






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Getting Pulsar Spinning——Addison Higham
展开查看详情
1 .Getting Pulsar Spinning Our story with adopting and deploying Apache Pulsar
2 . About Me SW Architect at Instructure github.com/addisonj twitter.com/addisonjh
3 .Today’s Agenda ● How we built consensus around Pulsar ● How we built our Pulsar clusters ● How we continue to foster adoption ● A deep dive into one primary use case
4 .Winning hearts and minds
5 . ● Company behind Canvas, a Learning Management System About used by millions of students in K-12 and Higher-Ed Instructure ● 2+ million concurrent active users, Alexa top 100 site ● AWS shop with a wide variety of languages/technologies used ● Lots and lots of features
6 .The problems ● Sprawl: As we began to use micro-services, we ended up with multiple messaging (Kinesis and SQS) systems being used inconsistently ● Feature gaps: Kinesis doesn’t provide long term retention and is difficult to get ordering to scale. SQS doesn’t provide replay and ordering is difficult ● Long delivery time: Kinesis really only worked for Lambda architecture, which takes a long time to build. We want Kappa as much as possible ● Cost: We expected usage of messaging to increase drastically. Kinesis was getting expensive ● Difficult to use: Outside of AWS Lambda, Kinesis is very difficult to use and not ideal for most of our use cases
7 .Why Pulsar? ● Most teams don’t need “log” capabilities (yet). They just want to send and receive messages with a nice API (pub/sub) ● However, some use cases require order and high throughput, but we didn’t want two systems ● Pulsar’s unified messaging model is not just marketing, it really provides us the best of both worlds ● We want minimal management of any solution. No need to re-balance after scaling up was very attractive ● We wanted low cost and long-term retention, tiered storage makes that possible ● Multi-tenancy is built in, minimize the amount of tooling we need
8 .The pitch Three main talking points: Capabilities Unified pub/sub and log, infinite retention, multi-tenancy, functions,geo-replication, and schema management, and integrations made engineers excited Cost Native k8s support to speed-up implementation, no rebalancing and tiered storage making it easy and low cost to run and operate were compelling to management Ecosystem Pulsar is the backbone of an ecosystem of tools that make adoption easier and quickly enable new capabilities helped establish a vision that everyone believed in
9 .The plan ● Work iteratively ○ MVP release in 2 months with most major features but no SLAs ○ Near daily releases to focus on biggest immediate pains/biggest feature gaps ● Be transparent ○ We focused on speed as opposed to stability, repeatedly communicating that helped ○ We very clearly communicated risks and then showed regular progress on the most risky aspects ● Focus on adoption/ecosystem ○ We continually communicated with teams to find the things that prevented them moving forward (kinesis integration, easier login, etc) ○ We prioritized building the ecosystem over solving all operational challenges
10 .The results Timeline ● End of May 2019: Project approved ● July 3rd 2019: MVP release (pulsar + POC auth) ● July 17th 2019: Beta v1 release (improved tooling, ready for internal usage) ● Nov 20th 2019: First prod release to 8 AWS regions Stats ● 4 applications in production, 4-5 more in development ● Heavy use of Pulsar IO (sources) ● 50k msgs/sec for largest cluster ● Team is 2 FT engineers + 2 split engineers
