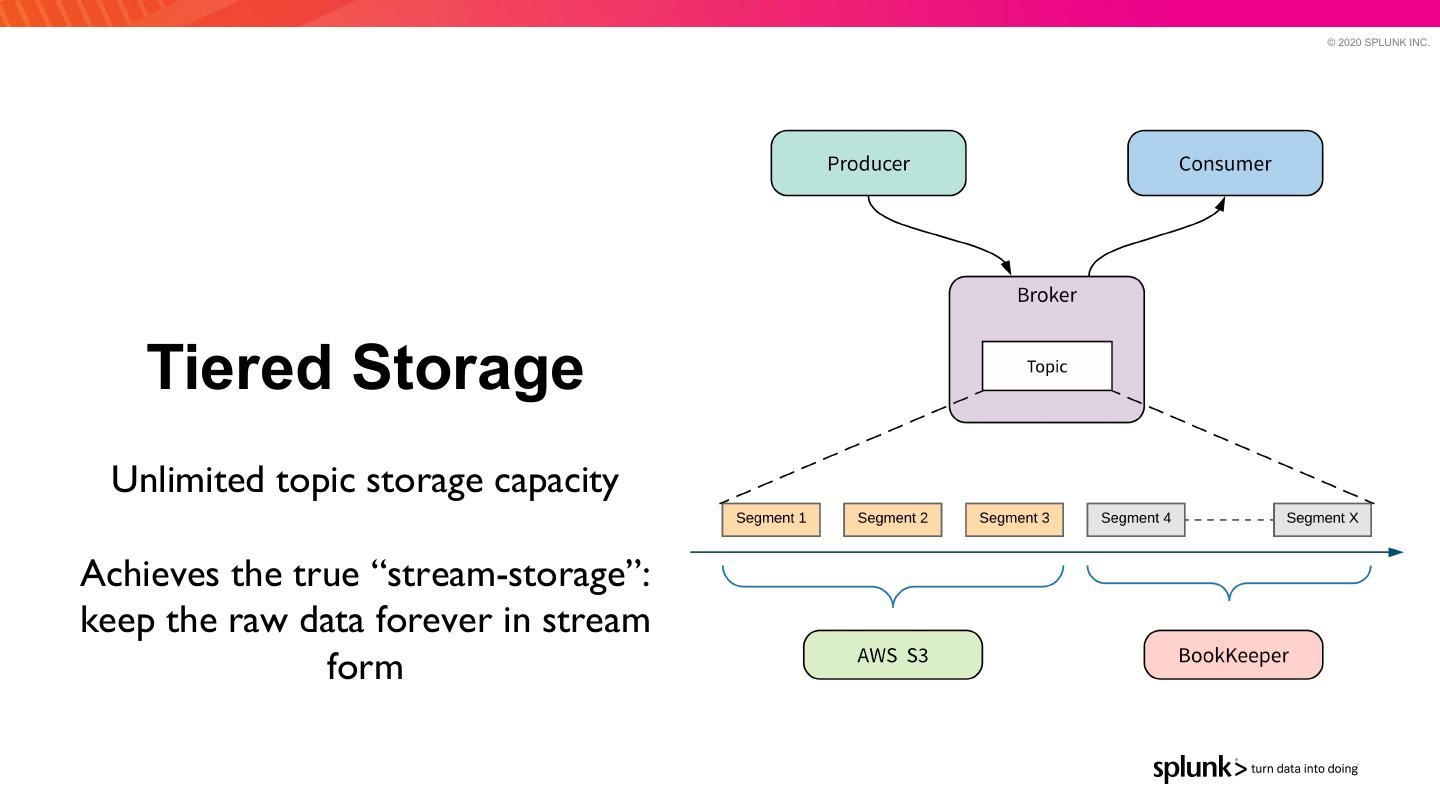
21 . © 2020 SPLUNK INC. Tiered Storage Unlimited topic storage capacity Achieves the true “stream-storage”: keep the raw data forever in stream form
22 . © 2020 SPLUNK INC. Tiered Storage ● Leverage cloud storage services to offload cold data — Completely transparent to clients ● Extremely cost effective — Backends (S3) (Coming GCS, HDFS) ● Example: Retain all data for 1 month — Offload all messages older than 1 day to S3 ● What this means for Pulsar SQL? ○ Pulsar SQL can query not only data in store in Bookies but also offloaded into a cloud storage service 2 2
