






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
基于 Apache Pulsar+Flink 构建下一代实时数据仓库
展开查看详情
1 .基于 Apache Pulsar + Apache Flink 构建下一代实时数据仓库 Build your next-generation real-time data warehouse based on Apache Pulsar and Apache Flink Yijie Shen Senior software engineer, StreamNatvie 1
2 . 01 对实时数仓的需求 Urgent Need for Real-time Data Warehouse Contents 02 Apache Pulsar 简介 Why Apache Pulsar 目录 03 基于 Pulsar 的数仓构建 Build Data Warehouse based on Apache Pulsar 04 Pulsar Flink 连接器 Pulsar Flink Connector 05 展望 Future Directions 2
3 .对实时数仓的需求 Urgent Need for Real-time Data Warehouse 01 3
4 . 对实时数仓的需求 Motivation on Building a Real-time Data Warehouse 无处不在的流数据 快速发掘数据价值 计算引擎批流融合的趋势 • Sensors, logs from mobile app, IoT • Batch and interactive analysis Unified / similar API for batch/interactive • Organizations got better at capturing • Stream processing and stream processing data • Machine learning • Graph processing 4
5 . 实时数仓的构建难点 Challenges for Traditional MQs or Log Storage Systems • 云原生架构的兼容性 Compatible with cloud native architecture • 多租户管理 Multi-tenant management • 扩展性 Scalability • 数据存储组织的复杂度 Complexity of a multi-system architecture • 多系统存储维护开销 Maintenance as well as provisioning • 数据可见性问题 Visibility of data 5
6 .Apache Pulsar 简介 Why Apache Pulsar 02 6
7 .云原生的架构 Pulsar -- Cloud Native Architecture 无状态服务层 Stateless serving 数据持久层 Durable storage 7
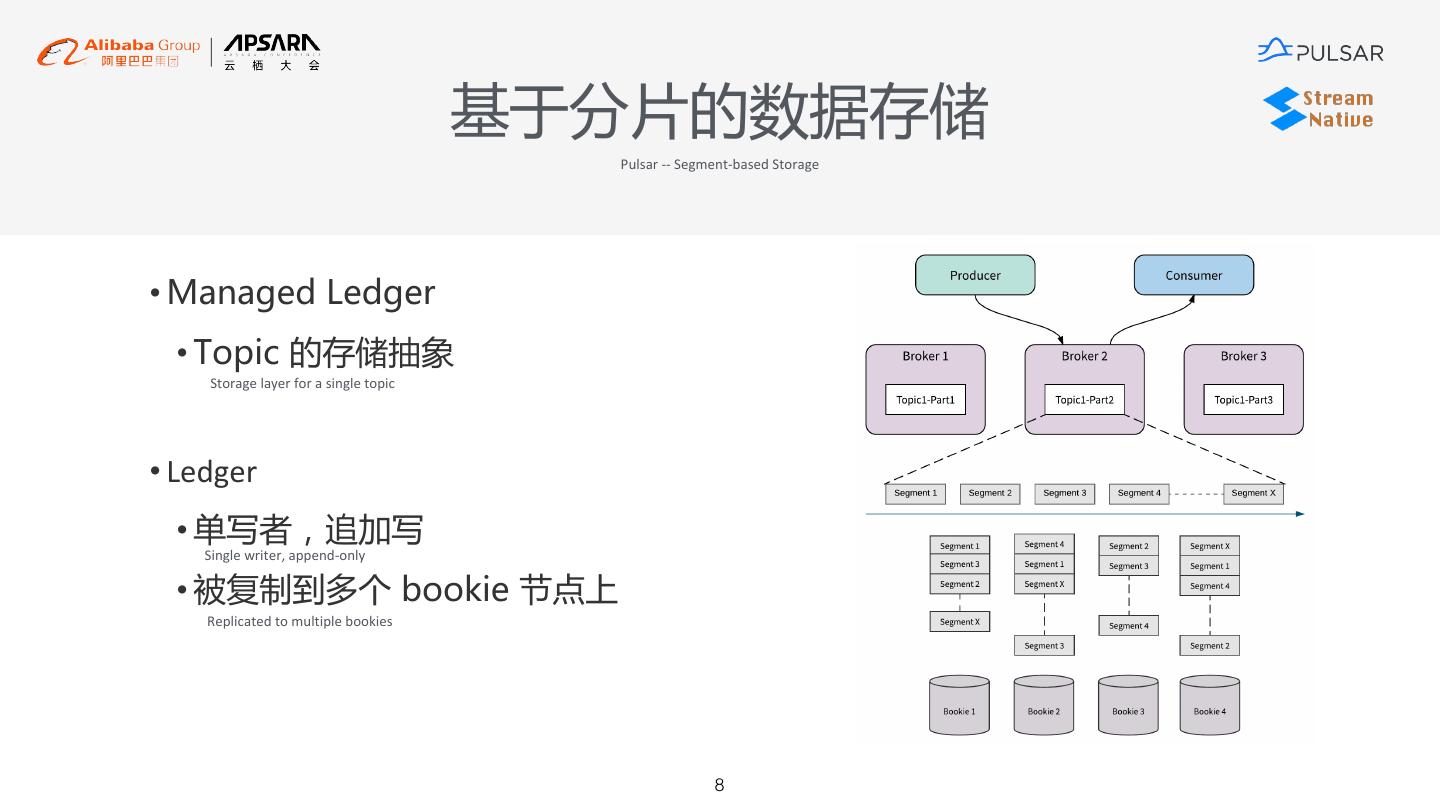
8 . 基于分片的数据存储 Pulsar -- Segment-based Storage • Managed Ledger • Topic 的存储抽象 Storage layer for a single topic • Ledger • 单写者,追加写 Single writer, append-only • 被复制到多个 bookie 节点上 Replicated to multiple bookies 8
9 . 无限、廉价的数据存储 Pulsar -- Infinite Data Storage • 使用廉价存储,持久化无限数据 Reduce storage cost • 按照分片粒度进行数据 Offload Offload data based on segment 9
