展开查看详情
2 .Contents
Source 、 Sink 与 Function Worker 的关系
Source 、 Sink 对 Pub/Sub 的封装使用
Source 、 Sink 对 Schema 的应用
Pulsar IO 当前的生态
�
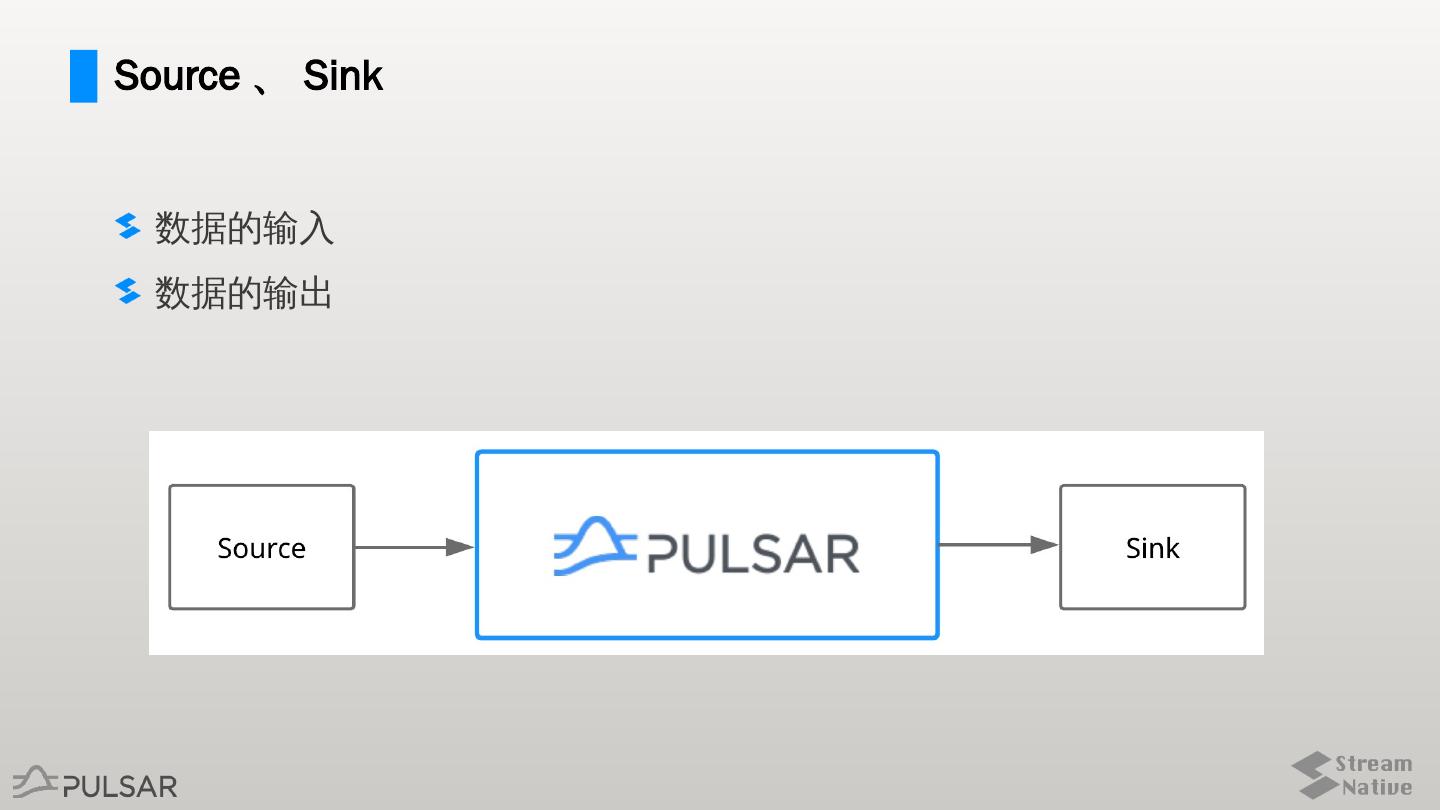
3 .Source 、 Sink
数据的输入
数据的输出
�
4 .Function Worker
Function Worker 承载了 Pulsar Serverless
Source 、 Sink 、 Function 运行在 Function
Worker 上
可以基于线程、进程和 k8s 三种模式运行
�
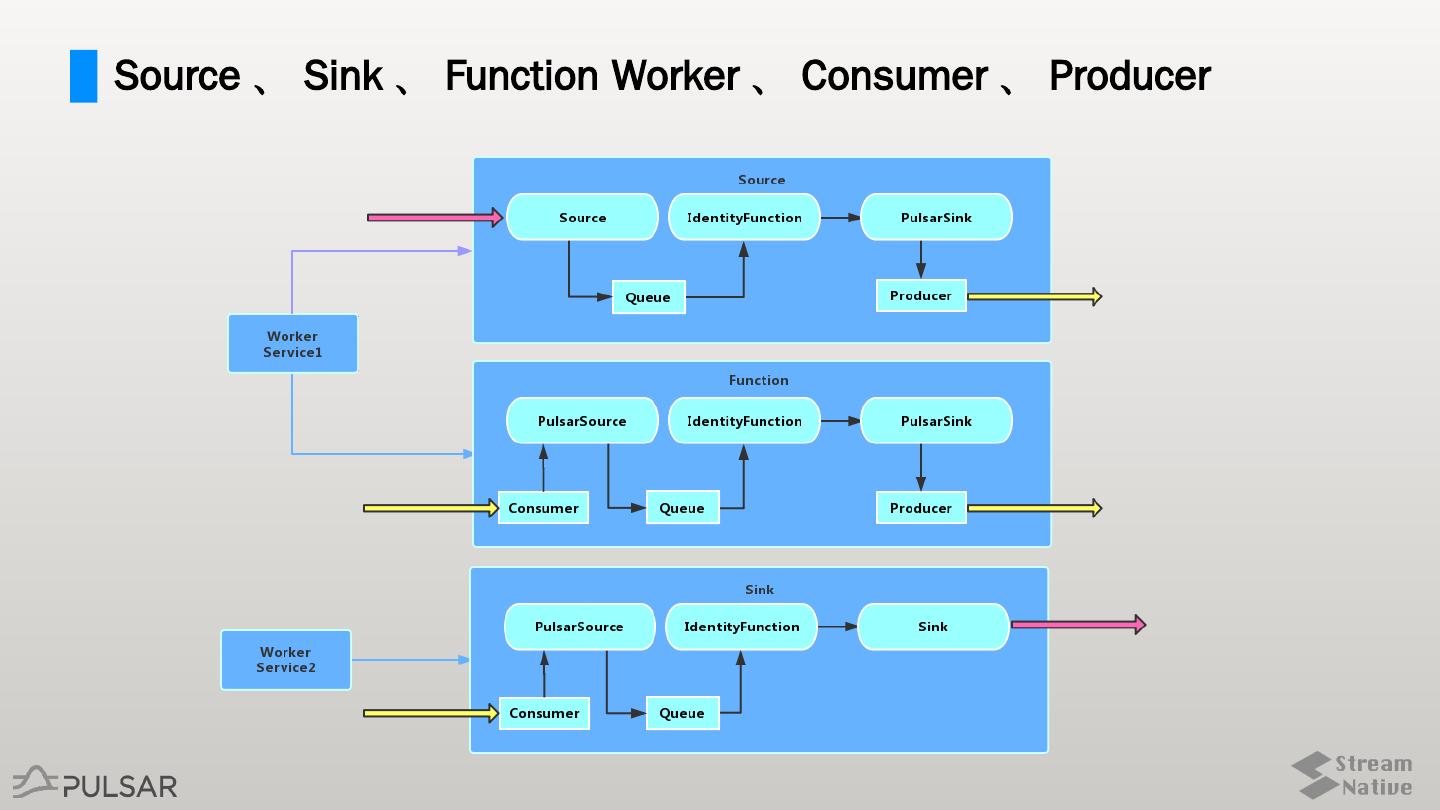
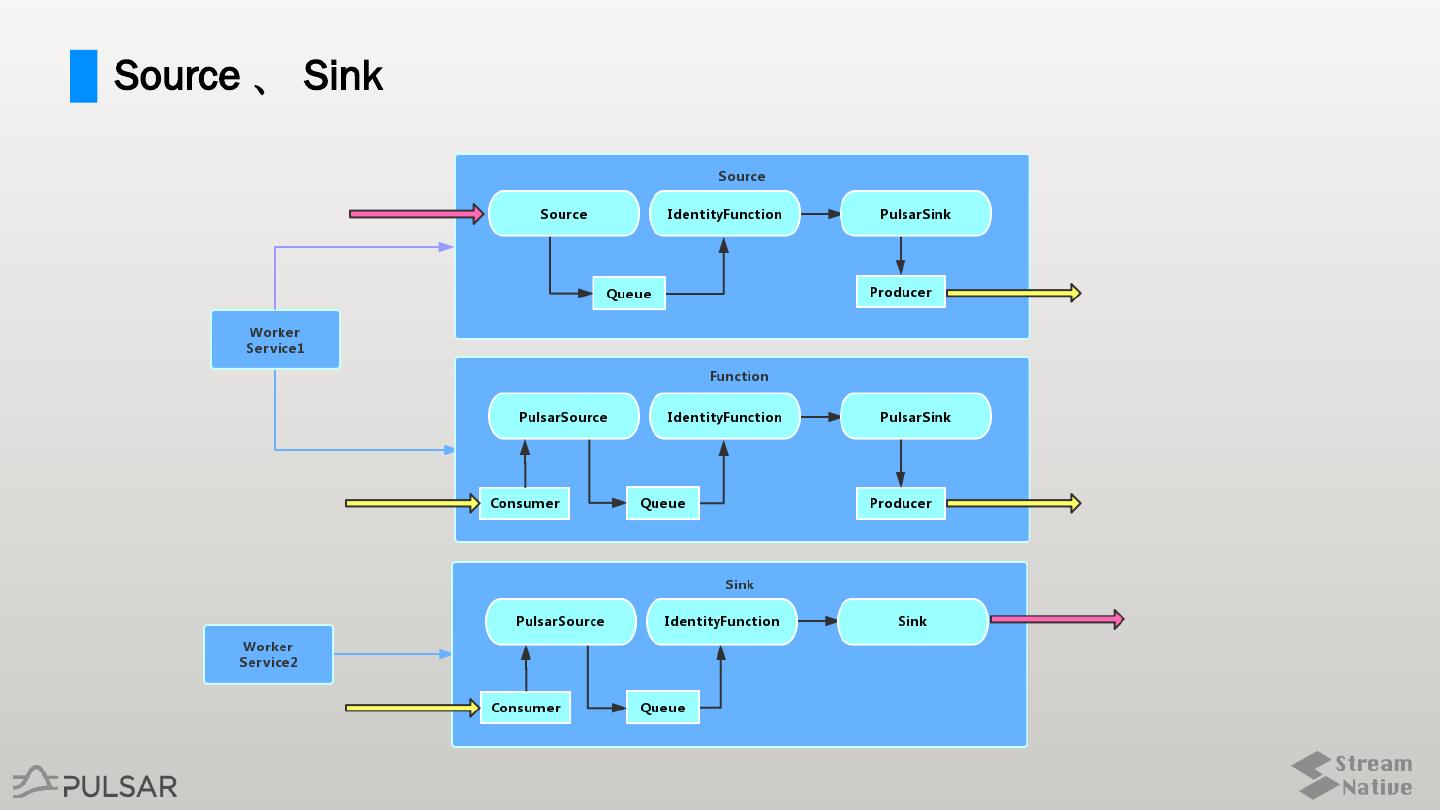