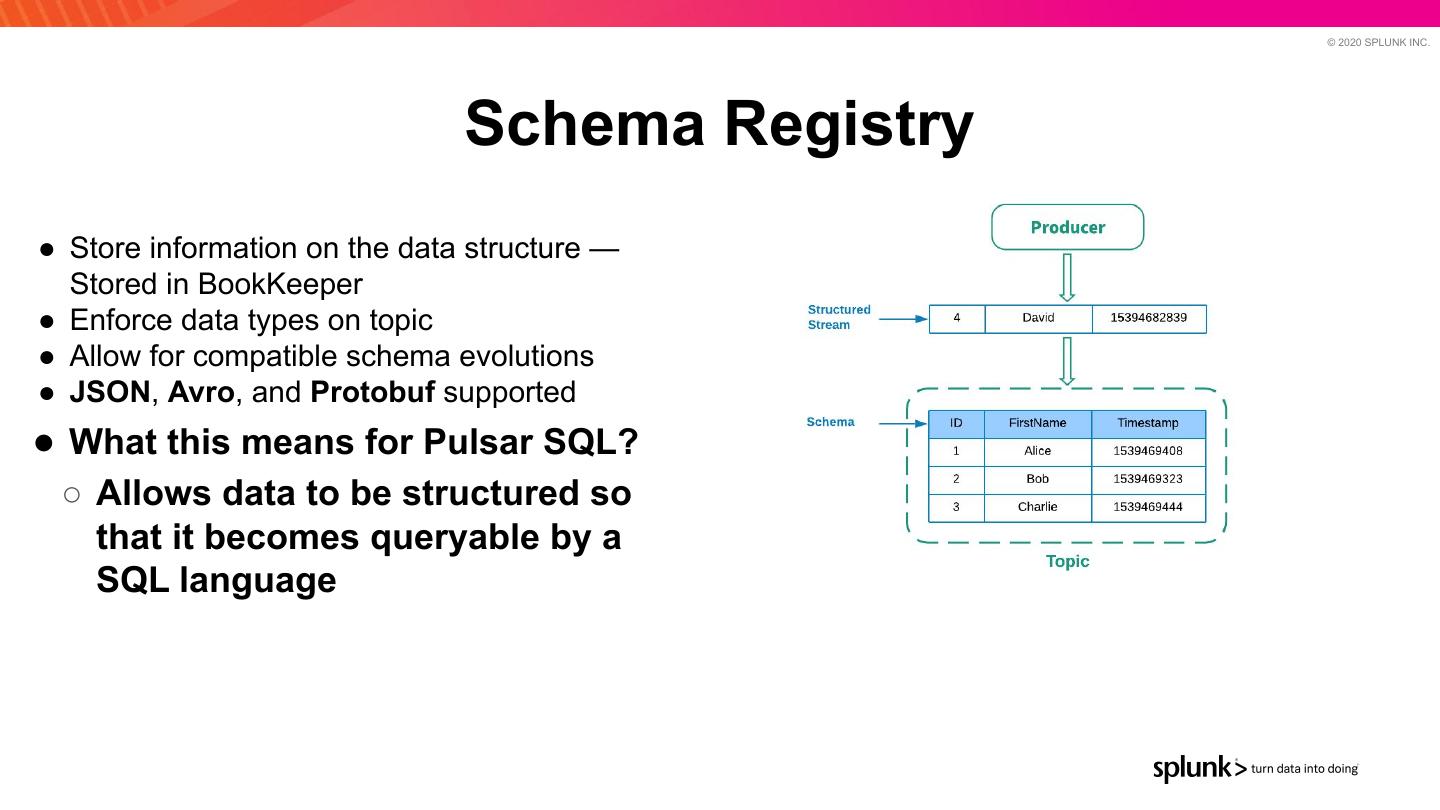
23 . © 2020 SPLUNK INC. Schema Registry ● Store information on the data structure — Stored in BookKeeper ● Enforce data types on topic ● Allow for compatible schema evolutions ● JSON, Avro, and Protobuf supported ● What this means for Pulsar SQL? ○ Allows data to be structured so that it becomes queryable by a SQL language
24 . © 2020 SPLUNK INC. Pulsar SQL Interactive SQL queries over data stored in Pulsar Query old and real-time data 2 4
25 . © 2020 SPLUNK INC. Pulsar SQL / 2 ● Based on Presto by Facebook — https://prestodb.io/ ● Presto is a distributed