10 . 有结构的数据 Pulsar – Structured Data • 内置的 Schema 注册 Built-in schema registry • 在服务器端的消息结构共识 Consensus of data at server-side • Topic 级别的消息结构 Data schema on a per-topic basis • 直接产生、消费有结构的数据 Send and receive typed message directly • Pulsar 进行消息验证 Validation • 支持消息版本的演化 Multi-version 10
11 .基于 Pulsar 的数仓构建 Data warehouse based on Apache Pulsar 03 11
12 . 实时数仓架构 Architecture for Real-time Data Warehouse Flink Stream Sub-stream Catalog Reader Reader Segment State Reader Store Broker Bookie Connectors ( based on Pulsar Function ) DB File Flume 12
13 . 元数据服务 Catalog Service • 元数据翻译层 Metadata translation layer • 将 Pulsar 的元数据以数据库语义表达 Express Pulsar metadata in DB terminologies • 提供对 Pulsar 元数据的查询和修改 Support performing *select* and *update* operations on metadata • 基本映射 Some basic mappings • Tenant/namespace à Database • Topic à Table • Topic Schema à Table Schema 13
14 . 灵活的数据读取模式 Flexible Data Consumption Mode • Segment Read • Stream Read • Sub-Stream Read • 直接从 Tiered Storage • Seek / Read • 基于 Sticky consumer、 Based on sticky consumer and key-shared 或者 BookKeeper 中读 • Topic Partition 粒度并行 Key-shared subscription Parallel execution at topic partition level Granularity of parallelism is at sub-topic level Segment • 基于 MessageId 的消 的 sub-topic 粒度并行 Read data from tiered storage or BK directly Reprocess based on MessageId • 细粒度的并发读 费、重做语义 • 将 partition 数目和消费 Read data concurrently with fine level of granularity Decouple partition number with • 更多的优化机会 并行度解藕 More optimization opportunities consumption parallelism e.g. Filter pushdown • Introduced in Pulsar 2.5.0 14
15 .Pulsar Flink Connector 04 15