5 .Source 、 Sink 、 Function Worker 、 Consumer 、 Producer
�
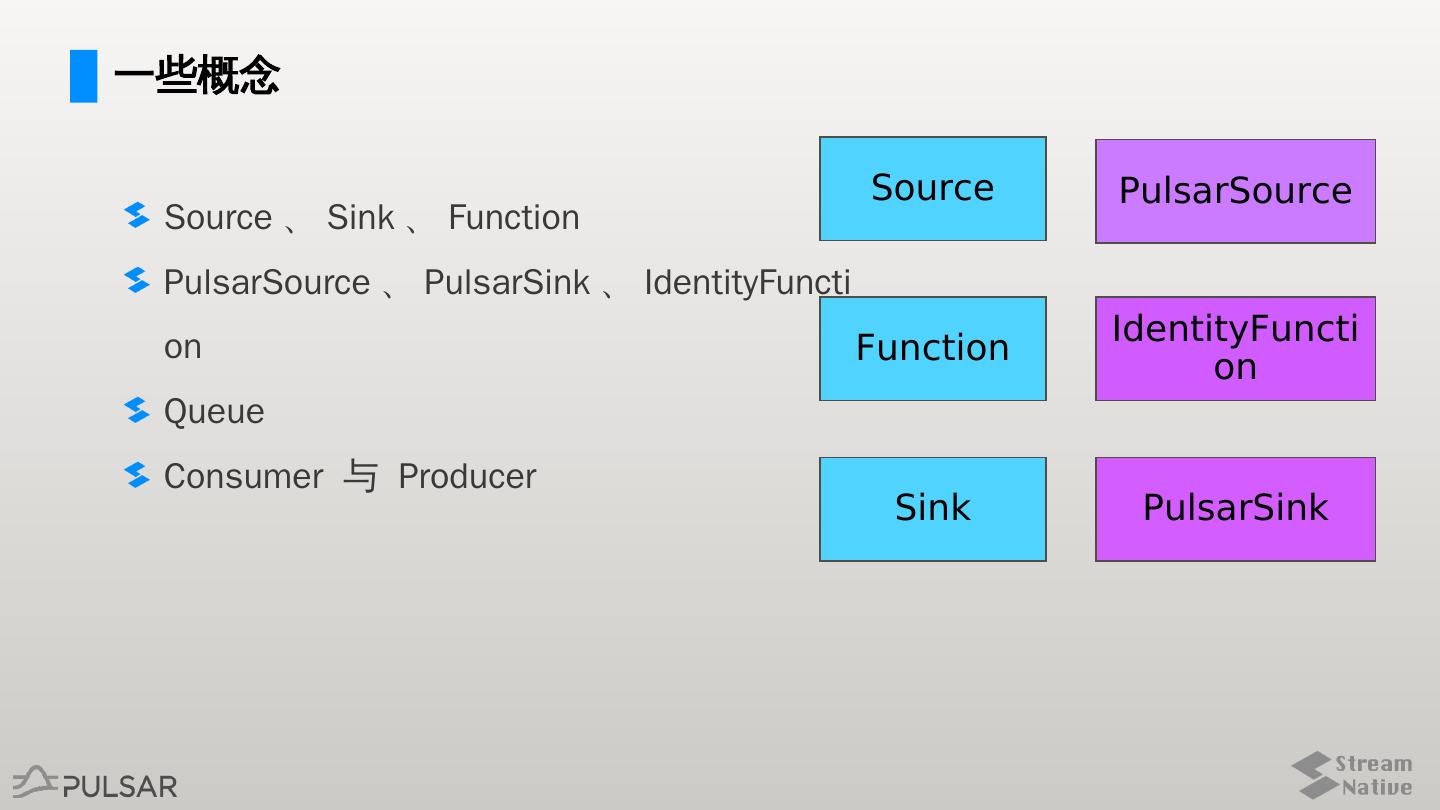
6 .一些概念
Source PulsarSource
Source 、 Sink 、 Function
PulsarSource 、 PulsarSink 、 IdentityFuncti
on IdentityFuncti
Function
on
Queue
Consumer 与 Producer
Sink PulsarSink
�
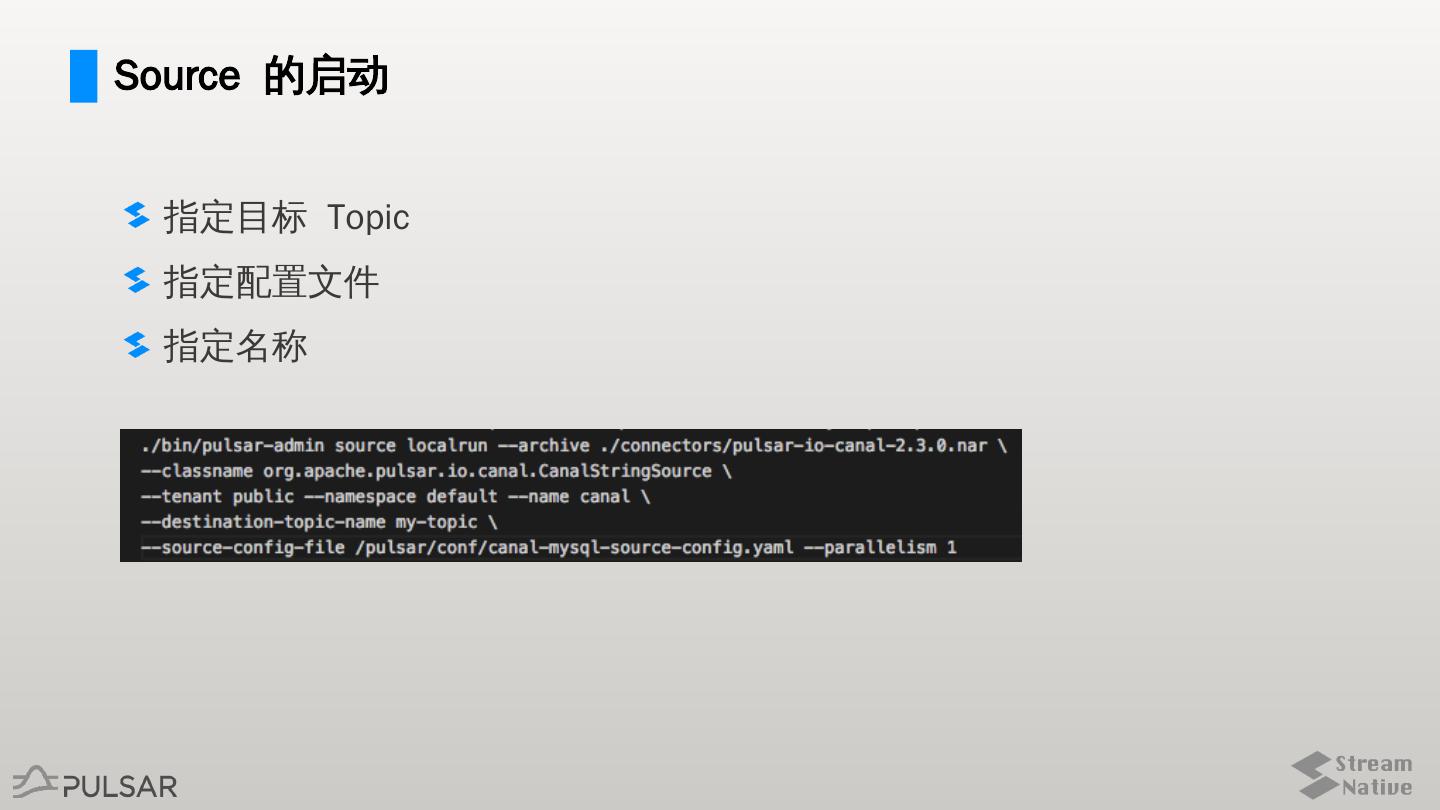
7 .Source 的启动
指定目标 Topic
指定配置文件
指定名称
�
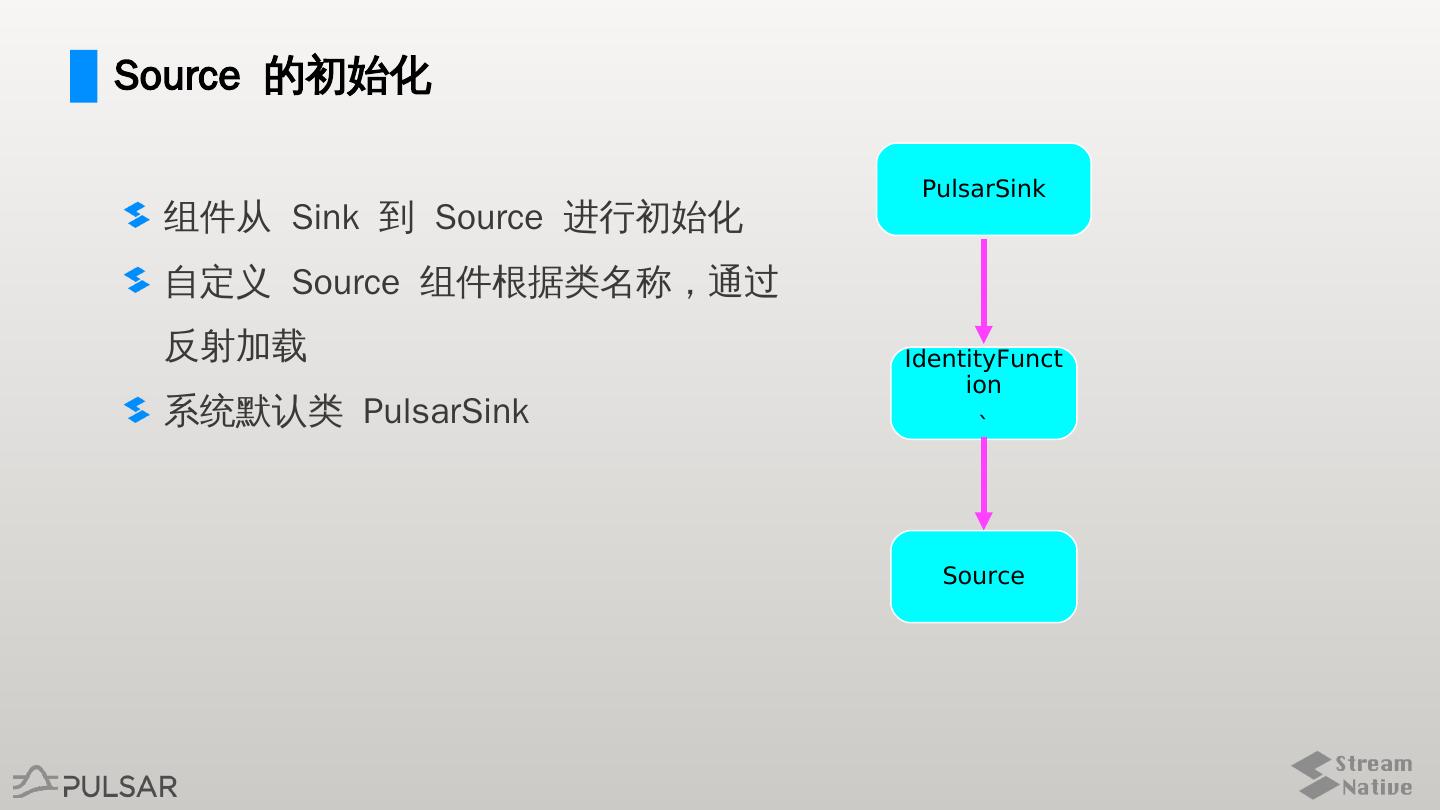
8 .Source 的初始化
PulsarSink
组件从 Sink 到 Source 进行初始化
自定义 Source 组件根据类名称,通过