11 .How we did it
12 . ● Pulsar is very full featured out of the box, we wanted to build as little as possible around it Our Approach ● We wanted to use off-the-shelf tools as much as possible and focus on high-value “glue” to integrate into our ecosystem ● Iterate, iterate, iterate
13 . ● We didn’t yet use K8S ● We made a bet that Pulsar on K8S K8S (EKS) would be quicker than raw EC2 ● It has mostly proved correct and helped us make the most of pulsar functions
14 .K8S details ● EKS Clusters provisioned with terraform and a few high value services ○ https://github.com/cloudposse/terraform-aws-eks-cluster ○ Core K8S services: EKS built-ins, datadog, fluentd, kiam, cert-manager, external-dns, k8s- snapshots ● Started with Pulsar provided Helm charts ○ We migrated to Kustomize ● EBS PIOPS volumes for bookkeeper journal, GP2 for ledger ● Dedicated pool of compute (by using node selectors and taints) just for Pulsar ● A few bash cron jobs to keep things in sync with our auth service ● Make use of K8S services with NLB annotations + external DNS
15 . ● Use built-in token auth with minimal API for managing tenants and role associations ● Core concept: Make an association between a AWS Auth IAM principal and pulsar role. Drop off credentials in a shared location in Hashicorp Vault ● Accompanying CLI tool (mb_util) to help teams manage associations and fetch creds ● Implemented using gRPC
16 .Workflows Adding a new tenant: ● Jira ticket with an okta group ● mb_util superapi --server prod-iad create-tenant --tenant new_team -- groups new_team_eng Logging in for management: ● mb_util pulsar-api-login --server prod-iad --tenant new_team ● Pops a browser window to login via okta ● Copy/Paste a JWT from the web app ● Generates a pulsar config file with creds and gives an env var to export for use with pulsar-admin
17 .Workflows (cont.) Associating an IAM principal ● mb_util api --server prod-iad associate-role --tenant my_team --iam-role my_app_role --pulsar-role my_app ● The API generates a JWT with the given role + prefixed with tenant name, stores it in a shared location (based on IAM principal) in hashicorp vault ● K8S cron job periodically updates the token Fetching creds for clients: ● mb_util is a simple golang binary, easy to distribute and use in app startup script ● PULSAR_AUTH_TOKEN=$(mb_util pulsar-vault-login --tenant my_team -pulsar- role my_app --vault-server https://vault_url) ● Grabs IAM creds, auth against vault, determines shared location, grabs credential ● Future version will support running in background and keeping a file up to date
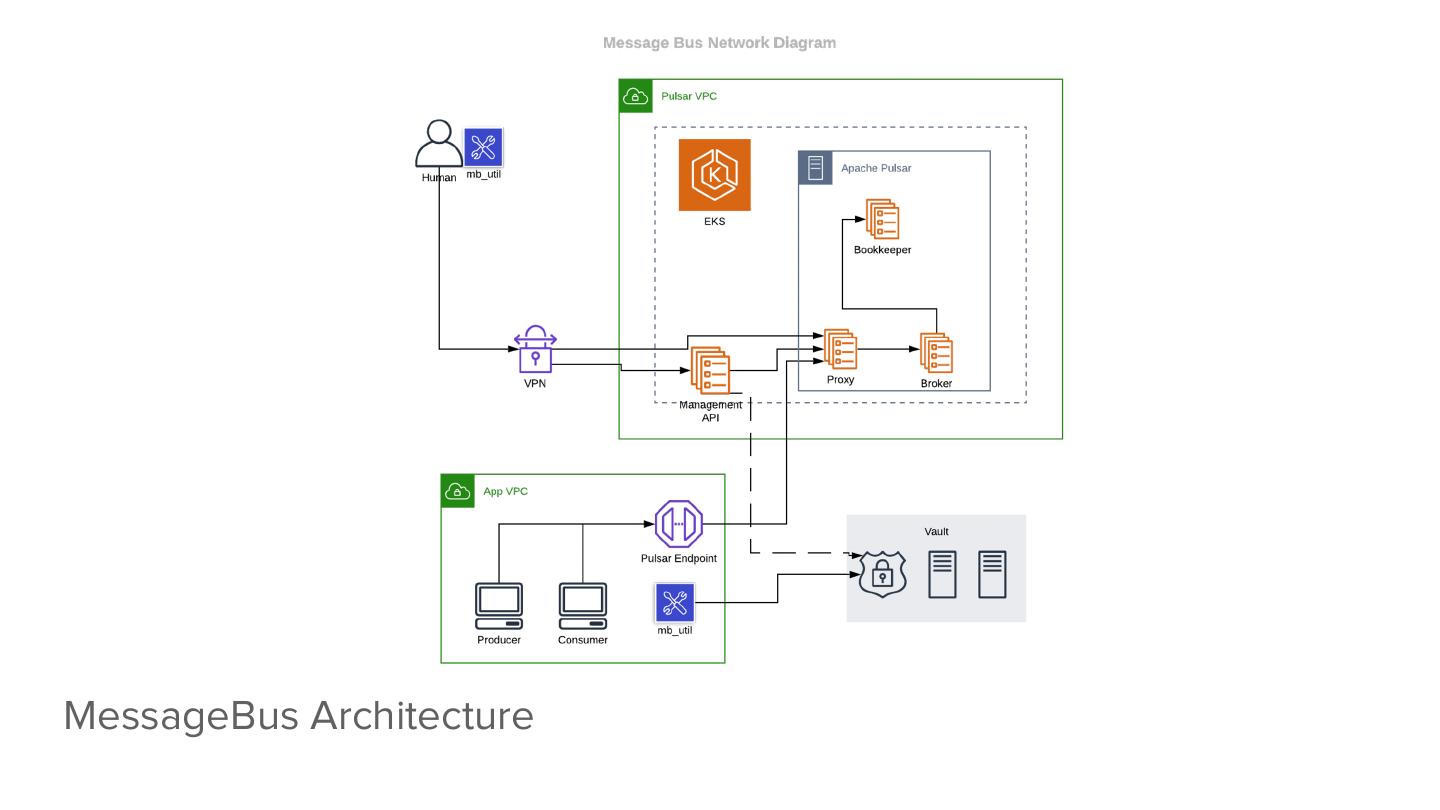
18 . ● For internal communication, we use EKS networking + K8S services ● Clusters are not exposed over Networking public internet nor do we share the VPC to apps. NLBs + VPC endpoints expose a single endpoint into other VPCs ● For geo-replication, we use NLBs, VPC peering, route53 private zones, and external-dns
19 .MessageBus Architecture
20 . NOTE: We have some issues with how we run global zookeeper, not currently recommended! Global MessageBus
21 .What worked ● Clusters are very easy to provision and scale up ● Pulsar has great performance even with small JVMs ● EBS volumes (via K8S PersistentVolumes) have worked great ● Managing certs/secrets is simple and easy to implement with a few lines of bash ● We can experiment much quicker ● Just terraform and K8S (no config management!) ● Pulsar functions on K8S + cluster autoscaling is magical