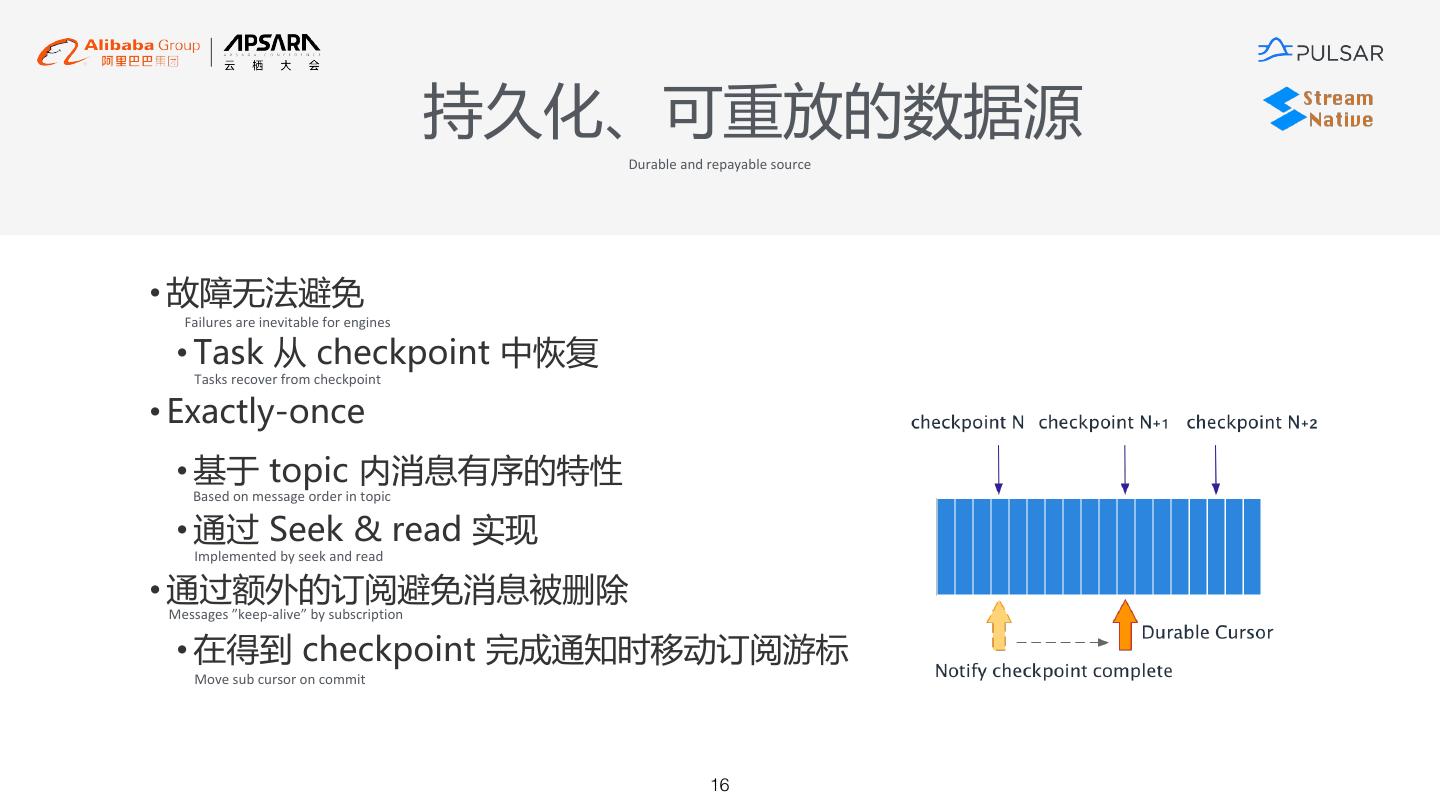
16 . 持久化、可重放的数据源 Durable and repayable source • 故障无法避免 Failures are inevitable for engines • Task 从 checkpoint 中恢复 Tasks recover from checkpoint • Exactly-once • 基于 topic 内消息有序的特性 Based on message order in topic • 通过 Seek & read 实现 Implemented by seek and read • 通过额外的订阅避免消息被删除 Messages ”keep-alive” by subscription • 在得到 checkpoint 完成通知时移动订阅游标 Move sub cursor on commit 16
17 . 结构化数据存取 Processing typed records • 将 Pulsar topic 看作是一张有结构的表 Regard Pulsar as structured storage • 在任务调度期获取表 Schema 定义 Fetch schema as the first step • 将 Pulsar message (反)序列化成Row Deserialize/Serialize your messages into Row • 支持 avro/json/protobuf 的消息转换 Support avro/json/protobuf conversion • 消息元数据转化为表的内部列 Message metadata as metadata fields • __key, __publishTime, __eventTime, __messageId, __topicfan 17
18 . Topic 和 Partition 发现 Topic/Partition discovery • 流处理作业是长时间运行的 Streaming jobs are long running • 在作业执行期间,topic 可能被添加或删除 Topics & partitions may be added on removed during job executions • 阶段性检查 topic 状态 Periodically check the status of topic • 每个 task 内部一个用于监控的线程 With a monitoring thread in each task 18
19 .未来方向 New Future on Cloud 05 19
20 . 分析友好的数据组织、访问 Analytical-friendly data organizations and access method • 谓词下推 + 粗粒度索引 • 列形式组织 Segment • 更灵活的数据消费模式 Filter push down & coarse-grained index Organize segment data in columnar format More flexible data consumption mode • Segment 级别的 max、 • 针对分析型负载 Max/min at segment level Target at analytical workloads min • 节约磁盘带宽 Save disk bandwidth / network IO • Broker 收集,写入 • 节约 CPU 时间 Indices are generated during broker put Save CPU time Segment 的元数据 20
21 .Pulsar Community
22 .Pulsar Community
23 .THANKS ! 23
3秒后跳转登录页面
去登陆