反射加载 IdentityFunct
ion
系统默认类 PulsarSink `
Source
�
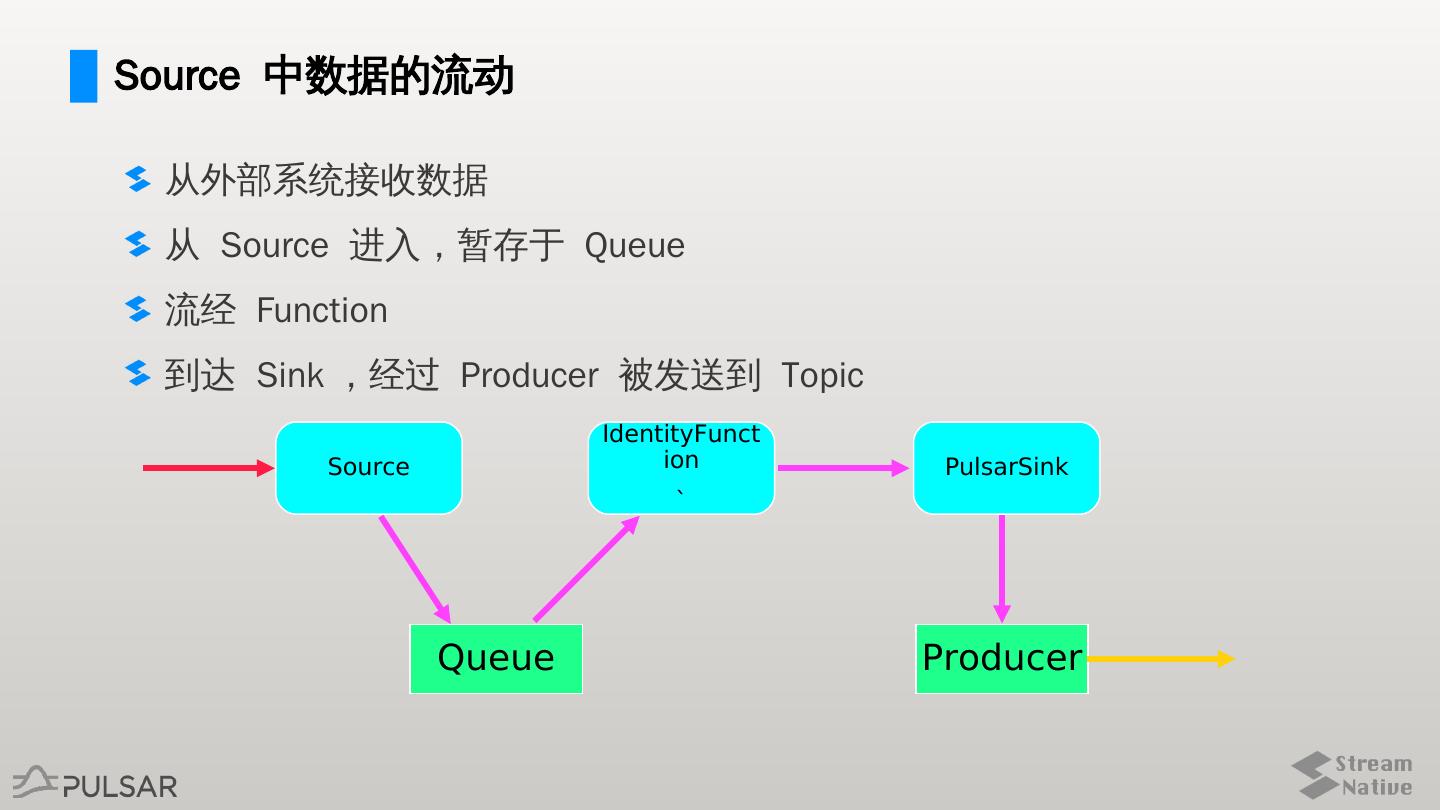
9 .Source 中数据的流动
从外部系统接收数据
从 Source 进入,暂存于 Queue
流经 Function
到达 Sink ,经过 Producer 被发送到 Topic
IdentityFunct
Source ion PulsarSink
`
Queue Producer
�
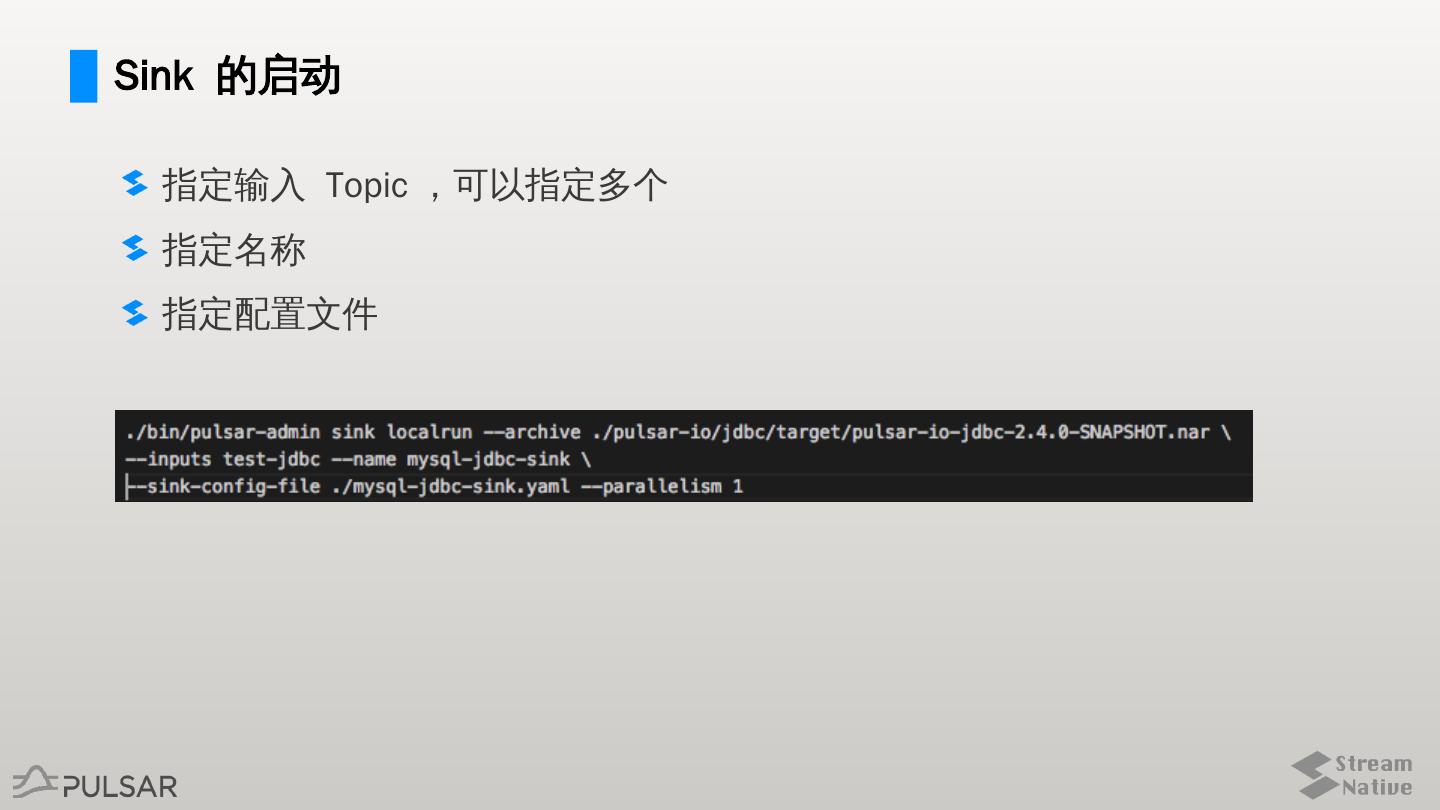
10 .Sink 的启动
指定输入 Topic ,可以指定多个
指定名称
指定配置文件
�
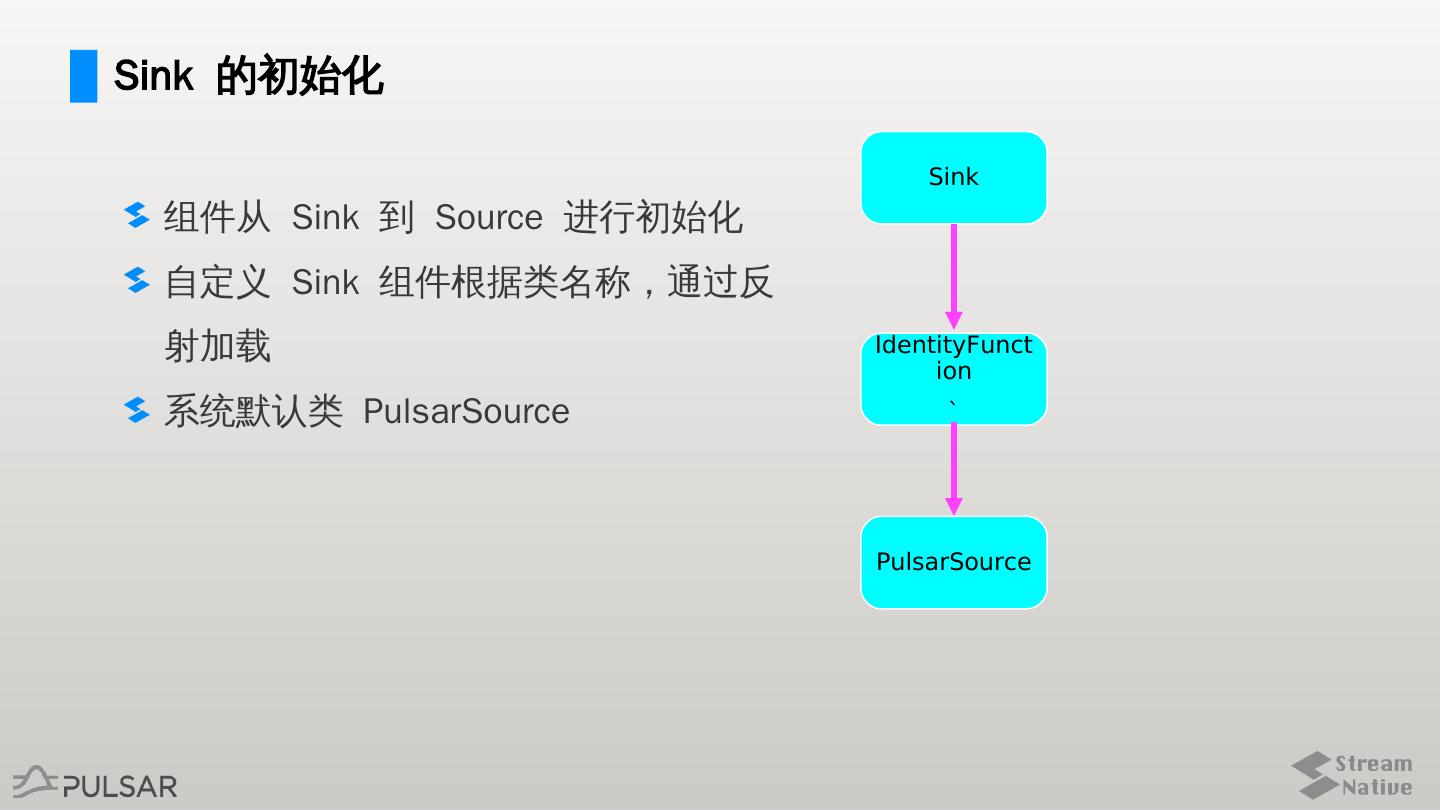
11 .Sink 的初始化
Sink
组件从 Sink 到 Source 进行初始化
自定义 Sink 组件根据类名称,通过反