query execution engine ● Fetches the data from multiple sources (HDFS, S3, MySQL, …) ● Full SQL compatibility 2 5
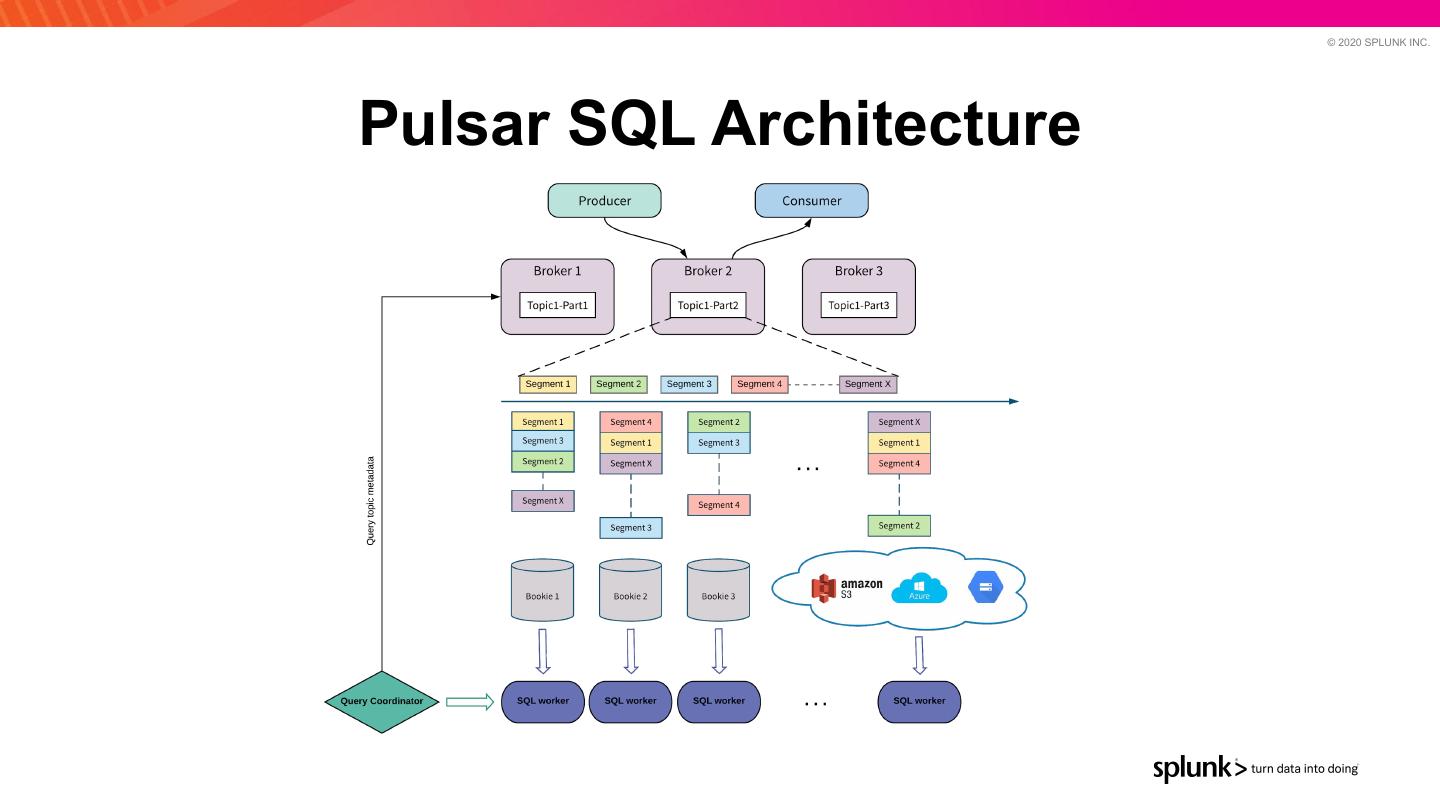
26 . © 2020 SPLUNK INC. Pulsar SQL / 3 ● Pulsar connector for Presto ○ Read data directly from BookKeeper — bypass Pulsar Broker ■ Can also read data offloaded to Tiered Storage (S3, GCS, etc.) ○ Many-to-many data reads ■ Data is split even on a single partition — multiple workers can read data in parallel from single Pulsar partition ■ Time based indexing — Use “publishTime” in predicates to reduce data being read from disk 2 6