22 .What needed (and still needs) work ● Pulsar (and dependencies) aren’t perfect at dealing with dynamic names ○ When a bookie gets rescheduled, it get a new IP, Pulsar can cache that ■ FIX: tweak TCP keepalive /sbin/sysctl -w net.ipv4.tcp_keepalive_time=1 net.ipv4.tcp_keepalive_intvl=11 net.ipv4.tcp_keepalive_probes=3 ○ When a broker gets rescheduled, a proxy can get out of sync. Clients can get confused as well ■ FIX: Don’t use zookeeper discovery, use a API discovery ■ FIX: Don’t use a deployment for brokers, use a statefulset ○ Pulsar function worker in broker can cause extra broker restarts ■ FIX: run separate function worker deployment ● Manual restarts sometimes needed ○ Use probes. if you want to optimize write availability, can use health-check ● Pulsar Proxy was not as “battle hardened” ● Large K8S deployments are still rare vs bare metal ● Zookeeper (especially global zookeeper) is a unique challenge ● Many random bugs in admin commands
23 .The good news Since we have deployed on K8S, lots of improvements have landed: ● Default helm templates are much better ● Lots of issues and bugs fixed that made running on K8S less stable ● Improvements in error-handling/refactoring are decreasing random bugs in admin commands (more on the way) ● Docs are getting better ● Best practices are getting established ● A virtuous cycle is developing: Adoption -> Improvements from growing community -> Easier to run -> Makes adoption easier
24 .Continuing to build and grow
25 . ● Adoption within our company is our primary KPI ● We focus on adding new Adoption integrations and improving tooling to make on-boarding easy ● Pulsar is the core, but the ecosystem built around it is the real value
26 .Pulsar Functions ● Pulsar Functions on K8S + cluster autoscaler really is a great capability that we didn’t expect to be as popular ● Teams really like the model and gravitate to the feature ○ “Lambda like” functionality that is easier to use and more cost effective ● Sources/Sinks allow for much easier migration and on-boarding ● Per function K8S runtime options (https://pulsar.apache.org/docs/en/functions-runtime/#kubernetes- customruntimeoptions) allow for us to isolate compute and give teams visibility into the runtime but without having to manage any infrastructure
27 .Kinesis Source/Sink ● We can easily help teams migrate from Kinesis ● Two options: ○ Change producer to write to Pulsar, Kinesis sink to existing Kinesis stream, slowly migrate consumers (lambda functions) ○ Kinesis Source replicates to Pulsar, migrate consumers and then producers when finished ● Same concept works for SQS/SNS
28 .Change Data Capture ● The CDC connector (https://pulsar.apache.org/docs/en/io-cdc/) is a really great way to start moving towards more “evented” architectures ● We have an internal version (with plans to contribute) that we will use to get CDC feeds for 60+ tables from 150+ Postgres clusters ● A very convenient way to implement the “outbox” pattern for consistent application events ● Dynamodb streams connector also works well for CDC
29 .Flink ● With K8S and zookeeper in place, running HA Flink (via https://github.com/lyft/flinkk8soperator) is not much effort ● Flink + Pulsar is an extremely powerful stream processing tool that can replace ETLs, Lambda architectures, and (🤞) entire applications
3秒后跳转登录页面
去登陆