射加载 IdentityFunct
ion
系统默认类 PulsarSource `
PulsarSource
�
12 .Sink 中数据的流动
PulsarSource 利用初始化的 Consumer 从 Topic 接收数据
将数据暂存于 Queue
流经 Function
到达用户自定义 Sink ,输出到外部系统
IdentityFunct
PulsarSource ion Sink
`
Consume
Queue
r
�
13 .对 Pub/Sub 的封装使
用
PulsarSource 封装了 Consumer
PulsarSink 封装了 Producer
�
14 .PulsarSink 中的 Producer
初始化 Schema
开启自动批处理
设置 LZ4 的消息压缩类型
设置消息的路由策略
设置发送的超时时间 0
设置 Topic
�
15 .PulsarSource 中的 Consumer
设置 Schema
设置订阅名称,订阅类型
设置 Topic
设置接收队列大小
设置 ack 的超时时间
设置死信队列
�
16 .Message
Value/data: 消息携带的数据
Key: 消息能使用其来做 hash ,决定数据发送到
哪里去
properties: 消息携带的属性
Producer name: 生产者的名字
Sequence id: 每条消息的唯一 id
�
17 .Producer 发送数据到 Topic
分区 Topic ,为每一个分区创建一个连接
分区名称 xxxx-partition-0 , xxxx-partition-1
三种路由策略,
RoundRobinPartition 、 SinglePartition 、 CustomPartition
default Sink 中使用自定义的路由策略 CustomPartition
Hash function 使用 Murmur3_32Hash
消息路由类 FunctionResultRouter
�
18 .CustomPartition 策略