27 . © 2020 SPLUNK INC. Pulsar SQL Architecture
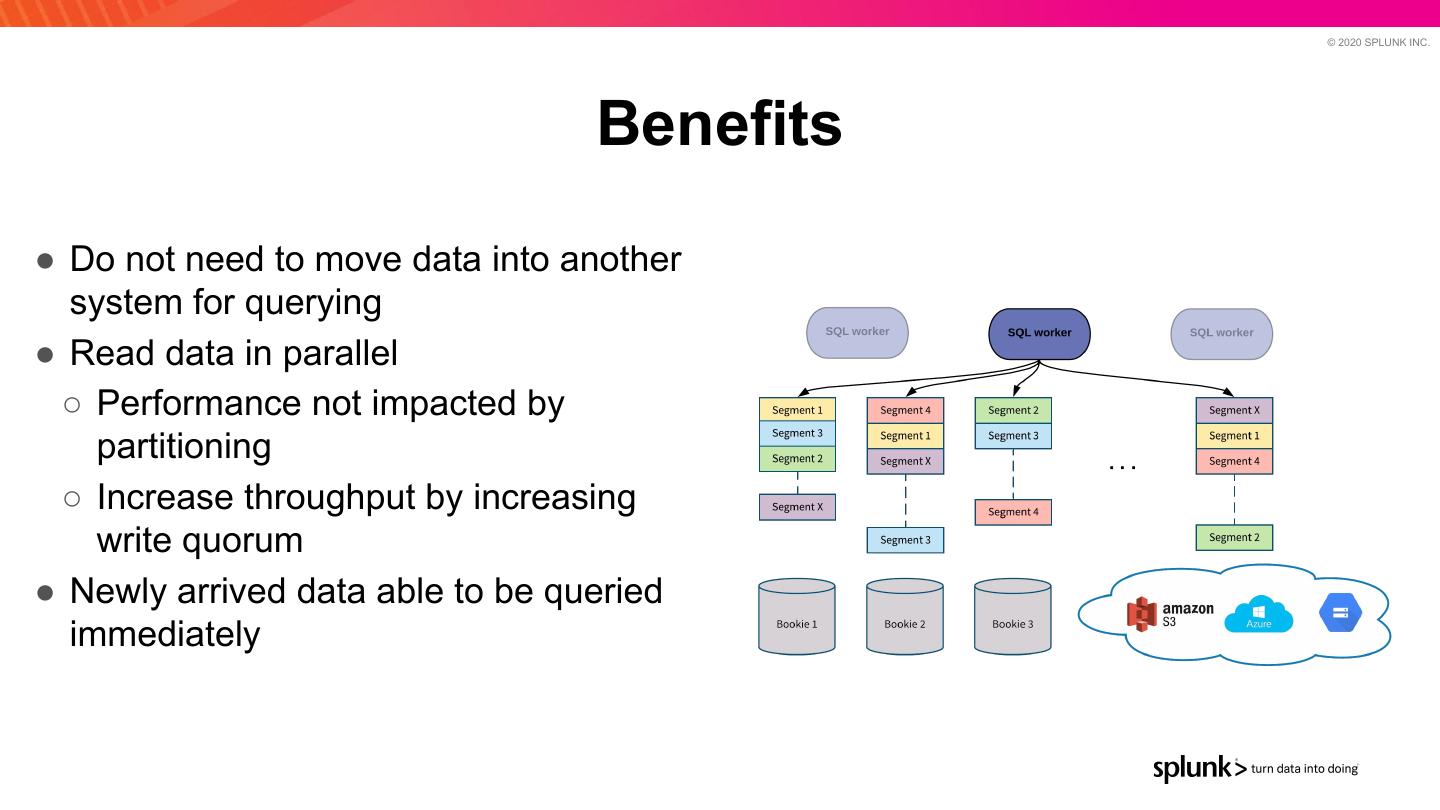
28 . © 2020 SPLUNK INC. Benefits ● Do not need to move data into another system for querying ● Read data in parallel ○ Performance not impacted by partitioning ○ Increase throughput by increasing write quorum ● Newly arrived data able to be queried immediately
29 . © 2020 SPLUNK INC. Compared to other message buses? ● Other messaging platforms have Presto integrations ● Typically uses a consumer to read data from brokers ● Topic/partition served by a single broker (limiting disk IO and network bandwidth)
3秒后跳转登录页面
去登陆