Key 被提供,使用 key 做 hash
Key 没有被提供并且没有 sequence id ,使用
RoundRobinPartition
如果没有 key 并且 sequence id 被提供,则使用
sequence id 做 hash
�
19 .Consumer 从分区 Topic 接收数据
Failover 订阅模式下会被发送到当前活跃的 Consumer
Shared 订阅下按照算法来接收数据
�
20 .Shared 模式下从 Topic 接收数据
五个消费者、两种优先级、两种可接收的数据量
数字越小优先级越高,相同优先级顺序发送
达到可接收消息数限制不再投递
投递顺序: C1 、 C2 、 C3 、 C1 、 C4 、 C5 、 C4
�
21 .Pulsar 中的 Schema
支持多种序列化,反序列化方式( AVRO 、 JSON 、
PROTOBUF 、各种原生类型、 KeyValue )
支持多种兼容模式(向前、向后、全兼容)
支持注册中心,通过 Topic 统一输入与输出的
Schema
支持 AutoSchema
….
�
22 .Source 和 Sink 中使用 Schema
为 Topic 设置 Schema
在 Source 和 Sink 运行时指定 Schema
�
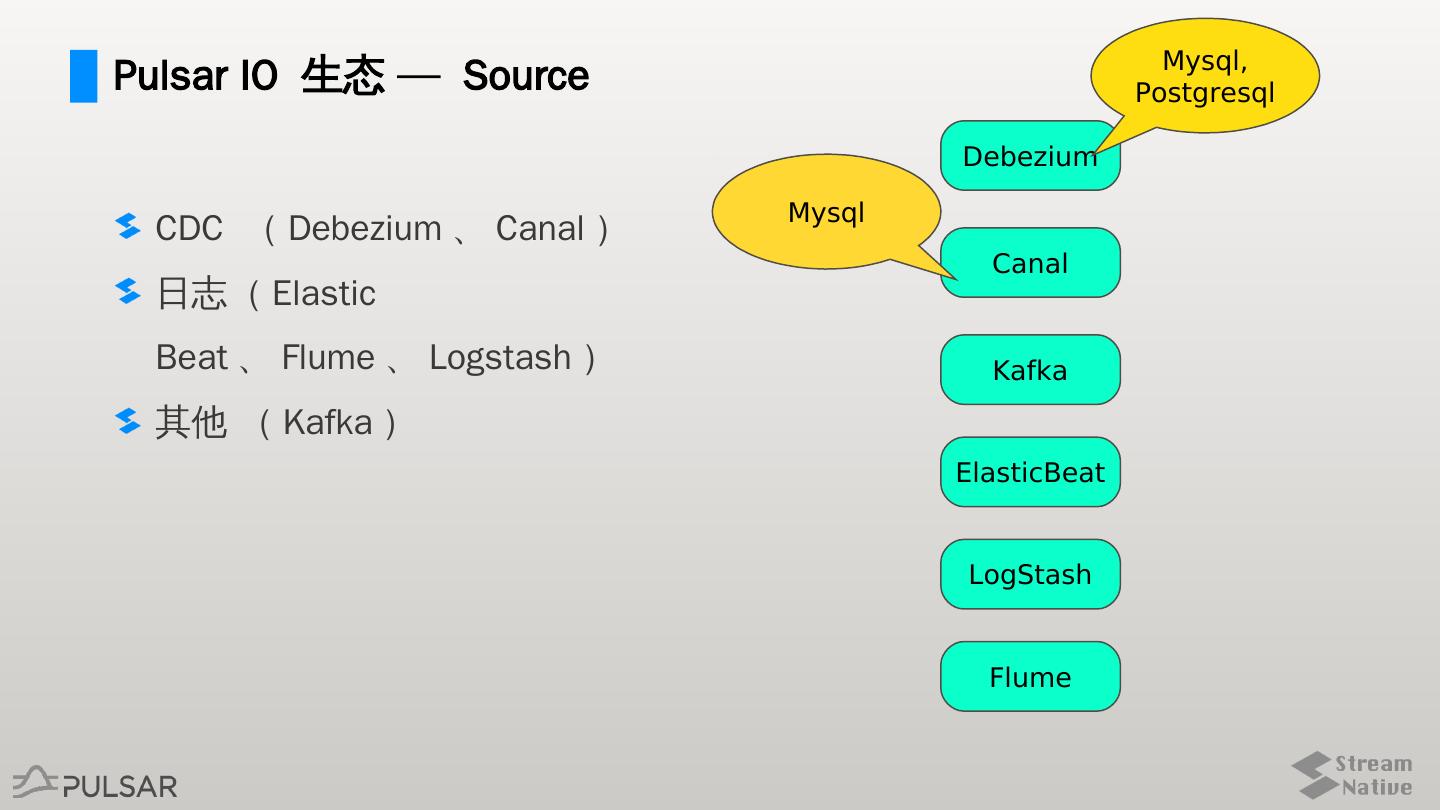
24 . Mysql,
Pulsar IO 生态 — Source Postgresql
Debezium
Mysql
CDC ( Debezium 、 Canal )
Canal
日志( Elastic
Beat 、 Flume 、 Logstash ) Kafka
其他 ( Kafka )
ElasticBeat
LogStash
Flume
�
25 .Pulsar IO 生态 — Sink
MongoDB
Redis
Hbase
Hdfs
JDBC
ElasticSearch
RabbitMQ
InfluxDB
…….
�
26 .如何快速开发一个 Source
继承 PushSource 类
实现 open 方法
实现消息的载体 Record 接口
使用 consume(record) 来实现发送消息到 Pulsar
在 pulsar-io.yaml 文件中增加 SourceClass 描述
�
27 .如何快速开发一个 Sink
实现 Sink 接口
增加 open 和 write 方法
在 pulsar-io.yaml 中增加 SinkClass 描述
�
28 .如何调试
启动 Pulsar 单机环境
使用 mvn 将你的项目编译成 nar 包
使用 pulsar-admin source/sink localrun 运行你的项目
在 logs/functions/tenant/namespace/function-name
下查看日志
�
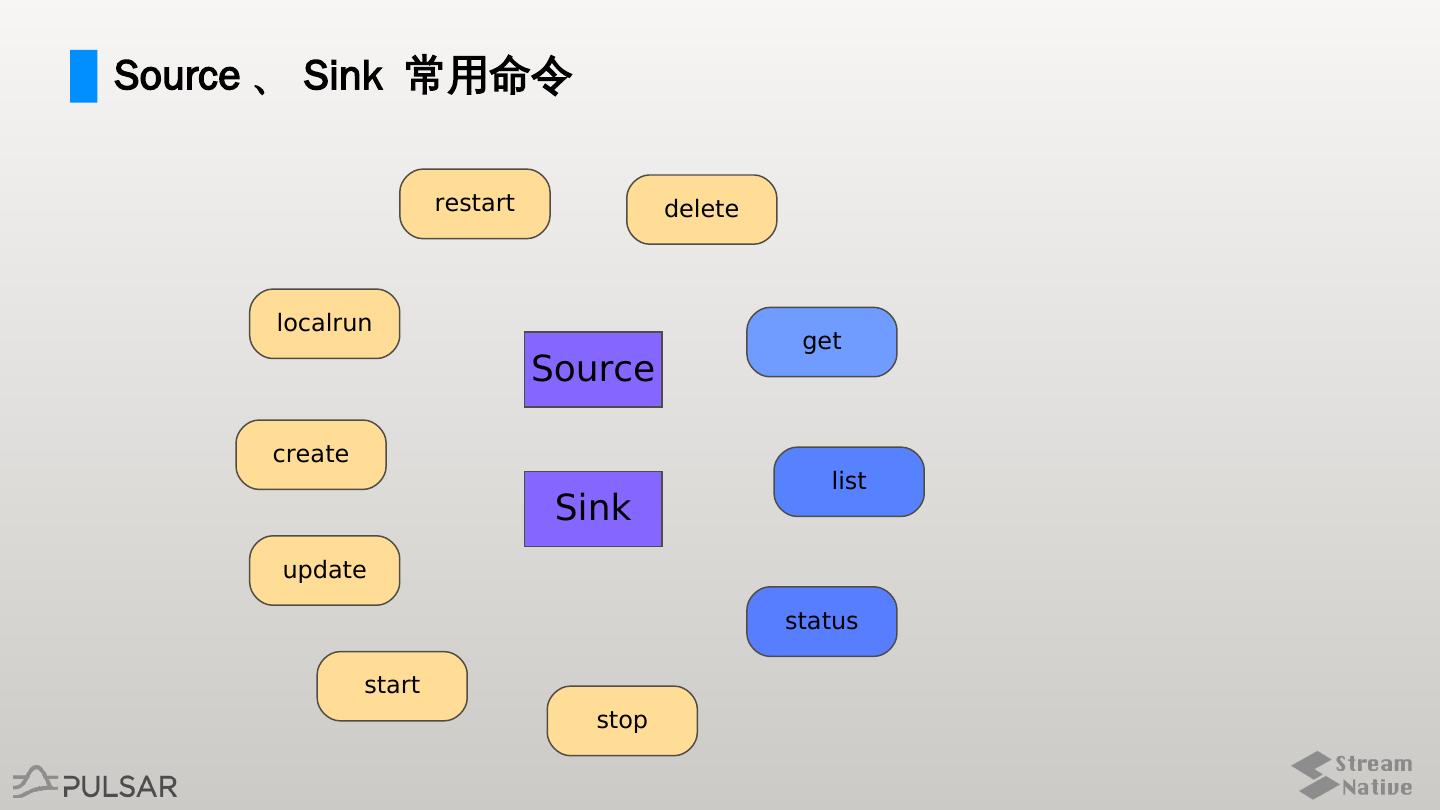
29 .Source 、 Sink 常用命令
restart delete
localrun
get
Source
create
list
Sink
update
status
start
stop
